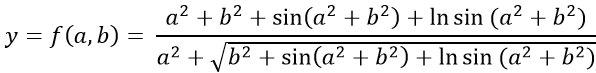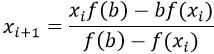FORTRAN-80
Tartalom
1. A programozás automatizálása és a FORTRAN programozási nyelv
1.1. Bevezetés
Az elektronikus számítógépek megjelenésével és elterjedésével nagyobb lehetőség nyílt arra, hogy a tudomány, a technika, és a gazdasági élet számtalan feladata közül minél többet oldhassunk meg gépi úton. A numerikus analízis és a rokon tudományágak folyamatosan adtak olyan újabb számítási eljárásokat, amelyek segítségével a feladatmegoldás célszerűbben gépesíthető. Ugyanakkor egyre több szellemi energiát kötött le a feladatok "gépre vitele", a programozás és kódolás.
Bizonyos fejlődési szintet képviselnek az ún. algoritmikus programozási nyelvek. Két fontosabb ok vezetett kialakulásukhoz : egyrészt az a felismerés, hogy a programozási munkában igen sok művelet automatizálható, azaz elvégeztethető magával a géppel, másrészt az az igény, hogy a matematikai formulákat közvetlenül - vagy legalábbis lehető csekély módosítással - be lehessen írni a programokba. Azokat az algoritmikus nyelveket, amelyek csak egy meghatározott számológép-típuson használhatók fel, autokódoknak nevezték. Ilyen például a NATIONAL ELLIOT-803 gép ELLIOT autokódja, a MINSZK-22 gép MITRA nevű autokódja stb. Ezeken a nyelveken lényegesen könnyebb a programozás, mint a gép nyelvén, az ún. gépi kódban.
Szükség volt továbbá olyan algoritmikus nyelv kifejlesztésére, amelyen írt program a különféle számológépeken egyaránt felhasználható, azaz ebből a szempontból univerzális. Ez az igény vezetett a magasabb szintű nyelvek, a FORTRAN és az ALGOL kialakulásához.
Felismerték azt is, hogy sok területen a feladatok tipikusak, azaz igen sok köztük a hasonlóság. Ezért célszerűnek látszott bizonyos közös vonásokat már a programozási nyelvekben figyelembe venni. Így alakították ki az ún. probléma orientált nyelveket, mint például az adatfeldolgozási feladatokra kidolgozott COBOL nyelvet, a sorbanállási problémák vagy rendszerszimulációs feladatok programozására alkalmas SIMSCRIPT vagy GPSS nyelveket és egy sor további programozási célnyelvet. Ily módon a fejlődés az idők folyamán rendkívül sok "nyelvjárás" kialakulásához vezetett, amelyeknek még a felületes áttekintése is elég nehéz.
A következő fejlődési lépésben olyan programozási nyelveket dolgoztak ki, melyek - legalábbis elvben - több nyelv előnyei egyesítenék, illetve amelyek magukban foglalnának több programozási nyelvvel egyenértékű ún. "nyelv-modulokat". Ez a törekvés érezhető a PL1 nyelven és részben az ALGOL 68 nyelvtervezeten is. (Egyes szerzők e két nyelvet tekintik az első univerzális nyelvnek.)
Az egyes programozási nyelvek közül egy konkrét számológép programozására csak azokat lehet használni, amelyhez a számológépnek van ún. fordítóprogramja. A fordító program segítségével ui. a gép az algoritmikus nyelven megír programot "lefordítja" a gép nyelvére, vagyis megszerkeszt a futtatásra, azaz a kívánt feladat gépi megoldására alkalma gépi kódú programot. Emellett a fordítóprogram hatáskörébe utalhatók bizonyos hibajelzési feladatok is. A továbbiakba a futtatásra alkalmas programot célprogramnak, vagy tárgyprogramnak, a megfelelő programozási nyelven írt programot pedig forrásprogramnak nevezzük.
A programozó számára nem okvetlenül szükséges, hogy ismerje a számológép gépi nyelvét, az ún. belső kódot, vagy éppen a fordítóprogram működését. Elég, ha ismeri a programozási nyelv - a továbbiakban forrásnyelv - szabályait. Ezzel a megoldandó feladatot be tudja programozni. A programozó számára a számológép a megfelelő fordítóprogrammal együtt egységes egészet képez.
Mindez igaz a programozási nyelvekre általában, így FORTRAN nyelvre is.
1.2. A FORTRAN nyelvek kialakulása
Könyvünkben az egyik legkorábban kifejlesztett univerzális algoritmikus nyelvcsaláddal, a FORTRAN nyelvekkel foglalkozunk. A FORTRAN nyelveket úgy tekinthetjük, mint az IBM Vállalatnak (International Bussiness Machines Corp.) és leányvállalatainak gépeire írt autokódok továbbfejlesztett változatait. 1953-ban az IBM John W. Backus nevű munkatársa javasolta feletteseinek, hogy dolgozzanak ki egy, az assembly-nél és autokódoknál hatékonyabban használható, magasabb nyelvű kódot a cég akkori IBM 704 nagygépeinek programozására. Backus megkapta az engedélyt, és így egy mintegy tíz főből álló csapattal neki is látott a nyelv kidolgozásának. A nyelv első változata 1956-ra készült el és a FORTRAN nevet kapta. A név a FORmula TRANslator szavak rövidítése. Az elnevezésből is látható, hogy elsősorban számítási feladatok elvégzésére fejlesztették ki, de ez nem mindenkit akadályozott meg abban, hogy pl. sakkprogramot készítsen FORTRAN-ban.
