A LISP Programozási Nyelv
Zimányi Magdolna, Kálmán László, Fadgyas Tibor
Műszaki Könyvkiadó, 1989
Tartalom
A LISP nyelv
A LISP nyelv a mesterséges intelligencia kutatásának kezdettől fogva alapvető programozási nyelve, amely meghatározó szerepet játszik a kutatásban és az eredmények gyakorlati alkalmazásában is. A nyelv neve a "LISt Processing language" (listafeldolgozó nyelv) rövidítése. Míg a LISP nyelvvel közel egyidőben született ALGOL 60 és FORTRAN nyelvet elsősorban a numerikus számítások igényei alakították ki, a LISP nyelvet azért hozták létre, hogy szimbolikus (szimbólumokból álló) kifejezésekkel végzett műveletekre alkalmas nyelvet teremtsenek.
A LISP különleges programozási nyelv azért is, mert új elgondolások alapján tervezték meg. Ezek jelentőségét sok tekintetben csak ma tudjuk igazán értékelni. Ezáltal a LISP a funkcionális nyelveknek lett első és máig legfontosabb képviselője.
A funkcionális programozás
Egy ALGOL 60, FORTRAN vagy BASIC program az utasításoknak meghatározott sorrendben végrehajtandó sorozata. Ezeket a nyelveket imperatív nyelveknek vagy Neumann-elvű nyelveknek nevezzük. A LISP nyelvet ezzel szemben a matematikai függvényfogalomra alapozták, egy LISP program függvénykifejezések kiértékelésének sorozata. A LISP tehát az előbb említett nyelvekkel szemben a funkcionális programozás nyelve. Hosszú ideig az egyedüli ilyen nyelv volt. Jean E. Sammet, az IBM cég egyik vezető munkatársa, 1970 körül még így osztályozta a programozási nyelveket: "A programozási nyelveket két csoportba sorolhatjuk: az egyik csoportba tartozik a LISP, a másikba az összes többi nyelv". Ma ez a kijelentés már nem érvényes, részben éppen a LISP hatása miatt. Napjainkban a LISP leszármazottai a programozási nyelvek népes családját alkotják. Hatással volt a LISP olyan nyelvek fejlődésére is, amelyek nem LISP származékok, így pl. a logikai programozás nyelvére, a PROLOG-ra. Ez a mesterséges intelligencia kutatásának másik jelentős, növekvő fontosságú nyelve, amely szerepet kapott a japánok ötödik generációs számítógépes vállalkozásában is.
Kiemelik a LISP-et a magasszintű programozási nyelvek közül a nyelv szerkezetének sajátosságai is. A LISP nyelvben a programok és az adatok azonos szerkezetűek, nem különülnek el egymástól. Ezáltal egy LISP program létrehozhat és végrehajthat egy másik programot, a LISP programok önmagukat is módosíthatják.
A mesterséges intelligencia kutatásáról
A mesterséges intelligencia kutatásának körét nem könnyű meghatározni. Az "intelligencia" szó szokásos értelmezése: az embernek az a képessége, amellyel összefüggéseket ismer fel, következtetéseket von le, képes a körülmények (esetleg igen gyors és erősen próbára tevő) változásaihoz megfelelően alkalmazkodni, azokra megfelelően válaszolni. A számítógépek megjelenésével egyidős az izgalmas kérdés, hogy képes lesz-e a számítógép az emberhez hasonlóan intelligensen "viselkedni"; vagyis összefüggéseket felismerni, célok eléréséért feladatokat megoldani. A mesterséges intelligencia körébe azok az eszközök és módszerek tartoznak, amelyek a számítógépek ilyen viselkedésének megvalósítására irányulnak. Ide tartoznak a tanuló- és tanítóprogramok, továbbá azok a programok, amelyek az ismeretek adott rendszeréből következtetéseket képesek levonni, pl. a geometria vagy a számelmélet axiómáiból kiindulva új állításokat, tételeket bizonyítanak be. A mesterséges intelligencia kutatásának területéhez tartoznak a játékprogramok is. Itt természetesen nem az elterjedt egyszerű, de látványos videojátékokra gondolunk, hanem pl. a sakkprogramokra, amelyek egy bonyolult szabályrendszert alkalmazva meghatározott stratégia alapján a lehető legjobb eredmény elérésére - általában az ellenfél vagy ellenfelek legyőzésére - törekszenek.
A mesterséges intelligencia kutatásában kezdődött meg azoknak a programoknak a kidolgozása, amelyek természetes (vagyis emberi) nyelven képesek felhasználójukkal kommunikálni. Ennek óriási jelentősége van napjainkban, amikor a számítástechnika alkalmazása az élet minden területén megjelenik: az oktatásban és az irodákban, a termelésirányítási rendszerekben és a robotok alkalmazásában, a kórházi betegellátásban és a bankokban. A természetes nyelvi kommunikáció is hozzájárulhat ahhoz, hogy számítástechnikai szakképzettség nélküli felhasználók is segítőtársként vehessék igénybe a számítógépet. A számítógéppel való természetes nyelvi kommunikáció kutatása a nyelvészetben is számottevő fejlődést indított meg.
A mesterséges intelligencia kutatásának sikerei azt a sajátos eredményt is hozták, hogy egyes területei idővel többé-kevésbé önállósultak. Számos területen tapasztalhattuk, hogy az elvi alapok kellő tisztázása, a terület sajátos módszereinek kialakulása után a diszciplína különvált a mesterséges intelligenciától, és önálló életet kezdett élni. Példaként említhetjük a matematikai formulák szimbolikus kezelésével foglalkozó számítógépes algebrai rendszereket. Történeti érdekesség hogy a LISP nyelvet létrehozó csoport egyik fő célja éppen az volt, hogy - az "Advice taker" (Tanácsadó) nevű, következtetésekre képes program kidolgozása mellett - egy olyan programot hozzon létre, amely matematikai kifejezéseket formálisan tud differenciálni. A LISP létrejöttét tehát a számítógépes algebrai problémák megoldásának igénye is ösztönözte. Később azonban a számítógépes algebra kidolgozta saját módszereit, eszköztárát, és ma már önálló diszciplínának tekinthetjük. A LISP azonban továbbra is a számítógépes algebra legfontosabb nyelve maradt.
A mesterséges intelligencia kutatásában felmerülő feladatokat az jellemzi, hogy a megoldásukhoz összetett adatszerkezeteken bonyolult logikai eljárásokat kell végrehajtani. Ezekhez a követelményekhez a LISP nyelv természetes eszközként illeszkedik.
A LISP történetének rövid áttekintése
A LISP nyelvet az 1950-es évek végén a Massachusetts Institute of Technology munkatársai dolgozták ki az Egyesült Államokban, a MAC (Man and Computer, Ember és Számítógép) kutatási program keretében. A csoport vezetője John McCarthy volt, a LISP atyja, aki a mesterséges intelligencia kutatásának ma is vezető alakja. Számos jelentős gondolattal járult hozzá a programozási nyelvek fejlődéséhez, többek között az ALGOL 60 nyelv kidolgozásában is fontos szerepet játszott. Az első kézikönyv, amely a McCarthy és munkatársai által kidolgozott LISP 1.5 változatot ismertette, 1960-ban jelent meg; a változat neve szerényen utal arra, hogy alkotói maguk sem tekintették véglegesnek. Azóta hatalmas fejlődés ment végbe, a nyelvnek sok új - gazdagabb lehetőségeket kínáló - változatát dolgozták ki.
Kezdetben a LISP rendszerek viszonylag nagy tárigénye és lassúsága akadályozta a nyelv elterjedését. A 70-es évek közepétől kezdve azonban a fejlődés a számítógépek sebességének és tárkapacitásának gyors növekedését és a hardware költségeinek csökkenését hozta magával. Ez tette lehetővé a LISP nyelv széles körű elterjedését. Ma a professzionális személyi számítógépeken is számos LISP rendszer áll a felhasználók rendelkezésére. Az elmúlt tíz évben pedig olyan számítógépeket is terveztek és hoztak kereskedelmi forgalomba, amelyeknek hardware architektúrája a LISP nyelv szerkezetéhez alkalmazkodik.
A LISP változatokról
A LISP változatok nagy száma a programozó számára gazdag lehetőségeket kínál, aki azonban a nyelvvel akar megismerkedni, annak nehézséget is jelent. Számos programozási nyelv - pl. a FORTRAN és a COBOL - szabályait nemzetközi szabvány rögzíti. Amikor egy szabvánnyal rendelkező nyelvről szerzett ismereteinket a gyakorlatban akarjuk használni, akkor számíthatunk arra, hogy a nyelvnek egy konkrét számítógépen hozzáférhető változata, gépi reprezentációja követi a szabványt. Ha pedig a gépi megvalósítás esetleg eltér a szabványtól - gyakran úgy, hogy bővítéseket tartalmaz ahhoz képest -, akkor bízhatunk abban, hogy a szabványon alapuló leírás, és az adott gépi változatot ismertető kézikönyvek segítségével ezeket az eltéréseket általában viszonylag könnyen áttekinthetjük.
A LISP nyelvre azonban mindezideig nincsen érvényes szabvány. A LISP változatok egymástól erősen különböznek.
Nem remélhetjük tehát, hogy ha az olvasottakat egy számítógép LISP rendszerében ki akarjuk próbálni, vagy ha egy másik LISP könyvet veszünk kézbe, akkor mindent ugyanúgy találunk, mint ahogy ebben a könyvben le van írva. A nehézségektől azonban nem kell visszariadnunk. Egyrészt a LISP nyelv hallatlanul egyszerű alapelvekre épül, rendkívül világos logikát követ, és ezek az alapelvek lényegében minden változatban közösek. Ha tehát a LISP nyelvre jellemző gondolkodásmódot elsajátítottuk, nem jelent nagy nehézséget egy újabb LISP rendszer megismerése, az eltérések áttekintése.
A változatok sokfélesége azért sem teszi helyzetünket reménytelenné, mert a LISP rendszerek néhány nagyobb családba sorolhatók, egy-egy jelentős LISP változat köré számos, hozzá hasonló változat csoportosul. A fontosabb családok: a Common LISP, az INTERLISP, a Maclisp (ennek ismertebb közeli rokonai közül megemlítendő még a Franz Lisp, és a Zetalisp), valamint a Standard LISP (amely neve ellenére nem vált szabvánnyá!). Célszerű, ha ezeknek a családoknak a legfontosabb jellemzőiről tájékozódunk, és ha tudjuk, hogy az általunk használt változat melyik családba tartozik. Még nem dőlt el a kérdés, hogy a jövőben melyik változat lesz a legelterjedtebb. Pillanatnyilag a Common LISP áll a legközelebb ahhoz, hogy egy kidolgozandó nyelvi szabvány alapjává váljon. A Maclisp egy adott géptípushoz kötött változat, ezért ma már kisebb jelentőségű, inkább "leszármazottai" révén hat a nyelv fejlődésére. Az INTERLISP-nek is sok leszármazottja van; itt említjük meg a sok gépen rendelkezésre álló LISP F3, ill. LISP F4 változatokat. Megjegyezzük, hogy más könyvekben a rokonsági fokok másféle osztályozásával is találkozhatunk, egyes szerzők pl. a Common LISP-et a Maclisp leszármazottai közé sorolják.
Az Olvasónak azt tanácsoljuk, hogy amikor egy számára új LISP rendszerrel kezd dolgozni, feltétlenül igyekezzék azt tisztázni, hogy ez milyen fontos tulajdonságokban különbözik más, általa már ismert - vagy az ebben a könyvben leírt - LISP rendszerektől, ill. miben egyezik meg azokkal.
Kiknek írtuk a könyvet?
Könyvünket mindazoknak szánjuk, akiket a számítógépek nem numerikus alkalmazásai érdekelnek. Nemcsak a számítástechnikával foglalkozók, hanem más szakterületeken tevékenykedő szakemberek érdeklődésére is számítunk. Ezért nem feltételezzük valamilyen programozási nyelv ismeretét, a könyv különösebb előismeretek nélkül is tanulmányozható. Csak annyi számítástechnikai tájékozottságot feltételezünk, amennyi ma már az általános műveltséghez tartozik. Akik már ismernek valamilyen programozási nyelvet, azoknak kitekintő megjegyzésekkel tesszük lehetővé az összehasonlítást. Matematikai ismeretekben sem feltételezünk többet a középiskolai tananyagnál.
Fel kell azonban hívnunk a figyelmet arra, hogy a LISP sajátos gondolkodásmódot kíván. Ennek oka a funkcionális és az imperatív nyelvek alapvetően eltérő szemléletmódjában rejlik, és éppen a más programozási nyelvet már ismerők számára jelenthet nehézséget. Ezért mondja ironikusan Malcolm A.C. MacCallum: "... azt mondják, hogy valaki már három hét alatt egészen jól megtanulhatja a LISP programozást - kivéve, ha előzőleg már FORTRAN nyelven tanult programozni, mert ekkor a tanulás akár hat hétig is eltarthat." Az imperatív nyelvekhez szokott programozónak nehézséget jelenthet ennek a sajátos gondolkodásnak az elsajátítása. Reméljük azonban, hogy olvasóink nem riadnak vissza ettől az erőfeszítéstől, és a LISP nyelv megismerése örömet okoz számukra.
A könyv felépítése
A LISP nyelvet tizenkét fejezetben mutatjuk be. Arra törekedtünk, hogy az Olvasó minél hamarabb azoknak az eszközöknek a birtokába jusson, amelyekkel felépítheti saját programjait. Ezt a törekvést megkönnyítette számunkra a LISP egyszerű és egységes szerkezete.
Az első öt fejezet a tulajdonképpeni bevezetés a LISP nyelvbe; az 1-3. fejezetekben írjuk le a legszükségesebb ismereteket. A 1. fejezetben a nyelv alapfogalmait, az atom, a lista fogalmát tárgyaljuk, és eljutunk a függvények alkalmazásához.
A 2. fejezetben mutatjuk be a LISP legfontosabb beépített függvényeit.
A 3. fejezetben tárgyaljuk a függvények definiálásának módját, ekkor már egyszerű programozási feladatokat meg tudunk oldani.
A 4. fejezetben elmélyítjük az eddig megszerzett ismereteket gyakorlással, sok példa bemutatásával; ennek során bevezetjük a halmazok kezelésére szolgáló függvényeket.
Az 5. fejezetben a tulajdonságlistákat, a szimbólumok közötti kapcsolatok ábrázolásának fontos eszközeit ismertetjük, majd pedig az eddig megismert függvényeket rendszerezzük, típusokba soroljuk.
Aki már ismer valamilyen programozási nyelvet, az első három fejezeten könnyen és gyorsan áthaladhat. Mégsem szabad sajnálni azonban az időt a 4. és 5. fejezet példáiban való elmélyedésre, a megszerzett ismeretek gyakorlására.
A bevezető fejezetek után a 6. fejezet mélyebb ismereteket nyújt; bemutatja, hogyan tárolja a LISP rendszer az atomokat és listákat a számítógép tárában. Ezzel jobban megérthetjük az eddig megismert függvények működését is, és újabb - igen hatékony, de óvatosan kezelendő - eszközöket ismerünk meg, a listaromboló függvényeket, amelyekkel a tár tartalmát megváltoztathatjuk.
A 7. fejezetben vezetjük be a magasabbrendű függvényeket, a LISP programozás legjellemzőbb és leghasznosabb eszközeit. Ezek a funkcionál matematikai fogalmához állnak közel, mivel argumentumuk maga is függvény.
A 8. fejezetben a LISP értelmezőprogram működésének további részleteit ismerjük meg, a lokális értékek nyilvántartásának módját. Visszatérünk a függvényeknek mint argumentumoknak a kezelésével kapcsolatos elvi nehézségekre is, itt tárgyaljuk a nevezetes funarg-problémát. Ebben a fejezetben írjuk le azokat a hasznos segédeszközöket, amelyekkel - hibakeresés, hibajavítás céljából - nyomon követhetjük a kiértékelés lépéseit. Ezeknek az ismereteknek a megszerzésével a LISP programozásban felsőbb osztályba léptünk, új ismereteinkkel tömörebb, elegánsabb, áttekinthetőbb programokat tudunk létrehozni.
A következő három fejezet az eddig tanultakat fontos részekkel egészíti ki. A LISP nyelv ugyan alapvetően a rekurzívan definiált függvények alkalmazására épül, de használhatók benne nemrekurzív eszközök is, ezeket a 9. fejezet írja le.
A 10. fejezet a nyelv bemeneti és kimeneti eszközeit ismerteti.
A 11. fejezetben visszatérünk az értelmezőprogram működésének vizsgálatához. Röviden foglalkozunk a LISP programok lefordításának módjával, a fordítóprogram használatával is.
A könyv utolsó, 12. fejezetében a LISP nyelv "valódi" alkalmazásaiba adunk kitekintést nagyobb példák részletes kidolgozásával. Ezzel eljuthatunk az önálló programozásig, egyszersmind a LISP néhány jellemző alkalmazási területét, az ott alkalmazott módszereket, adatábrázolási módokat is megismerhetjük. Természetesen ez a fejezet is csak ízelítőt adhat a LISP nyelv kimeríthetetlenül gazdag alkalmazási területeiből. Reméljük azonban, hogy aki eljutott könyvünk végéig, kedvet kap a további LISP programozáshoz.
A könyv példáiban igyekeztünk követni a "csigalépcső-elvet". A LISP nyelvben már néhány alapvető ismeret birtokában is igen sok feladatot meg lehet oldani. Az első fejezetekben bemutatott egyes feladatokra a későbbi fejezetekben ismételten visszatérünk, és megmutatjuk, hogyan lehet ezeket az újonnan elsajátított ismeretekkel tömörebben, hatékonyabban megoldani.
Könyvünket néhány függelék egészíti ki. Röviden áttekintjük - a teljesség igénye nélkül - a ma legelterjedtebb LISP változatok legfontosabb eltéréseit. Mivel a LISP programozó életének jelentős részét tölti zárójelek számlálásával, ezt a munkát egy egyszerű eljárás ismertetésével igyekszünk megkönnyíteni. A következő függelék a könyvben kitűzött feladatok megoldását tartalmazza, majd pedig a könyv szövegközi példáiban szereplő hibaüzeneteket foglaljuk össze. Ezeknek az áttekintése segítségünkre lehet akkor, amikor a gyakorlatban egy valódi értelmezőprogram hibaüzeneteivel találkozunk. Közlünk egy kis angol-magyar szótárt is, amely a függvénynevekben előforduló szavakat tartalmazza. Végül a könyvet függvénymutató egészíti ki.
A szerzők köszönetét mondanak a könyv lektorának, Krammer Gergelynek, aki lényegre tapintó kérdéseivel és megjegyzéseivel indíttatást adott arra, hogy újból és újból átgondolják és tovább csiszolják a könyvben leírtakat. Köszönettel tartoznak Lőcs Gyulának és Prószéky Gábornak, akik a számos értékes megjegyzéssel járultak hozzá a kézirat jobbításához. Köszönik Vámos Istvánnénak a kézirat változatainak gondos átolvasását, javítását, a kötet példaanyagának számítógépen való kipróbálásában nyújtott fáradhatatlan segítségét. A szerzők egyike (K.L.) külön köszönetét mond egykori hallgatóinak, a Magyar Tudományos Akadémia Nyelvtudományi Intézetében 1985-ben általa tartott LISP tanfolyam résztvevőinek; nekik is köszönheti, ha a LISP lényegét másoknak is el tudja magyarázni.
1.1. Az atomok
Az atomok a LISP nyelv elemi építőkövei. Nevüket onnan kapták, hogy a nyelv eszközeivel nem lehet őket alkotórészekre bontani.
Később látni fogjuk, hogy a fizika atomjaihoz hasonlóan a LISP atomjai sem "oszthatatlanok", ezeknek is van "szerkezetük". Ezt azonban kezdetben figyelmen kívül hagyhatjuk.
A LISP nyelv kétféle atomot ismer, szimbolikus atomot (más néven szimbólumot) és numerikus atomot (más néven számot). A szimbolikus atomok betűkből és számjegyekből álló karaktersorozatok, amelyeknek első karaktere mindig csak betű lehet. (Karakternek nevezzük összefoglaló néven a betűket, a számjegyeket és az egyéb írásjeleket. A karaktereknek a terminálon, sornyomtatón a látható képe jelenik meg, a számítógép tárában pedig egy szám alakjában tárolódnak. Vannak olyan karakterek is, amelyeknek nem felel meg látható kép, hanem valamilyen vezérlő funkciójuk van, ilyen pl. a sorvégjel.) A LISP nyelvben betűn az angol ábécé huszonhat nagybetűjét értjük, azaz az A, B, C, ..., X, Y, Z karaktereket. A szimbólumok hosszúsága nincs korlátozva. Megjegyezzük azonban, hogy a LISP rendszerek egy részében a szimbólum nem lehet tetszőlegesen hosszú. Szimbólumok pl.:
A
B
AB
MACSKA
KUTYA1
KUTYA2
NIL
ADD1
PACIFIC231
R2D2
C2H6
LEGESLEGMEGENGESZTELHETETLENEBB
Az atomok másik csoportját alkotják a numerikus atomok, más néven számok. Ezek a 0, 1, ..., 9 számjegyekből állhatnak. Az első számjegy előtt + vagy - előjel állhat; pozitív számok előtt az előjel kiírása nem kötelező. Pl.:
25
0
-124
+3333
Egyes LISP rendszerekben (IS-LISP, LISP/80) csak az egész számokat használhatjuk, más rendszerek megengedik a valós számok használatát is. Az utóbbiakban a valós számok tizedespontot és kitevőrészt is tartalmazhatnak: a 123 számot pl. valós számként a +1.23E+02 formában is írhatjuk. Könyvünkben csak az egész számok használatát tekintjük megengedettnek.
Atom belsejében nem fordulhat elő a szóköz karakter, mert ez az atom végét jelenti:
és hasonlóképpen
Az atom végét jelenti a sor vége is. A szóköz és a sorvégjel az ún. elhatárolójelek közé tartozik: később megismerünk más elhatárolójeleket is.
Állapítsuk meg az alábbi karaktersorozatokról, hogy atomok-e: ha igen, akkor azt is döntsük el, hogy szimbólumok vagy numerikus atomok!
| ALFA 27 HATVANHAT T B12 -987 LADA1200S PLUS |
szimbólum; numerikus atom (szám); szimbólum; szimbólum; szimbólum; numerikus atom (szám); szimbólum; szimbólum; |
de
6VAN
nem atom, nem szimbolikus atom, mert számjeggyel kezdődik; és nem is numerikus atom, mert olyan karaktert is tartalmaz, amely nem számjegy és nem is előjel (betűt).
2+3
sem atom, bár csak olyan karaktereket tartalmaz, amelyek számokban szerepelhetnek, de nem megengedett sorrendben: a + jel nem az első előforduló számjegy előtt áll.
KIAZ?MIAZ?
nem atom, mert atomokban meg nem engedett karaktert tartalmaz, a kérdőjel karaktert (?).
Egyes LISP rendszerek a szimbolikus atomokban a betűkön és a számjegyeken kívül más karaktereket is megengednek (IS-LISP). Ezek a rendszerek atomként fogadhatnak el olyan karaktersorozatokat is, amelyek előző definícióinknak nem tesznek eleget. Vannak olyan LISP rendszerek, amelyek elfogadják a szimbólumokban a kisbetűket is, mi azonban csak a nagybetűket használjuk.
1.2. A listák
Atomokból épülnek fel a listák. A listákat atomok és elhatárolójelek segítségével írhatjuk le. Az elhatárolójelek közül már találkoztunk a szóközzel és a sorvégjellel. Ugyancsak elhatárolójel a kezdő zárójel "(" és a bezáró zárójel ")" is. Az atomokat tehát szóközök, sorvégjelek és zárójelek határolják. Egy lista kezdő zárójellel kezdődik, ez után következnek egymástól egy vagy több szóközzel elválasztva vagy új sorban kezdve a lista elemei, a lista végét pedig bezáró zárójel jelöli. A lista elemei atomok vagy maguk is listák lehetnek. A
(KUTYA MACSKA)
lista kételemű, elemei a KUTYA és MACSKA atomok. Háromelemű a
(TIMES 3 5)
lista, elemei a TIMES szimbólum, valamint a 3 és 5 számok. A
(KETSZER 2 NEHA 5)
lista négyelemű, a KETSZER, 2, NEHA és 5 atomokból áll. Végül a
(MAJOM)
lista egyelemű, egyetlen eleme a MAJOM atom.
Azokat a listákat, amelyeknek minden eleme atom, egyszerű listának nevezzük. Egy listának azonban lista is lehet eleme, így a
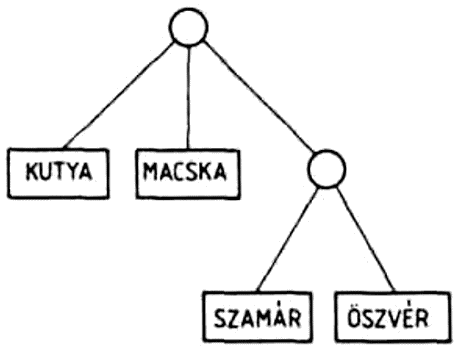
(KUTYA MACSKA (SZAMAR OSZVER))
háromelemű lista első eleme a KUTYA, második eleme a MACSKA atom, harmadik eleme pedig maga is lista, a (SZAMAR OSZVER) kételemű lista.
Egy listának azokat az elemeit, amelyek maguk is listák, az eredeti lista allistáinak nevezzük. A (KUTYA MACSKA) listának minden eleme atom, ennek a listának nincs allistája. A (KUTYA MACSKA (SZAMAR OSZVER)) listában a (SZAMAR OSZVER) az eredeti listának egy allistája. Egy allistának is lehet allistája: az
((ALMA (BARACK CSERESZNYE)) (((DINNYE) EPER)))
kételemű lista elemei olyan listák, amelyeknek maguknak is van allistája. Az (ALMA (BARACK CSERESZNYE)) listának allistája a (BARACK CSERESZNYE) lista, az eredeti lista második elemének, a (((DINNYE) EPER)) listának pedig allistája (és egyetlen eleme) a ((DINNYE) EPER) lista.
Figyeljünk fel arra, hogy ha egy atomot vagy listát egy zárójelpárral veszünk körül, ezzel új, az előzőtől különböző listát hozunk létre:
1.1.1. A listák ábrázolása
A listákat szemléletesen gráfokkal ábrázolhatjuk. A
(KUTYA MACSKA (SZAMÁR ÖSZVÉR))
lista ábrázolása:
Az ábra magyarázatához össze kell foglalnunk a gráfokra vonatkozó legfontosabb fogalmakat. A gráf csúcspontokból és élekből álló alakzat, minden él két csúcspontra illeszkedik. A v és w csúcspontokat összekötő élet (v,w)-vel jelöljük. Az élekhez irányt is rendelhetünk, ekkor a (v,w) és (w,v) éleket különbözőknek tekintjük. A (v,w) irányított élnek v a kezdő-, w pedig a végpontja. A gráfot irányítottnak nevezzük, ha az élei irányítottak. Egy irányítatlan gráfban a (v,w) és a (w,v) éleket azonosnak tekintjük.
Az (irányított vagy irányítatlan) gráfnak egy
(v1,v2), (v2,v3), ... (vn-1,vn)
élsorozatát útnak nevezzük. Ez az út v1-ből vn-be vezet, és a hossza n-1, az utat alkotó élek száma. A gráfot összefüggőnek nevezzük, ha bármely két csúcspontját út köti össze.
Ha a gráfban egy út kezdőpontja megegyezik a végpontjával, azaz a (v1,v2), (v2,v3), ... (vn-1,vn) útban v1 megegyezik vn-nel, akkor ezt az utat körnek nevezzük. Ha a gráf véges számú csúcspontot tartalmaz, véges gráfnak nevezzük. A továbbiakban csak véges gráfokkal foglalkozunk.
Különleges tulajdonságokkal rendelkező irányított gráfok az irányított fák. így nevezzük az olyan irányított gráfot, amely a következő tulajdonságokkal rendelkezik:
Azokat a csúcspontokat, amelyekből nem indul ki él, a fa leveleinek, azokat a csúcspontokat pedig, amelyekből kiindul él, a fa elágazási pontjainak nevezzük.
A fában a v csúcspont mélységének a gyökértől a hozzá vezető út hosszát nevezzük. Mivel a definícióból következik, hogy a gyökértől minden csúcsponthoz csak egyetlen út vezet, ezért a csúcspont mélysége egyértelműen meg van határozva.
Ha a v csúcspontból a (v,w1), (v,w2),... , (v,wn) élek indulnak ki, akkor a w1,w2,... ,wn pontokat a v fiainak nevezzük.
Rendezett fáról beszélünk, ha minden csúcspont fiaihoz sorszámot rendelünk. Az ilyen fát úgy rajzoljuk fel, hogy a csúcspontok fiai balról jobbra sorszám szerint következzenek.
Egy listát olyan irányított rendezett fával ábrázolhatunk, amelyben a fa v0 csúcspontjából (a fa gyökeréből) n számú él indul ki, ahol n a lista elemeinek száma. Az élek v1, v2, ... vn végpontjai felelnek meg a lista elemeinek. Ha a listaelem atom, a megfelelő csúcspontból nem indul ki újabb él, ez a fa egy levele. Ha a listaelem allista, akkor a megfelelő csúcspont elágazási pont, amelyből ismét annyi él indul ki, ahány eleme az allistának van.
A példánkban szereplő háromelemű listát tehát olyan fával ábrázolhatjuk, amelynek gyökeréből három él indul ki. Mivel a lista összesen négy atomot tartalmaz, ezért a fának négy levele van. A listának azért kell rendezett fát megfeleltetnünk, mert a listában az elemek sorrendje is számít: ha a listában két elemet felcserélünk, más listát kapunk.
Hasonlóképpen rajzolhatjuk fel az ((ALMA (BARACK CSERESZNYE)) (((DINNYE) EPER))) listának megfelelő fát is:
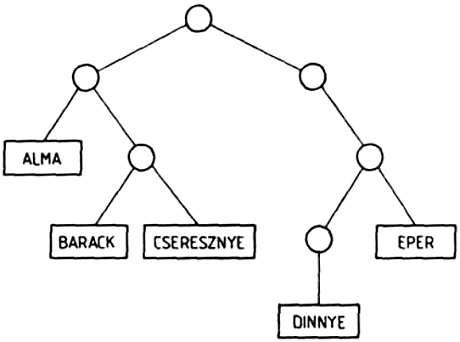
Vizsgáljuk meg, hogy az ALMA atom eleme-e ennek a listának? Könnyen beláthatjuk, hogy nem eleme, hiszen a lista két eleme két allista. A lista az ALMA atomot egy allistájának az elemeként tartalmazza.
Ezt úgy is megfogalmazhatjuk, hogy a lista nem a legfelső szinten tartalmazza az ALMA atomot, hanem a második szinten, vagy másképpen 2-es mélységben. Az ábráról is leolvashatjuk az egyes atomok mélységét: a listában az atom mélysége megegyezik a neki megfelelő fában az atomhoz tartozó csúcspont mélységével. A lista a BARACK és a CSERESZNYE atomokat a 3-as mélységben tartalmazza, mivel ezek egy allista (az első allista) allistájának az elemei: a DINNYE atomot még egy szinttel mélyebben, a 4-es mélységben, és végül az EPER atomot ismét a 3-as mélységben tartalmazza a lista. Ez a lista, amelynek elemei mind listák, a különböző szinteken összesen öt atomot tartalmaz.
Nézzünk még egy példát:
((KUTYA (VIZSLA KOPO KOMONDOR))
(MACSKA (SZIAMI ANGORA))
(BAROMFI (TYUK LIBA KACSA)))
Ezt a listát a következő ábra szemlélteti:
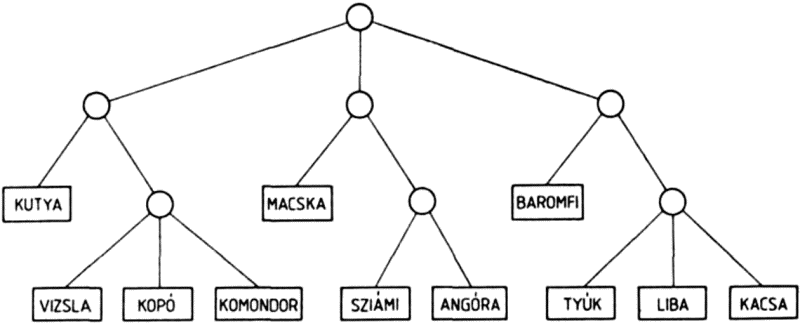
Azt, hogy milyen mélységben található a listaelem, meghatározhatjuk a listának megfelelő fa felrajzolása nélkül is, úgy, hogy megszámoljuk az adott elemtől balra lévő, még be nem zárt kezdő zárójeleket. Példánkban a KUTYA atomtól balra két kezdő zárójel található, ez az atom 2-es mélységben van. A VIZSLA, KOPO és KOMONDOR atomoktól balra három be nem zárt kezdő zárójel található, a mélység tehát 3. A MACSKA atomtól balra négy kezdő zárójel áll, de ezek közül kettő már be van zárva, ez tehát ismét 2-es mélységben van.
Amikor listákkal dolgozunk, gyakran csak a lista legfelső szintjére, a lista elemeire van szükségünk. Sok feladat azonban megkívánja, hogy a mélyebb szinteket, az allisták elemeit is vizsgáljuk. Ha egy listákra vonatkozó feladatot oldunk meg, mindig gondoljuk végig, hogy elegendő-e a legfelső szintet vizsgálnunk, vagy a mélyebb szintekkel is foglalkoznunk kell.
1.2.2. Zárójelezési hibák
A listák felírásakor könnyen elkövethetünk zárójelezési hibákat. A következő példákban néhány gyakori hibát mutatunk be:
(KUTYA (MACSKA (PAPAGAJ))
Itt az első kezdő zárójelhez nem tartozik bezáró zárójel.
((MICI) (MACKO)))
Itt viszont több a bezáró, mint a kezdő zárójel: voltaképpen egy hibátlanul felírt listát egy fölösleges bezáró zárójel követ. A következő példa
)BOLDOG (SZULETESNAPOT) FULES)
egyrészt nem kezdő zárójellel, hanem bezáró zárójellel kezdődik, másrészt pedig több bezáró zárójelet tartalmaz, mint kezdő zárójelet.
A zárójelezési hibák miatt az itt felírt három példa egyike sem lista. Foglaljuk össze a helyes zárójelezés szabályait:
Előző példáink közül a (KUTYA (MACSKA (PAPAGAJ)) és a ((MICI) (MACKO))) az első szabályt sérti meg, a )BOLDOG (SZULETESNAPOT) FULES) példa pedig az első és a második szabályt is megsérti. A harmadik szabály miatt az alábbi példa:
(PULI KUVASZ) (KOMONDOR)
nem hibásan felírt lista, hanem két lista, mégpedig egy kételemű és egy egyelemű lista.
A B. Függelékben ismertetünk néhány egyszerű módszert, amelyek megkönnyíthetik a zárójelezési hibák megkeresését.
A zárójelezési hibákat könnyebben elkerülhetjük, ha kialakítunk bizonyos szokásokat, amelyeket a listák leírásakor betartunk. A LISP nyelvben a listákat kötetlen formában írhatjuk. Minden olyan helyen, ahol szóköz vagy sorvégjel szerepelhet (két atom között, atom és zárójel között vagy két zárójel között), tetszőleges számú szóközt írhatunk, vagy új sort kezdhetünk. Tehát pl.
(A ( B (C) )( D (E F)))
vagy
(A (B
(C)) (D
( E F )))
ill.
(A (B (C)) (D (E F)))
ugyanannak a listának három különböző lehetséges felírási módja. A LISP nyelvben nincsenek kötelező szabályok, amelyek előírnák, hogy melyik formában kell felírnunk a listát, a programozási gyakorlatban azonban kialakultak és beváltak olyan szokások, amelyeknek betartásával áttekinthetővé tehetjük a lista szerkezetét.
Egy lehetséges felírási mód a következő:
Tehát pl. a fenti listát írjuk az
(A (B (C)) (D (E F)))
alakban.
Hosszabb listákat már igen nehéz áttekinteni:
((A (B C D) (E (F G) H) (I J)) K L (M ((N O) (P Q R S)) (T U V)))
A sorokat úgy tördelhetjük, hogy az azonos szintnek megfelelő kezdő zárójeleket, ill. atomokat egymás alá írjuk:
((A (B C D)
(E (F G) H)
(I J))
K L
(M ((N O)
(P Q R S))
(T U V)))
A listáknak nem ez az egyedül lehetséges felírási módja, de a LISP programozók általában hasonló szabályokat alkalmaznak. Az a fontos, hogy ha kialakítottuk a listák írásával kapcsolatos szokásainkat, akkor következetesen tartsuk be őket. Így az általunk írt LISP programok számunkra és mások számára is olvashatók, áttekinthetők lesznek. Kisebb lesz a zárójelezési hibák elkövetésének veszélye, és az esetleg elkövetett hibát is könnyebben találjuk meg.
Néhány LISP rendszer az eddig megismert elhatárolójeleken (azaz a kezdő és bezáró zárójelen, a szóköz- és a sorvégjelen) kívül megengedi elhatárolójelként az ún. nagyzárójelek, azaz a < és > karakterek használatát is. (IS-LISP-ben a ] szögletes zárójel az összes nyitott zárójelet bezárja.) Ezekkel a jelekkel bonyolultabb listaszerkezetek leírását egyszerűsíthetjük. A < kezdő nagyzárójel egyetlen közönséges kezdő zárójellel, a > nagyzárójel pedig egy vagy több közönséges bezáró zárójellel egyenértékű. A > nagyzárójel bezárja a legutoljára előfordult kezdő nagyzárójelet, és ezzel együtt minden, ez után álló, de még be nem zárt közönséges kezdő zárójelet is. Ha pedig nincsen be nem zárt kezdő nagyzárójel, akkor a bezáró nagyzárójel minden eddig leirt és még be nem zárt kezdő zárójelet bezár. Használjunk nagyzárójeleket legutóbbi példánk felírásához! Az
(A (B (C)) (D (E F)))
listát az
(A (B (C)) (D (E F>
vagy IS-LISP-ben
(A (B (C)) (D (E F]
alakban is írhatjuk.
1.3. A lista részei
A lista első eleme kitüntetett szerepet játszik, ezért külön nevet is kapott, ez a lista feje. Ha a lista fejét (első elemét) elvesszük, a megmaradó elemekből alkotott listát az eredeti lista farkának nevezzük. Az előző példáinkban szereplő listák közül a
(KUTYA MACSKA)
lista feje: KUTYA
farka: (MACSKA)
A
(KUTYA MACSKA (SZAMAR OSZVER))
lista feje: KUTYA
farka: (MACSKA (SZAMAR OSZVER))
A
(TIMES 3 5)
lista feje: TIMES
farka: (3 5)
Az
((ALMA (BARACK CSERESZNYE)) (((DINNYE) EPER)))
lista feje: (ALMA (BARACK CSERESZNYE))
farka: ((((DINNYE) EPER)))
Vegyük észre, hogy a lista feje - vagyis a lista első eleme - atom is, de mint utóbbi példánkban: lista is lehet. A lista farka azonban mindig lista, hiszen definíciónk szerint ez az a lista, amely akkor marad meg, ha az eredeti listából az első elemet elvesszük. A lista fejének és farkának fogalma között tehát ilyen értelemben "aszimmetria" áll fenn.
Egy kétatomos listának a feje egy atom, farka pedig egy egyatomos lista, ennek egyetlen eleme az eredeti lista második eleme. Pl. az első példánkban szereplő (KUTYA MACSKA) lista feje egy atom, a KUTYA atom, a farka pedig a (MACSKA) lista.
1.3.1. Az üres lista
Állapítsuk meg, hogy melyek az egyelemű (MAJOM) lista alkotórészei! Könnyen beláthatjuk, hogy a lista feje a MAJOM atom, mivel ez az első (és egyetlen) elem. De mi a listának a farka, miből áll a megmaradó elemek listája, ha az egyetlen elemet elvesszük?
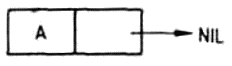
Azért, hogy a lista fejének és farkának fogalmát az egyelemű listára is értelmezhessük, be kell vezetnünk az üres lista fogalmát. így nevezzük azt a listát, amelynek egyetlen eleme sincsen. Az üres listát kétféleképpen jelölhetjük: a
()
és a
NIL
egyaránt az üres listát jelenti. Az új fogalom birtokában már értelmezhetjük a lista farkának fogalmát az egyelemű listára is: a (MAJOM) lista farka - és minden más egyelemű lista farka is - az üres lista, azaz (), másképpen NIL.
A kétféle jelölés azt sugallja, hogy az üres listának kettős természete van: az üres lista lista is, - erre utal a () jelölés -, de egyszersmind atom is, természetének ezt az oldalát a NIL jelölés tükrözi. Az üres lista az egyetlen objektum a LISP nyelvben, amely egyszerre atom is és lista is. Az üres listának tehát érdekes, minden más listáétól eltérő tulajdonságai vannak. A lista fejének és farkának a fogalmát az üres listára nem értelmezzük. A fej és farok definíciója az üres listára azért nem alkalmazható, mert az üres listának egyetlen eleme sincsen, tehát nincs első eleme sem.
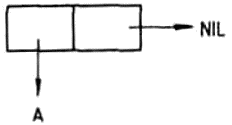
Az üres lista is lehet egy másik lista eleme. Pl. a
(NIL)
listának, amelyet a fentiek szerint a (()) alakban is írhatunk, egyetlen eleme az üres lista. Vegyük észre, hogy ez a lista nem azonos az üres listával, amelynek egyetlen eleme sincsen.
Az üres listát is ábrázolhatjuk grafikusan az 1.2.1. pontban leírt módon; olyan fával, amelynek egyetlen csúcspontja van, a gyökér, élei pedig nincsenek. A
(NIL NIL)
vagy más alakban felírva (() ()) listának két eleme van, mindkét eleme az üres lista.
1.4. Szimbolikus kifejezések, az értelmezőprogram
Az eddigiekben megismertük az atomok fajtáit, és láttuk, hogyan épülnek fel az atomokból a listák. Az atomokat és listákat összefoglaló néven szimbolikus kifejezésnek, S-kifejezésnek vagy röviden kifejezésnek nevezzük. Az alábbiak tehát S-kifejezések:
T
MACSKA
27
(KUTYA MACSKA)
(KUTYA (MACSKA (BARATSAG)))
(CATCH (22))
(1 3 5 7)
(PLUS 10 20)
A LISP nyelvben mind a programok, mind pedig az adatok, amelyeken a programok dolgoznak, S-kifejezésekből állnak.
Egy LISP program S-kifejezések egymásutánja. A program végrehajtása azt jelenti, hogy ezeket a kifejezéseket egy számítógép rendre kiértékeli.
A kiértékelés lényegét úgy érzékeltethetjük, ha bemutatjuk, hogy a programozó hogyan folytat párbeszédet a LISP rendszerrel a számítógép terminálja előtt ülve. A párbeszéd úgy zajlik le, hogy a programozó egymás után beírja a LISP programot alkotó S-kifejezéseket a terminál billentyűzetén, és ezeket a számítógép tárában lévő értelmezőprogram - más néven interpreter - rendre feldolgozza. Az értelmezőprogramot röviden értelmezőnek is nevezzük.
Az értelmezőprogram a következőképpen dolgozik: beolvassa a programozó által beírt S-kifejezést, és ezt kiértékeli, azaz meghatározza a kifejezés értékét, amely egy új S-kifejezés. A következő lépésben az értelmezőprogram ezt az értéket kiírja a terminál képernyőjére.
Egy kifejezés feldolgozását tehát az értelmezőprogram három lépésben végzi el:
Egy kifejezés kiértékelése után az értelmező arra vár, hogy a programozó egy új kifejezést írjon be. Az új kifejezést is ebben a három lépésben dolgozza fel. Az értelmezőprogram tehát minden egyes begépelt S-kifejezésre ugyanazt a munkafolyamatot ismétli.
Erről az olvasás-kiértékelés-kiírás körforgásról a 11.1. szakaszban még részletesen szó lesz. A 11.2. szakaszban pedig szólunk a fordítóprogramról is, amely abban különbözik az értelmezőprogramtól, hogy nem mondatonként fordít, mint a tolmács, hanem könyvenként, mint a műfordító.
Nézzük meg részletesebben ennek a körforgásnak a kiértékelési lépését! Hogyan határozza meg egy S-kifejezés értékét az értelmező? Egy S-kifejezés atom vagy lista lehet; először azzal foglalkozunk, hogyan határozza meg az értelmezőprogram egy atom értékét.
Az atomok között különleges atomnak nevezzük a számokat, valamint a T és a NIL szimbólumokat. Ezeket az atomokat azért nevezzük különlegesnek, mert mindig van értékük, ez maga az illető atom. Tehát pl. az 5 atom értéke 5, a -7 atom értéke -7, a NIL atom értéke pedig NIL. A különleges atomok értékét a programozó nem is változtathatja meg, ezek a LISP konstansai.
Azoknak a szimbolikus atomoknak, amelyek nem különleges szimbólumok, a programozó adhat értéket, azaz hozzájuk rendelhet értékként egy S-kifejezést. Hogy ezt hogyan teheti meg, azt a 2.1. szakaszban mondjuk el. Egy szimbolikus atom értéke S-kifejezés, azaz atom vagy lista lehet. A T és a NIL különleges szimbólumoktól különböző szimbolikus atomokat változóknak is nevezzük, mivel a hozzájuk rendelt érték többször is változhat a program végrehajtása során.
A következőkben az ember és a gép közötti párbeszéddel foglalkozunk. A nyomtatásban először mindig a programozó által beírt S-kifejezést adjuk meg. Az ez után következő sorban, ill. sorokban az értelmezőprogram válaszát, azaz a kifejezés értékét, amely szintén S-kifejezés. A programozó által beírt kifejezés előtt mindig egy különleges karakter, pl. a csillag karakter (*) áll azért, hogy az értelmezőprogram válaszától megkülönböztessük. Jegyezzük meg jól, hogy ez a karakter nem tartozik a kiértékelendő S-kifejezéshez.
A párbeszéd általában a terminál képernyőjén is hasonló formában jelenik meg. Az értelmezőprogram minden S-kifejezés beolvasása előtt egy különleges jelet ír ki a képernyőre, a felszólítójelet (más néven promptjelet). Ezzel jelzi a programozónak, hogy a következő kifejezés beolvasására vár. A felszólítójel egyes LISP rendszerekben egy karaktersorozat, más rendszerekben egyetlen karakter.
A könyvünkben szereplő összes felszólítójellel kezdődő példát magunk is kipróbálhatjuk, ha számítógépünkön van LISP értelmező. Mivel azonban az egyes LISP változatok kisebb-nagyobb mértékben eltérnek egymástól, előfordulhat, hogy egyes példákat a számunkra hozzáférhető rendszerben csak változtatás után hajthatunk végre.
Nézzük a párbeszéd legegyszerűbb esetét! Írjunk be olyan S-kifejezést, amely egyetlen különleges atomból áll! Válaszul az értelmező kiírja a kifejezés értékét:
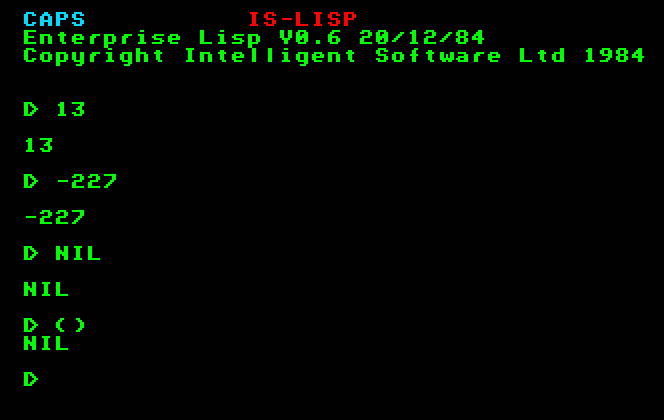
Megjegyezzük, hogy a legtöbb LISP értelmezőprogram az üres listát mindig NIL alakban írja ki, akkor is, ha a programozó lista alakjában írta le.
Ha a beírt S-kifejezés szimbólum, de nem különleges szimbólum, akkor két eset lehetséges: vagy van a beírt atomhoz hozzárendelve érték, vagy nincsen. Ha az atomnak van értéke, akkor az értelmező ezt írja ki. Legyen pl. a NEV atomhoz rendelt érték a PISTA atom, az ELETKOR atomhoz rendelt érték a 7 szám, és a GYEREKEK atomhoz rendelt érték a (PISTA JANCSI JOSKA) lista. Ekkor a párbeszéd a következő lehet:
* NEV
PISTA* ELETKOR
7* GYEREKEK
(PISTA JANCSI JOOSKA)
Ha azonban a felszólításra beírt S-kifejezés olyan atom, amelyhez nincs érék hozzárendelve, akkor az értelmezőprogram a kifejezés értékét nem tudja meghatározni, ilyenkor hibajelzést ad. Ha pl. az ELETKOR szimbólum helyett tévedésből az ELETKR szimbólumot írjuk be - amelyhez nincs hozzárendelve érték -, akkor hibajelzést kapunk.
A hibajelzés azt jelzi, hogy az ELETKOR szimbólumhoz nincs érték rendelve, az ELETKOR változónak nincs értéke.
A hibajelzés formája, a hibaüzenet szövege a különböző LISP rendszerekben más-más lehet.
Az olvasás - kiértékelés - kiírás körforgás leírása során mindvégig azt mondottuk, hogy a programozó a terminálon írja be a kiértékelendő kifejezést, és az értelmezőprogram a kifejezés értékét azonnal kiírja a képernyőre. A legtöbb LISP értelmezőprogram ilyen párbeszédes vagy más szóval interaktív üzemmódban működik. Egyes régebbi értelmezőprogramok azonban nem így működnek, hanem batch vagy más szóval kötegelt üzemmódban. Ilyenkor a programozónak előre össze kell állítania a teljes programot, a kiértékelendő kifejezések sorozatát, és lyukkártyáról, mágnesszalagról vagy más adathordozóról beolvastatnia az értelmező számára. A kiértékelés eredményeként kapott S-kifejezések kinyomtatott értéke pedig a sornyomtatón jelenik meg, esetleg csak hosszabb várakozás után. Mi a továbbiakban mindig úgy tekintjük a kiértékelést, mint a programozó és az értelmezőprogram párbeszédét.
A programozó a LISP program szövegében megjegyzéseket, kommentárokat is elhelyezhet. Számos LISP változatban ez a pontosvessző (;) vagy százalkékjel (%) használatával lehetséges. IS-LISP-ben a COMMENT függvény szolgál erre. Az értelmezőprogram a pontosvessző / százalékjel után a sor végéig következő szöveget figyelmen kívül hagyja, tehát a pontosvessző után megjegyzéseket írhatunk. Természetesen a megjegyzéseknek elsősorban akkor van jelentőségük, ha a program szövegét megőrizzük valamilyen adathordozón. Az a szerepük, hogy szövegesen is feltüntessék a program, az egyes programrészek feladatát, emlékeztessék a programozót, ill. a program felhasználóját a változók tartalmára, a program szerkezetére, az egyes programrészek funkciójára és a választott megoldások okára. Ha megfelelő megjegyzésekkel látjuk el a programot, az áttekinthetőbbé válik, később könnyebb lesz módosítani, továbbfejleszteni. Ezt tettük mi is könyvünk példáival, hogy segítsük a megértést.
1.5. A függvények és a prefixjelölés
Ha egy S-kifejezést azért írunk fel, hogy az értelmező kiértékelje, akkor a kifejezést formának is nevezzük. Az előző szakaszban láttuk, hogyan értékel ki az értelmezőprogram egy formát, ha az atom. Ebben a szakaszban azt mutatjuk meg, hogyan értékel ki az értelmező egy formát, ha az lista.
Ha a beírt forma lista, akkor az értelmezőprogram ennek az első elemét, azaz a lista fejét egy függvény nevének tekinti, a lista további elemeit pedig - ha vannak - a függvény argumentumainak. A függvénynév, azaz a kiértékelendő forma első eleme csak szimbólum lehet, a további elemek - az argumentumok - pedig S-kifejezések. Ez alól a szabály alól csak néhány kivétel van, ezekkel a könyv későbbi fejezeteiben foglalkozunk. (A forma első eleme szimbólumon kívül lehet még az 5. fejezetben tárgyalt lambda- és nlambda-kifejezés, ill. a 8. fejezetben leírt funarg-kifejezés. Ezekben az esetekben a forma első elemeként szereplő (lambda-, nlambda- vagy funarg-) kifejezés határozza meg értelmezőprogram számára, hogy milyen függvényt kell alkalmaznia.) Az olyan S-kifejezéseket, amelyeknek első eleme egy függvény neve, további elemei pedig a függvény argumentumai, függvénykifejezésnek nevezzük.
A forma kiértékelésekor az értelmezőprogram a függvényt a legtöbb függvény esetében az argumentumok értékére alkalmazza. Először tehát kiértékeli az argumentumként megadott S-kifejezéseket, majd az argumentumok értékére alkalmazza a függvényt. A forma értéke, azaz a kiértékelés eredménye a függvénynek az argumentumok értékén felvett értéke lesz.
Egy LISP program S-kifejezések egymásutánjából áll. Az S-kifejezések kiértékelése azt jelenti, hogy egy függvényt alkalmazunk az argumentumaira. Ezért nevezzük a LISP nyelvet applikatív, más szóval funkcionális nyelvnek. A legtöbb közismert programozási nyelven (FORTRAN, COBOL, PL/I, Pascal, stb.) írt programok - végrehajtható vagy nem végrehajtható - utasításokból állnak. Ezeket a nyelveket imperatív nyelveknek nevezzük. Másképpen Neumann-elvű nyelveknek is nevezzük őket, mivel alapelveiket Neumann János, a világhírű magyar születésű matematikus fogalmazta meg.
1.5.1. A beépített függvények
A LISP nyelvben beépített függvényeknek nevezzük azokat a függvényeket, amelyek a LISP rendszerhez tartoznak, ezeket minden további nélkül használhatjuk. A programozó maga is definiálhat függvényeket, ennek módját a 3.1. szakaszban mondjuk el.
A beépített függvények közül összeadásra a PLUS függvény, szorzásra a TIMES függvény szolgál. Nézzük meg, hogyan értékeli ki az értelmezőprogram a
(TIMES 3 4)
S-kifejezést! Először az argumentumokat értékeli ki; mivel a két argumentum a 3 és a 4 numerikus atom, mindkét argumentumnak az értéke önmaga. Ezután az értelmezőprogram a TIMES függvényt az argumentumok értékére, azaz a 3 és 4 számokra alkalmazza. A függvény alkalmazása a két argumentum értékének összeszorzását jelenti: a függvény értéke a két argumentum értékének szorzata lesz, azaz a 12 numerikus atom. Hasonlóképpen a
(PLUS 5 6)
S-kifejezés értéke a két argumentum értékének összege, azaz a 11 numerikus atom.
Vegyük észre, hogy az értelmezőprogram számára más feladatot jelent egy atom kiértékelése, mint egy listáé. Az atomhoz hozzárendelt értéket az értelmező tárolja, és az atom kiértékelésekor megkeresi. A lista értékét azonban az értelmezőprogram úgy állítja elő a kiértékeléskor, hogy a függvényt alkalmazza argumentumaira.
Az olyan függvénykifejezést, amelyben az argumentumok valamelyike maga is függvénykifejezés, összetett kifejezésnek nevezzük. Az értelmezőprogram az összetett kifejezések kiértékelésekor is először az argumentumokat értékeli ki, majd a kapott értékekre alkalmazza a függvényt. A
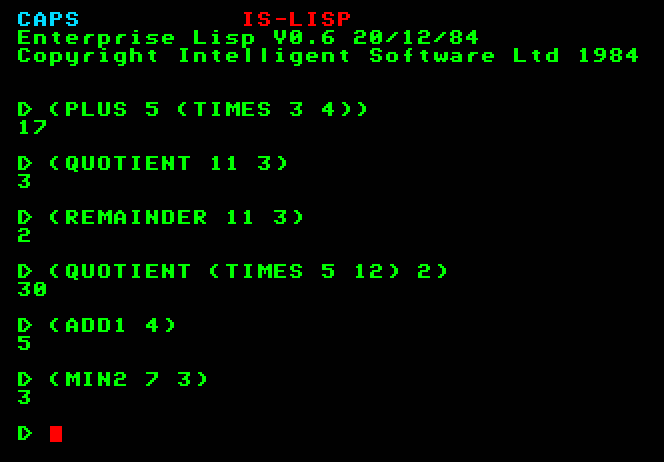
(PLUS 5 (TIMES 3 4))
S-kifejezés kiértékelésekor először az 5 és a (TIMES 3 4) formák értékelődnek ki: az elsőnek az értéke 5, a másodiké 12. Ezekre az értékekre alkalmazza az értelmezőprogram a PLUS függvényt. A kifejezés értéke tehát 17
Példáinkban a TIMES és a PLUS függvényeket mindig két argumentumra alkalmaztuk. Ezeknek a függvényeknek azonban nemcsak két, hanem több argumentuma is lehet. Az 5, -6 és 7 számok szorzatát meghatározhatjuk a következőképpen is:
(TIMES 5 -6 7)
A függvény értéke a három argumentum értékének szorzata (-210). Hasonlóképpen a PLUS függvényt is alkalmazhatjuk tetszőleges számú argumentumra:
(PLUS (TIMES 2 5) 5 7 (PLUS 2 4))
(PLUS 1 2 3 4 5 6 7 8 9 10)
A TIMES, ill. a PLUS függvénynek egyetlen argumentuma is lehet (legalább egy argumentumot azonban mindig meg kell adnunk), ekkor a kifejezés értéke az egyetlen argumentum értéke lesz.
Azokat a függvényeket, amelyeket tetszőleges számú argumentumra lehet alkalmazni, akárhány-argumentumú függvényeknek nevezzük. A TIMES és a PLUS tehát akárhány-argumentumú függvények.
A TIMES, és a PLUS függvénynek is van olyan változata, aminek csak két argumentuma lehet: a TIMES2 és a PLUS2. Ezek gyorsabban végzik el kijelölt műveletet.
További fontos beépített függvények a DIFFERENCE és a QUOTIENT. A DIFFERENCE függvénynek két argumentuma van, a függvény értéke a két argumentum értékének különbsége. A QUOTIENT függvénynek ugyancsak két argumentuma van, értéke a két argumentum értékének hányadosa. A QUOTIENT és a DIFFERENCE tehát kétargumentumú függvények. Pl.
(DIFFERENCE 15 7)
(QUOTIENT 49 7)
Azokban a LISP rendszerekben, amelyek csak az egész számokat ismerik, a QUOTIENT függvény értéke mindig egész szám. Pl. (QUOTIENT 9 3) és (QUOTIENT 11 3) függvények értéke egyaránt 3.
A QUOTIENT tehát az osztás maradékát eldobja; a hányadost nem kerekíti a szokásos értelemben, hanem csonkítja. A QUOTIENT függvény értéke egész szám, amelynek abszolút értéke megegyezik a valódi hányados abszolút értékének az egész részével, előjele pedig a valódi hányados előjelével.
Egy valós szám egész részének azt a legnagyobb egész számot nevezzük, amely a számnál nem nagyobb. Az x szám egész részének jelölésére az entier(z) jelölést szokás használni. Ha tehát a QUOTIENT függvényt az m és n egész számokra alkalmazzuk, a függvény értéke
sign(m/n) * entier(|m/n|)
lesz, ahol sign(x) az előjelfüggvény:
A legtöbb LISP rendszerben megtalálható a REMAINDER függvény, amely az osztás maradékát állítja elő. Ha m és n egész számok, és q az m/n osztásnak a QUOTIENT függvény által előállított eredménye, akkor az osztás r maradékát az
r = m - n*q
képlet határozza meg.
IS-LISP-ben a DIVIDE a hányados és a maradékot is megadja:
(DIVIDE 6 4)
Az eredmény (hányados . maradék) párból álló lista.
Az ADD1 és SUB1 függvénynek csak egy argumentuma van: az ADD1 az argumentum értékéhez 1-et hozzáad, a SUB1 pedig 1-et levon belőle:
(ADD1 5)
(SUB1 25)
(ADD1 (ADD1 (ADD1 4)))
Ugyancsak egyetlen argumentuma van a MINUS függvénynek: a függvény értéke az argumentum értékének (-1)-szerese. Pl.:
(MINUS 5)
(MINUS -7)
Egyargumentumú az ABS függvény is, amely az argumentum abszolút értékét állítja elő. Pl.:
(ABS 5)
(ABS -5)
A hatványozást végző EXPT függvénynek két argumentuma van (IS-LISP-ben nincs implementálva). Az első argumentum értéke az alap, a másodiké pedig a hatványkitevő, pl.:
(EXPT 2 10)
(EXPT (PLUS 3 2) 3)
A MIN és a MAX akárhány-argumentumú függvények (IS-LISP-ben nincs implementálva). A MIN függvény értéke argumentumainak értéke közül a legkisebb, a MAX függvényé pedig a legnagyobb. IS-LISP-ben ezeknek a függvényeknek csak két-agrumentumú változata van: MAX2, MIN2
(MIN2 7 3)
(MAX2 7 3)
Legyenek 5, 12 és 13 egy derékszögű háromszög oldalai, és számítsuk ki a háromszög területét! A
t = (a*m)/2
képletet alkalmazzuk, ahol t a területet, a az alapot, és m a magasságot jelöli. Így a terület
(QUOTIENT (TIMES 5 12) 2)
A továbbiakban a függvények leírásánál időnként a rövidség kedvéért az argumentum értéke helyett egyszerűen az argumentumról beszélünk: ezen azonban értelemszerűen az argumentum értékét értjük.
Ebben a szakaszban olyan beépített függvényeket ismertünk meg, amelyeknek argumentumai csak számok lehetnek, és a függvény értéke maga is szám. A LISP nyelvet azonban elsősorban nem aritmetikai feladatok megoldására dolgozták ki; ilyen célra sokkal alkalmasabb nyelvek is léteznek. A LISP nyelv igazi alkalmazási területe a szimbólumok kezelése. Később megismerjük azokat a beépített függvényeket is, amelyeket erre használhatunk.
1.5.2. A prefixjelölés
Az eddig megismert LISP függvényeken megfigyelhetjük a jelölés sajátosságait. Az algebrában az összeadás jelölésére a két összeadandó közé írunk egy jelet, azaz infixjelölést használunk, pl. 3 + 4 alakban. A LISP nyelvben ezzel szemben a kifejezéseket a prefixjelölés vagy függvényjelölés szabályai szerint írjuk, azaz mindig előre írjuk a függvény nevét (szimbólumát) és utána az argumentumait:
aritmetikai kifejezés LISP kifejezés 3 + 4
7 - 5
4*3
6/3(PLUS 3 4)
(DIFFERENCE 7 5)
(TIMES 4 3)
(QUOTIENT 6 3)
A LISP nyelv a függvényjelölés következetes alkalmazására épül.
1.6. Gyakori programozási hibák
A programozó hibákat követhet el az S-kifejezések beírásakor. Ennek rendszerint az a következménye, hogy az értelmezőprogram nem tudja kiértékelni a beírt kifejezést, és ezt egy hibaüzenettel jelzi; vagy kiértékeli ugyan a kifejezést, de az eredmény nem az lesz, amit a programozó el szeretett volna érni. Az 1.4. szakaszban már láttunk példát arra, hogy ha a kiértékelendő S-kifejezés olyan atom, amelyhez nincs érték rendelve, akkor az értelmező hibaüzenetet küld.
Milyen hibákat követhet el a programozó a kiértékelendő forma megadásakor, ha a forma egy lista?
Az értelmezőprogram a lista első elemét egy függvény neveként tekinti. Ha olyan szimbólumot adunk meg, amely nem egy függvény neve, azaz nem szerepel sem a beépített függvények, sem a programozó által definiált függvények között, akkor az értelmező hibajelzést ír ki, és a kiértékelés megszakad. Pl.:
(SZOROZD 6 8)
Hibát eredményez. A hibaüzenet szerint a SZOROZD definiálatlan függvény, az értelmezőprogram ilyen nevű függvényt nem ismer.
Az eddig megismert beépített függvények argumentumai csak számok lehetnek; ha ezeket olyan argumentumra alkalmazzuk, amelynek értéke nem szám, ugyancsak hibajelzést kapunk. Legyen pl. az ALMA atom értéke 6, a BARACK atom értéke pedig a SARGA szimbólum. Ekkor
(TIMES ALMA BARACK)
esetében a függvény argumentuma nem megengedett S-kifejezés, esetünkben nem szám. A hibaüzenetben először a függvénynév szerepel, majd pedig a hibásan megadott argumentum értéke.
Hibajelzést kapunk akkor is, ha egy függvény argumentuma olyan atom, amelynek nincs értéke. Ha elfelejtettünk értéket adni a HAT atomnak, akkor Pl.:
(TIMES 3 HAT)
Zárójelezési hibát sokféleképpen elkövethetünk. Ha túl kevés a bezáró zárójel, akkor - párbeszédes üzemmódban - az értelmezőprogram mindaddig várakozik további bemenő adatok beírására, amíg megfelelő számú bezáró zárójelet nem talál. Pl. ha a következőt írjuk be:
(TIMES (PLUS 2 3) (PLUS 4 5)
az értelmezőprogram további bemenő adatokat vár.
Úgy is elkövethetünk zárójelezési hibát, hogy az S-kifejezés belsejében hiányzik egy zárójel, vagy éppen fölösleges zárójelet írunk le. Pl.:
(TIMES 5 PLUS 2 3))
Itt az S-kifejezésben a PLUS szimbólum előtt nem írtuk ki a kezdő zárójelet, ezért az értelmező nem függvénynévként, hanem változóként értelmezi a szimbólumot. Mint változóhoz azonban nincs érték hozzárendelve, ezért kapunk hibajelzést. A helyes kifejezés ez lett volna:
(TIMES 5 (PLUS 2 3))
Azért időztünk hosszasabban ezeknél a példáknál, mert már első próbálkozásaink alkalmával előbb-utóbb találkozhatunk hibaüzenetekkel. Példáink segíthetnek a hibajelzések okának felismerésében.
2. A LISP alapvető függvényei
Az előző fejezetben megismert beépített függvények csak a LISP nyelv aritmetikai lehetőségeit mutatták be. Ebben a fejezetben először olyan függvényeket ismertetünk, amelyeknek segítségével az igaz és a hamis logikai értékeket kezelhetjük, majd pedig olyan függvényeket, amelyekkel a listákat részekre bonthatjuk, ill. alkotóelemeikből felépíthetjük.
Ezeknek a függvényeknek a bevezetése előtt azonban megmutatjuk, hogyan adhatunk értéket egy szimbólumnak.
2.1. Hogyan rendelhetünk értéket egy változóhoz?
Egy atomnak lehet értéke; a különleges atomoknak, azaz a numerikus atomoknak, a T és a NIL szimbólumoknak mindig van értéke, és ez az érték az atom maga. Ezt az értéket a programozó nem is változtathatja meg. Más szimbólumoknak a programozó adhat értéket a SETQ függvény segítségével, amelynek két argumentuma van. Az első argumentum mindig egy szimbolikus atom, a második argumentum tetszőleges S-kifejezés lehet, pl.:
(SETQ ALFA (PLUS 3 6))
A függvény második argumentuma kiértékelődik, és ez az érték lesz a függvénykifejezés értéke, tehát példánkban a 9.
A SETQ függvény két sajátosságban is különbözik az eddig megismert függvényektől: az egyik az, hogy csak a második argumentuma értékelődik ki, az első argumentuma - példánkban az ALFA atom - nem. Másrészt a kiértékelés során nemcsak az történik, hogy a (SETQ ALFA 9) S-kifejezés értékét az értelmezőprogram előállítja, hanem ezen kívül az is, hogy a SETQ függvény első argumentumához, az ALFA atomhoz hozzárendelődik a második argumentum értéke, azaz a 9 szám. Ha ezt követően az ALFA változót mint formát kell az értelmezőprogramnak kiértékelnie, a változó értékét kapjuk:
ALFA
A SETQ függvénnyel tehát egy szimbólumhoz, egy változóhoz értéket rendelhetünk. Ez az érték az a kifejezés, amelyet a SETQ második argumentumának kiértékelésekor kapunk: lehet egy atom - szám, vagy szimbólum - és lehet lista is. Néhány további példa:
(SETQ EGEREK-SZAMA 5)
(SETQ URES NIL)
(SETQ SZORZAT (TIMES 4 2))
A példákban szereplő S-kifejezések értéke rendre az 5 szám, a NIL szimbólum, azaz az üres lista, és végül a (TIMES 4 2) S-kifejezés értéke, azaz a 8 szám. Egyszersmind azonban a kiértékelés során az EGEREK-SZAMA atomhoz, az URES atomhoz és a SZORZAT atomhoz értéket rendeltünk.
Ha egy függvénykifejezés kiértékelésekor a függvényérték előállításán kívül - mintegy mellékesen - egyéb feladatok is elvégződnek, pl. a függvény valamelyik argumentumának az értéke megváltozik, akkor azt mondjuk, hogy a függvénynek mellékhatása van. Az ilyen függvényeket általában elsősorban mellékhatásuk miatt használjuk. A SETQ függvénynek az a mellékhatása, hogy az első argumentumaként megadott szimbólumhoz értéket rendel, éspedig a második argumentumként megadott S-kifejezés értékét. A függvényt azért használjuk, hogy vele egy szimbólumhoz értéket rendeljünk. Ha pusztán a második argumentum kiértékelése lenne a célunk, nem kellene a SETQ függvényt alkalmaznunk.
A korábban megismert függvényeknek nem volt mellékhatása, ezért nem változtatták meg argumentumaik értékét sem. Ha az előző értékadások érvényesek, akkor
(ADD1 EGEREK-SZAMA)
értéke 6. Az ADD1 függvény nem változtatja meg argumentumának, az EGEREK-SZÁMA szimbólumnak az értékét. Alkalmazzuk most a SETQ függvényt! Ekkor
(SETQ EGEREK-SZAMA (ADD1 EGEREK-SZAMA))
Először kiértékelődik a második argumentum. Értékét úgy kapjuk meg, hogy az EGEREK-SZÁMA atom értékéhez 1 hozzáadódik, és így az argumentum értéke 6 lesz: ezután az első argumentum, az EGEREK-SZAMA atom értéke megváltozik, új értéke a második argumentum értéke lesz. Ez lesz a függvénykifejezés értéke is.
Azokat a függvényeket, amelyeket mellékhatásuk miatt használunk, álfüggvényeknek nevezzük. Az elnevezést az indokolja, hogy mellékhatásuk miatt a matematikában szokásos függvényfogalomnak nem feleltethetők meg. Az álfüggvény formailag függvény, a kiértékelés során az értelmezőprogram az álfüggvényt argumentumaira alkalmazza, és egy függvényértéket állít elő; erre az értékre azonban többnyire nincs is szükségünk. A SETQ függvény tehát álfüggvény.
A korábban megismert függvények (ADD1, DIFFERENCE stb.) abban is különböznek a SETQ függvénytől, hogy mindegyik argumentumuk mindig kiértékelődik. Az ilyen függvényeket eval-típusú függvénynek nevezzük. (Az elnevezésben az eval az angol evaluate szó rövidítése, jelentése: "kiértékel".) A SETQ első argumentuma nem értékelődik ki, második argumentuma azonban igen. A SETQ tehát, mivel nem mindegyik argumentuma értékelődik ki, nem evaltípusú függvény.
A SETQ első argumentuma mindig csak szimbólum lehet: nem lehet lista, és nem lehet különleges atom - azaz szám, vagy a T, ill. NIL szimbólum - sem, mert az utóbbiak értékét a programozó nem változtathatja meg. Nem megengedettek tehát a következő értékadások:
(SETQ (TIMES 3 2) 6)
mert az első argumentum nem szimbólum, hanem lista;
(SETQ 5 7)
mert az első argumentum szám;
(SETQ NIL 0)
mert az első argumentum, a NIL, különleges szimbólum.
Nézzünk néhány további példát! Ha előző értékadásaink eredményeképpen az EGEREK-SZAMA atom értéke 6, a SZORZAT atom értéke pedig 8, akkor
(SETQ BAGLYOK-SZAMA EGEREK-SZAMA)
(SETQ NEGYZET (TIMES SZORZAT SZORZAT))
Első példánkban a SETQ függvény második argumentuma az EGEREK-SZAMA szimbólum, ennek értékét, a 6 értéket veszi fel a BAGLYOK-SZAMA atom is. A SZORZAT atom értéke 8, ezért a (TIMES SZORZAT SZORZAT) S-kifejezés értéke 64, ezt az értéket veszi fel a NEGYZET szimbólum is.
2.2 A QUOTE és az EVAL
A SETQ függvénnyel egy változóhoz értéket rendelhetünk. Eddigi tudásunk szerint ezt az értéket egy S-kifejezésnek - a SETQ második argumentumának - az értékeként állíthatjuk elő. Hogyan érhetnénk el azt, hogy közvetlenül megadhassuk azt az S-kifejezést - listát vagy atomot -, amelyet az első argumentumhoz értékként akarunk rendelni? Ha pl. azt akarjuk, hogy a BAGLYOK-SZAMA atom értéke a POCKOK-SZAMA szimbólum legyen, a KERT atom értéke pedig az (ALMA BARACK) lista, ezt nem érhetjük el a
(SETQ BAGLYOK-SZAMA POCKOK-SZAMA)
ill. a
(SETQ KERT (ALMA BARACK))
formák kiértékelésével: a SETQ második argumentuma ugyanis kiértékelődik - Ezeknek az értékadásoknak az esetén - mint előző példáinkban is láttuk - az értelmezőprogram a POCKOK-SZAMA atomot, ill. az (ALMA BARACK) listát megkísérli formaként kiértékelni.
Az értelmezőprogram megkísérli a második argumentumot, a POCKOK-SZAMA atomot kiértékelni. A példában a POCKOK-SZAMA szimbólumnak azonban nincs értéke, ezért hibajelzést kapunk. Ha pedig volna értéke, akkor ezt az értéket rendelné hozzá az értelmezőprogram a BAGLYOK-SZAMA változóhoz. Azt tehát jelen tudásunkkal semmiképpen sem érhetjük el, hogy a BAGLYOK-SZAMA változó értéke maga a POCKOK-SZAMA szimbólum legyen, ne pedig annak az értéke.
A KERT szimbólumhoz sem tudjuk az (ALMA BARACK) kifejezést, mint értéket a (SETQ KERT (ALMA BARACK)) kifejezés kiértékelésével hozzárendelni. Az értelmezőprogram megkísérelte kiértékelni a második argumentumot, úgy, hogy annak a fejét - azaz az ALMA atomot - függvénynévnek tekintette. Mivel azonban a LISP nyelvben nincs ALMA nevű beépített függvény, és a programozó sem definiált ilyen nevű függvényt, hibajelzést kaptunk.
Azt kellene tehát elérnünk, hogy egy kifejezést leírhassunk egy függvény argumentumaként - például a SETQ argumentumaként - úgy, hogy az argumentum ne értékelődjék ki. Olyan eszközre van szükségünk, amely megakadályozza, megtiltja a kifejezés kiértékelését. Ez az eszköz a QUOTE függvény, ennek egy argumentuma van, amely tetszőleges S-kifejezés lehet. Az argumentum nem értékelődik ki, a függvénykifejezés értéke maga az argumentum lesz, és nem annak az értéke. Pl.:
(QUOTE POCKOK-SZAMA)
(QUOTE (ALMA BARACK))
A QUOTE függvény segítségével most már elérhetjük, hogy a BAGLYOK-SZAMA atom értéke a POCKOK-SZAMA atom legyen. A SETQ függvény második argumentumaként azt a formát kell megadnunk, amelyben a POCKOK-SZAMA atomra a QUOTE függvényt alkalmazzuk:
(SETQ BAGLYOK-SZAMA (QUOTE POCKOK-SZAMA))
Hasonlóképpen
(SETQ KERT (QUOTE (ALMA BARACK)))
A BAGLYOK-SZAMA atom értéke a POCKOK-SZAMA szimbólum lett, a KERT atom értéke pedig az (ALMA BARACK) lista.
További példák:
(QUOTE (B C D))
(QUOTE (TIMES 3 2))
(SETQ A (QUOTE (B C D)))
(SETQ HAROMSZOR-KETTO (QUOTE (TIMES 3 2)))
Ezután az A atom értéke a (B C D) lista, a HAROMSZOR-KETTO atom értéke a (TIMES 3 2) lista, nem pedig annak az értéke.
Vegyük észre, hogy itt a HAROMSZOR-KETTO atomhoz a (TIMES 3 2) listát rendeltük értékként: ezt a kifejezést formaként ki is lehetne értékelni, hiszen a TIMES a LISP beépített függvénye. Itt azonban éppen az volt a célunk, hogy magát a listát rendeljük hozzá a HAROMSZOR-KETTO atomhoz, és ne az értékét. A QUOTE függvénnyel tehát megtiltottuk a kifejezés kiértékelését. Ha a QUOTE-ot nem alkalmazzuk, a kifejezés kiértékelődik. Pl.:
(SETQ MAS (TIMES 3 2))
A MAS változó értéke a (TIMES 3 2) forma értéke lett, azaz 6.