Miután más nagyszámítógép gyártók, az 1961-es UNIVAC-tól kezdve, saját FORTRAN fordítóikat fejlesztettek, a FORTRAN többplatformos számítógépes nyelv lett. 1962 májusában lehetővé vált, hogy az Amerikai Szabvánügyi Hivatal (American Standards Association, rövidítve: ASA) munkacsoportot hívjon létre, amelynek feladatául tűzte ki, hogy a FORTRAN nyelveket szabványos programozási nyelvként definiálja. A szabványtervezet 1964 októberére készült el, majd a szabvány elfogadása után FORTRAN 66 lett a neve, ezt tekintik a FORTRAN nyelv első hivatalos definíciójának. A szabvány a FORTRAN-II és FORTRAN-IV nyelveknek megfelelően két változatot definiál oly módon, hogy a több programozási lehetőséget nyújtó nyelv (a továbbiakban ASA FORTRAN) "részhalmazaként" értelmezi a szűkebb, ún. BASIC FORTRAN nyelvet. Ez azt jelenti, hogy minden BASIC FORTRAN nyelven megírt program egyben ASA FORTRANBAN írt program is, és jelentése ugyanaz, akár ASA FORTRAN-ban, akár BASIC FORTRAN-ban értelmezzük. Az ASA FORTRAN fordítóprogramjai tehát tökéletesen lefordítják a BASIC FORTRAN nyelven írt programokat is. Az ASA FORTRAN bizonyos utasításai viszont a BASIC FORTRAN-ban hiányoznak.
A szabvány bővítését az ANSI kezdeményezte 1969-ben. A FORTRAN-77 szabványt hivatalosan 1978-ban hagyták jóvá, amely jelentős funkciókkal bővítette a FORTRAN 66 számos hiányosságát.
A Microsoft 1977 júliusától árusította a FORTRAN-80 implementációját 8 bites mikroszámítógépekre. Ez akkor tetemesnek számító 350,00 dollárba került, és elképesztő hardware-követelményei voltak: minimum 32K memóriát és egy floppy meghajtót igényelt. A programcsomag tartalmazta az akkoriban igen népszerű MACRO-80 és Z80 Macro Assembler komponenseket is. Ezekről azért kell beszélnünk, mert az egyes számítógépekhez a gép adottságaitól függően olyan FORTRAN fordítóprogramokat írtak, amelyek néhány programozási kérdésben több, néha - ritkábban - kevesebb szabadságot, biztosítanak a programozó számára, mint a szabványos FORTRAN nyelv. A Microsoft a mikrogépekre készült legteljesebb FORTRAN implementációját ígérte.
A FORTRAN nyelveken érezhető egy speciális gyakorlati körülmény hatása is. Az IBM cég előszeretettel használt lyukkártyát adatok és programok bevitelére. Ennek következtében a FORTRAN nyelvnek is sajátossága az "egy sor - egy utasítás" megfeleltetés. Pontosabban: az egyes utasításokat a FORTRAN-ban mindig csak új sorban, a 7. karakterpozíciótól kezdve lehet elkezdeni. A kimeneti, beviteli utasítások illetve azok formázása is nehézkesnek tűnik, hiszen azokat nagy mennyiségű numerikus adatok feldolgozására szánták. Az ilyenfajta formai követelmények speciális programozói előnyökkel és hátrányokkal járnak.
1.3. Alapfogalmak
Egy FORTRAN nyelven írt programnak - ahhoz, hogy értelmes legyen - ki kell elégítenie bizonyos formai ("nyelvtani") követelményeket. Azt mondjuk, hogy szintaktikusan (vagy formálisan) helyes az olyan program, amely ezen "nyelvtani" szabályoknak eleget tesz. A fordítóprogramoktól megköveteljük, hogy szintaktikusan helyes forrásprogramok alapján végrehajtható célprogramokat készítsenek, a szintaktikusan hibás forrásprogramokról pedig közöljék ezek hibás voltát, és adjanak bizonyos felvilágosítást a hibák jellegéről.
A FORTRAN nyelven írt program utasítások sorozatából áll. Az egyes FORTRAN utasítások felírásának legáltalánosabb formai szabályai a következők:
Annak érdekében, hogy ezeknek a formai szabályoknak a betartása ne okozzon gondot a programozónak, régebben a programokat programlapokra írták. A programlapok alapján készülhettek el az egyes programkártyák (minden sorhoz egy-egy kártya tartozik). A kártyákon az egy oszlopban levő lyukak kombinációja egy karakternek felelt meg, melyet a könnyebb kezelhetőség kedvéért a kártya felső szélére általában rá is gépeltek. Könnyen lehetett az egyes kártyákat cserélni vagy további kártyákat közéjük beiktatni stb., így a program könnyen javítható, fejleszthető, módosítható maradt.