Mivel a QUOTE függvény argumentuma nem értékelődik ki, a QUOTE - a SETQ függvényhez hasonlóan - nem eval-típusú függvény.
A QUOTE függvényt igen gyakran használjuk. Mivel a kifejezéseket a QUOTE sok előfordulása áttekinthetetlenné, nehezen olvashatóvá teszi, a LISP nyelv szinte mindegyik változata megenged egy rövidebb írásmódot is. A
(QUOTE A)
helyett az
'A
jelölést is használhatjuk, azaz a QUOTE argumentuma elé egyszerűen az aposztróf jelet (') írhatjuk. írjunk le előző példáink közül néhányat ezzel a jelöléssel:
(SETQ BAGLYOK-SZAMA 'POCKOK-SZAMA)
(SETQ KERT '(ALMA BARACK))
(SETQ HAROMSZOR-KETTO '(TIMES 3 2))
Az aposztróf karakter nemcsak a QUOTE függvénynevet, hanem a (QUOTE argumentum).
S-kifejezéshez tartozó kezdő és bezáró zárójelet is helyettesíti.
Azzal, hogy az aposztróf jelölést bevezettük a QUOTE helyett, nem bővítettük a LISP nyelv lehetőségeit, a jelölés haszna csak annyi, hogy a programokat könnyebben lehet olvasni és írni.
Mivel minden különleges atom értéke önmaga, ezért előttük fölösleges a QUOTE függvényt alkalmaznunk. Pl.: (QUOTE NIL)
Az előző szakaszban megismert SETQ függvényen kívül értékadás céljára még két további függvényt is használhatunk: ezek a SET és a számos LISP változatban megtalálható - de az IS-LISP-ben nem - SETQQ.
A SET függvény abban tér el a SETQ-tól, hogy eval-típusú, mindkét argumentuma kiértékelődik. A függvény értéke a második argumentum értéke lesz, mellékhatásként pedig a második argumentum értéke az első argumentum értékéhez rendelődik hozzá. Legyen az ALFA változó értéke BETA: (SETQ ALFA 'BETA)
Ekkor
(SET ALFA 5)
és mellékhatásként az ALFA atom értékének, azaz a BETA atomnak az értéke lesz 5.
A SET első argumentuma tehát olyan S-kifejezés lehet, amelynek az értéke szimbolikus atom; nem lehet azonban különleges atom.
A SETQQ függvény egyik argumentuma sem értékelődik ki, ez tehát a SETQ függvényhez hasonlóan nem eval-típusú függvény. Mellékhatásának következtében az első argumentumhoz - amely csak szimbolikus atom lehet, de nem lehet különleges atom -, hozzárendelődik a második argumentum, amely ugyancsak nem értékelődik ki. Az alábbi értékadások hatása tehát azonos:
(SET 'EVSZAK '(TAVASZ NYAR OSZ TEL))
(SETQ EVSZAK '(TAVASZ NYAR OSZ TEL))
(SETQQ EVSZAK (TAVASZ NYAR OSZ TEL))
Mindhárom esetben az EVSZAK atom értéke a (TAVASZ NYAR OSZ TEL) lista lesz. A SET és a SETQQ függvények is álfüggvények, mivel - a SETQ függvényhez hasonlóan - mellékhatásuk van. Ezeket is elsősorban mellékhatásuk kedvéért használjuk.
Mint láttuk, a LISP nyelvben egy atom értéke lehet egy másik atom, ennek az atomnak pedig ugyancsak lehet értéke:
(SETQ POCKOK-SZAMA 5)
(SETQ BAGLYOK-SZAMA 'POCKOK-SZAMA)
POCKOK-SZAMA
A BAGLYOK-SZAMA változó értéke a POCKOK-SZAMA szimbólum, a POCKOK-SZAMA szimbólum értéke pedig 5. Nézzük meg, hogy hogyan kaphatjuk meg egy S-kifejezés értékének az értékét! Erre az EVAL függvény szolgál, amelynek egy argumentuma van, ez tetszőleges S-kifejezés lehet. Az argumentum kiértékelődik, értéke ismét egy S-kifejezés. Az EVAL függvény ezt az értéket, azaz argumentumának értékét kiértékeli. Példánkban tehát a BAGLYOK-SZAMA atom értékének, a POCKOK-SZAMA változónak az értékét úgy kaphatjuk meg, hogy az EVAL függvényt alkalmazzuk a BAGLYOK-SZAMA atomra:
(EVAL BAGLYOK-SZAMA)
Az EVAL függvény argumentuma, a BAGLYOK-SZAMA atom kiértékelődik, értéke a POCKOK-SZAMA atom. Az EVAL függvény ezt az értéket, a POCKOK-SZAMA atomot értékeli ki, ennek értéke 5. Ez lesz a függvénykifejezés értéke.
Az EVAL tehát a kiértékelésnek egy újabb szintjét vezeti be:
* (SETQ A 'B)
B* (SETQ B 'C)
C* (SETQ C '(TIMES 5 2))
(TIMES 5 2)* A
B* B
C* C
(TIMES 5 2)
Ha most az EVAL függvényt alkalmazzuk, akkor
* (EVAL A)
C* (EVAL B)
(TIMES 5 2)* (EVAL C)
10
Az (EVAL A) S-kifejezés értéke az A értékének, a B szimbólumnak az értéke, azaz C. Hasonlóképpen (EVAL B) értéke a B szimbólum értékének, a C atomnak az értéke, azaz a (TIMES 5 2) lista. Az (EVAL C) kifejezés értéke pedig a C értékének, a (TIMES 5 2) kifejezésnek az értéke, vagyis 10. Az EVAL ismételt alkalmazásával mindig egy-egy szinttel tovább jutunk a kiértékelésben. Egy szimbólum értékének az értékét szemléletesen úgy képzelhetjük el, mint a hagyma héjait: az EVAL ismételt alkalmazása mindig "lehámoz" egy-egy újabb héjat, egy réteget a hagymáról.
Láthatjuk, hogy a LISP nyelv abban különbözik a legtöbb programozási nyelvtől, hogy az utóbbiakban a program és az adatok általában jól láthatóan elkülönülnek, leírásuk formája alapján is megkülönböztethetők. A LISP nyelvben nincs ilyen választófej, itt a program és az adat egyaránt S-kifejezésekből áll. Ugyanaz a kifejezés egyszer adat, másszor pedig egy program része lehet: akkor adat, ha nem értékelődik ki, mert pl. a QUOTE-nak (vagy más nem eval-típusú függvénynek) az argumentuma; akkor pedig program része, ha kiértékelődik, mint egy eval-típusú függvény argumentuma vagy pedig mint egy közvetlenül az értelmezőprogram által beolvasott, kiértékelendő forma. A LISP nyelvben tehát a kiértékelés során, dinamikusan határozódik meg az, hogy egy S-kifejezést programként ki kell-e értékelni, vagy pedig adatként kell kezelni. Az értelmezőprogram számára a QUOTE függvény választja el a programot az adatoktól.
2.3. A predikátumok
Azokat a függvényeket, amelyeknek értéke csak az igaz és a hamis logikai értékek egyike lehet, a matematikai logikában használatos elnevezéssel predikátumnak nevezzük.
Az igaz érték jelölésére a T, a hamis érték jelölésére pedig a NIL különleges atomot használjuk (a T atom neve az angol true "igaz" rövidítése).
A predikátumok egyik fontos csoportját azok a függvények alkotják, amelyeknek az argumentumai számok lehetnek. Ebbe a csoportba tartozik a GREATERP függvény, amelynek két argumentuma lehet: mindkét argumentum értéke csak szám lehet. A függvény a T (igaz) értéket veszi fel, ha az első argumentum értéke nagyobb, mint a második argumentumé, és a NIL (hamis) értéket veszi fel, ha az első argumentum értéke kisebb, mint a második argumentumé vagy egyenlő vele. Pl.:
* (GREATERP 5 2)
T* (GREATERP 2 5)
NIL* (GREATERP 5 5)
NIL
Legyen a HAT atom értéke 6, és a NULLA atom értéke 0:
* (SETQ HAT 6)
6* (SETQ NULLA 0)
0* (GREATERP HAT NULLA)
T* (GREATERP HAT HAT)
NIL
Hasonló predikátum a LESSP függvény, amelynek ugyancsak két argumentuma van. A függvény értéke T, ha első argumentumának értéke kisebb, mint a második argumentum értéke, és NIL egyébként:
* (LESSP 2 5)
T
* (LESSP 5 2)
NIL
A LESSP és GREATERP függvények nevén megfigyelhetjük a LISP nyelv egyik konvencióját: a legtöbb beépített predikátum neve P betűre végződik, ez a Predikátum szó rövidítése. Sajnos, ezt a konvenciót nem alkalmazták egészen következetesen. Később meg fogunk ismerni olyan beépített predikátumokat, amelyeknek a neve nem P betűre végződik, és néhány olyan beépített függvényt is, amelynek a neve P betűre végződik, mégsem predikátum. A most bemutatandó predikátumok neve azonban követi a konvenciót.
A ZEROP függvény akkor veszi fel a T értéket, ha egyetlen argumentumának értéke 0, minden más esetben értéke NIL.
Ellenőrizzük, hogy az 5, 12 és 13 számok lehetnek-e egy derékszögű háromszög oldalhosszúságai! Pitagorasz tétele szerint, ha a és b egy derékszögű háromszög befogói, c pedig az átfogója, akkor teljesül az
a^2 + b^2 = c^2
egyenlőség. Ellenőrizzük:
* (SETQ A 5)
5* (SETQ B 12)
12* (SETQ C 13)
13* (ZEROP (DIFFERENCE (EXPT C 2)(PLUS (EXPT A 2) (EXPT B 2))))
T
Tehát valóban teljesül a c^2 - (a^2 + b^2) = 0 egyenlőség.
A ONEP függvény értéke akkor T, ha egyetlen argumentumának értéke 1, minden más esetben pedig NIL. Pl.:
(ONEP (DIFFERENCE 8 7))
A MINUSP függvény értéke T, ha argumentumának értéke negatív szám, és NIL, ha argumentumának értéke pozitív szám vagy 0.
Az EVENP függvény akkor veszi fel a T értéket, ha argumentumának értéke páros szám. Az IS-LISP-ben nincs implementálva. Pl.:
(EVENP (PLUS 3 (TIMES 4 6)))
Az ODDP függvény értéke pedig akkor T, ha argumentumának értéke páratlan szám. Az IS-LISP-ben nincs implementálva.
2.3.1. A logikai függvények
Az eddig megismert predikátumok argumentumai csak olyan S-kifejezések lehetnek, amelyeknek az értéke szám. Ahhoz, hogy predikátumokból összetett kifejezéseket építhessünk fel, olyan függvényekre is szükségünk van, amelyeknek argumentumai az igaz vagy hamis logikai értékeket vehetik fel. Ezeket a függvényeket logikai függvényeknek nevezzük.
A matematikai logikából ismert legfontosabb logikai függvények a konjunkció, a diszjunkció és a negáció.
p q p and q igaz
hamis
igaz
hamisigaz
igaz
hamis
hamisigaz
hamis
hamis
hamis
p q p or q igaz
hamis
igaz
hamisigaz
igaz
hamis
hamisigaz
igaz
igaz
hamis
p not p igaz
hamishamis
igaz
Minden logikai függvény felépíthető ebből a három függvényből.
A konjunkciónak a LISP nyelvben az AND függvény felel meg. A matematikai logikában használatos értelmezéssel szemben, ahol a konjunkciót csak két argumentum esetére értelmezzük, az AND függvénynek tetszőleges számú argumentuma lehet, tehát akárhány-argumentumú függvény. Az AND függvény értéke T, ha mindegyik argumentumának értéke igaz, különben NIL. Pl:
* (AND T T)
T* (AND T T NIL)
NIL
Az AND függvényt általában akkor használjuk, ha ahhoz, hogy egy állítás igaz legyen, több feltételnek kell együtt teljesülnie. Pl. az
(AND (GREATERP SZAM 0) (ODDP SZAM))
kifejezés értéke akkor T, ha a SZÁM értéke pozitív páratlan szám.
A diszjunkciónak az OR függvény felel meg, amely ugyancsak akárhány- argumentumú függvény, értéke T, ha legalább egy argumentum értéke igaz, különben NIL.
* (OR NIL T)
T* (OR NIL (AND T NIL) NIL)
NIL
Az OR függvényt használhatjuk pl. akkor, ha azt akarjuk eldönteni, hogy a SZAM értéke 0-tól különböző szám-e:
* (SETQ SZAM 5)
5* (OR (LESSP SZA 0) (GREATERP SZA 0))
T
A negáció műveletének a NOT függvény felel meg. A függvény egyargumentumú; értéke T, ha argumentumának értéke NIL és NIL, ha argumentumának értéke T.
A NOT segítségével egyszerűbben is felírhatjuk azt az S-kifejezést, amelynek értéke akkor T, ha a SZAM változó értéke nem 0:
(NOT (ZEROP SZAM))
A legtöbb LISP rendszerben általánosabban értelmezik a logikai értéket. A hamis értéknek mindig a NIL felel meg, viszont igaznak tekintenek
minden értéket, amely nem NIL. Ezekben a rendszerekben a logikai függvények argumentumaként tetszőleges S-kifejezés szerepelhet, és a függvények értéke is tetszőleges S-kifejezés lehet. A továbbiakban mi is ilyen általánosan értelmezzük a logikai függvényeket.
Ennek megfelelően tehát az AND függvény értéke NIL, ha van olyan argumentuma, amelynek értéke NIL. Ha pedig mindegyik argumentumának értéke NIL-től különböző, akkor az AND függvény értéke is egy NIL-től különböző kifejezés lesz, mégpedig - balról jobbra haladva - utolsó argumentumának az értéke:
* (AND 'TREFF 'KARO 'KOR 'PIKK)
PIKK
ami a fentiek szerint az igaz logikai értéknek felel meg. Ha azonban a kiértékelés során valamelyik argumentum értéke NIL, akkor a kifejezés értéke is NIL lesz:
* (SETQ HAMIS NIL)
NIL* (SETQ IGAZ T)
T* (AND HAMIS IGAZ)
NIL
Miért éppen az utolsó argumentum értékét kapjuk az AND kiértékelésekor, ha egyik argumentum értéke sem NIL? Ehhez tudnunk kell, hogy az értelmezőprogram a kifejezések kiértékelésekor mindig balról jobbra haladva értékeli ki az argumentumokat. A logikai függvények kiértékelésekor azonban csak addig halad a kiértékelésben, amíg az argumentumok értéke el nem dönti a kifejezés értékét. A további argumentumok nem értékelődnek ki.
Ha tehát az AND függvény értéke igaz, ami csak akkor teljesül, ha egyik argumentuma sem NIL, akkor mindegyik argumentum kiértékelődik, és a függvény értéke az utolsó argumentum értéke lesz. Ha azonban valamelyik argumentum értéke NIL, akkor ez eldönti, hogy a függvény értéke is NIL, így a további argumentumok nem értékelődnek ki.
Legyen a HAMIS változó értéke továbbra is NIL, az AZ, EN és ROZSAM változókról pedig tegyük fel, hogy nem rendeltünk hozzájuk értéket. Ekkor
(AND HAMIS AZ EN ROZSAM)
A függvény első argumentumának értéke NIL, így a második argumentum és a további argumentumok nem értékelődnek ki. A kifejezés kiértékelése során nem kapunk hibajelzést, annak ellenére, hogy további argumentumainak nincs értéke. Ha azonban megváltoztatjuk az argumentumok sorrendjét, akkor
(AND AZ EN ROZSAM HAMIS)
akkor hibát kapunk, mert az AZ változónak nincs értéke.
A logikai függvények kiértékelésére tehát különös gondot kell fordítanunk akkor, ha egy argumentum kiértékelése hibára vezethet, vagy kiértékelésének mellékhatása van. Az, hogy egy argumentum kiértékelődik-e vagy nem, függ az előző argumentumok értékétől. Előfordulhat, hogy a függvény kiértékelésekor az argumentumok valamilyen sorrendje esetén bekövetkezik a mellékhatás, vagy a hiba, ha azonban más sorrendben adjuk meg az argumentumokat, akkor nem. A következő példában az első argumentum kiértékelésének mellékhatása van:
* (AND (SETQ EVSZAK 4) (NOT 'NEGY))
NIL* (ADD1 EVSZAK)
5
Az első argumentum, a (SETQ EVSZAK 4) kifejezés kiértékelődik, és az EVSZAK változóhoz a 4 érték rendelődik. A kifejezés értéke NIL, mert második argumentumának értéke NIL. Mivel az EVSZAK változó értéket kapott, ezért az (ADD1 EVSZAK) forma kiértékelésekor hivatkozhatunk az értékére. Ha azonban megváltoztatjuk az argumentumok sorrendjét, akkor
* (AND (NOT 'NEGY) (SETQ EVSZAK 4))
NIL* (ADD1 EVSZAK)
Mivel az első argumentum értéke eldönti a kifejezés értékét, a (SETQ EVSZAK 4) kifejezés nem értékelődik ki, az EVSZAK változó nem kap értéket, és az EVSZAK értékére való hivatkozás hibát okoz.
A logikai függvények ilyen értelmezését felhasználhatjuk arra is, hogy egy S-kifejezés kiértékelése csak akkor történjék meg, ha egy másik forma értéke igaz, azaz nem NIL:
(AND (ZEROP EGEREK-SZAMA) (SETQ BAGLYOK-SZAMA 0))
A kifejezés kiértékelésekor csak akkor lesz a BAGLYOK-SZAMA változó értéke 0, ha az EGEREK-SZAMA változó értéke 0 volt.
Hasonlóképpen mivel az OR függvény értéke akkor igaz, ha bármelyik argumentuma igaz, az értelmezőprogram csak addig értékeli ki az argumentumokat, amíg az első NIL-től különböző értékű argumentumot meg nem találja (ha van ilyen); ekkor a függvény ezt az értéket veszi fel. Csak akkor értékelődik ki mindegyik argumentum, ha az utolsó argumentumot megelőző mindegyik argumentumnak az értéke NIL, ekkor az OR függvény értéke az utolsó argumentum értéke lesz.
(OR (GREATERP N 0) (ZEROP N))
Ha N értéke pozitív szám, akkor a kiértékelés az OR első argumentumával ér véget, ennek értéke T. Ha pedig N értéke 0 vagy negatív szám, akkor az OR második argumentuma ennek megfelelően a T vagy a NIL érték lesz, és ez lesz a kifejezés értéke is. Ha azonban N értéke nem szám, hibajelzést kapunk:
* (SETQ N 15)
15* (OR (GREATERP N 0) (ZEROP N))
T* (SETQ N 'SZAM)
SZAM* (OR (GREATERP N 0) (ZEROP N))
Ha kihasználjuk azt, hogy a logikai függvények kiértékelésekor minden kifejezés, amelynek értéke nem NIL, igaznak számít, akkor az AND és OR függvények segítségével olyan kifejezéseket írhatunk fel, amelyeknek értéke több feltétel teljesülésétől függ.
* (SETQ N 6)
6* (OR (AND (MINUSP N) ; Ha N negatív
(MINUS N)) ; akkor mínusz N,
N) ; egyébként N.
6* (SETQ N -5)
-5* (OR (AND (MINUSP N) ; Ha N negatív,
(MINUS N)) ; akkor mínusz N,
N) ; egyébként H.
5* (SETQ N 0)
0* (OR (AND (MINUSP N) ; Ha N negatív,
(MINUS N)) ; akkor mínusz N,
N) ; egyébként N.
0
Az (OR (AND (MINUSP N) (MINUS N)) N) kifejezés értéke, mint a példákból is látszik, az N szám abszolút értéke. Az OR első argumentuma (AND (MINUSP N) (MINUS N)), ennek a kifejezésnek az értéke akkor igaz, ha első argumentuma nem NIL, és ekkor értéke a második argumentum értéke, azaz (MINUS N), az N értékének (-1)-szerese. Ha azonban (MINUSP N) értéke NIL, akkor a kiértékelés az OR függvény második argumentumával folytatódik, és ennek az értéke, azaz N értéke lesz az egész kifejezés értéke is. A kifejezés értéke tehát valóban N abszolút értékével lesz egyenlő.
A NOT függvény argumentuma szintén tetszőleges S-kifejezés lehet. A függvény értéke csak a NIL argumentum esetén T, minden más esetben NIL.
* (NOT 'IGAZ)
NIL* (NOT (ODDP 6))
T
A LISP logikai függvényeinek ilyen értelmezése több szempontból is eltérést jelent a logikai függvények matematikában szokásos értelmezésétől. A matematikai logikában a logikai 'és' és a logikai 'vagy' függvény kétargumentumú, a LISP nyelvben az AND és OR függvény azonban akárhány- argumentumú. Lényeges különbség az is, hogy az AND és OR LISP függvények kiértékelésének eredménye függ az argumentumok megadásának sorrendjétől. így egy logikai függvény kiértékelését elvégezhetjük akkor is, ha valamelyik argumentumnak nincs is értéke, de a kiértékelés sorrendje miatt ez az argumentum nem értékelődik ki, mert a kifejezés értékét az előző argumentumok értéke már eldöntötte. Végül általánosítást jelent az, hogy a LISP-ben minden kifejezést, amelynek értéke nem NIL, "igaz"-nak tekintünk.
Az eddig megismert LISP függvényeket aszerint osztályoztuk, hogy argumentumaikat kiértékelik-e. Azokat a függvényeket, amelyek argumentumaikat kiértékelik, eval-típusúnak neveztük. Az AND és OR kiértékelése azonban sajátos módon történik, nem mindig értékelődik ki mindegyik argumentumuk, ezért az AND és az OR nem eval-típusú függvények.
2.3.2. Az elemi predikátumok
A LISP további három alapvető predikátuma az ATOM, az EQ és a NULL. Ezek a LISP nyelv elemi függvényei. Nevük az eddig megismert predikátumok nevétől eltérően nem P-re végződik, kivételt jelentenek a LISP nyelv már említett konvenciója alól.
Az ATOM függvény argumentuma tetszőleges S-kifejezés lehet: a függvény értéke T, ha az argumentum értéke atom, minden más esetben NIL. Pl:
* (ATOM 'ALFA)
T* (ATOM 23)
T
de
* (ATOM '(KUTYA MACSKA))
NIL* (SETQ ALFA '(A B C))
(A B C)* (ATOM ALFA)
NIL
Az üres lista - vagy másképpen a NIL szimbólum - is atom:
* (ATOM ())
T* (ATOM NIL)
T
Az EQ predikátumnak két argumentuma van, a predikátumot két atom azonosságának megállapítására használhatjuk. A függvény értéke T, ha mindkét argumentumának az értéke atom, és a két atom azonos. Ha mindkét argumentum értéke atom, de nem azonosak, akkor a függvény értéke NIL:
* (EQ 'ALFA 'ALFA)
T* (EQ 'ALFA 'BETA)
NIL* (EQ NIL NIL)
T
Az EQ függvény értelmezéséről a 6. fejezetben még részletesebben szólunk.
Vizsgáljuk meg, hogy a SZIN atom értéke a francia kártya színeinek egyike-e!
* (SETQ SZIN 'PIKK)
PIKK* (OR (EQ SZIN 'PIKK) (EQ SZIN 'KOR)
(EQ SZIN 'KARO) (EQ SZIN 'TREFF))
T
A NULL függvénynek egy argumentuma van. A függvény értéke T, ha argumentuma NIL, minden más esetben a függvény értéke NIL.
* (NULL NIL)
T* (NULL T)
NIL* (SETQ SZAM 5)
5* (NULL (ZEROP SZAM))
T
Természetesen azokban a rendszerekben, ahol minden kifejezés, amelynek az értéke nem NIL, igaznak minősül, a NOT függvény teljesen azonos a NULL függvénnyel.
További fontos predikátumok a LISTP, az NLISTP, az EQUAL és a NUMBERP. A LISTP predikátum azt vizsgálja, hogy argumentuma lista-e. Ennek a predikátumnak a neve már megfelel a LISP elnevezési konvencióinak, mivel P betűvel végződik.
* (LISTP '(A B))
T* (LISTP 'ALFA)
NIL
Legyen a SZINEK szimbólumnak az értéke egy lista, amely a francia kártya színeinek nevéből áll:
* (SETQ SZINEK '(PIKK KOR KARO TREFF))
(PIKK KOR KARO TREFF)* (LISTP SZINEK)
T* (LISTP 'SZINEK)
NIL* (ATOM SZINEK)
NIL* (ATOM 'SZINEK)
T
Ha a LISTP predikátumot az üres listára alkalmazzuk, a függvény értéke T, az üres lista tehát lista:
* (LISTP ())
T* (LISTP NIL)
T
Az előbb láttuk, hogy az ATOM predikátum értéke is T, ha az üres listára alkalmazzuk. Ez megfelel annak, amit az üres lista kettős természetéről mondtunk az 1.3. szakaszban.
Az NLISTP függvény (IS-LISP-ben nincs implementálva) a LISTP függvény ellentettje: akkor szolgáltatja a T értéket, ha argumentuma nem lista, és a NIL értéket adja, ha argumentuma lista:
* (NLISTP '(A B))
NIL* (NLISTP 'ALFA)
T* (NLISTP NIL)
NIL
Az NLISTP függvény nem azonos az ATOM függvénnyel, ha az ATOM függvényt alkalmazzuk a NIL argumentumra, a függvény értéke T.
Az EQ predikátumot csak atomok egyenlőségének vizsgálatára használjuk; az EQUAL predikátum pedig tetszőleges S-kifejezések egyenlőségének eldöntésére való. Ennek a függvénynek is két argumentuma van, ha mindkét argumentumának az értéke ugyanaz az S-kifejezés, akkor értéke T, ha viszont a két argumentum értéke nem egyenlő, akkor a függvény értéke NIL.
* (EQUAL 'ALFA 'ALFA)
T* (EQUAL 15 (TIMES 3 5))
T* (EQUAL 'ALFA 'BÉTA)
NIL* (EQUAL NIL NIL)
T* (EQUAL '(KUTYA MACSKA) '(KUTYA MACSKA))
T* (EQUAL '(KUTYA MACSKA) '(MEDVE FARKAS))
NIL
Az EQ és EQUAL függvény közötti különbséget akkor érthetjük meg jobban, ha megismerjük, hogyan tárolja a LISP rendszer a számítógép tárában az atomokat és listákat. (Ld. a 6.2.5. pontot.)
A NUMBERP predikátum értéke akkor T, ha egyetlen argumentuma szám:
* (NUMBERP 5)
T* (NUMBERP 'KILENC)
NIL* (NUMBERP '(1 2 3))
NIL
A NUMBERP függvény segítségével megvizsgálhatjuk, hogy megfelelő-e az argumentuma egy olyan függvénynek, amelyben az argumentum értéke csak szám lehet. A korábban szerepelt
(OR (GREATERP N 0) (ZEROP N))
kifejezést átalakíthatjuk úgy, hogy azt is megvizsgáljuk, hogy N értéke szám- e. Itt is kihasználhatjuk az AND függvénynek azt a tulajdonságát, hogy ha valamelyik argumentumának értéke NIL, további argumentumai nem értékelődnek ki:
* (SETQ N 'KILENC)
KILENC* (AND (NUMBERP N)
(OR (GREATERP N 0) (ZEROP N)))
NIL* (SETQ N (TIMES 3 3))
9* (AND (NUMBERP N)
(OR (GREATERP N 0) (ZEROP N)))
T
2.4. A listák részekre bontása és felépítése
A következőkben olyan függvényeket vezetünk be, amelyeknek argumentumai listák lehetnek. A legfontosabb ilyen függvények a CAR, a CDR és a CONS, ezek is a LISP nyelv elemi függvényei. A CAR és a CDR függvények segítségével a listákat alkotóelemeikre bonthatjuk, "szétszedhetjük", ezért ezeket szelekciós műveleteknek nevezzük; a CONS függvénnyel pedig a listákat "összerakhatjuk", ezt konstrukciós műveletnek nevezzük.
Az 1.3. szakaszban megismertük a lista fejének és farkának a fogalmát. Egy lista fejét a CAR függvény, farkát a CDR függvény segítségével állíthatjuk elő. A CAR egyargumentumú függvény, argumentuma kiértékelődik. Az argumentum értéke csak lista lehet, a CAR függvény értéke a lista feje, azaz a lista első eleme. A CDR függvény ugyancsak egyargumentumú, az argumentum értéke itt is csak lista lehet, a CDR értéke pedig a lista farka, tehát az a lista, amely az első elem, a fej elvétele után megmarad. A CAR függvény értéke tehát tetszőleges S-kifejezés - atom vagy lista - lehet, a CDR függvény értéke azonban mindig lista. A CAR és CDR elnevezések az IBM 704 típusú számítógép architektúrára vezethetők vissza: John McCarthy és munkatársai az első LISP rendszert erre a gépre dolgozták ki. A CAR a content of address portion of register ("a regiszter címrészének tartalma"), a CDR pedig a content of decrement portion of register ("a regiszter lépésszámláló részének tartalma") elnevezés rövidítése.
Írjuk fel az 1.3. szakasz példáit a CAR és a CDR függvény segítségével.
* (CAR (QUOTE (KUTYA MACSKA)))
KUTYA* (CDR (QUOTE (KUTYA MACSKA)))
(MACSKA)
A példákat természetesen leírhatjuk rövidebben is, az aposztrófjel segítségével:
* (CAR '(KUTYA MACSKA))
KUTYA* (CDR '(KUTYA MACSKA))
(MACSKA)* (CAR '(TIMES 3 5))
TIMES* (CDR '(TIMES 3 5))
(3 5)* (CAR '(KUTYA MACSKA (SZAMAR OSZVER)))
KUTYA* (CDR '(KUTYA MACSKA (SZAMAR OSZVER)))
(MACSKA (SZAMAR OSZVER))
A CDR függvény működését szemléletesen úgy írhatjuk le, hogy a függvény az argumentumként megadott lista kezdő zárójelét "átemeli" a lista első eleme fölött, és az első elem után helyezi el, elhagyva az első elemet:
(CDR '(A B C))
(B C)
Már láttuk, hogy az egyelemű lista farka az üres lista: ha a CDR függvényt egyelemű listára alkalmazzuk, az üres listát kapjuk:
* (CDR '(MAJOM))
NIL
Mivel az üres listának nincsen eleme, nincs első eleme sem, ezért a fej és a farok fogalmát az üres listára nem értelmezzük. A CAR és a CDR függvényeket sem értelmezzük az üres listára, az alábbi kifejezések kiértékelése hibához vezet:
(CAR ())
(CDR (CDR '(ALFA))
Az 1.3.1. pont néhány példája:
* (CAR ''(()))
NIL* (CDR '(()))
NIL* (CAR '(() ()))
NIL* (CDR '(() ()))
(NIL)
A CAR és a CDR függvény argumentuma csak lista lehet, atomi argumentumra a függvényeket nem alkalmazhatjuk.
A listák részeit vizsgálhatjuk az előző pontban megismert predikátumok segítségével is:
* (EQ 'KUTYA (CAR '(KUTYA MACSKA)))
T
A következő kifejezés csak akkor ad igaz értéket, ha az L értéke egyelemű lista:
(AND (LISTP L) (NOT (NULL L) (NULL (CDR L)))
Pl.:
* (SETQ L '(EGYELEMU))
(EGYELEMU)* (AND (LISTP L) (NOT (NULL L)) (NULL (CDR L)))
T* (SETQ L '(NEM LESZ JO))
(NEM LESZ JO)* (AND (LISTP L) (NOT (NULL L)) (NULL (CDR L)))
NIL
A listáknak fejre és farokra való bontása alapján a listáknak az előző fejezetben bemutatottól eltérő grafikus ábrázolását vezethetjük be. A listát ismét gráffal ábrázoljuk, éspedig irányított bináris fával. Így nevezzük azokat az irányított rendezett fákat, amelyeknek minden olyan csúcspontjából, amely nem levél, pontosan két él indul ki. Tehát minden ilyen csúcspontnak két fia van, egy bal oldali és egy jobb oldali fia. A gyökérpontból kiinduló bal oldali él végpontját feleltetjük meg a lista fejének, a jobb oldali él végpontját pedig a lista farkának. Ha a lista feje atom, akkor ez a végpont a fa egy levele. Azokból a csúcspontokból, amelyek listának felelnek meg, ismét két él indul ki, ezek az allista fejének és farkának felelnek meg. Az utolsó jobb oldali levél az üres lista, ebből nem indul ki él, mivel az üres listának nincs feje, sem farka. Rajzoljuk le ezzel az ábrázolással az 1.2.1. pontban lerajzolt listákat!
A (KUTYA MACSKA (SZAMAR OSZVER)) lista ábrázolása bináris fával:
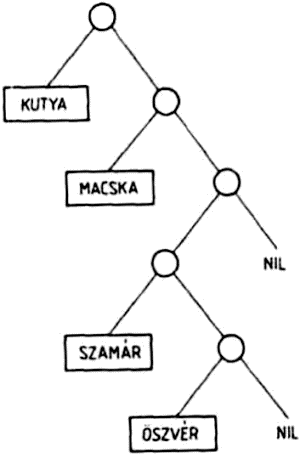
Az ((ALMA (BARACK CSERESZNYE)) (((DINNYE) EPER))) lista ábrázolása bináris fával:
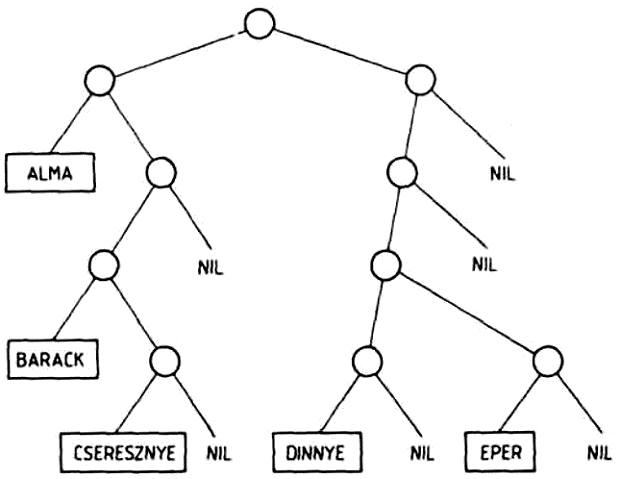
A ((KUTYA (VIZSLA KOPO KOMONDOR)) (MACSKA (SZIAMI ANGORA)) (BAROMFI (TYUK LIBA KACSA))) lista ábrázolása bináris fával:
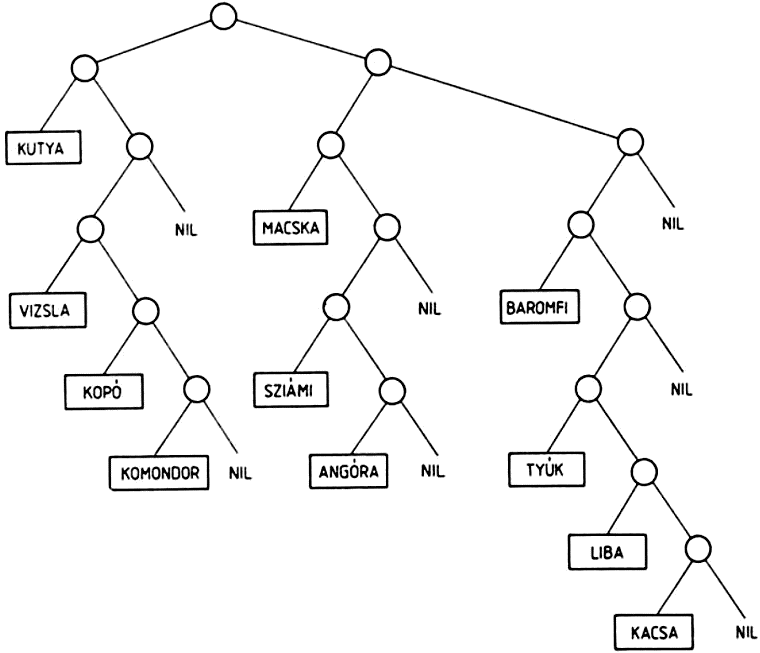
Ez az ábrázolási mód jól tükrözi a listák szerkezetét. Minden lista két részből, fejből és farokból épül fel. Az 1.2.1. pontban mutatott ábrázolási mód inkább a lista szintjeit, az egyes atomok tárolási mélységét szemlélteti.
A CONS függvény segítségével listákat állíthatunk össze. A függvénynek két argumentuma van, mindkét argumentum kiértékelődik. Az első argumentum értéke tetszőleges S-kifejezés, a második argumentum értéke lista. A CONS függvény értéke az a lista, amely úgy jön létre, hogy a függvény első argumentumát, mint első listaelemet a második argumentumként megadott lista elejére illesztjük:
* (CONS 'A '(B C))
(A B C)* (CONS 'KUTYA '(MACSKA))
(KUTYA MACSKA)* (CONS '(KUTYA '(MACSKA (SZAMAR OSZVER))))
(KUTYA MACSKA (SZAMAR OSZVER))
Ha a CONS függvény második argumentumának az értéke az üres lista, akkor a függvény értéke egyelemű lista:
* (CONS 'MAJOM ())
(MAJOM)* (CONS () ())
(NIL)
Ennek az egyelemű listának az egyetlen eleme az üres lista.
Láthatjuk, hogy a CONS abból a két alkatrészből épít fel egy listát, amelyre a CAR és CDR függvények a listát szétbontják. Ha az L szimbólum értéke lista, akkor
(CONS (CAR L) (CDR L))
éppen az L értékét adja eredményül:
* (SETQ L '(A B))
(A B)* (CAR L)
A* (CDR L)
(B)* (CONS (CAR L) (CDR L))
(A B)
vagyis eredményül megkapjuk az L változó értékét, az (A B) listát. Ha tehát a LISTA változó értéke nem atom (tehát nem is az üres lista), akkor mindig
* (EQUAL LISTA (CONS (CAR LISTA) (CDR LISTA)))
T
A CONS függvény működését - a CDR függvényéhez hasonlóan - úgy írhatjuk le szemléletesen, hogy második argumentumának, amely csak lista lehet, kezdő kerek zárójelét "átemeli" az első argumentum elé:
* (CONS 'A '(B C))
(A B C)
A CONS függvény működését a listák binárisfa-ábrázolásával is szemléltethetjük. A CONS a két argumentumát ábrázoló két bináris fát egyetlen bináris fává egyesíti úgy, hogy egy új gyökérpontot hoz létre. Ebből indul egy-egy él a két argumentumot ábrázoló bináris fához, mégpedig a bal oldali él az első, a jobb oldali él pedig a második argumentumnak megfelelő bináris fához.
Nézzük a következő példát:
* (CONS 'TIMES '(3 5))
(TIMES 3 5)
A CONS függvénnyel olyan S-kifejezést hoztunk létre, amelynek első eleme egy függvény - a TIMES beépített függvény - neve. Ezt az S-kifejezést tehát mint formát ki lehet értékelni. Alkalmazzuk a kifejezésre az EVAL függvényt:
* (EVAL (CONS 'TIMES '(3 5)))
15
A CONS függvény által előállított (TIMES 3 5) S-kifejezést az EVAL függvény kiértékelte. Ez a példa ismét azt világítja meg, hogy a LISP nyelvben "program" és "adat" között nincsenek merev válaszfalak. A CONS segítségével adatokból felépíthetünk egy S-kifejezést, amelyet az EVAL függvénnyel egy program részeként kiértékelhetünk.
2.4.1. A CAR és a CDR függvényekből összetett függvények
A CAR és a CDR függvények ismételt alkalmazásával tetszőleges részeket emelhetünk ki egy listából. A (PIKK KOR KARO TREFF) lista második elemét pl. úgy állíthatjuk elő, hogy a listára először a CDR függvényt alkalmazzuk:
* (CDR '(PIKK KOR KARO TREFF))
(KOR KARO TREFF)
Így olyan listát kapunk, amelynek az előállítandó elem az első eleme. Erre a CAR függvényt kell alkalmaznunk, hogy az eredeti lista második elemét megkapjuk:
* (CAR (CDR '(PIKK KOR KARO TREFF)))
KOR
Állítsuk elő most a ((KINT A BARANY) (BENT A FARKAS)) listában elsőként előforduló atomot! Ha a CAR függvényt alkalmazzuk, a függvény értéke a lista első eleme:
* (CAR '((KINT A BARANY) (BENT A FARKAS)))
(KINT A BARANY)
Az eredeti listában előforduló első atom ennek a listának az első eleme, tehát újból a CAR függvényt kell alkalmaznunk:
* (CAR (CAR '((KINT A BARANY) (BENT A FARKAS))))
KINT
A CAR és a CDR függvények ismételt alkalmazásával a listákból tetszőleges részeket választhatunk ki. A függvények ismételt alkalmazása azonban a sok zárójel miatt a kifejezéseket bonyolulttá teszi. A fenti feladatokat egyszerűbben megoldhatjuk, ha a CAR és CDR függvényekből összetett függvényeket használjuk. Ezeket minden LISP rendszer beépített függvényként tartalmazza.
A CAAR függvény a CAR függvény kétszer egymás utáni alkalmazásának felel meg, tehát a
(CAAR L)
kifejezés értéke ugyanaz, mint a (CAR (CAR L)) kifejezés értéke.
Hasonlóképpen a CADR függvény a CDR és a CAR függvény egymás utáni alkalmazásának felel meg - ebben a sorrendben -, tehát a
(CADR L)
kifejezés értéke ugyanaz, mint a (CAR (CDR L)) kifejezés értéke.
A CDAR függvény a CAR és a CDR függvény egymás utáni alkalmazásának felel meg - ebben a sorrendben -, a
(CDAR L)
kifejezés értéke tehát ugyanaz, mint a (CDR (CAR L)) kifejezés értéke.
Végül a CDDR függvény a CDR függvény kétszer egymás utáni alkalmazásának felel meg, a
(CDDR L)
kifejezés értéke ugyanaz, mint a (CDR (CDR L)) kifejezés értéke.
Előző példáinkat az újonnan bevezetett függvények segítségével így írhatjuk:
* (CADR '(PIKK KOR KARO TREFF))
KOR* (CAAR '((KINT A BARANY) (BENT A FARKAS)))
KINT
Alkalmazzuk a többi újonnan bevezetett függvényt is a ((KINT A BARANY) (BENT A FARKAS)) listára!
* (CADR '((KINT A BARANY) (BENT A FARKAS)))
(BENT A FARKAS)* (CDAR '((KINT A BARANY) (BENT A FARKAS)))
(A BARANY)* (CDDR '((KINT A BARANY) (BENT A FARKAS)))
NIL
A CAR és a CDR függvényekből ilyen módon sok függvényt származtathatunk. A legtöbb LISP rendszer tartalmazza a kétszeri függvényalkalmazásból adódó függvények mintájára alkotható, háromszori, ill. többszöri alkalmazásnak megfelelő függvényeket is. A
(CAAAR L)
kifejezés értéke ugyanaz, mint a (CAR (CAR (CAR L))) értéke,
(CAADR L)
értéke ugyanaz, mint a (CAR (CAR (CDR L))) értéke,
(CDDDR L)
értéke ugyanaz, mint a (CDR (CDR (CDR L))) értéke,
(CAAAAR L)
értéke ugyanaz, mint a (CAR (CAR (CAR (CAR L)))) értéke,
(CAAADR L)
értéke ugyanaz, mint a (CAR (CAR (CAR (CDR L))))
értéke és így tovább. (IS-LISP-ben összesen legfeljebb három CAR és CDR utasítás fűzhető össze.) Hasonlóképpen értelmezhetők a C...R függvények nagyobb mélységig is.
A C...R függvények elnevezése tükrözi azt a módot, ahogyan a CAR és a CDR függvényekből felépülnek. Az A és a D betűk a függvények nevében éppen a CAR és CDR függvények alkalmazásának fordított sorrendjében helyezkednek el. Ezt úgy jegyezhetjük meg, hogy az a Detű (A vagy D) áll a függvény nevében az argumentumhoz "közelebb", amelyiknek megfelelő függvény előbb alkalmazódik rá: (CADR L) az L lista CDR-jének a CAR-ja.
Nézzünk még néhány további példát! Láttuk, hogy egy lista második elemét a CADR függvény segítségével állíthatjuk elő. Egy lista harmadik elemét úgy kaphatjuk meg, hogy Kétszer alkalmazzuk a CDR függvényt, majd ezután a CAR függvényt, azaz:
* (CADDR '(PIKK KOR KARO TREFF))
KARO
Legyen
* (SETQ L '((A B) (C D) (E F)))
((A B) (C D) (E F))
Alkalmazzuk erre a listára a CADADR függvényt! A következő lépésekben haladunk:
(CDR L)
értéke ((C D) (E F)) (C D)) (CADR L) értéke (C D) (CDADR L) értéke (D) (CADADR L) értéke D
A CADADR függvény segítségével a D elemet kaptuk meg. Figyeljünk fel arra, hogy az L változó értéke eközben nem változott meg, mivel a CAR, a CDR és a C...R függvények egyikének sincs mellékhatása.
Határozzuk meg, hogy a CAR, ill. CDR függvények milyen kombinációit kell használnunk ahhoz, hogy rendre megkapjuk egy lista első, második, harmadik és további elemeit! Az első listaelemet a CAR függvény állítja elő, példáinkban pedig már láttuk, hogy egy lista második elemét a CADR függvény, harmadik elemét a CADDR függvény segítségével kaphatjuk meg. Beláthatjuk, hogy az n-edik listaelemet a CAD...DR függvény állítja elő, ahol a függvény nevében az A betűt n-1 darab D betű követi. Legyen pl.:
* (SETQ L1 '((A B) ((C D) E) F (G H I) (J)))
((A B) ((C D) E) F (G H I) (J))
A listának öt eleme van, a CAR és a CAD...DR függvények alkalmazásával rendre a következő értékeket kapjuk:
* (CAR L1)
(A B)* (CADR L1)
((C D) E)* (CADDR L1)
F* (CADDDR L1)
(G H I)* (CADDDDR L1)
(J)
Tovább nem folytathatjuk az eljárást, a CADDDDDR függvényt már nem alkalmazhatjuk a listára. (CDDDDR L1) értéke ugyanis a ((J)) egyelemű lista, ennek a listának a CDR-je pedig az üres lista, (CDDDDDR L1) értéke tehát NIL. Ennek a CAR-ja pedig nincs értelmezve.
A feladat végiggondolásával beláttuk, hogy egy lista elemeit rendre a CAR, CADR, CADDR, CAD...DR függvényekkel kaphatjuk meg: az utolsó listaelem elérése után a CAD.DR függvényeket már nem képezhetjük tovább.
A C...R függvények használatakor vigyáznunk kell arra, hogy ezeknek - ugyanúgy, mint a CAR és a CDR függvénynek - az argumentuma csak lista lehet.
Megjegyezzük, hogy a LISP rendszerek a C...R függvényeket általában csak meghatározott mélységig tartalmazzák beépített függvényként; csak azokat a függvényeket ismerik, amelyekben a C és az R között megadott számú - legfeljebb három vagy legfeljebb öt - A, ill. D betű áll (IS-LISP-ben három). Ha a programozónak ennél nagyobb mélységig összetett C...R függvényekre is szüksége van, akkor egymás után többször kell C...R függvényeket alkalmaznia, vagy neki magának kell az összetett függvényeket definiálnia. Ennek módját a 3. fejezetben ismerjük meg.
2.5. Listák létrehozása. Az APPEND és a LIST
A CONS függvényen kívül az APPEND és a LIST függvénnyel is létrehozhatunk listákat. Az APPEND függvénynek két argumentuma van, ezeknek az értéke csak lista lehet. A függvény a két lista elemeit egyetlen listába fűzi:
* (APPEND '(A B) '(C D))
(A B C D)
Itt a két argumentum értéke az (A B) és a (C D) lista. A függvény olyan listát hoz létre, amelyben az első lista elemei után következnek a második lista elemei. Egy másik példa:
* (APPEND '(MICIMACKO (MALACKA)) '(NYUSZI (BARATAI ES UZLETFELEI)))
(MICIMACKO (MALACKA) NYUSZI (BARATAI ES UZLETFELEI))
Itt a két listának allistái is vannak. További példák:
* (SETQ L1 '(ALMA BARACK))
(ALMA BARACK)* (SETQ L2 '(CSERESZNYE DINNYE))
(CSERESZNYE DINNYE)* (SETQ L3 '(EPER FUGE))
(EPER FUGE)* (APPEND L1 L2)
(ALMA BARACK CSERESZNYE DINNYE)* (APPEND (APPEND L1 L2) L3)
(ALMA BARACK CSERESZNYE DINNYE EPER FUGE)* (APPEND L1 NIL)
(ALMA BARACK)* (APPEND NIL L2)
(CSERESZNYE DINNYE)* (APPEND NIL NIL)
NIL
Példáink azt mutatják, hogy ha az APPEND egyik argumentuma az üres lista, akkor a függvény értéke a másik argumentum értéke lesz.
Az APPEND működését úgy is szemléltethetjük, hogy elhagyjuk az argumentumként megadott első lista bezáró zárójelét, és a második argumentum kezdő zárójelét:
(APPEND '(A B C) '(D E F))
A LIST függvény tetszőleges számú S-kifejezésből hoz létre új listát. A függvény akárhány-argumentumú; argumentumai kiértékelődnek, értékük tetszőleges S-kifejezés lehet. A LIST olyan listát hoz létre, amelynek elemei az argumentumok értékei:
* (LIST 'ALFA 'BETA 'GAMMA)
(ALFA BETA GAMMA)* (LIST '(A B) '(C D))
((A B) (C D))* (LIST (EXPT 1 2) (EXPT 2 2) (EXPT 3 2))
(1 4 9)
A LIST függvényt az APPEND függvénnyel összevetve tehát azt látjuk, hogy az APPEND az argumentumként megadott listák elemeiből épít fel egy listát, a LIST függvény pedig az argumentumként megadott kifejezésekből.
* (LIST '(MICIMACKO (MALACKA)) '(NYUSZI (BARATAI ES UZLETFELEI)))
((MICIMACKO (MALACKA)) (NYUSZI (BARATAI ES UZLETFELEI)))
Tegyük fel, hogy az L1, L2 és L3 listákra vonatkozó értékadások továbbra is érvényesek. Ekkor
* (LIST L1 L2 L3)
((ALMA BARACK) (CSERESZNYE DINNYE) (EPER FUGE))
Az APPEND függvény argumentumai csak listák lehetnek, a LIST függvény argumentumai azonban tetszőleges S-kifejezések is.
* (LIST '(ALFA BETA) 'GAMMA)
((ALFA BETA) GAMMA)* (LIST 1 2 3 4 5 6 7 8 9)
(1 2 3 4 5 6 7 8 9)* (LIST (CAR '(ALFA BETA)) (CAR '(GAMMA DELTA)))
(ALFA GAMMA)* (LIST L1 NIL)
((ALMA BARACK) NIL)* (LIST NIL Ll)
(NIL (ALMA BARACK))* (LIST NIL NIL)
(NIL NIL)
A LIST függvény hatását szemléletesen úgy jegyezhetjük meg, hogy argumentumait - mint listaelemeket egy kezdő és egy bezáró zárójel közé foglalja:
(LIST 'A 'B 'C)
Legyen
* (SETQ L '((KINT A BARANY) (BENT A FARKAS)))
((KINT A BARANY) (BENT A FARKAS))
és állítsuk elő a ((BENT A BARANY) (KINT A FARKAS)) listát! Ez pl. a következőképpen lehetséges:
* (LIST (CONS (CAADR L) (CDAR L)) (CONS (CAAR L) (CDADR L)))
((BENT A BARANY) (KINT A FARKAS))
A következő példák segítségével jobban megérthetjük az APPEND, a LIST, a CONS, a CAR és a CDR függvények közötti összefüggéseket. Legyen az L1 szimbólum értéke továbbra is az (ALMA BARACK) lista, az L2 szimbólumé pedig a (CSERESZNYE DINNYE) lista! Ekkor
* (CAR (APPEND Ll L2))
ALMA* (CAR Ll)
ALMA* (CDR (APPEND L1 L2))
(BARACK CSERESZNYE DINNYE)* (APPEND (CDR L1) L2)
(BARACK CSERESZNYE DINNYE)* (CAR (LIST L1 L2))
(ALMA BARACK)* (CDR (LIST L1 L2))
((CSERESZNYE DINNYE))* (LIST L2)
((CSERESZNYE DINNYE))* (CONS L2 NIL)
((CSERESZNYE DINNYE))
Általában is igazak a következő összefüggések: ha L1 és L2 értéke egy-egy lista, akkor az egy sorban levő kifejezések értékei azonosak:
| (CAR (APPEND L1 L2)) (CDR (APPEND L1 L2)) (CAR (LIST L1 L2)) (CDR (LIST L1 L2)) (CONS L NIL) |
(CAR L1) (APPEND (CDR L1) L2) L1 (LIST L2) (LIST L) |
Az ebben a fejezetben megismert függvények (CAR, CDR, CONS, APPEND, LIST) közös tulajdonsága, hogy argumentumaikat nem változtatják meg, nincs mellékhatásuk. Ha pl. az
* (APPEND L1 L2)
(ALMA BARACK CSERESZNYE DINNYE)
kiértékelés után kiértékeljük az L1, L2 változókat, azt tapasztaljuk, hogy értékük nem változott meg.
Később, a 6.3. szakaszban megismerünk olyan listaalkotó függvényeket is, amelyek befolyásolják argumentumaik értékét.
3.1. Függvények definiálása
Az előző fejezetekben megismert függvények a LISP beépített függvényei, ezek a nyelvben már definiálva vannak, tehát minden további nélkül használhatjuk őket. Arra is szükségünk van azonban, hogy mi magunk is bevezethessünk függvényeket.
Ha pl. egy feladat megoldása során többször kell számok négyzetét kiszámítanunk, használhatjuk az EXPT függvényt vagy a TIMES függvényt, azonban minden alkalommal le kell írnunk a függvény argumentumait az
(EXPT N 2)
ill. a
(TIMES N N)
alakban. Itt N az a változó, amelynek értékét négyzetre kell emelnünk. Egyszerűbben végezhetjük el a feladatot, ha egy új, egyargumentumú függvényt definiálunk, amely előállítja egy szám négyzetét. A függvény neve legyen NEGYZET, argumentuma pedig az a szám, amelynek a négyzetét ki akarjuk számítani. A NÉGYZET függvényt a DEFUN függvény segítségével definiálhatjuk:
(DEFUN NEGYZET (N) (TIMES N N))
Az értelmezőprogram ennek az S-kifejezésnek a kiértékelésekor a kiértékelés mellékhatásaként feljegyzi a függvény definícióját. Ezután a programozó ugyanúgy használhatja a NEGYZET függvényt, mint a beépített függvényeket. A kiértékelés természetesen az S-kifejezés értékét is előállítja: ez az éppen definiált függvény neve, példánkban tehát a NEGYZET függvényé:
* (NEGYZET 6)
36
Minden, ami a LISP nyelvben egyáltalán kiértékelhető - a függvénydefiníció is - S-kifejezés. A DEFUN függvény argumentumai írják le a függvény definícióját. A DEFUN akárhány-argumentumú függvény, de legalább három argumentumának kell lennie. Az argumentumok jelentése:
Esetünkben a függvény neve NEGYZET, a változók listája egyelemű, mivel a függvény egyargumentumú. A NEGYZET függvénynek N az egyetlen lambdaváltozója. A függvény törzse egyetlen S-kifejezésből, a (TIMES N N) kifejezésből áll, amely tartalmazza a függvény N lambdaváltozóját. Az elvégzendő feladatot úgy oldjuk meg, hogy az N értékét megszorozzuk önmagával.
A DEFUN függvény argumentumai nem értékelődnek ki, tehát ez nem eval-típusú függvény. A DE függvény értéke a definiált függvény neve, a DE mellékhatása pedig abban áll, hogy a definíciót az értelmezőprogram feljegyzi. A DE függvényt tehát, mint az eddig megismert más mellékhatással rendelkező függvényeket is, elsősorban nem az értékéért, hanem mellékhatása miatt alkalmazzuk.
Vizsgáljuk meg, hogyan alkalmazza az értelmezőprogram a NEGYZET függvényt egy argumentumra! Ha az értelmezőprogram a (NEGYZET 6) S-kifejezést olvassa be, amelynek első eleme a NEGYZET függvénynév, második eleme - a függvény argumentuma - pedig 6, ekkor először az argumentumként megadott S-kifejezés értékelődik ki: esetünkben ez a 6 szám, amelynek értéke önmaga. Ezt az értéket az értelmezőprogram hozzárendeli, hozzáköti a definícióban szereplő N lambdaváltozóhoz. Ezt a folyamatot lambdakötésnek nevezzük. A lambdaváltozókat ezért a függvénydefinícióra vonatkoztatva kötött változónak is nevezzük.
Az argumentum értékének a lambdaváltozóhoz való hozzárendelése csak a függvénykifejezés kiértékelésének tartamára érvényes.
Az értelmezőprogram az N változónak a lambdakötésben kapott értékével értékeli ki a függvénydefiníció törzsét alkotó S-kifejezéseket; esetünkben a törzs egyetlen kifejezés, a (TIMES N N) S-kifejezés. A (NEGYZET 6) függvénykifejezés értéke a (TIMES N N) kifejezés értéke, ahol N értéke 6.
Nézzünk más példákat is a NÉGYZET függvény alkalmazására! Az argumentum nemcsak szám lehet, hanem más S-kifejezés is, amelynek az értéke szám:
* (NEGYZET (TIMES 5 (PLUS 2 4)))
900
Először az argumentum, azaz a (TIMES 5 (PLUS 2 4)) S-kifejezés értékelődik ki, az N változó értéke ennek az értéke lesz (ehhez "kötődik"), azaz 30. Így értékelődik ki a függvény törzse, és a függvény kifejezés értéke a (TIMES N N) S-kifejezés értéke lesz, azaz 900.
Hasonlóképpen
* (NEGYZET (TIMES (DIFFERENCE 9 3) (PLUS 1 3)))
576
A definícióban nincs lényeges szerepe annak, hogy éppen az N szimbólumot használtuk lambdaváltozóként. A fentivel teljesen azonos értékű a definíció, ha lambdaváltozóként egy másik szimbólum szerepel:
(DEFUN NEGYZET (M) (TIMES M M))
Ha ezután a NEGYZET függvényt alkalmazzuk, az értelmezőprogram a függvény új definícióját használja. Esetünkben azonban az új definíció teljesen egyenértékű az előzővel.
A DEFUN segítségével a beépített függvények definícióját is megváltoztathatjuk, azokat is újradefiniálhatjuk. Ezzel a lehetőséggel nagyon óvatosan kell bánnunk, mivel egy hibás vagy át nem gondolt újradefiniálás az értelmezőprogramot is működésképtelenné teheti.
A NEGYZET függvényt másképpen is definiálhatjuk, ha az EXPT beépített függvényt használjuk:
(DEFUN NEGYZET (N) (EXPT N 2))
Az 1.5. szakaszban kiszámítottuk az első öt egész szám négyzetösszegét. A NEGYZET függvény definíciójának birtokában ezt most egyszerűbben is felírhatjuk:
* (PLUS (NEGYZET 1) (NEGYZET 2) (NEGYZET 3) (NEGYZET 4) (NEGYZET 5))
55
A NEGYZET függvény törzse egyetlen S-kifejezésből áll. Egy függvény törzse több S-kifejezésből is állhat. Az ilyen függvény kiértékelésekor a törzset alkotó kifejezések rendre kiértékelődnek, és a függvény értéke az utoljára kiértékelt S-kifejezés értéke lesz.
A függvénydefiníció általános alakját így írhatjuk fel:
(DEFUN függvénynév (változó1 változó2... változón)
S-kifejezés1
S-kifejezés2
...
S-kifejezésm)
Itt a függvénynév a definiálandó függvény nevét jelenti, ezt követi a lambdaváltozók listája: változó1, változó2, ... változón szimbólumok, n a lambdaváltozók száma. Jól jegyezzük meg, hogy a függvénynév és a lambdaváltozók egyaránt csak szimbolikus atomok lehetnek. A T és a NIL különleges atomok azonban nem szerepelhetnek sem függvénynévként, sem lambdaváltozóként. A függvény törzse egy vagy több S-kifejezésből áll, ezek tartalmazhatják a lambdaváltozókat.
Ha az így definiált függvényt argumentumokra alkalmazzuk, akkor az S-kifejezésben a függvénynevet annyi argumentumnak kell követnie, ahány lambdaváltozót a definíció tartalmaz. A
(függvénynév argumentum1 ... argumentum)
S-kifejezés kiértékelésekor az argumentumok kiértékelődnek, és az értelmezőprogram a lambdakötésben az egyes argumentumok értékét rendre hozzárendeli a megfelelő lambdaváltozóhoz, az első argumentum értékét az első változóhoz és így tovább. Ez a hozzárendelés azonban ideiglenes, csak a függvénykifejezés kiértékelésének tartamára érvényes. Ezután pedig az értelmezőprogram kiértékeli a függvény törzsét. Az utoljára kiértékelt kifejezés értéke lesz a függvény értéke.
Definiálhatunk olyan függvényt is, amelynek nincs argumentuma. Ekkor a definícióban a lambdaváltozók listája az üres lista lesz:
(DEFUN BEMUTATKOZOM () '(NEVEM REZ JEROMOS))
A függvény alkalmazásakor olyan S-kifejezést írunk le, melynek egyetlen eleme a függvénynév:
(BEMUTATKOZOM)
3.2. A kötött és a szabad változók
Az 1.5.1. pontban megismertük a REMAINDER függvényt, amely két egész szám osztásának maradékát állítja elő. Vannak olyan LISP rendszerek, amelyek ezt a függvényt nem tartalmazzák, ezért definiálnunk kell, ha szükségünk van rá.
A beépített függvények újradefiniálása veszélyes lehet. Ezért ha könyvünkben olyan függvény definícióját mutatjuk be, amelyet egyes LISP változatok beépített függvényként tartalmaznak, akkor a függvény nevéhez az UJ- előtagot illesztjük. Ezért az Olvasónak nem kell attól tartania, hogy újradefiniál egy beépített függvényt, amikor könyvünk példáit egy LISP változattal kipróbálja. Az ilyen függvények bemutatása, definiálása után azonban a könyv hátralevő részében általában az UJ- előtag nélküli változatot alkalmazzuk.
A függvényt tehát UJ-REMAINDER néven definiáljuk:
* (DEFUN UJ-REMAINDER (M N) ;M maradéka N-nel osztva
(DIFFERENCE M (TIMES N (QUOTIENT M N))))
A DEFUN függvény első argumentuma az UJ-REMAINDER, a függvény neve. A második argumentum az M és az N lambdaváltozókból álló (M N) lista, mivel a függvénynek két argumentuma van. A definíció törzse egyetlen S-kifejezés, ez leírja az M és az N változókon elvégzendő műveleteket: (DIFFERENCE M (TIMES N (QUOTIENT MN)))
Az M változó értékéből levonjuk az N értékének, valamint (QUOTIENT M N) értékének a szorzatát. A függvény értéke ennek a kifejezésnek az értéke lesz. A függvényt a következőképpen alkalmazhatjuk:
* (UJ-REMAINDER 17 3)
2* (UJ-REMAINDER -17 3)
-2* (UJ-REMAINDER (NEGYZET 5) (NEGYZET 3))
7
Kísérjük végig, hogy mi történik a függvény változóival a függvénykifejezés kiértékelésekor! Az (UJ-REMAINDER 17 3) kifejezésben a függvény argumentumai a 17 és a 3. A lambdakötés során az M lambdaváltozóhoz hozzárendelődik az első argumentum értéke, a 17, az N változóhoz pedig a második argumentum értéke, a 3. A függvény törzse, a (DIFFERENCE M (TIMES N (QUOTIENT MN))) S-kifejezés, ezekkel az értékekkel értékelődik ki. A kiértékelés eredménye az osztási maradék értéke lesz, azaz 2.
Az M és az N változóhoz tehát a függvénykifejezés kiértékelésének kezdetén a megfelelő argumentum értéke rendelődik hozzá. Mi történik a változó értékével a függvény kifejezés kiértékelése után? Már mondottuk, hogy a hozzárendelés csak a függvénykifejezés kiértékelése alatt érvényes, utána a változó elveszíti a lambdakötésben hozzárendelt értéket. Ha a függvénykifejezés kiértékelése előtt volt érték hozzárendelve, akkor visszakapja ezt az értéket; ha a változónak előzőleg sem volt értéke, akkor a kiértékelés után továbbra sem lesz.
Ha az UJ-REMAINDER függvény előző definíciója érvényben van, de az M változónak előzőleg nem volt értéke:
* (UJ-REMAINDER 17 3)
2* M
Hibajelzést kapunk, mert az (UJ-REMAINDER 17 3) kifejezés kiértékelése után az M változónak nincsen értéke.
Ha az M változónak előzőleg már volt értéke, akkor kiértékelés után visszakapja előző értékét. Tegyük fel, hogy az N változónak nincsen értéke:
* (SETQ M (PLUS 9 7))
16* (UJ-REMAINDER 38 5)
3* M
16* N
UNDEFINIED
Kezdetben az M változó értéke 16. Az (UJ-REMAINDER 38 5) S-kifejezés kiértékelésekor az M változóhoz a 38 értéket, az N változóhoz az 5 értéket rendeli az értelmezőprogram. A hozzárendelés azonban csak a függ-vénykifejezés kiértékelése alatt érvényes, ez után az M változó visszakapja előző értékét, a 16-ot, az N változónak pedig nincs értéke.
A LISP-ben tehát meg kell különböztetnünk a változók globális és lokális értékét. Egy változó globális értéket értékadásban a SETQ függvénnyel kaphat, a lambdakötésben kapott érték pedig lokális érték. Példánkban kezdetben az M változó globális értéke 16, az N változónak nincs globális értéke. Az UJ-REMAINDER függvény alkalmazásakor mindkét változó a lambdakötésben lokális értéket kap, az értelmezőprogram azonban megőrzi M globális értékét. Az M és az N változónak a lokális értéke vesz részt a függvény törzsének kiértékelésében: a kiértékelés után ez az érték elvész, és az M változó értékére való hivatkozáskor ismét annak globális értékét kapjuk. Ha azonban a változónak - mint példánkban az N-nek - nincs globális értéke, akkor nem lesz értéke a kiértékelés után sem, és az értékére való hivatkozás hibát okoz.
Nézzünk egy másik függvénydefiníciót:
* (DEFUN MELLEKHATAS (N)
(SETQ N (TIMES N 2))
(SETQ M N))
A függvény az N változóhoz a lambdakötésben kapott értékének 2-szeresét rendeli hozzá, majd az N így megváltoztatott értékét hozzárendeli az M változóhoz. Ez az érték lesz a függvény értéke is.
Az eddigi függvénydefiníciók törzse lambdaváltozókon kívül más változókat nem tartalmazott. Ennek a függvénynek a törzse azonban az N lambdaváltozón kívül az M változót is tartalmazza, amely nem szerepel a lambdaváltozók listáján, hanem szabad változó. Egy függvénydefinícióra vonatkoztatva szabad változónak nevezzük azt a változót, amely a függvény törzsében szerepel, de nem lambdaváltozó. A szabad változó nem kap értéket a lambdakötés révén.
Kövessük néhány esetben a MELLEKHATAS függvény alkalmazását! Tegyük fel, hogy az M és az N változóknak még nincs globális értéke.
* (MELLEKHATAS 23)
46* M
46* N
UNDEFINIED
A (MELLÉKHATAS 23) S-kifejezés kiértékelésekor az N változóhoz hozzárendelődik az argumentum értéke, azaz 23. A törzsben a (SETQ N (TIMES N 2)) kifejezés kiértékelésének mellékhatásaként az N változó új értéke előző értékének a 2-szerese, azaz 46 lesz. A (SETQ M N) kifejezés kiértékelése az M változóhoz is ugyanezt az értéket rendeli hozzá. Mivel a (SETQ M N) a függvény törzsében az utoljára kiértékelt S-kifejezés, ennek az értéke, azaz 46 lesz a (MELLEKHATAS 23) kifejezés értéke is.
Mivel az M szabad változó, a függvény törzsében történő értékadásokban a globális értéke változik meg, és az új értékét megőrzi a kiértékelés után is. Az N változónak azonban a SETQ hatására a lokális értéke változik meg, és a kiértékelés után a lokális érték elvész.
Mivel az N-nek nem volt globális értéke, ezért a kiértékelés után sem lesz.
* (SETQ N 9)
9* (SETQ M 15)
15* (SETQ K 23)
23
Hogyan alakul a változók értéke a (MELLEKHATAS K) S-kifejezés kiértékelésekor? Az N változóhoz ismét hozzárendelődik az argumentum értéke, ez most a K változó értéke, azaz 23. Az N értéke ezután ennek a 2-szerese, azaz 46 lesz, majd ez lesz az M változónak és a függvénykifejezésnek az értéke is:
* (MELLEKHATAS K)
46
Mi lesz a változók értéke a kiértékelés után?
* N
9* M
46* K
23
Az N változó globális értéke továbbra is 9. Az M változó értéke a függvénykifejezés kiértékelésékor kapott érték, azaz 46. A K változó értéke változatlan marad: a kiértékelésben ugyanis maga a K változó nem vett részt. Szerepe csak annyi, hogy az értéke az argumentumok kiértékelésekor hozzárendelődött az N változóhoz.
A függvények argumentumaként megadott szimbólum tehát kiértékelődik, és értéke hozzárendelődik a megfelelő lambdaváltozóhoz, magának az argumentumként megadott szimbólumnak az értéke azonban nem változik meg a függvénykifejezés kiértékelése során. Ez megfelel az ALGOL 60 nyelvben bevezetett érték szerinti hívás fogalmának.
Egy változó lehet kötött változó egy függvényben, és ugyanakkor szabad változó egy másikban:
* (DEFUN ATLAG (J K N)
(HANYADOS (PLUS J K)))
* (DEFUN HANYADOS (M)
(QUOTIENT M N))
* (ATLAG 10 30 2)
20
Az ATLAG függvény három kötött változót tartalmaz, a J-t, a K-t és az N-et. A HANYADOS függvényben csak egy kötött változó van, az M, az N változó pedig itt szabad változó. Amikor azonban az ATLAG függvényben alkalmazzuk a HANYADOS függvényt, akkor az N a kiértékelésnek egy magasabb szintjén kötött változóvá válik.
A következő példa a szabad változók kezelésének egy fontos problémáját világítja meg:
* (SETQ J 3)
* (DEFUN MELLEKHATAS2 (K L)
(QUOTIENT (PLUS K L) J))* (SETQ J 2)
2
Mi lesz a (MELLEKHATAS2 11 7) kifejezés értéke? A definíció szerint ez a K és az L változók értéke összegének és a J változó értékének a hányadosa. A K és L kötött változók értékét a lambdakötés határozza meg; a J szabad változó azonban két alkalommal is kap globális értéket. Felmerül a kérdés, hogy az értelmezőprogram a J változó melyik értékét használja: azt, amelyik a MELLEKHATAS2 függvény alkalmazásakor, vagy pedig azt, amelyik a MELLEKHATAS2 függvény definiálásakor volt J-hez rendelve? Ezt a rendkívül fontos problémát a LISP változatok többféleképpen oldják meg. A legtöbb LISP rendszer a szabad változónak azt az értékét veszi figyelembe, amelyik a függvény alkalmazásakor érvényes. Az ilyen rendszerekben a példánkban szereplő MELLEKHATAS2 függvény alkalmazásakor a J változó értéke 2 lesz, és eszerint
* (MELLEKHATAS2 11 7)
9
Ezekről a LISP rendszerekről (ilyen az IS-LISP is) azt mondjuk, hogy a szabad változók értékét dinamikusan kezelik. Más LISP értelmezőprogramok egy függvény alkalmazásakor a benne előforduló szabad változóknak azt az értékét használják, amely a függvény definiálásakor érvényes. Ezek a LISP rendszerek a szabad változók értékét lexikálisán (statikusan) kezelik. Az ilyen rendszerekben a fenti példa eredménye hat.
A szabad változók kezelésének kérdése a LISP változatok igen fontos problémája. Könyvünkben mindvégig azt feltételezzük, hogy az értelmezőprogram a szabad változók értékét dinamikusan kezeli.
Azokról a változókról, amelyekhez a SETQ függvénnyel globális értéket rendeltünk, azt is szokás mondani, hogy a program legfelső szintjén kötött változók. Egy függvénykifejezés kiértékelésekor a szereplő változók értékét az érvényben lévő változókötések határozzák meg. Ezek alkotják a kiértékelés környezetét. Egy függvény kiértékelésének kezdetekor, befejezésekor és értékadáskor a környezet megváltozik.
Ha egy függvényt alkalmazunk, felmerül az a kérdés is, hogy mi történik akkor, ha az argumentumok száma nem egyezik meg a függvény definíciójában szereplő lambdaváltozók számával. A LISP rendszerek egy része (ilyen az IS-LISP) szigorúan megköveteli, hogy az argumentumok száma a változók számával megegyezzék, és ha ez nem teljesül, akkor hibajelzést ad. A legtöbb LISP rendszer azonban megengedi, hogy az argumentumok száma több vagy kevesebb legyen a változókénál, ha több argumentumot adunk meg, akkor a fölöslegeseket figyelmen kívül hagyja az értelmezőprogram, ha viszont kevesebbet, akkor azokhoz a lambdaváltozókhoz, amelyeknek nem felel meg argumentum, az értelmezőprogram a NIL értéket rendeli. Pl.:
* (DEFUN KAPCSOL (X Y) (CONS X Y))
* (KAPCSOL 'ALMA)
(ALMA)* (KAPCSOL 'ALMA '(BARACK) '(CSERESZNYE))
(ALMA BARACK)
A KAPCSOL függvényben két lambdaváltozó szerepel, az alkalmazáskor azonban először csak egy argumentumot adunk meg, ezért az X változó a lambdakötésben az ALMA értéket, az Y változó - amelyhez nem tartozik argumentum - a NIL értéket kapja: a függvény értéke pedig (CONS 'ALMA NIL), azaz az (ALMA) lista lesz. A második alkalmazáskor három argumentumot adunk meg, az értelmezőprogram a harmadik argumentumot kiértékeli ugyan, de a függvénytörzs kiértékelésekor figyelmen kívül hagyja.
3.3. Néhány egyszerű függvény
Vezessünk be néhány további egyszerű függvényt. A 2.4. szakaszban megismert CAR, CADR, CADDR stb. függvényekkel előállíthatjuk egy lista első, második, harmadik stb. elemét. Sokan azonban szívesebben használnak olyan függvényeket, amelyeknek a neve utal arra, hogy hányadik listaelemet szolgáltatja a függvény, mivel az ilyen függvényeknek könnyebb megjegyezni a nevét. Definiáljuk ezért az ELSO, MASODIK és HARMADIK nevű függvényeket, amelyek rendre egy lista első, második, harmadik elemét szolgáltatják. Az ELSO függvény definíciója:
* (DEFUN ELSO (LIS) (CAR LIS))
* (ELSO '(A B C D))
A
A MASODIK függvényt kétféleképpen is definiálhatjuk. Hivatkozhatunk a CADR függvényre:
* (DEFUN MASODIK (LIS) (CADR LIS))
Ha azonban már definiáltuk az ELSO függvényt, akkor ezt is felhasználhatjuk:
* (DEFUN MASODIK (LIS) (ELSO (CDR LIS)))
* (MASODIK '(A B C D))
B
A MASODIK függvény két változata minden argumentumra ugyanazt az értéket állítja elő, a két definíció egyenértékű.
A HARMADIK függvényt is többféleképpen definiálhatjuk. A CADDR függvénnyel így:
* (DEFUN HARMADIK (LIS) (CADDR LIS))
Ha felhasználjuk a már definiált függvényeket, a HARMADIK függvény definícióját így is írhatjuk:
* (DEFUN HARMADIK (LIS) (MASODIK (CDR LIS)))
A 2.3. szakaszban bevezettük a konjunkció, a diszjunkció és a negáció logikai függvényeket, valamint ezek LISP-beli megfelelőit, az AND, az OR és a NOT függvényeket. A matematikai logika más függvényeit kifejezhetjük az általunk már ismert logikai függvényekkel. Az implikáció logikai függvény értéktáblázata a következő:
p q p impl q igaz
hamis
igaz
hamisigaz
igaz
hamis
hamisigaz
igaz
hamis
igaz
A formulában p-t az implikáció előtagjának, q-t az implikáció utótagjának nevezzük. Az értéktáblázatból leolvashatjuk, hogy értéke csak akkor hamis, ha a p előtag igaz, és a q utótag hamis; minden más esetben igaz. Az implikációt kifejezhetjük a negációval és a diszjunkcióval. Az implikációt tehát a negáció és a diszjunkció segítségével definiálhatjuk: az IMPL függvényt a NOT és az OR függvények segítségével írhatjuk fel:
* (DEFUN IMPL (A B) (OR (NOT A) B))
* (SETQ N 25)
25* (IMPL (GREATERP N 10) (GREATERP N 5))
T
azaz: ha N nagyobb mint 10, vagy egyenlő vele, akkor N nagyobb mint 5, vagy egyenlő vele.
Hasonlóképpen lehet az OR, az AND és a NOT függvények segítségével további logikai függvényeket is definiálni.
3.4. A feltételes kifejezések
Az 1.5. szakaszban megismertük az ABS beépített függvényt, amely argumentumának abszolút értékét állítja elő. írjuk fel az UJ-ABS függvény definícióját! Pozitív számoknak és a 0-nak az abszolút értéke magával a számmal, negatív számok abszolút értéke pedig a szám (-1)-szeresével egyenlő. Az UJ-ABS függvény definíciójának felírásához tehát vizsgálnunk kell azt, hogy az argumentum értéke pozitív szám, negatív szám vagy 0. A 2.3.1. pontban megismert logikai függvényekkel fel is írtunk egy kifejezést, amely egy szám abszolút értékét állítja elő: ezzel az UJ-ABS függvényt is definiálhatjuk:
(DEFUN UJ-ABS (N)
(OR (AND (MINUSP N) (MINUS N)) N))
Az UJ-ABS függvény egyargumentumú, ezért definíciója egy lambdaváltozót tartalmaz, az N-et. A függvény értéke argumentumának abszolút értéke:
* (UJ-ABS 6)
6* (UJ-ABS -5)
5* (UJ-ABS 0)
0
A logikai függvények segítségével előállíthatunk olyan kifejezéseket, amelyeknek értéke feltételek teljesülésétől függ. Ha azonban a kifejezés kiértékeléséhez több bonyolult feltételt kell vizsgálnunk, a logikai függvényekkel felírt kifejezés nehezen áttekinthető lesz. Ilyen feladatok megoldására feltételes kifejezéseket használhatunk.
Egy feltételes kifejezést a COND függvény segítségével írhatunk fel: a feltételes kifejezés értékét az dönti el, hogy több feltétel közül melyik teljesül. A COND függvény akárhány-argumentumú függvény, a feltételes kifejezés általános alakja a következő:
(COND arg1 arg2 ... argn)
ahol arg1, arg2, ... argn a COND argumentumai, n pedig az argumentumok száma. A COND mindegyik argumentuma kételemű lista lehet. Az első listaelem egy feltételt jelent, a második listaelem pedig egy tevékenységet, amelyet a feltétel teljesülése esetén végre kell hajtani. A feltételes kifejezés általános alakját tehát így is írhatjuk:
(COND (feltétel1 tevékenység1)
(feltétel2 tevékenység2)
...
(feltételn tevékenységn))
Az i-edik argumentum két elemét feltétei, és tevékenységi jelöli. Az első elem, feltétel, értéke igaz vagy hamis lehet. A második listaelem, tevékenység, egy S-kifejezés, amely feltétel, értékétől függően vagy kiértékelődik, vagy nem. Az argumentum tehát mindig két részből, feltételrészből és tevékenységrészből áll.
A feltételes kifejezés másképpen értékelődik ki, mint az eddig megismert S-kifejezések:
A feltételes kifejezés kiértékelése tehát addig tart, ameddig az értelmezőprogram meg nem találja az első olyan argumentumot, amelyben az első elem (a feltétel) értéke igaz. Az ehhez tartozó tevékenység lesz a feltételes kifejezés értéke.
Mi a feltételes kifejezés értéke akkor, ha a feltételek egyike sem teljesül? A kifejezés értéke ekkor NIL, ilyenkor azt mondjuk, hogy "keresztülesünk" a feltételes kifejezésen.
A feltételes kifejezés segítségével így definiálhatjuk az UJ-ABS függvényt:
(DEFUN UJ-ABS (N)
(COND ((MINUSP N) (MINUS N))
(T N)))
A függvény értékét a feltételes kifejezés kiértékelése szolgáltatja. A COND első argumentuma a ((MINUSP N) (MINUS N)) kételemű lista: ennek első eleme, azaz feltételrésze a (MINUSP N) kifejezés, amelynek értéke csak T vagy NIL lehet. Az argumentum második eleme a (MINUS N) kifejezés: ha az első elem értéke T, tehát N értéke negatív, akkor a feltételes kifejezés, és így az UJ-ABS értéke is (MINUS N) értéke lesz. Ha azonban (MINUSP N) értéke NIL, akkor a kiértékelés a COND második argumentumával folytatódik. Mivel ennek első eleme T, ami mindig igaz, a feltételes kifejezés, és az UJ-ABS függvény értéke is N értéke lesz.
Nézzünk egy példát arra az esetre, amikor egyik feltétel sem teljesül, azaz "keresztülesünk" a feltételes kifejezésen. Ha az abszolút érték kiszámítására szolgáló függvény definiálásakor megfeledkezünk arról, hogy az argumentum értéke pozitív szám vagy 0 is lehet, és csak a negatív értéket vizsgáljuk, olyan definícióhoz jutunk, amelyik az argumentumnak nem minden értékére állítja elő a kívánt értéket:
(DEFUN HIANYOS-ABS (N) ;csak az N<0 feltételt vizugáljuk
(COND ((MINUSP N) (MINUS N))))
Ez a függvény helyesen állítja elő az abszolút értéket, ha az argumentum értéke negatív szám. Ha azonban pozitív argumentumra vagy a 0 argumentumra alkalmazzuk, a feltétel nem teljesül, "keresztülesünk" a feltételes kifejezésen:
* (HIANYOS-ABS 6)
NIL
A "keresztülesés"-sel szemben úgy biztosíthatjuk magunkat, hogy a COND utolsó argumentumában feltételként mindig a T értéket adjuk meg. Ekkor, ha az előző argumentumok feltételrészei közül egyiknek az értéke sem igaz, akkor is teljesül az utolsó feltétel, és így a feltételes kifejezés értéke az utolsó argumentum második elemének értéke lesz.
A feltételes kifejezés értelmezését megjegyezhetjük úgy is, hogy értéke
ha feltétel1 akkor tevékenység1,
egyébként, ha feltétel2 akkor tevékenység2,
egyébként, ha feltételn akkor tevékenységn,
egyébként NIL.
Ha követjük azt a célszerű programozói gyakorlatot, hogy az utolsó argumentum feltételrésze mindig a T szimbólum, akkor a feltételes kifejezés általános alakja így módosul:
(COND (feltétel1 tevékenység1)
(feltétel2 tevékenység2)
...
(T tevékenységn)
A feltételes kifejezésnek ezt a formáját így értelmezhetjük: a kifejezés értéke
ha feltétel1 akkor tevékenység1,
egyébként, ha feltétel2 akkor tevékenység2,
egyébként, ha feltételn, akkor tevékenységn,
egyébként NIL.
3.4.1 Az általánosított feltételes kifejezések
A legtöbb LISP változat megengedi a feltételes kifejezés általánosított alakjának a használatát is. Az általánosított feltételes kifejezésben a COND argumentumai nemcsak kételemű listák lehetnek, hanem egyelemű vagy többelemű listák is. Az értelmezőprogram a többelemű argumentumnak az első elemét itt is feltételként értékeli ki, a további elemeket pedig tevékenységeknek tekinti. A feltétel teljesülése esetén mindegyik hozzá tartozó tevékenységet balról jobbra haladva sorban kiértékeli; az utolsó tevékenység értéke lesz a feltételes kifejezés értéke. Ha pedig a COND argumentuma egyelemű lista, az értelmezőprogram ezt feltételként értékeli ki, mégpedig olyan feltételként, amelyet nem követ tevékenység; ha a feltétel teljesül, akkor a feltétel értéke lesz a feltételes kifejezés értéke is.
Az általánosított feltételes kifejezés tehát pl. ilyen alakú lehet:
(COND (...)
(feltételi, tevékenységi1 tevékenységi2 ... tevékenységim)
...
(feltételj)
...
(feltételk tevékenységk)
...)
Itt az i-edik argumentum feltételrészét több tevékenység követi. Szavakban ezt így fogalmazhatjuk meg:
ha feltételi, akkor tevékenységi1, ... tevékenységim
vagyis ha a feltételi teljesül, akkor a tevékenységi1,..., tevékenységim rendre kiértékelődik, és a feltételes kifejezés értéke a tevékenységim lesz.
A j-edik argumentum feltételrészét nem követi tevékenység. Ezt így fogalmazhatjuk meg:
ha feltételj, akkor feltételj
vagyis ha a feltételj teljesül, akkor a feltételes kifejezés értéke is feltételj lesz. Az értelmező azonban a feltételt csak egyszer értékeli ki.
A k-adik argumentum feltételrészét egyetlen tevékenység követi, ahogy a feltételes kifejezés korábban megismert alakjában már láttuk.
A következő függvénydefinícióban példát mutatunk be általánosított feltételes kifejezésre:
(DEFUN ALTALANOSITOTT (N)
(COND ((GREATERP N 0) (SETQ K 0) (SETQ L 1) N)
((ZEROP N))
(T (MINUS N))))
Az első feltételt több tevékenység is követi, a második feltételt viszont nem követi tevékenység. Mi lesz az ÁLTALÁNOSÍTOTT függvény értéke?
Ha a függvény argumentuma pozitív szám, tehát az első feltétel teljesül, akkor az első feltételt követő tevékenységek egymás után kiértékelődnek, és a kifejezés értéke az utolsó tevékenység értéke lesz.
* (ALTALANOSITOTT 5)
5
A (GREATERP N 0) feltétel teljesül, az ezt követő tevékenységek rendre kiértékelődnek: a K szabad változó értéke 0, az L szabad változó értéke 1 lesz, a feltételes kifejezés értéke pedig az N értéke, azaz 5.
Ha az argumentum értéke 0, akkor a második feltétel teljesül: (ZEROP N) értéke T. Mivel ezt a feltételt nem követi tevékenység, a feltételes kifejezés értéke magának a feltételnek az értéke lesz:
* (ALTALANOSITOTT 0)
T
Példánk jól szemlélteti, hogy az általánosított feltételes kifejezéseknek azt a fajtáját, amelyben egy feltételt több tevékenység követ, sokszor arra használjuk, hogy a feltétel teljesülése esetén mellékhatással rendelkező kifejezéseket értékeljünk ki, pl. változóknak értéket adjunk.
Beláthatjuk, hogy az általánosított feltételes kifejezéseknek megfelelő kifejezést már nem lehet csupán az AND és az OR logikai függvényekkel felírni.
3.5. A rekurzív függvénydefiníciók
A LISP nyelvben rendkívül fontos szerepet játszanak a rekurzív függvénydefiníciók. Egy függvény definíciót rekurzívnak nevezünk, ha a függvény törzsében alkalmazzuk magát a függvényt. A rekurzív függvénydefiníciót először a faktoriális függvény példáján mutatjuk be, amely nemnegatív egész számokon van értelmezve; az n pozitív egész szám faktoriálisa az 1- től n-ig terjedő égész számok szorzatát jelenti. A függvény matematikában szokásos jelölése n!:
n! = 1 x 2 x ... x n ha n > 0
A definícióból kiolvashatjuk, hogy ha az n - 1 szám faktoriálisát már meghatároztuk, akkor az n faktoriálisát egyetlen szorzással kiszámíthatjuk:
n! = n x (n - 1)! ha n > 0
A függvényt a 0 argumentumra is értelmezzük, a 0 faktoriálisa definíció szerint 1-gyel egyenlő. A faktoriális függvény teljes definíciója tehát
n! = n x (n - 1)! ha n > 0; n! = 1 ha n = 0
Negatív számokra és nem egész számokra a faktoriális függvényt nem értelmezzük. Írjuk fel annak a LISP függvénynek a definícióját, amely kiszámítja egy szám faktoriálisát! A definícióban feltételes kifejezéssel választjuk szét a különböző eseteket. Abban az esetben, amikor az argumentum értéke 0, egyszerűen megkapjuk a függvény értékét:
(DEFUN FAKTORIALIS (N)
(COND ((ZEROP N) 1)
... ))
Abban az esetben, amikor N értéke nem 0, az N faktoriálisának kiszámítását visszavezethetjük a (SUB1 N) faktoriálisának kiszámítására:
(DEFUN FAKTORIALIS (N)
(COND ((ZEROP N) 1)
(T (TIMES N (FAKTORIALIS (SUB1 N))))))
A függvény törzsében tehát alkalmazzuk a FAKTORIALIS függvényt az argumentum 1-gyel csökkentett értékére.
Kövessük végig a FAKTORIALIS függvény kiértékelését néhány esetben! A legegyszerűbb esetben
(FAKTORIALIS 0)
Az argumentum értéke 0, a feltételes kifejezésben az első feltétel teljesül, a függvény értéke tehát 1.
Ha az argumentum értéke 1, a
(FAKTORIALIS 1)
kifejezés kiértékelésekor az első feltétel nem teljesül, a kiértékelés a második feltétel vizsgálatával folytatódik. A feltétel értéke T, ezért a második feltételhez tartozó tevékenység kiértékelődik: a (TIMES N (FAKTORIALIS (SUB1 N))) kifejezés, amely ismét a FAKTORIÁLIS függvényt tartalmazza. (FAKTORIALIS (SUB1 N)) argumentumának értéke 0, így a függvény törzsében az első feltétel teljesül, és a függvény értéke 1. Ezután (FAKTORIALIS (SUB1 N)) értéke még megszorzódik N értékével, azaz 1-gyel, végül tehát
* (FAKTORIALIS 1)
1
Hasonló a (FAKTORIALIS N) kiértékelése, ha N értéke tetszőleges pozitív szám: először a második feltétel teljesül, ezért a FAKTORIALIS függvényt az argumentum 1-gyel csökkentett értékére kell alkalmazni. Ez mindaddig ismétlődik, amíg az argumentum értéke 0 nem lesz: ha pozitív egész számból indultunk ki, akkor ez véges számú lépés után bekövetkezik. A 0 faktoriálisa közvetlenül adódik, majd visszafelé haladva szorzásokkal egymás után megkapjuk a FAKTORIALIS függvény értékeit.
Kövessük nyomon a FAKTORIALIS függvény kiértékelését!
* (FAKTORIALIS 3)
6
A FAKTORIALIS függvény argumentuma 3, tehát az N változó értéke kezdetben 3, a következő lépésben a FAKTORIALIS függvényt a 2 argumentumra alkalmazzuk, ekkor az N változó értéke 2 lesz. A további lépésekben a függvényt az 1 és a 0 argumentumra alkalmazzuk, az N értéke 1, majd 0 lesz. Az N lambdaváltozó előző értéke azonban mindig megőrződik, és a kiértékelés után N visszakapja előző értékét. Minden alkalmazás után kiíródik a FAKTORIALIS függvény értéke is.
A rekurzió két lényeges feltétele:
Az utóbbi feltételt - feltételeket - megállási vagy befejezési feltételnek is szokás nevezni. A faktoriális függvény esetében a függvény kiszámítását az 1-gyel csökkentett argumentumhoz tartozó függvényérték kiszámítására vezetjük vissza, ez az egyszerűbb eset. A megállási feltétel pedig a argumentum esete, erre a függvény értéke közvetlenül kiszámítható.
A 3.1. szakaszban kiszámítottuk az 1-től 5-ig terjedő egész számok négyzetösszegét. Most olyan függvényt definiálunk, amely 1-től tetszőleges n egész számig kiszámítja a számok négyzetösszegét. Feltesszük, hogy a NEGYZET függvény definíciója (amelyet a 3.1. szakaszban adtunk meg) most is érvényben van. A megállási feltétel az az eset, amikor N értéke 0, ekkor a függvény értéke is 0: egyébként pedig N négyzetét kell hozzáadnunk az első n-1 szám négyzetösszegéhez.
(DEFUN NEGYZETOSSZEG (N)
(COND ((ZEROP N) 0)
(T (PLUS (NEGYZET N)
(NEGYZETOSSZEG (SUB1 N))))))
Nevezetes függvény a Fibonacciról elnevezett függvény. Fibonacci ehhez a nyulak szaporodásának modellezésével jutott el. Egyetlen nőstény nyúl leszármazottainak a számát a következőképpen számította ki: feltételezte, hogy egy nyúl egyhónapos korában válik szaporodóképessé, és ekkor egyetlen utódot hoz a világra. Az egyszerűség kedvéért feltételezte azt is, hogy minden újszülött nyúl nőstény, és a nyulak örökké élnek. Ezért minden nyúl, amelyik eléri a szaporodóképes kort, ettől kezdve havonta egy utódot hoz a világra. A Fibonacci-függvény az n-edik hónap végén élő összes nyúl számát adja meg. Ezt úgy kaphatjuk meg, hogy az utolsó hónapban született nyulak számát hozzáadjuk az n-1-edik hónap végén élt nyulak számához. Az utolsó hónapban született nyulak száma viszont azonos az n-2-edik hónap végén élt nyulak számával, hiszen ezeknek a nyulaknak született utóda az utolsó hónapban. Az f(n) Fibonacci-függvény definíciója tehát
f(n) = 1, ha n=0;
f(n) = 1, ha n=1;
f(n) = f(n-1) + f(n-2), ha n>1.
Legyen a LISP függvény neve FIBONACCI, definícióját így írhatjuk fel:
(DEFUN FIBONACCI (N)
(COND ((ZEROP N) 1)
((ONEP N) 1)
(T (PLUS (FIBONACCI (SUB1 N))
(FIBONACCI (SUB1 (SUB1 N)))))))
A definíció érdekessége a kettős rekurzió: a függvény értékének előállításához két előző függvényértéket kell kiszámítanunk.
* (FIBONACCI 3)
3* (FIBONACCI 8)
34
A kettős rekurzió miatt sok fölösleges számítást is végzünk. A (FIBONACCI 4) értékének kiszámításához elő kell állítani (FIBONACCI 3) és (FIBONACCI 2) értékét; (FIBONACCI 3) kiszámításához azonban ismét ki kell számítani (FIBONACCI 2) értékét, majd (FIBONACCI 1) értékét is és így tovább. így (FIBONACCI 4) kiszámításához a függvényt a 3 argumentumra egyszer, a 2 argumentumra kétszer, a különböző argumentumokra összesen 8-szor kell alkalmazni.
Hogyan definiáljuk a FIBONACCI függvényt, hogy értékét kevesebb munkával számíthassuk ki? Ehhez a függvény már kiszámított értékeit meg kell őriznünk. Vezessük be a FIB1 segédfüggvényt, amelynek az N változón kívül még két további lambdaváltozója is van: a K és az L, ezeket használjuk a már kiszámított függvényértékek megőrzésére:
(DEFUN FIBONACCI (N)
(FIB1 N 1 0))(DEFUN FIB1 (N K L)
(COND ((ZEROP N) K)
(T (FIB1 (SUB1 N) (PLUS K L) K))))* (FIBONACCI 4)
5
Láthatjuk, hogy most lényegesen kevesebb számítási munkával kaptuk meg a függvényértéket, a FIB1 segédfüggvényt csak ötször kellett alkalmazni.
A LISP nyelvben gyakran használjuk azt a módszert, hogy egy rekurzív függvénydefinícióban egy segédfüggvényt vezetünk be, amelynek változólistáján az eredetileg kiszámítandó függvény változóin kívül egy vagy több további változó is szerepel. Ezekben a változókban a rekurzív függvény már előállított értékeit őrizzük meg, hogy megtakarítsuk azok ismételt kiszámítását, ezért gyűjtőváltozóknak nevezzük őket. A FIB1 segédfüggvényben tehát a K és az L változók gyűjtőváltozók.
Egy másik jól ismert, rekurzívan definiálható függvény az Ackermann-féle függvény, amelynek definíciója, ha a függvény jelölése A(m,n):
| A(m,n) = n+1 A(m,n) = A(m-1,1) A(m,n) = A(m-1, A(m,n-1)) |
ha m=0; ha m>0 és n=0; ha m,n>0 |
Legyen a LISP függvény neve ACKERMANN:
(DEFUN ACKERMANN (M N)
(COND ((ZEROP M) (ADD1 N))
((ZEROP N) (ACKERMANN (SUB1 M) 1))
(T (ACKERMANN (SUB1 M)
(ACKERMANN M (SUB1 N))))))
A függvénydefinícióban itt is kettős rekurziót találunk, itt azonban az ACKERMANN függvény argumentumában szerepel a függvény rekurzív alkalmazása. Próbáljuk meg kiszámítani a függvény értékét M és N néhány értéke mellett!
* (ACKERMANN 2 1)
5* (ACKERMANN 3 1)
13
Az ACKERMANN függvény különleges tulajdonsága, hogy értéke az argumentumok növekedésével hihetetlenül gyorsan növekszik. (ACKERMANN 4 1) értéke 2^16 - 3, azaz 65533, (ACKERMANN 5 1) értéke pedig 2^65533 - 3. Ez olyan nagy szám, hogy a 10-es számrendszerben több mint 20000 számjegy kell a leírásához. Ha megpróbáljuk kiszámítani az ACKERMANN függvény értékét ezekre az argumentumokra, a számítás elképzelhetetlenül hosszú ideig tartana, vagy pedig az értelmezőprogram előbb-utóbb azt jelezné, hogy ilyen nagy számok ábrázolására nincs felkészülve.
Ha a rekurzív függvénydefiníció nem tartalmaz megállási feltételt, végtelen rekurzióhoz juthatunk. Nézzük meg, hogyan alakul a faktoriális függvény definíciója és kiértékelése, ha megfeledkezünk a megállási feltételről, és kihagyjuk annak a vizsgálatát, hogy az argumentum értéke 0-val egyenlő-e:
(DEFUN HIBAS-FAKTORIALIS (N) ;Hiányzik a megállási feltétel!
(TIMES N (HIBAS-FAKTORIALIS (SUB1 N))))
A definícióban nem adtunk meg megállási feltételt, így a HIBAS-FAKTORIALIS függvény minden alkalmazásakor eggyel csökkenti az argumentum értékét, majd erre újból alkalmazza a függvényt. Így a rekurzió elvileg végtelenül folytatódhatna anélkül, hogy a keresett függvényértéket előállítaná. A gyakorlatban azonban a végtelen rekurzió is előbb-utóbb megszakad azért, mert kimerül a rendelkezésre álló tárterület, vagy pedig azért, mert az adott számítógépen korlátozott az egy feladat végrehajtására használható idő, és elérjük ezt az időkorlátot. Párbeszédes üzemmódban megszakíthatjuk a kiértékelést, ha az a gyanúnk támad, hogy a függvény kiértékelése végtelen rekurzió miatt tart túl hosszú ideig.
A faktoriális függvény kiszámítására egy érdekes alternatív definíciót adhatunk a 2.2. szakaszban bevezetett EVAL függvény segítségével. A faktoriális függvény az első n pozitív egész szám szorzata. Kiszámíthatjuk tehát úgy is, hogy létrehozunk egy listát, amely az összeszorzandó számokból áll, majd alkalmazzuk a TIMES függvényt:
(DEFUN LISTN (N)
(COND ((ZEROP N) (LIST 1))
(T (CONS N (LISTN (SUB1 N))))))(DEFUN FAKTORIALIS (N)
(EVAL (CONS 'TIMES (LISTN N))))
A FAKTORIALIS függvénynek ebben a definíciójában az EVAL függvényt alkalmazzuk arra a listára, amely úgy jön létre, hogy a TIMES függvénynevet és a LISTN függvény által létrehozott, egész számokból álló listát a CONS függvénnyel egyesítjük, azaz pl. a (TIMES 1 1 2 3 4 5 6) listára. Egy LISP programmal hoztuk létre azt a programot, amelynek kiértékelésével megkapjuk a FAKTORIALIS függvény értékét. Ismét arra láttunk példát, hogy a LISP-ben program és adat között nincsenek válaszfalak.
3.5.1. Függvények és algoritmusok
A LISP nyelvet funkcionális nyelvnek nevezzük, mivel a LISP-ben nem végrehajtandó utasításokat írunk le, hanem függvényeket, amelyeket argumentumokra kell alkalmazni. Az eddigiekben bemutatott LISP függvénydefiníciók alapján azonban azt is érzékelhetjük, hogy a LISP nyelv függvényfogalma különbözik a matematikából jól ismert függvényfogalomtól. A LISP függvények a függvény értékét egy meghatározott eljárás segítségével állítják elő, algoritmusokat (Az algoritmus szó al-Khvarizmi arab matematikus nevéből származik (élt kb. i.u. 800 és 850 között).) valósítanak meg.
Algoritmusnak nevezünk egy feladat megoldására szolgáló, meghatározott lépésekből álló eljárást, ha eleget tesz bizonyos követelményeknek. Az eljárás egyes lépéseiben az előző lépések eredményétől függően esetleg döntéseket kell hoznunk arról, hogy hogyan folytatódjék az eljárás. Az eljárás szót itt teljesen általános értelemben használjuk, nemcsak valaminek a kiszámítására szolgáló eljárás lehet. Eljárást ír le pl. a somlói galuska receptje, vagy a KRESZ egy szabálya, mert arról rendelkezik, hogy mi a teendő egy adott forgalmi helyzetben. De eljárás az a használati utasítás is, amely azt írja le, hogyan helyezzük üzembe új televíziókészülékünket. Egy eljárást akkor nevezzük algoritmusnak, ha kielégíti az alábbi követelményeket:
A bemutatott LISP függvények, a NEGYZET, az ELSO, a FAKTORIALIS és a FIBONACCI függvények eleget tesznek a fenti követelményeknek, tehát algoritmusokat írnak le. A NEGYZET függvény számokra, az ELSO függvény listákra, a FAKTORIALIS függvény nemnegatív egész számokra alkalmazható, és mindegyik véges sok lépésben meghatározott eredményt szolgáltat. Nem algoritmus azonban a HIBAS-FAKTORIALIS függvény definíciója által leírt eljárás, amelyből kihagytuk a megállási feltételt, mert ez az eljárás nem ér véget véges számú lépésben, akármilyen egész számra alkalmazzuk is.
Az általunk leírt algoritmusok mindegyik lépése jól meghatározott. Mikor fordulhat elő az, hogy egy eljárás egy lépése nem jól meghatározott?
Ilyen helyzet adódhat a mindennapi életből vett példáinkban: a konyhai receptek gyakori utasítása a "végy egy csipet sót"; nehéz azonban megmondani, hogy mennyi is pontosan egy csipet. Természetesen a konyhai munka követelményeihez általában elegendően pontos ez az előírás; nem elegendő azonban egy kémiai kísérlethez, ahol milligrammnyi vagy mikrogrammnyi pontossággal kell meghatározni a felhasznált anyagok mennyiségét.
A LISP függvények definíciójánál látnunk kell, hogy ha egy függvényre különböző definíciókat adunk, akkor általában különböző algoritmusokat is írunk le. A FAKTORIALIS függvényre adott mindkét definíció az első n egész szám szorzatának előállítására ad utasítást, de más a műveletek elvégzésének sorrendje. A FIBONACCI függvény két változata is ugyanazt a számítási eredményt szolgáltatja, de az első változatban a szereplő mennyiségeket mindig újból kiszámítjuk, a második változatban az egyszer már kiszámított részeredményeket megőrizzük, és újra felhasználjuk. Ez nem változtatja meg a számítás eredményét, csak elvégzésének idejét: a második algoritmus tehát a számítási idő szempontjából hatékonyabb. Bonyolult feladatok megoldásakor fontos, hogy az adott algoritmus ne csak helyes, hanem hatékony is legyen.
3.6. A leggyakrabban előforduló programozási hibák
Függvénydefiníciók írásakor leggyakrabban úgy követhetünk el hibát, hogy kihagyjuk a definíció valamelyik részét, és a definíció hiányos lesz.
Az alábbi definíció azért hibás, mert hiányzik a függvény név:
(DEFUN (X Y) ;Hiányzik a függvénynév!
(TIMES X Y))
A következő definícióból a változók listája hiányzik:
(DEFUN HIANYOS ;Hiányzik a változólista!
(OR (AND X Y) (AND (NOT Z))))
A definícióból a függvény törzse hiányzik:
(DEFUN ROSSZ (X Y Z)) ;Hiányzik a függvény törzse!
A hibák egy másik csoportját azok az esetek alkotják, amikor a definíció valamely helyén egy ott meg nem engedett S-kifejezés szerepel.
Hibás a definíció, ha a függvénynév helyén nem szimbólum áll, vagy pedig a változólista nemcsak szimbólumokat tartalmaz, pl.:
(DEFUN TUL-SOK-ZAROJEL ((X) (Y)) ;Hibás! A változólista
(CONS (CAR X) Y)) ;nem szimbólumokat tartalmaz!
Itt a változólistán szimbólumok helyett listák szerepelnek.
Hibát okoz, ha a függvénynév vagy a változólista különleges szimbólumokat tartalmaz:
(DEFUN KULONLEGES (T NIL) ;Lambdaváltozó nem lehet
(LIST T NIL)) ;különleges szimbólum!
Itt a változólistán a T és NIL különleges szimbólumok szerepelnek, noha ezek nem lehetnek lambdaváltozók.
(DEFUN T (X) ;A függvénynév nem lehet
(CDR X)) ; különleges szimbólum!
Itt függvénynévként a T különleges szimbólum szerepel.
A feltételes kifejezések írásakor is gyakran elkövethetünk hibákat. A következőkben ezeket a hibákat mutatjuk be.
Hibás a feltételes kifejezés, ha a COND argumentumaként nem listát adunk meg:
(COND A B) ;A COND argumentuma nem lista!
Itt a COND két argumentuma közül egyik sem lista.
Ha a feltételes kifejezés utolsó feltételében szerepel a T, hibát követünk el, ha azt zárójelbe tesszük:
(COND ((NULL LIST) 'ALFA)
((T) 'BETA)) ;Hibás feltétel!
Ugyancsak gyakori hiba az, hogy a feltételes kifejezésben a COND argumentumainak leírásánál kihagyunk egy kezdő zárójelet:
(COND (NULL LISTA) NIL) ;Hiányzik egy kezdő zárójel!
(T LISTA)) ;Hibás feltételes kifejezés!
1. feladat
A három logikai alapfüggvény, az AND, az OR és a NOT segítségével definiáljuk a következő logikai függvényeknek megfelelő LISP függvényeket!
a) Kizáró vagy: Kétargumentumú függvény, amelynek értéke csak akkor igaz, ha az argumentumok közül egy és csak egy argumentum értéke igaz, különben hamis. A LISP függvény neve legyen XOR.
A függvény értéktáblázata:
p q p xor q igaz
hamis
igaz
hamisigaz
igaz
hamis
hamishamis
igaz
igaz
hamis(DEFUN XOR (X Y)
(AND (OR X Y) (NOT (AND X Y))))
b) Ekvivalencia: Kétváltozós függvény, értéke akkor igaz, ha mindkét argumentum értéke igaz, vagy mindkét argumentum értéke hamis; egyébként értéke hamis. A LISP függvény neve legyen EQUIV.
p q p equiv q igaz
hamis
igaz
hamisigaz
igaz
hamis
hamisigaz
hamis
hamis
igaz(DEFUN EQUIV (X Y)
(AND (OR (NOT X) Y) (OR X (NOT Y))))
2. feladat
Definiáljuk a HAROMSZOG-TERULETE függvényt, amellyel egy háromszög területét számíthatjuk ki, ha ismert a háromszög alapja és magassága!
(DEFUN HAROMSZOG-TERULETE (ALAP MAGASSAG)
(QUOTIENT (TIMES (ALAP MAGASSAG) 2)))
3. feladat
Definiáljuk a KOZEJE-ESIK predikátumot, amelynek három argumentuma, a K, az M és az N csak szám lehet! A predikátum értéke igaz, ha a K szám az M és az N számok közé esik; azaz nagyobb, mint M, és kisebb, mint N. Egyébként a függvény értéke hamis.
(DEFUN KOZEJE-ESIK (K M N)
(AND (GREATERP K M) (LESSP K N)))
4. feladat
Defináljuk az UJ-EXPT függvényt, amely az m szám n-edik hatványát számítja ki! A függvénydefiníciót az alábbi rekurzív összefüggés alapján írjuk fel:
m^n = 1, ha n=0
m^n = m * m^n-1, ha n>0(DEFUN UJ-EXPT (ALAP KITEVO)
(COND ((ZEROP KITEVO) 1)
(T (TIMES ALAP (UJ-EXPT ALAP (SUB1 KITEVO))))))
5. feladat
Definiáljuk az OSSZEAD függvényt, amelynek egy lambdaváltozója van, és ennek értéke egy számokból álló lista! A függvény számítsa ki a listát alkotó számok összegét!
A feladatra két megoldást is adunk:
(DEFUN OSSZEAD (LIS)
(COND ((NULL LIS) 0)
(T (PLUS (CAR LIS) (OSSZEAD (CDR LIS))))))(DEFUN OSSZEAD1 (LIS)
(COND ((NULL LIS) 0)
(T (EVAL (CONS 'PLUS LIS)))))
6. Feladat
A
Pn(x) = an + an-1x + ... + a1x^n-1 + a0x^n
polinomnak az x helyen vett helyettesítési értékét az ún. Horner-elrendezés segítségével a következő rekurzív képlet alapján számíthatjuk ki:
Pn(x) = xPn-1(x)+an ha n>0
P0(x) =a0
Definiáljuk a HORNER függvényt, amelynek első argumentuma egy x érték, második argumentuma pedig a polinom együtthatóiból álló lista, amely az együtthatókat az (an an-1 . a1 a0) sorrendben tartalmazza. Alkalmazzuk a függvényt a
P(x) = 5 + 4x + 3x^2 + 2x^3
polinom x = 2 helyen való helyettesítési értékének, és a
Q(z) = 8x - 4x3 + x^6
polinom x = 4 helyen való helyettesítési értékének a kiszámítására! Vegyük figyelembe, hogy az együtthatók listáján a 0-val egyenlő együtthatókat is meg kell adnunk!
(DEFUN HORNER (X LIS)
(COND ((NULL (CDR LIS)) (CAR LIS))
(T (PLUS (CAR LIS)
(TIMES X (HORNER X (CDR LIS)))))))
A P(x) polinom együtthatóinak listája (5 4 3 2), a polinom helyettesítési értéke az x=2 helyen:
* (HORNER 2 '(5 4 3 2))
41
A Q(x) polinom együtthatóinak listája (0 8 0 -4 0 0 1), - a 0-val egyenlő együtthatóknak is szerepelnie kell a listában -, a polinom helyettesítési értéke az x=4 helyen:
* (HORNER 4 '(0 8 0 -4 0 0 1))
3872
4. További rekurzív függvénydefiníciók
4.1. Listákon értelmezett függvények
Az első három fejezetben megismerkedtünk a LISP alapvető fogalmaival, függvényeivel. A birtokunkban levő eszközökkel a legtöbb programozási feladatot meg tudjuk oldani.
A LISP programozás azonban sajátos gondolkodásmódot igényel, amelynek elsajátítása sok fáradságába kerülhet azoknak is, akik már rendelkeznek programozási tapasztalattal más nyelvek (FORTRAN, Pascal, BASIC, különböző assembler nyelvek) körében.
Ebben a fejezetben a LISP-ben való jártasságot szeretnénk elmélyíteni sok példa segítségével. A fejezet kidolgozott példái módot adnak a rekurzív függvénydefiniálási módszer elsajátítására, amely a LISP programozásban alapvető fontosságú. Az első pontban több egyszerű függvény segítségével ízelítőt adunk a LISP programozásból. A következő szakaszokban mélyebb ismeretekre teszünk szert először az egyszerűbb, majd az egyre bonyolultabb rekurzív függvények körében.
A bemutatott függvények nagy része az értelmezőprogramba van beépítve, ezért a programozónak általában nem kell definiálnia őket. Érdemes mégis végigkövetni a definíciójukat, mert sok ötletet, módszert adnak a bonyolultabb LISP programok írásához.
Az előző fejezetben numerikus értékeken értelmezett rekurzív függvényeket definiáltunk. Most olyan rekurzív függvényeket vezetünk be, amelyeknek argumentuma lista lehet. A listákon végzendő műveleteket természetesen fogalmazhatjuk meg rekurzív függvénydefiníciók segítségével, mivel magának a listának a fogalma is rekurzívan definiálható:
Definiáljunk egy függvényt, amely egy lista elemeinek számát - más néven hosszát - adja meg! Mivel a legtöbb LISP rendszerben LENGTH néven van ilyen függvény, az UJ-LENGTH nevet adjuk a definícióban, a lambda- változó pedig legyen LIS. Ha LIS üres lista, akkor nincs eleme, a lista hossza tehát 0. Ez a rekurzió megállási feltétele. Ha LIS nem üres lista, akkor a feladatot visszavezethetjük egy egyszerűbb esetre, a lista farkának hosszához hozzáadunk 1-et. A definíciót tehát így írhatjuk:
(DEFUN UJ-LENGTH (LIS)
(COND ((NULL LIS) 0) ;Megállási feltétel.
(T (ADD1 (UJ-LENGTH (CDR LIS]
Alkalmazzuk a függvényt:
* (UJ-LENGTH '(A B C D))
4* (UJ-LENGTH NIL)
0* (UJ-LENGTH '((A B) (C (D E) F) (((G H)))))
3
Definiáljuk az UJ-REVERSE függvényt, amely egy lista elemeinek sorrendjét megfordítja! (Az elemeket fordított sorrendben helyezi el egy listában.) A legegyszerűbb az üres lista esete, ennek megfordítása önmaga. A nem üres lista megfordítása a következő: a lista farkát megfordítjuk, és a lista fejét az APPEND függvénnyel ennek végéhez illesztjük:
(DEFUN UJ-REVERSE (LIS)
(COND ((NULL LIS) NIL)
(T (APPEND (UJ-REVERSE (CDR LIS))
(LIST (CAR LIS]
Kevesebb függvényalkalmazással járó, hatékonyabb definíciót írhatunk fel, ha egy segédfüggvényt vezetünk be, amely egy gyűjtőváltozóban megőrzi a lista farkának megfordítását. Gyűjtőváltozót már alkalmaztunk a FIBONACCI függvény definíciójában.
(DEFUN UJ-REVERSE (LIS)
(UJ-REVERSE1 LIS NIL)) ;segédfüggvény
(DEFUN UJ-REVERSE1 (LIS MUNKA) ;MUNKA a gyűjtőváltozó
(COND ((NULL LIS) MUNKA)
(T (UJ-REVERSE1 (CDR LIS)
(CONS (CAR LIS) MUNKA]
A MUNKA nevű gyűjtőváltozóban gyűjtjük az eredményt; ebben épül fel az eredeti lista elemeit fordított sorrendben tartalmazó lista. Ez lesz a függvény értéke:
* (UJ-REVERSE '(A B C))
(C B A)* (UJ-REVERSE ())
NIL* (UJ-REVERSE '(BAGOLY IS BIRO A MAGA HAZABAN))
(HAZABAN MAGA A BIRO IS BAGOLY)
A függvényérték így kevesebb függvényalkalmazással állítható elő, mivel az APPEND függvényt nem kell alkalmaznunk.
Azokban a LISP változatokban, amelyek megengedik, hogy egy függvényt kevesebb argumentumra alkalmazzunk, mint ahány lambdaváltozó a definíciójában szerepel, nincs szükség segédfüggvény bevezetésére. Magának az UJ-REVERSE függvénynek a definíciójában szerepeltethetjük a MUNKA gyűjtőváltozót:
(DEFUN UJ-REVERSE (LIS MUNKA)
(COND ((NULL LIS) MUNKA)
(T (UJ-REVERSE (CDR LIS)
(CONS (CAR LIS) MUNKA]
Ha ezek után a függvényt egy argumentumra, egy listára alkalmazzuk, akkor a MUNKA változóhoz az értelmezőprogram a lambdakötésben a NIL értéket rendeli hozzá.
Az UJ-REVERSE függvénynek ez a definíciója megegyezik az UJ-REVERSE1 függvény definíciójával. Fontos azonban tudni, hogy ezt a módszert nem használhatjuk azokban a LISP változatokban, amelyek megkívánják, hogy egy függvényt pontosan annyi argumentumra alkalmazzunk, mint ahány lambdaváltozó a definíciójában szerepelt.
Az UTOLSO-ELEM függvény egy lista utolsó elemét szolgáltatja. A függvényt értelmezzük arra az esetre is, ha az argumentum értéke atom, ekkor a függvényérték az argumentum értéke. Az üres listának nincs eleme, erre az esetre a függvényt úgy értelmezzük, hogy értéke NIL. Ez a rekurzió megállási feltétele is:
(DEFUN UTOLSO-ELEM (X)
(COND ((NULL X) NIL) ;Az üres listának nincs eleme.
((ATOM X) X) ;Ha az argumentum atom;
((NULL (CDR X)) (CAR X)) ;ha egyelemű lista;
(T (UTOLSO-ELEM (CDR X] ;különben a farok utolsó eleme
; lesz az érték.
Példa az alkalmazásra:
* (UTOLSO-ELEM '((A KUTYA UGAT) (A MACSKA NYAVOG)))
(A MACSKA NYAVOG)* (UTOLSO-ELEM '((A B) (C (D E) F) (((G H)))))
(((G H)))
Figyeljük meg a függvény definíciójában, hogy miután a függvényt rekurzívan alkalmaztuk a lista farkára, az így kapott függvényértékkel már semmilyen további műveletet sem végzünk; az érték változatlanul adódik vissza a magasabb szintekre, és ez lesz végül az UTOLSO-ELEM függvény értéke. A rekurziónak ezt a fajtáját farokrekurziónak nevezzük.
Ugyancsak farokrekurzióval definiálhatjuk az N-EDIK-ELEM függvényt, amely egy lista n-edik elemét szolgáltatja, feltételezve, hogy az elemek számozását 1-gyel kezdjük:
(DEFUN N-EDIK-ELEM (LIS N)
(COND ((ONEP N) (CAR LIS))
(T (N-EDIK-ELEM (CDR LIS) (SUB1 N]* (N-EDIK-ELEM '(EGY KETTO HAROM NEGY OT) 3)
HAROM
Sok LISP változat (az IS-LISP nem) beépített függvényként tartalmazza az NTH függvényt, amely a listának nem az n-edik elemét, hanem az n-edik "szeletét" állítja elő, azaz n = 1 esetén magát a listát, n = 2 esetén a lista farkát - CDR , majd a farok farkát - CDDR - és így tovább. Írjuk fel az UJ-NTH függvény definícióját!
(DEFUN UJ-NTH (LIS N)
(COND ((ONEP N) LIS)
(T (UJ-NTH (CDR LIS) (SUB1 N]* (UJ-NTH '(EGY KETTO HAROM NEGY OT) 3)
(HAROM NEGY OT)
Egy lista első atomjának megkeresésére az ELSO-ATOM függvényt vezethetjük be:
(DEFUN ELSO-ATOM (LIS)
(COND ((NULL LIS) NIL)
((ATOM (CAR LIS)) (CAR LIS)) ;A lista feje atom
(T (ELSO-ATOM (CAR LIS))))) ;Tovább keresünk a lista fejében
A függvény a lista fejét vizsgálja, ha ez atom, megtaláltuk az első atomot, ha pedig lista, akkor ennek első atomját keressük.
Nézzünk bonyolultabb példákat is! A bridzsjátékot francia kártyával játsszák, a négy szín neve pikk, kör, káró és treff. Minden színből 13 kártya szerepel a csomagban, összesen 52 kártya. Egy színen belül négy figura van, az ász, a király, a dáma és a bubi, a többi kártyát a 2-től 10-ig terjedő számok jelölik. Osztáskor a négy játékos 13-13 kártyát kap. A kártyáknak pontokban kifejezett értéke van, de csak a figuráknak a pontértéke pozitív, a többié
0 (ezek "értéktelen kártyák"). Egy játékos kezében lévő lap játékerejét a kártyák pontértékének összege határozza meg. Az egyik szokásos számítási mód szerint a figurák pontértéke:
A játékos lapjának ereje dönti el, hogy érdemes-e licitálnia, vagyis játékra vállalkoznia.
A négy bridzsjátékos jelölésére a négy égtáj nevét szokás használni. írja le az Északkal jelölt játékos kezében lévő lapot a következő lista:
(SETQ ESZAK
'((PIKK A) (PIKK D) (PIKK TIZES) (PIKK NYOLCAS) (PIKK HATOS) (KOR B) (KOR HETES)
(KARO K) (KARO D) (KARO OTOS)
(TREFF A) (TREFF K) (TREFF KILENCES)))
A lap erejének kiszámítására a LAPERO függvényt definiáljuk.
(DEFUN LAPERO (L)
(COND ((NULL L) 0)
((EQ (CADAR L) 'A) (PLUS 4 (LAPERO (CDR L)))) .ász
((EQ (CADAR L) 'K) (PLUS 3 (LAPERO (CDR L)))) ;király
((EQ (CADAR L) 'D) (PLUS 2 (LAPERO (CDR L)))) ;dáma
((EQ (CADAR L) 'B) (PLUS 1 (LAPERO (CDR L)))) ;bubi
(T (LAPERO (CDR L] ;egyéb lap
A bridzs szabályai szerint ahhoz, hogy valaki játékra vállalkozzék, legalább 13 pontjának kell lennie. Játékosunk tehát vállalhatja a játékot.
Az Európa térképén található országokról meg akarjuk állapítani, hogy egy adott országnak melyek a szomszédjai. Európa országait egy gráffal ábrázolhatjuk, amely a szomszédsági kapcsolatokat tünteti fel. Egy országnak a gráf egy csúcspontja felel meg, mellé írjuk az ország nevének nemzetközi szabvány szerinti rövidítését (ezeket a rövidítéseket a gépkocsikon látható jelzésekről ismerhetjük). Minden csúcspontot egy-egy él köt össze a szomszédos országoknak megfelelő csúcspontokkal. Csak azokat az országokat tekintjük szomszédosnak, amelyeknek közös szárazföldi határa van; nem szerepelnek tehát az ábrán azok az országok, amelyeknek teljes területe szigeten van, Izland, Nagy-Britannia és Írország. Nem tüntettük fel a törpeállamokat sem (Monaco, Andorra stb.), a Szovjetuniónak és Törökországnak pedig - mivel átnyúlnak Ázsiába - csak európai szomszédait ábrázoljuk.
A szomszédsági kapcsolatokat listaszerkezettel írhatjuk le. Ennek minden eleme kételemű allista, amely a gráf egy élének felel meg: az allista két eleme egy-egy ország neve, amelyek egymás szomszédai. Tehát minden ország annyi kételemű listában szerepel, ahány szomszédja van:
(SETQ EUROPA
'((P E) (E F) (F B) (B NL) (NL D) (B L) (F L) (L D) (F D)
(F CH) (F I) (D L) (D DDR) (D CS) (D A) (D CH) (D DK)
(CH I) (CH A) (I A) (I YU) (DDR CS) (CS PL) (DDR PL)
(PL SU) (CS A) (CS SU) (CS H) (H A) (H SU) (SU SF)
(SF S) (SF N) (N S) (H RO) (H YU) (A YU) (YU RO) (YU BG)
(YU GR) (YU AL) (AL GR) (GR BG) (BG RO) (SU RO) (BG TR)))
Az EUROPA szimbólumhoz rendeltük a szomszédsági kapcsolatokat ábrázoló listát. Ezután definiálhatjuk a SZOMSZEDAI függvényt:
(DEFUN SZOMSZEDAI (ORSZAG TERKEP)
(COND ((NULL TERKEP) NIL)
<(EQ (CAAR TERKEP) ORSZAG) ; Ha ORSZÁG az első elem,
(CONS (CADAR TERKEP) ; a másodikat csatoljuk
(SZOMSZEDAI ORSZAG (CDR TERKEP> ; a szomszédok listájához,
<(EQ (CADAR TERKEP) ORSZAG) ; ha pedig a második elem,
(CONS (CAAR TERKEP) ; az allista első elemét
(SZOMSZÉDAI ORSZAG (CDR TERKEP> ;csatoljuk a szomszédok listájához
(T (SZOMSZÉDAI ORSZAG (CDR TERKEP> ;különben tovább keresünk
A függvény egy ország szomszédait keresi meg a TÉRKÉP listán. Megvizsgálja, hogy tartalmazza-e az argumentumot a térképnek megfelelő lista feje (amely kételemű lista); ha igen, akkor a listafej másik elemét a függvényértékként előálló listához csatolja a CONS függvénnyel, és a TERKEP lista farkában keresi a további elemeket. Ha pedig a lista feje nem tartalmazza az argumentumot, akkor a TERKEP lista farkában kezdi keresni. Példa a függvény alkalmazására:
* (SZOMSZEDAI 'A EUROPA)
(D CH I CS H YU)* (SZOMSZEDAI 'F EUROPA)
(E B L D CH I)
de
* (SZOMSZEDAI 'USA EUROPA)
NIL
mert az USA jelű ország - az Egyesült Államok - nincs rajta Európa térképén.
4.2. Listák legfelső szintjét kezelő függvények
Definiáljunk egy olyan predikátumot, amely eldönti, hogy egy adott elemet a legfelső szinten tartalmaz-e egy adott lista; az ELEME tehát kétargumentumú függvény, az első argumentum az elem, a második a lista. A függvény definíciója:
(DEFUN ELEME (ELEM LISTA)
(COND ((NULL LISTA) NIL) ;Üres listának nincs eleme
((EQUAL ELEM (CAR LISTA)) T) ;Megtaláltuk az elemet
(T (ELEME ELEM (CDR LISTA] ;Tovább keresünk a lista farkában* (ELEME 'SEMMI ())
NIL* (ELEME 'SEMMI '(SEMMI SINCS INGYEN))
T
Értékeljük ki az
(ELEME 'HUSZAR '(FUTO (BASTYA) HUSZAR))
formát! A kiértékelés kezdetén a definíció első két feltétele nyilván nem teljesül, hiszen a LISTA változónak az értéke nem NIL, és a feje sem a HUSZAR szimbólum. Ezért a függvény értékét a harmadik kifejezés határozza meg, ami az egyszerűbb eset (eggyel rövidebb lista) vizsgálatának felel meg. Egy újabb formát kell kiértékelni, ennek az értéke lesz a függvény értéke is. Ez a forma ismét az ELEME függvény alkalmazását írja elő, a HUSZAR és a ((BASTYA) HUSZAR) argumentumokra.
Az újabb és újabb formák kiértékelésének az vet véget, ha eljutunk valamelyik megállási feltételhez. Ha a feltételes kifejezés első vagy második feltétele teljesül, a hozzájuk tartozó tevékenységekben nem kell az ELEME függvényt alkalmazni, tehát az ELEME függvényben két megállási feltétel is van. Az első ahhoz az esethez tartozik, amikor a lista nem tartalmazza az adott elemet. Ekkor a rekurzív lépések során eljutunk az üres lista vizsgálatához, a függvény értéke NIL. A második megállási feltétel ahhoz az esethez tartozik, amikor a lista tartalmazza az elemet. Ekkor eljutunk ahhoz az állapothoz, amikor az adott elem maga a vizsgált lista első eleme, így a függvény értéke T. Pl. az
(ELEME 'TIGRIS '(PARDUC OROSZLAN))
forma kiértékeléséhez az ELEME függvényt az első rekurzív lépésben a TIGRIS és az (OROSZLAN), a másodikban pedig a TIGRIS és a () argumentumokra kell alkalmazni. A második lépésben a megállási feltétel teljesül, a NIL értéket kapjuk, és így a kiértékelés megáll.
Az ELEME függvény definiálása nélkül is eldönthetjük, hogy egy kifejezés eleme-e egy listának. A LISP-ben létezik ugyanis egy beépített függvény, amely ezt vizsgálja: a MEMBER függvény. Ennek értéke NIL, ha az első argumentumként megadott elem nem szerepel a második argumentumként megadott lista legfelső szintjén. Ha viszont szerepel, akkor - az ELEME függ-vénytől eltérően - értéke nem T, hanem egy lista. (A 2. fejezetben láttuk, hogy minden értéket, ami nem NIL, igaz értékűnek tekintünk.) Ez a lista úgy áll elő, hogy az argumentumként megadott listából elhagyjuk a keresett elem előtt levő listaelemeket. Legyen a KEDVESEK szimbólum értéke a (DELFIN KOALA TATU) lista, a FOGHIJASOK szimbólum értéke pedig a (LAJHAR HANGYASZ TATU SUN) lista:
* (MEMBER 'TATU FOGHIJASOK)
(TATU SUN)
Ha az elem többször is előfordul a listában, akkor a MEMBER értéke az a lista, amelynek feje a keresett elem első előfordulása.
* (MEMBER 'TATU (APPEND KEDVESEK FOGHIJASOK))
(TATU LAJHAR HANGYASZ TATU SUN)
Az ELEME függvény definíciója alapján könnyen felírhatjuk a MEMBER függvénnyel azonos értéket szolgáltató UJ-MEMBER definícióját is; a definícióban a második feltételnél, amikor megtaláltuk a keresett elemet a listán, a T érték helyett a LISTA változónak az értékét adja meg a függvény:
(DEFUN UJ-MEMBER (ELEM LISTA)
(COND ((NULL LISTA) NIL)
((EQUAL ELEM (CAR LISTA)) LISTA) ;Itt van az eltérés
(T (UJ-MEMBER ELEM (CDR LISTA]* (ELEME '(TATU SUN) '(MAKI PAVIAN (TATU SUN) EGER))
T* (UJ-MEMBER '(TATU SUN) '(MAKI PAVIAN (TATU SUN) EGER))
((TATU SUN) EGER)
Definiáljunk ezután olyan függvényt, amelynek segítségével törölhetünk egy elemet egy listából. Legyen ez az ELHAGY függvény, amely kétargumentumú, argumentumai egy S-kifejezés - az eltávolítandó elem - és egy lista; értéke pedig az a lista, amelyből az elem első előfordulását töröltük a legfelső szinten. (IS-LISP-ben DELETE a függvényneve.)
Az ELHAGY definíciójában - akárcsak az UJ-MEMBER-ében - két megállási feltétel van. Ha a lista üres, akkor az érték az üres lista, NIL; ha pedig a lista feje az eltávolítandó S-kifejezés, akkor az érték a lista farka. A függvényben rekurzív lépést akkor alkalmazunk, ha a lista feje nem az eltávolítandó S-kifejezés. Ha azonban ezt a rekurzív lépést úgy fogalmazzuk meg, mint az UJ-MEMBER esetében - vagyis a függvényt az ELEM változónak az értékére és a LISTA értékének a farkára alkalmazzuk - hibás definíciót kapunk:
(DEFUN ELHAGY (ELEM LISTA) ;Hibás!
(COND ((NULL LISTA) NIL)
((EQUAL ELEM (CAR LISTA))
(CDR LISTA))
(T (ELHAGY ELEM (CDR LISTA] ;Ez a hibás sor!
Figyeljük meg, mi történik!
* (ELHAGY 'OZ '(DOROTHY OZ TOTO))
(TOTO)
A hiba az, hogy az OZ-t megelőző listaelemeket is elhagyjuk. Azt szeretnénk, hogy ha a lista feje nem azonos az ELEM értékével, a fej a függvény értékében is szerepeljen. Ezt úgy érhetjük el, hogy a rekurzív lépésben megtartjuk a LISTA első elemét. A helyes definíció:
(DEFUN ELHAGY (ELEM LISTA)
(COND ((NULL LISTA) NIL)
((EQUAL ELEM (CAR LISTA)) ;Ha a lista feje az ELEM,
(CDR LISTA)) ;kihagyjuk.
(T (CONS ;Ha nem, a CONS függvénnyel
(CAR LISTA) ;hozzákapcsoljuk a
(ELHAGY ELEM (CDR LISTA] rekurzívan kapott értékhez.
Próbáljuk ki ezt az új függvényt!
* (ELHAGY 'OZ '(DOROTHY GYAVA-OROSZLAN OZ TOTO))
(DOROTHY GYAVA-OROSZLAN TOTO)
Az UJ-MEMBER és az ELHAGY függvények működését összehasonlítva azt látjuk, hogy az UJ-MEMBER függvénynél a legegyszerűbb eset értéke egyben a bonyolultabb esetek értéke is. Ez a függvény tehát farokrekurzív. Az ELHAGY függvény azonban nem farokrekurzív, mert a legegyszerűbb eseteknek az értéke - a megállási feltételhez tartozó érték - nem azonos a bonyolultabb esetek értékével. Az egyszerűbb esetek értékére ugyanis még alkalmazzuk a CONS függvényt, és ennek az értéke lesz a bonyolultabb esetek értéke. Az ELHAGY függvény kiértékelésénél fontos szerepe van annak, hogy a korábbi változóértékek megőrződtek. Az ÚJ-MEMBER függvénynél - és a farokrekurzív függvényeknél általában -, mivel az értékek visszaadásakor már nem értékelődik ki egyetlen forma sem, a változók korábbi értékeit nem használjuk fel. Az ELHAGY függvénynél viszont a változók korábbi értékét a CONS függvény alkalmazásánál felhasználjuk.
Minden LISP értelmezőprogram tartalmaz olyan beépített függvényt, amellyel egy elemet törölhetünk egy listából. Általában REMOVE a függvény neve és két argumentuma van: egy S-kifejezés és egy lista, mint az ELHAGY függvénynek. A két függvény között az a különbség, hogy míg az ELHAGY (DELETE) csak az adott elem első előfordulását törli, a REMOVE az elem minden előfordulását törli a lista legfelső szintjén. Az UJ-REMOVE függvényt - amely működésében a REMOVE függvénnyel megegyezik - az ELHAGY definíciójának átalakításával kaphatjuk:
* (DEFUN UJ-REMOVE (ELEM LISTA)
(COND ((NULL LISTA) NIL)
((EQUAL ELEM (CAR LISTA)) ;Ha a lista feje törlendő,
(UJ-REMOVE ELEM ; a lista farkából is
(CDR LISTA))) ; rekurzív módon töröljük
(T (CONS (CAR LISTA) ; az elemet.
(UJ-REMOVE ELEM (CDR LISTA]* (UJ-REMOVE '(OZ TOTO) '(TOTO (OZ TOTO) DOROTHY (OZ TOTO)))
(TOTO DOROTHY)
Az UJ-REMOVE definíciója tehát egy megállási feltételt és két rekurzív lépést tartalmaz; a második feltétel teljesülése esetén egyszerű farokrekurzióhoz folyamodunk, ha pedig a harmadik feltétel teljesül, összetettebb rekurziót alkalmazunk.
4.3. A halmazkezelő függvények
Ebben a szakaszban halmazokkal kapcsolatos függvényekre adunk példákat. A halmazműveleteket listakezelő függvényekkel valósítjuk meg.
Könyvünkben csak véges sok elemet tartalmazó halmazok szerepelnek. Ezeket úgy adjuk meg, hogy elemeiket kapcsos zárójelek között, vesszővel elválasztva felsoroljuk. Pl. halmaz a következő:
{gyík, kígyó, krokodilus, R2D2, 1987}.
A halmazokat egyszerű módon ábrázolhatjuk listákkal; a halmaz elemeit mint egy lista elemeit ábrázoljuk. A kapcsos zárójelek helyett a listák leírásához használt kerek zárójeleket, a szavak, számok helyett a nekik megfelelő atomokat írjuk, és a vesszőket elhagyjuk. Az előbbi halmaznak a
(GYIK KIGYO KROKODILUS R2D2 1987)
lista felel meg.
Az üres halmaznak - amelynek nincs egyetlen eleme sem, és amelynek szokásos jelölése {} vagy 0 - az üres lista felel meg. Ha a halmaz valamely elemének meghatározása több szóból áll, ennek egy kötőjelekkel összefűzött atomot feleltetünk meg: a
{páncélos teknős, a házunk előtt álló platánfa}
kételemű halmaznak a
(PANCELOS-TEKNOS A-HAZUNK-ELOTT-ALLO-PLATANFA)
listát feleltetjük meg.
A halmaz és lista megfeleltetése nem kölcsönösen egyértelmű! Például a {B,K,V} és a {B,V,K} halmazok nyilván azonosak, hiszen a felsorolás sorrendje halmazok esetén nem számít, de a (B K V) és a (B V K) listák különbözőek!
Nem tekintjük halmaznak az olyan listát, amely egy elemet többször is tartalmaz. Pl. a (HASS IS ALKOSS IS) listát nem tekintjük halmaznak, mivel az IS elem kétszer szerepel.
Egy halmaznak egy másik halmaz is eleme lehet:
{muréna, polip, {veréb, cinke, csusza}}
az ilyen halmazokkal azonban majd csak a 4.5. szakaszban foglalkozunk.
A MEMBER és a REMOVE függvények halmazok kezelésére is használhatók. Az előbbi függvénnyel eldönthetjük, hogy egy elemet tartalmaz-e a halmaz, az utóbbival az elemet törölhetjük a halmazból.
* (MEMBER 'ES '(LANDERER ES HECKENAST))
(ES HECKENAST)* (REMOVE 'ES '(LANDERER ES HECKENAST))
(LANDERER HECKENAST)
Mivel nem minden lista tekinthető halmaznak, hasznos definiálnunk egy függvényt, amellyel eldönthetjük, hogy egy lista halmaznak tekinthető-e vagy sem. Legyen ez a HALMAZ-E függvény, amelynek egyetlen argumentuma van. A függvény értéke T, ha az argumentum halmaz, azaz egyetlen elemet sem tartalmaz többszörösen; ha pedig az argumentum nem halmaz, azaz atom vagy olyan lista, amely egy elemet többszörösen is tartalmaz, akkor a függvény értéke NIL. A definíció:
(DEFUN HALMAZ-E (LISTA)
(COND ((NULL LISTA) T) ;Az üres lista halmaz
((ATOM LISTA) NIL) ;az atom nem halmaz
((MEMBER (CAR LISTA) ;a lista feje szerepel
(CDR LISTA)) ; a lista farkában:
NIL) ; nem halmaz
(T (HALMAZ-E (CDR LISTA]* (HALMAZ-E '(ARU KAPU (BORU TANU) DARU))
T
A HALMAZ-E függvény az ELEME és az UJ-MEMBER függvényhez hasonlóan farokrekurzív.
Definiáljunk most olyan függvényt, amely a többszörös elemeket tartalmazó listákból az elemek ismételt előfordulásait törli! Az értékként kapott lista már halmaznak tekinthető, ezért legyen a függvény neve HALMAZOSIT. Egy argumentuma van, a lista, amelyből halmazt kell előállítani.
(DEFUN HALMAZOSIT (LISTA)
(COND ((NULL LISTA) NIL)
((MEMBER (CAR LISTA) ;Ha a lista feje eleme
(CDR LISTA)) ; a lista farkának,
(HALMAZOSÍT (CDR LISTA))) ; akkor elhagyjuk
(T (CONS (CAR LISTA) ;Ha nem eleme, akkor
; a halmazosltott lista farkához fűzzük
(HALMAZOSIT (CDR LISTA>* (HALMAZOSIT '(HASS IS ALKOSS IS))
(HASS ALKOSS IS)
Készítsük el a halmazelméletből ismert legfontosabb függvények LISP definícióit! Az A és B halmazok egyesítése azokból az elemekből áll, amelyeket vagy az A, vagy a B halmaz tartalmaz.
Definiáljuk az UJ-UNION függvényt, amelynek két argumentuma van, mindkettő lista (mégpedig olyan, amely halmaznak tekinthető); értéke pedig a halmazok egyesítésének megfelelő lista. A függvényt a következő algoritmus alapján definiáljuk. Mivel a második halmaz minden eleme biztosan eleme lesz az egyesített halmaznak, csak a második halmazt kell kibővítenünk az első halmaz azon elemeivel, amelyek nem szerepelnek a második halmazban:
(DEFUN UJ-UNION (H1 H2)
(COND ((NULL H1) H2) ;Ha H1 üres, az eredmény H2.
((MEMBER (CAR H1) H2) ;Ha H1 első eleme szerepel a
; H2 halmazban, akkor nem
(UJ-UNION (CDR H1) H2)) ; kell foglalkoznunk vele.
(T (CONS (CAR H1) ;Ha nem szerepel, hozzáfűzzük
(UJ-UNION (CDR H1) H2] ; a maradék H1 és H2 egyesítéséhez* (UJ-UNION '(DO RE MI FA) '(DO (TI LA) SZO FA))
(RE MI DO (TI LA) SZO FA)
Figyeljük meg, hogy a függvény nem szimmetrikus:
* (UJ-UNION '(DO (TI LA) SZO FA) '(DO RE MI FA))
((TI LA) SZO DO RE MI FA)
Az argumentumok felcserélésével olyan listát kapunk, amely az elemeket más sorrendben tartalmazza, mint halmaz azonban megegyezik az előzővel.
Természetesen a halmazok egyesítését előállító függvényt másképpen is definiálhatjuk. Egy másik megoldási lehetőség az, ha az APPEND és a HALMAZOSIT függvényeket használjuk:
(DEFUN UJABB-UNION (H1 H2)
(HALMAZOSIT ;A két listát összefűzi, majd
(APPEND H1 H2))) ; törli a többszörös elemeket.* (UJABB-UNION '(DO RE MI FA) '(DO (TI LA) SZO FA))
(RE MI DO (TI LA) SZO FA)
Az A és a B halmazok metszete azokból az elemekből áll, amelyeket mind az A, mind a B halmaz tartalmaz. Az UJ-INTERSECTION függvényt az előzőek alapján könnyen definiálhatjuk, a rekurzió ugyanolyan szerkezetű, mint az UJ-UNION esetében:
(DEFUN UJ-INTERSECTION (H1 H2)
(COND ((NULL H1) NIL) ;H1 üres, a metszet is üres.
((MEMBER (CAR H1) H2) ;Ha H1 első eleme H2-nek is
(CONS (CAR H1) ; eleme, akkor ez a metszetnek
(UJ-INTERSECTION (CDR H1) H2))) ; is eleme
(T (UJ-INTERSECTION (CDR H1) H2]* (UJ-INTERSECTION '(RE DO) '(SZO MI DO))
(DO)
Vezessük be a részhalmaz fogalmát: a B halmaz az A halmaz részhalmaza, ha B minden eleme egyszersmind eleme A-nak is. A RESZHALMAZA-E predikátum eldönti, hogy az első argumentumként megadott halmaz részhalmaza-e a második argumentumnak.
(DE RESZHALMAZA-E (H1 H2)
(COND ((NULL H1) T)
(T (AND (MEMBER (CAR H1) H2) ;ha H1 feje eleme
; H2-nek, és H1 farka részhalmaza H2-nek
(RESZHALMAZA-E (CDR H1) H2]
* (RESZHALMAZA-E '(GYIK KIGYO SIKLO)
'(HULLO EMLOS GYIK HAL KIGYO MADAR SIKLO))
T
Láttuk, hogy a halmazoknál az elemek sorrendje nem számít, ezért egy halmaznak több különböző lista felelhet meg, amelyek egymástól csak elemeik sorrendjében különböznek. Szükségünk van tehát olyan predikátumra is, amely két listáról eldönti, hogy ugyanannak a halmaznak felelnek-e meg.
(DEFUN AZONOSAK-E (H1 H2)
(AND (RESZHALMAZA-E H1 H2)
(RESZHALMAZA-E H2 H1)))* (AZONOSAK-E '(TATU SUN HANGYASZ KAKUKK RIGO)
'(KAKUKK HANGYASZ RIGO SUN TATU))
T
A függvény definíciójában azt használtuk fel, hogy ha H1 minden eleme egyben eleme H2-nek is, és H2 minden elemét tartalmazza a H1 halmaz, akkor a két halmaz megegyezik.
4.4. A listák minden szintjét kezelő függvények
A fejezetben eddig ismertetett függvények közös tulajdonsága, hogy csak a lista legfelső szintjét kezelik. Pl.:
(UJ-MEMBER 'SZENDE '(KUKA HAPCI (SZENDE SZUNDI)))
NIL
hiszen SZENDE nem eleme a listának, csak egy allistájának. Hasonlóan
(UJ-REMOVE 'MOHA '(ZUZMO (MOHA PAFRANY) MOHA))
(ZUZMO (MOHA PAFRANY))
az UJ-REMOVE törli a MOHA elemet a legfelső szintről, de nem törli a második szintről a (MOHA PAFRANY) allistából.
Ebben a szakaszban olyan függvényeket fogunk bevezetni, amelyek a lista minden szintjét feldolgozzák. A minden listaszintet kezelő függvények közül az egyik legegyszerűbb a lista zárójelszintjeinek maximális számát, vagy másképpen a lista legnagyobb zárójelezési mélységét adja meg.
Legyen a függvény neve MILYEN-MELY, argumentuma egy lista, értéke pedig az a szám, amely a lista legnagyobb mélységét megadja:
(DEFUN MILYEN-MELY (LISTA)
(COND ((NULL LISTA) 0)
((ATOM LISTA) 0)
(T (MAX (ADD1 (MILYEN-MELY (CAR LISTA)))
(MILYEN-MELY (CDR LISTA]
A függvény értéke 0, ha argumentuma atom vagy az üres lista. Ha az argumentum ennél bonyolultabb S-kifejezés, a függvény két irányban keresi a legnagyobb mélységet. Először a lista fejének (amely maga is lehet lista) a mélységét vizsgálja. Ekkor, mivel a lista feje eleme a listának, a lista fejének legnagyobb mélységéhez még hozzá kell adnunk 1-et. Ezt az értéket hasonlítjuk össze a lista farkában "mért" legnagyobb mélységgel, a két érték közül a nagyobb lesz a lista mélysége. (A 2.4. szakaszban láttuk, hogy a lista feje és farka nem szimmetrikus fogalmak! A lista feje eleme a listának, a farka azonban nem.) A fej és a farok mélységét a MILYEN-MELY függvény rekurzív alkalmazásával kapjuk.
A 4.2 szakaszban bevezetett, csak a lista legfelső szintjét vizsgáló függvények
- pl. az UJ-MEMBER - esetében a rekurzió egyszerűbb volt; a függvényt mindig a lista farkára alkalmaztuk a rekurziós lépésben. Most azonban a lista fejére és farkára is alkalmazzuk a függvényt. Ezt a rekurzív módszert fej-farok rekurziónak nevezik. Azokban az esetekben, amikor a lista minden szintjét kezelni kell, szinte mindig fej-farok rekurziót használunk.
Definiáljunk egy függvényt, amely az argumentumként megadott listában valamennyi szinten előforduló atomok számát adja meg, a többször előforduló atomokat annyiszor számítva, ahányszor előfordulnak. A NIL atomot - az üres listát - azonban nem számolja közéjük. Legyen a függvény neve HANYATOMOS, egyetlen argumentuma lista vagy atom lehet. A függvény definíciója:
(DEFUN HANYATOMOS (S)
(COND ((NULL S) 0) ;Üres listában nincs atom.
((ATOM S) 1) ;ha az argumentum atom: 1
(T (PLUS (HANYATOMOS (CAR S)) ;Az atomok száma egyenlő
(HANYATOMOS (CDR S] ; a lista fejében és a
; farkában levők számának összegével* (HANYATOMOS '((SZ E N) S (A (V) ())))
6
Az IRON egyargumentumú függvény értéke olyan lista, amely az argumentumban található atomokat (eredeti sorrendjükben) a legfelső szinten tartalmazza. Ha az argumentum értéke atom, a függvény értéke egyelemű lista, amelynek egyetlen eleme az argumentum értéke. Ha pedig az argumentum értéke lista, akkor szemléletesen úgy mondhatjuk, hogy a függvény eltünteti a lista leírásából a közbülső zárójeleket, mintegy "kivasalja" a listát. (Egyes LISP változatokban ennek a függvénynek a neve LINEARIZE.) A függvény definícióját így írhatjuk fel:
(DEFUN UJ-IRON (S)
(COND ((NULL S) NIL) ;Az üres lista ki van vasalva
((ATOM S) (LIST S)) ;Atom esetében egyelemű lista
(T (APPEND (UJ-IRON (CAR S));A kivasalt fejhez
(UJ-IRON (CDR S] ; kapcsoljuk a kivasalt farkat* (UJ-IRON '(BEKA (CET ((SUN (MACSKA) CAPA) (TATU) GYIK))))
(BEKA CET SUN MACSKA CAPA TATU GYIK)
A 4.2. szakaszban definiált ELEME, UJ-MEMBER és UJ-REMOVE függvények csak a lista legfelső szintjét vizsgálták. Sokszor azonban arra van szükségünk, hogy egy S-kifejezésről eldöntsük, vajon tartalmazza-e a lista akár a legfelső, akár valamelyik mélyebb szinten. Abban az esetben, ha az illető S-kifejezés atom, az UJ-IRON függvényt mint segédfüggvényt használhatjuk:
(DEFUN VAN-E-BENNE (A LIS)
(MEMBER A (UJ-IRON LIS))) ;A kivasalt listában keressük* (VAN-E-BENNE 'CAPA '(BEKA (CET ((SUN (MACSKA) CAPA) (TATU) GYIK]
(CAPA TATU GYIK)
Vezessük be a TARTALMAZZA-E függvényt, amely nemcsak atom, hanem tetszőleges S-kifejezés esetén is eldönti, hogy szerepel-e a listában. A függvény kétargumentumú: az első argumentum egy S-kifejezés, a második egy lista. A definíció:
(DEFUN TARTALMAZZA-E (SK LIS)
(COND ((NULL LIS) NIL) ;Az üres listában nincs
((EQUAL SK (CAR LIS)) T) ;A lista fejével egyezik
((ATOM (CAR LIS)) ;A lista feje atom. Így
(TARTALMAZZA-E SK (CDR LIS))) ; a farkában keressük
(T (OR (TARTALMAZZA-E SK (CAR LIS)) ;Keressük a lista
(TARTALMAZZA-E SK (CDR LIS] ; fejében vagy a farkában* (TARTALMAZZA-E '(GYIK) '((KIGYO (GYIK)) SUN (TEKNOS BEKA)))
T
Fel kell hívnunk a figyelmet a fej-farok rekurzív függvények definiálásakor gyakran előforduló hibára. A CDR függvény szerinti rekurziónál általában a NULL függvényt használjuk a megállási feltételben, hiszen ha a rekurzió során mindig a lista farkát vesszük, előbb-utóbb eljutunk az üres listához. Ha azonban fej-farok rekurziót használunk, lehet, hogy a lista feje nem lista, így a megállási feltétel - amely azt vizsgálja, hogy az argumentum az üres lista-e -, nem állítja meg a kiértékelést, azaz végtelen vagy hibás rekurzióhoz jutunk. A fej-farok rekurzív függvényeknél ezért általában szükség van olyan megállási feltételre is, amely azt vizsgálja, hogy az argumentum (vagy az argumentum feje) atom-e. Így tettünk a MILYEN-MELY, a HANYATOMOS, vagy a TARTALMAZZA-E függvény esetében is.
A kétargumentumú TOROL függvény az UJ-REMOVE függvényhez hasonlóan az első argumentum valamennyi előfordulását törli a második argumentumként megadott listáról. A különbség az, hogy a TOROL függvény a lista minden szintjén törli az adott kifejezést. A függvény első argumentuma tehát tetszőleges S-kifejezés, a második lista lehet. A TOROL függvény szerkezetében nagyon hasonló a TARTALMAZZA-E függvényhez, a feltételek ugyanis azonosak, csak a hozzájuk tartozó tevékenységeket kell megváltoztatnunk. A definíció:
(DEFUN TOROL (SK LIS)
(COND ((NULL LIS) NIL) ;Nincs mit törölni
((EQUAL SK (CAR LIS)) ;A lista feje törlendő:
(TOROL SK (CDR LIS))) ; a farkából is elhagyjuk
((ATOM (CAR LIS)) ;A lista feje atom: csak
(CONS (CAR LIS) ; a farkából kell törölni
(TOROL SK (CDR LIS))))
(T (CONS (TOROL SK (CAR LIS)) ;Alkalmazzuk a
(TOROL SK (CDR LIS] ; fej-farok rekurziót.* (TOROL 'MOHA '(ZUZMO (MOHA PAFRANY) MOHA))
(ZUZMO (PAFRANY))* (TOROL '(DE VISZONT)
'(AMBAR (DE (VISZONT) (DE VISZONT)) HACSAK (NEM DE VISZONT) (MEGIS (DE VISZONT))))
(AMBAR (DE (VISZONT)) HACSAK (NEM DE VISZONT) (MEGIS))
Alapvető fontosságú az a függvény, amely egy S-kifejezést a lista minden szintjén egy másik S-kifejezéssel helyettesít. A SUBST függvény háromargumentumú: az első argumentum az új S-kifejezés, a második a régi, helyettesítendő kifejezés, a harmadik pedig a lista, amelyben a helyettesítést elvégezzük. A függvény nemcsak feltételeiben, hanem a tevékenységeiben is hasonlít a TOROL függvényhez, ugyanis a második argumentumtól különböző elemeket a függvény értékének most is tartalmaznia kell. A függvény:
(DEFUN UJ-SUBST (UJ REGI LIS)
(COND ((NULL LIS) NIL) ;Nincs mit cserélni
((EQUAL REGI (CAR LIS)) ;A lista feje cserélendő:
(CONS UJ ; cserélünk a
(UJ-SUBST UJ REGI (CDR LIS)))) ; farkában is
((ATOM (CAR LIS))
(CONS (CAR LIS) ;Változatlanul hagyjuk de
(UJ-SUBST UJ REGI (CDR LIS))))) ; a farkát vizsgáljuk
(T (CONS (UJ-SUBST UJ REGI (CAR LIS)) ;Következik
(UJ-SUBST UJ REGI (CDR LIS] ; a fej-farok rekurzió
A definíció váza csak a második feltétel tevékenységében tér el a TOROL definíciójától. Ha a lista feje a keresett elem, az új elemet a CONS függvénnyel hozzákapcsoljuk a rekurzív lépésben adódó (UJ-SUBST UJ REGI (CDR LIS)) forma értékéhez, erre a TOROL függvénynél nem volt szükség.