Ahhoz, hogy programunk helyesen működjék, nem elég, ha szintaktikusan helyes. Magától értetődően szükséges az is, hogy éppen azokat a műveleteket hajtsa végre, amelyeket a programozó kívánt. Az ilyen értelemben is helyes programokat szemantikusán helyesnek nevezzük. Világos, hogy egy program lehet szintaktikusan hibátlan, de szemantikailag hibás.
Az egyes utasításokat csakis az ún. FORTRAN jelkészlet karaktereiből építhetjük fel. Ezek:
Jel A jel neve
=
+
-
*
/
(
)
,
.betűköz
egyenlőségjel
plusz
mínusz
szorzásjel
törtvonal
kezdő zárójel
végzárójel
vessző
pont
A FORTRAN-80 nem tesz különbséget a kis- és nagybetűk között, a programban tetszőlegesen használható kisbetű és nagybetű is, akár keverve is. A régebbi FORTRAN fordítók azonban csak a nagybetűs írásmódot ismerik, az egyértelműség érdekében ezért a nagybetűk használata javasolt.
A dollárjelet, vagy árfolyamjelet nem minden gépi reprezentáció használja, ezért sokszor nem tekintik a FORTRAN jelkészlethez tartónak, a Microsoft pedig betűnek tekinti.
A FORTRAN-utasításokat két nagy csoportba oszthatjuk: végrehajtó és nem végrehajtó utasításokra. A végrehajtható utasítások műveleteket határoznak meg, és a FORTRAN-fordító objektumprogram-utasításokat generál belőlük. Háromféle végrehajtható utasítás létezik:
A FORTRAN utasítások nagy részét arra használják, hogy velük bizonyos matematikai mennyiségeknek, a változóknak, értéket adjunk. Ezek az ún. értékadó utasítások. Például a
19 X=X-Y+12.5
értékadó utasítás az X változó korábbi értéke alapján kiszámíttat egy új X értéket, amely az egyenlőségjel jobb oldalán lévő kifejezés számértékével, az ún. aktuális értékével egyezik meg.
A gép X előző értéke helyébe az utasítással meghatározott új értéket írja be. Például ha az utasítás végrehajtása előtt X pillanatnyi értéke 3.5, Y pillanatnyi értéke pedig 2.5 volt, akkor az utasítás végrehajtása után X értéke 13.5 lesz (Y értéke továbbra is 2.5 marad). Ugyanaz a változó egy programban többször is kaphat új értéket, akár értékadó utasítások, akár a perifériális egységek segítségével végzett beolvasás hatására.
Az utasítás előtt álló "19" szám az utasítás címkéje. A címkék teszik lehetővé, hogy a program egyes utasításai egymásra hivatkozhassanak. Vannak olyan utasítások, ún. vezérlésátadó utasítások, amelyek hatására a gép a soron következő utasítás helyett a megadott címkéjű utasítást hajtja végre. A vezérlésátadás függhet bizonyos feltételek teljesülésétől is. Eszerint beszélünk feltételes, illetőleg feltétlen vezérlés átadó utasításról. A címke nélküli
GOTO 19
illetve a címkével ellátott
12 GOTO 19
feltétlen vezérlésátadó utasítások hatására a vezérlés a "19" címkéjű utasításra adódik át. Látjuk, hogy a vezérlésátadó utasításnak is lehet címkéje.
A nem végrehajtható utasítások leírják a processzornak az adatok típusát és elrendezését, valamint információt adnak a bemeneti/kimeneti formátumokról és az adatok inicializálásáról az objektumprogram számára a program betöltése és végrehajtása során. Ötféle nem végrehajtható utasítás létezik:
A fordítást vezérli az INCLUDE direktíva, melynek hatására a fordító egy külső FORTRAN forrásprogramot illeszt be az aktuális programba, az INCLUDE utasítás helyére. Alakja:
INCLUDE<file-név>
Az INCLUDE használatával szükségtelenné válik, hogy a gyakran használt, kipróbált rutinjaikat minden alkalommal az aktuális programba másoljuk.
Nagyon fontos fogalom az azonosító fogalma. Ezen körülbelül ugyanazt értjük, mint a "név" köznapi fogalmán. Azonosítója van többek között minden változónak. Például az első példában látható utasításban az X betű egy változót azonosít vagy jelöl; azaz megkülönbözteti a többi változótól. Azonosítója van másféle programozási objektumoknak (ún. szintaktikus egységeknek) is: vektoroknak, mátrixoknak, szegmenseknek (lásd a 4. fejezetet), sőt teljes programoknak is. A FORTRAN fordítóprogramnak sok esetben szüksége van arra, hogy a fordítás folyamán a programban előforduló azonosítókról bizonyos felvilágosításokat, információkat kapjon. Ilyen információ például, hogy az azonosító vektort jelöl; hogy a vektornak 5 komponense van stb. Ezeket az információkat ún. deklaratív, vagy nem végrehajtható utasítások segítségével adhatjuk meg. A FORTRAN nyelv sajátsága, hogy ha egyes azonosítókat nem deklarálunk, akkor a fordítóprogram megfelelő szabályok alapján saját maga definiálja azok tulajdonságait. Ez megkönnyíti a program írását, bár olykor hibához is vezet.