Példánkban a (PLUS A B) kifejezést helyettesítjük minden szinten az (EXPT A X) kifejezéssel:
* (UJ-SUBST '(EXPT A X) '(PLUS A B)
'(TIMES (ADD1 (PLUS A B)) (SUB1 A) (PLUS A B)))
(TIMES (ADD1 (EXPT A X)) (SUB1 A) (EXPT A X))
Következő példánkban pedig egy kifejezésben az X elemet a (SUB1 X) kifejezéssel helyettesítjük:
* (UJ-SUBST '(SUB1 X) 'X '(ADD1 (EXPT A X)))
(ADD1 (EXPT A (SUB1 X)))
Érdekes megfigyelni, hogy a minden szintet kezelő függvények a kiértékelés során milyen utat járnak be az argumentumként megadott listához tartozó fán. Vegyük alapul a listák bináris fával való ábrázolását, amelyet a 2.4. szakaszban vezettünk be. Az UJ-IRON függvény esetében pl. a fej-farok rekurzió során mindig az (UJ-IRON (CAR S)) forma értékelődik ki először, vagyis a fa egy csúcspontjából mindig a bal oldali élen indulunk tovább. Ha ez nem lehetséges - mert a csúcspont levél - akkor értékelődik ki az (UJ-IRON (CDR S)) forma, ekkor haladunk tovább az előző pontból jobbra induló élen. A fa bejárása során tehát felülről lefelé haladva mindig a balról első, még bejáratlan ágon indulunk el mindaddig, amíg van ilyen ág. Ha a függvény definícióját úgy módosítanánk, hogy a rekurzív lépésnél
(APPEND (UJ-IRON (CDR S))
(UJ-IRON (CAR S)))
forma szerepeljen, akkor éppen a fordított sorrendben járnánk végig a fa pontjait, és az atomok eredeti sorrendje is megváltozna.
4.5. Általánosabb halmazkezelő függvények
A 4.3. szakaszban bevezettük a halmazok és listák közötti megfeleltetést, nem vizsgáltunk azonban olyan halmazokat, amelyeknek az elemei között is lehetnek halmazok. Terjesszük ki most a megfeleltetést ilyen halmazokra is! A következő rekurzív algoritmust használjuk:
A halmaznak megfeleltetett lista tehát allistát is tartalmazhat. A
{növény, {rigó, cinke, veréb}, {emlős, {ponty, csuka}}}
halmaznak a
(NOVENY (RIGO CINKE VEREB) (EMLOS (PONTY CSUKA)))
lista felel meg. Az üres halmaznak továbbra is a NIL felel meg, így az egyelemű {0} halmaznak a (NIL) egyelemű lista felel meg. A megfeleltetés kiterjesztésével általánosíthatjuk a 4.3. szakaszban bevezetett halmazkezelő függvényeket: bevezetjük a minden szintet kezelő megfelelőiket.
A MEMBER és a REMOVE függvény, mint láttuk, halmazok kezelésére is használható (4.3. szakasz). Azt gondolhatnánk, hogy a halmazelemet is tartalmazó halmazok kezelésére használhatjuk a minden szintet kezelő változataikat. A TARTALMAZZA-E és a TOROL függvény azonban nem alkalmas ilyen halmazok kezelésére.
* (TARTALMAZZA-E '(1 2 3) '(SZAM (1 3 2) (BETU EKEZET)))
NIL
A függvény értéke NIL, bár a megadott {szám, {1, 3, 2}, {betű, ékezet}}
halmaznak az {1,2,3} halmaz eleme, hiszen az elemek felsorolásának rendje nem számít. A TARTALMAZZA-E és a TOROL függvény ennek figyelembevételére nem képes, de a MEMBER és a REMOVE függvény sem. A függvények definícióit végignézve láthatjuk, hogy mi ennek az oka. Ezek a függvények ugyanis az EQUAL beépített függvény alkalmazásával hasonlítják össze a listákat; ez az összehasonlítás az (1 2 3) és az (1 3 2) listákat természetesen különbözőnek mutatja.
Olyan predikátumra van tehát szükségünk, amely képes eldönteni két halmazról, hogy azonosak-e. Próbáljuk meg a 4.3. szakaszban bevezetett AZONOSAK-E függvény segítségével:
* (AZONOSAK-E '(SZAM (1 2 3) (BETU EKEZET)) '(SZAM (1 3 2) (BETU EKEZET)))
NIL
Ez a függvény sem a várt eredményt adja, ugyanis csak akkor képes kimu?tatni két halmaz azonosságát, ha azok csak elemeik sorrendjében különböz?nek. Mivel ez a függvény is csak a legfelső szintet kezeli, ez sem ismeri fel két halmaz azonosságát akkor, ha azoknak olyan eleme is van, amely maga is halmaz, és ennek elemeit más sorrendben adjuk meg. Vezessük be ezért az AZONOSAK-E függvény minden szintet kezelő változatát, a HALMAZ-EQ predikátumot! Ez a függvény bonyolultabb lesz, mint az eddig tárgyaltak, mert az elemek különböző sorrendjével megadott azonos halmazokat tetszőleges mélységben fel kell ismernie.
A HALMAZ-EQ függvény kétargumentumú, mindkét argumentum csak lista lehet. Legyenek a függvény változói H1 és H2! A H1 halmaz első eleméről megvizsgáljuk, hogy eleme-e a H2 halmaznak. Ha nem eleme, akkor készen vagyunk, a két halmaz nem azonos, a függvény értéke NIL. Ha eleme, akkor ezt az elemet töröljük a H2 halmazból, majd az így kapott halmazra és a (CDR H1) halmazra alkalmazzuk rekurzív módon a HALMAZ-EQ függvényt.
Tekintsük először a legegyszerűbb esetet! Ha mindkét halmaz üres, a függvény értéke T. Ha csak az egyik halmaz üres, a függvény értéke NIL. A következő egyszerűbb eset az, ha a H1 halmaz első eleme atom. Ekkor az algoritmusnak megfelelően a H1 és a H2 halmazok megegyeznek, ha a H1 feje eleme H2-nek, és ha ezt az atomot mindkét halmazból elhagyva a kapott halmazok megegyeznek.
Ha H1 első eleme halmaz, akkor el kell döntenünk, hogy van-e ugyanilyen halmazeleme a H2 halmaznak is. Erre most nem használhatjuk a MEMBER függvényt, mert lehet, hogy a H2 halmaz ugyan tartalmazza ezt a halmazt, de az elemek sorrendje a halmazon belül más. Tegyük fel, hogy van egy kétargumentumú segédfüggvényünk - legyen a neve HALMAZ-PARJA -, amely eldönti, hogy az első argumentumnak van-e megfelelője a második argumentumként megadott listában, vagyis olyan eleme, amely halmazként megegyezik az első argumentummal. Ha van, a függvény értéke a második argumentum ezen eleme, ha nincs, értéke NIL. A HALMAZ-EQ függvény definíciója a HALMAZ-PÁRJA függvény segítségével:
(DEFUN HALMAZ-EQ (H1 H2)
(COND ((NULL H1) (NULL H2)) ;Két üres halmaz azonos
((NULL H2) NIL) ;Ha csak H2 üres, NIL
((ATOM (CAR H1)) ;Ha H1 feje atom, akkor
(AND (MEMBER (CAR H1) H2) ; ha ez H2-nek eleme,
(HALMAZ-EQ (CDR H1) ; rekurzívan vizsgáljuk
(REMOVE (CAR H1) H2)) ; a többit is
(T (AND (HALMAZ-PARJA (CAR H1) H2) ;Ha H1 feje halmaz és
(HALMAZ-EQ (CDR H1) ; van neki megfelelő
(REMOVE ; halmaz H2-ben, tovább
(HALMAZ-PARJA (CAR H1) H2) H2]; keresünk.
A definícióban felhasznált HALMAZ-PARJA függvényt a már definiált HALMAZ-EQ segítségével könnyen felírhatjuk:
(DEFUN HALMAZ-PARJA (CSOMAG RAKTAR)
(COND ((NULL RAKTAR) NIL)
((HALMAZ-EQ CSOMAG ;Ha a RAKTAR első eleme a
(CAR RAKTAR)) ; CSOMAG-gal azonos halmaz,
(CAR RAKTAR)) ; ez lesz a függvény értéke.
(T (HALMAZ-PARJA CSOMAG ;Ha nem, akkor rekurzívan
(CDR RAKTAR] ;tovább keresünk.* (HALMAZ-EQ '((ABC) (A B) C)
'((B A) C (C A B)))
T* (HALMAZ-PARJA '(A (B C)) '((A B) C ((C B) A)))
((C B) A)
A HALMAZ-PARJA függvény definíciójában kihasználtuk, hogy mindkét argumentuma lista. Ha pl. az első argumentuma atom volna, a HALMAZ-EQ függvény első argumentuma is atom volna; ez viszont hibához vezetne, hiszen a CAR függvényt atomra alkalmaznánk.
A fenti függvények definíciójában egy újdonságot is megfigyelhetünk. A HALMAZ-EQ függvényben felhasználtuk a HALMAZ-PARJA függvényt, ugyanakkor az utóbbiban már használtuk a HALMAZ-EQ függvényt.
A HALMAZ-EQ függvény rekurzív módon hivatkozik önmagára, de mivel a HALMAZ-PARJA függvényt is felhasználja - ez pedig a HALMAZ-EQ-t - a definíció közvetett rekurziót is tartalmaz. Ha két vagy több egymásra kölcsönösen hivatkozó függvényt definiálunk, ügyelnünk kell arra, hogy a kiértékelés so?rán ne keletkezzen végtelen rekurzió. Az előbbi példából jól látható, hogy a rekurzív függvényalkalmazások során egyre egyszerűbb esetekhez jutottunk.
Ugyanakkor azt is láthatjuk, hogy a HALMAZ-PARJA függvényt minden alkalommal kétszer alkalmazzuk ugyanarra az argumentumra. A második (felesleges) kiértékelést úgy kerülhetjük el, hogy első alkalommal a kiértékelés eredményét egy PARJA nevű segédváltozóban megőrizzük, és második alkalommal ennek a változónak az értékére alkalmazzuk a függvényt. (Ugyanígy tettünk a 4.1. szakaszban, az UJ-REVERSE1 függvény bevezetésénél.)
(DEFUN HALMAZ-EQ (H1 H2) (HALMAZ-EQ1 H1 H2 NIL))
(DEFUN HALMAZ-EQ1 (H1 H2 PARJA)
(COND ((NULL H1) (NULL H2))
((NULL H2) NIL)
((ATOM (CAR H1))
(AND (MEMBER (CAR H1) H2)
(HALMAZ-EQ1 (CDR H1)
(REMOVE (CAR H1) H2))))
(T (AND (SETQ PARJA
(HALMAZ-PARJA (CAR H1) H2))
(HALMAZ-EQ1 (CDR H1)
(REMOVE PARJA H2]
A bevezetett függvények mellett szükségünk van egy olyan függvényre, amely egy elemről eldönti, hogy tartalmazza-e a halmaz. Ha az elem maga is halmaz, használhatjuk a HALMAZ-PARJA függvényt, ha az elem nem halmaz, akkor ez a függvény nem alkalmazható, mert argumentuma csak lista lehet. Definiáljuk ezért a HALMAZ-ELEME függvényt, amely atomi elemeket is képes vizsgálni! A függvény első argumentuma tetszőleges S-kifejezés lehet, második argumentuma azonban csak lista lehet. A függvény értéke T vagy NIL, attól függően, hogy a halmaz (lista) tartalmazza-e az elemet vagy sem.
(DEFUN HALMAZ-ELEME (E H)
(COND ((NULL H) NIL) ;Üres halmaznak nem eleme
((ATOM E) (ELEME E H)) ;Ha atom, az ELEME vizsgál
(T (AND (HALMAZ-PARJA E H) T] ;Ha az E halmaz: rekurzió* (HALMAZ-ELEME 'GEPARD '((TIGRIS OROSZLAN) GEPARD (MACSKA)))
T
A HALMAZ-ELEME alapján most már elkészíthetjük a minden szintet kezelő halmazegyesítő, ill. halmazmetszetet készítő függvényeket. A UNION és az INTERSECTION függvények nem alkalmasak erre, mert a halmaznak azokat az elemeit, amelyek maguk is halmazok, ezek a függvények csak akkor tekintik azonos halmazoknak, ha elemeiknek sorrendje is azonos.
Az új halmaz-egyesítő és metszetképező EGYESIT, ill. METSZET függvények definíciója az UJ-UNION, ill. az UJ-INTERSECTION függvények definíciójához hasonlóan írható fel, a különbség annyi, hogy a vizsgálatnál a MEMBER függvény helyett a HALMAZ-ELEME függvényt alkalmazzuk.
(DEFUN EGYESIT (H1 H2)
(COND ((NULL H1) H2) ;Ha H1 üres, az eredmény H2.
((HALMAZ-ELEME (CAR H1) H2) ;Ha H1 feje eleme H2-nek,
(EGYESIT (CDR H1) H2)) ; akkor H1-ből elhagyjuk
(T (CONS (CAR H1) ;Ha nem eleme, nem hagyjuk el
(EGYESIT (CDR H1) H2]
A METSZET függvény definíciója pedig:
(DEFUN METSZET (H1 H2)
(COND ((NULL H1) NIL) ;Ha H1 üres, a metszet is az
((HALMAZ-ELEME (CAR H1) H2);Ha H1 feje eleme H2-nek,
(CONS (CAR H1) ; akkor a metszetnek is.
(METSZET (CDR H1) H2)))
(T (METSZET (CDR H1) H2] ;Egyébként a metszetből elhagyjuk
A LISP programozásban gyakran használunk halmazkezelő függvényeket. Alkalmazásuk egyszerűsíti a függvények definícióját, ha olyan feladatot oldunk meg, amelynél a listában tárolt adatok sorrendje a feladat megoldása szempontjából lényegtelen.
4.6. Listákat rendező függvények
Definiáljunk olyan függvényt, amely egy atomokból álló lista elemeit betűrendbe rakja. A következő rendezési eljárást választjuk:
Az atomok (elemek) összehasonlításához az ALPHORDER beépített predikátumot használjuk. Ez kétargumentumú függvény, argumentumai atomok lehetnek, értéke T, ha az első argumentum betűrendben megelőzi a második argumentumot - vagy a két argumentum azonos -, egyébként NIL. Ha az atom nemcsak betűket tartalmaz, hanem számjegyet, vagy mínuszjelet is, a kisebb számjegy megelőzi a nagyobbat, a számjegyek megelőzik a betűket, a mínuszjel pedig minden más karaktert megelőz. IS-LISP-ben ALPHORDER helyett ORDERP függvényt használhatunk, de ez ponbt fordítva működik: akkor ad T értéket, ha az első argumentum nagyobb.
* (ALPHORDER 'BALATON 'ALIGA)
NIL*(ORDERP 'BALATON 'ALIGA)
T
Ha a rendezés fenti algoritmusát használjuk, látszik, hogy a feladat két jól elkülönülő részre osztható, ezért a RENDEZ-A rendezőfüggvény definíciójában a beszúrást a BESZUR-A segédfüggvénnyel valósítjuk meg. A függvények definíciója:
(DEFUN RENDEZ-A (SZAVAK)
(COND ((NULL SZAVAK) NIL)
((NULL (CDR SZAVAK)) SZAVAK)
(T (BESZUR-A (CAR SZAVAK) (RENDEZ-A (CDR SZAVAK](DEFUN BESZUR-A (SZO SOR) ;A SOR már rendezett lista!
(COND ((NULL SOR) (LIST SZO)) ;A legegyszerűbb eset
((ALPHORDER SZO (CAR SOR)) ;Ha a SZÓ megelőzi az első
(CONS SZO SOR)) ; elemet, ez lesz az első
(T (CONS (CAR SOR) ;Egyébként a lista farkába
(BESZUR-A SZO (CDR SOR] ; kell beszúrni
Ha a rendezendő elemek között listák is lehetnek, egy másik predikátumra van szükségünk. Az ALPHORDER ugyanis csak atomot tud atommal összehasonlítani, ekkor azonban atomot listával vagy listát listával is össze kell hasonlítani. A leggyakrabban használatos összehasonlító elv a következő:
Az ((ELSO) SOKADIK) és a (MASODIK (SOKADIK)) listák közül a (MASODIK (SOKADIK)) áll előbb; listákról lévén szó, a 3. szabály szerint a két lista fejének, azaz a MASODIK, ill. (ELSO) S-kifejezéseknek az összehasonlítása dönt, a 2. szabály szerint pedig a MASODIK atom előbb áll, mint az (ELSO) lista.
Definiáljunk a fenti rendező elv szerint összehasonlító predikátumot, a MEGELOZI-E függvényt, amely kétargumentumú, és az argumentumai S- kifejezések lehetnek:
(DEFUN MEGELOZI-E (S1 S2)
(COND ((AND (ATOM S1) (ATOM S2)) ;Ha mindkettő atom,
(ALPHORDER SI S2)) ; az ALPHORDER dönt.
((ATOM S1) T) ;Az atom előzi a listát
((ATOM S2) NIL) ;Csak az egyik atom
((EQUAL (CAR S1) (CAR S2)) ;Mindkettő lista,
(MEGELOZI-E (CDR SI) (CDR S2))) ; a farkuk dönt.
(T (MEGELOZI-E (CAR S1) (CAR S2] A listák feje nem azonos.* (MEGELOZI-E '((EZ (EGY)) (LISTA)) '(EZ (IS) LISTA))
NIL
* (MEGELOZI-E '((EZ (EGY)) (LISTA)) '((EZ (EGY)) (MASIK) LISTA))
T
A RENDEZ-M függvény olyan listák rendezésére is alkalmas, amelyeknek elemei maguk is lehetnek listák. A függvény a BESZUR-M segédfüggvényt használja. A BESZUR-M definíciója előállítható úgy, hogy a BESZUR-A függvény definíciójában a MEGELOZI-E predikátumra cseréljük az ALPHORDER függvényt.
(DEFUN RENDEZ-M (SZAVAK)
(COND ((NULL SZAVAK) NIL)
((NULL (CDR SZAVAK)) SZAVAK)
(T (BESZUR-M (CAR SZAVAK) (RENDEZ-M (CDR SZAVAK](DEFUN BESZUR-M (SZO SOR)
(COND ((NULL SOR) (LIST SZO))
((MEGELOZI-E SZO (CAR SOR)) (CONS SZO SOR))
(T (CONS (CAR SOR) (BESZUR-M SZO (CDR SOR]* (BESZUR-M '(PARDUC TIGRIS)
'(GEPARD HIUZ LEOPARD (MACSKA OROSZLAN) (PUMA VADMACSKA)))
(GEPARD HIUZ LEOPARD (MACSKA OROSZLAN)
(PARDUC TIGRIS) (PUMA VADMACSKA))* (RENDEZ-M '((OROSZLAN TIGRIS) PARDUC
((LEOPARD) VADMACSKA) GEPARD))
(GEPARD PARDUC (OROSZLAN TIGRIS) ((LEOPARD) VADMACSKA))
Definiáljunk olyan függvényt, amely minden szinten rendezi az elemeket! Pl. a
((MEDVE (FARKAS ROKA)) (LAJHAR TATU HANGYASZ)
(EMBER (GORILLA CSIMPANZ ORANGUTAN)))
listából az
((EMBER (CSIMPANZ GORILLA ORANGUTAN)) (HANGYASZ LAJHAR TATU)
(MEDVE (FARKAS ROKA)))
listát készíti el.
A minden szinten rendező függvény definíciója a BESZUR-M függvény segítségével:
(DEFUN MINDENT-RENDEZ (LISTA)
(COND ((NULL LISTA) NIL)
((ATOM (CAR LISTA)) ;Ha a lista feje atom,
(BESZUR-M (CAR LISTA) ; ezt beszúrjuk a
(MINDENT-RENDEZ (CDR LISTA)))) ; listafarokba,
(T (BESZUR-M ;Ha nem atom: a
(MINDENT-RENDEZ (CAR LISTA)) ; rendezett fejet
; beszúrjuk a rendezett farokba
(MINDENT-RENDEZ (CDR LISTA]
Az e pontban tárgyalt algoritmuson kívül még sok rendezési eljárás ismeretes. A 8. feladatban egy, a beszúrásos algoritmusnál hatékonyabb eljárást is leírunk.
1. feladat
Definiáljunk olyan függvényeket, amelyek nem üres listák elemeit körkörösen eltolják!
a) A LTOLASE függvény a lista első elemét a lista végére teszi, a többi elemet pedig eggyel előrébb, pl : az (E L T O L A S) listából (LTOLASE) listát készít.
b) A SELTOLA függvény a lista utolsó elemét a lista elejére teszi, a többit pedig eggyel hátrább: az (E L T O L A S) listából (SELTOLA) listát készít.
(DEFUN LTOLASE (LISTA)
(APPEND (CDR LISTA) (LIST (CAR LISTA](DEFUN SELTOLA (LISTA)
(REVERSE (LTOLASE (REVERSE LISTA]
2. feladat
Definiáljuk a halmazelméleti kivonásnak megfelelő HALMAZ-KIVONAS függvényt! Az A\B halmaz elemei mindazok, amelyek A-nak elemei, de nem elemei B-nek.
(DEFUN HALMAZ-KIVONAS (HAL1 HAL2)
(COND ((NULL HAL2) HAL1)
(T (HALMAZ-KIVONAS (REMOVE (CAR HAL2) HAL1)
(CDR HAL2]
3. feladat
Definiáljuk a SZIM-KUL függvényt a halmazelméleti szimmetrikus különbség kiszámítására. A A és b különbség halmazhoz azok az elemek tartoznak, amelyek vagy csak az A-nak elemei, de B-nek nem, vagy pedig csak B-nek, de A-nak nem.
A feladatra két megoldást adunk:
(DE SZIM-KUL (HAL1 HAL2)
(HALMAZ-KIVONAS (METSZET HAL1 HAL2)
(EGYESIT HAL1 HAL2](DE SZIM-KUL1 (HAL1 HAL2)
(EGYESIT (HALMAZ-KIVONAS HAL1 HAL2)
(HALMAZ-KIVONAS HAL2 HAL1]
4. feladat
Egy halmaz összes részhalmazából álló halmazt az illető halmaz hatványhalmazának nevezzük. Pl. az {ALFA, BETA, GAMMA} halmaz hatványhalmaza az
{{}, {ALFA}, {BETA}, {GAMMA},
{ALFA, BETA}, {ALFA, GAMMA}, {BETA, GAMMA},
{ALFA, BETA, GAMMA}}
halmaz. Definiáljuk a HATVANYHALMAZ függvényt, amely előállítja egy halmaz hatvány halmazát!
(DEFUN HATVANYHALMAZ (HAL)
(COND ((NULL HAL) (LIST NIL))
(T (APPEND (HOZZATESZ (CAR HAL) (HATVANYHALMAZ (CDR HAL)))
(HATVANYHALMAZ (CDR HAL](DEFUN HOZZATESZ (E H)
(COND ((NULL H) NIL)
(T (CONS (CONS E (CAR H))
(HOZZATESZ E (CDR H]
Hatékonyabbá tehetjük a függvényt, ha még egy segédfüggvényt definiálunk, és egy változóban megőrizzük a függvény értékét:
(DEFUN HATVANYHALMAZ (HAL) (HATVANYHALMAZ1 HAL NIL))
(DEFUN HATVANYHALMAZ1 (HAL RHAT)
(COND ((NULL HAL) (LIST NIL))
(T (SETQ RHAT (HATVANYHALMAZ (CDR HAL)))
(APPEND (HOZZATESZ (CAR HAL) RHAT) RHAT]
5. feladat
Definiáljuk a PERMUTAL egyargumentumú függvényt! Ennek argumentuma egy nem üres lista, amely halmaznak feleltethető meg. A függvény előállítja a halmaz elemeinek összes permutációját, azaz az elemek összes lehetséges sorrendjét. Az így kapott listákat egy listába fűzve értékként megadja.
* (PERMUTAL '(ITT VAN EGY))
((ITT VAN EGY) (ITT EGY VAN) (VAN ITT EGY)
(VAN EGY ITT) (EGY ITT VAN) (EGY VAN ITT))
Alkalmazzuk az előző feladat megoldásában definiált HOZZÁTESZ függvényt:
(DEFUN PERMUTAL (LISTA) (PERMUTAL1 LISTA LISTA NIL))
(DEFUN PERMUTAL1 (ELSOK ELEMEK MUNKA)
(COND ((NULL (CDR ELEMEK)) (LIST ELEMEK))
((NULL ELSOK) NIL)
(T (SETQ MUNKA (REMOVE (CAR ELSOK) ELEMEK))
(APPEND (HOZZATESZ (CAR ELSOK) (PERMUTAL MUNKA))
(PERMUTAL1 (CDR ELSOK) ELEMEK NIL]
6. feladat
Ha két olyan listát, amelynek elemei között listák is vannak, minden szinten betűrendbe rendezünk, akkor az EQUAL segítségével is eldönthető, hogy mint halmazok azonosak-e. Ezt felhasználva definiáljuk az UJABB-HALMAZ-EQ függvényt!
Alkalmazzuk a 4.6. szakaszban definiált MINDENT-RENDEZ függvényt:
(DEFUN UJABB-HALMAZ-EQ (H1 H2)
(EQUAL (MINDENT-RENDEZ H1) (MINDENT-RENDEZ H2)))
7. feladat
Definiáljuk a MEGELOZI-E2 függvényt úgy, hogy atom- és listaargumentum esetén ne feltétlenül az atom előzze meg a listát, hanem az atom ill. a lista első atomjának betűrendi helye döntsön.
* (MEGELOZI-E2 'ELSO '((MASODIK) HARMADIK))
T* (MEGELÖZI-E2 'MASODIK '((ELSO) HARMADIK))
NIL(DEFUN MEGELOZI-E2 (E1 E2)
(COND ((AND (ATOM E1) (ATOM E2))
(ALPHORDER E1 E2))
((ATOM E1) (MEGELOZI-E2 E1 (CAR E2)))
((ATOM E2) (MEGELOZI-E2 (CAR E1) E2))
(T (MEGELOZI-E2 (CAR E1) (CAR E2]
8. feladat
Definiáljuk a RENDEZ2 rendezőfüggvényt, amely egy nem üres lista elemeit betűrend szerint rendezi! Az algoritmus legyen a következő: párosítsuk a rendezendő elemeket, és válasszuk ki minden párból az ALPHORDER predikátum szerint előbb állót. Ha a lista páratlan elemű, akkor az utolsó - pár nélkül álló - elemet is kiválasztjuk. Az így kiválasztott elemeket ismét osszuk párokba, és ismételjük meg az eljárást addig, amíg csak egyetlen elemünk marad. Ez az elem lesz a rendezett lista első eleme, ezt töröljük a rendezendők listájából. A leírt eljárás alapján válasszuk ki a következő olyan elemet, amely megelőzi az összes többit és így tovább.
(DEFUN RENDEZ2 (ELEMEK)
(COND ((NULL (CDR ELEMEK)) ELEMEK)
(T (CONS (CAR (ELSO-ELEM ELEMEK))
(RENDEZ2
(ELMOZDIT
(CAR (ELSO-ELEM ELEMEK)) ELEMEK]
A felhasznált segédfüggvények:
(DEFUN ELMOZDIT (ELEM LISTA)
(COND ((NULL LISTA) NIL)
((EQUAL ELEM (CAR LISTA)) (CDR LISTA))
(T (CONS (CAR LISTA)
(ELMOZDIT ELEM (CDR LISTA](DEFUN ELSO-ELEM (ELEMEK)
(COND ((NULL (CDR ELEMEK)) ELEMEK)
(T (ELSO-ELEM (OSSZEHASONLIT ELEMEK](DEFUN OSSZEHASONLIT (ELEMEK)
(COND ((NULL (CDR ELEMEK)) ELEMEK)
((ALPHORDER (CAR ELEMEK) (CADR ELEMEK))
(CONS (CAR ELEMEK) (OSSZEHASONLIT (CDDR ELEMEK))))
(T (CONS (CADR ELEMEK) (OSSZEHASONLIT (CDDR ELEMEK]
5. Tulajdonságlisták, lambdakifejezések, függvény típusok
5.1. Szimbólumok tulajdonságai
Az előző fejezetben több olyan feladatot oldottunk meg, amelyeket úgy jellemezhetünk, hogy egy szimbólumhoz tartozó tulajdonságokat kell kezelnünk, ezekhez kell hozzáférnünk. A bridzskártyához kapcsolódó példában a lap erejének kiszámításakor egy kártya tulajdonságának a pontértékét tekinthetjük, az országok szomszédainak előállításakor egy ország tulajdonságának azt nevezhetjük, hogy mely országok a szomszédai. Ezeket a feladatokat eddigi eszközeinkkel csak nehézkesen tudtuk megoldani. A LISP-ben azonban létezik egy olyan apparátus, amelynek segítségével a hasonló feladatokat egyszerűbben, természetesebben oldhatjuk meg: szimbólumokhoz tulajdonságokat rendelhetünk, így keletkeznek az ún. tulajdonságlisták.
Rendeljük hozzá pl. az egyes kártyalapoknak megfelelő szimbólumokhoz a PONTERTEK tulajdonságot! Erre a PUT függvény szolgál:
(PUT 'A 'PONTERTEK 4)
A PUT függvény az A szimbólumhoz hozzárendeli a PONTERTEK tulajdonságot. A tulajdonság attribútuma a PONTERTEK szimbólum, a tulajdonság értéke pedig a 4 szám. Néha a rövidség kedvéért egyszerűen a tulajdonság értékét nevezzük tulajdonságnak. Másképpen tehát úgy is mondhatjuk, hogy az A szimbólumhoz hozzárendeltünk egy attribútum-tulajdonság párt, amely a PONTERTEK attribútumból és a hozzá tartozó tulajdonságból, a 4 számból áll. Egy szimbólumhoz több attribútum-tulajdonság pár is tartozhat, ezeket a LISP rendszer a szimbólum tulajdonságlistáján tárolja.
A tulajdonságlistán mindegyik attribútumhoz egyetlen tulajdonság tartozhat. Az attribútum mindig szimbolikus atom, a hozzá tartozó tulajdonság tetszőleges S-kifejezés lehet.
A PUT függvény tehát egy szimbólum tulajdonságlistáján elhelyez egy attribútum-tulajdonság párt. A függvénynek három argumentuma van, amelyek kiértékelődnek. Az első argumentum értéke az a szimbólum, amelyhez az attribútum-tulajdonság párt hozzárendeljük, a második argumentumé az attribútum, a harmadik argumentumé pedig tetszőleges S-kifejezés lehet, ez lesz a tulajdonság értéke. A PUT függvény értéke a harmadik argumentum értéke lesz, vagyis az a tulajdonság, amelyet a megadott névvel hozzárendeltünk a szimbólumhoz, esetünkben a 4 szám.
Hasonlóképpen rendelhetjük hozzá a többi kártyának megfelelő szimbólumhoz is a PONTÉRTÉK attribútumhoz tartozó tulajdonságértékeket:
* (PUT 'K 'PONTERTEK 3)
3* (PUT 'D 'PONTERTEK 2)
2* (PUT 'B 'PONTERTEK 1)
1
A többi kártyára vonatkozólag pedig
* (PUT 'TIZES 'PONTERTEK 0)
0...
* (PUT 'KETTES 'PONTERTEK 0)
0
Egy szimbólum tulajdonságlistáján lévő adott attribútumhoz tartozó tulajdonság értékét a GETP (IS-LISP-ben GET) függvénnyel kaphatjuk meg. A függvénynek két argumentuma van, mindkettőnek az értéke szimbólum: az első argumentum az az atom, amelynek egy tulajdonságát keressük, a második argumentum pedig az attribútum. A függvény értéke az az érték, amely a szimbólum tulajdonságlistáján az attribútumhoz tartozik. Ha pl. az A szimbólumra és a PONTERTEK attribútumra alkalmazzuk a GETP függvényt, akkor
* (GETP 'A 'PONTERTEK)
4
vagy
* (GET 'A 'PONTERTEK)
4
A GETP függvény nem predikátum, bár neve P betűre végződik.
Ha az egyes kártyáknak megfelelő szimbólumok pontértékét a fentiek szerint a szimbólum tulajdonságlistáján helyezzük el, a játékos laperejének kiszámítására a tulajdonságokat kezelő függvények segítségével a LAPERO2 függvényt definiálhatjuk:
(DEFUN LAPERO2 (L)
(COND ((NULL L) 0)
(T (PLUS (GET (CADAR L) 'PONTERTEK)
(LAPERO2 (CDR L]
A függvény az L listán sorra veszi a párokat, és az egyes kártyáknak megfelelő szimbólumokhoz megkeresi a pontértéket - a PONTERTEK attribútumhoz tartozó tulajdonságot -, a függvény értéke a tulajdonságok értékének összege. Ha a játékos kezében lévő tizenhárom kártyát továbbra is az ESZAK változó értéke, a 4.1. szakaszban definiált lista írja le:
* (LAPERO2 ESZAK)
19
Egy szimbólum tulajdonságlistáján egy attribútumhoz csak egyetlen ér?ték tartozhat, ezért lehet a GETP függvénnyel az attribútum alapján megtalálni a tulajdonságot. Ha a PUT függvénnyel a szimbólum adott attribútumához egy másik tulajdonságértéket rendelünk, akkor a tulajdonság előző értéke elvész.
A bridzsjáték egy másik "iskolája" a kártyákat másként értékeli, itt az ász 7, a király 5, a dáma 3, a bubi továbbra is 1 pontot ér. Térjünk át most erre a számítási módra! Ekkor
* (PUT 'A 'PONTERTEK 7)
7* (PUT 'K 'PONTERTEK 5)
5* (PUT 'D 'PONTERTEK 3)
3
A többi kártyához tartozó pontérték változatlan. Ha ezután ismét alkalmazzuk a LAPERO2 függvényt az ESZAK kártyára, akkor
* (LAPERO2 ESZAK)
31
Vegyük észre, hogy a LAPERO2 függvény definícióját nem kellett megváltoztatnunk!
Leírhatjuk a játékos lapját is tulajdonságlistával, ha az ESZAK szimbólumhoz négy attribútum-tulajdonság párt rendelünk. Az egyes színeket jelző attribútumokhoz tartozik az azonos színű kártyák listája:
* (PUT 'ESZAK 'PIKK '(A D TIZES NYOLCAS HATOS))
(A D TIZES NYOLCAS HATOS)* (PUT 'ESZAK 'KOR '(B HETES))
(B HETES)* (PUT 'ESZAK 'KARO '(K D OTOS))
(K D OTOS)* (PUT 'ESZAK 'TREFF '(A K KILENCES))
(A K KILENCES)
Ha így ábrázoljuk az adatokat, a laperőt a LAPERÖ3 függvénnyel számíthatjuk ki, ezt így definiálhatjuk:
(DEFUN LAPERO3 (L)
(COND ((NULL L) 0)
(T (EVAL (CONS 'PLUS
(PONTLISTA ;A négy színhez tartozó
(APPEND ; pontértékek összege
(APPEND (GET L 'PIKK)
(GETP L 'KOR))
(APPEND (GET L 'KARO)
(GETP L 'TREFF]
A függvényben egyetlen listába fűzzük a négy színhez tartozó kártyáknak megfelelő szimbólumokat. Mivel az APPEND-nek csak két argumentuma van, a négy lista összefűzéséhez az APPEND-et ismételten kell alkalmaznunk. A PONTLISTA segédfüggvény a lapban szereplő kártyák pontértékének listáját állítja elő, erre a listára alkalmazzuk a PLUS függvényt. A PONTLISTA függvény definíciója:
(DEFUN PONTLISTA (L)
(COND ((NULL L) '(0))
(T (CONS (GETP (CAR L) 'PONTERTEK)
(PONTLISTA (CDR L]
Vegyük észre a LAPERO2 és a LAPERO3 függvény alkalmazása közötti különbséget! A LAPERO2 függvényt az ESZAK szimbólum értékére alkalmazzuk, ez az érték a lapot leíró lista. A LAPERO3 függvényt viszont az ESZAK szimbólumra alkalmazzuk, nem pedig annak értékére; mivel ebben az esetben a játékos lapját az ESZAK szimbólum tulajdonságlistája írja le.
Ugyancsak leírhatjuk attribútum-tulajdonság párokkal Európa országainak szomszédsági kapcsolatait. Legyen az EUROPA szimbólum értéke egy lista, amely az európai országok nevét jelentő szimbólumokból áll! Ekkor
* (SETQ EUROPA
'(P E F B L NL D DK CH I A H CS
DDR PL SU SF N S RO YU AL GR TR BG))
(P E F B L NL D DK CH I A H CS DDR PL SU SF N S RO YU AL GR TR BG)
Az egyes országok tulajdonságlistáján a SZOMSZEDOK attribútumhoz rendeljük hozzá a szomszédos országok neveit tartalmazó listát, értékeljük ki a következő S-kifejezéseket:
(PUT 'P 'SZOMSZEDOK '(E))
(PUT 'E 'SZOMSZEDOK '(P F))
(PUT 'F 'SZOMSZEDOK '(B L D CH I E))
(PUT 'B 'SZOMSZEDOK '(NL D L F))
(PUT 'L 'SZOMSZEDOK '(F B D))
(PUT 'NL 'SZOMSZEDOK '(B D))
(PUT 'D 'SZOMSZEDOK '(NL DK DDR CS A CH F L B))
(PUT 'DK 'SZOMSZEDOK '(D))
(PUT 'CH 'SZOMSZEDOK '(F D I A))
(PUT 'I 'SZOMSZEDOK '(F CH A YU))
(PUT 'A 'SZOMSZEDOK '(CH D CS H YU I))
(PUT 'H 'SZOMSZEDOK '(A CS SU RO YU))
(PUT 'CS 'SZOMSZEDOK '(D DDR PL SU H A))
(PUT 'DDR 'SZOMSZEDOK '(D PL CS))
(PUT 'PL 'SZOMSZEDOK '(DDR SU CS))
(PUT 'SU 'SZOMSZEDOK '(RO H CS PL SF N))
(PUT 'SF 'SZOMSZEDOK '(S N SU))
(PUT 'N 'SZOMSZEDOK '(S SU SF))
(PUT 'S 'SZOMSZEDOK '(N SF))
(PUT 'RO 'SZOMSZEDOK '(BG YU H SU))
(PUT 'YU 'SZOMSZEDOK '(AL I A H RO BG GR))
(PUT 'AL 'SZOMSZEDOK '(GR YU))
(PUT 'GR 'SZOMSZEDOK '(AL YU BG TR))
(PUT 'TR 'SZOMSZEDOK '(GR BG))
(PUT 'BG 'SZOMSZEDOK '(GR YU RO TR))
Ezek után egyszerűen definiálhatjuk a SZOMSZEDAI2 függvényt, amely az adatok ilyen ábrázolása mellett szolgáltatja egy ország szomszédait:
(DEFUN SZOMSZEDAI2 (ORSZAG)
(GET ORSZAG 'SZOMSZEDOK))* (SZOMSZEDAI2 'A)
(CH D CS H YU I)
Tulajdonságlistákkal leírhatjuk a családi kapcsolatokat is. A magyar történelemben fontos szerepet játszott a Hunyadi család: Hunyadi János apja Both bajnok volt, felesége Szilágyi Erzsébet, ennek fivére Szilágyi Mihály. Hunyadi Jánosnak és Szilágyi Erzsébetnek két fia volt, Hunyadi Mátyás - a király - és Hunyadi László. A családi kapcsolatokat így írhatjuk le attribútum-tulajdonság párokkal:
(PUT 'HUNYADI-JANOS 'APJA 'BOTH-BAJNOK)
(PUT 'HUNYADI-JANOS 'FELESEGE 'SZILAGYI-ERZSEBET)
(PUT 'SZILAGYI-ERZSEBET 'FERJE 'HUNYADI-JANOS)
(PUT 'HUNYADI-MATYAS 'APJA 'HUNYADI-JANOS)
(PUT 'HUNYADI-LASZLO 'APJA 'HUNYADI-JANOS)
(PUT 'HUNYADI-MATYAS 'ANYJA 'SZILAGYI-ERZSEBET)
(PUT 'HUNYADI-LASZLO 'ANYJA 'SZILAGYI-ERZSEBET)
Mivel egy embernek több fivére is lehet, ezért a FIVERE attribútumhoz nem egy nevet rendelünk tulajdonságként, hanem egy személynevekből álló listát. (Ez természetesen lehet egyelemű vagy üres lista is.)
(PUT 'HUNYADI-MATYAS 'FIVERE '(HUNYADI-LASZLO))
(PUT 'SZILAGYI-ERZSEBET 'FIVERE '(SZILAGYI-MIHALY))
Definiáljuk a SZULEI függvényt! Ennek értéke egy lista, amely egy személy apjának és anyjának nevét tartalmazza: a függvény a személy tulajdonságlistájáról előveszi az APJA és az ANYJA attribútumokhoz tartozó tulajdonságok értékét, és egy listán elhelyezi őket:
(DEFUN SZULEI (NEV)
(COND ((NULL (GETP NEV 'APJA))
(COND ((NULL (GETP NEV 'ANYJA)) NIL)
(T (LIST (GETP NEV 'ANYJA)))))
((NULL (GET NEV 'ANYJA)) (LIST (GET NEV 'APJA)))
(T (LIST (GET NEV 'APJA) (GET NEV 'ANYJA]* (SZULEI 'HUNYADI-MATYAS)
(HUNYADI-JANOS SZILAGYI-ERZSEBET)* (SZULEI 'HUNYADI-JANOS)
(BOTH-BAJNOK)* (SZULEI 'SZILAGYI-ERZSEBET)
NIL
Valamivel rövidebben írhatjuk le a SZULEI függvény definícióját, ha az apa és az anya nevét az APJA, ill. ANYJA segédfüggvényekkel állítjuk elő:
(DEFUN APJA (NEV)
(GET NEV 'APJA))(DEFUN ANYJA (NEV)
(GET NEV 'ANYJA))(DEFUN SZULEI (NEV)
(COND ((NULL (APJA NEV)) ;Ha nem ismert az apa:
(COND ((NULL (ANYJA NEV)) NIL) ; az anya sem ismert;
(T (LIST (ANYJA NEV))))) ; csak az anya ismert
((NULL (ANYJA NEV)) (LIST (APJA NEV))) ;Csak az apa ismert
(T (LIST (APJA NEV) (ANYJA NEV] ;A szülök ismertek
Definiáljuk ezek után az ANYA-GYERMEKEI függvényt! Ez a gyermeket jelentő szimbólum tulajdonságlistáján megkeresi az ANYJA attribútumhoz tartozó személynevet, és ennek a névnek a tulajdonságlistáján az eredeti szimbólumot a GYERMEKEI attribútumhoz kapcsolja úgy, hogy a GYERMEKEI attribútumhoz tartozó érték egy lista lesz. Tehát, ha az anya nevének tulajdonságlistáján a GYERMEKEI attribútumhoz még nem tartozik érték, akkor a gyermek nevét egyelemű listaként kapcsoljuk az attribútumhoz; ha pedig a GYERMEKEI attribútumhoz már egy nem üres lista tartozik, amely az új nevet még nem tartalmazza, akkor erre a listára felfűzzük az új nevet:
(DEFUN ANYA-GYERMEKEI (NEV)
(COND ((NULL (ANYJA NEV)) NIL) ;Ha nem ismert az anya
((MEMBER NEV (GET (ANYJA NEV) ;Ha a NÉV szerepel
'GYERMEKEI)) ; a gyermekek között,
(GET (ANYJA NEV) 'GYERMEKEI)) ; nincs változás.
(T (PUT (ANYJA NEV) 'GYERMEKEI ;Ha nem szerepel, a
(CONS NEV (GET (ANYJA NEV) ; gyermekek listájához
'GYERMEKEI] ; hozzáfűzzük.
Ha az ANYA-GYERMEKEI függvényt a HUNYADI-MATYAS szimbólumra alkalmazzuk, a függvény a SZILAGYI-ERZSEBET szimbólum tulajdonságlistáján elhelyezi a GYERMEKEI attribútumot és a hozzá tartozó (HUNYADI-MATYAS) tulajdonságot. Ha pedig ezután a függvényt a HUNYADI-LASZLO argumentumra alkalmazzuk, a függvény a GYERMEKEI attribútumhoz a (HUNYADI-LASZLO HUNYADI-MATYAS) listát rendeli:
* (ANYA-GYERMEKEI 'HUNYADI-MATYAS)
(HUNYADI-MATYAS)* (GET 'SZILAGYI-ERZSEBET 'GYERMEKEI)
(HUNYADI-MATYAS)* (ANYA-GYERMEKEI 'HUNYADI-LASZLO)
(HUNYADI-LASZLO HUNYADI-MATYAS)* (GET 'SZILAGYI-ERZSEBET 'GYERMEKEI)
(HUNYADI-LASZLO HUNYADI-MATYAS)
A legtöbb LISP változatban megtalálhatjuk az ADDPROP függvényt, ennek segítségével egy szimbólum tulajdonságlistáján lévő értékhez, ha az egy
lista, további elemeket csatolhatunk. Az ADDPROP függvénynek három argumentuma van, az első a szimbólum, amelynek tulajdonságlistáját megváltoztatjuk. A második argumentum az attribútum, az ehhez tartozó tulajdonságnak listának kell lennie (ez természetesen lehet az üres lista is). A harmadik argumentum tetszőleges S-kifejezés, ezt a kifejezést a függvény a szimbólum tulajdonságlistáján a megadott attribútumhoz tartozó tulajdonsághoz csatolja. A tulajdonságnak listának kell lennie, ennek a listának a végéhez csatolja a függvény az adott S-kifejezést mint listaelemet.
Az ADDPROP függvény segítségével az ANYA-GYERMEKEI definícióját egyszerűbbé tehetjük:
(DE ANYA-GYERMEKEI (NEV)
(COND ((NULL NEV) NIL)
((NULL (ANYJA NEV)) NIL)
((MEMBER NEV (GETP (ANYJA NEV) 'GYERMEKEI))
(GETP (ANYJA NEV) 'GYERMEKEI))
(T (ADDPROP (ANYJA NEV) 'GYERMEKEI NEV>
Vegyük észre, hogy az ANYA-GYERMEKEI függvény újabb változatának alkalmazása kissé más eredményt ad, mint az előző változaté; a gyermekek nevét most fordított sorrendben kaptuk, mivel az ADDPROP függvény az új értéket a tulajdonságlista végéhez csatolja.
Vezessük be a NAGYBATYJA függvényt, amely egy személy nagybátyjainak, azaz anyja és apja fivéreinek nevét fűzi egy listába. Felhasználjuk a SZULEI, az APJA és az ANYJA függvényeket:
(DEFUN NAGYBATYJA (NEV)
(COND ((NULL (SZULEI NEV)) NIL) ;A szülök ismeretlenek
(T (APPEND (GET (ANYJA NEV) 'FIVERE) ;Az anya fivérei
(GET (APJA NEV) 'FIVERE] ;Az apa fivérei* (NAGYBATYJA 'HUNYADI-MATYAS)
(SZILAGYI-MIHALY)* (NAGYBATYJA 'HUNYADI-LASZLO)
(SZILAGYI-MIHALY)
Egy szimbólumhoz tartozó attribútumot és a hozzá tartozó tulajdonságot a REMPROP függvénnyel törölhetjük a tulajdonságlistáról. A függvény első argumentuma a szimbólum, amelynek tulajdonságlistájáról töröljük a tulajdonságot, második argumentuma az attribútum. A függvény törli a szimbólum tulajdonságlistájáról a megfelelő párt, ha a tulajdonságlista tartalmazta az attribútumot. A függvény értéke az attribútum, ha ez szerepelt a tulajdonságlistán, egyébként pedig NIL.
* (REMPROP 'HUNYADI-MATYAS 'FIVERE)
FIVÉRE* (REMPROP 'HUNYADI-MATYAS 'NOVERE)
NIL
Ezután
* (GET 'HUNYADI-MATYAS 'FIVERE)
NIL
a HUNYADI-MATYAS szimbólum tulajdonságlistája nem tartalmazza a FIVERE attribútumot.
A DEFLIST függvény egyszerre több szimbólumhoz rendel hozzá olyan attribútum-tulajdonság párokat, amelyekben ugyanaz az attribútum szerepel:
* (DEFLIST '((A 4) (K 3) (D 2) (B 1) (TIZES 0) (KILENCES 0)
(NYOLCAS 0) (HETES 0) (HATOS 0) (OTOS 0) (NEGYES 0) (HARMAS 0) (KETTES 0))
'PONTERTEK)
(A K D B TIZES KILENCES NYOLCAS HETES HATOS OTOS NEGYES HARMAS KETTES)
A függvény első argumentuma egy kételemű listákból álló lista. Az egyes allisták első eleme az a szimbólum, amelyhez a tulajdonságot hozzárendeljük, a második eleme pedig a tulajdonság értéke. A DEFLIST második argumentuma az az attribútum, amelyhez a tulajdonságok tartoznak. A függvény értéke az első argumentumok szimbólumaiból álló lista. Példánkban a DEFLIST függvény az A atomhoz a PONTERTEK attribútumból és a 4 tulajdonságból álló párt rendeli hozzá, a K atomhoz a PONTERTEK attribútumból és a 3 tulajdonságból álló párt, és így tovább. A DEFLIST függvénynek az értéke pedig az (A K D B ... HARMAS KETTES) lista.
Hasonlóképpen Európa országaihoz a SZOMSZEDOK attribútumhoz tartozó tulajdonságokat a következőképpen rendelhetjük hozzá:
* (DEFLIST '((P (E))
(E (P F))
(F (B L D CH I E))
(B (NL D L F))
(L (F B D))
(NL (B D))
(D (NL DK DDR CS A CH F L B))
(DK (D))
(CH (F D I A))
(I (F CH A YU))
(A (CH D CS H YU I))
(H (A CS SU RO YU))
(CS (D DDR PL SU H A))
(DDR (D PL CS))
(PL (DDR SU CS))
(SU (RO H CS PL SF N))
(SF (S N SU))
(N (S SU SF))
(S (N SF))
(RO (BG YU H SU))
(YU (AL I A H RO BG GR))
(AL (GR YU))
(GR (AL YU BG TR))
(TR (GR BG))
(BG (GR YU RO TR)))
'SZOMSZEDOK)(P E F B L NL D DK CH I A H CS DDR PL SU SF N S RO YU AL GR TR BG)
Megnehezítheti a megértést, hogy az érték szót a LISP-ben több különböző fogalom jelölésére használjuk: az eddigiekben beszéltünk egy változó értékéről, azaz a változóhoz hozzárendelt értékről; egy kifejezés értékéről, ami a kifejezés kiértékelésének eredményét jelenti, és végül most egy szimbólum tulajdonságának értékéről. A szövegösszefüggésből azonban mindig ki fog derülni, hogy az érték szót melyik értelemben használjuk.
5.2. A lambdakifejezések
A könyvben eddig már sok függvényt definiáltunk. Ha ezeket a definíciókat begépeljük a terminálon, tetszőlegesen használhatjuk is ezeket a függvényeket, mert az értelmező a definíciókat megjegyzi.
Egy függvény definiálásakor a definíció a függvénynév szimbólum tulajdonságlistájára kerül, mégpedig az FNCELL nevű attribútumhoz tartozó tulajdonságként. (A különböző LISP változatokban más és más szimbólumot használnak az FNCELL helyett. Az FNCELL az angol function cell kifejezésből származik.) A definíció ún. lambda kifejezés formájában tárolódik. Nézzük pl. a 4.5. szakaszban definiált HALMAZ-ELEME függvényt!
* (GET 'HALMAZ-ELEME 'FNCELL)
(LAMBDA (E H)
(COND ((NULL H) NIL) ((ATOM E) (ELEME E H))
(T (AND (HALMAZ-PARJA E H) T))))
A HALMAZ-ELEME szimbólumnak az FNCELL attribútumhoz tartozó tulajdonsága egy lambdakifejezés, amely a HALMAZ-ELEME függvény definícióját írja le.
A lambdakifejezés általános alakja a következő:
(LAMBDA változólista törzs)
A kifejezés első eleme a LAMBDA szimbólum, utána következik a lambdaváltozók listája, majd a törzset képező egy vagy több S-kifejezés. A lambdakifejezésnél - úgyanúgy, mint a DEFUN esetében - a változólista csak szimbólumokat tartalmazhat, és ezek között nem lehet különleges atom. A függvény törzse tetszőleges számú S-kifejezésből állhat. A lambdakifejezés formája abban különbözik a függvények definiálására szolgáló formától, hogy a DEFUN szimbólum helyén LAMBDA áll, és hiányzik a függvény neve. A változólista és a függvénytörzs azonban teljesen azonos. Ha a DEFUN segítségével egy függvényt definiálunk, akkor mellékhatásként az értelmezőprogram a függvénynévnek az FNCELL attribútumhoz tartozó tulajdonságaként lambdakifejezés formájában elhelyezi a definíciót. A függvény alkalmazásakor az értelmezőprogram a lambdakifejezést alkalmazza az argumentumokra.
A lambdakifejezés elnevezésnek történelmi okai vannak. Az 1940-es években Alonzo Church definiálta a függvényeket a lambda szimbólum segítségével. Használatával különböztetjük meg a függvény változóit azoktól a szimbólumoktól, amelyekre a függvényt alkalmazzuk. A LISP-beli lambdakifejezés tökéletesen megfeleltethető ennek a jelölési módnak. McCarthy és tanítványai a LISP kidolgozásánál a lambda-kalkulusra építettek.
Lambdakifejezést közvetlenül is alkalmazhatunk argumentumokra úgy, hogy a függvény neve helyett használjuk. Az 1.5. szakaszban azt mondtuk, hogy egy forma feje - két kivételtől eltekintve - csak függvénynév lehet. Az egyik kivétel a lambdakifejezés. Ennek alkalmazásakor a forma alakja a következő:
(lambdakifejezés argumentum1 argumentum2 ...)
azaz
((LAMBDA változólista törzs) argumentum1 argumentum2 ...)
Alkalmazzuk a HALMAZ-ELEME függvény definíciójának megfelelő lambdakifejezést pl. az (A B) és az (A (B A) C) argumentumokra:
(<LAMBDA (E H)
(COND ((NULL H) NIL)
((ATOM E) (ELEME E H))
(T (AND (HALMAZ-PARJA E H) T>'(A B)
'(A (B A) C))
T
Így tehát névtelen függvényeket is alkalmazhatunk argumentumokra:
* (<LAMBDA (L) ;értéke egy lista első és
(LIST (CAR L) (CAR (REVERSE L> ; utolsó eleméből álló lista
'(ELSO MASODIK HARMADIK UTOLSO)) ;Az argumentum.
(ELSO UTOLSO)
Egy lambdakifejezés törzse további lambdakifejezéseket is tartalmazhat:
* (<LAMBDA (X Y) ;X első és Y utolsó eleméből
(REVERSE ; álló kételemű lista megfordítva
(<LAMBDA (L) ;A "belső" kifejezés egyezik
(LIST (CAR L) (CAR (REVERSE L>; az előző példabelivel.
(APPEND X Y> ;A "belső" kif. argumentuma'(A B C) ;A "külső" kif. argumentumai
'(X Y Z))
(Z A)
Ha lambdakifejezést közvetlenül alkalmazunk argumentumokra, minden egyes alkalmazásnál le kell írnunk az egész lambdakifejezést, nem hivatkozhatunk egy szimbólumra - névre - úgy, mint a DE / DEFUN segítségével definiált függvényeknél. Ebből az is következik, hogy nem írhatunk rekurzív lambdakifejezést, hiszen nincs neve, amelyre a lambdakifejezés törzsében rekurzívan hivatkozhatnánk.
Fel kell hívnunk a figyelmet arra, hogy a LAMBDA nem függvény. A LAMBDA szimbólum - a lambdakifejezés első eleme - azt jelzi az értelmezőprogramnak, hogy itt egy függvény megadása következik. Ezért hibához vezet, ha a forma első eleme maga a LAMBDA szimbólum, nem pedig lambdakifejezés.
A függvénydefiníciók lambdakifejezésként való tárolása lehetővé teszi, hogy a korábban definiált függvények definícióját elolvashassuk, és azokat akár módosítsuk is. A GETP és PUT függvények használatával ezt megtehetjük, ha az FNCELL attribútumra hivatkozunk. Van azonban egyszerűbb megoldás is, a függvénydefiníciók kezelésére szolgál a GETD és PUTD függvény. A GETD egyetlen argumentuma egy szimbólum - függvénynév lehet, és értéke az ehhez a függvénynévhez tartozó definíció:
* (GETD 'ELEME)
(LAMBDA (ELEM LISTA)
(COND ((NULL LISTA) NIL)
((EQUAL ELEM (CAR LISTA)) T)
(T (ELEME ELEM (CDR LISTA)))))
A PUTD kétargumentumú: első argumentuma a definiálandó függvény neve (szimbólum), a második pedig a függvény definíciója (lambdakifejezés). A függvény értéke a második argumentumának értéke, mellékhatásaként a függvénydefiníció tárolódik. A SEMMIT-TESZ függvényt a PUTD segítségével így definiálhatjuk:
* (PUTD 'SEMMIT-TESZ '(LAMBDA () ()))
(LAMBDA NIL NIL)
Módosítsuk ezek segítségével az ELEME függvény definícióját, cseréljük ki mindenütt a függvénydefinícióban a LISTA változót L-re! Ekkor
(PUTD 'ELEME
(SUBST 'LISTA 'L (GETD 'ELEME)))
(LAMBDA (ELEM L)
(COND ((NULL L) NIL)
((EQUAL ELEM (CAR L)) T) (T (ELEME ELEM (CDR L)))))
A GETD alkalmazásával megkaphatjuk a beépített függvények definícióit is:
* (GETD 'ABS)
(LAMBDA (X) (COND ((MINUSP X) (MINUS X)) (T X)))
A legalapvetőbb beépített függvények definícióját azonban nem kaphatjuk meg a GETD alkalmazásával: ezek ugyanis le vannak fordítva a gép számára közvetlenül érthető nyelvre. Azokat a függvényeket, amelyek nem rendelkeznek lambdakifejezés alakjában tárolt definícióval, lefordított függvénynek nevezzük. A lefordított függvényeknek nincs az FNCELL attribútumhoz tartozó tulajdonsága:
* (GETP 'CONS 'FNCELL)
NIL
Ha pedig a lefordított függvényre a GETD-t alkalmazzuk, akkor pl. a következő értéket kaphatjuk:
* (GETD 'CONS)
(SUBR 1724)
Itt a SUBR (az angol subroutine szó rövidítése) arra utal, hogy a CONS lefordított függvény, az ezt követő szám pedig a számítógép tárának az a címe, ahol a CONS függvénynek megfelelő szubrutin kezdődik. Mivel az ilyen függvények definíciója nem lambdakifejezésként tárolódik, lambdaváltozóik sincsenek. Alkalmazásukkor az argumentumok értékei mint paraméterek adódnak át egy gépi kódú szubrutinnak. (Erről a 11. fejezetben még lesz szó.)
Az előbbi kifejezések kiértékeléséből azt is láthatjuk, hogy a GETD függvény nemcsak egyszerűen egy szimbólumnak az FNCELL attribútumhoz tartozó tulajdonságát adja meg, hiszen abban az esetben, ha a függvény lefordított függvény, az FNCELL attribútumhoz nem tartozik tulajdonság. Hasonlóan a PUTD alkalmazásának hatása sem teljesen azonos a
(PUT függvénynév 'FNCELL lambdakifejezés)
alakú kifejezés kiértékelésének hatásával, mert a PUTD - és a DE - használata esetén az értelmezőprogram a függvénynévről azt is feljegyzi, hogy ehhez a szimbólumhoz egy függvény definíciója tartozik. Ha csak a PUT függvényt használjuk, akkor ez nem történik meg. Definiáljuk pl. a MAS-PUTD függvényt, amely a PUT függvényt alkalmazza:
* (DE MAS-PUTD (FN DEF)
(PUT FN 'FNCELL DEF))
MAS-PUTD
A függvény első argumentuma a definiálandó függvény neve, a második pedig a függvény definíciója lambdakifejezés alakjában. Ha egy függvényt a PUTD-vel újradefiniálunk, akkor redefined figyelmeztető üzenetet kapunk.
A MAS-PUTD használatakor viszont nem kapunk ilyen figyelmeztetést. A MAS-PUTD ugyan elhelyezi a függvénydefiníciót a szimbólum tulajdonságlistáján, a LISP rendszer azonban nyilvántartásában nem jegyzi fel, hogy ehhez a szimbólumhoz egy függvénydefiníció tartozik. Ezért nem figyelmeztet arra, ha egy már létező definíciót felülírunk:
* (MAS-PUTD 'SEMMIT-TESZ '(LAMBDA (X Y) Y))
(LAMBDA (X Y) Y)
Az egyes LISP értelmezőprogramok jelentősen eltérnek egymástól abban, hogy milyen beépített függvényeket tartalmaznak, és abban is, hogy ezek közül melyek lefordított függvények. Az elemi függvények, a CAR, a CDR, a CONS, az ATOM, a NULL és az EQ azonban minden LISP rendszerben lefordított függvények.
5.3. A függvények típusai
A LISP nyelv függvényeit két fontos rendszerező elv alapján négy csoportba oszthatjuk.
Az első elv az argumentumok számához kapcsolódik. A LISP függvényeit ez alapján rögzített argumentumszámú és akárhány-argumentumú függvényekre osztjuk. Használtunk már 1-, 2-, 3- stb.-argumentumú függvényeket, a DE / DEFUN segítségével eddigi ismereteink alapján mi is tudunk olyan függvényeket definiálni, amelyeknek meghatározott számú argumentuma van.
A korábbi fejezetekben láttunk már példát akárhány-argumentumú függvényekre is, amelyeket változó számú argumentummal használhatunk. Ilyen függvények pl. a PLUS, a TIMES és az AND. Ezek azonban mind beépített függvények, eddigi ismereteink alapján nem tudunk akárhány-argumentumú függvényeket definiálni.
A függvényeket csoportosíthatjuk aszerint is, hogy a függvény alkalmazásakor az argumentum, ill. argumentumok kiértékelődnek-e. A 2.1. szakaszban már bevezettük az eval- és a nem eval-típusú függvények fogalmát. Azokat a függvényeket, amelyeknek alkalmazásakor az argumentumok kiértékelődnek, és a függvény ezekre az értékekre alkalmazódik, eval-típusú függvényeknek neveztük. Ilyen a megismert függvények nagy része. Ismerünk olyan függvényeket is, amelyek alkalmazásakor a függvény argumentumai nem értékelődnek ki, a függvényt az argumentumokra, nem pedig azok értékére alkalmazzuk. Ezek a függvények tehát nem eval-típusú függvények. Fontos megjegyzés, hogy eval-típusúnak csak akkor nevezünk egy függvényt, ha minden argumentuma kiértékelődik. Ha van legalább egy argumentuma, amely nem értékelődik ki, akkor a függvény nem eval-típusú.
A LISP-ben léteznek olyan függvények is, amelyek akárhány-argumentumúak és egyszersmind nem eval-típusúak is, ilyen pl. a DE, a TRACE, az AND és az OR.
A fejezet hátralevő részében azt mutatjuk be, hogyan definiálhatunk akárhány-argumentumú, ill. nem eval-típusú függvényeket.
5.3.1. Akárhány-argumentumú függvények definiálása
A 4.5. szakaszban definiáltuk a METSZET függvényt, amely két halmaz metszetét állítja elő. Tegyük fel, hogy az N-METSZET függvényt akarjuk definiálni, amellyel tetszőleges számú halmaz metszetét tudjuk előállítani. Bár az eddig megismert definiálási eszközökkel nem tudunk akárhány-argumentumú függvényt definiálni, olyan függvényt mégis definiálhatunk, amely akárhány halmaz metszetét képezi. Mivel nem tudjuk, hogy a függvénynek hány halmaz metszetét kell képeznie, úgy definiáljuk, hogy argumentumai nem az egyes halmazok lesznek, hanem egyetlen argumentuma lesz, a halmazokból álló lista. Feltesszük, hogy legalább egy vagy egynél több halmaz metszetét képezzük, tehát az argumentumlistának legalább egy eleme van. A definíció:
(DEFUN N-METSZET (HALMAZLISTA)
(COND ((NULL (CDR HALMAZLISTA)) ;Ha egyetlen halmaz van,
(CAR HALMAZLISTA)) ; az érték ez a halmaz.
(T (METSZET ;Egyébként az első
(CAR HALMAZLISTA) ; halmaz metszetét
(N-METSZET ; képezzük az összes többi
(CDR HALMAZLISTA] ; halmaz metszetével.
Az N-METSZET függvény nem akárhány-argumentumú ugyan, segítségével mégis tetszőleges számú halmaz metszetét képezhetjük. Ennek a megoldásinak az a hátránya, hogy a függvény alkalmazása előtt az egyes halmazokból egy listát kell alkotnunk a CONS vagy a LIST segítségével.
* (N-METSZET '((EZ EGY HALMAZ)))
(EZ EGY HALMAZ)* (N-METSZET
(LIST '(EZ EGY HALMAZ) '(EZ EGY MASIK HALMAZ)
'(EZ IS HALMAZ) '(MAR EZ IS HALMAZ)))
(EZ HALMAZ)
A LISP nyelvben azonban nemcsak a 3.1. szakaszban leírt módon definiálhatunk függvényeket, hanem arra is van lehetőség, hogy akárhány-argumentumú függvényeket definiáljunk.
Ha egy akárhány-argumentumú függvényt definiálunk, nem sorolhatjuk fel a változókat egy változólistán, mert egy-egy alkalmazáskor más és más
számú argumentuma lesz a függvénynek. Ehelyett a definícióban megállapodás szerint egyetlen szimbólumot kell írnunk a változólista helyére, ennek a szimbólumnak az értéke a függvény alkalmazásakor az argumentumok értékeiből álló lista lesz. A függvénydefiníció egyébként formailag megegyezik a korábban bemutatottakkal.
Így definiálhatjuk pl. az AKARHANY-METSZET függvényt, amelynek tetszőleges számú argumentumai halmazok, és a függvény értéke a halmazok metszete:
(DEFUN AKARHANY-METSZET HALMAZOK
(N-METSZET HALMAZOK))
A függvény törzse egyetlen S-kifejezés, amely az előbb bevezetett N-METSZET függvényt alkalmazza a HALMAZOK változó értékére. A függvény törzsében a HALMAZOK szimbólumot úgy használhatjuk, mint a rögzített argumentumszámú függvények esetében a lambdaváltozókat.
* (AKARHANY-METSZET '(A B C) '(A C D) '(B C A D) '(D C B A))
(A C)
Példánkban a kiértékeléskor a HALMAZOK változó értéke a következő lista:
((A B C) (A C D) (B C A D) (D C B A))
Az akárhány-argumentumú függvények sajátossága, hogy definíciójuk nem lehet rekurzív. Pontosabban: a könyvben eddig használt definiálási módszerekkel nem lehet rekurzívan akárhány-argumentumú függvényt definiálni. Az 5.3.3. pontban, az UJ-AND definiálásakor látunk majd példát arra, hogyan lehet az EVAL függvény segítségével mégis rekurzív definíciót adni.
Vizsgáljuk meg ezt egy példán: definiáljuk a SOK-APPEND akárhány-argumentumú függvényt, amelynek tetszőleges számú lista lehet az argumentuma! A SOK-APPEND függvény az APPEND-hez hasonlóan a listákat egyetlen listába fűzi, és ez a lista lesz a függvény értéke. Ha megpróbálnánk rekurzívan definiálni ezt az akárhány-argumentumú függvényt, a következőt írhatnánk fel:
(DEFUN SOK-APPEND LISTAK ;Hibás!
(COND ((NULL LISTAK) NIL)
(T (APPEND (CAR LISTAK)
(SOK-APPEND (CDR LISTÁK] ;Itt a hiba!
Emlékeztetünk arra, hogy a 3.4.1 pontban bevezetett általánosított feltételes kifejezésben megengedtük, hogy egy feltételt több tevékenység is kövessen, pl.
(COND ((GREATERP N 0) (SETQ K 0) (SETQ L 1) N)
((ZEROP N))
(T (MINUS N)))
Ha nem általánosítottuk volna a feltételes kifejezéseket, azaz ha egy feltételt csak egy tevékenység követhetne, akkor az első feltétel után a PROGN függvényt kellene használnunk:
(COND ((GREATERP N 0) (PROGN (SETQ K 0) (SETQ L 1) N))
... )
Az általánosított feltételes kifejezéssel tehát "megtakaríthatjuk" a PROGN használatát. Ezért azt mondjuk, hogy az általánosított feltételes kifejezésben implicit progn szerkezetet használhatunk.
Az akárhány-argumentumú függvények definíciója is lambdakifejezés alakjában tárolódik. Ezekben a lambdakifejezésekben a LAMBDA után - ugyanúgy, mint a DEFUN esetében a függvény neve után - a változólista helyén egy szimbólum áll, amelynek értéke a függvény kiértékelésekor az argumentumok értékeiből álló lista lesz.
Az ilyen lambdakifejezések segítségével "névtelen" akárhány-argumentumú függvényeket is használhatunk. Az N-APPEND függvényt akárhány-argumentumú lambdakifejezésben is alkalmazhatjuk:
(LAMBDA LISTA (N-APPEND LISTA))
'(A PELDAK HASZNOSABBAK)
'((MINT))
'(A SZABALYOK (QUOTE NEWTON)))
(A PELDAK HASZNOSABBAK (MINT) A SZABALYOK (QUOTE NEWTON))
5.3.2. Nem eval-típusú függvények definiálása
A LISP függvények nagy része eval-típusú függvény. Ott azonban, ahol az argumentumokat (általában) nem kell kiértékelni, célszerűbb nem eval-típusú függvényeket definiálni. Nem eval-típusú függvények definiálására a DF függvényt használjuk. (IS-LISP-ben nincs implementálva!) A DF használata a DE használatával minden szempontból megegyezik, de a segítségével definiált függvény nem eval- típusú függvény lesz.
Definiáljuk a METSZETQQ nem eval-típusú függvényt, amely (mint a METSZET függvény) a megadott két halmaz metszetét képezi, de argumentumai nem értékelődnek ki:
(DF METSZETQQ (H1 H2)
(METSZET H1 H2))
A DF függvény is akárhány-argumentumú, és mint a DE függvénynek, legalább három argumentumra szüksége van: az első a definiálandó függvény neve, a második a változólista, a továbbiak alkotják a függvény törzsét. A METSZETQQ függvénnyel tehát előállíthatjuk ezen halmazok metszetét, anélkül, hogy a QUOTE-ot kellene használnunk.
A DF segítségével azonban nem készíthetünk rekurzív függvénydefiníciókat. Pontosabban: a könyvben eddig használt definiálási módszerekkel nem lehet rekurzívan nem eval-típusú függvényt definiálni. Az 5.3.3. pontban, az
UJ-AND definiálásakor látunk majd példát arra, hogyan lehet az EVAL függvény segítségével mégis rekurzív definíciót adni.
Próbáljunk meg a DF segítségével rekurzív módon definiálni egy nem eval-típusú függvényt, amely - mint a 4.1. szakaszban definiált UTOLSO-ELEM - az argumentumként megadott lista utolsó elemét adja. Látni fogjuk, hogy a rekurzív definíció hibára vezet, ezért a függvény neve legyen ROSSZ-UTOLSO:
(DF ROSSZ-UTOLSO (X) ;Hibás!
(COND ((NULL X) NIL)
((ATOM X) X)
((NULL (CDR X)) (CAR X))
(T (ROSSZ-UTOLSO (CDR X> ;Itt a hiba!
A kiértékelés során az X változó értéke először az (ELSO MASODIK HARMADIK) lista lett, az első két feltétel nem teljesült, így a ROSSZ-UTOLSÓ függvényt rekurzív módon a (CDR X) argumentumra alkalmazzuk. A függvény azonban nem eval-típusú függvény, argumentuma nem értékelődik ki, így az X változó új értéke nem a (CDR X) forma értéke - a (MASODIK HARMADIK) lista -, hanem maga a (CDR X) kifejezés lett. A megállási feltételek így sohasem teljesülnek, ezért mindig újra és újra alkalmazzuk a függvényt.
A nem eval-típusú függvényeket - az akárhány-argumentumú függvényekhez hasonlóan - általában úgy definiálhatjuk, hogy segédfüggvényként eval-típusú függvényt használunk. Az akárhány-argumentumú függvényeknél általában szükség volt rekurzióra, a nem eval-típusú függvényekre azonban ez nem igaz. Definiálhatjuk pl. az UJ-SETQ nem eval-típusú függvényt, amely - mint a SETQ - egy szimbólumnak értéket ad:
(DF UJ-SETQ (NEV ERTEK)
(SET NEV (EVAL ERTEK)))
A függvényt a DF segítségével definiáltuk, alkalmazásakor két változójának értéke a két argumentum, nem pedig azok értéke lesz. Mivel a függvény második argumentumának az értékére van szükségünk, erre alkalmazzuk az EVAL függvényt, és az így kapott értéket rendeljük az első argumentumként megadott szimbólumhoz.
Az iménti definíció alapján tehát olyan függvényeket is tudunk definiálni, amelyeknél az argumentumok egy részénél azok értékére, más részüknél magára az argumentumra van szükség. Ezeket a "vegyes" függvényeket mindig a DF-fel definiáljuk, és a megfelelő argumentumokat az EVAL függvénnyel kiértékeljük.
A DF segítségével definiált függvények nlambdakifejezés alakjában tárolódnak. Az nlambdakifejezés csak abban különbözik a lambdakifejezéstől, hogy a LAMBDA szimbólum helyett NLAMBDA szerepel benne. Az NLAMBDA szimbólum jelzi az értelmezőnek, hogy a függvény nem eval-típusú.
Az nlambdakifejezéssel alkalmazhatunk "névtelen" nem eval-típusú függvényeket argumentumokra. A következő kifejezés értéke az argumentumként megadott függvény definíciójában szereplő atomok listája. A könnyebb olvashatóság kedvéért erre a listára nem vesszük fel a NIL atomot (amely szinte minden esetben szerepel), és a függvénydefinícióban - nem lefordított függvények esetén - kötelezően szereplő LAMBDA, ill. NLAMBDA szimbólumokat. Ha azonban a függvény definíciójának törzsében használunk LAMBDA ill. NLAMBDA szimbólumot, akkor ez is felkerül a listára.
* (<NLAMBDA (FV) (HALMAZOSIT (UJ-IRON (CDR (GETD FV>
ROSSZ-UTOLSO)
(COND ATOM NULL CAR T ROSSZ-UTOLSO CDR X)
5.3.3. Akárhány-argumentumú, nem eval-típusú függvények definiálása
Mindkét jellemzővel rendelkező függvények pl. a DE, az AND és az OR. Az ilyen típusú függvények definiálására is a DF függvényt használjuk, a változólista helyett pedig - ahogy az akárhány-argumentumúaknál láttuk - itt is egyetlen szimbólum áll.
A tetszőlegesen sok halmaz metszetét előállító, akárhány-argumentumú, nem eval-típusú METSZET-NQ függvényt így definiálhatjuk:
(DF METSZET-NQ HALMAZOK (N-METSZET HALMAZOK))
Az AND és az OR függvények alkalmazásukkor nem értékelik ki feltétle?nül mindegyik argumentumukat, hanem balról jobbra haladva sorban csak addig, amíg a függvény értéke meghatározódik. Definiáljuk az UJ-AND függvényt! Ez nem eval-típusú, akárhány-argumentumú függvény lesz, azonban - mint láttuk - definíciójában rekurziót kell használnunk. Ennek érdekében definiálhatnánk egy eval-típusú, egyargumentumú segédfüggvényt, ehelyett azonban egy új definiálási módszerrel oldjuk meg a feladatot:
(DF UJ-AND ARGK
(COND ((NULL ARGK) T) ;Ha nincs argumentum
((NULL (EVAL (CAR ARGK))) NIL) ;Ha az első elem hamis,
; akkor a függvény is.
(T (EVAL ;Ha igaz, a további
(CONS 'UJ-AND (CDR ARGK> ;elemeket vizsgáljuk.
A rekurzív lépésnél nem alkalmazhattuk az
(UJ-AND (CDR ARGK))
formát, hiszen - mint láttuk - a nem eval-típusú függvény argumentuma nem értékelődik ki. A feltétellánc utolsó elemeként az (EVAL (CONS ...)) alak szerepel, ezt érdemes részletesebben is megvizsgálnunk. Az UJ-AND függvényt nem a (CDR ARGK) listára, hanem a (CDR ARGK) lista elemeire mint argumentumokra akarjuk alkalmazni. Ezért a CONS függvénnyel készítünk egy listát, amelynek feje az UJ-AND szimbólum, a többi eleme pedig a (CDR ARGK) értékének elemeiből áll, és az EVAL segítségével kiértékeljük. A kiértékelés közben az adatokból (egy szimbólumból és egy listából) összeállított lista a következő lépésben mint program, mint kiértékelendő forma szerepel.
A megismert definiáló eszközökkel olyan új függvényeket is készíthetünk, amelyek függvények definiálását szolgálják, pl. az UJ-DE függvény definíciója:
(DF UJ-DE ARGK
(PUTD (CAR ARGK) ;az első argumentum a függvénynév
(CONS 'LAMBDA (CDR ARGK))) ;a lambdakifejezés elkészítése
(CAR ARGK)) ;UJ-DE értéke a függvénynév
5.3.4. A SELECTQ függvény
A SELECTQ fontos akárhány-argumentumú, nem eval-típusú beépített függvény (Az IS-LISP-ben nincs definiálva). A függvény a feltételes kifejezéshez hasonlít abban, hogy segítségével feltételekhez tartozó tevékenységeket (formákat) értékelhetünk ki. Használata sokszor hatékonyabb, mint ha feltételes kifejezést alkalmaznánk.
Alkalmazásakor a következő alakú formát írjuk fel:
(SELECTQ S-kifejezés1
(összehasonlxtandó1 tevékenység1.1 tevékenység1.2 ...)
(összehasonlítandó2 tevékenység2.1 tevékenység2.2 ...)
(összehasonlítandón tevékenységn.1 tevékenységn.2 ...)
S-kifejezés2)
Az első argumentumnak olyan S-kifejezésnek kell lennie, amelynek értéke egy szimbolikus atom. Az ez után következő argumentumok feje - összehasonlitandó1, összehasonlítandó2, ... össehasonlítandón - egy-egy szimbolikus atom, ezek nem értékelődnek ki. A SELECTQ ezeket az atomokat sorban összehasonlítja az első argumentum, S-kifejezés1 értékével úgy, hogy az EQ függvényt alkalmazza az összehasonlításkor. Az első olyan esetben, amikor az összehasonlítás eredménye nem NIL, kiértékeli a feltételhez tartozó tevékenységeket. A függvény értéke az utoljára kiértékelt tevékenység értéke. A SELECTQ utolsó argumentuma, S-kifejezés2 értékelődik ki akkor, ha mindegyik összehasonlítás eredménye NIL, és ekkor ez a függvény értéke is. Az általánosított feltételes kifejezéshez hasonlóan a SELECTQ függvényben is kiértékelődhet több tevékenység egy-egy összehasonlítás eredményétől függően; itt is szerepelhet implicit progn szerkezet. A 4.1. szakaszban definiált LAPERO függvény pl. a figurák értékét így számíthatná ki:
(DE FIGURA-ERTEK (KARTYA)
(SELECTQ KARTYA
(A 4) ;ász
(K 3) ;király
(D 2) ;dáma
(B 1) ;bubi
0)) ;egyébként
A LAPERO függvény definíciója ezután a következő lehet:
(DE LAPERO (L)
(COND ((NULL L) 0)
(T (PLUS (FIGURA-ERTEK (CADAR L))
(LAPERO (CDR L>
A SELECTQ alkalmazásakor az összehasonlítandó atomok helyén az atom helyett egy atomokból álló lista is szerepelhet. Ha a lista valamelyik eleme egyezik a keresett atommal (az S-kifejezés1 értékével), akkor a hozzá tartozó tevékenységek kiértékelődnek:
(DE KELL-E-FOLYTATNI (BEOLVASOTT-ATOM)
(SELECTQ BEOLVASOTT-ATOM
((I IG IGE IGEN) (SETQ MI-LEGYEN 'FOLYTASD))
((N NE NEM) (SETQ MI-LEGYEN 'NE-FOLYTASD))
'ERVENYTELEN-VALASZ))
A KELL-E-FOLYTATNI függvény a MI-LEGYEN változó értékét állítja be a függvény argumentumától függően: ha az argumentum értéke IGEN, a MI-LEGYEN változó értéke FOLYTASD lesz, ha pedig az argumentum értéke NEM, akkor a MI-LEGYEN értéke NE-FOLYTASD. A függvényt azonban úgy definiáljuk, hogy az argumentum "rövidített" alakját is elfogadja, IGEN helyett tehát elég legyen az I, IG vagy IGE, ill. NEM helyett elegendő az N vagy a NE alakot megadni. Ezt a függvényt a COND segítségével definiálni igen körülményes.
(DEFUN KELL-E-FOLYTATNI (BEOLVASOTT-ATOM)
(COND ((OR (EQ BEOLVASOTT-ATOM 'I)
(EQ BEOLVASOTT-ATOM 'IG)
(EQ BEOLVASOTT-ATOM 'IGE)
(EQ BEOLVASOTT-ATOM 'IGEN))
(SETQ MI-LEGYEN 'FOLYTASD))
((OR (EQ BEOLVASOTT-ATOM 'N)
(EQ BEOLVASOTT-ATOM 'NE)
(EQ BEOLVASOTT-ATOM 'NEM))
(SETQ MI-LEGYEN 'NE-FOLYTASD))
(T 'ERVENYTELEN-VALASZ)))
A SELECTQ függvényt azért is előnyösebb lehet alkalmazni, mint a vele egyenértékű feltételes kifejezést, mert a SELECTQ használatakor az S-kifejezés1 amelynek értékét a különböző szimbólumokkal összehasonlítjuk, csak egyetlenegyszer értékelődik ki, a feltételes kifejezés alkalmazásakor pedig minden egyes alkalommal. Ez a hosszabb kiértékelési idő mellett más következményekkel is jár akkor, ha az S-kifejezés1 kiértékelésének mellékhatása is van (erre a 10. fejezetben, a bemeneti-kimeneti függvények tárgyalásakor még visszatérünk).
Definiáljuk az UJ-SELECTQ függvényt! A definiálás során két segédfüggvényt is használunk:
(DF UJ-SELECTQ ARGK
(S-SEGED (EVAL (CAR ARGK)) ;Az elsö argumentumnak az
(CDR ARGK))) ; értékére, a többinél magára az
; argumentumra alkalmazzuk a segédfüggvényt(DE S-SEGED (A KIFK)
(COND ((NULL (CDR KIFK)) ;Ha egy kifejezés van,
(EVAL (CAR KIFK))) ; ez a SELECTQ értéke
<(VAN-ILYEN A (CAAR KIFK)) ;Szerepel-e az atom:
(EVAL (CONS 'PROGN ;Ha igen, kiértékeljük a
(CDAR KIFK> ; tevékenységeket a PROGN-nel
(T (S-SEGED A (CDR KIFK> ;Tovább vizsgáljuk
Amikor a feltételes kifejezés második elemében megvizsgáljuk, hogy az adott atom előfordul-e a feltétel-részben felsorolt atomok között, a VAN-ILYEN segédfüggvényt alkalmazzuk. A MEMBER függvényt most nem alkalmazhatjuk, mert ezt a függvényt nem értelmeztük arra az esetre, ha a második argumentum atom. A VAN-ILYEN függvény értéke akkor T, ha az első argumentumként megadott atom szerepel a második argumentumként megadott listában, vagy ha a két argumentum ugyanaz az atom, egyébként NIL. A VAN-ILYEN függvény definíciója:
(DE VAN-ILYEN (ELEM L)
(COND ((ATOM L) (EQ ELEM L)) ;Ha atom a második argumentum
((NULL (CDR L)) ;Ha lista, de csak egyelemű
(EQ ELEM (CAR L)))
(T (VAN-ILYEN (CDR L> ;Tovább keressük az ELEM-et
Mielőtt a SELECTQ használatára még egy példát bemutatunk, egy kis kitérőt kell tennünk. A fentiekben láttuk, hogy egy nem lefordított függvényről el tudjuk dönteni, hogy milyen típusú. Ha a függvény definíciója lambda-kifejezés formájában tárolódik, akkor eval-típusú, ha pedig nlambdakifejezés formájában, akkor nem eval-típusú. Ha a definícióban argumentumlistát találunk, akkor rögzített argumentumszámú függvényről, ha pedig az argumentumlista helyén egy szimbólum áll, akkor akárhány-argumentumú függvényről van szó.
Lefordított függvények esetében a függvényről csak azt tudjuk eldönteni, hogy eval- vagy nem eval-típusú-e. A GETD függvény ugyanis lefordított, eval-típusú függvény esetében (mint az 5.2. szakaszban láttuk) olyan listát ad értékként, amelynek első eleme a SUBR szimbólum. Ha a függvény lefordított de nem eval-típusú, akkor a SUBR szimbólum helyén az FSUBR szimbólum áll. Ezek alapján most már definiálhatjuk a MILYEN-FUGGVÉNY függvényt, amely argumentumáról, egy függvénynévről értékként megadja, hogy milyen típusú:
(DE MILYEN-FUGGVENY (FN)
(SELECTQ (CAR (GETD FN))
(LAMBDA
(LIST (COND ((LISTP (CADR (GETD FN)))
'ROGZITETT-ARGUMENTUMSZAMU)
(T 'AKARHÁNY-ARGUMENTUMU))
'EVAL-TlPUSU))
(NLAMBDA
(LIST (COND ((LISTP (CADR (GETD FN)))
'ROGZITETT-ARGUMENTUMSZAMU)
(T AKARHANY-ARGUMENTUMU))
'NEM EVAL-TlPUSU))
(SUBR '(LEFORDITOTT EVAL-TIPUSU))
(FSUBR '(LEFORDITOTT NEM EVAL-TIPUSU))
'(NINCS ILYEN FUGGVENY)))
6. Mélyebben a listákról és atomokról
6.1. A listák és atomok tárolása
Ebben a pontban részleteiben is megismerjük a listák és az atomok felépítését. Ez feltétlenül szükséges a LISP működésének megértéséhez.
Miben különböznek az atomok a listáktól? Eddig annyit tudunk erről, hogy minden atomnak van neve, és lehet értéke. Emellett az atomok különféle sajátosságokkal is rendelkeznek: egy atom lehet egy beépített függvény neve, lehet különleges atom; továbbá az atomokhoz - mint az 5.1. szakaszban láttuk - tulajdonságokat is rendelhetünk. A listák viszont összetett szerkezetek, amelyek meghatározott sorrendben lévő elemekből állnak, és az elemek maguk is lehetnek listák. Tudjuk azt is, hogy a listáknak nem lehet értéket adni, az értelmezőprogram a kiértékeléssel határozhatja meg az egyes listák - a formák - értékét. Nincsenek továbbá olyan sajátosságaik, mint az atomoknak (nincsenek "különleges listák", és egy listához nem lehet tulajdonságokat rendelni).
Az atomokhoz tehát másféle információk tartoznak mint a listákhoz: egy lista tárolásához az elemeit kell tárolnunk, (és az elemek sorrendjét); egy atom tárolásához viszont többféle dolgot: a nevét, a globális értékét és egyéb sajátosságait.
Az atomokhoz és a listákhoz tartozó információkat a számítógép tárában tárolja a LISP rendszer. A következőkben egyszerűsített képet adunk arról, hogyan történik ez. A tár minden egységének címe van, amelynek alapján a benne tárolt információt vissza lehet keresni. Ha egy táregység tartalma egy másik egység címe, akkor ezt mutatónak nevezzük.
6.1.1. A listák tárolása
Egy listának a tárban egy - két mutatóból álló - egység, ún. cella felel meg. A cella első mutatója a fejmutató: azt jelzi, hogy hol található a lista feje a tárban, a második mutató a farokmutató, a lista farkának a címe. Tehát pl. az (A) lista tárolása a tárban ilyen lehet:
cím: fejmutató: farokmutató: #140 #252 #0
A számjel karakterrel (#) jelöljük a címet jelentő számokat. A 140 címen egy - két címből álló - cellát találunk. A fejmutató a 252 címre mutat, ez az A atom címe a tárban. A farokmutató a 0 címre mutat, ezt egyezményesen a NIL címének tekintjük, azt jelzi, hogy ez a lista utolsó (ebben az esetben egyetlen) cellája. Többelemű lista esetében a második mutató nem a NIL-re, hanem egy listacellára mutat. Pl. az (A B C) lista tárolása a tárban ilyen lehet:
cím: fejmutató: farokmutató: #160 #252 #0 ... #180 #284 #196 ... #196 #304 #0
feltéve, hogy a 252 cím az A atom címe, a 284 cím a B atomé, a 304 cím pedig a C atomé. A 160 cím az (A B C) listának, a 180 cím a (B C) listának, a 196 cím a (C) listának, végül a 0 cím a NIL-nek felel meg. Általában egy lista elemei rendszerint nem egymás utáni címeken helyezkednek el a számítógép tárában.
A szemléletesség kedvéért a továbbiakban a címeket elhagyjuk: a listacellákat a fent látott "dobozokkal" ábrázoljuk, de a bal, ill. a jobb oldali részbe a fej- és a farokmutató helyett beírjuk azt az S-kifejezést, amelyre az illető mutató mutat. A jobb áttekinthetőség kedvéért (ha az S-kifejezés túl hosszú, vagy őt magát is dobozzal ábrázoljuk), a mutató helyett a dobozból
kivezető nyíl végére rajzoljuk a megfelelő S-kifejezést, vagy annak dobozos ábrázolását. Az (A) lista dobozos ábrázolása tehát ilyen lesz:
Amit másképp így is írhatunk:
vagy
A NIL-re mutató mutatókat szokásosan a doboz átlós áthúzásával jelöljük. Tehát az (A) listát ábrázolhatjuk így is:
Az (A B C) néhány dobozos ábrázolása:
Ha az atomok nevét nem írjuk bele a dobozokba:
Ha pedig a 2.4. szakaszban megismert binárisfa-ábrázolást követjük:
Bármelyik listaelem lehet lista, tehát fejmutató is mutathat listára. Pl. az ((A B) (C D)) lista dobozos ábrázolása:
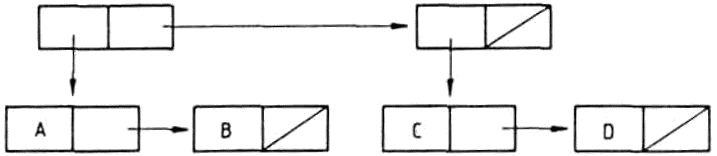
6.1.2. Az atomok tárolása
Egy-egy atom címén a tárban a következőket kell tárolnunk:
Minden atom csak egyetlen példányban létezik, az értelmezőprogram a létező atomokról vezetett nyilvántartás segítségével gondoskodik arról, hogy két különböző atomnak ne lehessen azonos a nyomtatási neve. A legtöbb LISP rendszerben az OBLIST függvény alkalmazásával ehhez a nyilvántartáshoz hozzá is férhetünk. Ennek a függvénynek nincsen argumentuma, értéke a létező nyomtatási neveket tartalmazó lista. (A 6.2.6. pontban látni fogjuk, hogy bizonyos kivételes nyomtatási nevek nem szerepelnek ebben a listában.) Az OBLIST függvény használata lehet az első lépés abban is, hogy egy még ismeretlen LISP rendszert felderítsünk: eligazítást ad arról, hogy az adott rendszerben milyen függvények vannak.
Egy különleges atom értékét nem kell tárolni (hiszen az önmaga), tulajdonságai és egyéb sajátosságai sem lehetnek. A különböző atomokkal kapcsolatban tehát változó számú információt kell tárolni. Az atomoknak ezért olyan táregységek felelnek meg, amelyekben - a listacellákkal ellentétben - kettőnél több információt (pl. mutatót) lehet tárolni; ezek tényleges száma az adott rendszertől függ. Egy mutató az atom nyomtatási nevére, a másik a globális értékére mutat, és így tovább.
Az atomokhoz tartozó attribútumtulajdonság párok az atom tulajdonságlistájában tárolódnak. Az egy atomhoz tartozó címek egyike a tulajdonságlistára mutat. A tulajdonságlista alakja általában:
(attribútum1 tulajdonság1 attribútum2 tulajdonság2 ...)
Olyan listáról van tehát szó, amelynek páros számú eleme van, és elemei váltakozva attribútumok, ill. a hozzájuk tartozó tulajdonságértékek.(Egyes LISP rendszerek a tulajdonságlistákat nem valódi listák formájában tárolják, ld. 6.4.1. pont.) A régebbi LISP rendszerek az atomokat is tulajdonságlista formájában tárolták (valamilyen módon jelezve, hogy nem közönséges listáról van szó); a nyomtatási nevet, a globális értéket, a függvénydefiníciót egy-egy tulajdonságként ábrázolták. Vannak átmenetek is a régebbi és az újabb LISP rendszerek között: pl. az itt ismertetett változatban a tulajdonságlistán (nem pedig az atom mellett tárolt egyik címen) tároljuk a nem lefordított függvények definícióját (az FNCELL attribútum mellett, 1.5.2. szakasz), de a többi említett sajátosságról feltételezzük, hogy nem lehet a GETP alkalmazásával hozzájuk férni. Más rendszerekben lehet, hogy az atom más sajátosságai kaphatók meg a GETP segítségével.
Mivel az alábbiakban csak az atomok nevére és értékére fogunk hivatkozni, leegyszerűsítjük az ábrázolásukat, és olyan dobozokat rajzolunk helyettük, amelyek csak két mezőből állnak: a felső mezőbe az atom nevét, az alsóba pedig a globális értékét írjuk.
Ha az atom értékének megfelelő S-kifejezés túl hosszú, vagy dobozos ábrázolásban kívánjuk feltüntetni, itt is nyíllal fogjuk jelölni. Ha pl. A értéke B, B értéke pedig C, ezt így ábrázolhatjuk:
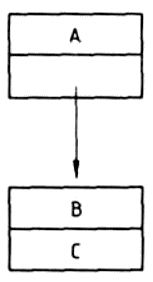
Ha A értéke a (B C D E) lista, ezt így rajzolhatjuk:
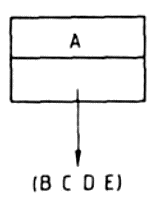
6.1.3. A dobozos ábrázolás
A most bevezetett ún. dobozos ábrázolás mellett továbbra is használjuk a nyomtatási képpel való ábrázolást. A nyomtatási kép nem más, mint az a karaktersorozat, amellyel az értelmezőprogram egy táregység tartalmát a terminál képernyőjén vagy a nyomtató papírján megjelenítheti. Láttuk, hogy az atom nyomtatási képét nyomtatási neve határozza meg. A listának nincs neve, nyomtatási képe a már jól ismert, zárójellel kezdődő és végződő karaktersorozat, amelyet kinyomtatáskor az értelmezőprogramnak minden egyes alkalommal elő kell állítania.
Rajzoljuk le az ((A B) (C D)) listát úgy, hogy a listákat is, az atomokat is dobozosán ábrázoljuk!

A dobozos ábrázolásban az atomok értékét csak akkor jelöljük, ha ez fontos; ha az értékeket beírjuk, olyan információkat is feltüntethetünk, amelyek a nyomtatási képen nem láthatók. Pl. az (A) listát így rajzolhatjuk le, ha A globális értéke B:
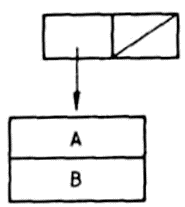
6.2. A mutatókezelő függvények
Tekintsük át a korábban megismert listakezelő függvényeket a tárban való tárolás szempontjából!
6.2.1. A szelekciós függvények
A CAR és a CDR függvények segítségével arra kapunk választ, hogy mi egy lista feje, ill. farka, hova mutat a fej- és a farokmutatója. Vagyis a CAR függvény értéke az az atom vagy lista, amelyre az argumentum értékének megfelelő cella első mutatója mutat, a CDR értéke pedig az, amelyre az argumentum értékének megfelelő cella második mutatója mutat. A következő rajzokon vastag vonallal jelöljük azt a listacellát vagy atomot, amely az egyes formák értékeként adódik:
* (CAR '((ABC) D))
(A B C)
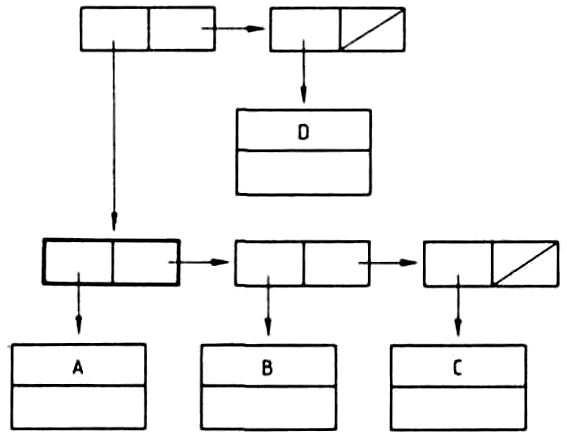
Az ábra az argumentum értékének, az ((A B C) D) listának a dobozos ábrázolása. A tárban ezt a listát első cellájának (a rajzon a bal felső cellának) a címe azonosítja. A CAR függvény értéke az a cella, amelyre az argumentum fejmutatója mutat: a fejmutató ebben az esetben a vastagon rajzolt cella címe, ez éppen az (A B C) listát azonosítja, annak első cellája.
* (CDR '((A B C) D))
(D)
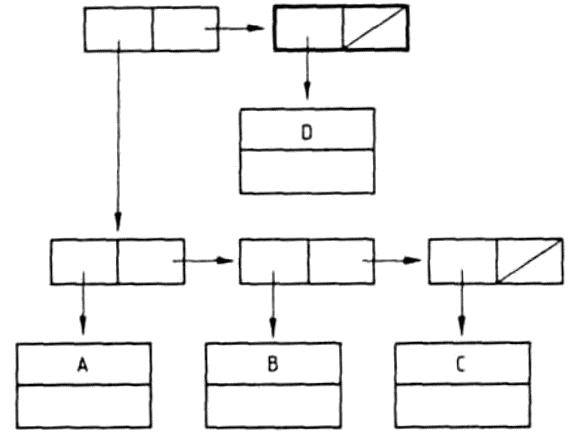
Az argumentum értéke ugyanaz a lista, mint ami az előző ábrán látható. A CDR függvény értéke az a cella, amelyre a listacella második mutatója mutat. A második mutató a vastag vonallal jelzett cella címe, ez a (D) listát azonosítja.
* (CAAR '((A B C) D))
A
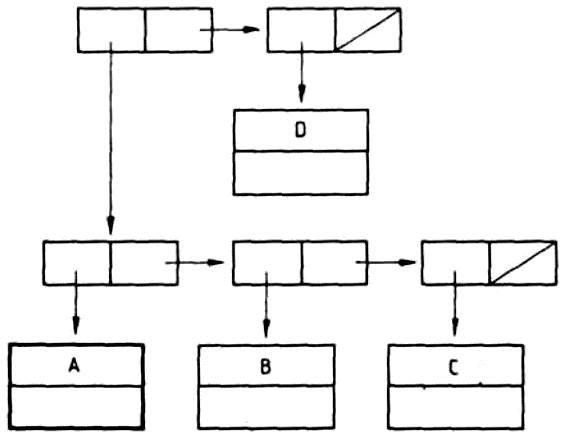
Az argumentum értéke ugyanaz a lista, mint az előző példákban. A függvényérték itt nem listacella, hanem atom, mert annak a cellának, amelyre a lista fejmutatója mutat (az (A B C) listának) a fejmutatója egy atomra mutat (a vastag vonallal jelzett A atomra).
6.2.2. A konstrukciós függvények. A CONS és a LIST
A CAR, a CDR és a belőlük származtatott összetett C...R függvények tehát bizonyos cellák tartalmáról tudósítanak. Más jellegű mutatókezelő függvények azok, amelyek új listát hoznak létre. Ilyenek pl. a CONS és a LIST. Új listát csak úgy lehet létrehozni, ha van még fel nem használt cella a tárban az új lista mutatóinak beírásához. A fel nem használt cellák az értelmezőprogram működésének kezdetén, az első forma beolvasása előtt egyetlen hosszú listába vannak felfűzve. Ezt a listát a szabad cellák listájának nevezzük. A konstrukciós függvények minden egyes alkalmazásakor az értelmezőprogram a szabad cellák listájából vesz igénybe újabb cellákat (hogy mi történik, ha a szabad cellák elfogynak, arról a 6.5. szakaszban lesz szó).
Hasonlóképpen új atomok beolvasásakor az atomok tárolására fenntartott területet kell igénybe venni. Amikor az értelmezőprogram beolvassa a '(A B) S-kifejezést, létrehoz egy új listát, és - ha az A és B atomok még nem léteztek - két új atomot is.
A CONS az új lista létrehozásához egyetlen szabad cellát vesz igénybe, az első mutató helyére beírja az első argumentum értékének a címét, a másodikba pedig a második argumentumét. A függvényérték az újonnan lefoglalt cellával azonosított lista:
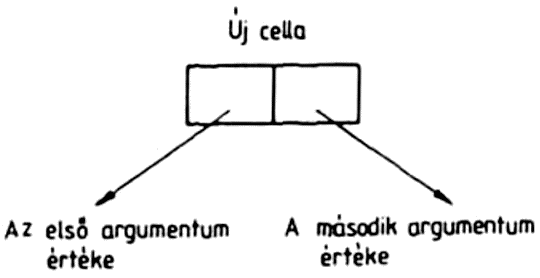
Tegyük fel, hogy az argumentumok értéke a LATASA atom, ill. a (JO) lista!
* (CONS 'LATASA '(JO))
(LATASA JO)
Ekkor az újonnan lefoglalt cella, vagyis a CONS által létrehozott lista dobozos ábrázolása:
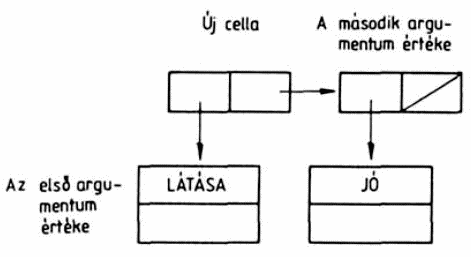
A CONS függvény mindig csak egy új cellát vesz igénybe, a LIST viszont annyi szabad cellát foglal le, ahány argumentuma van. Az első cella első mu?tatójába kerül az első argumentum címe, a második mutatóba a következő újonnan lefoglalt cella címe és így tovább. Pl. ha az argumentumok értéke A, (B C), ill. D, akkor három szabad cellára van szükség a kifejezés értékeként keletkező lista tárolásához:
* (LIST 'A '(B C) 'D)
(A (B C) D)
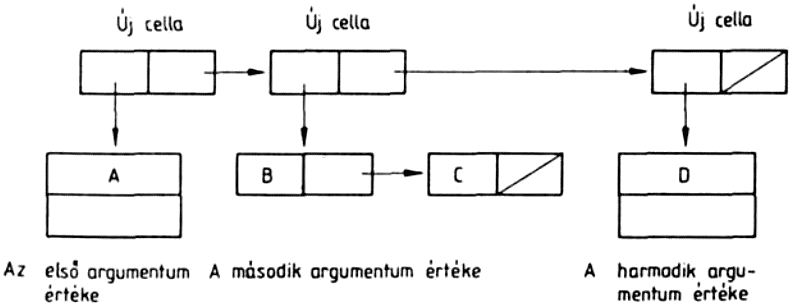
6.2.3. Az értékmutatót megváltoztató függvények
A CONS és a LIST függvényekre egyaránt az jellemző, hogy kiértékelésük révén semmilyen már létező mutató nem változik meg, csak új cellák foglalódnak le. Vannak ezzel szemben olyan mutatókezelő függvények is, amelyeknek van mellékhatása. Ilyenek pl. az értékadó függvények. A SETQ mellékhatása az, hogy egy atom (az első argumentum) értékmutatója megváltozik.
Legyen pl. a KUTYA szimbólum értéke az (UGAT) lista! Ekkor
* (SETQ KUTYA '(LATASA ROSSZ))
(LATASA ROSSZ)
A fenti forma kiértékelésekor
Az (UGAT) lista továbbra is létezik a tárban; az egyetlen különbség a kiértékelés előtti állapothoz képest az, hogy a KUTYA atom értékmutatója többé nem mutat rá. Az elért állapot tehát:
A fenti példa a LISP nyelv egyik nagyon lényeges vonását illusztrálja. A legtöbb programozási nyelvben minden változó a tár egyetlen rögzített egységére utal, ezért ha egy változónak új értéket zulunk, a régi érték visszahozhatatlanul elvész. A LISP-ben azonban az értékadáskor éppen az változik meg, hogy az illető változó a tár melyik egységére utal: a változó régi értéke továbbra is tárolódik a tárban, csak eggyel kevesebb mutató fog rámutatni az értékadás után. Ha az illető táregységre már csak egyedül az adott változó mutatott, akkor persze az új értékadás után feleslegessé válik a tartalmát tárolni (ld. 6.5. szakasz).
6.2.4. A listamásolatok és az értékadás. A COPY
A 6.1. szakaszban láttuk, hogy minden atom csak egyetlen példányban létezik. A konstrukciós függvények működéséből következik viszont az, hogy ezek akkor is létrehozzák a megfelelő listákat, ha a tárban van már ugyanolyan lista, mint ami az értékük. Listák tehát több példányban is létezhetnek. Ezért előállhat a következő helyzet:
A rajzon két listát ábrázoltunk, mind a kettőnek (A B) a nyomtatási képe, de az egyiket a bal felső, a másikat a bal alsó cella azonosítja. Ilyen esetben azt mondjuk, hogy a két lista egymás másolata.
Vizsgáljuk meg most alaposabban, mik a következményei a SETQ mellékhatásainak! Mi történik az alábbi formák kiértékelésekor?
* (SETQ KUTYA '(HARAP))
(HARAP)* (SETQ TEVE '(HARAP))
(HARAP)
Mindkét forma kiértékelésekor létrejön a (HARAP) lista egy-egy másolata a tárban. A KUTYA és a TEVE atomok értékének nyomtatási képe egyaránt a (HARAP) lista lesz, de a tárban ez a (HARAP) lista két különböző másolatának felel meg. Az elért állapot tehát:
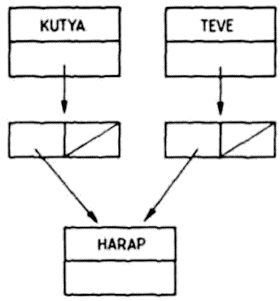
Figyeljük meg, hogy a (HARAP) lista két különböző másolatában a HARAP atom ugyanaz, hiszen ez csak egy példányban létezhet! Úgy érhetjük el, hogy a két atom értéke a (HARAP) listának ugyanaz a másolata legyen (ne pedig két különböző), hogy a listát csak egyszer hozzuk létre.
* (SETQ KUTYA '(HARAP))
(HARAP)* (SETQ TEVE KUTYA)
(HARAP)
Az első forma kiértékelésekor létrejött a (HARAP) lista egy példánya, de a KUTYA változó kiértékelése nem hozott létre újabb példányt. Ezért az elért állapot:
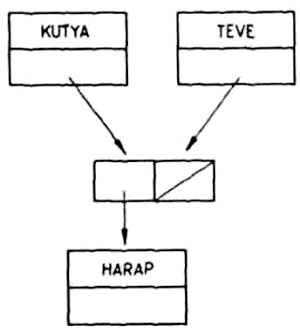
Ugyanezt az az állapotot elérhetjük egyetlenforma kiértékelésével is:
* (SETQ KUTYA (SETQ TEVE '(HARAP)))
(HARAP)
Itt is létrejött egy példány a (HARAP) listából, a SETQ függvény alkalmazása azonban csak a TEVE és a KUTYA értékmutatójára hat, a listát a SETQ nem hozza létre még egy példányban.
Definiáljunk most olyan függvényt, amelynek argumentuma egy lista, értéke pedig a lista egy újonnan létrehozott másolata! Mivel ez a függvény a legtöbb LISP rendszerben létezik, és a neve COPY, az általunk definiált függvényt UJ-COPY-nak nevezzük:
(DEFUN UJ-COPY (LISTA)
(COND ((NULL LISTA) NIL) ;A NIL-t nem lehet lemásolni.
(T (CONS (CAR LISTA) ;A CONS hozza létre az új
(UJ-COPY (CDR LISTA] ; cellákat.
A kiértékelés során a CONS függvény éppen annyiszor alkalmazódik, ahány eleme van a LISTA listának, ennyi cellát veszünk igénybe a szabad cellák listájából arra a célra, hogy a LISTA másolatát elkészítsük. Könnyű belátni, hogy az újonnan létrejött lista nyomtatási képe megegyezik a LISTA nyomtatási képével.
Vizsgáljuk meg, milyen állapothoz vezet az alábbi formák kiértékelése!
* (SETQ TEVE '(HARAP))
(HARAP)* (SETQ KUTYA (COPY TEVE))
(HARAP)
Bár a (HARAP) listát az értelmezőprogram csak egyszer olvasta be - az első forma kiértékelése előtt , a KUTYA és a TEVE atom értéke ennek a listának két különböző másolata lett:
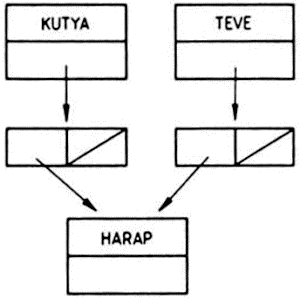
Vizsgáljuk meg dobozos ábrázolás segítségével a COPY függvény működését!
* (SETQ LISTA1 '((ALAMUSZI MACSKA) (NAGYOT UGRIK)))
((ALAMUSZI MACSKA) (NAGYOT UGRIK))* (SETQ LISTA2 (COPY LISTA1))
((ALAMUSZI MACSKA) (NAGYOT UGRIK))
Az elért állapot:

Mint az ábrán is láthatjuk, a COPY függvény csak a lista legfelső szintjét másolja le.
6.2.5. Azonosságvizsgáló függvények: az EQ és az EQUAL
A 2.3.2. pontban felhívtuk a figyelmet arra, hogy az EQ-t csak atomok összehasonlítására használhatjuk, az EQUAL-lal viszont atomokat és listákat is összehasonlíthatunk. Most már pontosabban megérthetjük, mit jelent ez. Az EQ azért nem használható listák összehasonlítására, mert nem a nyomtatási képet hasonlítja össze, hanem azt, hogy az argumentumok értéke a tár ugyanazon egységének (listák esetében cellájának) felel-e meg:
* (EQ '(HARAP) '(HARAP))
NIL
Az érték azért NIL, mert a forma kiértékelésekor a (HARAP) listából két másolat jött létre a tár két különböző cellájában. A két cella címe nem azonos, az EQ pedig ezt a két címet veti egybe. Atomok esetén ez a probléma nem merül fel, hiszen az atomok csak egy példányban létezhetnek:
* (EQ 'KUTYA 'KUTYA)
T
Bár a KUTYA karaktersorozatot az értelmezőprogram kétszer olvasta be, a kiértékelés során nem jöhet létre két KUTYA atom.
Az EQUAL függvény azonban akkor veszi fel a T értéket, ha argumentumainak nyomtatási képe azonos. Azonos atomok esetén természetesen az értéke T, mivel az atomok nyomtatási képét nyomtatási nevük egyértelműen meghatározza. Az EQUAL értéke T akkor is, ha két azonos nyomtatási képű lista az argumentumok értéke, de a két lista valójában két különböző másolat:
* (SETQ KUTYA '(HARAP))
(HARAP)* (SETQ TEVE (COPY KUTYA))
(HARAP)* (EQUAL KUTYA TEVE)
T
Ezzel szemben az EQ értéke listaargumentumok esetén csak akkor T, ha a két argumentum nem másolata egymásnak, hanem ugyanaz a lista:
* (SETQ KUTYA '(HARAP)
(HARAP)* (SETQ TEVE KUTYA)
(HARAP)* (EQ KUTYA TEVE)
T
6.2.6. Új szimbólumok létrehozása. A GENSYM
Vannak olyan feladatok, amelyek megoldásához olyan szimbólumokra van szükség, amelyek bizonyosan nem léteztek még előzőleg. Erre a célra az argumentum nélküli GENSYM függvényt használhatjuk, amely minden egyes alkalmazásakor egy új atomot hoz létre. Az így generált atom neve a legtöbb LISP rendszerben G betűvel kezdődik, és egy egész számmal folytatódik, amely a GENSYM minden alkalmazásakor eggyel növekszik:
* (GENSYM)
G0001* (GENSYM)
G0002
Az így létrehozott atomok azért nem lesznek azonosak egyetlen korábban létrehozott atommal sem, mert a rendszer nem helyezi el a nevüket az atomok listáján. A GENSYM által létrehozott atomok tehát kivételesek: nem azonosak a velük azonos nyomtatási képű, de nem GENSYM-mel létrehozott atomokkal:
* (SETQ UJ-SZIMBOLUM (GENSYM))
G0003* (EQ UJ-SZIMBOLUM 'G0003)
NIL
A GENSYM által generált atomok az OBLIST függvény értékében sem szerepelnek.
A fentiekből következik, hogy a GENSYM által létrehozott atomokra a nyomtatási nevükkel nem hivatkozhatunk, ezen a módon értéket sem adhatunk nekik:
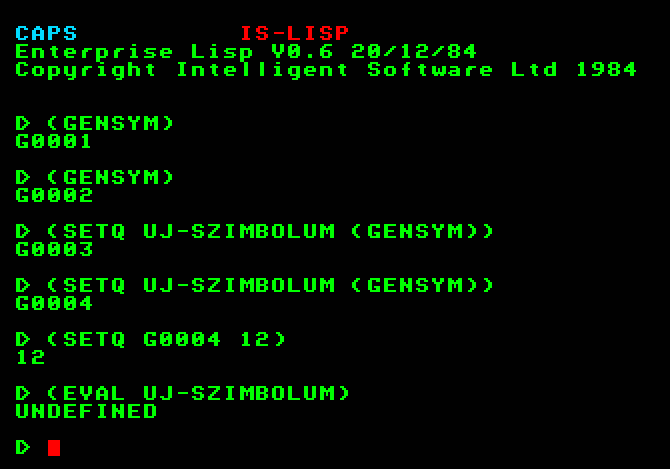
A kapott hibaüzenet igen furcsának tűnik, hiszen egy G0004 nevű változónak adtunk értéket. A valóságban az UJ-SZIMBOLUM változó értéke, amelynek nyomtatási neve szintén G0004, nem azonos azzal az atommal, amelynek értéket adtunk:
* C0004
12
Mivel a GENSYM által létrehozott atomokra név szerint nem hivatkozhatunk, egyetlen megoldás marad: a GENSYM alkalmazásával egyidejűleg létre kell hozni egy olyan mutatót, amely a GENSYM által létrehozott szimbólumra fog mutatni. A fenti példákban az UJ-SZIMBOLUM atom értékmutatója volt ez a mutató. Az UJ-SZIMBOLUM atomon keresztül érhetjük el a generált atomot, ha pl. értéket kívánunk adni neki:
* (SET UJ-SZIMBOLUM 14)
14* (EVAL UJ-SZIMBOLUM)
14* G0004
12
6.2.7. Még egyszer a konstrukciós függvényekről. Az APPEND
Térjünk most vissza az új listát létrehozó mutatókezelő függvényekhez, és vizsgáljuk meg az APPEND működését! Az APPEND alkalmazása során mindenekelőtt létrejön az első argumentum egy új másolata; majd ennek a másolatnak az utolsó cellájában a második mutató (amely ekkor NIL) megváltozik: a második argumentum címe kerül bele. Ez a módosított másolat a függvényérték, amely a két argumentum elemeit az eredeti sorrendben tartalmazza.
Vizsgáljuk meg ezt a folyamatot részletesebben!
(SETQ ALANY '(ALAMUSZI MACSKA))
(ALAMUSZI MACSKA)(SETQ ALLITMANY '(NAGYOT UGRIK))
(NAGYOT UGRIK)
Az értékadások utáni állapot:
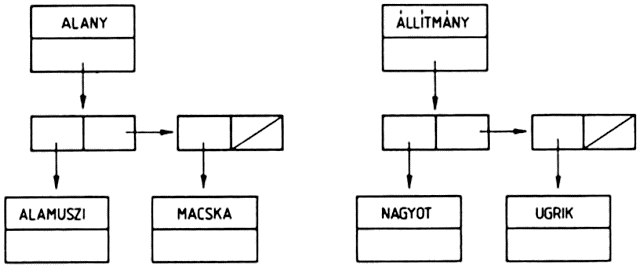
Most alkalmazzuk az APPEND függvényt az ALANY és az ÁLLÍTMÁNY értékére! Ekkor
* (APPEND ALANY ALLITMANY)
(ALAMUSZI MACSKA NAGYOT UGRIK)
A kiértékelés fő lépései:
1. Létrejön az ALANY értékének másolata (a rajzon a két legalsó cella):
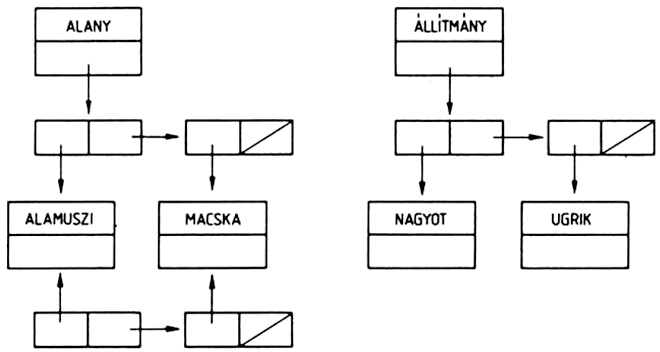
2. A másolat utolsó mutatójába, amely eddig a NIL-re mutatott, az ALLITMANY értékének címe kerül:
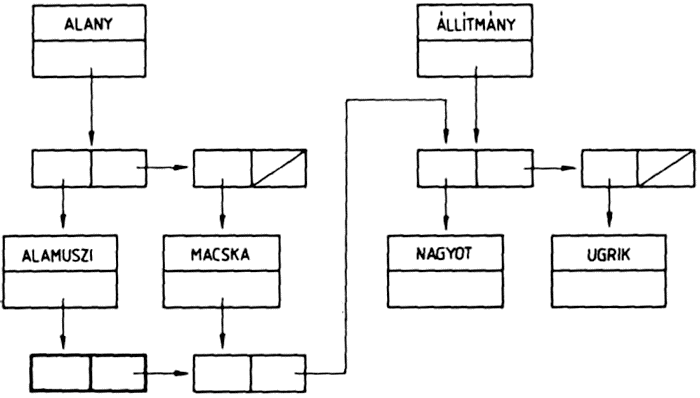
Az érték az a lista, amelyet a tárban a vastagon rajzolt cella azonosít.
6.3. A romboló függvények
Felmerül a kérdés, hogy az APPEND függvénynek miért kell szabad cellákat igénybe vennie, miért kell lemásolnia az első argumentumot, ahelyett hogy magának az első argumentumnak az utolsó mutatóját változtatná meg NIL-ről a második argumentum címére. Dobozos ábrázolással a kiinduló állapot:
Az elért állapot:
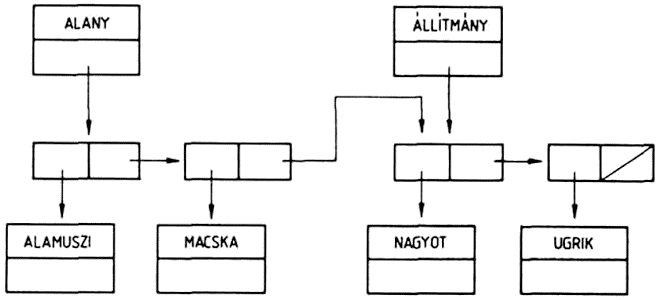
Van olyan függvény, amelynek éppen az a hatása, mint amit a fenti ábra mutat. Ez abban különbözik az APPEND-től, hogy nem vesz el cellát a szabad cellák listájáról, de az alábbiakban tárgyalandók miatt ritkábban használatos. A függvény neve NCONC. Az NCONC-nak, akárcsak az APPEND-nek, két lista az argumentuma; mellékhatásaként az első argumentum értékének utolsó mutatója megváltozik, a kiértékelés után a második argumentum értékére mutat. A fenti dobozos ábrázolásból is kitűnik, hogy az NCONC mellékhatásaként az első argumentum értéke megváltozik, tehát az NCONC az APPEND-del szemben megváltoztathatja egyes atomok értékét:
* (APPEND ALANY ALLITMANY)
(ALAMUSZI MACSKA NAGYOT UGRIK)* ALANY
(ALAMUSZI MACSKA)* (NCONC ALANY ALLITMANY)
(ALAMUSZI MACSKA NAGYOT UGRIK)* ALANY
(ALAMUSZI MACSKA NAGYOT UGRIK)
Az előző szakaszban tárgyalt mutatókezelő függvényeket a következőképpen csoportosíthatjuk:
Mint az NCONC példáján láthattuk, a romboló függvények "rejtett értékadó függvények", mert atomok értékmutatóját nem változtatják meg ugyan, de a listaszerkezetek megváltoztatásával közvetve megváltoztathatják egyes atomok értékét is.
Romboló függvényeket azért használunk viszonylag ritkábban, mint nem rombolókat, mert alkalmazásuknak váratlan következményei lehetnek. Ezek abból adódnak, hogy a romboló függvények (az egyszerű értékadó függvényekkel szemben) olyan atomok értékét is megváltoztathatják, amelyek az argumentumaikban (vagy a definíciójukban) nem szerepelnek. Lássunk erre egy egyszerű példát! A következő értékadások után:
* (SETQ KUTYA '(HARAP))
(HARAP)* (SETQ TEVE KUTYA)
(HARAP)* (SETQ MACSKA '(NYAVOG))
(NYAVOG)
a tár minket érdeklő része így ábrázolható:
Ha most a KUTYA és a MACSKA értékét, vagyis a (HARAP) és a (NYAVOG) listát az NCONC függvény alkalmazásával fűzzük össze a (HARAP NYAVOG) listává, akkor nemcsak a KUTYA szimbólum értéke változik meg, hanem a TEVE atomé is:
* (NCONC KUTYA MACSKA)
(HARAP NYAVOG)
A létrejött állapot:
* TEVE
(HARAP NYAVOG)* KUTYA
(HARAP NYAVOG)
Figyeljük meg, hogy a TEVE szimbólum nem szerepel a kiértékelt formában, tehát könnyen előfordulhat, hogy értékének megváltozásával nem számoltunk.
Két további fontos romboló függvény a RPLACA és a RPLACD. Nevük végén az A, ill. a D arra utal, hogy listák CAR-ját (fejmutatóját), ill. CDR-jét (farokmutatóját) változtatják meg. Tegyük fel, hogy a KUTYA és a MACSKA atomok értéke a (LATASA JO) listának ugyanaz a másolata!
Ha erre a listára egy romboló függvényt alkalmazunk, ezzel egyszerre változtatjuk meg a két atom értékét:
* (RPLACA KUTYA 'SZAGLASA)
(SZAGLASA JO)
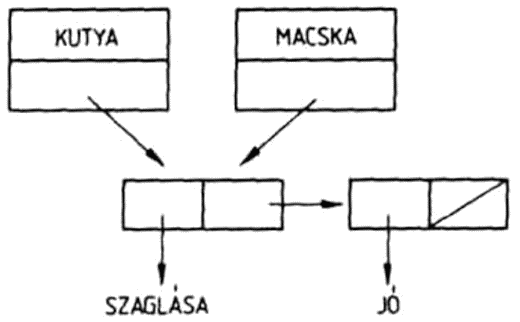
* KUTYA
(SZAGLASA JO)* MACSKA
(SZAGLASA JO)
A RPLACA kétargumentumú függvény. Az első argumentum értékének listának kell lennie, a második argumentum értéke tetszőleges S-kifejezés lehet. Mellékhatása az, hogy az első argumentum fejmutatója megváltozik, a kiértékelés után a második argumentumra mutat. Értéke (mint a SETQ-nak) az első argumentumnak a kiértékelés után vett értéke. A SETQ-val ellentétben azonban mindkét argumentum kiértékelődik, ebben a RPLACA a SET-re hasonlít.
A RPLACD a RPLACA-hoz hasonlóan működik, de a listák farok-mutatóját rombolja. Tegyük fel, hogy mind a KUTYA, mind a MACSKA atom értéke a (SZAGLASA JO) lista:
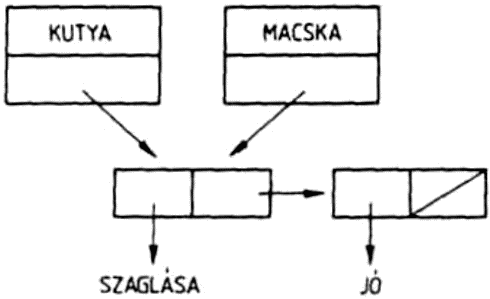
Ekkor a lista romboló megváltoztatása mindkét atom értékét megváltoztatja:
* (RPLACD MACSKA '(ROSSZ))
(SZAGLASA ROSSZ)

* KUTYA
(SZAGLASA ROSSZ)* MACSKA
(SZAGLASA ROSSZ)
A RPLACD, akár csak a RPLACA, kétargumentumú, eval-típusú függvény, és az első argumentum értékének listának kell lennie.
A romboló függvények használata csaknem mindig veszélyeket rejt magában. Kivételt képez az az eset, amikor olyan listaszerkezetre alkalmazzuk őket, amely a kiértékelés során jön létre új cellák igénybevételével, és így a létrejött listára még bizonyosan nem mutat mutató a tárban előzőleg létezett atomokból és cellákból. Teljesen veszélytelen (és az APPEND alkalmazásánál takarékosabb) megoldás pl. két lista összefűzésére az NCONC használata az alábbi esetben:
* (SETQ MONDAT (NCONC '(ALAMUSZI MACSKA) '(NAGYOT UGRIK)))
(ALAMUSZI MACSKA NAGYOT UGRIK)
6.4. A pontozott párok és a körkörös listák
Ebben a szakaszban az S-kifejezések két további típusával ismerkedünk meg: a pontozott párokkal és a körkörös listákkal. Azért nem szóltunk eddig ezek létezéséről, mert lényegüket csak a tárban való tárolás módjának ismeretében érthetjük meg.
6.4.1. A pontozott párok
A pontozott párok nevüket nyomtatási képükről kapták. Íme egy pontozott pár:
(A . B)
A pontozott párban a pont nem listaelem (bár előtte és utána a listaelemekhez hasonlóan szóköznek kell lennie), hanem a LISP egy újabb - eddig be nem vezetett - elhatárolójele: a pontozott pár első elemét választja el a másodiktól. Az (A . B) pontozott pár első eleme az A atom, a második eleme a B atom.
A pontozott párok első elemét fejnek, a másodikat faroknak nevezzük. Nem véletlen, hogy a listáknál megismert elnevezéseket használjuk, a lista ugyanis pusztán speciális esete a pontozott párnak. Mindkét fajta S-kifejezésnek van feje és farka, és a tárban mindkettőt egy cella azonosítja. Az (A . B) pontozott pár dobozos ábrázolása ilyen:
A pontozott pároknak tehát a farka lehet atom is (és pontozott pár is), míg a listáknak a farka csak lista vagy NIL lehet.
Mivel a listák speciális pontozott párok, (olyanok, amelyeknek a farka lista), az (A) listát így is írhatnánk: (A . NIL), hiszen a feje A, a farka pedig a NIL. Az (A B) lista pedig (A . (B . NIL)) alakban is írható, hiszen dobozos ábrázolása ilyen:
Hasonlóképpen az (A B C D E F G) alakú lista pontozott párként
(A . (B . (C . (D . (E . (F . (G . NIL>
alakban írható.
Minden lista pontozott pár, de nem minden pontozott pár lista. A pontozott jelölést nem használjuk azonban akkor, amikor egy S-kifejezés pontozott jelölés nélkül is felírható (vagyis lista). Csak ott használunk pontozott jelölést, ahol más jelölés nem lehetséges, tehát az (A B . C) pontozott párt nem írjuk (A . (B . C)) alakban, bár ez a felírás sem hibás. A LISP rendszerek szintén a legtakarékosabb formában nyomtatják ki a pontozott párokat.
Azoknak a függvényeknek a többsége, amelyekről eddig annyit tudtunk, hogy valamelyik argumentumuk lista, valójában pontozott párokon van értelmezve. (Az illető argumentumok pontozott párok is lehetnek.) Mindenek-előtt a CAR és a CDR függvények ilyenek, hiszen a pontozott pároknak feje és farka is van:
* (CAR '(A . B))
A* (CDR '(A . B))
B* (CDR '(A B . C))
(B . C)* (CDDR '(A B . C))
C
A CAR és a CDR viselkedéséből logikusan adódik, hogy a CONS értékkészletét valójában nemcsak listák, hanem pontozott párok alkotják; a CONS második argumentuma tehát nemcsak lista, hanem atom vagy pontozott pár is lehet:
* (CONS 'A 'B)
(A . B)* (CONS 'A '(B . C))
(A B . C)
A CONS függvényhez hasonlóan az APPEND második argumentuma is lehet pontozott pár vagy atom:
* (APPEND '(A B) '(C . D))
(A B C . D)* (APPEND '(A B) 'C)
(A B . C)
Az utóbbi függvényérték dobozos ábrázolással szemléltetve:
Az APPEND azonban nincs értelmezve arra az esetre, ha az első argumentum nem lista.
Pontozott párokat leginkább a LISP rendszer belső könyvelésében, helytakarékossági célból használnak (ld. 8.2. szakasz): míg az (A B) lista tárolásához két cella kell, az (A . B) pontozott pár csak egy cellát foglal el. Vannak LISP rendszerek, amelyek a tulajdonságlistákat pontozott párokból álló lista alakjában, az
((attribútum1 . tulajdonság1) (attribútum2 . tulajdonság2) ...)
alakban tárolják.
6.4.2. A körkörös listák
A romboló függvények lehetőséget adnak arra, hogy ún. körkörös listákat hozzunk létre. Annak a definíciónak az értelmében, miszerint a listák utolsó cellájának a farka NIL, a körkörös listák nem listák: utolsó cellájuk második mutatója nem a NIL szimbólumra mutat, hanem a körkörös lista valamelyik cellájára. A körkörös listák ezért nem ábrázolhatok fagráfként (a hozzájuk tartozó gráf nem körmentes, ld. 1.2.1. pont).
Legyen a KUTYA atom értéke a (NEM NYAVOG) lista!
Tegyük most a RPLACD segítségével körkörössé ezt a listát! Ezt többféleképpen is megtehetjük. Változtassuk meg először az utolsó cella második mutatóját úgy, hogy az első cellára mutasson! A következő formát kell kiértékelni:
(RPLACD (CDR KUTYA) KUTYA)
A kiértékelés utáni állapot:
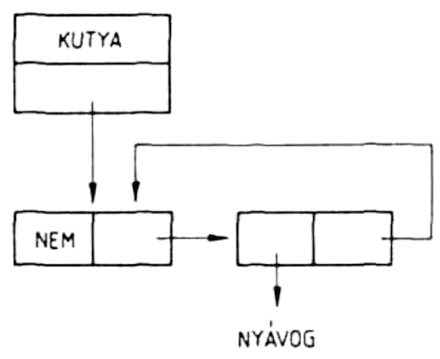
Elérhetjük azt is, hogy az utolsó mutató a körkörös lista második cellájára mutasson. Ehhez a következő S-kifejezést kell kiértékelnünk:
(RPLACD (CDR KUTYA) (CDR KUTYA)
A kiértékelés utáni állapot:
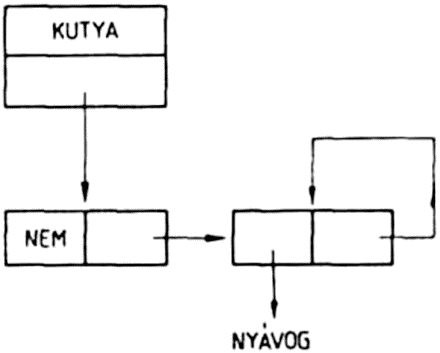
Végül körkörös listát kapunk akkor is, ha a második cellát elhagyva az első cella második mutatóját változtatjuk meg úgy, hogy magára az első cellára mutasson:
(RPLACD KUTYA KUTYA)
Az elért állapot:
Végezzük most el ténylegesen a fenti formák kiértékelését! Figyeljük meg, hogyan nyomtatja ki az értékeket az értelmezőprogram!
* (RPLACD (CDR KUTYA) KUTYA)
(NEM NYAVOG NEM NYAVOG NEM NYAVOG NEM NYAVOG NEM NYAVOG NEM NYAVOG NEM NYAVOG NEM NYAVOG NEM NYAVOG NEM ---)
A körkörös listákat az értelmezőprogram nem tudja kinyomtatni, hiszen ezek "végtelen hosszúak". Ilyenkor az értelmezőprogram egy bizonyos számú elem kinyomtatása után általában valamilyen jellel (pl. a "-" jellel) jelzi, hogy a listának további elemei vannak. Az IS-LISP nem jelez, a végtelen kiírás a STOP billentyűvel megszakítható. A másik két forma kiértékelése:
* (RPLACD (CDR KUTYA) (CDR KUTYA))
(NEM NYAVOG NYAVOG NYAVOG NYAVOG NYAVOG NYAVOG NYAVOG NYAVOG NYAVOG NYAVOG NYAVOG NYAVOG NYAVOG ---)* (RPLACD KUTYA KUTYA)
(NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM NEM ---)
A körkörös listák jelentősége a programozói gyakorlatban elenyésző, de a legtöbb rendszerben ugyanúgy használhatjuk őket, mint a szokásos listákat. Csak arra kell ügyelnünk, hogy bizonyos függvények nem értelmezhetők körkörös listákra (pl. hibához vezet, ha a LENGTH függvényt vagy a 7. fejezetben bevezetendő listabejáró függvényeket körkörös listára alkalmazzuk).
Írjunk olyan titkosíró programot, amely egy adott szöveg minden betűje helyett az ábécében megadott számú betűvel utána álló betűt írja! Mind a titkosító (sifrírozó), mind pedig a megfejtő (desifrírozó) függvényben a második argumentum azt jelzi, hogy mennyivel akarjuk eltolni az ábécé betűit. A titkosításhoz és a megfejtéshez olyan "korongot" használhatunk, amelyre felírjuk az ábécé betűit úgy, hogy az ábécé eleje és vége összeérjen. A korongot körkörös listával ábrázoljuk:
* (SETQ ABC
'(A B C D E F G H I J K L M N O P Q R S T U V W X Y Z))
(A B C D E F G H I J K L M N O P Q R S T U V W X Y Z)* (SETQ ABC-HOSSZA (LENGTH ABC))
26* (NCONC ABC ABC)
(A B C D E F G H I J K L M N O P Q R S T U V W X Y Z A B C D E F G H I J K L M N O P Q R S T U V W X Y Z A B C D E F G H I J K L M N O P Q R S T U V W X Y Z A B ---)
Ezzel létrehoztuk a körkörös ábécét.
A titkosítás első lépése, hogy megkeressük a betű első előfordulását a körkörös ábécében a MEMBER függvénnyel. A MEMBER függvény értéke olyan körkörös lista lesz, amelynek első eleme a titkosítandó betű. A keresett betű ennek a listának az n + 1-edik eleme, ha n az eltolás nagysága:
(DEFUN TITKOSIT (BETUK ELTOLAS)
(COND ((NULL BETUK) NIL)
(T (CONS (N-EDIK-ELEM (MEMBER (CAR BETUK) ABC)
(ADD1 ELTOLAS))
(TITKOSIT (CDR BETUK) ELTOLAS]
A titkosírásos szöveg megfejtését ugyancsak a TITKOSIT függvénnyel végezhetjük, csak az eltolás mértékét kell úgy megválasztanunk, hogy az eredeti eltolás és a megfejtésnél használt eltolás összege az ábécé hosszával legyen egyenlő:
(DEFUN MEGFEJT (BETUK ELTOLAS)
(TITKOSIT BETUK (DIFFERENCE ABC-HOSSZA ELTOLAS)))
A TITKOSIT és a MEGFEJT függvényeket így használhatjuk:
* (TITKOSIT '(H A L) 1)
(I B M)* (MEGFEJT '(I B M) 1)
(H A L)
6.5. A hulladékgyűjtés
Említettük, hogy a szabad cellák egyetlen listába vannak felfűzve. Ezért az értelmezőprogramnak csak az első szabad cella címét kell nyilvántartania. Eddig csak arra láttunk példát, hogy a szabad cellák fogynak, arra nem, hogy szaporodnak: az új listát létrehozó függvények minden egyes alkalma?zása és minden egyes forma beolvasása szabad cellákat vesz igénybe. Pedig számtalan esetben teljesen felesleges a szabad cellák lefoglalása. Pl. a 6.2.5. pontban látott
(EQ '(HARAP) '(HARAP))
forma kiértékelésekor úgy foglaltunk le szabad cellákat, hogy ezek után egyetlen mutató sem mutat rájuk, tehát utólag hozzáférhetetlenek. Ha egy atom értéke lista volt, és az atomhoz új értéket rendelünk, lehet, hogy a régi értékre ezek után már egyetlen mutató sem fog mutatni, a tárban mégis cellákat foglal el. Ha ez így megy tovább, a szabad cellák listája előbb-utóbb elfogy.
A LISP rendszerekben ez be is következik. Amikor a szabad cellák egy forma kiértékelése közben elfogynak, megindul a hulladékgyűjtés. Ez azt jelenti, hogy a LISP rendszer megvizsgálja, mely cellák váltak fölöslegessé, és ezeket a szabad cellák listájához csatolja. Egy cella akkor válik fölöslegessé, amikor nem lehet elérni a benne található információt; vagy azért, mert nem mutat rá mutató, vagy pedig azért, mert azok a cellák, amelyeknek valamelyik mutatója rá mutat, maguk is fölöslegesek. A 6.2.3. pontban látott példánál:
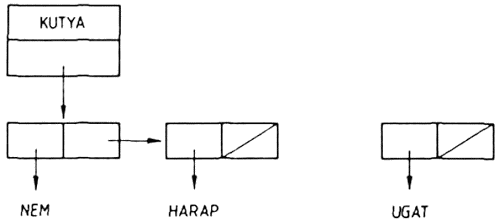
az (UGAT) listára való hivatkozás törlődött, mivel a SETQ alkalmazásával új értéket adtunk a KUTYA atomnak. Ha más mutató nem mutatott erre a cellára, akkor elérhetetlenné, fölöslegessé vált. A hulladékgyűjtés lényege tehát annak megállapítása, hogy mely cellák fölöslegesek.
A hulladékgyűjtés a legtöbb LISP rendszerben automatikusan indul meg akkor, amikor a szabad cellák száma egy küszöbérték alá csökken. A hulladékgyűjtő program általában két lépésben működik: először megjelöli az értékes cellákat, majd egy listába gyűjti a nem megjelölteket. Az első lépést megjelölésnek, a másodikat takarításnak is nevezzük. Az értékes cellák megjelölése az értékes, védett atomok számontartásán alapul.
A LISP rendszer könyvelést vezet azokról az atomokról, amelyek értékkel és (vagy) egyéb sajátosságokkal rendelkeznek. Az értékes cellák megjelölése ezektől az atomoktól indul ki. A hulladékgyűjtő program a megjelölő szakaszban megjelöli az értékes atomok értékének és tulajdonságlistájának megfelelő listaszerkezetek minden celláját, továbbá minden olyan atomot, amelyre ezekből a cellákból mutató mutat. Az ezt követő gyűjtés során nemcsak a megjelöletlen cellákat gyűjti össze a hulladékgyűjtő program, hanem az atomok tárolására fenntartott tárrészt is megtisztítja a nem elérhető atomoktól.
Nem minden atom védett, amely az OBLIST függvény értékében szerepel: ezek közül csak azok védettek, amelyek értékkel és (vagy) tulajdonságokkal rendelkeznek.
Sok LISP rendszer a fölöslegessé vált cellákat nem a fenti, a megjelölés és takarítás elvén alapuló hulladékgyűjtéssel nyeri vissza, hanem a rendszer mindig azonnal felülírhatja őket (vagyis minden lépésnél, ahol ez előfordulhat, ellenőrzi, hogy nem váltak-e fölöslegessé cellák). Ez úgy történik, hogy az értelmezőprogram minden cella mellett számon tartja, hány mutató mutat az illető cellára, és a mutatóváltoztató függvények alkalmazásakor megfelelően könyveli a celláknak ezt a hivatkozásszámlálóját. Amint egy cella hivatkozásszámlálója nullává válik, a cella automatikusan felkerül a szabad cellák listájára, és felülírhatóvá válik.
A hulladékgyűjtés rendszerével ezt a könyvelést meg lehet takarítani, de ez csak akkor takarékosabb megoldás, ha ritkán van szükség rá. Igen hátrányos lehet azonban pl. olyan programok esetében, amelyek sok "védett" cellát vesznek igénybe (olyanokat, amelyeket nem lehet kisöpörni a takarítás alkalmával), ezért a hulladékgyűjtő program mindig csak kevés szabad cellát tud újra előteremteni, és emiatt újra és újra működésbe kell lépnie.
1. feladat
Mi a kérdőjellel jelölt érték?
* (SETQQ EMLOS (KACSACSORU ERSZENYES MEHLEPENYES))
(KACSACSORU ERSZENYES MEHLEPENYES)* (SETQ EMLOSOK EMLOS)
(KACSACSORU ERSZÉNYES MEHLEPENYES)* (RPLACA EMLOSOK 'KACSACSORU-EMLOS)
(KACSACSORU-EMLOS ERSZENYES MEHLEPENYES)* EMLOS
?
2. feladat
Számos LISP változatban (az IS-LISP-ben nem) beépített függvényként megtalálható az ATTACH, amely a romboló függvények közé tartozik. A vele azonos módon működő UJ-ATTACH függvény definícióját a következőképpen írhatjuk fel:
(DEFUN UJ-ATTACH (X Y)
(RPLACD Y (CONS (CAR Y) (CDR Y)))
(RPLACA Y X))
Állapítsuk meg dobozos ábrázolással, hogyan működik az ÚJ-ATTACH függvény! Ennek alapján határozzuk meg a kérdőjellel jelölt értékeket!
* (SETQQ KELTA (IR WALESI))
(IR WALESI)* (SETQ KELTAK KELTA)
(IR WALESI)* (UJ-ATTACH 'KONTINENTALIS KELTA)
?* KELTAK
?
7. A függvények mint argumentumok
7.1. A magasabbrendű függvények
A 4.6. szakaszban definiáltuk a BESZUR-A függvényt, amelynek első argumentuma egy szimbólum; ezt a függvény egy rendezett listába (a függvény második argumentumába) a szimbólum betűrend szerinti helyére "szúrja be":
(DEFUN BESZUR-A (SZO SOR)
(COND ((NULL SOR) (LIST SZO))
((ALPHORDER SZO (CAR SOR))
(CONS SZO SOR))
(T (CONS (CAR SOR) (BESZUR-A SZO (CDR SOR>* (BESZUR-A 'C '(A B D))
(A B C D)
A - szintén a 4.6. szakaszban bevezetett - BESZUR-M függvénynek, amely nemcsak szimbólumokra van értelmezve, hanem tetszőleges S-kifejezésekre is, pontosan ugyanilyen a definíciója, azzal a különbséggel, hogy az ALPHORDER helyett ott a MEOELOZI-E predikátumot használjuk összehasonlításra. Ha viszont olyan függvényt definiálunk, amely a BESZUR-A-tól és a BESZUR-M-től csak abban tér el, hogy az összehasonlító predikátum nem az ALPHORDER vagy a MEGELOZI-E, hanem a LESSP, akkor a BESZUR-SZAM függvényt kapjuk, amely csak számokra van értelmezve:
(DEFUN BESZUR-SZAM (SZAM SOR)
(COND ((NULL SOR) (LIST SZAM))
((LESSP SZAM (CAR SOR)) ;Csak ebben a Borban tér el!
(CONS SZAM SOR))
(T (CONS (CAR SOR) (BESZUR-SZAM SZAM (CDR SOR]* (BESZUR-SZAM 3 '(0 2 4 6))
(0 2 3 4 6)
Ha pedig a GREATERP függvényt használjuk összehasonlításra, akkor az így definiált függvény egy csökkenő számsorba szúr be egy számot.
Eddigi ismereteink alapján tehát a rendezett listába való beszúrásnál minden egyes kiválasztó predikátumhoz külön beszúró függvényt kellett definiálnunk, és ezek a definíciók csak az alkalmazott kiválasztó predikátumban tértek el egymástól. Kényelmesebb lenne, ha olyan beszúró függvényt használhatnánk, amelyben az alkalmazott predikátum a függvény egyik lambdaváltozója, tehát argumentumként lehetne megadni azt, hogy mi szerint van rendezve a lista. Próbáljuk meg most definiálni ezt az általános beszúrófüggvényt, a neve legyen BESZUR. A feladat első pillantásra egyszerűnek tűnhet. Hibás azonban a következő megoldás:
(DEFUN BESZUR (ELEM LISTA HASONLITOFV) ;Hibás!
(COND ((NULL LISTA) (LIST ELEM))
((HASONLITOFV ELEM (CAR LISTA)) ;Ez a hibás sor!
(CONS ELEM LISTA))
(T (CONS (CAR LISTA)
(BESZER ELEM (CDR LISTA) HASONLITOFV]
A hiba az, hogy a HASONLITOFV változót függvénynévként használjuk a fenti definícióban. Az 1. és 5. fejezetben megtanultuk, hogy a formák (függvénykifejezések) első eleme csak egy függvény neve vagy egy lambdakifejezés lehet. Hibához vezet tehát, ha a függvény helyén olyan kifejezés áll, amelynek értéke egy függvény neve, de ő maga nem függvénynév, az értelmezőprogram ugyanis nem értékeli ki a formák első elemét. Hibához vezet ezért az is, ha olyan kifejezést használunk függvénynév helyett, amelynek értéke egy lambdakifejezés.
Eddigi ismereteink alapján az általános BESZUR függvény definícióját csak az EVAL és a CONS segítségével tudjuk - eléggé körülményesen - megfogalmazni. Ennek nehézségeivel később, a 7.1.1. pont végén még foglalkozunk.
7.1.1. Az APPLY és a FUNCTION
Az általános BESZUR függvényt az APPLY függvény alkalmazásával definiálhatjuk. Mint a 11. fejezetben látni fogjuk, az APPLY és az EVAL az a két függvény, amelyet maga az értelmezőprogram is alkalmat, ezek alkotják az értelmezőprogram magját, ezek végzik el a tulajdonképpeni munkát a kiértékelés során. Ennek a függvénynek két argumentuma van: az első egy tetszőleges S-kifejezés, amelynek értéke egy függvény neve vagy egy lambda-kifejezés, ez az APPLY függvény-argumentuma. A második argumentum értéke pedig egy lista, az APPLY lista-argumentuma. A kiértékeléskor az első argumentum - a függvény-argumentum - értékeként adódó függvény alkalmazódik a második argumentum - a lista-argumentum - értékére.
A lista-argumentum értéke a függvény argumentumainak listája:
* (SETQ FUGGVENY 'NEGYZET)
NEGYZET* (APPLY FUGGVENY '(5))
25* (SETQQ FUGGVENY (LAMBDA (X) (TIMES X X)))
(LAMBDA (X) (TIMES X X))* (APPLY FUGGVENY '(5))
25
Az APPLY-t és általában azokat a függvényeket, amelyeknek valamelyik argumentuma függvény, magasabbrendű függvényeknek (más néven funkcionáloknak) nevezzük.
A BESZUR helyes definíciójában az APPLY függvényt kell alkalmaznunk:
(DEFUN BESZUR (ELEM LISTA HASONLITOFV)
(COND ((NULL LISTA) (LIST ELEM))
((APPLY HASONLITOFV ;Itt javítottuk ki
(LIST ELEM (CAR LISTA))) ; a definíciót.
(CONS ELEM LISTA))
(T (CONS (CAR LISTA)
(BESZUR ELEM (CDR LISTA) HASONLITOFV]* (BESZUR 3 '( 0 2 4 6) 'LESSP)
(0 2 3 4 6)
A fenti formában a BESZUR függvény harmadik argumentuma a (QUOTE LESSP) formának az értéke. Bár a QUOTE alkalmazása ebben az esetben nem vezet hibához (ld. 8.4. szakasz), függvény-argumentumok esetén a QUOTE helyett a FUNCTION függvényt célszerű használni, amelyről a 8.4. szakaszban részletesebben szólunk. A továbbiakban ezt a gyakorlatot fogjuk követni. Definiáljuk a BESZUR-A függvényt az általános BESZUR segítségével!
(DEFUN BESZAR-A (ELEM LISTA)
(BESZUR ELEM LISTA (FUNCTION ALPHORDER)))
Nézzünk egy bonyolultabb példát! Az összehasonlító függvényt lambdakifejezés alakjában adjuk meg; annak a listának az elemei, amelybe beszúrunk, csökkenő hosszúság szerint rendezett listák:
* (BESZUR '(A B C) '((A B C D E) (A B C D) (AB) (A))
(FUNCTION
(LAMBDA (LISTA1 LISTA2)
(GREATERP (LENGTH LISTA1) (LENGTH LISTA2]
((A B C D E) (A B C D) (A B C) (A B) (A))
Magasabbrendű függvény maga a BESZUR is, mivel egyik argumentuma vagy egy függvény neve, vagy egy lambdakifejezés.
Az APPLY segítségével megoldható az akárhány-argumentumú függvények rekurzív definiálása is (l. 5.3.1. pont):
(DEFUN AKARHANY-METSZET HALMAZOK
(COND ((NULL HALMAZOK) NIL)
((NULL (CDR HALMAZOK)) (CAR HALMAZOK))
(T (METSZET (CAR HALMAZOK)
(APPLY (FUNCTION AKARHANY-METSZET) (CDR HALMAZOK]
Az AKARHANY-METSZET az APPLY és a FUNCTION alkalmazása nélkül is definiálható (ezzel a módszerrel az APPLY általában nélkülözhető lenne), ha a CONS alkalmazásával az AKARHANY-METSZET függvénynévből és a HALMAZOK listából előállítunk egy kiértékelendő formát, majd erre alkalmazzuk az EVAL függvényt. Ez a megoldás azonban további bonyodalmakkal jár:
(DEFUN AKARHANY-METSZET HALMAZOK ;Hibás!
(COND ((NULL HALMAZOK) NIL)
((NULL (CDR HALMAZOK)) (CAR HALMAZOK))
(T (METSZET (CAR HALMAZOK)
(EVAL (CONS 'AKARHANY-METSZET
(CDR HALMAZOK] ;Itt a hiba!
A definíció azért hibás, mert a CONS alkalmazásával előállított formában szereplő listákat - mivel az AKARHANY-METSZET függvény eval-típusú - az interpreter megkísérli kiértékelni. Az első létrehozott forma az
(AKARHANY-METSZET (B C D E F) (C D E F G))
S-kifejezés, ennek kiértékelésekor az első lépés a (B C D E F) S-kifejezés kiértékelése. A CONS második argumentumának tehát olyan listának kell lennie, amelyben a második és további elemek (QUOTE halmaz) alakúak. Ennek a listának az előállítására az EGYENKENT-QUOTE segédfüggvényt használhatjuk:
(DEFUN EGYENKENT-QUOTE (LISTA)
(COND ((NULL LISTA) NIL)
(T (CONS (LIST 'QUOTE (CAR LISTA))
(EGYENKENT-QUOTE (CDR LISTA]* (EGYENKENT-QUOTE '(A B C D))
('A 'B 'C 'D)
A helyes (de az APPLY alkalmazásánál nehézkesebb) definíció tehát:
(DEFUN AKARHANY-METSZET HALMAZOK
(COND ((NULL HALMAZOK) NIL)
((NULL (CDR HALMAZOK)) (CAR HALMAZOK))
(T (METSZET (CAR HALMAZOK)
(EVAL (CONS 'AKARHANY-METSZET
(EGYENKENT-QUOTE (CDR HALMAZOK]* (AKARHANY-METSZET '(A B C D E) '(B C D E F) '(C D E F G))
(C D E)
7.2. Hogyan általánosíthatjuk a függvényeket?
Az előző szakaszban sok különböző, de azonos szerkezetű "beszúró függvény" alapján definiáltunk egyetlen általános, magasabbrendű BESZUR függvényt. Általában, ha sok olyan függvényünk van, amelyeknek szerkezete hasonlít egymásra, ezeket mindig egyszerűbben írhatjuk fel magasabbrendű függvények segítségével.
7.2.1. Példák magasabbrendű függvényekre
Tegyük fel, hogy sok olyan függvényt definiáltunk, amelynek argumentuma egy lista, értéke pedig egy olyan lista, amely az argumentumnak csak azokat az elemeit tartalmazza, amelyek bizonyos követelménynek eleget tesznek. Legyen az egyik függvény a NEGATIV, amely egy számokból álló lista azon elemeit választja ki, amelyek 0-nál kisebbek; egy másik függvény pedig a HALMAZ-ELEMEK, ez egy halmaz azon elemeit fűzi egy listába, amelyek maguk is halmazok:
(DEFUN NEGATIV (SZAMOK)
(COND ((NULL SZAMOK) NIL)
((MINUSP (CAR SZAMOK)) ;Kiválasztási feltétel
(CONS (CAR SZAMOK) (NEGATIV (CDR SZAMOK))))
(T (NEGATIV (CDR SZAMOK]* (NEGATIV '(1 -3 5 -7 9))
(-3 -7)(DE HALMAZ-ELEMEK (HALMAZ)
(COND ((NULL HALMAZ) NIL)
((HALMAZ-E (CAR HALMAZ)) ;Kiválasztási feltétel:
(CONS (CAR HALMAZ) ; a 4.3.-ban bevezetett
(HALMAZ-ELEMEK (CDR HALMAZ)))) ; HALMAZ-E függvényt
(T (HALMAZ-ELEMEK (CDR HALMAZ] ; használjuk* (HALMAZ-ELEMEK '(A (B C) (D) (E F F E)))
((B C) (D))
Láthatjuk, hogy a két definíció csak a függvény nevében és az elemek kiválasztási feltételében - a definíció harmadik sorában - különbözik. Az ilyen függvények helyett definiálhatjuk az általános AZOK függvényt, amelynek két argumentuma van: az első argumentuma lista, a második pedig a kiválasztó predikátum:
(DEFUN AZOK (LISTA PREDIKATUM)
(COND ((NULL LISTA) NIL) ;Megállási feltétel
((APPLY PREDIKATUM ;Kiválasztási feltétel
(LIST (CAR LISTA)))
(CONS (CAR LISTA) (AZOK (CDR LISTA) PREDIKATUM)))
(T (AZOK (CDR LISTA) PREDIKATUM]* (AZOK '(1 -3 5 -7 9) (FUNCTION MINUSP))
(-3 -7)* (AZOK '(A (B C) (D) E) (FUNCTION LISTP))
((B C) (D))
Az AZOK függvény segítségével tehát sokkal egyszerűbben írhatjuk fel a NEGATIV és HALMAZ-ELEMEK definícióját:
(DEFUN NEGATIV (LISTA)
(AZOK LISTA (FUNCTION MINUSP)))(DEFUN HALMAZ-ELEMEK (HALMAZ)
(AZOK HALMAZ (FUNCTION HALMAZ-E)))
Lássunk most egy olyan példát, amelyben az AZOK függvény-argumentuma lambdakifejezés! A ROVIDEK függvény egy lista azon elemeit fűzi fel egy listára, amelyek atomok vagy egyelemű listák:
(DEFUN ROVIDEK (LISTA)
(AZOK LISTA
(FUNCTION (LAMBDA (ELEM) ;A lambdakifejezésre
; is a PUNCTION-t kell alkalmazni!