A deklaratív utasításokat a 4. fejezetben tárgyaljuk.
Nagyon fontos szabálya a FORTRAN nyelven írt forrásprogramnak, hogy az utasításokban tetszőleges számban és helyen lehet jelentés nélküli betűköz karaktereket elhelyezni. Ez a szabály még a több karakterből álló azonosítókra is érvényes: betűközök helyezhetők az azonosítók betűi közé is, anélkül, hogy az azonosítók jelentése megváltozna. Például a következő utasítások jelentése teljesen megegyezik:
12 ALLAT = KUTYA+MACSKA1
1 2 AL LAT = KU TYA+MACS KA1
vagy
12 GOTO 19
12 GO TO 19
2. Aritmetikai és logikai kifejezések, Relációk
2.1. Értéktípusok
A FORTRAN nyelv igen sok utasítása használ fel aritmetikai és logikai kifejezéseket, valamint relációkat. Célszerű tehát e fogalmakkal az utasítások tárgyalása előtt részletesen megismerkednünk.
Tegyük fel, hogy sikerült valamilyen mennyiséget ismert mennyiségekkel kifejeznünk. Például az ax^2 + bx + c = 0 másodfokú egyenlet gyökeit kifejezhetjük az
képlettel. Ha az egyenlőségjel jobb oldalán álló kifejezést - a FORTRAN nyelv később ismertetendő szabályainak megfelelően - leírjuk, például a következő módon:
(-B+(B**2-4.0*A*C)**0.5)/(2.0*A)
akkor aritmetikai kifejezéshez jutottunk. Ha ismeretes A, B és C értéke, akkor az aritmetikai kifejezést "ki lehet értékelni", vagyis van aktuális értéke. Ha viszont A, B és C ismeretlenek, vagy a program még nem adott nekik értéket, akkor nincs értelme a kifejezés aktuális értékéről beszélni. A továbbiakban mindig feltesszük, hogy kifejezéseink olyan programba vannak beágyazva, mely az előforduló változóknak már előzőleg adott értéket.
Mivel egy aktuális érték a számológépben többféleképpen "ábrázolható", a FORTRAN nyelv is az értékek többféle típusát vezeti be. Aritmetikai kifejezések aktuális értéke négyféle típusú lehet. Ezek közül az INTEGER vagy "egész" típusú értékeket a számológép pontosan ábrázolja. Ezek az értékek a pozitív és negatív egész számok és a nulla, a számológépben ábrázolható értéktartományban. A REAL vagy "valós" típusú értékek csak bizonyos relatív pontossággal ábrázolhatók, mégpedig a gép típusától függően. Mikroszámítógépeken a FORTRAN-80 -ban 7 tizedes számjegy pontossággal. A DOUBLE PRECISION vagy "kétszeres pontosságú" értékek csak a számábrázolás nagyobb relatív pontosságában térnek el a "valós" értékektől; a hivatkozási nyelv csak ennyi ír elő. Az ICT gépi reprezentációban ez azt jelenti, hogy pontosság 21 tizedes jegy, szemben a REAL értékek 12 jegy pontosságával. FORTRAN-80-ban 16 számjegy pontosságú. A COMPLEX vagy "komplex" típusú értéket a gépben egy "valós" típusú számpár képviseli, ez a típus a FORTRAN-80-ban nincs megvalósítva.
Ha például két REAL típusú értéket összehasonlítunk (relációba hozunk), akkor van értelme egy olyan állításnak, hogy az első érték nagyobb a másodiknál, pl.: A nagyobb, mint B. Ez a megállapításunk A és B adott értékei mellett lehet igaz vagy hamis. Ilyenformán relációnk - A és B aktuális értékétől függően - felveszi az igaz, vagy a hamis értéket. Ez nem számérték, hanem új értéktípus, ún. LOGICAL vagy "logikai" érték. Nyilvánvaló, hogy logikai érték csak kétféle lehet: igaz (TRUE), vagy hamis (FALSE).
Felírhatok olyan ún. logikai kifejezések, amelyek "kiértékeléséhez" logikai értékekkel kell speciális, ún. logikai műveleteket végezni. Sok hasonlóság van az aritmetikai és logikai kifejezések felírása és kiértékelése között, például a zárójel használata tekintetében is.
Most sorra vesszük azokat az alapvető szintaktikus egységeket, amelyeket kifejezések felírásában használunk.
2.2. Számok
A négyféle típusú számértéknek - INTEGER, REAL, DOUBLE PRECISION és COMPLEX - megfelelően, a FORTRAN-ban négyféle típusú számról, vagy számkonstansról beszélhetünk (a FORTRAN-80-ban a COMPLEX típus nincs megvalósítva).