(OR (ATOM ELEM) (NULL (CDR ELEM]* (ROVIDEK '(A (B C) (D) E (F G H)))
(A (D) E)
Definiáljunk olyan függvényt, amely egy - szimbólumokból álló - listáknak adott karaktersorozattal kezdődő elemeit gyűjti ki! Legyen a függvény neve KIGYUJT, első argumentuma a szimbólumlista, a második a megadott kezdet. Szükséges még egy argumentum, a betűrendben a megadott szókezdet után következő szókezdet, mert az összehasonlítást az ALPHORDER segítségével végezzük. (A 10.2.2. pontban látni fogjuk, hogy ennek a feladatnak sokkal egyszerűbb megoldása is van):
(DEFUN KIGYUJT (SZIMBOLUMOK ELEJE KOVETKEZO)
(AZOK SZIMBOLUMOK
(FUNCTION (LAMBDA (SZIMBOLUM)
(AND (ALPHORDER SZIMBOLUM KOVETKEZO)
(NULL (EQ SZIMBOLUM KOVETKEZO))
(ALPHORDER ELEJE SZIMBOLUM>* (KIGYUJT '(BABA BABAK BABZSAK BAC BAB BACI) 'BAB 'BAC)
(BABA BABAK BABZSAK BAB)
A 4. fejezetben két olyan halmazfüggvényt is definiáltunk, amely egy halmazból megfelelő tulajdonságokkal rendelkező részhalmazt választ ki. A 4.7. szakasz 2. feladatában bevezetett HALMAZ-KIVONAS műveletét felfoghatjuk úgy is, hogy az első argumentum azon elemeit választjuk ki, amelyek a másodiknak nem elemei. A 4.3. szakaszban definiált UJ-INTERSECTION függvény értékét pedig felfoghatjuk úgy is, hogy az az első argumentumnak azon részhalmaza, amely a másodiknak is részhalmaza. Az AZOK függvény segítségével tehát ezeket is egyszerűbben írhatjuk fel:
(DEFUN HALMAZ-KIVONAS (H1 H2)
(AZOK H1 (FUNCTION
(LAMBDA (ELEM) (NULL (MEMBER ELEM H2>(DEFUN UJ-INTERSECTION (H1 H2)
(AZOK H1 (FUNCTION
(LAMBDA (ELEM) (MEMBER ELEM H2>
7.2.2. Magasabbrendű logikai függvények. Az EVERY és a SOME
A következő magasabbrendű függvény sok LISP rendszerben megtalálható beépített függvényként (az IS-LISP-ben nincs implementálva). Neve EVERY, két argumentuma van: egy lista és egy predikátum. Értéke T, ha a predikátumot a lista elemeire alkalmazva a kapott értékek egyike sem NIL. Ha csak egy olyan elem is van a listában, amelyre a predikátum értéke NIL, az EVERY értéke is NIL (és a további listaelemekre a predikátum már nem alkalmazódik). Az EVERY segítségével egyszerűbben definiálhatjuk a RESZHALMAZA-E függvényt, mint a 4.3. szakaszban tettük:
(DE RESZHALMAZA-E (H1 H2)
(EVERY H1 ;H1 minden elemének
(FUNCTION
(LAMBDA (ELEM) (MEMBER ELEM H2>
; H2-ben is benne kell lennie
Tanulságos, ha magunk is megírjuk az EVERY függvény definícióját:
(DEFUN UJ-EVERY (LISTA PRED)
(COND ((NULL LISTA) T) ;A T értéket rendeljük
; az üres listához.
((NULL (CDR LISTA)) ;Ez a megállási feltétel:
(APPLY PRED LISTA)) ; ha egyelemű, csak
; ezen az értéken múlik a függvényérték.
(T (AND (APPLY PRED
(LIST (CAR LISTA))) ;Az első elemre is
; igaznak kell lennie
(UJ-EVERY (CDR LISTA) PRED]; meg a többire is.
Az EVERY mellett sok LISP rendszer (az IS-LISP nem) beépített függvényként tartalmaz egy másik magasabbrendű logikai függvényt is, a SOME függvényt. Ennek is lista az első argumentuma, a második pedig predikátum. A függvényérték T, ha a lista legalább egy elemére alkalmazva a predikátum értéke nem NIL, egyébként a függvény értéke NIL, és a további listaelemekre a predikátum már nem is alkalmazódik:
(DEFUN VAN-E-HALMAZ-ELEME (HALMAZ)
(SOME HALMAZ (FUNCTION HALMAZ-E)))* (VAN-E-HALMAZ-ELEME '(A (B C B) E))
NIL* (VAN-E-HALMAZ-ELEME '(A (B C) (D) E))
T
7.3. A MAP függvények
Számtalan alkalmazási lehetősége van a - minden LISP rendszerben rendelkezésre álló - általános listabejáró függvényeknek, az ún. MAP függvényeknek. Könnyen felismerhetők arról, hogy mindegyikük neve MAP-pal kezdődik. A MAP függvények a LISP programozásnak igen fontos eszközei. Jellegzetességük az, hogy rekurzív módon bejárnak egy listát (amely az első argumentumuk), és minden vizsgált listarészletre alkalmaznak egy függvényt (ez a második argumentumuk).
7.3.1. A MAPCAR és a MAPC
A MAPCAR függvény lista-argumentumának minden elemére alkalmazza második argumentumát, a függvény-argumentumot. Értéke a függvényértékek listája. (A függvény-argumentumra itt is a FUNCTION-t alkalmazzuk!):
* (MAPCAR '(5 6 7 8) (FUNCTION (LAMBDA (X) (QUOTIENT X 2))))
(2 3 3 4)* (MAPCAR '((A) (B A) (C B A) (D C B A)) (FUNCTION CAR))
(A B C D)
A MAPCAR függvénnyel a 4.4. szakaszban bevezetett UJ-SUBST függvényre is egyszerűbb definíciót adhatunk:
(DEFUN UJ-SUBST (UJ REGI LIS)
(COND ((EQUAL LIS REGI) UJ) ;Helyettesítendő.
((ATOM LIS) LIS) ;Meghagyandó.
(T (MAPCAR LIS (FUNCTION ;Minden allistában
(LAMBDA (ELEM) ; elvégezzük ugyanezt
(UJ-SUBST UJ REGI ELEM] ; a helyettesítést.
Definiáljuk a MAPCAR segítségével a HELYETTESIT függvényt! Ez az UJ-SUBST-tól csak abban tér el, hogy kizárólag a lista legfelső szintjén helyettesít:
(DEFUN HELYETTESIT (UJ REGI LIS)
(MAPCAR LIS ;A lista minden elemét
(FUNCTION (LAMBDA (ELEM) ; feldolgozzuk.
(COND ((EQUAL ELEM REGI) ;Helyettesítendő?
UJ) ;Ha igen, helyettesítünk.
(T ELEM] ;Ha nem, meghagyjuk az elemet.
A MAPCAR-t gyakran használjuk arra is, hogy az APPLY argumentumaként szereplő függvény számára argumentumlistát állítsunk össze. A 3.5. szakaszban rekurzívan definiáltuk a NEGYZETOSSZEG függvényt az első n pozitív egész szám négyzetösszegének kiszámítására. Definiáljuk most a NEGYZETOSSZEG2 függvényt, amellyel tetszőlegesen megadott számok négyzetösszegét határozhatjuk meg! A definíciót így adhatjuk meg:
(DEFUN NEGYZETOSSZEG2 (SZAMOK)
(APPLY (FUNCTION PLUS) (MAPCAR SZAMOK (FUNCTION NEGYZET]* (NEGYZETOSSZEG2 (1 2 3 4 5))
55
Végül alkalmazhatjuk a MAPCAR-t az AKARHÁNY-METSZET "suta" definíciójának (ld. 7.1.1. pont) EGYENKENT-QUOTE segédfüggvényében:
(DEFUN EGYENKENT-QUOTE (LISTA)
(MAPCAR LISTA
(FUNCTION (LAMBDA (ELEM) (LIST 'QUOTE ELEM]
Most pedig definiáljunk egy olyan függvényt, amely ugyanúgy viselkedik, mint a MAPCAR!
(DEFUN UJ-MAPCAR (LISTA FUGGVENY)
(COND ((NULL LISTA) NIL) ;Megállási feltétel.
(T (CONS (APPLY FUGGVENY ;Az egyes elemek
(LIST (CAR LISTA))) ; feldolgozása
(UJ-MAPCAR (CDR LISTA) FUGGVENY]
A MAPC függvény abban különbözik a MAPCAR-tól, hogy értéke nem az eredmények listája, hanem mindig NIL:
* (MAPC '(ALFA BETA GAMMA) (FUNCTION (LAMBDA (NEV) (SET NEV T))))
NIL
A fenti forma kiértékelésének hatására az első argumentum - a listaargumentum - elemei sorban a T értéket veszik fel; a MAPC függvény értéke azonban NIL. A MAPC függvényt tehát akkor érdemes használni, ha függvényargumentumának mellékhatása van (értékadó függvény, mint példánkban, vagy nyomtató függvény, ld. a 10.3. szakaszt).
7.3.2. A MAPLIST és a MAP
A MAPLIST függvény nem a lista elemeire, hanem a listára, a lista farkára, majd a farok farkára - és így tovább -, alkalmazza függvényargumentumát. Tehát ha a lista-argumentum az (A B C D) lista, akkor a függvény-argumentumot először az egész listára, ezután a (B C D) listára, majd a (C D), végül a (D) listákra alkalmazza. A függvény értéke (akárcsak a MAPCAR-nak) a függvényértékek listája:
* (MAPLIST '(A B C D)
(FUNCTION (LAMBDA (FAROK) (LIST (CAR FAROK) (CDR FAROK]
((A (B C D)) (B (C D)) (C (D)) (D NIL))
A MAP nevű függvény szintén a listára, a lista farkára, majd a farok farkára - és így tovább - alkalmazza a függvény-argumentumot, de értéke nem a függvényértékek listája, hanem NIL, tehát úgy viszonyul a MAPLIST-hez, mint a MAPC a MAPCAR-hoz.
A MAPCAR, a MAPC, a MAPLIST és a MAP függvények összefüggését a következő táblázat foglalja össze:
értéke lista értéke NIL fejek feldolgozása MAPCAR MAPC farkak feldolgozása MAPLIST MAP
7.3.3. A MAP függvények harmadik argumentumáról
Bejárhatjuk a listákat úgy is, hogy nem minden elemet vizsgálunk, hanem csak minden másodikat vagy harmadikat. Sok LISP rendszerben a MAP függvényeknek harmadik argumentuma is lehet, ez adja meg, hogy milyen függvényt használ a MAP függvény a farokrekurzió során. (Ha nem adunk meg harmadik argumentumot, akkor egyesével halad, vagyis a CDR-t alkalmazza.)
A LEGNAGYOBB függvény argumentumának olyan listának kell lennie, amelynek elemei számok. A lista legnagyobb elemét úgy választjuk ki, hogy a listaelemeket páronként hasonlítjuk össze. Minden párból azt a számot tartjuk meg, amelyik nagyobb, majd az így kapott listára újra alkalmazzuk a LEGNAGYOBB függvényt mindaddig, amíg egyelemű listát nem kapunk (amelynek egyetlen eleme az eredeti lista legnagyobb eleme):
(DEFUN LEGNAGYOBB (SZAMOK)
(COND ((NULL SZAMOK) NIL) ; Megállási feltétel.
((NULL (CDR SZAMOK)) ; Egyelemű lista, az
(CAR SZAMOK)) ; egyetlen elem a legnagyobb.
(T (LEGNAGYOBB
(MAPLIST SZAMOK <FUNCTION
(LAMBDA (FAROK)
(COND ((NULL (CDR FAROK)) ;Egyelemű
(CAR FAROK)) ; farok.
((GREATERP (CAR FAROK) ;A farok első
(CADR FAROK)) ; két elemét
(CAR FAROK)) ; hasonlítjuk
(T (CADR FAROK> ; össze.
(FUNCTION CDDR> ;Kettesével haladunk* (LEGNAGYOBB '(1 9 5 3 2))
9
7.3.4. Egyéb MAP függvények
A 4.1. szakaszban láttuk, hogyan lehet rekurzív függvénnyel előállítani egy ország szomszédainak a listáját, ha a térképet a szomszédokból álló párokkal ábrázoljuk. Tegyük most fel, hogy a lista mindegyik párt mindkét sorrend-ben tartalmazza, tehát ha az (A B) pár eleme a listának, akkor a (B A) pár is az. Mivel farokrekurziót használunk, ebben az esetben is alkalmazhatunk MAP függvényt. Próbálkozzunk először a MAPC függvénnyel!
(DEFUN SZOMSZEDAI3 (ORSZAG TERKEP)
(SZOMSZEDAI3-SEGED ORSZAG TERKEP NIL))(DEFUN SZOMSZEDAI3-SEGED (ORSZAG TERKEP EREDM)
<MAPC TERKEP ;Minden egyes pár
(FUNCTION (LAMBDA (PAR) ; megvizsgálunk
(COND <(EQ (CAR PAR) ORSZAG) ;Ha az első tag
; a keresett ország,
(SETQ EREDM ;a szomszédot a
(APPEND EREDM (CDR PAR> ; munkaváltozóhoz fűzzük.
(T NIL> ;Ha nem, nincs teendő.
EREDM) ;Értéke a gyüjtöváltózó végsó értéke.
Felmerülhet, hogy a SZOMSZEDAI3 definiálásánál a MAPCAR-t használjuk. Ekkor nincs szükség gyűjtőváltozóra, de a függvényértékben minden olyan pár helyén, amelynek az első eleme nem a keresett ország, a NIL jelenik meg. Ha tehát a MAPCAR-t használnánk, az értékből végül (a REMOVE segítségével) el kellene tüntetnünk a NIL elemeket.
Egyszerűbben is megoldhatjuk a feladatot, ha egy új listabejáró függvényt definiálunk (nevezzük MAPCART-nak), amely csak a NIL-től különböző függvényértékeket gyűjti:
(DEFUN MAPCART (LISTA FUGGVENY MUNKA)
(COND ((NULL LISTA) NIL) ; Megállási feltétel.
((SETQ MUNKA ; Az egyes értékeket a MUNKA
(APPLY FUGGVENY ; változó értékévé
(LIST (CAR LISTA)))) ; tesszük, de csak ha nem
(CONS MUNKA ; NIL, akkor illesztjük az érték elejére.
(MAPCART (CDR LISTA) FUGGVENY))) ; Rekurzió.
(T (MAPCART (CDR LISTA) ;Farokrekurzió, ha az érték
FUGGVENY] ;NIL volt.(DEFUN SZOMSZEDAI3 (ORSZAG TERKEP)
(MAPCART TERKEP (FUNCTION
(LAMBDA (PAR) (AND (EQ (CAR PAR) ORSZAG) (CADR PAR>
Másképpen is elérhetjük, hogy a NIL értékek a függvényértékben ne szerepeljenek, pl. úgy, hogy a szomszédok összegyűjtésére az APPEND függvényt használjuk, hiszen
* (APPEND '(A B C) NIL)
(A B C)* (APPEND NIL '(A B C))
(A B C)
Definiáljunk tehát olyan MAP függvényt (nevezzük MAPCAPP-nak), amely a függvényértékeket az APPEND segítségével fűzi össze!
(DEFUN MAPCAPP (LISTA FUGGVENY)
(COND ((NULL LISTA) NIL)
(T (APPEND (APPLY FUGGVENY (LIST (CAR LISTA)))
(MAPCAPP (CDR LISTA) FUGGVENY]
Íme a SZOMSZEDAI3 definíciója a MAPCAPP segítségével:
(DEFUN SZOMSZEDAI3 (ORSZAG TERKEP)
(MAPCAPP TERKEP (FUNCTION
(LAMBDA (PAR) (AND (EQ (CAR PAR) ORSZOG) (CDR PAR]
Valahányszor a pár első eleme nem a keresett ország, az AND kifejezés értéke NIL lesz, tehát a szomszédok listájához nem adódik hozzá újabb elem. A többi esetben az AND értéke a pár farka, vagyis a szomszédot tartalmazó egyelemű lista, s ezt éppen APPEND-del kell az előző szomszédok listájához fűzni, hogy a végső érték a szomszédok listája legyen.
Sok LISP rendszerben létezik a MAPCAN függvény, amely csak abban tér el az itt definiált MAPCAPP-tól, hogy az APPEND helyett a romboló NCONC függvényt alkalmazza:
(DEFUN UJ-MAPCAN (LISTA FUGGVENY)
(COND ((NULL LISTA) NIL)
(T (NCONC (APPLY FUGGVENY (LIST (CAR LISTA)))
(UJ-MAPCAN (CDR LISTA) FUGGVENY]
A MAPCAN használata elvileg nem rejt magában veszélyt, hiszen az a listaszerkezet, amelyet a MAPCAN alkalmazásakor az NCONC rombol, az APPLY értékeként jön létre a kiértékelés során, tehát biztos, hogy előzőleg semmiféle mutató nem mutatott rá. Ennek ellenére használatát nem javasoljuk, mert sok LISP rendszerben bajt okozhat: a lokális értékek nyilvántartásának módjától függően lehetnek olyan mutatók, amelyek tudtunk nélkül a rombolt listaszerkezetre mutatnak.
7.4. A MAP függvények és a tulajdonságlisták
Gyakran használjuk a MAP függvényeket olyan feladatok megoldására, amelyekben tulajdonságlistákkal dolgozunk. Ha egy lista elemeinek tulajdonságait kell valamilyen rendszer szerint megvizsgálnunk, akkor kézenfekvő az, hogy a listát valamelyik MAP függvénnyel járjuk be. Sok feladatot, amelyet eddigi tudásunkkal csak eléggé körülményesen tudtunk megoldani, a MAP függvények segítségével sokkal tömörebben, áttekinthetőbben, elegánsabban oldhatunk meg.
Nézzük a bridzskártya laperejének kiszámítására az 5.1. szakaszban bevezetett LAPERO3 függvényt! Ez azt feltételezi, hogy egy játékos lapját a játékost jelentő szimbólum tulajdonságlistáján a PIKK, a KOR, a KARO és a TREFF attribútumokhoz tartozó tulajdonságokkal írjuk le. A LAPERO3 függvényt és a PONTLISTA segédfüggvényt is egyszerűbben definiálhatjuk újra MAP függvényekkel:
(DEFUN LAPERO3 (L)
(COND ((NULL L) 0)
(T (APPLY (FUNCTION PLUS)
(PONTLISTA
(MAPCAPP '(PIKK KOR KARO TREFF)
(FUNCTION (LAMBDA (X) (GET L X](DEFUN PONTLISTA (LIS)
(COND ((NULL LIS) '(0))
(T (MAPCAR LIS (FUNCTION (LAMBDA (X)
(GET X 'PONTERTEK]
A PONTLISTA függvényben a MAPCAR függvénnyel fűzzük listába az egyes lapok pontértékét. A LAPERO3 függvényben listákat kell összefűznünk; mivel az üres lista is szerepelhet köztük, ezért a MAPCAPP függvényt használjuk.
Ha az ESZAK-kal jelölt játékos lapja most is ugyanaz, mint az 5.1. sza?kaszban, és a 7-5-3-1 értékelési módot használjuk, akkor
* (LAPERO3 'ESZAK)
31
A családi kapcsolatok ábrázolásakor bevezettük a NAGYBATYJA függvényt, amely a SZULEI függvényt alkalmazva adja meg egy személy nagybátyjainak - szülei fivéreinek - a nevét. A NAGYBATYJA új definíciója:
(DEFUN NAGYBATYJA (NEV)
(COND ((NULL (SZULEI NEV)) NIL)
(T (MAPCAPP (SZULEI NEV)
(FUNCTION (LAMBDA (X) (GET X 'FIVERE]* (NAGYBATYJA 'HUNYADI-MATYAS)
(SZILAGYI-MIHALY)
Nehezebb feladat az OSEI függvényt definiálni, amely egy személy összes ősének - szüleinek, szülei szüleinek és így tovább - a nevét fűzi egy listába. A függvény definiálásakor fel kell készülnünk arra is, hogy nem minden szülőnek ismertek a szülei, tehát van olyan név, amelyre a SZULEI függvény értéke NIL. Mivel nem akarjuk, hogy az ősök listáján ezek a NIL értékek megjelenjenek, ezért a definíciót itt is a MAPCAPP függvénnyel írhatjuk fel:
(DEFUN OSEI (NEV) (OSEI-SEGED (SZULEI NEV)))
(DEFUN OSEI-SEGED (SZULOK)
(COND ((NULL SZULOK) NIL)
(T (APPEND SZULOK (MAPCAPP SZULOK (FUNCTION OSEI]* (OSEI 'BOTH-BAJNOK)
NIL* (OSEI 'HUNYADI-JANOS)
(BOTH-BAJNOK)* (OSEI 'HUNYADI-MATYAS)
(HUNYADI-JANOS SZILAGYI-ERZSEBET BOTH-BAJNOK)
Az OSEI függvényt MAP függvények nélkül már igen kényelmetlen feladat lenne definiálni.
Nézzünk a térképekkel kapcsolatban néhány bonyolultabb feladatot! Eddig nem foglalkoztunk azzal, hogy a térképnek listával, ill. tulajdonságlistával való leírásakor nem követtünk-e el hibát. Mivel azonban minden bonyolult listaszerkezet leírásakor hibázhatunk, hasznos egy függvényt definiálnunk a térkép szerkezetének ellenőrzésére. Legyen a függvény neve TERKEP-VIZSGALAT, argumentuma pedig egy térkép neve. A térképet - mint az 5.1. szakaszban - egy listával ábrázoljuk, amely a térképen lévő valamennyi ország nevét tartalmazza. Az egyes országok szomszédainak nevei az ország tulajdonságlistáján helyezkednek el, a SZOMSZEDOK attribútumhoz tartozó tulajdonságként. A TERKEP-VIZSGALAT függvény a következőket ellenőrzi:
A TERKEP-VIZSGALAT függvény értéke egy lista, amely egy-, ill. kételemű allistákból áll. Ha egy ország neve előfordul valamelyik ország szomszé?dai között, de nincs rajta a térképen, a függvény egyelemű allistaként adja vissza. Két olyan ország neve pedig, amelyek közül az első előfordul a má?sodik ország szomszédai között, de a második nincsen az első szomszédai között, kételemű allistaként jelenik meg. Ha a függvény nem talált egyetlen hibát sem a térképen, akkor értéke NIL.
(DEFUN TERKEP-VIZSGALAT (TERKEP)
(MAPCAPP TERKEP (FUNCTION ORSZAG-VIZSGALAT)))
Az egyes országokat az ORSZAG-VIZSGALAT segédfüggvény vizsgálja az 5.1. szakaszban bevezetett SZOMSZEDAI2 függvény segítségével:
(DEFUN ORSZAG-VIZSGALAT (ORSZAG1) ;Az ország szom-
(MAPCAPP (SZOMSZEDAI2 ORSZAG1) ; szédait vizsgálja
(FUNCTION SZOMSZED-VIZSGALAT)))(DEFUN SZOMSZED-VIZSGALAT (ORSZAG2) ;Az egyes szomszé-
(SZOMSZED-VIZSGALAT-SEGED TERKEP NIL)) ; dokat vizsgálja(DEFUN SZOMSZED-VIZSGALAT-SEGED (TERKEP HIBALISTA)
(OR (MEMBER ORSZAG2 TERKEP) ;Rajta van-e az
(SETQ HIBALISTA ;ország a térképen?
(CONS (LIST ORSZAG2) HIBALISTA))) ;A gyűjtöváltozó
(COND ((NOT (MEMBER ORSZAG1 ;Kölcsönös-e
(SZOMSZEDAI2 ORSZAG2))) ;a szomszédság?
(CONS (LIST ORSZAG1 ORSZAG2) HIBALISTA))
(T HIBALISTA))) ;A függvény értéke
Ábrázoljuk most csak Európa egy részének - Nyugat-Európának - a térképét! Tegyük fel, hogy az országnevek listája a NYUGAT-EUROPA változó értéke, és írjuk fel az egyes országok szomszédait tartalmazó tulajdonság-listákat! Nyugat-Európa térképe álljon a következő országokból: Portugália, Spanyolország, Franciaország, Belgium, Luxemburg, Hollandia és a Német Szövetségi Köztársaság:
* (SETQ NYUGAT-EUROPA '(P E F B L NL D))
(P E F B L NL D)
A szomszédok közül most csak azokat akarjuk ábrázolni, amelyek Nyugat- Európa térképén találhatók:
(DEFLIST
'((P (E)) (E (F)) (F (B L D CH E)) (L (F NL D)) (NL (B D))
(D (NL CH F L B)))
'SZOMSZEDOK)
Egyszerű rátekintéssel is észrevehetjük, hogy a térkép ábrázolásába több hiba is belekerült. Így Portugália szomszédai között szerepel Spanyolország, megfordítva azonban nem. A szomszédok között Svájc is szerepel, amelyet a NYUGAT-EUROPA változó értéke nem tartalmaz. Vizsgáljuk meg a térképet!
* (TERKEP-VIZSGALAT NYUGAT-EUROPA)
((P E) (F B) (F CH) (CH) (L NL) (NL B) (D CH) (CH) (D B))
A vizsgálat felszínre hozta a már észrevett hibákat és néhány továbbit is. A kapott lista tartalmazza a (P E) párt, jelezve, hogy Portugália nem szerepel Spanyolország tulajdonságlistáján. Egyelemű listaként találjuk Svájc nevét, tehát előfordul valamelyik ország szomszédai között, bár ő maga nincs rajta a térképen. Svájc és Belgium neve több ország nevével együtt is előfordul, jelezve, hogy az illető ország tulajdonságlistáján ők ugyan szerepelnek, de az illető ország nincs az ő tulajdonságlistájukon. Észrevehetjük, hogy ehhez a két országhoz nem rendeltünk a DEFLIST függvénnyel a SZOMSZEDOK attribútumhoz tartozó tulajdonságot. Végül hibákat találunk Luxemburg és Hollandia szomszédainak megadásánál is.
A térkép javítására az ORSZAGOT-ELHELYEZ függvényt vezetjük be. Ez az adott országot hozzácsatolja a térképhez, ha még nincs rajta, és hozzácsatolja a nevét az ország azon szomszédainak a tulajdonságlistájához is, amelyekről hiányzik. A függvény három argumentuma az ország neve, a szomszédainak nevét tartalmazó lista és a térkép neve:
(DEFUN ORSZAGOT-ELHELYEZ (ORSZAG SZOMSZEDLISTA TERKEP)
;A szomszédlistát az ország tulajdonságlistájára teszi
(PUT ORSZAG 'SZOMSZEDOK SZOMSZEDLISTA)
;Javítja a szomszédok tulajdonságlistáit
(SZOMSZEDOT-JAVIT ORSZAG SZOMSZEDLISTA TERKEP)
(COND ((NOT (MEMBER ORSZAG TERKEP)) ;Ha nincs az ország
(UJ-ATTACH ORSZAG TERKEP)) ; a térképen,
(T TERKEP))) ; hozzácsatolja
A függvény értéke a TERKEP értéke, amely megváltozhatott, ha az ország nevét hozzá kellett csatolni. A SZOMSZEDOT-JAVIT függvény a MAPC segítségével adja hozzá az ország nevét azoknak a szomszédainak a tulajdonságlistájához, amelyen még nem szerepelt:
(DEFUN SZOMSZEDOT-JAVIT (ORSZAG SZOMSZEDLISTA TERKEP)
(MAPC SZOMSZEDLISTA (FUNCTION (LAMBDA (X)
(COND ((NOT (MEMBER ORSZAG (SZOMSZEDAI2 X)))
(ADDPROP X 'SZOMSZEDOK ORSZAG))
(T NIL]
Javítsuk ki a térkép hibáit! Portugáliát helyezzük el Spanyolország tulajdonságlistáján a szomszédok között; ezt elérhetjük úgy, hogy megadjuk Spanyolország nevét, és szomszédainak új listáját, amely már tartalmazza Portugáliát is:
* (ORSZAGOT-ELHELYEZ 'E '(F P) NYUGAT-EUROPA)
(P E F B L NL D)
Ezután már helyesen kapjuk meg Spanyolország szomszédait:
* (SZOMSZEDAI2 'E)
(F P)
Másképpen is javíthatjuk a térképet: az ORSZAGOT-ELHELYEZ függvénynek Portugália nevét és szomszédainak listáját ugyanúgy adjuk meg, mint ahogy a DEFLIST függvénynek megadtuk, ekkor a SZOMSZEDOT-JAVIT függvény helyezi el Portugália nevét Spanyolország tulajdonságlistáján:
* (ORSZAGOT-ELHELYEZ 'P '(E) NYUGAT-EUROPA)
(P E F B L NL D)* (SZOMSZEDAI2 'E)
(P F)
A NYUGAT-EUROPA szimbólum értéke ugyanaz, mint volt, hiszen Portugália eddig is szerepelt rajta, csak Spanyolország tulajdonságlistája változott meg a függvényalkalmazás mellékhatáséiként:
* NYUGAT-EUROPA
(P E F B L NL D)
Helyezzük el Svájcot a térképen!
* (ORSZAGOT-ELHELYEZ 'CH '(F D) NYUGAT-EUROPA)
(CH P E F B L NL D)* NYUGAT-EUROPA
(CH P E F B L NL D)* (SZOMSZEDAI2 'CH)
(F D)
A NYUGAT-EUROPA szimbólum értékéhez a függvény hozzácsatolta a Svájc nevének megfelelő szimbólumot. Javítsuk ki ezután Luxemburg hibásan megadott szomszédainak listáját!
* (ORSZAGOT-ELHELYEZ 'L '(F B D) NYUGAT-EUROPA)
(CH P E F B L NL D)
Adjuk meg Belgium szomszédait is!
* (ORSZAGOT-ELHELYEZ 'B '(NL D L F) NYUGAT-EUROPA)
(CH P E F B L NL D)
Ha ezután újból megvizsgáljuk a térképet, már nem találunk hibát:
* (TERKEP-VIZSGALAT NYUGAT-EUROPA)
NIL
Észrevehetjük, hogy a TERKEP-VIZSGALAT függvény nem derít fel minden lehetséges hibát; pl. nem vizsgálja azt, hogy van-e a térképen olyan ország, amelynek egyáltalán nincsenek szomszédai. Szükség lenne továbbá olyan térképjavító függvényre is, amellyel törölhetünk egy tévesen feltüntetett országot a térképről, és mindazon országok tulajdonságlistájáról, amelyekén szerepel. Az eddigi példák is érzékeltethetik azonban, hogy a tulajdonságlisták és a MAP függvények segítségével bonyolult adatszerkezeteken végrehajtandó algoritmusokat viszonylag egyszerűen, áttekinthetően írhatunk le.
A TERKEP-VIZSGALAT függvénnyel természetesen ellenőrizhetjük azt is, hogy Európa térképét helyesen írtuk-e le az 5.1. szakaszban. Legyen az EUROPA változó értéke az ott felírt lista, és legyenek az egyes országok szomszédai is az 5.1. szakaszban megadottak! Ekkor
* (TERKEP-VIZSGALAT EUROPA)
NIL
A térkép tehát ellentmondások nélkül ábrázolja a szomszédsági kapcsolatokat.
A magasabbrendű függvények megismerésével érkeztünk el a LISP nyelv ismeretének arra a fokára, amely lehetővé teszi, hogy a legbonyolultabb feladatokat is világos, áttekinthető, de hatékony programokkal oldjuk meg. A magasabbrendű függvények alkotják a LISP programozás legjellemzőbb, legsajátosabb és leghasznosabb eszközeit. Ezek segítségével elkerülhetjük, hogy egymáshoz hasonló feladatok megoldására mindig új meg új függvényeket kelljen szerkesztenünk.
1. feladat
Definiáljuk az általános BESZUR függvény mintájára az általános LEG függvényt, amelynek első argumentuma egy lista, a második pedig egy predikátum! Az érték a listának az az eleme, amely a predikátum szempontjából a "leg", pl. a legnagyobb, legkisebb, leghosszabb stb. elem.
(DEFUN LEG (LISTA FUGGVENY)
(COND ((NULL LISTA) NIL) ;üres lista: nincs legnagyobb elem
((NULL (CDR LISTA)) ;az egyetlen elem a legnagyobb
(CAR LISTA))
((APPLY FUGGVENY
(LIST (CAR LISTA) ;ha az első elem nagyobb.
(CADR LISTA)))
(LEG (CONS (CAR LISTA) ; ezt tartjuk meg.
(CDDR LISTA)) FUGGVENY))
(T (LEG (CDR LISTA) FUGGVENY] ;ha a második elem nagyobb.
2. feladat
Definiáljuk az általános BESZUR segítségével az általános RENDEZ függvényt!
(DEFUN RENDEZ (LISTA FUGGVENY)
(COND ((NULL LISTA) NIL)
((NULL (CDR LISTA)) (LIST (CAR LISTA)))
(T (BESZUR (CAR LISTA)
(RENDEZ (CDR LISTA) FUGGVENY) FUGGVENY]
3. feladat
Az UJ-SUBST új definíciójából kiindulva definiáljuk a HANYATOMOS függvényt magasabbrendű függvény segítségével!
(DEFUN HANYATOMOS (LISTA)
(COND ((NULL LISTA) 0)
((ATOM LISTA) 1)
(T (APPLY (FUNCTION PLUS)
(MAPCAR LISTA
(FUNCTION HANYATOMOS]
4. feladat
Definiáljuk újra magasabbrendű függvények segítségével a 4.4. szakaszban szereplő TOROL függvényt!
(DEFUN TOROL (CSOMAG RAKTAR)
(COND ((NLISTP RAKTAR) RAKTAR)
(T (MAPCAR (REMOVE CSOMAG RAKTAR)
(FUNCTION (LAMBDA (AL-RAKTAR)
(TOROL CSOMAG AL-RAKTAR]
5. feladat
Definiáljuk a 4.4. szakaszban bevezetett MILYEN-MELY függvényt magasabbrendű függvények segítségével!
(DEFUN MILYEN-MELY (LISTA)
(COND ((NLISTP LISTA) 0)
(T (ADD1 (LEGNAGYOBB (MAPCAR LISTA (FUNCTION MILYEN-MELY]A LEGNAGYOBB segédfüggvény argumentuma egy lista, a függvény értéke a lista maximális eleme. A segédfüggvényt a 7.3.3. pontban definiáltuk a MAPCAR segítségével; a következőkben egy egyszerűbb, rekurzív definíciót adunk:
(DEFUN LEGNAGYOBB (L)
(COND ((NULL (CDR L)) (CAR L)) ;Egyelemü lista
((GREATERP (CAR L) (LEGNAGYOBB (CDR L))) (CAR L))
(T (LEGNAGYOBB (CDR L]
6. feladat
Írjuk le az ÚJ-MAPC egy lehetséges definícióját!
(DE UJ-MAPC (LISTA FUGGVENY)
(COND ((NULL LISTA) NIL)
(T (APPLY FUGGVENY (LIST (CAR LISTA)))
(UJ-MAPC (CDR LISTA) FUGGVENY]
7. feladat
Definiáljuk a MINDEN-ATOMRA-ALKALMAZD függvényt! Ez egy lista minden szintjén szereplő atomokon elvégez egy meghatározott műveletet, és az értékek listáját adja eredményül, pl.
* (MINDEN-ATOMRA-ALKALMAZD '(1 (2 3) ((4 5) (6 7) 8))
(FUNCTION ADD1))
(2 (3 4) ((5 6) (7 8) 9))(DEFUN MINDEN-ATOMRA-ALKALMAZD (LISTA FUGGVENY)
(COND ((NULL LISTA) NIL)
((NLISTP LISTA) (APPLY FUGGVENY (LIST LISTA)))
(T (MAPCAR LISTA (FUNCTION (LAMBDA (ELEM)
(MINDEN-ATOMRA-ALKALMAZD ELEM FUGGVENY]
8. feladat
Írjunk olyan függvényt, amely csak abban különbözik az előző feladatban szereplő MINDEN-ATOMRA-ALKALMAZD függvénytől, hogy nem őrzi meg az eredeti listaszerkezetet, hanem a kapott függvényértékeket egy lista legfelső szintjén gyűjti össze:
* (MINDEN-ATOMRA-ALKALMAZD-2 '(1 (2 3) ((4 5) (6 7) 8))
(FUNCTION ADD1))
(2 3 4 5 6 7 8 9)(DE MINDEN-ATOMRA-ALKALMAZD-2 (LISTA FUGGVENY)
(COND ((NULL LISTA) NIL)
((NLISTP LISTA) (APPLY FUGGVENY (LIST LISTA)))
((LISTP (CAR LISTA))
(APPEND (MINDEN-ATOMRA-ALKALMAZD-2 (CAR LISTA) FUGGVENY)
(MINDEN-ATOMRA-ALKALMAZD-2 (CDR LISTA) FUGGVENY)))
(T (CONS (APPLY FUGGVENY (LIST (CAR LISTA)))
(MINDEN-ATOMRA-ALKALMAZD-2 (CDR LISTA) FUGGVENY]Egyszerűbben is megoldhatjuk a feladatot, ha a 4.4. szakaszban megismert IRON függvényt alkalmazzuk (figyeljük meg, hogy a fenti definíció ugyanolyan szerkezetű, mint az UJ-IRON 4.4. szakaszbeli definíciója):
(DE MINDEN-ATOMRA-ALKALMAZD-2 (LISTA FUGGVENY)
(IRON (MINDEN-ATOMRA-ALKALMAZD LISTA FUGGVENY)))
9. feladat
A 7.2.2. pontban megismertük a SOME függvényt. Definiáljuk az UJ-SOME függvényt!
(DE UJ-SOME (LISTA PREDIKATUM)
(AND LISTA
(OR (APPLY PREDIKATUM (LIST (CAR LISTA)))
(UJ-SOME (CDR LISTA) PREDIKATUM]
10. feladat
Definiáljuk az ELSO-NEM-NIL függvényt! Első argumentuma egy lista, a második egy függvény. Értéke a lista első olyan eleme, amelyre a függvényt alkalmazva az érték nem NIL. Ha ilyen elem nincs, az érték NIL.
Feltételezve, hogy általánosított feltételes kifejezést használhatunk:
(DE ELSO-NEM-NIL (LISTA PREDIKATUM)
(COND ((NULL LISTA) NIL)
((APPLY PREDIKATUM (LIST (CAR LISTA))))
(T (ELSO-NEM-NIL (CDR LISTA) PREDIKATUM]Egy másik lehetséges definícióban munkaváltozót használunk:
(DEFUN ELSO-NEM-NIL (LISTA PREDIKATUM MUNKA)
(COND ((NULL LISTA) NIL)
((SETQ MUNKA (APPLY PREDIKATUM (LIST (CAR LISTA)))) MUNKA)
(T (ELSO-NEM-NIL (CDR LISTA) PREDIKATUM]
11. feladat
Definiáljuk az UJ-MAPCON függvényt! Ennek két argumentuma van, egy lista és egy függvény. Alkalmazásakor a második argumentum - a függvény - a listára, a lista farkára, a lista farkának farkára és így tovább alkalmazódik. A MAPCON az értékeket az NCONC függvény alkalmazásával fűzi egy listába - akárcsak a MAPCAN -, a MAPCON értéke az így létrejött lista.
(DEFUN UJ-MAPCON (LISTA FUGGVENY)
(COND ((NULL LISTA) NIL)
(T (NCONC (APPLY FUGGVENY (LIST (LISTA))
(UJ-MAPCON (CDR LISTA) FUGGVENY]
8. A lokális értékek nyilvántartásáról
A 3. fejezetben megtanultuk, hogy a változók lambdakötésben kapott ún. lokális értéke csak az adott függvény alkalmazása során van érvényben, az alkalmazás után ezek a változók visszakapják előző lokális vagy globális értéküket (ha volt ilyen egyáltalán). Ennek a fejezetnek az első részében arról szólunk, hogyan tárolja és könyveli a LISP rendszer egy változó különböző lokális értékeit. Foglalkozunk mindezek fontosabb következményeivel is.
Végül olyan eszközöket ismerünk meg, amelyekkel már kiértékelés közben sokkal részletesebben tekinthetünk bele a LISP könyvelésébe.
8.1. A lokális értékek könyvelése
8.1.1. A paraméterverem
A tárnak azt a részét, amelyben a LISP a szimbólumok lokális értékét és a könyvelésükhöz szükséges információt tárolja, paraméterveremnek nevezzük. A veremtár általában olyan tárat jelent, amelynek mindig csak a legfelső "rekesze" hozzáférhető, az alatta levőket csak akkor olvashatjuk el, ha a legfelső rekeszt már eltávolítottuk. A LISP-ben a paraméterverem minden rekesze egy alkalmazandó függvényt és a függvény lambdaváltozóinak kötését tartalmazza, vagyis azt, hogy milyen lokális értéket kell a kiértékelés kezdetén az egyes lambdaváltozókhoz rendelni. Ezeket a rekeszeket a LISP-ben függvényblokkoknak (vagy röviden blokkoknak) nevezzük. A paraméterverem ún. LIFO tár (az angol "last in - first out" rövidítése; jelentése kb.: "aki utoljára jött be, az megy ki először"). Ez azt jelenti, hogy az új függvényblokkok a paraméterverem tetejére kerülnek. Mindig a legutoljára létrehozott függvényblokk van a paraméterverem tetején, és ezt kell először eltávolítani ahhoz, hogy a mélyebben levő blokkok tartalmához hozzáférhessen az értelmezőprogram.
Az értelmezőprogram minden függvényalkalmazásnál létrehoz egy függvényblokkot. Abban a pillanatban, amikor megkezdődik egy kiértékelendő S- kifejezés beolvasása, a paraméterverem még üres, egyetlen változónak sincs lokális értéke. Ha a beolvasott S-kifejezés lista, és első eleme egy függvénynév (amelyhez egy nem lefordított függvény definíciója tartozik) vagy egy lambdakifejezés, létrejön az első blokk, amely a kiértékelés befejezéséig a paraméterverem legalsó blokkja marad.
Tegyük fel, hogy érvényben van a FAKTORIALIS függvénynek a 3.5. szakaszban adott definíciója! Ekkor
(DEFUN FAKTORIALIS (N)
(COND ((ZEROP N) 1)
(T (TIMES N (FAKTORIALIS (SUB1 N]
és tegyük fel, hogy az értelmezőprogram a (FAKTORIÁLIS 2) kiértékelendő S- kifejezést olvassa be! A kiértékelés kezdetén a paraméterverem üres. Ekkor - szokásos kifejezéssel élve - azt mondhatjuk, hogy a (FAKTORIALIS 2) a kiértékelés legfelső szintjén kiértékelendő forma. A (FAKTORIALIS 2) kiértékelésekor az első létrehozott függvényblokkot így ábrázolhatjuk:
n=2
FAKTORIALIS (1. blokk)
A blokk felső részében mindig a lambdaváltozók kötéseit tüntetjük fel (itt csak egy kötés van, az N lambdaváltozóhoz a 2 érték rendelődik hozzá); az alsó részben pedig annak a függvénynek a nevét, amelynek alkalmazása alatt az illető változókötések érvényben vannak.
Rekurzívan definiált függvényeknél (mint amilyen a FAKTORIALIS is), az egyre újabb (egyre feljebb levő) blokkok az egyre "egyszerűbb" eseteknek felelnek meg. Kövessük végig, mit tartalmaz a paraméterverem a (FAKTORIALIS 2) kiértékelésének különböző szakaszaiban! A FAKTORIALIS első rekurzív alkalmazása előtt (amíg a paraméterveremben csak az 1. blokk található), az N változó értéke (az 1. blokknak megfelelően) 2. Ezért a (ZEROP N) megállási feltétel nem teljesül; a feladatot visszavezetjük a (FAKTORIALIS 1) feladatra. Ez újabb lambdakötéssel jár: a FAKTORIALIS második alkalmazásának idejére az N lambdaváltozóhoz az 1 érték rendelődik hozzá:
n=1
FAKTORIALIS (2. blokk)n=2
FAKTORIALIS (1. blokk)
Mindaddig, ameddig a 2. blokk meg nem szűnik, - vagyis amíg az értelmezőprogram ki nem értékelte a (FAKTORIALIS N) formát -, N értéke 1; mivel veremtárról van szó, az N változó előző kötése mindaddig hozzáférhetetlen, ameddig a 2. blokk létezik. A rekurzív függvényalkalmazásnak LIFO tár segítségével való könyvelése éppen azért lehetséges, mert a rekurzió lényegéből következik, hogy az egyszerűbb feladat megoldásánál a bonyolultabb eseteket nem kell ismerni.
A következő lépésben a (ZEROP N) feltétel ismét nem teljesül, hiszen az N lokális értéke 1, ezért a feladatot a "legegyszerűbb" (FAKTORIÁLIS 0) forma kiértékelésére vezetjük vissza. Újabb függvényblokk jön létre:
n=0
FAKTORIALIS (3. blokk)n=1
FAKTORIALIS (2. blokk)n=2
FAKTORIALIS (1. blokk)
Amikor a (FAKTORIALIS 0) kiértékelése lezajlott, az értelmezőprogram eltávolítja a 3. blokkot:
n=1
FAKTORIALIS (2. blokk)n=2
FAKTORIALIS (1. blokk)
Most "kapta vissza" N az 1 értéket. A TIMES függvény tehát az (1 1) argumentumlistára alkalmazódik. A kapott érték a (FAKTORIALIS 1) értéke, tehát a 2. blokkot is el kell távolítani:
n=2
FAKTORIALIS (1. blokk)
N lokális értéke ismét 2, a TIMES tehát a (2 1) argumentumlistára alkalmazódik, a kiértékelés befejeződött. Az értelmezőprogram a legalsó blokkot is eltávolítja, a paraméterverem kiürül, visszatértünk a kiértékelés legfelső szintjére.
Mivel a COND, a ZEROP, a TIMES és a SUB1 függvények lefordított függvények, az ő alkalmazásukkor nem történik lambdakötés, hiszen definíciójuk a tárban nem lambdakifejezés formájában, hanem a számítógépen közvetlenül lefuttatható (bináris) programként tárolódik. Ezért ezeknek a függvényeknek az alkalmazásakor nem jön létre függvényblokk a paraméterveremben; alkalmazásuk sorrendjét az értelmezőprogram a tár egy másik részében tartja nyilván, amellyel azonban itt nem foglalkozunk.
Láthattuk, hogy egy változó kiértékelésekor a LISP rendszer a paraméterveremben található változókötéseket vizsgálja meg, mégpedig felülről lefelé. Pl. a (ZEROP N) megállási feltétel vizsgálatához - mivel a ZEROP eval-típusú függvény - ki kellett értékelni az N változót; a ZEROP függvényt N lokális értékére kell alkalmazni, a lokális értéket pedig mindig a változó legutoljára létrehozott kötése határozza meg. Amikor kiürül a paraméterverem, és visszakerülünk a legfelső szintre, az N-nek nincs lokális értéke; ha van globális értéke, ezt "visszakapja".
A paramétervermet nem lehet a végtelenségig növelni: egy önmagát végtelen sokszor újra hívó függvény hívása folyamatosan növeli a vermet, és hibához vezet. Ez bekövetkezhet azért, mert a függvény definíciója nem tartalmaz megállási feltételt (ld. a 3.5. szakaszt):
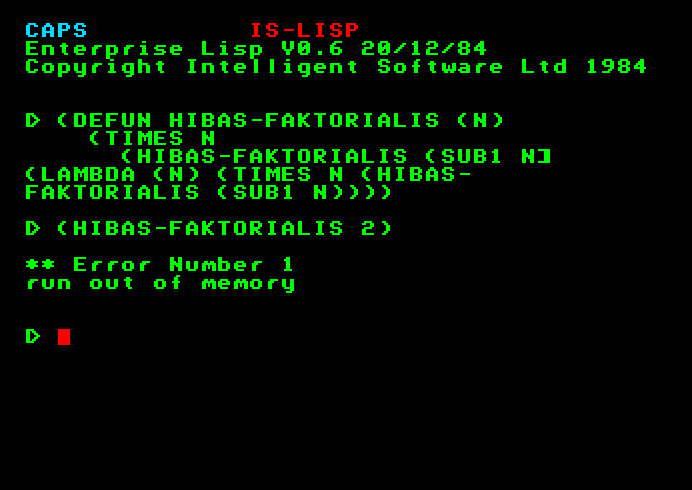
ami azt jelenti, hogy a paraméterverem "túlcsordult". N értéke ebben a pillanatban (a paraméterverem méretétől függő) nagy abszolút értékű negatív szám. Túlcsorduláshoz vezethet az is, ha a függvény definíciójában van ügyan megállási feltétel, de az argumentum megválasztása miatt soha nem teljesülhet:
* (FAKTORIALIS -3)
A túlcsordulás pillanatában N értéke ismét egy nagy abszolút értékű negatív szám. Végül úgy is bekövetkezhet túlcsordulás, hogy az alkalmazott függvényben van megállási feltétel, de a rekurzív lépés(ek) hibájából soha nem teljesülhet (ld. 5.3.2. pont):
(DEFUN ROSSZ-UTOLSO (LISTA) ;Nem-eval-típusú!
(COND ((NULL LISTA) NIL)
((ATOM LISTA) LISTA)
((NULL (CDR LISTA)) (CAR LISTA))
(T (ROSSZ-UTOLSO (CDR LISTA] ;Ezért ez a sor hibás!
A túlcsordulás pillanatában a LISTA változónak az értéke a (CDR LISTA) lista; a 2. függvényblokktól kezdve újra és újra ez az érték rendelődött hozzá az újabb és újabb függvény blokkokban (az 1. függvény blokkban az (A B C) érték rendelődött hozzá).
8.2. Az asszociációs listák
Az asszociációs listák fontos szerepet játszanak a LISP rendszer könyvelésében. Az asszociációs listák minden eleme egy-egy változó-érték pár. Az "asszociációs lista" elnevezés onnan származik, hogy benne egy-egy változóhoz egy-egy érték van asszociálva, azaz társítva. Asszociációs listának nevezzük a LISP-ben az olyan listákat, amelyeknek minden egyes eleme pontozott pár. Az asszociációs lista elemei tehát listák is lehetnek; ne feledjük, hogy a lista a pontozott pár speciális esete! Az egyes listaelemek feje és farka alkotja a változó-érték párokat.
A LISP rendszerek általában egyetlen asszociációs lista formájában külön is tárolják a paraméterveremben található változókötéseket. Amikor a (FAKTORIALIS 2) kiértékelése során az N változó értéke 0, a paraméterveremhez tartozó asszociációs lista ilyen:
((N . 0) (N . 1) (N . 2))
Az asszociációs listán balról jobbra (az elejétől a vége felé) haladva helyezkednek el az N változó kötései. Az N változó éppen érvényben levő kötése az első ilyen pár, N lokális értéke a fenti asszociációs lista szerint éppen 0.
Az asszociációs listák kezelésének megkönnyítésére a LISP-ben külön beépített függvények szolgálnak, ami érthető, hiszen a rendszer is ezen függvények segítségével kezeli saját asszociációs listáit. Az asszociációs listákat kezelő függvények között a legegyszerűbb a SASSOC. Két argumentuma van, az első egy tetszőleges S-kifejezés, a második olyan S-kifejezés, amelynek értéke egy asszociációs lista:
(SETQ ASSZOCIACIOSLISTA
'((FINNORSZAG . HELSINKI)
(NORVEGIA . OSLO)
(SVEDORSZÁG . STOCKHOLM)))
((FINNORSZAG . HELSINKI) (NORVEGIA . OSLO) (SVEDORSZAG . STOCKHOLM))* (SASSOC 'NORVEGIA ASSZOCIACIOSLISTA)
(NORVEGIA . OSLO)
A SASSOC tehát a megadott asszociációs lista első olyan elemét adja eredményül, amelynek feje megegyezik az első argumentum értékével. Azért az első ilyen elem az érték, mert ez felel meg az utolsó "változókötésnek". A "megegyezik" szót úgy kell érteni, hogy a nyomtatási képük egyezik meg. Tehát a SASSOC akkor is alkalmazható, ha listát keresünk az asszociációs listában: a SASSOC az EQUAL függvény alkalmazásával végzi az összehasonlítást:
* (SASSOC '(A B) '((A . B) ((A B) . C) (D E)))
((A B) . C)
Létezik egy másik függvény, az ASSOC, amely az összehasonlítást az EQ függvénnyel végzi:
* (ASSOC '(A B) '((A . B) ((A B) . C) (D E)))
NIL* (ASSOC 'D '((A . B) ((A B) . C) (D E)))
(D E)
Amikor az értelmezőprogram a paraméterveremben egy változó utolsó kötését keresi, az ASSOC függvényt használja.
Asszociációs listát használhatunk a már többször vizsgált (ld. a 4.1., az
5.1., a 7.1. és a 7.4. szakaszokat) térkép-ábrázolási feladat megoldására is. Most nem páronként tároljuk a szomszédos országokat, mint a 4.1. szakaszban, hanem egy-egy allistában helyezzük el az országot és az összes szomszédját. Az allisták első elemei az egyes országok, a további elemek pedig a hozzájuk tartozó szomszédok:
* (SETQ EUREPA '((A H YU I CH D CS) ...)
((A H YU I CH D CS) ...)
A térképet leíró asszociációs listában minden pontozott pár feje egy ország, farka a vele szomszédos országok listája. A SZOMSZEDAI4 függvény ekkor tehát az ASSOC ismeretében ilyen egyszerűen definiálható:
(DEFUN SZOMSZEDAI4 (ORSZAG TERKEP)
(CDR (ASSOC ORSZAG TERKEP)))* (SZOMSZEDAI4 'A EUROPA)
(H YU I CH D CS)
8.3. A formák kiértékelésének környezete
Egy forma kiértékelésének környezete nem más, mint az összes változókötés a forma kiértékelésének megkezdésekor, vagyis az az asszociációs lista, amely a paraméterverem változókötéseit tartalmazza.
Vannak esetek, amikor azt szeretnénk, hogy egy forma értékét ne befolyásolja az, hogy milyen forma kiértékelése során értékelődik ki. Ezt úgy érhetjük el, hogy a kiértékelés előtt új blokkot hozunk létre a paraméterverem tetején (vagyis a paraméterverem asszociációs listájának elejére új párokat illesztünk), és ezzel meggátoljuk, hogy az értelmezőprogram az előző kötésekhez hozzáférjen. Így felülbírálhatjuk a forma kiértékelésének környezetét.
Erre az EVALA függvényt használhatjuk (IS-LISP-ben nincs implementálva). Ez az EVAL-tól csak abban különbözik, hogy van egy második argumentuma is, amelynek értéke egy asszociációs lista.
* (EVALA '(CONS A B) '((A . FEJE) (B FARKA)))
(FEJE FARKA)
A fenti forma kiértékelésekor a (CONS A B) úgy értékelődik ki, hogy A és B paraméterverembeli esetleges más, létező kötésétől vagy globális értékétől függetlenül az A a FEJE, a B pedig a (FARKA) értéket veszi fel. Vagyis az EVALA kiértékelése úgy kezdődik, hogy a második argumentum értéke kerül a paraméterverem tetejére. A kiértékelés befejezésekor ezek a változókötések a paraméterveremből eltűnnek.
Könnyedén definiálhatjuk az UJ-EVALA függvényt, ha felidézzük, amit a 8.1.1. pontban megtanultunk: minden függvényalkalmazás új blokkot hoz létre a paraméterveremben. A definícióban felhasználjuk, hogy a LISP-ben a programok és az adatok azonos szerkezetűek. A függvény első argumentumából létrehozunk egy olyan függvényt, amelynek a törzse ezt az argumentumot tartalmazza, lambdaváltozói pedig az asszociációs listában található változók, majd az így kapott függvényt alkalmazzuk az asszociációs listában levő értékek listájára:
(DEFUN UJ-EVALA (FORMA A-LISTA)
(APPLY (LIST 'LAMBDA
(MAPCAR A-LISTA (FUNCTION CAR)) ;A változók
FORMA)
(MAPCAR A-LISTA (FUNCTION CDR] ;Az értékek
Vagyis az EVALA alkalmazását bemutató fenti példánk a következő kiértékeléssel egyenértékű:
* (APPLY '(NLAMBDA (A B) (CONS A B)) '(FEJE (FARKA)))
(FEJE FARKA)
Az EVALA függvény segítségével - és általában azokkal a függvényekkel, amelyeknek argumentumai között a paraméterverem tetejére helyezendő asszociációs lista van - egy változóban megőrzött környezetet később újra használhatunk. Tegyük fel, hogy egyes atomokkal tárgyakat írunk le, az atomok tulajdonságlistáján helyezzük el a tárgyak különböző fizikai jellemzőit:
* (PUT 'TARGY1 'FAJSULY 15)
15* (PUT 'TARGY1 'TERFOGAT 200)
200
Ezek után definiáljuk a SULY függvényt, amely egy tárgy fajsúlyából és térfogatából kiszámítja a tárgy súlyát:
(DE SULY (TGY)
(TIMES (GETP TGY FAJSULY) (GETP TGY TERFOGAT)))* (SULY 'TARGY1)
3000
Ennél a módszernél egyszerűbb, ha a TARGY1 atom tulajdonságlistáján a JELLEMZOK attribútumhoz tartozó tulajdonságként tárolunk egy asszociációs listát, amely a fizikai jellemzőit ábrázolja:
* (PUT 'TARGY1 'JELLEMZOK '((FAJSULY . 15) (TERFOGAT . 200)))
((FAJSULY . 15) (TERFOGAT . 200))
Ezek után a SÚLY függvény így definiálható:
(DEFUN SULY (TGY)
(EVALA '(TIMES FAJSULY TERFOGAT) (GET TGY 'JELLEMZOK)))* (SULY 'TARGY1)
3000
Az új függvénydefinícióban csak egyszer kellett alkalmaznunk a GET függvényt. Ezt a módszert különösen akkor érdemes alkalmazni, ha mind az attribútumok neve, mind a hozzájuk rendelt tulajdonságok sokszor változnak, ami a PUT és a GET alkalmazását igen nehézkessé teszi.
Az EVALA-hoz hasonló, környezetet létrehozó függvény a LET (IS-LISP-bennincs implementálva). Alkalmazásának általános alakja:
(LET ((változó1 skif1)
...
(változóm skifm))
forma1
forma2
...
forman)
A LET alkalmazásának mellékhatása, hogy a formák kiértékelődnek; a függvényérték az utolsó forma értéke. Ebből a szempontból tehát a LET a PROGN-hez hasonlóan működik (ld. 5.3.1. pont). A különbség pusztán annyi, hogy ezek a formák az első argumentumban meghatározott változókötések mellett értékelődnek ki. Fontos különbség az EVALA-hoz képest, hogy a LET első argumentuma nem asszociációs lista, változói-hez skifi értéke rendelődik hozzá.
Egy egyszerű példa a LET használatára: a CIKLIKUS-PERMUTALTAK függvény egy lista elemeinek azon permutációit állítja elő, amelyek az elemek sorrendjének megváltoztatása nélkül kaphatók meg (feltéve, hogy úgy tekintjük, hogy az utolsó elemet az első követi):
(DEFUN CIKLIKUS-PERMUTALTAK (LISTA)
(CIKLIKUS-PERM-SEGED (LENGTH LISTA) LISTA))(DEFUN CIKLIKUS-PERM-SEGED (N L)
(COND ((ZEROP N) NIL)
(T (LET ((PERMUTALT (LTOLASE L)))
(CONS PERMUTALT
(CIKLIKUS-PERM-SEGED (SUB1 N) PERMUTALT]* (CIKLIKUS-PERMUTALTAK '(A B C D))
((B C D A) (C D A B) (D A B C) (A B C D)
A definícióban felhasznált LTOLASE függvényt a 4.7. szakasz 1. feladatának megoldásaként definiáltuk. Megjegyezzük, hogy a CIKLIKUS-PERMUTALTAK segítségével a PERMUTAL függvényre sokkal elegánsabb definíciót adhatunk, mint a 4.7. szakasz 5. feladatának megoldásában. Egy lista elemeinek összes permutációját ugyanis úgy is megkaphatjuk, hogy előállítjuk a ciklikus permutáltak listáját, majd ennek minden egyes elemére meghatározzuk a farok összes permutációját:
(DEFUN PERMUTAL (LISTA)
(MAPCAPP (CIKLIKUS-PERMUTALTAK LISTA)
(FUNCTION (LAMBDA (PERMUTALT)
(MAPCAR (PERMUTAL (CDR PERMUTALT))
(FUNCTION (LAMBDA (PERMUTALT-FAROK)
(CONS (CAR PERMUTALT) PERMUTALT-FAROK]
8.4. A FUNCTION és a FUNARG-kifejezések
Ebben a szakaszban olyan kérdéseket tárgyalunk, amelyek erősen kötődnek az egyes LISP változatokhoz. Ha a FUNCTION függvényt csak úgy használjuk, ahogy a 7.1. szakaszban leírtuk, akkor az alábbi kérdésekkel nem kerülünk szembe. Ezért a könyv első olvasásakor ezt a szakaszt "átugorhatjuk".
Térjünk vissza a FUNCTION függvényhez, amelyet már alkalmaztunk, de nem ismertettünk részletesen. Azt mondtuk, hogy hibához vezethet, ha FUNCTION helyett a QUOTE-ot használjuk egy argumentumként szereplő függvény kiértékelésének megtiltására. Azt viszont nem mondtuk meg, miben áll ez a hiba, és mikor következhet be.
A 7.1.1. pontban az APPLY függvény bevezetésekor a FUGGVÉNY változóhoz a NÉGYZET szimbólumot rendeltük:
* (SETQ FUGGVENY 'NEGYZET)
NEGYZET
Vizsgáljuk meg, mi történik, ha az értékadásnál QUOTE helyett FUNCTION-t alkalmazunk:
* (SETQ FUGGVENY (FUNCTION NEGYZET))
(FUNARG NEGYZET)
A FUNCTION függvény értéke egy funarg-kifejezés, olyan lista, amelynek első eleme a FUNARG szimbólum (ez nem függvénynév!), második eleme pedig a FUNCTION argumentuma. Ugyanilyen szerkezetű a FUNCTION értéke akkor is, ha lambdakifejezésre alkalmazzuk:
* (SETQ FUGGVENY (FUNCTION (LAMBDA (X) (TIMES X X))))
(FUNARG (LAMBDA (X) (TIMES XX)))
Ha abban a függvényben, amelyre a FUNCTION-t alkalmazzuk - függvénynév esetén a hozzá tartozó definícióban, lambdakifejezés esetén magában a lambdakifejezésben - nincsenek szabad változók, akkor a függvénynév, ill. lambdakifejezés teljesen egyenértékű a neki megfelelő funarg-kifejezéssel:
* (APPLY 'NEGYZET '(5))
25* (APPLY (FUNCTION NEGYZET) '(5))
25* (APPLY '(LAMBDA (X) (TIMES XX)) '(5))
25* (APPLY (FUNCTION (LAMBDA (X) (TIMES XX))) '(5))
25
Ha azonban a függvénynévhez tartozó definícióban ill. a lambdakifejezésben szabad változó szerepel, a QUOTE és a FUNCTION értéke gyökeresen eltér egymástól:
* (SETQ KUSZOB 10)
10* (SETQ QUOTE-TUL-NAGY
(QUOTE (LAMBDA (SZAM) (GREATERP SZAM KUSZOB]
(LAMBDA (SZAM) (GREATERP SZAM KUSZOB))
* (SETQ FUNCTION-TUL-NAGY
(FUNCTION (LAMBDA (SZAM) (GREATERP SZAM KUSZOB]
(FUNARG (LAMBDA (SZAM) (GREATERP SZAM KUSZOB)) ((KUSZOB . 10)))
Abban a lambdakifejezésben, amelyre az első esetben a QUOTE-ot, a másodikban pedig a FUNCTION-t alkalmaztuk, a KÜSZÖB szabad változó. A QUOTE értékében nincs semmi meglepő; a FUNCTION értéke viszont nem olyan kételemű funarg-kifejezés, mint azok, amelyeket előbbi példáinkban láttunk, van egy harmadik eleme is. A harmadik listaelem egy asszociációs lista, amely ebben az esetben egyetlen változókötést tartalmaz, mert a lambdakifejezésben egyetlen szabad változó volt. A funarg-kifejezés általános alakja tehát
(FUNARG függvénynév asszociációs-lista)
ahol függvénynév helyett a funarg-kifejezésben lambdakifejezés is állhat, az asszociációs lista pedig a függvénydefinícióban vagy lambdakifejezésben található szabad változók kötéseit tartalmazza a FUNCTION alkalmazásának pillanatában.
A fenti példában szereplő QUOTE-TUL-NAGY és FUNCTION-TUL-NAGY változók értéke nemcsak formájában különbözik, de alkalmazásuk sem egyenértékű:
* (SETQ KUSZOB 5)
5* (APPLY QUOTE-TUL-NAGY '(8))
T* (APPLY FUNCTION-TUL-NAGY '(8))
NIL
A QUOTE-TUL-NAGY értékében szereplő KUSZOB szabad változónak az értékét az értelmezőprogram a szokásos módon állítja elő: az APPLY alkalmazásakor a KUSZOB értéke 5, ezért a függvényérték T, hiszen a 8 nagyobb, mint az 5. A FUNCTION-TUL-NAGY alkalmazásakor azonban az értelmezőprogram a funarg- kifejezésben szereplő asszociációs lista alapján állapítja meg a szabad KUSZOB változó értékét; ez az érték 10. Ezért az APPLY értéke NIL, hiszen a 8 nem nagyobb, mint a 10.
Összefoglalva: ha az alkalmazott függvény (ill. függvény név esetén az ehhez tartozó definíció) lambdakifejezés, akkor a benne található szabad változók a függvény alkalmazásának környezetében értékelődnek ki. Ha viszont funarg-kifejezést alkalmazunk, vagy olyan függvényt, amelynek definíciója funarg-kifejezés, akkor a függvénytörzsben szereplő szabad változók a funarg-kifejezés létrehozásának (a FUNCTION alkalmazásának) pillanatában vett környezet szerint értékelődnek ki. Az általunk leírt LISP-változatban tehát a FUNCTION szerepe az, hogy lehetővé teszi olyan függvények létrehozását, amelyeknek alkalmazásakor az értelmezőprogram - az általános szabálytól eltérően - a szabad változók értékét lexikálisán határozza meg.
A függvény-argumentumok alkalmazási környezetének most bemutatott problémáját a LISP-ben funarg-problémának nevezzük. A FUNCTION alkalmazásával érjük el, hogy a függvény-argumentum a megfelelő környezetben kerüljön alkalmazásra.
Az előzőekből az következik, hogy a QUOTE és a FUNCTION nemcsak akkor egyenértékűek, ha az argumentumukban nem szerepel szabad változó, hanem akkor is, ha alkalmazásuk és értékük alkalmazása ugyanabban a környezetben történik. Ezért az általunk ismertetett LISP változatban a legtöbbször nem vezet hibához az, ha magasabbrendű függvények függvény-argumentumára nem a FUNCTION, hanem a QUOTE függvényt alkalmazzuk. Pontosabban: a magasabbrendű függvények függvényargumentumára a QUOTE alkalmazása csak akkor vezethet hibához, ha a QUOTE alkalmazása és a függvény-argumentum alkalmazása között a függvény-argumentumban található szabad változók értéke megváltozhat:
(DEFUN UJ-INTERSECTION (HALMAZ1 HALMAZ2)
(AZOK HALMAZ1 '(LAMBDA (ELEM) (MEMBER ELEM HALMAZ2]
Ebben az új definícióban az AZOK függvény második argumentumában a lambdakifejezésre nem a FUNCTION, hanem a QUOTE függvényt alkalmazzuk. Ez azonban nem vezethet hibához, mert a lambdakifejezésben szereplő HALMAZ2 szabad változó értéke nem változik meg a QUOTE alkalmazása és a lambdakifejezés alkalmazása között.
Ennek ellenére a biztonságos megoldás az, ha a magasabbrendű függvények argumentuma mindig funarg-kifejezés. Ezt azért hangsúlyozzuk újra és újra, mert a FUNCTION használata megóvja a felhasználót egy súlyos veszélytől, a változónevek egybeesésének káros következményeitől. Tekintsük a következő definíciót:
(DEFUN Q-KIVUL-VAN (SZAM KUSZOB)
(OR (APPLY QUOTE-TUL-NAGY (LIST SZAM))
(LESSP SZAM KUSZOB)))
A Q-KIVUL-VAN függvény értéke T, ha az első argumentum kisebb, mint a második, vagy "túl nagy", vagyis ha a QUOTE-TUL-NAGY értékét (egy predikátumot) a SZAM-ra alkalmazva a függvényérték nem NIL. Igen ám, de a QUOTE-TUL-NAGY értékében történetesen szerepel a KUSZOB szabad változó. Mivel pedig a QUOTE-TUL-NAGY értéke nem funarg-kifejezés, hanem lambdakifejezés (a QUOTE, nem pedig a FUNCTION segítségével hoztuk létre); a benne szereplő szabad változó értékét alkalmazásának a környezete határozza meg. Az alkalmazás pillanatában azonban a KUSZOB változó lokális értékkel rendelkezik (hiszen ez a Q-KIVUL-VAN második lambdaváltozója)! A QUOTE-TUL-NAGY értékében szereplő szabad változó tehát kötötté vált pusztán attól, hogy neve egybeesik az alkalmazási környezet egyik lambdaváltozójának nevével:
* (SETQ KUSZOB 10)
10* (Q-KIVUL-VAN 5 -6)
T
Bár az 5 a -6 és a 10 közé esik, a Q-KIVUL-VAN értéke T. A változónevek nemkívánatos egybeesését funarg-kifejezés használatával elkerülhetjük:
(DEFUN F-KIVUL-VAN (SZAM KUSZOB)
(OR (APPLY FUNCTION-TUL-NAGY (LIST SZAM))
(LESSP SZAM KUSZOB)))* (F-KIVUL-VAN 5 -6)
NIL
8.5. A kiértékelés félbeszakítása
A kiértékelés félbeszakítása hibakeresésre használható, sok lehetőséget ad a LISP könyvelésbe való betekintésre. (Az IS-LISP-ben sajnos ezek a lehetőségek nincsenek implementálva.) Egy forma kiértékelésének szünetében nemcsak az éppen alkalmazott függvény argumentumait ellenőrizhetjük, hanem más változók értékét is, sőt, akár az egész paramétervermet is megvizsgálhatjuk. Ráadásul tetszőleges formát is kiértékeltethetünk, és így a változók értékeit is megváltoztathatjuk. A kiértékelés félbeszakítása nem minden LISP rendszerben lehetséges - valójában csak interaktív használat esetén van értelme - , de ahol mód nyílik rá, ott sem feltétlenül ugyanazok a lehetőségek. Ezért a következőkben leírtaktól a különböző LISP rendszerek igen nagy mértékben eltérhetnek.
A BREAK nevű akárhány-argumentumú, nem eval-típusú LISP függvény (IS-LISP-ben nincs implementálva) argumentumai függvénynevek, mellékhatása pedig az, hogy az illető függvények legközelebbi (és minden további) alkalmazásakor a kiértékelés megszakad, és ekkor betekinthetünk a LISP könyvelés részleteibe. A kiértékelés szünetében - ha nem változtatjuk meg - minden részeredmény érintetlenül megmarad. A kiértékelést újra megindíthatjuk, és az attól a ponttól folytatódik, ahol félbeszakadt.
A szünet megkezdését egyrészt üzenet jelzi ("FAKTORIALIS felfüggesztve"), másrészt a felszólítójel megváltozása (feltételezzük, hogy a szünetben a felszólítójel a kettőspont). Az N kötött változó értéke - erről az N forma kiértékelésével megbizonyosodhatunk - ebben a pillanatban 3.
A kiértékelés újraindítása az OK paranccsal történik.Fontos, hogy az OK nem függvény, hanem parancs, amely csak a kiértékelés szünetében adható ki. Tudjuk, hogy parancsok a LISP-ben nem léteznek, de a kiértékelés szünetében voltaképpen kilépünk az értelmezőprogram körforgásából. Az OK parancs tehát arra szolgál, hogy a félbeszakadt kiértékelés folytatódjon.
Arra is van mód azonban, hogy a kiértékelést végleg beszüntessük. Ehhez az kell, hogy a paraméterverem tartalmát töröljük, hiszen így visszakerülünk az értelmezőprogram alapállapotába. A paraméterverem törlésére a RESET függvény szolgál (IS-LISP-ben nincs implementálva). A RESET függvénynek nincs argumentuma, sőt értéke sem. A RESET függvényt a leggyakrabban olyankor alkalmazzuk, ha a kiértékelés nem a mi kívánságunkra, hanem valamilyen hiba következtében szakadt félbe (ld. alább, 8.5.3. pont).
Ha nem a RESET függvényt alkalmazzuk, hanem az OK parancsot adjuk ki, a folytatódó kiértékelés ismét félbe fog szakadni, mivel a FAKTORIALIS függvény rekurzívan újra alkalmazódik. A FAKTORIALIS második alkalmazásakor az argumentum 2. Amikor azonban már 0 az N értéke, a FAKTORIALIS függvény többször nem alkalmazódik, mert a megállási feltétel teljesül. Ezért a kiértékelés félbeszakítás nélkül fog folytatódni.
Egy forma kiértékelésének szünetében a paraméterveremben a változók értéke megőrződik mindaddig, amíg OK paranccsal nem folytatjuk a kiértékelést. A kiértékelés szünetében azonban bármilyen formát kiértékeltethetünk (ahogy a fenti példában az N S-kifejezést), de ekkor számolnunk kell azzal, hogy ilyenkor a mellékhatással rendelkező függvények a változók lokális értékét érinthetik. A SETQ alkalmazásával a lokális értéket is megváltoztathatjuk (ezt a 2.1. szakaszban láttuk), és ez befolyásolhatja a kiértékelés újraindítása után kapott eredményt:
* (FAKTORIALIS 3)
- FAKTORIALIS broken
: N
3
:OK- FAKTORIALIS broken
: N
2
: (SETQ N 3)
3
: OK- FAKTORIALIS broken
: N
3
: OK- FAKTORIALIS broken
: N
2- FAKTORIAIS broken
:N
1
: OK- FAKTORIALIS broken
: N
0
: OK
36
Beavatkozásunk miatt az érték nem az eredeti forma, a (FAKTORIALIS 3) értéke lett: a (TIMES 3 2 1) értéke helyett a (TIMES 3 2 3 2 1) forma értéke lett a függvényérték.
8.5.1. A feltételes BREAK
Sok rendszerben a kiértékelés felfüggesztését feltételekhez lehet kötni. A különböző LISP rendszerekben ezek a feltételek rendkívül eltérően adhatók meg. Viszonylag gyakori az a konvenció, hogy a BREAK argumentumai listák is lehetnek, amelyeknek a feje a függvénynév, következő eleme pedig egy S-kifejezés, amelynek értéke igaz vagy hamis lehet. A kiértékelés az adott függvényben csak akkor szakad meg, ha az S-kifejezés értéke (a pillanatnyilag érvényes környezetben kiértékelve) nem NIL:
* (BREAK (FAKTORIALIS (ZEROP N)))
(FAKTORIALIS)* (FAKTORIALIS 3)
- FAKTORIALIS broken
: N
0
Egy másik szokásos konvenció, hogy a BREAK argumentumai olyan listák lehetnek, amelyeknek első eleme függvénynév, második eleme az IN szimbólum, harmadik eleme pedig egy másik függvénynév. A BREAK ilyen alkalmazásának mellékhatása az, hogy a kiértékelés csak akkor szakad félbe, ha az első függvény alkalmazása a második függvény alkalmazása során történt:
* (BREAK (ZEROP IN FAKTORIALIS))
(ZEROP-IN-FAKTORIALIS)* (ZEROP EGEREK-SZÁMA)
NIL* (FAKTORIALIS 3)
- ZEROP broken
: N
3
Az ZEROP első alkalmazásakor a kiértékelés nem szakadt meg, mert a függvényt nem a FAKTORIALIS alkalmazása során alkalmaztuk (hanem a legfelső szinten).
A BREAK-nek a legtöbb LISP rendszerben ugyanolyanok lehetnek az argumentumai, mint a TRACE-nek (és viszont), tehát ha "feltételes BREAK" létezik, akkor általában "feltételes TRACE" is.