Egész típusú (INTEGER) számot egy vagy több számjeggyel írhatunk fel; a legelső számjegyet egy előjel is megelőzheti. A pozitív előjel elhagyható. A számok első jegyei értéktelen nullák is lehetnek. Helyesen vannak felírva például a következő egész számok:
1
+1
0023
-75
1969
-32768
Mivel a programsorokban tetszőleges pozícióban elhelyezhetünk betűköz (space) karaktereket, amelyek nem érintik a program jelentését, a számok belsejében levő üres karaktereknek sincs semmiféle jelentőségük. Így az
1
+ 1
0 02 3
-7 5
1 969
-32 768
számok megegyeznek a fentiekkel.
Ez a megjegyzés mindegyik számtípusra érvényes.
A gépi reprezentációkban a különféle típusú számok abszolút értéke nem haladhatja meg a megfelelő gép számábrázolási rendszeréből eredő korlátokat.
Az INTEGER típusú számok -32768 és +32767 eső egész szám, 2 byte-on ábrázolhatóak. A . (pont) karakter nem megengedett, a pozitív előjel elhagyható. Maximum öt számjegyből állhat (vezető nullákkal, pl.: +00672).
FORTRAN-80-ban az egész számok hexadecimális alakban is felírhatóak Z vagy X karakterek után, aposztróf (') jelek között. A hexadecimális szám 1-4 karakterből állhat, a 0-9 és A-F karakterekből. Példák:
Z'12'
X'AB11F'
Z'FFFF'
X'1F'
A valós típusú (REAL) számok öt részből állhatnak: előjelből, egész részből, tizedespontból, törtrészből és kitevőrészből, 7 számjegy pontossággal. Tárolásához 4 byte szükséges. Például a -25.7117x10^9 számértéket a következőképpen részekből áll:
Ennél a felírási példánál mind az öt részt felhasználtuk. Ezek egyike-másika bizonyos megszorításokkal elhagyható, vonatkozó szabályok a következők:
Példák helyesen felírt valós számokra:
-11 500.
+40.007 072
.5147
-115.E2
4.0007E+1
.05E-12
+6E13
-08.80E-03
7.2E-00
Példák hibásan felírt valós számokra:
+0,5
E-3
+.E+3
A számítógépek nagyrészt bináris számrendszerben dolgoznak, ezért a felírt REAL típusú számokat általában nem lehet pontos értékükkel ábrázolni a gépen. Ennek következtében bevitelkor kerekítésre kerül sor.
A kétszeres pontosságú (DOUBLE PRECISION) számokat a valós típusúakhoz hasonló módon írjuk fel 16 számjegy pontossággal, csupán a kitevő-rész E betűje helyett D betűt használunk. Tárolásához 8 byte szükséges. A REAL típustól eltérően azonban itt mindig szerepelnie kell a kitevőrésznek és ezzel együtt a D betűnek.
Példák helyesen felírt dupla pontosságú számokra:
-115.D2
4.0007D+1
.05D-12
+6D13
-73D4
3.14159235358979D00
Példák hibásan felírt dupla pontosságú számokra:
-0,47D+5
D-06
+.D+2
3.14159235358979
Magától értetődően a 4.0007E+1 valós, és a 4.0007D+1 kétszeres pontosságú szám belső gépi ábrázolásban egymástó eltér, ezért számértékeik is különböznek. A tízes számrendszerben a megadott két szám pontosan egyenlő. A gép viszont kettes számrendszerben dolgozik, amiben ezeket a számokat csak végtelen szakaszos "bináris törttel" (vö. végtelen szakaszos tizedestört!) lehet megadni. De a gép csak véges számjegyet jegyez fel; valós "számábrázolás" esetén kevesebb jegyet vesz figyelembe, mint kétszeres pontosságú esetén. Így ez a két "közelítő érték" vagy "számábrázolás" egymással általában érték szempontjából sem egyenlő.
Az ASA FORTRAN hivatkozási nyelv nem határozza meg sem a számok abszolút értékének maximumát, sem pontosságát. Ezek a gépi reprezentációktól függenek. Előírja azonban, hogy a kétszeres pontosságú ábrázolás relatív pontosságának meg kell haladnia a valós számok ábrázolásának relatív pontosságát.
A LOGICAL (logikai) típus két állapot ábrázolására szolgál: .TRUE. (igaz) állapot nem nulla értéket jelent, a .FALSE. (hamis) érték pedig nulla értéket jelent. Ennek ábrázolására egyetlen bit is elég lenne (0, 1), azonban a legtöbb fordítóhoz hasonlóan a FORTRAN-80 is egy byte-ot használ a logikai típus ábrázolására. Ezért az alkalmas -128 és +127 közötti egész szám tárolására is.
Az INTEGER*4 típusú egész számok 10 számjegy pontosságúak, 4 byte szükséges a tárolásához. A pozitív előjel elhagyható. Tizedespont vagy vessző nem megengedett, de szóköz megengedett a forrásprogramban. Értéktartománya: -2147483648 - 2147483647
Példák:
-2147483647
- 2 147 483 647
2.3. Változók, azonosítók
Ahhoz, hogy aritmetikai kifejezéseket felírhassunk, jelölnünk kell a bennük szereplő változókat. A (-B+(B**2-4.0*A*C)**0.5)/(2.0*A) formulában ezt egy-egy nagybetűvel tettük. Tekintve, hogy mindössze 26 nagybetűt használhatunk, a jelölésre egy karakter nyilván általában nem elegendő. A FORTRAN nyelv megengedi, hogy erre a célra több karakterből álló karaktersorozatokat, - ún. azonosítókat - használhassunk. (Hasonló azonosítókkal lehet vektort, mátrixot, szegmenst vagy programot is jelölni.)
Az azonosítók maximális hossza hat karakter. Az első karakter csak betű lehet, a többi betű vagy számjegy (ide értve a $ jelet is). Tilos a más célra fenntartott karaktersorozatokat - az ún. alapszavakat - (GOTO, WRITE, ...) vagy ilyenekkel kezdődő karaktersorozatokat (GOTO12, IFJU, ..) azonosítóként használni. A betűköz karakter nem tartozik az azonosítóhoz, még ha belsejében is van. Például a következő azonosítók megegyeznek:
AZUREG
AZ UR EG
AZUR EG
Szabad azonosítót folytatósorban folytatni. Például:
AZUREG = ALUK*VOROS+AUU
1REG/12.0
Ebben a felírásban a második sor elején álló 1 számjegy nem tartozik ha AZUREG azonosítóhoz, hanem a folytatósort jelzi! A programozási gyakorlatban lehetőleg elkerülik az azonosítók elválasztását vagy tagolását.
A FORTRAN nyelv aritmetikai kifejezésekben egész, valós, kétszeres pontosságú és komplex típusú változókat használ, melyek a megfelelő típusú aktuális értékeket vehetik fel. A logikai (LOGICAL) változókat (általában) logikai kifejezésekben használhatjuk. Ezek a TRUE és FALSE logikai értékeket vehetik fel részletesen a Második fejezet 7. pontjában foglalkozunk.
Hacsak valamilyen deklaratív utasítással (lásd 4. fejezetet) eltérő előírást nem adunk meg, akkor a FORTRAN programokban a I, J, K, L, M és N betűkkel kezdődő azonosítókat egész típusú, a többi betűvel kezdődőeket valós mennyiségek, változók jelölésére használjuk. (Egész típusú mennyiség lehet például vektor is, melynek komponensei egész típusú számok.) Ezt a szabályt a későbbiekben az automatikus típusdeklarálás szabályának fogjuk nevezni.
Egy tömbnek 1, 2 vagy 3 dimenziója lehet. A tömbdeklarátor a tömb dimenzióját és méretét is jelzi. A vektorok és mátrixok egyes komponenseit indexes változókkal jelöljük. Ilyenkor pl. a vektor azonosítóját zárójelben követi a komponens sorszáma (az index). Így például a
VEKTOR(3)
indexes változó a VEKTOR azonosítójú vektor harmadik komponensét jelenti.
2.4. Aritmetikai műveletek
Az értékadó utasítások általános alakja:
v = e
ahol v tetszőleges változó vagy tömbelem, e pedig aritmetikai kifejezés.
Az egyes aritmetikai műveletek jelölésére a FORTRAN-ban a következő műveleti jeleket használjuk:
Az aritmetikai műveletek eredményének típusát az operandusok típusa határozza meg. Ha a v változó és az e kifejezés adattípusai eltérőek, akkor a kifejezés által meghatározott érték a változó típusának megfelelően automatikusan konvertálódik. (Ez nem jelenti azt, hogy az eredmény minden esetben helyes lesz!) A táblázatban szereplő Y az érvényes cserét, az Y lábjegyzetei pedig az átalakítási szempontokat jelzi.
Változó típusa: INTEGER REAL LOGICAL
DOUBLE INTEGER*4
Megjegyzések:
Látható, hogy a hatványozás jele (az egymás utáni két csillag) két szorzásjel egymás után. Tehát ha szorzást akarunk programozni és folytatósor elején megismételjük az előző sor végére tett szorzásjelet, a képlet szemantikailag hibás lesz, mert szorzás helyet hatványozást ír elő. Ügyeljünk arra, hogy programunkban két aritmetikai műveleti jel semmilyen módon ne kerüljön egymás mellé! Ez - a szorzásjel ismétlésének kivételével - szintaktikus hiba.
2.5. Aritmetikai kifejezések
A legegyszerűbb aritmetikai kifejezéseket számok, azonosítók (továbbiakban együttesen: operandusok) és aritmetikai műveleti jelek segítségével írhatjuk fel. (Az aritmetikai kifejezések fogalmát később a standard függvények, valamint a zárójelek bevezetésével bővítjük.) Az ilyen legegyszerűbb aritmetikai kifejezések aritmetikai műveleti jelek és operandusok váltakozó sorozatai. Operandus most tehát számkonstans vagy változó-azonosító lehet. Példák ilyen egyszerű aritmetikai kifejezésekre:
l/J + K/N
+273.16 + Q/F
-F**3.0 + 1.0-X**2/2.0*T
A gép e jelsorozatokat bizonyos értelmezési szabályoknak megfelelően értékeli ki. A közönséges matematikai képletírásnak megfelelően a műveleti jeleket ún. elsőbbségük (precedenciájuk) szerint csoportokba soroljuk:
A kifejezéseket a bennük előforduló műveleti jelek alapján célszerű külön névvel ellátni. Ezek a nevek és a megfelelő szintaktikus egységek a következők:
Ezek szerint az elsődleges aritmetikai kifejezés egyben tényező és tag is. Példák:
A tényező fenti definíciójának megfelelően a FORTRAN nyelvben tilos egy elsődleges kifejezést két hatványozási jel közé zárni, azaz aritmetikai kifejezésekben tilos az E**F**G típusú jelsorozatok leírása. (Ezt a szabályt zárójelek alkalmazásával lehet megkerülni, amit később látni fogunk.)