8.5.1. Az UNBREAK
Ha megtaláltuk és kijavítottuk a keresett hibát, az UNBREAK függvénnyel elérhetjük, hogy a kiértékelés többé ne szakadjon meg:
* (UNBREAK ZEROP)
(ZEROP-IN-FAKTORIALIS)* (UNBREAK)
(FAKTORIALIS)
Az első esetben egyetlen függvényt "oldottunk fel" a felfüggesztés alól; a második esetben, amikor argumentum nélkül alkalmaztuk az UNBREAK függvényt, az összes felfüggesztett függvényt (itt most csak a FAKTORIALIS-t) feloldottuk.
8.5.3. Amikor nem a felhasználó akarja a szünetet...
Ebben a fejezetben többször is említettük már, hogy a formákat az értelmezőprogram értékeli ki, és az értelmezőprogram alkalmazza a függvényeket az argumentumokra. A 11. fejezetben látni fogjuk, hogy ez a már ismertetett EVAL és APPLY függvények alkalmazásával megy végbe. A legtöbb LISP rendszerben a hibaüzenetek után automatikusan megszakad a kiértékelés; a rendszer ugyanis úgy működik, hogy az EVAL kiértékelőfüggvény, ill. az APPLY alkalmazófüggvény alkalmazása feltételesen felfüggesztődik akkor, ha értékkel nem rendelkező változót, ill. definiálatlan függvényt észlel. Ilyenkor kijavíthatjuk a (pl. gépelési) hibát:

Mivel a FAC szimbólumhoz nem tartozott definíció, az EVAL elkalmazása megszakadt.
Más rendszerekben ilyenkor az az APPLY alkalmazása felfüggesztődik. A kiértékelés szünetében alkalmazhatjuk a DEFUN függvényt, ennek mellékhatásaként a FAC függvény névvé válik, az újraindítás után a kívánt értéket adja a kiértékelés. Ha úgy látjuk, hogy a hiba kijavításával nem érdemes a kiértékelés szünetében próbálkozni, egyszerűen alkalmazzuk a 8.5. szakasz elején megismert RESET függvényt.
8.5.4. Bepillantás a paraméterverembe
Azt az asszociációs listát, amely a LISP rendszerben érvényes változókötéseket tartalmazza, az ALIST függvény argumentum nélküli alkalmazásával kapjuk meg:
* (BREAK FAKTORIALIS)
(FAKTORIALIS)* (FAKTORIALIS 3)
- FAKTORIALIS broken:(ALIST)
((N . 3))
: OK
- FAKTORIALIS broken: (ALIST)
((N . 2) (N . 3))
Az asszociációs lista itt először egy, majd két változókötést tartalmaz. Az N lokális értékét az utolsó változókötés, az asszociációs listában mindig az elsőként szereplő pontozott pár határozza meg, vagyis N értéke az első szünetben 3, a másodikban 2. Ha az ALIST függvényt a kiértékelés legfelső szintjén alkalmazzuk, az érték természetesen NIL, hiszen ilyenkor a paraméterverem üres.
Az ALIST függvényt nemcsak szünetben lehet alkalmazni, azt is lehetővé teszi, hogy egy függvény ellenőrizze, hogy milyen környezetben alkalmaztuk:
(DE FAKTORIALIS-NYOMT (N)
(COND ((ZEROP N) ;A PRINT függvény kinyomtatja az
(PRINT (ALIST)) 1) ; argumentumát (ld. 10.3. szakasz).
(T (PRINT (ALIST))
(TIMES N (FAKTORIALIS-NYOMT (SUB1 N>
A FAKTORIALIS-NYOMT definíciója abban különbözik a FAKTORIALIS-étól, hogy ez a függvény mellékhatásként minden egyes rekurzív alkalmazás előtt (és a megállási feltétel teljesülésekor is), kinyomtatja a paraméterveremhez tartozó asszociációs listát:
* (FAKTORIALIS-NYOMT 3)
((N . 3))
((N . 2) (N . 3))
((N . 1) (N . 2) (N . 3))
((N . 0) (N . 1) (N . 2) (N . 3))
6
A kiértékelés szüneteltetésekor általában mód nyílik a paraméterverem tetszetős formában való kinyomtatására is. A BTV parancs hatására a paraméterverem tartalma kinyomtatódik a képernyőre. A BTV parancs tehát csak a kiértékelés szünetében, terminálról adható ki.
9. A nemrekurzív programozási eszközök
A LISP nyelv alapvető programozási módszere az, hogy rekurzívan definiált függvényeket alkalmazunk argumentumokra. Az imperatív nyelvekben az utasítások végrehajtásának sorrendjét a ciklusutasítások különböző fajtáival és a vezérlésátadási utasításokkal vezérlik. A LISP nyelvben is megtalálhatjuk ezeknek az utasításoknak a megfelelőit, tehát a LISP is tartalmaz nemrekurzív eszközöket. Mivel azonban a LISP funkcionális nyelv, ezeket is függvényként, mégpedig álfüggvényként használhatjuk. A nemrekurzív eszközöket elsősorban azért használják, mert a segítségükkel definiált függvények sokszor kevesebb tárat és futási időt igényelnek, mint rekurzív megfelelőik.
9.1. Egyszerű iteratív függvények
Az iteráció a nemfunkcionális programozási nyelvek egyik legjellemzőbb programozási eszköze. Segítségével a program egy részét többször is végre lehet hajtani.
A LISP-ben azt nevezzük iterációnak, ha egy formát egymás után többször kiértékelünk; és egy meghatározott feltétel teljesülésétől függ, hogy meddig kell a kiértékelést ismételnünk.
9.1.1. A RPT függvény
A legegyszerűbb iteratív függvény a RPT (az IS-LISP-ben nem definiált). Ennek segítségével azt írhatjuk elő, hogy egy S-kifejezés hányszor értékelődjön ki. (Ez a függvény az imperatív nyelvek szóhasználata szerint a számlálós ciklusnak felel meg.) A függvénynek két argumentuma van. Az első argumentum értékének számnak kell lennie, ez határozza meg, hányszor kell elvégezni a kiértékelést, a második argumentum tetszőleges forma lehet. A függvény alkalmazásakor a második argumentum értéke annyiszor értékelődik ki egymás után, amennyi az első argumentum értéke. A függvényérték a második argumentum értékének utoljára kapott értéke lesz. A 4.1. szakaszban rekurzívan definiált UJ-NTH függvényt így definiálhatjuk újra a RPT függvénnyel:
* (DE UJ-NTH (LISTA SZAM)
(RPT (SUB1 SZAM) '(SETQ LISTA (CDR LISTA>
Figyeljük meg, hogy a RPT függvény eval-típusú függvény, ezért alkalmazásakor a második argumentum is kiértékelődik, és az argumentum értéke értékelődik ki ismételten. Ezért alkalmaztuk a fenti példában a QUOTE függvényt a RPT második argumentumának megadásakor.
9.1.2. A WHILE függvény
A WHILE függvény segítségével olyan ciklusokat szervezhetünk, amelyekben a kifejezés mindaddig kiértékelődik, amíg egy feltétel teljesül. A WHILE akárhány-argumentumú, de legalább két argumentumot meg kell adni. Az első argumentum tetszőleges S-kifejezés - ez az iteráció ún. megállási feltétele -, amely mindig kiértékelődik. Ha értéke nem NIL, kiértékelődnek a további argumentumok is, majd ismét az első argumentum értékelődik ki és így tovább. Ez mindaddig ismétlődik, amíg az első argumentum értéke NIL nem lesz, ekkor a kiértékelés befejeződik. A WHILE függvény értéke mindig NIL. Az UJ-MAPC függvényt így definiálhatjuk a WHILE segítségével:
* (DEFUN UJ-MAPC (LISTA FUGGVENY)
(WHILE LISTA
(APPLY FUGGVENY (LIST (CAR LISTA)))
(SETQ LISTA (CDR LISTA]
9.1.3. Az UNTIL függvény
Az UNTIL függvény éppen a WHILE "fordítottja". Argumentumait ugyanúgy kell megadnunk, mint a WHILE argumentumait, de a második és a további argumentumok csak akkor értékelődnek ki, ha az első argumentum - a megállási feltétel - értéke NIL. Ez ismétlődik mindaddig, ameddig az első argumentum értéke először bizonyul igaznak. Az UNTIL értéke ez az érték lesz. A MAPC függvény újabb változatát így definiálhatjuk az UNTIL segítségével:
(DEFUN T-ERTEKU-MAPC (LISTA FUGGVENY)
(UNTIL (NULL LISTA)
(APPLY FUGGVENY (LIST (CAR LISTA)))
(SETQ LISTA (CDR LISTA]
A T-ERTEKU-MAPC értéke - a MAPC-től eltérően - mindig T lesz, hiszen az utolsó iterációs lépést követően vizsgált feltétel, a (NULL LISTA) értéke mindig T.
Természetesen - ugyanúgy, mint a rekurzió alkalmazásakor - az iteratív függvények használatakor is gondoskodnunk kell arról, hogy a megadott formák kiértékelése ne ismétlődhessen végtelen sokszor; legyen olyan eset, amelyben a megállási feltétel teljesül.
9.2. A DO függvény
Az újabb LISP rendszerekben (az IS-LISP-ben nem) megtalálható a DO függvény is, melynek a segítségével bonyolultabb ciklusokat építhetünk fel. A DO függvénnyel mindazt meg lehet valósítani, amit a RPT, a WHILE vagy az UNTIL függvénnyel felírhatunk. Ugyanúgy, mint az UNTIL esetében, a DO alkalmazásakor is S-kifejezések értékelődnek ki újra és újra, egészen addig, míg a feltételként megadott kifejezés értéke igaz nem lesz. A DO függvény fontos lehetősége, hogy - éppúgy, mint a 8.3. szakaszban bevezetett LET függvénynek - itt is megadhatunk egy változólistát argumentumként. A változókhoz a változólistán értéket is rendelhetünk. A DO általános alakját így írjuk fel:
(DO ((változó1 érték1)
(változó2 érték2)
...
(változóm értékm))
(feltétel tevékenység)
S-kifejezés1
S-kifejezés2
...
S-kifejezésn)
Az első argumentum a változólista, amely kételemű allistákból áll. Az allisták első eleme tetszőleges (de nem különleges) szimbólum lehet, ezeket DO-változóknak nevezzük, a második elem pedig tetszőleges S-kifejezés lehet. A DO kiértékelésének kezdetekor minden változónak az értéke a hozzá tartozó S-kifejezés értéke lesz. A legtöbb LISP változatban a változólistán egyelemű allista is szerepelhet, ekkor a megfelelő DO-változó értéke kezdetben NIL.
A DO-változók pontosan olyanok, mint a LET-változók (ld. 8.3. szakasz): A DO kiértékelése után a DO-változók is elveszítik lokális értéküket, és ha volt előzőleg értékük, azt visszakapják.
A DO második argumentuma egy kételemű lista, amelynek elemei tetszőleges S-kifejezések lehetnek. Az első elem a megállási feltétel, a második elemet tevékenységnek nevezzük. A DO harmadik és esetleges további ar-gumentumai tetszőleges S-kifejezések lehetnek, ezek alkotják a DO törzsét. Ha a megállási feltétel értéke NIL, akkor a törzset alkotó S-kifejezések egymás után kiértékelődnek. Az utolsó S-kifejezés után azonban nem fejeződik be a DO kiértékelése, hanem újra kiértékelődik a feltétel - és azt követően minden S-kifejezés - egészen addig, amíg a feltétel értéke igaz érték nem lesz. Ekkor értékelődik ki a megállási feltétel után álló tevékenység, és ennek értéke lesz a DO kifejezés értéke.
Számítsuk ki a DO alkalmazásával a 2^10 hatványt!
(DO ((EREDMENY 1) ;Az EREDMENY kezdeti értéke 1.
(KITEVO 10)) ;A KITEVŐ kezdeti értékéke 10.
((ZEROP KITEVO) EREDMENY) ;Ha a kitevő 0, kész.
(SETQ EREDMENY ;Különben az EREDMÉNY-t
(TIMES 2 EREDMENY)) ; megkétszerezzük,
(SETQ KITEVO (SUB1 KITEVO)))
1024
A legtöbb LISP dialektusban a DO-kifejezés további lehetőségekkel is rendelkezik. Az egyik ilyen lehetőség az, hogy a második argumentum a feltétel után több tevékenységet is tartalmazhat. Ekkor a feltétel igaz értéke esetén mindegyik tevékenység kiértékelődik, és az utolsó tevékenység értéke lesz a DO-kifejezés értéke. A feltételes kifejezés általánosított alakjához (ld. 5.3.1. pont) hasonlóan tehát itt is használhatunk implicit progn szerkezetet.
A másik lehetőség az, hogy a változólistán nemcsak kezdeti értéket adhatunk a változóknak, hanem előírhatjuk azt is, hogy az iteráció további lépéseiben hogyan változzon az értékük. Ehhez a változólistán háromelemű allistákat adhatunk meg. A DO általános alakja ezek után:
(DO ((változó1 érték1 változtatás1)
(változó2 érték2 változtatás2)
...
(változóm értékm változtatásm))
(feltétel tevékenység1 tevékenység2... tevékenységp)
S-kifejezés1
S-kifejezés2
...
S-kifejezésn)
A változólista allistáin szereplő harmadik elem szerepe az, hogy segítségével az S-kifejezések kiértékelése után, az újabb iterációs lépés kezdetekor megváltoztathatjuk a DO-változók értékét. Ekkor a változók újra értéket kapnak, mégpedig a megfelelő változtatás forma értékét. (Ha ilyen forma nincs, a változó értéke ugyanaz marad, mint amit a legutolsó értékadás során kapott. Ez az értékadás természetesen a törzsben is lehet.) Ezután újra kiértékelődik a feltétel, majd a D0 törzse.
Számítsuk ki most a 2^10 hatványt az általánosított DO segítségével!
* (DO ((EREDMENY 1 (TIMES 2 EREDMENY))
(KITEVO 10 (SUB1 KITEVO)))
((ZEROP KITEVO) EREDMENY))
1024
Ebből a példából látszik, hogy a változólista milyen hatékony eszköz: a feladatot meg lehet oldani úgy, hogy csak a változólista értékadási lehetőségeit használjuk fel.
Célszerű a DO-kifejezést egy függvény definíciójában elhelyezni, ekkor nem kell minden alkalmazáskor az egész kifejezést (a változólistát, a megállási feltételt, a tevékenységeket, a D0 törzsét) leírni. Pl. a LEGNAGYOBB függvény, amelyet a 7.3.3. pontban már definiáltunk, egy listán megadott számok közül kiválasztja a legnagyobbat:
(DE LEGNAGYOBB (SZAMOK)
(DO ((SZ SZAMOK (CDR SZ))
(LNAGYOBB (CAR SZAMOK))) ;Változólista
((NULL SZ) LNAGYOBB) ;Feltétel, tevékenység
(AND (GREATERP (CAR SZ) LNAGYOBB) ;Törzs
(SETQ LNAGYOBB (CAR SZ>* (LEGNAGYOBB '(1 3 0 2 5 11 6 4))
11
A LEGNAGYOBB függvény esetében a függvény törzsét egyetlen S-kifejezés alkotja, amelyben a LNAGYOBB változó értékét megváltoztatjuk, ha a lista elemei között az előzőeknél nagyobb számot találunk.
A különböző DO-változókhoz tartozó kezdeti értékek egyidejűleg értékelődnek ki, majd a kapott értékek hozzárendelődnek a változókhoz. Erre akkor kell figyelnünk, ha a változólistán a kezdeti értékeket szolgáltató kifejezésekben DO-változók is szerepelnek. A következő példa ezt szemlélteti:
* (SETQ A 1)
1* (SETQ B 2)
2* (DO ((A 3) (B A))
(T (LIST A B)))
(3 1)
Látható, hogy B kezdeti értéke a kezdeti értékek meghatározásánál A-nak a DO alkalmazása előtti értékével, 1-gyel lett azonos, nem pedig az A kezdeti értékével, 3-mal.
Definiáljuk az ITERATIV-REVERSE függvényt, amely - mint a REVERSE függvény - értékként a lista elemeit fordított sorrendben adja meg! Használjuk a definícióban a DO-t!
(DE ITERATIV-REVERSE (LISTA)
(DO ((MUNKA NIL)) ;Változólista
((NULL LISTA) MUNKA) ;Feltétel, tevékenység
(SETQ MUNKA (CONS (CAR LISTA) MUNKA)) ;Törzs
(SETQ LISTA (CDR LISTA>
A DO argumentumaként megadott változólista vagy törzs üres is lehet. A 9.1.1. pontban a RPT függvénnyel definiált UJ-NTH függvényt most kétféleképpen definiáljuk újra. Az első definícióban a változólista egy üres lista:
(DE UJ-NTH (LISTA SZAM)
(DO () ;A változólista üres
((ZEROP SZAM) LISTA) ;Feltétel, tevékenység
(SETQ LISTA (CDR LISTA)) ;Törzs
(SETQ SZAM (SUB1 SZAM>
A második definícióban a DO törzse üres:
(DE UJ-NTH (LISTA SZAM)
(DO ((L LISTA (CDR L)) ;Változólista
(SZ SZAM (SUB1 SZ)))
((ZEROP SZ) L))) ;Feltétel, tevékenység
IS-LISP-ben a DO helyett a LOOP használható ciklusszervezésre. Ennek alakja végtelen ciklus esetében:
(LOOP (tevékenység))
A kilépési feltétel vizsgálatára használható a WHILE és UNTIL is:
(LOOP (feltétel) (tevékenység))
vagy
(LOOP (tevékenység) (feltétel))
A két példa egyenértékű:
(SETQ N 0)
(LOOP (PRINT (SETQ N (ADD1 N))) (UNTIL(EQ N 10)))(SETQ N 0)
(LOOP (PRINT (SETQ N (ADD1 N))) (WHILE(LESSP N 10)))
9.3. A PROG függvény
Az első nemrekurzív eszköz, amely a korai LISP változatokban szerepelt, a PROG függvény volt (IS-LISP-ben nincs implementálva). A DO függvénnyel összehasonlítva egy lényeges eltérést kell kiemelnünk. Láttuk a DO függvénynek azt a tulajdonságát, hogy a törzs kiértékelése után (hacsak a megállási feltétel igaz nem lett), mindig újból végrehajtódik az iterációs lépés. Ez a tulajdonság kényelmes eszközzé teszi a DO függvényt, de azzal a megkötéssel jár, hogy a törzsben szereplő kifejezések mindig ugyanabban a sorrendben értékelődnek ki. A PROG függvény ezzel szemben lehetővé teszi, hogy a kifejezéseket tetszőleges sorrendben értékeljük ki, mint ahogy a nemfunkcionális programozási nyelvekben címkék és "GO TO" utasítások segítségével vezérelhetjük az utasítások végrehajtásának sorrendjét.
A PROG-kifejezések a következő alakúak:
(PROG (változó1 változó2... változóm)
S-kifejezés1
S-kifejezés2
.
S-kifejezésn)
A kifejezés első eleme a PROG szimbólum, ezután következik a PROG változóinak listája. Ezeket a továbbiakban PROG-változóknak nevezzük. A DO-változókhoz hasonlóan, PROG-változó (a T és a NIL kivételével) bármely szimbólum lehet, és a PROG-változók is lokális értékükkel vesznek részt a kiér-tékelésben. A DO-változókkal ellentétben a PROG-változóknak nem adhatunk kezdeti értéket a változólistán. Minden PROG-változónak kezdetben NIL az értéke.
A változólista után tetszőleges számú S-kifejezés következik, ezek a PROG-kifejezés törzsét alkotják. A PROG törzsében három különleges szerepet játszó S-kifejezés fordulhat elő:
Ha a törzs valamelyik S-kifejezése szimbólum, ezt címkének nevezzük. A címkék nem értékelődnek ki.
Ha a törzs nem tartalmazza a GO, ill. a RETURN függvényeket, akkor az S-kifejezések - a címkéket kivéve - a megadott sorrendben egymás után kiértékelődnek. Amikor az utolsó forma is kiértékelődött, a PROG-kifejezés kiértékelése befejeződik, értéke NIL lesz. A kifejezés kiértékelése után a PROG- változók is (mint a lambdaváltozók) elveszítik értéküket.
A címke segítségével azonban megváltoztathatjuk a kiértékelés sorrendjét. A címke által a kifejezések sorában kijelölhetünk egy helyet, amelyre hivatkozni lehet. A címkére (GO címke) alakban hivatkozhatunk a GO függvény segítségével. Amikor az értelmezőprogram a GO-t tartalmazó kifejezést kiértékeli, mellékhatásként nem a sorrendben utána következő, hanem az illető címke után álló első kifejezéssel folytatódik a kiértékelés. Ha a PROG törzsének utolsó S-kifejezése is kiértékelődött - és ez nem tartalmazott olyan GO-kifejezést amelynek hatására a kiértékelés a törzs valamely más helyén folytatódik -, akkor a PROG kiértékelése befejeződik, a függvény értéke most is NIL.
A PROG kiértékelése akkor is befejeződik, ha a törzsben egy RETURN kifejezés kiértékelődik. Ennek alakja:
(RETURN S-kifejezés)
A RETURN argumentuma kiértékelődik, ez lesz a RETURN álfüggvény és a PROG függvény értéke is. A RETURN-t tartalmazó kifejezésnek nem kell az utolsónak lennie a PROG törzsében, sőt egy PROG-kifejezésben több RETURN is előfordulhat. A RETURN kiértékelésével azonban minden esetben befejeződik a PROG kiértékelése, vagyis "kilépünk" a PROG-ból.
A 3.5. szakaszban bevezetett NEGYZETOSSZEG függvénnyel egy számsorozat négyzetösszegét tudjuk kiszámítani. Oldjuk meg most ezt a feladatot a PROG segítségével! Határozzuk meg az 1, 2, ..., 8 számok négyzetösszegét:
(PROG (N MUNKA)
(SETQ MUNKA 0) ; A MUNKA-ban összegzünk,
(SETQ N 8) ; N az utolsó szám.
CIKLUS ; A ciklus kezdete, címke
(SETQ MUNKA ; A MUNKA változóhoz hozzáadjuk
(PLUS MUNKA (EXPT N 2))) ; az újabb tagot
(SETQ N (SUB1 N)) ;Csökkentjük N értékét
(AND (GREATERP N 0) ;Ha N>0,
(GO CIKLUS)) ; a következő cikluslépés
((RETURN MUNKA)) ;Ha nem: kész az összeg.
A GO és a RETURN kifejezések szerepéből következik, hogy őket csak PROG-kifejezés belsejében lehet használni, azon kívül értelmetlenek.
Akárcsak a DO-kifejezéseket, a PROG-kifejezéseket is ritkán használják önállóan, többnyire egy függvény definíciójában szerepelnek. Egy függvénydefinícióban szereplő PROG-kifejezésen belül a függvény lambdaváltozóit ugyanúgy használhatjuk, mint bármely más függvényben. Ha azonban a lambdaváltozók valamelyikét a PROG-változók között is felsoroljuk, az alkalmazáskor a változó a lambdakötésben kapott értékét elveszíti, és - mint minden PROG-változónak - kezdetben NIL lesz az értéke.
Definiáljuk újra a FAKTORALIS függvényt a PROG segítségével!
(DE FAKTORIALIS (N)
(PROG (K L)
(SETQ K N)
(SETQ L 1)
KOVETKEZO
(COND ((ZEROP K) (RETURN L)))
(SETQ L (TIMES K L))
(SETQ K (SUB1 K))
(GO KOVETKEZO)))
Minden modern számítógépnyelvben - az imperatív és az applikatív nyelvekben is - megtalálható az a törekvés, hogy a nyelven könnyen lehessen létrehozni áttekinthető, jól olvasható, strukturált programokat. A PROG ezeknek az igényeknek nem tesz eleget. A címkékkel, GO-kifejezésekkel teletűzdelt törzs általában nehezen bontható fel kisebb, jól követhető programrészekre. A PROG használata ellen szól, hogy ami PROG-kifejezéssel leírható, az világosabban és áttekinthetőbben leírható egy vagy esetleg több DO-kifejezéssel. Ezért a LISP programozásban a PROG jelentősége egyre kisebb.
1. feladat
Definiáljuk a KIVONAS függvényt a RPT segítségével! A KIVONAS függvény két argumentuma szám lehet, és értéke a két szám különbsége.
2. feladat
Definiáljuk újra az UTOLSO-ELEM függvényt az UNTIL függvény segítségével!
(DEFUN UTOLSO-ELEM (X)
(COND ((NULL X) NIL)
((ATOM X) X)
((NULL (CDR X)) (CAR X)) ;egyelemű lista
(T (CAR (UNTIL '(NULL (CDR X)) '(SETQ X (CDR X]
3. feladat
A DO függvény felhasználásával definiáljunk egy új, BUBOREK-RENDEZES nevű függvényt! Ennek összehasonlító függvénye a 4. vagy a 7. fejezetben alkalmazott függvények valamelyike lehet, és rendezési algoritmusa a következő: A lista elemeit sorban megvizsgáljuk, és ha olyan szomszédos elemekre akadunk, amelyek "rossz" sorrendben vannak, felcseréljük őket. Pl. ha az ALPHORDER az összehasonlító függvény, akkor az (A D E X B C) listában az első felcserélendő szomszédos elempár az X és a B, mert betűrendben a B előbb áll az X-nél. A csere után a lista: (A D E B X C). A felcserélés után újra élőiről kezdjük a lista elemeinek vizsgálatát. Ha valamely vizsgálat során elérjük az utolsó elemet, és azt sem kell felcserélnünk az előtte állóval, akkor készen vagyunk, a listát rendeztük.
10. A bemeneti és a kimeneti függvények
10.1. A bemeneti és a kimeneti függvények
Minden programozási nyelvben fontos probléma, hogy hogyan olvastathatjuk be a program által feldolgozandó adatokat valamilyen külső adathordozóról, és hogyan jeleníthetjük meg a program által előállított eredményeket külső adathordozón. Az adatok beolvasását bemenetnek, angol szóval inputnak, az eredmények kiírását pedig kimenetnek, angol szóval outputnak nevezzük.
A LISP bemeneti és kimeneti lehetőségeinek ismertetése előtt be kell vezetnünk néhány fontos fogalmat, a periféria, az adatállomány és a rekord fogalmát. A számítógéphez külső egységek csatlakozhatnak, így pl. a mágneslemezegység, a mágnesszalagegység, a sornyomtató vagy - ma már egyre ritkábban - a lyukszalag-, ill. a lyukkártyaolvasó és -lyukasztó. Ezeket a berendezéseket összefoglaló néven perifériának nevezzük. Azokat a berendezéseket, amelyekről adatokat vihetünk be a gép tárába - ilyen a lyukszalag- és lyukkártyaolvasó -, bemeneti perifériának, azokat pedig, amelyekre adatokat írhatunk ki a gép tárából, kimeneti perifériának nevezzük, ilyen a sornyomtató, a lyukszalag- és a lyukkártyalyukasztó. A mágnesszalag- és mágneslemezegység, valamint a terminál egyszerre bemeneti és kimeneti periféria is, mivel írásra és olvasásra is használható.
Összetartozó adatok együttesét adatállománynak nevezzük. Az adatállományokat általában névvel láthatjuk el, ezzel azonosíthatjuk őket. Az már nem tartozik a LISP nyelv ismertetéséhez, hogy hogyan kell egy mágnesszalagon vagy mágneslemezen tárolt adatállományhoz nevet rendelnünk, ez az adott számítógéptől függ.
Az adatállományokban tárolt adatokat kisebb egységekre, rekordokra tagolva kezelhetjük. Egy rekord egy lyukkártya, egy sor a sornyomtatón vagy egy sor, amelyet a terminál billentyűzetén gépelünk be. A terminálon való beíráskor vagy lyukszalagra lyukasztáskor a rekord végét egy külön karakter, az ún. sorvégjel jelöli.
A LISP-ben az írást és olvasást bemeneti és kimeneti függvények segítségével végezhetjük el. Ezek kivétel nélkül álfüggvények, az írás, ill. olvasás a függvények mellékhatásaként megy végbe. Sok esetben a függvények értékére nincs is szükségünk, csak a mellékhatásukra.
Mindezideig megtehettük, hogy nem használtuk a bemeneti és a kimeneti függvényeket, mert az olvasás - kiértékelés - kiírás körforgásban az értelmezőprogram elvégzi a kiértékelendő kifejezések beolvasását és a kife-jezések értékének kiírását.
Nagyobb programok írásakor azonban a bemeneti és a kimeneti függvények már nélkülözhetetlenek. Ha pl. egy függvénydefiníció törzsében szereplő kifejezés értékét akarjuk kiírni a függvény kiértékelése közben, akkor használnunk kell a kimeneti függvényeket, mivel a körforgásban az értelmezőprogram csak a legfelső szinten kiértékelt kifejezések értékét írja ki. (Bár a TRACE függvénnyel kiírathatjuk egyes kifejezések értékét, de csak megszabott formában, ezért ez főként csak nyomkövetési célokra alkalmas.) A kimeneti függvényeket kell alkalmaznunk akkor is, ha nem felel meg céljainknak az értelmezőprogram által használt kiíratási forma, hanem magunk akarjuk a kiírás formáját megválasztani, pl. táblázatokat, grafikonokat, ábrákat akarunk készíteni. A bemeneti függvényekre pedig szükségünk van akkor, ha egy függvény kiértékelése közben kell újabb adatokat beolvasnunk, vagy ha egy programot olyan adatokkal is végre akarunk hajtatni, amelyeket nem a terminál billentyűzetén írunk be, hanem külső adathordozóról (mágneslemezről, mágnesszalagról) olvassuk be őket.
Azért is ismernünk kell a bemeneti és a kimeneti lehetőségeket, hogy egy LISP programot (vagy annak egy részét) hibakeresés, továbbfejlesztés vagy újbóli felhasználás céljából megőrizhessünk egy külső adathordozón, ahonnan később beolvashatjuk azt.
A bemeneti és a kimeneti függvényeket két csoportba sorolhatjuk. Az egyik csoportba azok tartoznak, amelyek segítségével írhatunk és olvashatunk, meghatározhatjuk a kiírás formáját. A másikba pedig azok, ame-lyek segítségével kijelölhetjük, megnyithatjuk, ill. lezárhatjuk azt az adatállományt, amelyből olvasni vagy amelybe írni akarunk. Az első csoport függvényei a legtöbb LISP rendszerben nagyon hasonlóak.
A legtöbb LISP rendszer a munka kezdetekor automatikusan a terminált jelöli ki mind a bemeneti, mind pedig a kimeneti perifériának. Ezért, ha csak a terminálon dolgozunk, nem kell használnunk az adatállomány-kijelölő függvényeket, a terminált nem kell sem megnyitnunk, sem pedig lezárnunk.
A bemeneti és a kimeneti függvények bevezetéséhez ismernünk kell a karakterfüzéreket, vagy röviden füzéreket. Ezért először ezeket mutatjuk be.
10.2. A füzérkezelő függvények
A bemeneti és a kimeneti függvények használatakor fontos szerepet játszanak a karakterfüzérek. A füzér az S-kifejezéseknek az atomoktól, a listáktól és a pontozott pároktól különböző újabb fajtája. A füzér karak-tersorozat, amelyet idézőjelek (") közé zárva írunk le. A füzérek tetszőleges karaktereket, még betűközöket is tartalmazhatnak. A legtöbb LISP rendszer a füzérekben a nagy- és a kisbetűk használatát egyaránt megengedi. A füzérek listák elemei is lehetnek; egy lista tehát atomokon és listákon kívül füzéreket is tartalmazhat. Minden füzér értéke önmaga; ebben a füzérek a különleges atomokhoz hasonlítanak.
(SETQ VERNEFUZER "80 nap alatt a Fold korul (Irta Verne) ")
A füzéreket leggyakrabban a képernyőn vagy sornyomtatón megjeleníthető tetszetős kiírások létrehozására használjuk, de fontos szerepük van a szöveges információk feldolgozásában is.
A füzérek kezelésére több függvény is a rendelkezésünkre áll (ezek az IS-LISP-ben nincsenek implementálva). A STRINGP rendszerfüggvénnyel dönthetjük el, hogy egy S-kifejezés füzér-e; a STRINGP szerepe a NUMBERP, ill. az ATOM predikátumokéhoz hasonló. Két füzér azonosságát a STREQUAL függvénnyel állapíthatjuk meg.
* (STRINGP VERNEFUZER)
T
A CONCAT akárhány-argumentumú függvény argumentumai füzérek, ezeket egymás után fűzi, értéke az így létrejövő egyetlen füzér:
* (CONCAT "SAS" "KACSA" "PATKO" "VALYOG")
"SASKACSAPATKOVALYOG"
A füzérek esetében - mivel ezeknek értéke a füzér maga - felesleges a QUOTE függvényt alkalmazni.
A SUBSTRING függvénynek három argumentuma van, egy füzér és két szám. A függvény értéke az eredeti füzér egy része: az a füzér, amelynek karakterei az eredeti füzér karakterei az első sorszámtól a másodikig. Ezért egyik szám sem lehet nagyobb, mint a füzér karaktereinek száma, és a másodiknak legalább akkorának kell lennie, mint az elsőnek:
* (SUBSTRING VERNEFUZER 1 7)
"80 nap "
A függvényérték a VERNEFUZER-nek az 1. karaktertől a 7. karakterig terjedő része.
Az NCHARS függvény egyargumentumú, az argumentumnak füzérnek kell lennie. Értéke a füzér karaktereinek száma (a füzér hossza):
* (NCHARS VERNEFUZER)
39
10.2.1. A füzérek és a szimbólumok
Vannak olyan függvények, amelyekkel szimbólumokból füzéreket, ill. füzérekből szimbólumokat készíthetünk. A MKSTRING függvény argumentuma egy atom, a függvény az atom nyomtatási nevének karaktereiből egy füzért hoz létre:
* (MKSTRING 'EMLOSOK)
"EMLOSOK"
Ennek a feladatnak a fordítottját végzi el a MKATOM; egy füzér az argumentuma, a füzér karaktereiből álló szimbólum az értéke:
* (MKATOM "EMLOSOK")
EMLOSOK
Láttuk, hogy a füzérekben különleges, a szimbólumokban meg nem engedett karakterek is szerepelhetnek. Mi történik, ha a MKATOM függvényt olyan füzérre alkalmazzuk, amely ilyen karaktereket is tartalmaz?
* (MKATOM "KETSZER 2 NEHA 5?")
KETSZER! 2! NÉHA! 5!?
Mint látható, minden olyan karakter elé, amely szimbolikus atomban nem szerepelhet, az értelmező egy különleges karaktert (itt a ! jelet) helyez. Ezt a karaktert escape karakternek, magyarul mentesítőjelnek, röviden mentőjelnek nevezzük, mert mentesít a különleges karakterek használatának tilalma alól. A mentőjelet olyan szimbólumok létrehozására használhatjuk, amelyekben eddig meg nem engedett karakterek, pl. elhatárolójelek is szerepelhetnek. Magát a mentőjelet is lehet szimbólumban használni, ilyenkor meg kell kettőzni, vagyis eléje kell írni a mentőjelet.
a mentőjelek eltűnnek a szimbólumból akkor, ha füzérré alakítjuk: ezek nem számítanak a szimbólum karakterei közé.
A mentőjelek bevezetése után módosítanunk kell a szimbolikus atomokra az 1. fejezetben adott definíciót: a szimbolikus atomok betűkön és számokon kívül olyan különleges - betűtől és számjegytől különböző - karaktereket is tartalmazhatnak, amelyek előtt mentőjel áll.
A mentőjelet több LISP rendszer is arra használja, hogy segítségével "megvédje" a rendszerfüggvények nevét és a rendszer által különleges célokra használt változókat. Ha nem használunk mentőjelet, akkor ezekben a rendszerekben nem fenyeget az a veszély, hogy akaratlanul újradefiniálunk egy rendszerfüggvényt, vagy a rendszer által más célra használt változónak új értéket adunk. Nagy LISP programokban azonban hasznos lehet a mentő-jelek használata, ha el akarjuk kerülni, hogy a program különböző részeiben más-más célra használt szimbólumok nevei egybeessenek. Ekkor azonban előzőleg tájékozódnunk kell a rendszer által használt nevekről is, hogy az ezekkel való ütközést elkerüljük.
10.2.2. A füzérek és a listák
A füzéreket szimbólummá és a szimbólumokat füzérré alakító függvényeken kívül léteznek szimbólumokat listává és listákat szimbólummá alakító függvények is. A PACK függvény argumentuma egy lista, értéke olyan szimbólum, amely a lista elemeinek karaktereiből áll:
* (PACK '(SAS KACSA PATKO VALYOG))
SASKACSAPATKOVALYOG
A következő példában egy tulajdonságlistában összetett attribútumokhoz tartozó tulajdonságokat keresünk meg:
* (PUT 'MAGYARORSZAG 'XIX-SZAZADI-FOVAROS 'BUDA)
BUDA* (PUT 'MAGYARORSZAG 'XX-SZAZADI-FOVAROS 'BUDAPEST)
BUDAPEST* (DE FOVAROSA (ORSZAG KORSZAK)
(GETP ORSZAG (PACK (LIST KORSZAK '-SZAZADI-FOVAROS))))
FOVAROSA* (FOVAROSA 'MAGYARORSZAG 'XIX)
BUDA
Ügyeljünk arra, hogy ha az argumentum elemei között listák is vannak, akkor ezeknek a karakterei (a zárójelekkel és az atomokat elválasztó szóközzel együtt) belekerülnek a függvényértékbe:
* (PACK '(A (B C) D))
A!(B! C!)D
A PACK függvénnyel ellentétes az UNPACK funkciója, ennek argumentuma egy szimbólum, értéke pedig lista, amelynek atomjai a szimbólum karakterei (egyes LISP változatokban ennek a függvénynek a neve EXPLODE):
* (UNPACK 'HETEDHETORSZAGRA)
(H E T E D H E T O R S Z A G R A)
Ez meglehetősen kiszélesíti a füzérekkel végezhető műveletek lehetőségeit. Definiáljunk egy függvényt, amely egy füzér megfordítottját állítja elő!
(DE FUZFORD (FUZER)
(MKSTRING (PACK (REVERSE (UNPACK (MKATOM FUZER>
Az UNPACK függvény segítségével sokkal egyszerűbben definiálhatjuk a 7.2.1. pontban megismert KIGYÜJT függvényt, amely egy szimbólumokból álló listából kiválasztja az adott karaktersorozattal kezdődő szimbólumokat:
(DE KIGYUJT (SZIMBOLUMOK ELEJE)
(AZOK SZIMBOLUMOK ;A SZIMBOLUMOK közül a
(FUNCTION (LAMBDA (ELEM) ; megfelelő kezdetüek
(UGYANUGY-KEZDODIK ; kiválasztása.
(UNPACK ELEJE) ;Karakterekre bontjuk
(UNPACK ELEM> ; az argumentumokat.
A KIGYUJT előző definíciójában három változó szerepelt, a harmadikra az újabb definícióban nincs szükség, mivel nem az ALPHORDER predikátummal végezzük az összehasonlítást. A segédfüggvények definíciója:
(DE UGYANUGY-KEZDODIK (KEZDET SZO) ;Azt vizsgálja.
(EQUAL KEZDET ; hogy a SZÓ eleje
(ELSO-N SZO (LENGTH KEZDET> ; megegyezik-e a KEZDET-tel(DE ELSO-N (LISTA SZAM) ;LISTA elejéről
(COND ((ZEROP SZAM) NIL) ; leválasztja az első
((LESSP (LENGTH LISTA) SZAM) NIL) ; SZAM elemet
((ONEP SZAM) (LIST (CAR LISTA)))
(T (APPEND (LIST (CAR LISTA))
(ELSO-N (CDR LISTA) (SUB1 SZAM>
Egy lista elemei közül az AL karakterekkel kezdődőekeket választjuk ki:
* (KIGYUJT '(ALMA ALMARIUM AKARAT APRO AMULETT ALAMUSZI) 'AL)
(ALMA ALMARIUM ALAMUSZI)
10.3. Az S-kifejezések olvasása és írása
A legegyszerűbb bemeneti és kimeneti függvények egy S-kifejezés olvasására vagy írására szolgálnak.
A READ függvénnyel, amelynek nincs argumentuma, egy S-kifejezést olvashatunk be. A (READ) forma kiértékelésekor az értelmezőprogram megáll, és egy S-kifejezés beolvasására várakozik. A beolvasandó kifejezést párbeszédes üzemmódban a terminál billentyűzetén írhatja be a felhasználó, de az értelmezőprogram olvashat más adathordozóról, pl. mágneslemezről is. Következő példáinkban feltételezzük, hogy a terminálról olvasunk. Később, a 10.5. szakaszban látjuk majd, hogyan lehet más bemenő perifériát kijelölni. A READ egy S-kifejezést olvas be, tehát addig olvas, amíg a kifejezés végét meg nem találja: atom beolvasásakor az atom végét jelentő szóközt, vagy sorvégjelet, lista vagy pontozott pár beolvasásakor az azt bezáró zárójelet, füzér esetében pedig a bezáró idézőjelet. A READ függvény értéke a beolvasott kifejezés, amely nem értékelődik ki:
* (READ)
* (A B (C D))
(A B (C D))
A fenti párbeszédben a (READ) függvénykifejezés beírása után írjuk be a beolvasandó S-kifejezést, erre válaszul az értelmező kiírja a (READ) függvény értékét, azaz a beolvasott kifejezést.
A READ függvény által beolvasott kifejezésekben szereplő atomokat az értelmezőprogram megvizsgálja, és ha azok a rendszer nyilvántartásában még nem szerepeltek, akkor új atomként a létező atomok listáján helyezi el őket.
A beolvasott atom mentőjelet is tartalmazhat. Füzért is beolvashatunk:
* (SETQ ALFA (READ))
* "HOSVERTOL PIROSULT GYASZTER"
"HOSVERTOL PIROSULT GYASZTER"
A READ használatakor az értelmező semmilyen figyelmeztetéssel sem jelzi, hogy minek a beolvasására vár, a felhasználónak mit kell beírnia. Ezért célszerű, ha a READ alkalmazása előtt egy figyelmeztető üzenet kiírásáról gondoskodunk.
Az üzenetet egy kimeneti függvénnyel írhatjuk ki. Ilyen függvény a PRINT, amelynek egyetlen argumentuma egy tetszőleges S-kifejezés, ez kiértékelődik, és mellékhatásként kiíródik az értéke. Általában ez az érték a PRINT értéke is. IS-LISP-ben 5 különböző PRINT függvény közül választhatunk, melyek formázásban térnek el egymástól: PRIN, PRINC, PRINT, PRINTC és SPRINT.
A PRINT függvénnyel karakterfüzéreket is kiírathatunk:
(PRINT "Hanyat lep a vereb egy evben?")
Figyeljük meg, hogy a karakterfüzér kiírásakor a PRINT függvény az azt körülvevő idézőjeleket is megjeleníti a képernyőn, ill. sornyomtatón.
A következő példában olyan függvényt definiálunk, amely a READ függvénnyel olvas be S-kifejezéseket, az olvasás előtt pedig a PRINT függvénnyel jelzi, hogy mit kell beírnunk. Vezessük be először a HANYADIK függvényt, amelynek két argumentuma van, egy S-kifejezés és egy lista! A függvény értéke NIL, ha a lista nem tartalmazza az S-kifejezést a legfelső szinten, ha pedig tartalmazza, akkor a függvény értéke azt adja meg, hogy az S-kifejezés a listának hányadik eleme. A függvény az INDEX segédfüggvénnyel számítja ki a sorszámot.
(DEFUN HANYADIK (ELEM LISTA) (INDEX ELEM LISTA 1))
(DE INDEX (ELEM LISTA N)
(COND ((NULL LISTA) NIL)
((EQ (CAR LISTA) ELEM) N)
(T (INDEX ELEM (CDR LISTA) (ADD1 N]* (HANYADIK 'HAROM '(EGY KETTO HAROM NEGY))
3
Változtassuk meg most a függvény definícióját! A vizsgálandó elemet és listát ne argumentumként kapja meg, hanem folytasson velünk párbeszédet: szólítson fel arra, hogy a terminálon írjuk be a megkeresendő elemet, majd a listát is. Legyen az új függvény neve PÁRBESZEDES-HANYADIK, argumentuma nincs. A függvény értéke az S-kifejezés sorszáma a lista elemei között, ill. NIL, ha a kifejezés nem eleme a listának. Segédfüggvényként itt is felhasználjuk az INDEX függvényt:
(DEFUN PARBESZEDES-HANYADIK ()
(PRINTC "IRD BE AZ ELEMET:")
(INDEX (READ)
(PROGN (PRINTC "IRD BE A LISTAT:") (READ)) 1))
Az INDEX függvény második argumentumában a PROGN függvény első argumentuma tartalmazza a kiírandó szöveget, a második pedig a (READ) függvénykifejezés. így érjük el azt, hogy az INDEX értéke a beolvasott kifejezés legyen; mivel még a beolvasás előtt ki kell írnunk a terminálra a figyelmeztető üzenetet, szükségünk van a PRINT mellékhatására, de nincs szükségünk az értékére. Megjegyezzük, hogy a bemeneti és a kimeneti függvények használatakor gyakran alkalmazzuk hasonló módon a PROG1 vagy a PROGN függvényt.
A PRINT függvény segítségével egy függvény kiértékelése közben kiírathatjuk egyes, a függvény törzsében szereplő kifejezések értékét. Ha csak egyes részeredményekre van szükségünk, kevesebb, ill. áttekinthetőbb kiírással követhetjük nyomon a kiértékelés menetét, mintha a TRACE függvényt használnánk. A 4.1. szakaszban UJ-REVERSE néven definiáltunk egy függvényt, amely megfordítja egy lista elemeinek sorrendjét. Segédfüggvényként az UJ-REVERSE1 függvényt használtuk:
* (UJ-REVERSE '(BAGOLY IS BIRO A MAGA HAZABAN))
(HAZABAN MAGA A BIRIO IS BAGOLY)
A kiértékelés egyes lépéseinek eredményét megjeleníthetjük úgy, hogy az UJ-REVERSE1 függvény definiálásakor a függvény törzsében kiíratjuk a (CONS (CAR LIS) MUNKA) kifejezés értékét:
(DEFUN UJ-REVERSE1 (LIS MUNKA)
(COND ((NULL LIS) MUNKA)
(T (UJ-REVERSE1 (CDR LIS)
(PRINT (CONS (CAR LIS) MUNKA]* (UJ-REVERSE *(BAGOLY IS BIRO A MAGA HAZABAN))
(BAGOLY)
(IS BAGOLY)
(BIRO IS BAGOLY)
(A BIRO IS BAGOLY)
(MAGA A BIRO IS BAGOLY)
(HAZABAN MAGA A BIRO IS BAGOLY)
(HAZABAN MAGA A BIRO IS BAGOLY)
A függvény kiértékelésekor minden lépésben kiíródik a (CONS (CAR LIS) MUNKA) kifejezés értéke. Az utolsó érték - a megfordított lista - kétszer jelenik meg, egyszer a PRINT függvénnyel való kiíratás hatására, ezután az értelmező program is kiírja, mint a kifejezés értékét.
A PRINT függvény olyan formában jelenít meg egy S-kifejezést, amilyen formában a READ függvény beolvasáskor várja azt. Ha a PRINT függvénnyel valamilyen külső adathordozóra - pl. mágnesszalagra, mágneslemezre - írunk ki egy kifejezést, azt onnan a READ később vissza tudja olvasni. Ezért, ha a kiírás eredményét újból az értelmezőprogrammal akarjuk beolvastatni, akkor rendszerint a PRINT függvényt használjuk.
Más kimeneti függvények inkább arra használhatók, hogy a felhasználó által jól olvasható formában jelenítsük meg az eredményeket. Ilyen a PRIN2 és a PRIN1 függvény (IS-LISP-ben ezek helyett PRIN, PRINC, PRINT, PRINTC és SPRINT használható). A PRIN2 csak abban különbözik a PRINT függvénytől, hogy a kiírás befejezése után nem következik új sor, ezért a következő kiírás ugyanabba a sorba kerül. A PRIN2 függvény értéke ugyancsak az argumentumának az értéke. A függvényt bonyolultabb kiírási formák, táblázatok, ábrák készítéséhez használhatjuk.
* (PRIN2 (CDR '(A B C D)))
(B C D)(B C D)* (PRIN2 "KI AZ? MI AZ? VAGY UGY!")
"KI AZ? MI AZ? VAGY UGY!""KI AZ? MI AZ? VAGY UGY!"
A kiírt S-kifejezés után az értelmezőprogram ugyanabba a sorba írja ki a függvény értékét.
A PRIN1 függvény argumentuma ugyancsak tetszőleges S-kifejezés lehet, ennek értéke lesz a függvény értéke is. A PRIN1 által kiírt érték után sem következik új sor. A PRIN2 függvénytől abban különbözik, hogy nem írja ki a kifejezésben szereplő mentőjeleket, sem pedig a füzéreket közrefogó idézőjeleket, így kényelmesen olvasható kiírási képet állít elő.
A példákban láthattuk, hogy a kiírási képet zavarja, ha a kimeneti függvények értéke is kiíródik, hiszen ezeket a függvényeket nem értékük, hanem mellékhatásuk kedvéért használjuk. Ezért a bemeneti és kimeneti függvényeket gyakran PROG szerkezetben, vagy a PROG1, ill. a PROGN függvény argumentumaként adjuk meg, ezzel kerülhetjük el fölösleges értékek kiírását. Ezért használtuk a PARBESZEDES-HANYADIK függvény definíciójában is a PROGN függvényt.
Néhány további függvény a kiírási forma kialakítására használható.
A SPACES függvénynek egy argumentuma van, ennek értéke mindig szám. A függvény hatására az argumentum értékének megfelelő számú szóköz íródik. IS-LISP-ben a (PRINC BLANK) függvény használható szóköz kiírására, de ennek nem lehet argumentuma.
A TERPRI függvénynek nincs argumentuma, hatására az éppen kiírt rekord befejeződik, a kiírás további része új rekordba kerül, a képernyőn új sorba íródik. A függvény értéke NIL. Ha pl. a PRIN1 függvény többszöri alkalmazásával több kifejezés értékét egy sorba írattuk, utána a TERPRI függvénnyel kezdhetünk új sort. Hibát okozhat, ha ezt elfelejtjük.
Az EJECT függvény (IS-LISP-ben nincs implementálva) szintén argumentum nélküli függvény, értéke NIL: hatására a kimeneti periférián - ha az sornyomtató - lapváltás megy végbe.
A legtöbb LISP rendszerben megtalálható a PRETTYPRINT függvény (IS-LISP-ben nincs), amely egy S-kifejezést "tetszetős", azaz a lista szerkezetének megfelelően tördelt formában ír ki; az azonos szintnek megfelelő atomokat, ill. zárójeleket egymás alá írja. A függvény egyetlen argumentuma a kiírandó S-kifejezés; a függvény értéke az argumentum értéke lesz:
* (SETQ L '(A (B C (D (E) F) G (H)) K))
(A (B C (D (E) F) G (H)) K)* (PRETTYPRINT L)
(A (B C
(D (E) F)
G
(H))
K) (A (B C (D (E) F) G (H)) K)
A PRETTYPRINT függvénnyel való kiíratás után - ugyanúgy, mint a PRIN1, PRIN2 függvényeknél - nem következik soremelés.
A READC bemeneti függvénynek (IS-LISP-ben nincs implementálva) nincs argumentuma. Egyetlen karaktert olvas be, segítségével kifejezéseket karakterenként olvashatunk be. Definiáljuk az OLVAS függvényt! Ez mindaddig olvas új karaktereket, amíg vesszőt vagy szóközt nem talál, ekkor a beolvasott karakterekből egy füzért készít és ezt kiírja. A vessző és szóköz karaktereket a VESSZO és SZOKOZ változókban helyezzük el:
(SETQ VESSZŐ '!,)
(SETQ SZOKOZ '! )
(DE OLVAS ()
(PROG (LISTA KARAKTER) ;A LISTA változóban
; gyűjti a karaktereket
KOVETKEZO ;Címke
(SETQ KARAKTER (READC)) ;A beolvasott karakter
<COND <(OR (EQ KARAKTER VESSZO) ;Vesszőig
(EQ KARAKTER SZOKOZ)) ; vagy szóközig keres
(RETURN ;Ha vesszőt vagy
(PRINT ; szóközt talál, kiírja
(MKSTRING ; a fordított listából
(PACK (REVERSE LISTA>; készített füzért
(T (SETQ LISTA ;Különben a listához
(CONS KARAKTER LISTA> ; csatolja a karaktert
(GO KOVETKEZO> ;Az iteráció kővetkező lépése
A függvény a beolvasott karakterekből füzéreket készít.
Az OLVAS függvényt a DO segítségével is definiálhatjuk:
(DE OLVAS ()
(DO ((LISTA NIL (CONS KARAKTER LISTA)) ;Változólista
(KARAKTER NIL (READC)))
((OR (EQ KARAKTER VESSZO) ;Feltétel
(EQ KARAKTER SZOKOZ))
(PRINT (MKSTRING (PACK (REVERSE LISTA> ;Tevékenység
Vegyük észre, hogy a DO törzse hiányzik, a "változtatás"-ba és a megállási feltételt követő tevékenységbe építettük be az elvégzendő feladatot.
A bemeneti és a kimeneti függvényekkel hibaüzenetet is kiírhatunk, ha egy kifejezés értékének ellenőrzésekor azt tapasztaljuk, hogy az nem megengedett érték; pl. nem szám, ha számnak kellene lennie. A 3.5. szakaszban definiált FAKTORIALIS függvény definícióját így egészíthetjük ki az argumentum vizsgálatával és hibaüzenetekkel:
(DEFUN FAKTORIALIS (N)
(COND ((NOT (NUMBERP N))
(PRINC "HIBA: FAKTORIALIS ARGUMENTUMA NEM SZAM ---"
BLANK)
((MINUSP N)
(PRINC "HIBA: FAKTORIALIS ARGUMENTUMA NEGATIV ---"
BLANK)
(PRINT N))
((ZEROP N) 1)
(T (TIMES N (FAKTORIALIS (SUB1 N]
10.4. Összetett feladatok
Egy ősi keleti legenda szerint Hanoi városában egy rúdra 64 különböző átmérőjű, középen kifúrt korongot fűztek fel az átmérő nagysága szerinti sorrendben: legalul van a legnagyobb átmérőjű korong. Szentéletű szerzeteseknek valamennyi korongot egy másik rúdra kell áthelyeznie úgy, hogy végül a korongok ezen ugyancsak a kiinduló sorrendben helyezkedjenek el. Segédeszközül használhatnak egy harmadik rudat, ideiglenesen erre is elhe-lyezhetnek korongokat. Egy lépésben egyetlen korongot tehetnek át az egyik rúdról a másik két rúd valamelyikére. Az áthelyezések során sohasem kerülhet nagyobb átmérőjű korong egy kisebb átmérőjű korong fölé. A legenda szerint a világnak akkor lesz vége, ha a szerzetesek befejezték a korongok áthelyezését.
Ez a feladat a "Hanoi tornyok" néven vált ismertté. Jelölje a három rudat rendre R1, R2 és R3! Kezdetben az R1 rúdon helyezkednek el csökkenő nagyság szerinti sorrendben a korongok, az R2 és az R3 rúd üres. A feladatot akkor oldottuk meg, ha a korongok - ugyanebben a sorrendben - az R3 rúdra kerültek át.
Az n korong áthelyezésének feladatát visszavezethetjük n-1 korong áthelyezésének esetére:
Az algoritmus megfogalmazásából kiolvashatjuk, hogy a feladatot rekurzívan definiált függvénnyel oldhatjuk meg. Kettős rekurziót kell alkalmaznunk: mindkétszer n-1 korongot helyezünk át, először az R1 rúdról az R2 rúdra, majd pedig az R2 rúdról az R3 rúdra. A rekurzív eljárás akkor fejeződik be, ha n értéke nullával egyenlő.
A kérdés az, hogyan írjuk le egy korong áthelyezését egyik rúdról a másikra. Felmerülhet a gondolat, hogy a korongokat sorszámokkal jelöljük, és az egy rúdon lévő korongokat a rudat jelölő szimbólum tulajdonságlistáján helyezzük el. Egy másik lehetőség, hogy a korongokhoz rendeljük hozzá annak a rúdnak a szimbólumát, amelyre éppen fel vannak fűzve. Beláthatjuk azonban, hogy egyszerűbb ábrázolással is megoldhatjuk a feladatot. Mivel a rudakról mindig csak a legfelső korongot Vehetjük el, ill. csak legfelülre helyezhetünk el korongot, ezért az átrakás menetét pontosan leírhatjuk, ha csak azt tartjuk számon, hogy egy-egy lépésben melyik rúdról melyikre helyezzük át a korongot. (A rudakat voltaképpen úgy tekinthetjük, mint veremtárakat, mivel mindig csak a legfelső koronghoz férhetünk hozzá.) Elegendő tehát csak a három rudat számon tartanunk, és lépésenként azt kiírnunk, hogy az adott lépésben melyik rúdról melyik rúdra helyezünk át korongot. Az egyes lépések eredményét nem is őrizzük meg. A függvénydefiníció tehát a következő lehet:
(DEFUN HANOI (N RUD1 RUD2 RUD3) ;RUD1-ről RUD3-ra
(COND ((ZEROP N) NIL)
(T (HANOI (SUB1 N) RUD1 RUD3 RUD2) ;RUD1-ről RUD2-re
(HONNAN-HOVA N RUD1 RUD3) ;Kiírja az áthelyezést
(HANOI (SUB1 N) RUD2 RUD1 RUD3] ;RUD2-ről RUD3-ra
A függvény első változója N, az áthelyezendő korongok száma; RUD1, RUD2 és RUD3 pedig a rudakat jelölő szimbólumok. RUD1 a kiinduló R1 rúdnak, RUD2 az R2 segédrúdnak, RUD3 pedig az R3 rúdnak felel meg, amelyre a korongokat át kell helyeznünk. A függvény törzsében a feltételes kifejezés "implicit progn" lehetőségét használjuk; a T feltételt három tevékenység követi. A függvény első rekurzív alkalmazásakor az n-1 számú korongot a RUD1-ről a RUD2-re tesszük át, és eközben RUD3 a segédrúd. Hasonlóan értelmezhető a második rekurzív függvényalkalmazás is, ekkor a korongokat a RUD2-ről RUD3-ra tesszük át. A HONNAN-HOVA függvény azt írja ki, hogy melyik rúdról melyikre helyezzük át az N-edik korongot:
(DEFUN HONNAN-HOVA (N RUD1 RUD3)
(PRINC BLANK N ". korongot az ")
(PRINTC RUD1 " rudrol az " RUD3)
(PRINTC "rudra tettuk at.")
(TERPRI))
A kiírásban a PRINC függvényt használjuk, hogy a kiírt szöveg után ne kezdődjék új sor. Az utolsó kiírás után a TERPRI függvénnyel egy további soremelésről is gondoskodnunk. A PRINC és PRINTC függvény hatására a karakterfüzérek idézőjel nélkül íródnak ki.
Alkalmazzuk a HANOI függvényt három korongra! A rudakat jelöljék az R1, R2 és R3 szimbólumok:
* (HANOI 3 'R1 'R2 'R3)
1. korongot az R1 rudrol az R3 rudra tettuk at
2. korongot az R1 rudrol az R2 rudra tettuk at
1. korongot az R3 rudrol az R2 rudra tettuk at
3. korongot az R1 rudrol az R3 rudra tettuk at
1. korongot az R2 rudrol az R1 rudra tettuk at
2. korongot az R2 rudrol az R3 rudra tettuk at
1. korongot az R1 rudrol az R3 rudra tettuk at
NIL
A feladat megoldásának egy másik változatában a HANOI függvény fejlécet ír ki az egyes lépéseket leíró sorok előtt, majd a rekurzív HANOI1 segédfüggvényt alkalmazza. Az egyes lépések végrehajtását kiíró HONNAN-HOVA függvényt is megfelelően módosítanunk kell:
(DEFUN HANOI (N RUD1 RUD2 RUD3)
(PRINTC "Korong sorszama Honnan Hova")
(HANOI1 N RUD1 RUD2 RUD3))(DEDUN HANOI1 (N RUD1 RUD2 RUD3)
(COND ((ZEROP N) NIL)
(T (HANOI1 (SUB1 N) RUD1 RUD3 RUD2)
(HONNAN-HOVA N RUD1 RUD3)
(HANOI1 (SUB1 N) RUD2 RUD1 RUD3](DEFUN HONNAN-HOVA (N RUD1 RUD3)
(PRINTC " " N " " RUD1 " " RUD3))
Egy másik példán az ún. szisztematikus szöveggenerálást mutatjuk be. Így nevezzük azokat a feladatokat, amelyekben állandó szövegrészek közé - bizonyos szabályok szerint - változó szövegeket kell beillesztenünk. Szinte minden nép népköltészetében ismerünk olyan verses mondókákat, amelyekben egy tréfás szöveg több versszakon keresztül ismétlődik egyre újabb sorokkal bővülve, amelyek azonban csak egy-egy szóban térnek el az előzőktől. Ilyen a közismert magyar népdal, a Kitrákotty-mese, ennek a szövegét így állíthatjuk elő:
(DEFUN MESE ()
(VERSSZAK
'((TYÚKO KITRÁKOTY)
(RÉCÉ RIP-HAJNAL)
(PULYKA DANDALU)
(LUDA GIGÁGÁ)
(DISZNÓ RÖF-RÖF-RÖF)
(JUHO BEHEHE)
(KECSKÉ NYIKRABÁ)
(CSIKÓ MIHÁJBÁ)
NIL))(DEFUN VERSSZAK (LIS MUN)
(COND ((NULL LIS) NIL)
(T (PRINTC "ÉN ELMENTEM A VÁSÁRBA FÉLPÉNZEN")
(PRINC (CAAR LIS))
(PRINTC "T VETTEM A VÁSÁRBAN FÉLPÉNZEN")
(MIT-MOND (CONS (CAR LIS) MUN))
(PRINTC "KÁRIKITTYOM, ÉDES TYÚKOM")
(PRINTC "MÉGIS VAN EGY FÉLPÉNZEM.")
(TERPRI)
(VERSSZAK (CDR LIS) (CONS (CAR LIS) MUN](DEFUN MIT-MOND (LISTA)
(COND ((NULL LISTA) NIL)
(T (PRINC (CAAR LISTA))
(PRINC "M MONDJA ")
(PRINTC (CADAR LISTA))
(MIT-MOND (CDR LISTA]
A MESE függvény argumentuma kételemű allistákból álló lista; az allista első eleme az állat neve, ehhez (ahol kell) a ragozás által megkívánt kötőhangot is hozzáillesztjük, a második pedig az állat hangjára jellemző hangutánzó szó.
10.5. Adatállományok kezelése
Mindezideig azt feltételeztük példáinkban, hogy mind a bemenet, mind pedig a kimenet céljára a terminált használjuk, tehát az adatokat a billentyűzeten visszük be, a kiírások pedig a képernyőn jelennek meg. A programban azonban több bemeneti, ill. kimeneti adatállományt is használhatunk. Tegyük fel, hogy a munkát a terminálon kezdjük meg, ez az ún. standard bemeneti és kimeneti adatállomány. A további adatállományokat a rájuk vonatkozó első írás, ill. olvasás előtt meg kell nyitni, és az utolsó írás vagy olvasás után le kell zárni.
Egy adatállományra a legtöbb LISP rendszerben egy névvel, az ún. adatállománynéwel hivatkozhatunk, ezt kell megadnunk a megnyitáskor (és esetleg a lezáráskor is). Megnyitáskor azt is meg kell mondanunk, hogy írásra, vagy olvasásra akarjuk-e az adatállományt használni. Egy adatállomány megnyitására az OPEN, lezárására a CLOSE függvény szolgál. Pl. a LEMEZFILE nevű adatállományt olvasásra a következőképpen nyithatjuk meg:
(OPEN 'LEMEZFILE 'INPUT)
A függvény első argumentuma az adatállománynév, második argumentuma pedig a megnyitás módját jelölő INPUT vagy OUTPUT szimbólum. A továbbiakban az olvasás az utoljára megnyitott bemeneti adatállományból történik az adatállomány utolsó rekordjának, azaz az adatállomány végének az eléréséig. Ezután a beolvasás ismét a standard bemeneti adatállományból folytatódik, mivel ez az utoljára kiválasztott bemeneti adatállomány.
Előfordulhat az is, hogy a bemeneti adatállományból az adatállomány végének elérése előtt egy újabb OPEN függvény kifejezést olvasunk, amelyik egy másik adatállományra hivatkozik. Ekkor az olvasás ebből az adat-állományból folytatódik, és ennek a végén az előzőleg utoljára megnyitott adatállományhoz tér vissza.
Egy adatállományból való beolvasás befejezhetődhet az adatállomány végének elérése nélkül is úgy, hogy az adatállományt a CLOSE függvénnyel lezárjuk:
(CLOSE 'LEMEZFILE)
A bemeneti és a kimeneti függvényekkel kapcsolatban hangsúlyozzuk, amire korábban is többször figyelmeztettünk; ha egy adott gép LISP rendszerével dolgozni kezdünk, először alaposan tanulmányozzuk a függ-vényeket. Egyes LISP rendszerekben a függvények neve eltér az itt használt nevektől, vagy másképpen kell az argumentumaikat megadni. Sok LISP rendszerben változatos további bemeneti és kimeneti lehetőségeket is találhatunk.
11. Az értelmezőprogram és a fordítóprogram
Az értelmezőprogramról (interpreterről) korábban annyit mondtunk, hogy a kiértékelendő S-kifejezésekben előírt műveleteket egyenként végrehajtja, majd az értéknek megfelelő eredményt kiírja a képernyőre. Az értelmező-program működését most már pontosabban is tárgyalhatjuk, ez megkönnyíti a LISP működésének megértését.
11.1. Az értelmezőprogram
Az alábbiakban vázlatosan ismertetjük az értelmezőprogram három fő komponensét; a LISP rendszerekben ezek rendszerint lefordított függvények. Itt azonban úgy mutatjuk be őket, mint le nem fordított függvényeket, hogy működésüket szemléletesebbé tegyük. A tárgyalandó definíciók az olvasás - kiértékelés - kiírás körforgás, a kiértékelés és a függvényalkalmazás függvényeinek definíciói. Az utóbbi két függvényt, az EVAL-t valamint az APPLY-t a programozó is használhatja, erre láttunk példát a 2.2. szakaszban és a 7.1.1. pontban.
11.1.1. Olvasás - kiértékelés - kiírás
Az értelmezőprogram fő alkotórésze az olvasó - kiértékelő - kiíró program. Tegyük fel, hogy az általunk tárgyalt LISP rendszerben ennek a neve LISPX. Definícióját vázlatosan így írhatjuk fel:
(DE LISPX () (PRINT (PROMPTTEXT)) (PRINT (EVAL (READ>
A (PRINT (PROMPTTEXT)) kifejezés egy ún. promptszöveg kiírását jelenti, amely egy kifejezés beírására szólít fel. Ez egyetlen karakter is lehet: könyvünkben a csillag (*) karaktert használjuk.
Az olvasás - kiértékelés - kiírás körforgást az értelmezőprogram legfelső szintjének is nevezik. A legfelső szinten a kiértékelőfüggvény, az EVAL argumentuma az az S-kifejezés, amelyet a gép a READ segítségével a terminálról (pontosabban az éppen használatban levő bemenő egységről) olvas; a PRINT hatására az EVAL értéke kiíródik a képernyőre (ill. az éppen kijelölt kimenő egységre). Az alacsonyabb szinteken, amikor nem közvetlenül annak az S-kifejezésnek a kiértékelése történik, amelyet a felhasználó beír, hanem ennek a részeit értékeli ki az értelmezőprogram, a részértékek nem íródnak ki a képernyőre, és olvasás sem történik (hacsak az S-kifejezésben nincs olvasó vagy kiíró utasítás).
Az olvasó - kiértékelő - kiíró függvény kiértékelésére nem kell külön utasítást adnunk, ez az értelmezőprogram elindulásakor azonnal megkezdődik, és minden kiértékelés után újra megindul.
11.1.2. Az EVAL függvény
Maga a kiértékelés és az alacsonyabb szintek kezelése tehát az EVAL függvény dolga. Az EVAL LISP-ben írt definíciója igen terjedelmes lenne, ezért csak vázlatosan, beszélő nevű segédfüggvények feltételezésével írjuk le:
| (DE EVAL (SKIP) (COND ((KÜLÖNLECES-E SKIF) SKIF) <(ATOM SKIF) |
;Különleges atom, ; pl. szám, T, NIL. ;Ezt részesítjük |
Ha az EVAL argumentuma lista, a munka legnagyobb részét az APPLY függvényre hárítja, amelyet szintén ismerünk már (ld. 7.1.1. pont).
11.1.3. Az APPLY
Az APPLY függvény definíciójának a következőkről kell gondoskodnia:
Az APPLY fontos feladata, hogy a változókötések létrehozásakor megállapítsa:
Ha az APPLY második argumentuma, az argumentumlista a szükségesnél kevesebb argumentumot tartalmaz, akkor különböző értelmezőprogramok különbözőképpen járhatnak el: vagy hibásnak tekintik a függvényalkalmazást, vagy pedig a NIL értéket kötik a hiányzó argumentumoknak megfelelő lambdaváltozókhoz. A következő definícióban, amely az APPLY igen vázlatos leírása, a változókötések helyes előállításáról a KELLÖ-ARGUMENTUMOK nevű segédfüggvény gondoskodik:
(DE APPLY (FV ARGL MUNKA) |
;MUNKA: munkaváltozó. |
A legfelső szintű kiértékelés éppen akkor fejeződik be, amikor a legfelső blokk törlése egyben az egyetlen blokk törlése is, vagyis amikor a paraméterverem kiürül. Ezért a TÖRÖLD-A-VEREM-TETEJÉT függvénynek "figyelnie kell" arra is, hogy a törölt függvényblokk az utolsó blokk volt-e. Ha igen, a LISPX függvényt automatikusan újra alkalmazni kell, meg kell kezdeni az újabb olvasás - kiértékelés - kiírás ciklust.
A 8.5. szakaszban megismert RESET függvény működését úgy képzelhetjük el, hogy a kiértékelés során a TÖRÖLD-A-VEREM-TETEJÉT függvény rekurzívan alkalmazódik mindaddig, amíg a paraméterverem teljesen ki nem ürül.
A LISP bármely függvény újradefiniálását megengedi. Az értelmezőprogram függvényeinek újradefiniálására azonban csak akkor vállalkozzunk, ha az eredeti, beépített függvények működését egészen pontosan ismerjük, értjük (pl. a rendszer nyomtatott leírásából), és a változtatást alaposan átgondoltuk. Ha pl. az olvasó - kiértékelő - kiírófüggvény a fenti LISPX, akkor hasznos lehet a következőképpen újradefiniálni:
(DE UJ-LISPX () (PRINT (PROMPTTEXT))
(SETQ !*ÉRTÉK (PRINT (EVAL (READ>
Ebben az esetben a kiértékelés ugyanúgy megy végbe, mint eddig, de a !*ÉRTÉK változó globális értéke mindig az előző S-kifejezés értéke lesz. Így, ha az érték érdekesnek bizonyul, azonnal tovább dolgozhatunk vele:
* (GETP 'EMLŐSÖK 'ALFAJOK)
(KLOAKÁSOK ERSZÉNYESEK MÉHLEPÉNYESEK)* (GETP (CADR !*ÉRTÉK) 'ALFAJOK)
(KENGURU KOALA PANDA)
11.2. A fordítóprogramról
A fordítóprogram az értelmezőprogram egyik beépített függvénye, amelyet nem beépített függvényekre alkalmazhatunk, és a kiértékelés mellékhatásaként létrejön az argumentumként megadott függvényeknek a számítógép nyelvére lefordított változata. A lefordított függvények LISP definíciója nem vész el, és nem is tanácsos ezt megszüntetni, mert a lefordított definíciót már nem lehet módosítani. Az egyetlen módosítási lehetőség az, hogy a LISP nyelvű definíciót módosítjuk, és a függvényt újra lefordítjuk.
A fordítóprogram működésének részleteire nem térünk ki, mert használata erősen függ az egyes rendszerektől.
A fordítófüggvény neve általában COMPILE, ez eval-típusú, egyargumentumú függvény. Argumentumának értéke függvénynevek listája, az e listában szereplő függvényeket kívánjuk lefordítani:
* (SETQQ TÉRKÉPFÜGGVÉNYEK (SZOMSZÉDJA-E SZOMSZÉDAI))
(SZOMSZÉDJA-E SZOMSZÉDAI)* (COMPILE TÉRKÉPFÜGGVÉNYEK)
(SZOMSZÉDJA-E SZOMSZÉDAI)* (GETD 'SZOMSZÉDJA-E)
(SUBR 2340)
A kapott érték mutatja, hogy a SZOMSZÉDJA-E függvény SUBR típusú lefordított függvénnyé vált. A GETD által szolgáltatott lista második eleme a tár azon helyének gépi címe, ahol a lefordított függvény definíciója megtalálható. Ha ezután a függvényt alkalmazzuk, a lefordított változat fog működni. A lefordított függvények alkalmazása jóval gyorsabb, mint a le nem fordítottaké; mivel azonban a bennük alkalmazott függvények nyomkövetésére nincs mód, csak olyan függvényeket érdemes lefordítani, amelyeknek hibátlan működéséről már meggyőződtünk.
A lefordított függvények használatakor azonban nem szabad megfeledkeznünk arról, hogy a lefordított függvény definíciója már nem lista formájában, hanem végrehajtandó gépi utasítások sorozatának formájában tárolódik. Ezért a lefordított függvényben nem őrződik meg a lambdaváltozóknak a LISP függvénydefinícióban használt neve, a lefordított függvénynek nincsenek lambdaváltozói. Nézzük a következő példát:
(DE KÍVÜL-VAN (SZÁM KÜSZÖB)
(COND ((MINUSP SZÁM) T)
(T (TÚL-NAGY SZÁM))))(DE TÚL NAGY (N) (GREATERP N KÜSZÖB))
* (KÍVÜL-VAN 7 9)
NIL* (KÍVÜL-VAN 9 7)
T* (COMPILE '(KÍVÜL-VAN TÚL-NAGY))
(KÍVÜL-VAN TŰL-NAGY)* (KÍVÜL-VAN 7 9)
---Error: illegal argument - TÚL-NAGY
A hiba oka az, hogy a KÍVÜL-VAN függvény lefordított változatának alkalmazásakor a KÜSZÖB változó nem kap lokális értéket. így a TÚL-NAGY függvényben, ahol a KÜSZÖB változó szabad változóként szerepel, ennek nincs értéke.
Mindazokban a LISP rendszerekben, amelyek a változók értékét dinamikusan kezelik, a szabad változókat is tartalmazó függvények másképpen viselkedhetnek, ha lefordítjuk, mint akkor, ha az értelmezőprogram dolgozza fel őket. Ez is hozzájárult ahhoz, hogy egyes újabb LISP rendszerekben a változók értékét lexikálisán (statikusan) kezelik, annak érdekében, hogy az értelmezett és lefordított függvények azonos módon viselkedjenek.
Azok a függvények sem viselkednek ugyanúgy lefordított és értelmezett módon, amelyek önmagukat módosítják, úgy, hogy feltételezik, hogy a függvénydefiníció lista formájában tárolódik, és saját definíciójukat a LISP valamelyik romboló függvényével (RPLACA, RPLACD, NCONC, ld. 6.3. szakasz) megváltoztatják. Mivel azonban a lefordított függvény definíciója már nem lista formájában tárolódik, a lefordított függvény nem módosíthatja magát ugyanígy.
12. Kidolgozott feladatok
Az előző fejezetekben áttekintettük a LISP nyelv elemeit, beépített függvényeit, megismerkedtünk a LISP-ben alkalmazott programozási módszerekkel. Ismereteink birtokában nagyobb feladatok megoldására is vállalkoz-hatunk. Ebben a fejezetben néhány nagyobb példát mutatunk be az előző fejezetekben elsajátított ismeretek elmélyítésére. Ezekben a LISP több alkalmazási területe is szerepel - természetesen a teljesség igénye nélkül. A példák gondos követése segíthet az önálló programozásban. Kidolgozásukban inkább az áttekinthetőségre, követhetőségre törekedtünk, mint arra, hogy a lehető legtömörebb megoldásokat válasszuk.
12.1. A legrövidebb út megkeresése
Térjünk vissza Európa országainak vizsgálatához, amellyel már könyvünkben többször is (a 4.1., az 5.1., a 7.3., a 7.4. és a 8.2. szakaszokban) foglalkoztunk. Az országok szomszédsági kapcsolatait ábrán gráffal ábrázoltuk.
Keressük most két ország között a "legrövidebb" útvonalat! Azt az útvonalat tekintjük legrövidebbnek, amelyik a legkevesebb országot érinti, a legkevesebb határ átlépését jelenti.
Induljunk ki pl. Portugáliából, és keressünk olyan útvonalat, amely a legkevesebb országon áthaladva vezet Magyarországra. Természetesen több azonos hosszúságú útvonal is lehetséges.