Megjegyezzük, hogy ezzel szemben az ALGOL nyelv megengedi a fenti szerkezetek felírását, hiszen balról jobbra szabálya meghatározza a két hatványozás elvégzésének sorrendjét. Ez az út a FORTRAN-ban nem járható!
A FORTRAN-ban az osztásjel (/) értelmezése a következő: az osztás jelét közvetlenül követő egyetlen tényező reciprok értékét kell képezni és az osztást ezzel való szorzással kell helyettesíteni. (Ez megfelel az osztás szokásos értelmezésének.) Például:
A*B*C/D értelme A*B*C*(1/D) azaz (abc)/d A*B/C*D értelme A*B*(1/C)*D azaz (abd)/c A*B/C/D értelme A*B*(1/C)*(1/D) azaz (ab)/(cd) A/B/C*D értelme A*(1/B)*(1/C)*D azaz (ad)/(bc)
A tagok kiértékelése során ez a szabály matematikailag ugyanarra az eredményre vezet, mint az ALGOL nyelvben kimondott balról jobbra szabály. Megjegyezzük azonban, hogy ez nem feltétlenül jelenti azt, hogy numerikusan is egyező eredményt kapunk, hiszen általánosan ismert tény, hogy matematikailag egyenlő mennyiségek különböző numerikus számítás során gyakran eltérőnek adódnak. Erre később példát is látunk majd.
A FORTRAN nyelvben a fenti legegyszerűbb aritmetika kifejezések kiértékelésének szabályai a következők:
Ez a szabály lehetővé teszi, hogy a fordítóprogram esetleg optimalizálja a felírt kifejezések kiértékelését, viszont megnehezíti több olyan programozási fogás alkalmazását, amely az ALGOL nyelvben a programozó rendelkezésére áll (ún. mellékhatások). Az egészek osztása is vet fel ide kapcsolódó problémákat, melyekre még visszatérünk.
Megjegyezzük, hogy a precedenciaszabályt lehet abszolút és reiatív értelemben felfogni. Ha pl. az aritmetikai kifejezésekben szereplő összes szorzást előbb végezzük el, mint a legelső összeadást, akkor abszolút precedenciáról, ha viszont egyetlen operandus két oldalán álló műveleti jelre vonatkozóan igazodunk csak a szabályhoz, akkor relatív precedenciáról beszélünk. A FORTRAN nyelv a szabályt csak relatív értelemben tartja kötelezőnek.
Ezek után beszélnünk kell az aritmetikai kifejezések típusáról. Minden kifejezés olyan típusú, amilyen aktuális értékének típusa. Az egyes aritmetikai műveletek eredményének típusait a 2.4. pontban foglaltuk össze. Ezekkel összhangban a kifejezések típusáról a következőket mondhatjuk:
Térjünk most vissza az egészek osztásának problémájára! Tekintsük a következő egész típusú kifejezést:
I*J/5*K
Legyen l = 2; J=3; K = 16. Milyen értéket vesz fel ez a kifejezés?
Értékeljük ki kifejezésünket a műveleteket külön féle - engedélyezett - sorrendben elvégezve, és ügyelve arra, hogy az egész osztás "abszolút értékben lefelé" kerekít! A műveletek elvégzésének sorrendjét jelöljük zárójelekkel a következő példák szerint:
((l*J)/5)*K = (6/5)*16 = 16
((l*J)*K)/5 = 96/5 = 19
(l/5)*(J*K) = (2/5)*48 = 0
((I*K)/5)*J = (32/5)*3 = 18
Láthatjuk, hogy a FORTRAN nyelv szabályai szerint helyesen felírt egész típusú vagy egész kifejezés értéke nincs egyértelműen definiálva! A legtöbb gépi reprezentáció - így a FORTRAN-80 is - ilyen esetben a balról jobbra szabály szerint értékelik ki a kifejezést, vagyis 16-ot ad eredményül.
Vegyük most a következő valós típusú kifejezést:
A*B/C/D
ahol legyen A = 3E37, B = 4E48, C = 5E52 és D = 6E47. Tegyük fel, hogy olyan számológép értékeli ki kifejezésünket, melyben a legnagyobb ábrázolható valós szám értéke kb. 10^77, és a gép olyan, hogy ha egy szorzás ennél nagyobb eredményt adna (ún. lebegőpontos túlcsordulás lépne fel), akkor az eredményt legnagyobb ábrázolható számmal helyettesíti. Mi ennek a hatása különféle műveleti sorrendek esetén?