A térképekre vonatkozó eddigi feladatokban többféle ábrázolást is használtunk. A feladat megoldásához az 5.1. szakaszban bevezetett ábrázolást és az ott definiált SZOMSZEDAI2 függvényt választjuk. Mindegyik ország tulajdonságlistáján a SZOMSZEDOK attribútumhoz tartozó tulajdonságként helyeztük el a szomszédos országok neveiből álló listát:
(DEFLIST
'((P (E))
(E (P F))
(F (B L D CH I E))
(B (NL D L F))
(L (F B D))
(NL (B D))
(D (NL DDR L F B DK CH A CS))
(DK (D))
(CH (F D I A))
(I (F CH A YU))
(A (CH D CS H YU I))
(H (A YU CS SU RO))
(CS (DDR D A H SU PL))
(DDR (D CS PL))
(PL (DDR SU CS))
(SU (RO H CS PL SF N))
(SF (SU N S))
(N (S SF SU))
(S (N SF))
(RO (BG YU H SU))
(YU (AL I A H RO BG GR))
(AL (GR YU))
(BG (GR YU RO TR))
(GR (BG TR AL YU))
(TR (GR BG)))
'SZOMSZEDOK)
A feladat kitűzésének és a megoldás módjának is sokféle változata lehetséges. Megfogalmazhatjuk úgy, hogy csak egyetlen legrövidebb útvonalat keresünk. Kereshetjük azonban valamennyi legrövidebb útvonalat is.
Egy rekurzív megoldást mutatunk be, amely a kiinduló országból a célországba vezető összes legrövidebb útvonalat állítja elő. Létrehozzuk a kezdeti országból kiinduló útvonalak listáját: ez kezdetben egyetlen egyelemű listát tartalmaz, amelynek eleme a kiinduló ország. Ha ez a célország is, akkor feladatunkat meg is oldottuk. Ha pedig nem, akkor létrehozzuk az eggyel hosszabb útvonalak listáját úgy, hogy a lista utolsó elemének szomszédait rendre hozzáillesztjük a listához, ha még nem voltak rajta. Ha az így előállított újabb útvonalak végpontjai között sem szerepel a célország, akkor ismét létre kell hoznunk az eggyel hosszabb útvonalak listáját. Ezt mindaddig folytatnunk kell, amíg az n országból álló útvonalak listáján nem találunk - egy vagy több - útvonalat, amelynek utolsó eleme a célország. Ekkor a keresés befejeződik, és a függvény értéke ezeknek az útvonalaknak a listája lesz. A függvény definíciója:
(DE LEGRÖVIDEBB-UTAK (KEZDET CÉL)
(SEGÉD-LEGRÖVIDEBB-UTAK (LIST (LIST KEZDET)) CÉL))(DE SEGÉD-LEGRÖVIDEBB-UTAK (ÚTLISTA CÉL)
(COND ((NULL ÚTLISTA) NIL)
<(AZOK ÚTLISTA ;Azokat az útvonalakat keressük
(FUNCTION ; az útlista útjai között,
(LAMBDA (ÚT) ; melyeknek vége a célország.
(EQ (UTOLSÓ-ELEM ÚT) CÉL>
(T (SEGÉD-LEGRÖVIDEBB-UTAK ;Ha nincs ilyen,
(EGGYEL-HOSSZABB-UTAK ; tovább keresünk az eggyel
ÚTLISTA) ; hosszabb utak között.
CÉL>
A függvény a korábban definiált AZOK és UTOLSÓ-ELEM függvényeket alkalmazza. Az EGGYEL-HOSSZABB-UTAK segédfüggvény az adott útvonalakat tartalmazó listából elkészíti az eggyel hosszabb útvonalakat tartalmazó listát. A listán szereplő minden útvonalból újabb, eggyel hosszabb útvonalakat készít úgy, hogy az útvonal végéhez hozzáilleszti az utolsó ország azon szomszédait, amelyek az útvonalon még nem szerepeltek. A szomszédokat itt is a SZOMSZEDAI2 függvénnyel állítjuk elő.
(DE EGGYEL-HOSSZABB-UTAK (ÚTLISTA)
(MAPCAN ÚTLISTA
(FUNCTION ;Az utolsó elem
(LAMBDA (ÚT) ; szomszédait az
(EGGYEL-HOSSZABB-FOLYTATÁSOK ÚT ; útvonalhoz illesztve
(SZOMSZÉDAI2 (UTOLSÓ-ELEM ÚT> ; készítünk hosszabb
; útvonalakat.
A függvény a MAPCAN függvénnyel fűzi újabb listába az eggyel hosszabb útvonalakat, amelyeket az EGGYEL-HOSSZABB-FOLYTATÁSOK függvény ugyancsak a MAPCAN-nal készít el:
(DE EGGYEL-HOSSZABB-FOLYTATÁSOK (ÚT KŐVETKEZŐ-ORSZÁGOK)
(MAPCAN KÖVETKEZŐ-ORSZÁGOK
(FUNCTION (LAMBDA (KÖVETKEZŐ-ORSZÁG) ;Ha a szomszéd
(COND <(NOT (MEMBER KÖVETKEZŐ-ORSZÁG ÚT)); még nincs
(LIST (APPEND ÚT (LIST KÖVETKEZŐ-ORSZÁG>
(T NIL> ; az útvonalon, hozzáillesztjük.
Ha a függvényt Portugáliára és Magyarországra alkalmazzuk:
* (LEGRÖVIDEBB-UTAK 'P 'H)
((P E F D A H) (P E F D CS H) (P E F CH A H)
(P E F I A H) (P E F I YU H))
Ezzel megkaptuk a Portugáliából Magyarországra vezető összes legrövidebb - legkevesebb országot érintő - útvonalat. Ha a célország nem érhető el a kiinduló országból, a függvény értéke NIL:
* (LEGRÖVIDEBB-UTAK 'NL 'USA)
NIL
Hollandiából az Egyesült Államokba - feladatunk kitűzésének feltételei szerint - nem vezet útvonal.
A legrövidebb útvonal - vagy útvonalak - meghatározása az úgynevezett keresési feladatok közé tartozik. Az ilyen feladatok megoldási algoritmusai a lehetséges esetek nagy számából választják ki a megoldást (vagy megoldásokat), úgy, hogy a lehetséges eseteket valamilyen - algoritmustól függő - sorrendben végigvizsgálják. Ilyen algoritmusok tervezésénél két fontos szabály van:
A 2. szabályt azért mondtuk ki, hogy ne kerüljünk végtelen ciklusba, azaz a keresés során ne vizsgáljuk újra és újra ugyanazt (vagy ugyanazokat) a lehetőségeket. (Tulajdonképpen az is elég, ha csak azt kötjük ki, hogy minden esetet legfeljebb véges sokszor vizsgálhatunk.)
A keresési algoritmusok tervezését megnehezíti, hogy sok feladatban a lehetséges esetek száma rohamosan növekszik. Ezt példánkban is érzékelhetjük, egy sok országot tartalmazó térképen gyorsan növekedhet a vizsgálandó országok száma, amint távolodunk a kiinduló országtól. A keresési algoritmusok tervezésében tehát az is fontos, hogy a keresési tér, a vizsgált esetek száma ne növekedjék robbanásszerűen.
12.2. Gráfok színezése
Egy híres matematikai probléma kapcsolódik a térképek színezéséhez: egy térképet - amelyen csak az országok határvonalait jelöljük be - a lehető legkevesebb színnel kell kiszínezni úgy, hogy minden országot csak egy színnel színezünk ki, és két szomszédos ország színe mindig különböző. Már a múlt században sejtették, hogy erre mindig elegendő négy szín, bármilyen is legyen a térkép. Az 1970-es évek elején számítógépekkel bebizonyították, hogy a sejtés igaz.
Hogyan fogalmazhatjuk meg a problémát gráfokkal? A térképnek egy gráfot feleltetünk meg. A gráf minden csúcspontjához egy színt kell rendelnünk úgy, hogy bármely két csúcspont, amelyet él köt össze, különböző színű legyen. Egy adott gráfról azt is megkérdezhetjük, hogy három színnel kiszínezhető-e, vagyis, ha a színezés során csak három színt használhatunk, létezik-e olyan színezés, amely a fenti feltételnek eleget tesz. Tekintsük a 4.1. fejezetben bemutatott gráfnak csak azt a részét, amely a Svájc, Ausztria, Olaszország, Jugoszlávia csúcspontokból áll! Láthatjuk, hogy ez három színnel kiszínezhető, de kettővel nem.
A gráfok külön osztályát alkotják azok, amelyeket térképek megfeleltetésével kapunk: ezeket síkba rajzolható gráfoknak nevezzük. Ezt a nevet azért kapták, mert lerajzolhatok egy papírra úgy, hogy az élek nem metszik egymást, csak a csúcspontokban van közös pontjuk. Bár a síkba rajzolható gráfok színezésére négy különböző szín mindig elég, ez egy tetszőleges, nem síkba rajzolható gráfra nem igaz.
Az ábrán látható gráf nem síkba rajzolható, és kiszínezéséhez nem elég négy szín. A gráf kiszínezéséhez legalább öt szín szükséges, mivel bármely két csúcspontját él köti össze, és így a gráfban nem lehet két azonos színű csúcspont. Azokat a gráfokat, amelyeknek bármely két csúcspontja között van él, teljes gráfoknak nevezzük. Az ábrán látható gráf tehát egy teljes 5 csúcspontú gráf. A fenti meggondolásból következik, hogy egy teljes n-csúcspontú gráf kiszínezéséhez legalább n szín szükséges. Olaszország, Ausztria, Svájc csúcspontjai egy háromszöget - teljes három csúcspontú gráfot - alkotnak, így színezésükhöz legalább három szín szükséges.
A gráfszínezési probléma megoldására sok algoritmust ismerünk. Ezek általában ugyancsak kereső algoritmusok. A legegyszerűbb gráfszínezési algoritmus használatakor feltesszük, hogy a gráf csúcspontjai és a felhasználható színek sorszámozva vannak. Az algoritmus a következő lépésekből áll:
Színezzük ki ezzel az algoritmussal három színt (piros, kék, sárga) használva a térkép alábbi ábrán látható részletét!
A leírt algoritmus visszalépéses, úgynevezett backtracking algoritmus. Az elnevezés arra utal, hogy ha a kereső algoritmus elakad, visszalép, és más irányban keres tovább.
Egy gráfot most úgy ábrázolunk listával, hogy rajta minden csúcsponthoz egy kételemű allista tartozik, amelynek feje a csúcspont, második eleme pedig egy lista, amely ezzel a csúcsponttal összekötött csúcspontokból áll.
Az ábrán látható gráfhoz a következő lista tartozik:
((DDR (D CS)) (D (DDR CS A CH)) (CH (D A))
(A (D CS CH)) (CS (D DDR A)))
Ahhoz, hogy a gráf pontjainak lehetséges színeit nyilvántartsuk, az előzőhöz hasonló listaszerkezetet használunk. A pontok lehetséges színeit tartalmazó lista olyan kételemű allistákból áll, amelyeknek feje a csúcspont, farka pedig az adott pont lehetséges színeiből álló lista. Kezdetben, amikor a FESTŐ függvényt először alkalmazzuk, a lista ilyen alakú:
((DDR (KÉK PIROS SÁRGA)) (D (KÉK PIROS SÁRGA)) (CH (KÉK PIROS SÁRGA)) (A (KÉK PIROS SÁRGA)) (CS (KÉK PIROS SÁRGA)))
A SZÍNEZÉS függvény a FESTŐ függvényt alkalmazza a kezdeti listákra. A pontok kezdeti lehetséges színeit a MAPCAR függvény segítségével állítjuk elő:
(DE SZÍNEZÉS (GRÁF SZÍNEK)
(FESTŐ GRÁF ;A FESTŐ függvényt a GRÁF és
(MAPCAR GRÁF ; a csúcspontok lehetséges színeit
(FUNCTION (LAMBDA (X) ; tartalmazó listára alkalmazzuk.
(LIST (CAR X) SZÍNEK>
A pontok színezését a FESTŐ függvény végzi:
(DE FESTŐ (GRÁF SZÍNLISTA)
(COND ((NULL (CDR GRÁF)) ;Nincs több csúcspont,
<AND (CADAR SZÍNLISTA) ;a csúcspontok színeit
(PRINT ; ha vannak -
(LIST (CAAR GRÁF) ; kinyomtatja.
(ELSÖ-SZÍN SZÍNLISTA>)
((NULL (LEHET-E SZÍNLISTA)) NIL) ;lehet-e továbbszínezni
(<FESTÖ (CDR GRÁF) ;ki lehet-e színezni a
(ELÖRE-LÉP (CADAR GRÁF) ; "maradékot"
(ELSÖ-SZÍN SZÍNLISTA)
(CDR SZlNLISTA>
(LIST (CAAR GRÁF)
(ELSÖ-SZÍN SZÍNLISTA))) 'SZÍNŰ)
(T (FESTŐ GRÁF ;ha nem, másik színt próbál
(CONS (LIST (CAAR SZÍNLISTA)
(CDADAR SZÍNLISTA))
(CDR SZÍNLISTA>(DE ELSÖ-SZÍN (SZÍNLISTA) ;az első pont első
(CAADAR SZÍNLISTA)) ; lehetséges színét adja meg(DE LEHET-E (SZÍNLISTA) ;megvizsgálja, a gráf
(COND ((NULL SZÍNLISTA) T) ; minden pontjának
((NULL (CADAR SZÍNLISTA)) NIL); van-e lehetséges
(T (LEHET-E (CDR SZÍNLISTA> ; színe.
A színezés adminisztrációját az ELÖRE-LÉP függvény végzi, a SZÍNLISTÁ-ban a megfelelő színeket törli:
(DE ELÖRE-LÉP (SZOM SZÍN SZÍNLISTA)
;A legutoljára színezett csúcspont színét letiltja
; a vele összekötött csúcspontoknál.
(COND ((NULL SZÍNLISTA) SZÍNLISTA) ;nincs több pont
((MEMBER (CAAR SZÍNLISTA) SZOM) ;a pont szerepel a
<CONS (LIST (CAAR SZÍNLISTA) ; színezett pont
(REMOVE SZÍN ; szomszédai között:
(CADAR SZÍNLISTA))); a színt letiltjuk
(ELÖRE-LÉP SZOM SZÍN (CDR SZÍNLISTA>)
(T (CONS (CAR SZÍNLISTA) ;Ha nem szerepel,
(ELÖRE-LÉP SZOM SZÍN ; rekurzívan
(CDR SZÍNLISTA> ; vizsgáljuk tovább
A következőkben egy másik színezési algoritmust ismertetünk, amely többre képes az előzőnél. Ez ugyanis csak azt tudja eldönteni, hogy egy adott gráf és szám esetén ki lehet-e színezni a gráfot a megadott számú színnel. A most bemutatandó algoritmus azonban arra is képes, hogy egy gráfról megállapítsa, legalább hány szín szükséges a gráf kiszínezéséhez. Ezt a számot az illető gráf kromatikus számának nevezzük. Ha az algoritmussal meghatároztuk a gráf kromatikus számát, akkor - a meghatározás menetéből - megadhatjuk a gráf egy minimális számú színt használó színezését is.
Az algoritmus lényege az, hogy a gráf kromatikus számának meghatározását visszavezeti két "egyszerűbb" gráf kromatikus számának meghatározására. Megértéséhez bevezetünk két, gráfokon értelmezett műveletet, amellyel az eredeti G gráfból G' ill. G'' új gráfokat készíthetünk. Beláthatjuk, hogy G minden kiszínezését meg tudjuk vizsgálni G'vagy G" színezéseinek vizsgálatával.
Az első művelet segítségével a G gráfból készíthetünk egy másik G' gráfot úgy, hogy valamely két össze nem kötött csúcspontját (jelöljük őket P1-gyel, ill. P2-vel) egybeejtjük: ez azt jelenti, hogy a G-beli P1 és P2 csúcspontokat G-ben egyetlen P csúcsponttal helyettesítjük; a P csúcspontot összekötjük az összes olyan csúcsponttal, amelyik P1-gyel vagy P2-vel össze volt kötve az eredeti G gráfban; a többi csúcspont és a köztük futó élek változatlanul szerepelnek G-ben.
A másik művelet sokkal egyszerűbb: a P1, P2 (éllel össze nem kötött) pontok között behúzunk egy élt, így kapjuk a G'' gráfot.
Ha a G' gráfot ki tudjuk színezni k színnel, akkor az eredeti G gráfot is ki tudjuk színezni ennyi színnel. A két gráf ugyanis csak abban különbözik, hogy a P1, P2 pontokat egybeejtettük egyetlen P ponttá. Tekintsük ugyanis a G' egy színezését, és "szedjük szét" a P pontot, vagyis állítsuk vissza az eredeti állapotot. Ha a keletkező P1, P2 pontokat a P színével színezzük ki, akkor - mivel P1, P2 között nem fut él - a G olyan színezését kapjuk, amely eleget tesz a feltételeknek. Ha pedig a G'' gráfot ki lehet színezni l színnel, akkor a G gráf is kiszínezhető ennyi színnel. Elég ugyanis a G" kiszínezett gráfban a P1, P2 között futó élt kitörölni, és már elő is állt a G megfelelő színezése. A k ill. l számok közül a kisebbet fogadjuk el, tehát a G kromatikus számát úgy kapjuk, hogy G' ill. G'' kromatikus száma közül a kisebbet vesszük.
Mivel ezt az eljárást folytatva egyre kevesebb csúcspontú, ill. azonos csúcspontszám esetén egyre több élt tartalmazó gráfokat kapunk, véges sok lépésben teljes gráfokhoz jutunk. Egy teljes gráf kromatikus száma pedig a csúcspontjainak számával egyenlő.
Annak érdekében, hogy a kromatikus számot meghatározó függvények egyszerűek legyenek, nem építettük be azt az algoritmusban rejlő lehetőséget, hogy a kromatikus szám meghatározásával együtt a gráf színezését is megadjuk.
Az algoritmus alapján a következő függvényeket definiáljuk:
(DE KROMATIKUS-SZÁMA (GRÁF)
(LET ((KIJELÖLTEK (ÖSSZEKÖTETLENEK GRÁF))) ;Két összekötetlen pontot jelöl
(COND ((NULL KIJELÖLTEK) (LENGTH GRÁF)) ;Ha ilyen nincs: ez teljes gráf
(T (MIN ; ha van: a következő két gráf
; közül a kisebbik kromatikus számút veszi alapul:
<KROMATIKUS-SZÁMA
(MAPCAPP GRÁF ;a pontok egybeejtésével és a
(FUNCTION (LAMBDA (PONT)
(EJT PONT
(CAR KIJELÖLTEK)
(CADR KIJELÖLTEK>
<KROMATIKUS-SZÁMA
(MAPCAR GRÁF ;pontok összekötésével
(FUNCTION (LAMBDA (PONT) ;keletkező gráf
(KÖT PONT (CAR KIJELÖLTEK>>(DE ÖSSZEKÖTETLENEK (GR) ;két összekötetlen pontot keres;
(COND ((NULL (CDR GR)) NIL) ;nincs több pont
((ÉL-E (CAAR GR) ; vizsgálj a van-e él két pont
(CDR GR) ; között, ha nincs, kész,
(CADAR GR)))
(T (ÖSSZEKÖTETLENEK (CDR GR> ;ha van tovább keres(DE ÉL-E (CSÚCS RÉSZGR SZOMSZÉDJAI) ;vizsgálja, hogy
; CSÚCS öszse van-e kötve a RÉSZGR-ban levő pontokkal
(COND ((NULL RÉSZGR) NIL)
((MEMBER CSÚCS (CADAR RÉSZGR)) ;ha igen, tovább keres
(ÉL-E CSÚCS (CDR RÉSZGR) SZOMSZÉDJAI))
(T (LIST (LIST CSÚCS (CAAR RÉSZGR))
SZOMSZÉDAI> ;ha nem, ezt a pontot adja
; meg a CSÚCS pont párjaként(DE EJT (CS PÁR SZOMSZÉDOK)
;két összekötetlen pontot egybeejt
;CS a gráf tetszőleges pontja
;a következő eseteket kell kezelni:
(COND ((EQ (CAR PÁR) (CAR CS)) NIL) ;CS az első egybeejtendő
((EQ (CADR PÁR) (CAR CS)) ;CS a második egybeejtendő
<LIST (LIST (CAR CS)
(UNION SZOMSZÉDOK (CAR CS>)
((MEMBER (CADR PÁR) (CADR CS)) ;CS szomszédai között van
<LIST (LIST (CAR CS)
(REMOVE (CAR PÁR) (CADR CS>) ;a második egybeejtendő
(T (LIST (SUBST (CADR PÁR) (CAR PÁR) CS> ;egyébként(DE KÖT (CS PÁR)
;két összekötetlen pontot összeköt
;CS a gráf tetszőleges pontja
;a következő eseteket kell kezelni:
(COND ((EQ (CAR PÁR) (CAR CS)) ;CS az első
<LIST (CAR CS) (CONS (CADR PÁR) (CADR CS>); kötendő
((EQ (CADR PÁR) (CAR CS)) ;CS a második
<LIST (CAR CS) (CONS (CAR PÁR) (CADR CS>) ; kötendő
(T CS> ;egyébként
12.3. Algebrai kifejezések differenciálása
A LISP segítségével matematikai kifejezéseket szimbolikusan kezelhetünk, így szimbolikusan felírt matematikai kifejezések összegét, szorzatát, vagy adott szimbólum szerinti differenciálhányadosát képezhetjük úgy, hogy a művelet eredménye ismét egy szimbolikus alakban felírt matematikai kifejezés. Ez a probléma nevezetes szerepet játszott a LISP történetében, annak idején McCarthynak és munkatársainak a LISP megalkotásával egyik fő célja éppen az volt, hogy olyan nyelvet hozzanak létre, amelyben kifejezéseket szimbolikusan lehet differenciálni.
A matematikai kifejezéseket a LISP-ben prefixjelöléssel ábrázoljuk, pl. az
x^4 + x^2*y^2 + y^4
kifejezést így írhatjuk át LISP kifejezéssé:
(PLUS (EXPT X 4) (TIMES (EXPT X 2) (EXPT Y 2)) (EXPT Y 4))
A következőkben prefixjelöléssel, LISP kifejezésként felírt kifejezések differenciálására adunk meg eljárást. Az egyszerűség kedvéért csak olyan kifejezésekkel foglalkozunk, amelyek a négy alapművelet, a hatványozás, és a negatív előjel segítségével épülnek fel szimbolikus változókból és egész számokból.
Ha a kifejezések differenciálásának ismert szabályaiból indulunk ki, észrevehetjük, hogy az összeg, szorzat stb. differenciálásának szabályai rekurzív összefüggések; pl. egy összeg differenciálhányadosát úgy kapjuk meg, hogy a tagok differenciálhányadosának összegét képezzük.
A DERIV függvény megvizsgálja a differenciálandó kifejezést, és annak típusától (összeg, szorzat stb.) függően alkalmazza a megfelelő segédfüggvényt, amely az adott típusú kifejezés differenciálását végzi el. Az összeg, ill. szorzat differenciálásának szabályait csak kéttagú összegre, ill. kéttényezős szorzatra írtuk fel, a segédfüggvényeket azonban úgy kell definiálnunk, hogy az n-tagú összegre és n-tényezős szorzatra is alkalmazhatók legyenek. A DERIV függvénynek tehát a kifejezés típusától függően más-más segédfüggvényt kell alkalmaznia; az eseteket egy SELECTQ kifejezéssel választjuk szét. KIF a differenciálandó kifejezés, X pedig a szimbolikus változó, amely szerint differenciálunk:
(DEFUN DERIV (KIF X)
(COND ((ATOM KIF) ;Ha a kifejezés atom,
(COND ((EQ KIF X) 1) ; X
(T 0))) ;konstans.
(T (SELECTQ (CAR KIF) ;Ha nem atom
(PLUS (DERPLUS KIF X)) ;összeg
(DIFFERENCE (DERDIFF KIF X)) ;különbség
(TIMES (DERTIMES KIF X)) ;szorzat
(QUOTIENT (DERQUOTIENT KIF X)) ;hányados
(MINUS (DERMINUS KIF X)) ;negatív
(EXPT (DEREXPT KIF X)) ;hatvány
(PROGN (PRIN1 KIF) ;egyébként:
(PRINTC "Kifejezes nem megfelelo alaku"]
A SELECTQ utolsó argumentumára azért van szükség, hogy ha a DERIV argumentuma olyan kifejezés, amelyre nem adtunk meg deriválási szabályt, akkor ezt egy figyelmeztető üzenet kiírásával jelezze, és a NIL értéket adja.
A segédfüggvények:
(DEFUN DERPLUS (KIF X) ;összeg
(CONS 'PLUS ;n-tagú
(MAPCAR (CDR KIF) (FUNCTION
(LAMBDA (KIF) (DERIV KIF X](DEFUN DERTIMES (KIF X) ;n-tényezős szorzat
(COND ((NULL (CDDDR KIF))
(DERTIMES2 KIF X)); ha kéttényezös
(T (LIST 'PLUS ; különben rekurzívan
(CONS 'TIMES ; alkalmazzuk a
(CONS (CADR KIF) ; differenciálási
(DERTIMES (CONS 'TIMES (CDDR KIF)) ; szabályt
X)))
(CONS 'TIMES
(CONS (DERIV (CADR KIF) X)
(CDDR KIF]
A DERTIMES függvény a kéttényezős szorzatra a DERTIMES2 segédfüggvényt alkalmazza:
(DEFUN DERTIMES2 (KIF X) ;kéttényez>s szorzat
(LIST 'PLUS
(LIST 'TIMES
(CADR KIF)
(DERIV (CADDR KIF) X))
(LIST 'TIMES
(CADDR KIF)
(DERIV (CADR KIF) X](DEFUN DERMINUS (KIF X)
(LIST 'MINUS (DERIV (CADR KIF) X] ;negatív(DEFUN DERQUOTIENT (KIF X) ;hányados
(LIST 'QUOTIENT
(LIST 'DIFFERENCE
(LIST 'TIMES (DERIV (CADR KIF) X) (CADDR KIF))
(LIST 'TIMES (CADR KIF) (DERIV (CADDR KIF) X)))
(LIST 'EXPT (CADDR KIF) 2](DEFUN DEREXPT (KIF X) ;hatvány
(LIST 'TIMES
(CADDR KIF)
(LIST 'EXPT (CADR KIF) (SUB1 (CADDR KIF)))
(DERIV (CADR KIF) X]
Alkalmazzuk néhány kifejezésre a DERIV függvényt:
* (DERIV '(PLUS X Y) 'X))
(PLUS 1 0)* (DERIV 'X 'X))
1* (DERIV 'Y 'X))
0* (DERIV '(MINUS X) 'X))
(MINUS 1)* (DERIV '(PLUS X (TIMES X Y)) 'X)
(PLUS 1 (PLUS (TIMES X 0) (TIMES Y 1)))* (DERIV '(PLUS (TIMES X Z) (DIFFERENCE Y X)) 'X)
(PLUS (PLUS (TIMES X 0) (TIMES Z 1)) (DIFFERENCE 0 1))* (DERIV '(QUOTIENT X (PLUS X 2)) 'X)
(QUOTIENT (DIFFERENCE (TIMES 1 (PLUS X 2)) (TIMES X (PLUS 10))) (EXPT (PLUS X 2) 2))* (DERIV '(SIN X) 'X) ;nem adtunk meg differenciálási szabályt
(SIN X) Kifejezes nem megfelelo alaku
A DERIV függvény segítségével tehát előállítottuk kifejezések differenciálhányadosát szimbolikus alakban. Az utolsó feladatban a kiírt üzenet jelzi, hogy a DERIV függvényt olyan argumentumra alkalmaztuk, amelynek deriválására nincs felkészítve.
Tulajdonképpeni feladatunknak azonban ezzel csak egy részét oldottuk meg. Nem foglalkoztunk azzal a problémával, hogy hogyan alakíthatunk prefix alakra egy matematikai jelöléssel felírt kifejezést, sem pedig azzal, hogy hogyan alakíthatjuk a prefix alakban kapott eredményeket infix alakra. Ezekre az átalakításokra viszonylag nem túl bonyolult algoritmusok ismeretesek.
Jóval nehezebb feladatot jelent a kifejezések egyszerűsítése. Megfigyelhetjük, hogy a DERIV függvény által előállított kifejezéseknek szinte mindegyike egyszerűbb alakban is felírható olyan átalakításokkal, amelyeket a papíron, ceruzával végzett számításokban rendszerint el is végzünk. Tekintsük az egyszerű
* (DERIV '(PLUS X (TIMES X Y)) 'X)
(PLUS 1 (PLUS (TIMES X 0) (TIMES Y 1)))
példát! A kapott kifejezést egyszerűbb alakra hozhatjuk, ha a (TIMES Y 1) kifejezést a vele egyenértékű Y kifejezéssel, a (TIMES X 0) kifejezést pedig 0-val helyettesítjük. Ezzel a (PLUS 1 (PLUS 0 Y)) alakra hoztuk a kifejezést; ez még tovább egyszerűsíthető, ha a (PLUS 0 Y) kifejezést Y-nal helyettesítjük. Végül tehát a kifejezést a vele egyenértékű, de egyszerűbb
(PLUS 1 Y)
alakra hoztuk az
X + 0
X * 1
X * 0
azonosságok alkalmazásával.
Általánosságban úgy is felvethető a kérdés, hogy egy tetszőleges kifejezést hogyan hozhatjuk a legegyszerűbb alakra. Erre a problémára azonban már nem lehet egyértelmű választ adni. Még viszonylag egyszerű esetekben sem lehet ugyanis megmondani, hogy melyik egy kifejezés legegyszerűbb alakja. A
(PLUS (EXPT A 2) A)
kifejezést helyettesíthetjük a vele egyenértékű
(TIMES A (PLUS A 1))
kifejezéssel, az azonban már nem egyértelmű, hogy melyik az egyszerűbb alak. A kérdésre csak akkor lehet válaszolni, ha tudjuk, hogy mi a további feladat, amit a kifejezésekkel el kell végezni. A kifejezések egyszerűsítése a matematikai kifejezések szimbolikus kezelésével foglalkozó számítógépes algebrának egyik legbonyolultabb problémája.
12.4. Szótárkezelő függvények
A szótárak tárolásának egyik elterjedt módja a következő: az ábécé minden betűjéhez hozzárendelünk egy mutatót. Az egy bizonyos betűvel kezdődő szavak azután olyan alszótárat alkotnak, amely a megfelelő mutatóval jelzett címen található, és ugyanezen az elven épül fel: pl. az a betűvel kezdődő szavak alszótárában ismét az ábécé minden betűjéhez tartozik egy mutató, s ezek a mutatók jelzik, hol találhatók az ab, ac stb. kezdetű szavak alszótárai. Ha egy ilyen "szókezdet" egyben szó is (mint pl. az ab a németben), akkor a hozzá tartozó alszótár mindenekelőtt az ehhez a szóhoz tartozó szótári információt tartalmazza, csak azután a többi betűhöz tartozó mutatókat. Ha az illető szó nem létezik a nyelvben (mint pl. az ac a magyarban), akkor valamilyen egységes, speciális jel áll a szótári információ helyén. Ha egy szókezdethez nem tartozik folytatás (mint pl. az abc-hez a magyarban), akkor a neki megfelelő alszótárban - ha egyáltalán van - természetesen nem szerepelnek további alszótármutatók; és általában, mindig csak azok az alszótármutatók vannak feltüntetve, amelyek valahol mélyebben tartalmaznak szótári információkat.
Természetesen adódik, hogy egy LISP-ben írt szótárkezelő rendszerben az egyes mutatók valóságos, listacellákban tárolt mutatók legyenek; a szótári információkat szintén listában tároljuk; a szótári információ hiányát pedig értelemszerűen az üres lista, a NIL jelölje. Megjegyzendő, hogy a nyelvészek igen sokféle szótári információt szoktak számon tartani (pl. ragozási típus, jelentés, igéknél vonzatok stb.), tehát a szótári információt mindenképpen tovább tagolható formában - listában - kell tartanunk. Itt azonban a további tagolással nem foglalkozunk, legfeljebb a szófajt és a latin jelentést írjuk be szemléltetésképpen. Annyit azonban érdemes biztosítanunk, hogy az ún. homonímák (azonos alakú szavak) egyszerre több szótári információt is tartalmazhassanak. (Pl. a vár szó azt, hogy "főnév, jelentése: castrum" és azt is, hogy "ige, jelentése: exspecto".) Ezért a szótári információt eleve szótári információk listájaként érdemes elképzelni.
Lássuk most már, hogyan fest ténylegesen egy alszótár:
(kezdőbetű információk
(következőbetű1 ...)
(következőbetű2 ...)
...)
Egy a betűvel kezdődő szavakat tároló alszótár pl. ilyen lehet:
(A ((BETŰ NEVE) (NÉVELŐ))
(B NIL
(L NIL
(A NIL
(K ((FŐNÉV))))))
(D ((IGE))
(Ó ((FŐNÉV))))
... )
Ebben a részletben a következő szavak találhatók:
A
A
ABLAK
AD
ADÓ... BETŰ NEVE
... NÉVELŐ
... FŐNÉV
... IGE
... FŐNÉV
Természetesen benne vannak a nemlétező (szótári információval nem rendelkező) AB, ABL, ABLA "szavak" is. Az egész szótárat egyszerűen ilyen alszótárak listájának tekintjük, vagyis olyan alszótárnak, amelyből a kezdőbetű és a hozzá tartozó szótári információ hiányzik.
Mivel az ilyen szótárban a szavak mintegy betűnként "elszórva" szerepelnek, nemcsak szavakat visszakeresni, de új szavakat beírni is külön függvények segítségével érdemes. Kezdjük azzal, ahogyan egy ilyen alakú szótárat fel lehet építeni, ill. bővíteni lehet.
Mindenekelőtt egy olyan függvényt definiálunk, amely egy szóból és a hozzá tartozó információból vadonatúj alszótárat alkot. Nevezzük ezt a függvényt ÚJ-ALSZÓTÁR-nak. Az egyszerűség kedvéért az ÚJ-ALSZÓTÁR első argumentuma a szó betűiből álló lista legyen. Így ugyanis rekurzívan definiálhatjuk a függvényt:
<DE OJ-ALSZÓTÁR (SZÓ INFORMÁCIÓ)
(COND ((NULL (CDR SZÓ)) ;Az utolsó betűnél tartunk.
(LIST (CAR SZÓ) INFORMÁCIÓ))
(T (LIST (CAR SZÓ) NIL
(ÚJ-ALSZÓTÁR (CDR SZÓ) INFORMÁCIÓ>* (SETQ ALSZÓTÁR
(ÚJ-ALSZÓTÁR '(V Á R) '((FŐNÉV CASTRUM) (IGE EXSPECTO>
(V NIL (Á NIL (R ((FŐNÉV CASTRUM) (IGE EXSPECTO)))))
A következő függvény, amelyre szükségünk lesz, egy már létező alszótárat egészít ki egy új szóval. Definiáljuk az ALSZÓTÁRBA-ÍR függvényt:
(DE ALSZÓTÁRBA-ÍR (SZÓ INFORMÁCIÓ ALSZÓTÁR)
(AND (EQ (CAR ALSZÓTÁR) (CAR SZÓ)) ;Meggyőződünk arról,
; hogy a jó alszótárba írunk-e.
(COND <(NULL (CDR SZÓ)) ;A szó utolsó betűjénél tartunk,
;most kell beírni az információt.
(CONS (CAR ALSZÓTÁR) ;A kezdőbetű.
(CONS (APPEND
(CADR ALSZÓTÁR) ;A régi információ.
INFORMÁCIÓ) ;Az új információ.
(CDDR ALSZÓTÁR> ;Az al-alszótárak.
(T (CONS (CAR ALSZÓTÁR) ;A kezdőbetű.
(CONS (CADR ALSZÓTÁR) ;A régi információ.
(SZÓTÁRBA-ÍR (CDR SZÓ) ;Ezt a függvényt
; még definiálnunk kell!
INFORMÁCIÓ (CDDR ALSZÓTÁR>* (SETQ ALSZÓTÁR (ALSZÓTÁRBA-ÍR '(V Á G) '((IGE SECO)) ALSZÓTÁR))
(V NIL
(Á NIL
(R ((FŐNÉV CASTRUM) (IGE EXSPECTO)))
(G ((IGE SECO)))))
Az ALSZÓTÁRBA-ÍR függvény a következőképpen működik: ha nem a szó kezdőbetűjének megfelelő alszótárat adunk meg argumentumul, akkor az érték NIL. Ha igen, és a szó egyetlen betűből áll (vagyis az utolsó betűjé?nél tartunk), akkor az alszótárat kiegészíti a megadott információval. Ha pedig egynél több betűből áll a szó, akkor a SZÓTÁRBA-ÍR függvényre bízza a második és további betűk, valamint az információ beírását. (Arról nem gondoskodunk, hogy az új szavak a betűrend szerint megfelelő helyre kerüljenek.)
A SZÓTÁRBA-ÍR függvénynek tehát a következők az argumentumai: egy szó betűiből álló lista (nevezzük BETŰLISTÁ-nak), aszóhoz tartozó információ (nevezzük INF-nek), valamint egy szótár, vagyis alszótárlista. Azt várjuk el ettől a függvénytől, hogy a szótárat módosítva adja értékül: ha van az alszótárak között olyan, amely a szó kezdőbetűjének (a BETŰLISTA első elemének) felel meg, akkor abba írja be a szót, ha nincs, a lista végére illesszen egy új alszótárat, amely a kérdéses szót tartalmazza. A SZÓTÁRBA-ÍR függvényt tehát így definiáljuk:
<DE SZÓTÁRBA-ÍR (BETÜLISTA INF SZÓTÁR)
(COND ((NULL SZÓTÁR); felkészülünk az alszótárak
; szerinti rekurzióra.
(LIST (ÚJ-ALSZÓTÁR BETÜLISTA INF)))
((EQ (CAAR SZÓTÁR)
(CAR BETÜLISTA)) ;Az első alszótárba kell
; beírnunk a szót:
(CONS (ALSZÓTÁRBA-ÍR BETÜLISTA ;Csak ezt az alszótárat
INF (CAR SZÓTÁR)); változtatjuk meg, a többit nem.
(CDR SZÓTÁR)))
(T (CONS (CAR SZÓTÁR) ;Az első alszótárat nem
; változtatjuk meg, a többivel próbálkozunk:
(SZÓTÁRBA-ÍR BETŰLISTA INF (CDR SZÓTÁR>* (SETQ SZÓTÁR (LIST ALSZÓTÁR))
((V NIL
(Á NIL
(R ((FŐNÉV CASTRUM) (IGE EXSPECTO)))
(G ((IGE SECO))))))* (SETQ SZÓTÁR (SZÓTÁRBA-ÍR '(L Á B) '((FŐNÉV P E S)) SZÓTÁR))
((V NIL
(Á NIL
(R ((FŐNÉV CASTRUM) (IGE EXSPECTO)))
(G ((IGE SECO)))))
(L NIL
(Á NIL
(B ((FŐNÉV PES))))))
Láthatjuk, hogy ez a függvény mindhárom eddig definiált szótárfüggvényt (önmagát is beleértve) alkalmazza.
Definiáljunk most olyan függvényt, amely gondosan kikérdez a beírandó szavakról és információkról, és a már definiált függvények segítségével kiegészíti a már létező, ill. létrehozza a még nem létező szótárat. Feltételezzük, hogy a szótár a nyelv nevére utaló atom tulajdonságlistáján a SZÓTÁR tulajdonság alatt helyezkedik el. Nevezzük el ezt a függvényt SZÓTÁR-BŐV-nek.
(DE SZÓTÁR-BÖV (NYELV)
(PROG (SZÓTÁR SZÓ INFORMÁCIÓ MUNKA)
(SETQ SZÓTÁR (GETP NYELV 'SZÓTÁR))
(PRINTC "Tagadó válasz: NIL") ;Feltételezzük,
; hogy a NIL szó nem lesz benne a szótárban.
SZÓHUROK
(PRINTC "Szó?")
(SETQ SZÓ (READ))
(COND ((NULL SZÓ) ;Tagadó válasz.
(PUT NYELV 'SZÓTÁR SZÓTÁR)
(RETURN NYELV))
(T (GO JAVlTÓHUROK))) ;Nem teljesen felesleges.
JAVÍTÓHUROK
(PRINTC "Első információ?")
(SETQ INFORMÁCIÓ (LIST (READ)))
(COND ((NULL INFORMÁCIÓ) ;Tagadó válasz: hibás.
(GO JAVlTÓHUROK))
(T (GO INFORMÁCIÓHUROK))) ;Nem teljesen felesleges.
INPORMÁCIÓHUROK
(PRINTC "További információ?")
(SETQ MUNKA (READ))
(COND ((NULL MUNKA) (GO BEÍR)) ;Tagadó válasz.
(T (SETQ INFORMÁCIÓ
(APPEND INFORMÁCIÓ
(LIST MUNKA))) ;A már létező információ
; vége, újra kérdezünk:
(GO INFORMÁCIÓHUROK)))
BEÍR
<SETQ SZÓTÁR
(SZÓTÁRBA-ÍR (UNPACK SZÓ)
INFORMÁCIÓ SZÓTÁR> ; A lényeg valójában a
; SZÓTÁRBA-ÍR függ vényben történik.
(GO SZÓHUROK)))
Mit jelent a "nem teljesen felesleges" megjegyzés? Azt, hogy az illető GO-kifejezések elhagyásával, ill. az egész feltétel-tevékenység-pár elhagyásával úgyis a megfelelő címkékhez kerülne a vezérlés, hiszen éppen ezek a címkék következnek az illető feltételes kifejezések után. Mégis jobb a felesleges GO-kifejezéseket beleírni a függvénybe, hogy ha a címkék későbbi módosítás miatt távolabbra kerülnek vagy sorrendjük megváltozik, ne kelljen GO-kifejezések utólagos beiktatására gondolnunk.
Példa a SZÓTÁR-BŐV működésére:
* (SZÓTÁR-BŐV 'MAGYAR-LATIN)
Tagadó válasz: NIL
Szó?
* LÁB
Első információ?
* (FŐNÉV PES)
További információ?
* NIL
Szó?
* VÁG
Első információ?
* (IGE SECO)
További információ?
* NIL
Szó?
* VÁR
Első információ?
* (IGE EXSPECTO)
További információ?
* (FŐNÉV CASTRUM)
További információ?
* NIL
Szó?
* NIL
MAGYAR-LATIN* (GETP 'MAGYAR-LATIN 'SZÓTÁR)
((V NIL
(Á NIL
(R ((FŐNÉV CASTRUM) (IGE EXSPECTO)))
(G ((IGE SECO)))))
(L NIL
(Á NIL
(B ((FŐNÉV PES))))))
Más hasznos függvényeket is definiálhatunk. Elsőként a nehezen áttekinthető, "elszórt" szótárformát "szép" listaformává alakító függvényt definiálunk. Ezt a függvényt SZÓTÁRLISTÁ-nak fogjuk nevezni. Mindenekelőtt az egyes alszótárakat listává alakító ALSZÓTÁRLISTA segédfüggvényt definiáljuk, amelynek argumentuma egy alszótár és a szó első betűit tartalmazó lista, a SZÓ-ELEJE. Ha az alszótár a listázandó szótárnak eleme, nem pedig egy mélyebben elhelyezkedő alszótár, akkor az utóbbi változónak az értéke NIL lesz.
(DE ALSZÓTÁRLISTA (ALSZÓTÁR SZÓ-ELEJE)
(COND ((NULL ALSZÓTÁR) NIL)
<(NULL (CADR ALSZÓTÁR)) ;Nem szóvég.
(SZÓTÁRLISTA (CDDR ALSZÓTÁR) ;Az alszótár alszótárait
(APPEND SZÓ-ELEJE ; kell listázni.
(LIST (CAR ALSZÓTÁR>
(T (CONS (CONS <PACK
(APPEND ;Ennyi egy szócikk.
SZÓ-ELEJE (LIST (CAR ALSZÓTÁR>
(CADR ALSZÓTÁR))
(SZÓTÁRLISTA (CDDR ALSZÓTÁR) ;Mint amikor nem
(APPEND SZÓ-ELEJE ; találtunk
(LIST (CAR ALSZÓTÁR> ; szövéget.* (ALSZÓTÁRLISTA (CAR SZÓTÁR))
((VÁR (IGE EXSPECTO) (FŐNÉV CASTRUM))
(VÁG (IGE SECO))
(LÁB (FŐNÉV PES)))
Megfigyelhetjük, hogy a definícióban maga a SZÓTÁRLISTA a segédfüggvény, tehát a SZÓTÁRLISTA és az ALSZÓTÁRLISTA egymást alkalmazó függvények. Lássuk most a SZÓTÁRLISTA definícióját:
(DE SZÓTÁRLISTA (SZÓTÁR SZÓKEZDET)
(MAPCAPP SZÓTÁR (FUNCTION (LAMBDA (ALSZÓTÁR)
(ALSZÓTÁRLISTA ALSZÓTÁR SZÓKEZDET>
A végleges szótárlistázó függvénynek csak egy argumentuma lesz, a nyelv, amelynek szótárát listázni kívánjuk. A szótárból alkotott listát betűrendbe is szedjük:
(DE SZÓTÁRL (NYELV)
(RENDEZ-A (SZÓTÁRLISTA (GETP NYELV 'SZÓTÁR>* (SZÓTÁRL 'MAGYAR-LATIN)
((LÁB (FŐNÉV PES))
(VÁG (IGE SECO))
(VÁR (IGE EXSPECTO) (FŐNÉV CASTRUM)))
A másik hasznos függvénynek, amelyet itt definiálunk, egy szó betűiből álló lista és egy szótár az argumentuma, értéke pedig a szóhoz tartozó információ:
(DE KIKERES (SZÓ SZÓTÁR)
(AND (SETQ SZÓTÁR ;Legyen a SZÓTÁR a SZÓ
(ASSOC (CAR SZÓ) ; kezdőbetűjének megfelelő
SZÓTÁR)) ; alszótár.
(COND ((NULL (CDR SZÓ)) ;Elérkeztünk a SZÓ végéhez.
(CADR SZÓTÁR))
(T (KIKERES (CDR SZÓ)
(CDDR SZÓTÁR>* (KIKERES '(V Á R) (GETP 'MAGYAR-LATIN 'SZÓTÁR))
((IGE EXSPECTO) (FŐNÉV CASTRUM))
Mivel ennek a függvénynek is a szó betűiből álló lista és a teljes szótár az argumentumai, egy kényelmesebben használható INFORMÁCIÓ függvényt is érdemes definiálni:
(DE INFORMÁCIÓ (SZÓ NYELV) (KIKERES (UNPACK SZÓ)
(GETP NYELV 'SZÓTÁR)))* (INFORMÁCIÓ 'VÁG 'MAGYAR-LATIN)
((IGE SECO))
A. A LISP-dialektusok
A LISP nyelvet 1959-ben az MIT-n (Massachusetts Institute of Technology, Cambridge, Massachusetts) fejlesztették ki. Egy korai (IBM 704) számítógépen futó LISP 1.5 volt az első LISP rendszer. Az következő években két új változatát fejlesztették ki, amelyek - eltérő módon - a nyelv alkalmazhatóságát jelentősen növelték.
A BBN LISP (Bolt-Beranek-Newman) változatot először PDP-1, majd SDS-940 típusú számítógépen implementálták, később a PDP-10-es gépen mint INTERLISP vált ismertté. Napjainkban az INTERLISP használható a VAX számítógépeken, és több változata futtatható az IBM cég által gyártott gépeken is. A XEROX cég által gyártott "Dandelion" LISP- gépeknek is ez a változat (INTERLISP-D) az alapnyelve. Ehhez a dialektushoz tartozik a TLC LISP, a LISP F3 és a LISP F4 is.
A másik változatot először a PDP-6-os számítógépen fejlesztették ki, majd Maclisp néven a DEC-20-as számítógépre implementálták. A Maclisp egy korai változatát a stanfordi egyetemen továbbfejlesztették, ez lett a LISP 1.6. Ennek két további változatát fejlesztették ki:
Eközben a Maclisp változatot továbbfejlesztették az MIT-n, ennek következtében több új LISP-változat született. A legfontosabb a Lisp machine LISP, amely később két további változat alapja lett.
A felsoroltak mellett VAX típusú gépekre több új változat is készült. A Franz Lisp változat a UNIX operációs rendszer alatt, a NIL változat a VMS operációs rendszer alatt fut.
Ekkorra a Maclisp leszármazottai is már annyira különböztek egymástól, hogy ezért 1981-ben egy bizottság hozzáfogott - elsősorban a Maclisp leszármazottakat alapul véve - egy, a LISP-változatok előremutató tulaj-donságait egyesítő új, Common Lisp-nek nevezett változat megalkotásához. 1986-ban az IFIP (International Federation for Information Processing) munkabizottságot hívott létre, hogy a LISP nyelvre szabványt készítsen. A szabvány alapjául a Common Lisp szolgál.
Egy másik fontos LISP-dialektus, a Scheme elsősorban oktatási célra készült, ez a nyelv képezi az alapját az MIT számítástechnikai kurzusainak, ezért gyorsan terjed, és sok gépen implementálták.
A következőkben a legfontosabb szempontokat alapul véve összehasonlítjuk az egyes LISP-változatokat. A téma kimerítő tárgyalására nem vállalkozunk - ez a könyv terjedelmét a többszörösére növelhetné -, célunk az, hogy felhívjuk a figyelmet azokra a területekre, amelyeknél - valamely változat használatakor - eltérést tapasztalhatunk a könyvben leírtaktól.
Az EVAL-QUOTE változatok
Ma már csak történeti érdekességű szempont két LISP-változat összehasonlításakor, hogy a változat EVAL vagy EVAL-QUOTE típusú-e. A különbség a két típus között az, hogy az EVAL-QUOTE változatoknál a legfelső szinten más alakban kell megadnunk a formákat, mint a mélyebb szinteken. Az EVAL típusú változatoknál ilyen megkülönböztetés nincs. Mint láttuk, az (A B C) lista fejét egy EVAL típusú változatban úgy kapjuk, hogy egy listát írunk le, amelynek első eleme a CAR függvénynév. Ezzel szemben egy EVAL-QUOTE változatban a legfelső szinten az (A B C) lista fejét úgy kapjuk, hogy először leírjuk a függvény nevét, esetünkben a CAR szimbólumot, majd egy listában megadjuk az argumentumokat:
* CAR ((A B C)
A
A legfelső szinten az argumentumokra itt nem kell a QUOTE függvényt alkalmazni, mert az értelmezőprogram ezt önmagától is megteszi. (Ezért hívják ezeket a változatokat EVAL-QUOTE típusúaknak.)
A jelenleg használatos LISP-változatok túlnyomó többsége EVAL típusú, könyvünkben mi is ezt a típust vettük alapul. A McCarthy-féle LISP 1.5 azonban EVAL-QUOTE típusú volt.
A karakterkészlet
A következő alapvető eltéréseket a megengedett karakterkészlettel kapcsolatban tapasztalhatjuk. A karakterkészlet általában bővebb, mint amit könyvünkben alapul vettünk (természetesen a változatok az ékezetes karaktereket általában nem tartalmazzák). Így a szimbólumokban előfordulhatnak pl. a !, #, $, &, *, ©, - karakterek, kis- és nagybetűk is. Az "engedékeny" változatok betűnek fogadnak el minden karaktert, amely nem számjegy, és szimbólumnak fogadnak el minden karaktersorozatot, amely nem szám. Ilyen változat az INTERLISP, amelyben érvényes szimbólum pl. az 1987:1-SŐ-KIADÁS karaktersorozat is. Az "engedékeny" változatok sem engedik meg azonban, hogy a szimbólum belsejében pont (.) vagy szóköz karakter legyen.
Külön ki kell térnünk a kis- és nagybetűk problémájára. Azokban a LISP-változatokban, amelyek a kisbetűk használatát megengedik, általában az alábbi két megoldás valamelyikét alkalmazzák: az egyikben a LISP-értelmező megkülönbözteti a kis- és nagybetűket egymástól, tehát az ABBA, Abba, abba karaktersorozatokat különböző szimbólumoknak tekinti. Más LISP rendszerek megengedik ugyan, hogy az S-kifejezések beírásakor kis- és nagybetűket is használjunk, azonban a belső ábrázolásban nem különbözteti meg őket egymástól. Ezekben a rendszerekben tehát a programozó beírhatja az ABBA, Abba, ill. abba karaktersorozatok bármelyikét, az értelmező azonban ezek mindegyikét ugyanazon szimbólumként értelmezi.
A beépített függvények
Az egyes változatok között a legtöbb eltérés a beépített függvényekben van. A különböző dialektusok más és más beépített függvényeket tartalmaznak. Lehet, hogy ugyanazt a feladatot megoldó függvénynek más a neve, vagy az azonos nevű függvény más célt szolgál, esetleg a függvények csak abban különböznek egymástól, hogy az argumentumaikat más sorrendben várják. Pl. ha az INTERLISP változatban a MAPCAR függvényt használjuk, a
* (MAPCAR '(13 -24 -5 -6) 'ABS)
(13 24 5 6)
helyes kifejezés. A Common Lisp változatban fordított sorrendben kelt megadnunk a függvény argumentumait:
* (MAPCAR 'ABS '(13 -24 -5 -6))
(13 24 5 6)
A Common Lisp-ben használható SYMBOLP függvény megfelelőjét az INTERLISP-ben LITATOM-nak hívják. A két függvény teljesen megegyezik - mindkettő eldönti az argumentumáról, hogy szimbólum-e -, csak a ne-vükben különböznek.
A beépített függvények tükrözik azt is, hogy a fejlesztők milyen célra szánták a nyelvet: az egyik változatban pl. a bemeneti és kimeneti függvények bőséges választéka áll rendelkezésünkre, a másik változat pedig nagyobb számban tartalmaz aritmetikai függvényeket.
A forma első eleme
A legtöbb LISP-ben a forma első eleme csak függvény név, lambdakifejezés vagy funarg-kifejezés lehet (pl. ilyen az INTERLISP, a Common Lisp, a Standard LISP). Van néhány olyan változat is (pl. a Scheme), amelyben a forma feje tetszőleges S-kifejezés lehet. A forma kiértékelésekor ezekben a rendszerekben először ez az S-kifejezés értékelődik ki, ennek értéke mindig egy függvénynév kell, hogy legyen. Ez a függvény alkalmazódik a formában megadott argumentumokra. Pl. a Scheme változatban nem vezet hibához a következő kifejezés:
* ((CADR '(PLUS TIMES DIVIDE)) 3 9)
27
Ugyanez a kifejezés az INTERLISP-ben Undefined function hibaüzenetet eredményez.
Az üres lista feje és farka
Fontos tudni, hogy abban a változatban, amelyet használunk, van-e értéke a (CAR NIL) és a (CDR NIL) formáknak, vagyis értelmezve van-e az üres lista feje és farka. Némely LISP-változat (pl. a Standard LISP) ezek kiértékelésekor hibajelzést ad (ilyen az IS-LISP is), más változatban (pl. az INTERLISP, vagy a Common Lisp esetében) ezek értéke NIL. Ennek megfelelően a CONS függvény is az utóbbi változatokban az általunk leírttól eltérően működik: a 2.4. szakaszban láttuk, hogy (CONS (CAR LISTA) (CDR LISTA)) kifejezés értéke az eredeti LISTA változó értéke, ha az egy nem üres lista volt.
Az olyan LISP-változatban azonban, amely az üres lista fejét és farkát NIL-ként értelmezi, akkor ha a LISTA értéke (), akkor a (CONS (CAR LISTA) (CDR LISTA)) kifejezés értéke (()) lesz. Ezekben a változatokban tehát erre az esetre nem teljesül a CAR, CDR és CONS függvényeknek a 2.4. szakaszban leírt összefüggése, mivel az üres lista nem állítható elő úgy, hogy CAR-ját és CDR-jét a CONS függvénnyel összekapcsoljuk:
* (CAR NIL)
NIL* (CDR NIL)
NIL* (CONS NIL NIL)
(NIL)
ami nem azonos az üres listával.
Az atomok feje és farka
Hasonlóképpen eltérhetnek egymástól a LISP-változatok abban is, hogy értelmezik-e az atomokra a fej és farok fogalmát. A (CAR 'X) és (CDR 'X) alakú formák kiértékelése pl. az INTERLISP-ben nem vezet hibához, itt a (CAR 'X) kifejezés értéke az X atom értéke, a (CDR 'X) kifejezés értéke pedig X tulajdonságlistája. A Common Lisp-ben azonban az ilyen kifejezések hibához vezetnek, a CAR és CDR függvény argumentuma csak lista lehet.
A feltételes kifejezések
Nem minden változatban használhatunk általánosított feltételes kifejezéseket. Az ilyen rendszerekben minden egyes feltételt csak egy tevékenység követhet. Ha ilyen változatot használunk, az általánosított feltételes kifeje-zéseket a PROGN függvény segítségével írhatjuk át. Pl. a
(COND ((ATOM (CADR LISTA))
(PRINT 'ATOM)
(SETQ MEGVAN (CADR LISTA))
(EQUAL MEGVAN 'TATU))
(T (PRINT 'NINCS) NIL))
általánosított feltételes kifejezés helyett ezt írhatjuk:
(COND ((ATOM (CADR LISTA))
(PROGN (PRINT 'ATOM)
(SETQ MEGVAN (CADR LISTA))
(EQUAL MEGVAN 'TATU)))
(T (PROCN (PRINT 'NINCS) NIL)))
Függvények definiálása
A Maclisp, a Common Lisp, a Lisp machine Lisp változatokban (ilyen az IS-LISP is) a DEFUN segítségével definiálhatunk függvényeket:
(DEFUN ADD3 (SZ) (ADD1 (ADD1 (ADD1 SZ))))
A DEFUN argumentumai (a DE-hez hasonlóan) a függvénynév, a változók listája és a függvénytörzs. Abban az esetben, ha akárhány-argumentumú függvényt definiálunk, a DEFUN használatakor is egyetlen szimbólum áll a változólista helyén:
(DEFUN DUPLA SOR (LIST SOR SOR))
A DEFUN-t nem eval-típusú függvények definiálására is használhatjuk. Ekkor a definícióban a függvény típusát is meg kell adnunk a következőképpen:
(DEFUN függvénynév FEXPR változólista törzs)
például:
(DEFUN NYOMTAT FEXPR (EZT) (PRINT EZT))
A DEFUN második argumentumaként megadott FEXPR szimbólum jelzi az értelmezőnek, hogy nem eval-típusú függvényt definiálunk.
Ezekben a rendszerekben nincs lehetőségünk akárhány-argumentumú, nem eval-típusú függvények definiálására, de ún. makrókat definiálhatunk. A makrókat az értelmezőprogram a függvényektől lényegesen eltérő módon kezeli. Ha a kiértékelendő forma olyan lista, amelynek feje makrónév, akkor az értelmezőprogram a makró definícióját (amelynek mindig egy lambda-változója van) magára erre a formára alkalmazza, és a kapott értéket - amelyet a makró kifejtésének nevezünk - kiértékeli.
A makrókat is a DEFUN segítségével definiálhatjuk, a definícióban a MACRO szimbólum jelzi, hogy makródefinícióról van szó A következő példa egy makró definiálását mutatja be. Az ESREVER makró az argumentumként megadott tetszőleges számú S-kifejezést egy listában, fordított sorrendben adja meg:
(DEFUN ESREVER MACRO (X)
(LIST 'REVERSE (LIST 'QUOTE (CDR X))))* (ESREVER A B CD (E F G))
((E F G) CD B A)
A makrókifejtéskor a REVERSE szimbólumból és az argumentumokból a (REVERSE '(A B CD (E F G))) forma készül el, amely kiértékelve a fordított listát adja.
Mivel a makrók nem függvények, ezért sem a MAP, sem az APPLY függvények alkalmazásakor nem szerepelhetnek függvény-argumentumként.
Az UCI-LISP és a TLC LISP változatokban szintén van makró-definiálási lehetőség, ezekben a változatokban a függvények definiálására a DE és DF függvények, makrók definiálására a DM (define macro) függvény szolgál.
A függvények alkalmazásakor néhány rendszerben (pl. a Standard LISP- ben) hibajelzést kapunk akkor, ha a függvényt nem annyi argumentumra alkalmazzuk, mint ahány lambdaváltozó szerepel a függvény definíciójában. Más rendszerekben (pl. az INTERLISP-ben) ez nem vezet hibához: ha kevesebb argumentumra alkalmazzuk a függvényt, azoknak a változóknak, amelyekhez nem tartozik argumentum, az értéke NIL lesz; ha pedig több argumentumra alkalmazzuk a függvényt, a fölösleges argumentumokat az értelmező figyelmen kívül hagyja.
A függvénydefiníciók tárolásában is lehetnek eltérések az egyes változatok között. Sok LISP rendszerben nem a függvény tulajdonságlistáján tárolódik a függvény definíciója, ezért a GETP és PUT függvényekkel nem ke-zelhetjük őket. A GETD és a PUTD - ha léteznek ezek a függvények - ekkor is alkalmazható.
A szabad változók értékének kezelése
Fontos tudnunk, hogy az általunk használt változat hogyan értékeli ki a szabad változókat, mert az ebből eredő hibák nem jelentkeznek közvetlenül, sokszor csak nehezen lehet felderíteni őket. Az egyik lehetőség, hogy az értelmező a szabad változó értékét dinamikusan határozza meg, tehát azt az értékét veszi alapul, amellyel a változó a kiértékeléskor rendelkezik. Az INTERLISP változat ezt az elvet követi. A másik lehetőség az, hogy az értelmező a szabad változó értékét lexikálisán (statikusan) határozza meg, tehát a szabad változó azon értékét tekinti, amellyel a függvény definiálásakor rendelkezett. Így értékeli ki a szabad változókat pl. a Common Lisp.
Az iteratív eszközök
Az iteratív eszközök közül a PROG szinte minden LISP-változatban megtalálható. A DO azonban csak az újabb rendszerekben használható, a McCarthy féle LISP 1.5-ben már volt PROG, de DO még nem. A PROG-kifejezések tekintetében kevés az eltérés az egyes rendszerek között, de a DO, az UNTIL és a WHILE függvények sok változatban teljesen hiányoznak, vagy másként használhatók. Így pl. a Common Lisp-ben a DO törzsében is lehet RETURN-kifejezés.
B. Az IS-LISP sajátosságai
A változók nevei betűkből, számjegyekből, valamint speciális karakterekből állhatnak (ezeket képes változó, ill. függvénynévként értelmezni). A szögletes zárójel (]) a "nagyzárójel" szerepét tölti be (az összes nyitott nyitózárójelet lezárja).
A szövegszerkesztő segítségével készíthetjük LISP "programjainkat" (amelyek gyakorlatilag függvények, melyek által szolgáltatott eredmények újabb függvények paramétereiként jelenhetnek meg). A már lefordított (értelmezett) függvények újraszerkesztését, alakítását a
(FEDIT név)
utasítás segítségével tehetjük meg, ahol név a függvény neve.
Az így szerkesztett programban azonban már a név helyén LAMBDA szó áll (ez a már korábban ismertté vált, már értelmezett utasítás belső jelzésére szolgál). A szerkesztés végét az ESC billentyűvel közölhetjük a programmal, amely a módosításnak megfelelően újrafordítja azt.
Programok kimentése, betöltése
A LISP-rendszer bővítése után kapott új állapotot (függvények, változók) elmentve, a későbbiek során ettől az adott szinttől folytathatjuk munkánkat. A mentést a
(SAVE "név")
utasítással, a visszatöltést pedig
(LOAD "név")
segítségével tehetjük meg.
IS-LISP függvények
A következőkben a beépített függvényeket soroljuk fel, megadva a hívási paramétereiket, valamint a típusukat. Ez a felsorolás lehetőség szerint az irodalomtól való eltérést mutatja.
A típusok a következőek lehetnek:
| Fügvény |
szolgáltatott érték |
leírás |
típus |
| (ABS szám1) szám1 | szám1=abs(szám) | abszolútérték |
subr |
| (ADD1 szám1) | szám2 | szám2=szám1+1 |
subr |
| (APPEND lista1 lista2) | kista | lista=list1+lista2 |
subr |
| (AT sor oszlop) | NIL | a kurzort a sor, oszlop helyre mozgatja | |
| (ATOM x) | T vagy NIL | T (igaz) értéket ad ha az x atom, nem lista |
subr |
| (BALNK) | space | a space karaktert tárolja |
id |
| (BAND2 szám1 szám2) | szám | szám=(szám1 AND szám2) |
subr |
| (BEAM kifejezés) | NIL |
Amennyiben a kifejezés nem NIL, akkor a rajzolás az adott videocsatornán bekapcsolódik, egyébként kikapcsolt lesz |
subr |
| (BNOT szám) | szám | bitenként negál |
subr |
| (BOR2 szám1 szám2) | szám | bitenkénti VAGY művelet |
subr |
| (BORDER szám) | NIL | a keretszínt állítja be |
subr |
| (BXOR@ szám1 szám2) | szám | szám=szám1 XOR szám2 |
subr |
| (CAPTURE régi új) | NIL | átirányítja a régi csatornáról történő olvasási műveleteket az új csatornára | |
| (CHARACTER szám) | betű | a számnak megfelelő ASCII karaktert adja |
subr |
| (CHARP x) | T vagy NIL | T ha a paraméter változó, egyébként NIL |
subr |
| (CHARS par) | szám | a par hosszát adja |
subr |
| (CLEAR) | NIL | képernyőtörlés |
subr |
| (CLOSE szám) | szám |
Ha a szám egy érvényes csatorna száma, amelyik megnyitott file, úgy a file lezárásra kerül |
subr |
| (CODEP x) | T vagy NIL | T ha x kódpointer, egyébként NIL |
subr |
| (COMMENT szöveg) | NIL | megjegyzés |
fsubr |
| (CREATE csatorna név) | szám | név file megnyitása |
subr |
| (CURSOR kif) | NIL | kurzor ki-be |
subr |
| (DEFVIDEO mód gmód gszín) | NIL |
szöveges és grafikus paraméterek beállítása (mód text-hez 40 vagy 80; gmód = video mode; gszín=video color) |
subr |
| (DEL csatorna) | csatorna | Az adott EXOS csatorna lezárása |
subr |
| (DIGIT x) | T vagy NIL | T ha x neve számmal kezdődik, egyébként NIL |
subr |
| (EDIT kif) | a kif szerkesztése |
subr |
|
| (ELLIPSE <x> <y>) | NIL | Ellipszist rajzol, az aktuális képernyő-pozícióval, mint középponttal |
subr |
| (EOF) | T vagy NIL | teszteli az aktuális input csatorna állapotát |
subr |
| (ERROR szám) | hibagenerálás |
subr |
|
| (FKEY kszám szöveg) | NIL | funkcióbillentyű definiálása |
subr |
| (FLATTEN struktúra) | lista | Eltávolítja a struktúrából a leágazásokat, így az eredménye egy lista |
subr |
| (FLUSH csatorna) | NIL | Kiüríti az adott számú csatornát |
subr |
| (GETCHAR) | egy karakter beolvasása |
subr |
|
| (GRAPHICS) | NIL | grafikus megjelenítés |
subr |
| (GRS csatorna) | szám | A grafikus csatorna beállítása az előző érték visszaküldésével |
subr |
| (IN ioport) | szám | portról olvas |
subr |
| (INK szín) | NIL | Tintaszín a kiválasztott palettáról) |
subr |
| (JOY szám) | szám | A botkormány leolvasása |
subr |
| (LITER x) | T vagy NIL | T ha x neve betűvel kezdődik, NIL ha nem |
subr |
| (MAX2 szám1 szám2) | szám | visszaadja a nagyobb számot |
subr |
| (MEMBER x y) | NIL vagy lista |
A visszaadott érték NIL, ha x nem eleme y-nak, egyébként a kapott lista az x elemmel kezdődik |
subr |
| (MESSOFF / MESSON szám) | szám |
A rendszer által adott üzenetek vezérlése. 1 - szemétgyűjtés eredménye ennyi byte-ot szabadított fel (OFF); 2 - szemétgyűjtések száma (OFF); 4 - hibaszám (ON); 8 - hibakövetés (ON); 64 - a QUOTE függvény vezérlése (ON) |
subr |
| (OBLIST) | lista | a rendszernevek listában |
subr |
| (OPEN szám file-név) | szám | file megnyotása |
subr |
| (OUT érték ioport) | érték | portra ír |
subr |
| (PAINT) | NIL | Kifestés |
subr |
| (PALETTE c0 c1 ... c7) | NIL | A palettaszínek beállítása |
subr |
| (PAPER szín) | NIL | A papír színének beállítása |
subr |
| (PEEK cím) | érték | A (memória)cím tartalmát adja |
subr |
| (PLIST azonosító) | lista | Az azonosító tulajdonságait tartalmazó listát adja vissza |
subr |
| (PLOT x y) | NIL | Abszolút grafikus koordináta megadás |
subr |
| (PLOTMODE szám) | NIL | Rajzolás vezérlése: 0 - egyszerű rajzolás; 1- OR; 2 - AND; 3 - XOR |
subr |
| (PLOTR x y) | NIL | Relatív grafikus koordináta megadás |
subr |
| (PLOTSTYLE szám) | NIL | A rajzolt vonal stílusa állítható be |
subr |
| (POKE cím, érték) | érték | A (memória)címre az értéket írja |
subr |
| (RANDOM szám) | szám | Véletlenszámok előállítása |
subr |
| (RANDOMIZE sorszám) | sorszám | A véletlenszám-generálás vezérlése az adott sorszámtól kezdődik |
subr |
| (RDS csatorna) | csatorna | Módosítja az adott sorszámú csatornát és visszaadja a megelőző csatornaszámot |
subr |
| (RECLAIM) | szám | Tárolóhely visszavételt kezdeményez, a kapott számértéket öttel megszorozva a szabad memória mértékét kapjuk |
subr |
| (REDIRECT régi új) | NIL | A kimeneti műveletek átirányítása a csatornák között |
subr |
| (SETATTRIBUTES szám) | NIL | Grafikus attribútum beállítása) |
subr |
| (SETCOLOUR szám palettaszín) | NIL | A palettaszín megadása |
subr |
| (SET-TIME idő-string) | NIL | Az idő beállítása |
subr |
| (SETVIDEO felbontás színek videox videoy | NIL | Videómód definiálása |
subr |
| (SNDS csatorna) | csatorna | Adott csatorna átírása |
subr |
| (SPRINT kifejezés) | NIL | Formázott kiírás |
subr |
| (TEXT) | NIL | szöveges megjelenítés |
subr |
| (TIME) | szöveg | az időt adja vissza |
subr |
| (WRS csatorna) | csatorna | A kimeneti csatorna átirányítása |
subr |
Kapcsolat az EXOS-al
A LISP alapjában (így az IS-LISP is) magasszintű pofiramozási nyelv. Ez a tulajdonság azt jelenti, hogy más típusú gépeken futó LISP értelmezők forrásprogramjait is képes (kis számú módosítás után) végrehajtani. Így azonban az ENTERPRISE egyedi tulajdonságai (grafika, hang stb.) háttérbe szorulnak, hiszen más operációs rendszer nem biztos, hogy ugyanúgy kezel mindent, mint az EXOS. Az IS-LISP a EXOS-al való kapcsolat révén jobban kihasználhatóvá teszi a gépközeli (gépfüggő) dolgok felhasználását a programozási munkában. Az EXOS változók elérését az alábbi eljárások (subr típusú függvények) végzik:
(EXOS-READ <változó>), amely az adott EXOS-változó értékét adja vissza;
(EXOS-WRITE <változó> <érték>), amely az adott EXOS-változó átírása után, az új (megváltoztatott) értéket adja vissza;
(EXOSTOGGLE <változó>), amely az adott (lényegében két állapotot meghatározó) változó tartalmát billenti át.
C. Hogyan ellenőrizzük a zárójelezés helyességét?
A LISP-programozás egyik leggyakoribb problémája annak eldöntése, hogy egy kifejezés helyesen van-e zárójelezve. Ezt vizsgálnunk kell egy kifejezés leírásakor, vagy hibakereséskor, ha a program nem úgy működik, ahogy elképzeltük. Ezt a munkát az is megkönnyíti, ha a listákat áttekinthetően írjuk le, betartjuk az erre vonatkozó - pl. az 1.2.2. pontban leírt - konvenciókat; hosszabb, összetett listák vizsgálatára azonban hasznos lehet a következőkben ismertetendő módszerek alkalmazása.
Összetartozó zárójelek megkeresése
Ha az ellenőrizni kívánt listák nem túl hosszúak, akkor egyszerűen úgy ellenőrizhetjük a zárójelezés helyességét, hogy az egymáshoz tartozó kezdő és bezáró zárójeleket azonos módon - pl. azonos sorszámmal, vagy azonos színű tollal - jelöljük meg. Az egyes kezdő zárójeleknek megfelelő bezáró zárójeleket a következőképpen kereshetjük meg:
Idézzük fel az 1.2. szakasz néhány példáját: az
((ALMA (BARACK CSERESZNYE)) (((DINNYE) EPER)))
karaktersorozatban az elsőként megtalált zárójelpárt jelöljük meg, az összetartozó zárójelekhez azonos sorszámot írunk:
((ALMA (BARACK CSERESZNYE)) (((DINNYE) EPER)))
1 1
A következő zárójelpár:
((ALMA (BARACK CSERESZNYE)) (((DINNYE) EPER)))
2 1 12
Az eljárást folytatva végül a következőket kapjuk:
((ALMA (BARACK CSERESZNYE)) (((DINNYE) EPER)))
62 1 12 543 3 456
Ez a karaktersorozat tehát lista. Következő példánk azonban - az 1.2.2. pontból - ezt az eredményt adja az első lépés után:
(KUTYA (MACSKA (PAPAGÁJ))
2 1 12
Az eljárás nem folytatható, az első kezdő zárójelhez nem tartozik bezáró zárójel. Ez tehát nem lista. A következő példában:
((MICI) (MACKÓ)))
31 1 2 23
eljutottunk egy olyan pontig, ahol megtaláltuk az összetartozó zárójelpárokat, tehát megtaláltuk egy lista végét. A lista vége után egy olyan bezáró zárójel maradt, amelyhez nem tartozik kezdő zárójel.
A következő példa
)BOLDOG (SZÜLETÉSNAPOT) FÜLES)
nem lista, mivel végül két bezáró zárójel marad, amelyekhez nem tartozik kezdő zárójel. A
(PULI KUVASZ) (KOMONDOR)
példában pedig a KUVASZ utáni bezáró zárójelnél egy olyan ponthoz érünk el, ameddig minden zárójel meg van jelölve, a karaktersorozat további része viszont még tartalmaz zárójeleket. Itt tehát ismét egy lista végét értük el: (PULI KUVASZ) egy lista: a karaktersorozat fennmaradó részét külön kell vizsgálnunk: (KOMONDOR) egy újabb lista.
Ha a vizsgált karaktersorozat nagyzárójeleket is tartalmaz, így találjuk meg az összetartozó zárójeleket:
A bezáró nagyzárójelet tehát, ha több kezdő zárójelet zár be, több színnel vagy több számmal kell megjelölnünk.
Ezt a módszert azonban csak azoknál a listáknál használhatjuk jól, amelyeket többé-kevésbé még szemmel is át tudunk tekinteni. Nagyobb listáknál, amelyekben egy-egy összetartozó zárójelpár két zárójelét esetleg sok sor választja el egymástól, jobban alkalmazható a következő módszer.
A zárójelek számlálása
A módszer alkalmazásakor a karaktersorozatot ismét balról jobbra haladva vizsgáljuk, azonban minden zárójelet rögtön megszámozunk akkor, amikor elértük, és nem térünk vissza - mint az előző módszernél - a karaktersorozat elejére. A zárójeleket egy számláló segítségével jelöljük meg, amelynek értéke kezdetben 0. Balról jobbra haladva
A karaktersorozat akkor lista, ha a következők teljesülnek:
Nézzük példáinkat most ezzel a módszerrel! A számláló értékét az egyes zárójelek alá írjuk:
((ALMA (BARACK CSERESZNYE)) (((DINNYE) EPER)))
012 3 21 234 3 210
A számláló értéke az utolsó karakternél 0 és közben csak pozitív értékeket vesz fel, ez tehát lista.
A következő példa:
(KUTYA (MACSKA (PAPAGÁJ))
01 2 3 21
A számláló értéke nem csökken 0-ra az utolsó karakternél. Ez tehát nem lista. A következő példában
((MICI) (MACKÓ)))
012 1 2 10(-1)
a számláló 0-vá válik, majd az utolsó karakternél (-1)-re csökken, jelezve, hogy egy helyesen felírt listát egy fölösleges bezáró zárójel követ. Nem lista a következő:
)BOLDOG (SZÜLETÉSNAPOT) FÜLES)
0(-1) 0 (-1) (-2)
A számláló az utolsó karakternél (-2)-re csökken; közben felvesz más negatív értékeket és a 0 értéket is.
(PULI KUVASZ) (KOMONDOR)
01 0 1 0
A számláló az utolsó karakternél 0, de közben is felveszi a 0 értéket, jelezve, hogy ez nem egyetlen, hanem két lista.
A nagyzárójel
Nagyzárójelet is tartalmazó karaktersorozatokra az eljárást így alkalmazhatjuk: egy kezdő nagyzárójel - ugyanúgy, mint a közönséges kezdő zárójel -, 1-gyel növeli a számlálót. A bezáró nagyzárójel pedig a számláló értékét az előző kezdő nagyzárójelet közvetlenül megelőző értékre csökkenti - ha van ilyen - ha pedig nincsen előző kezdő nagyzárójel, akkor 0-ra.