(A*B)/(C*D) = 10^77/10^77 = 1.0
((A*B)/C)/D = (10^77/5E52)/6E47 = 2E24/6E47 = 0.333E - 23
((A/C)*B)/D = ((0.6E - 15)*4E48)/6E47 = 2.4E33/6E47 = 0.4E-14
stb...
Láthatjuk, hogy a gépi reprezentációban most sem közömbös az egyes műveletek sorrendje, hiszen a túlcsordulások a különféle sorrendek esetén erősen eltérhetnek egymástól. Példánkban az első sorrend két túlcsordulást eredményezett: 10^85 és 10^99 helyett számolt a gép 10^77-tel. A második sorrendben csak egy túlcsordulás lépett fel (10^85), a harmadikban egy sem.
Ha elő akarjuk írni aritmetikai kifejezésekben a műveletek elvégzésének sorrendjét, zárójeleket alkalmazunk ugyanúgy, ahogyan az a közönséges matematikai képletekben szokásos. Egyetlen zárójelezéshez egy bal oldali és egy jobb oldali zárójelet használunk fel. Minden megkezdett zárójelet be kell zárni! A zárójelpár belsejében aritmetikai kifejezés áll.
A zárójelpárt kívülről úgy kell tekinteni, mintha a benne szereplő aritmetikai kifejezéssel együtt egyetlen operandus lenne.
A FORTRAN-ban csakis kerek zárójelek, "(" és ")" használhatók.
Abból, hogy a zárójelbe zárt kifejezés egyetlen operandust jelöl, következik, hogy a teljes aritmetikái kifejezés kiértékelése a zárójelpárba zárt kifejezés kiértékelésével kezdődik. Többszörösen egymásba skatulyázott zárójelek esetén mindig a "legbelső" zárójel kiértékelése a legelső feladat, akárcsak közönséges matematikai képletek esetén.
Írjunk át most néhány matematikai formulát FORTRAN nyelvbeli aritmetikai kifejezéssé.
A csonkakúp térfogata FORTRAN aritmetikai kifejezésben:
PI*H*(R*R + R*R1 + R1*R1)/3.0
Tekintsük a következő kétismeretlenes lineáris egyenletrendszert:
ax + by = p
cx + dy = q
ennek a megoldóképlete
x = (pd-bq)/(ad-bc)
y = (aq-cp)/(ad-bc)
A jobb oldalak FORTRAN-beli aritmetikai kifejezés formájában, ha a nevező nem nulla:
(P*D - B*Q)/(A*D - B*C)
(A*Q - C*P)/(A*D - B*C)
Jelen pontban még egy fogalom bevezetésével kívánjuk bővíteni az aritmetikai kifejezések fogalmát. A FORTRAN nyelvben is megengedett, hogy függvényhivatkozást építsünk be az aritmetikai kifejezésbe, éppen úgy, ahogyan a függvényeket a matematikai képletekben használjuk. Például az
a^2 + b^2 - 2ab cos y
formulát a FORTRAN-ban a következőképpen írhatjuk le:
A**2 + B**2 - 2.0*A*B*COS(GAMMA)
Láthatjuk, hogy a függvényt valamilyen névvel, ún. függvényazonosítóval jelöltük, melyet zárójelek közé zárva követett a független változó.
A függvény argumentumát tartalmazó zárójelpár közé aritmetikai kifejezést is beírhatunk. Sőt, mint ahogy a következő példa mutatja, a függvények egymásba skatulyázhatók. Az
ln(x) arc tg(cos(x+y)*sin b)
formula FORTRAN megfelelője:
ALOG(X)*ATAN(COS(X+Y)*SIN(B))
A függvények használatának szabályai aritmetikai kifejezésekben a következők:
Most csupán azokkal a függvényazonosítókkal foglalkozunk, amelyeket a FORTRAN nyelv definiál. Ezek lehetnek ún. belső és külső standard függvények. A kétféle típus a programozó szempontjából csaknem azonos módon használandó, ezért a köztük levő különbségekkel nem foglalkozunk. Jelöléseiket, jelentésüket és egyéb adataikat alább adjuk meg:
| Elnevezés | Definíció |
Argumentum száma |
Függvény-azonosító |
Argumentum |
Függvény |
típusa |
|||||
| Abszolút érték | |a| | 1 |
ABS | Real | Real |
| IABS | Integer | Integer | |||
| DABS | Double | Double | |||
| Csonkítás v. abszolút lefelé kerekítés | |a|-nál kisebb legnagyobb egész , a előjelével | 1 |
AINT | Real | Real |
| INT | Real | Integer | |||
| IDINT | Double | Integer | |||
| Maradékképzés | a1 (mod a2) | 2 |
AMOD | Real | Real |
| MOD | Integer | Integer | |||
| Legnagyobb argumentum kiválasztása | Max (a1, a2, ...) | => 2 |
AMAX0 | Integer | Real |
| AMAX1 | Real | Real | |||
| MAX0 | Integer | Integer | |||
| MAX1 | Real | Integer | |||
| DMAX1 | Double | Double | |||
| Legkisebb argumentum kiválasztása | Min (a1, a2, ...) | => 2 |
AMIN0 | Integer | Real |
| AMIN1 | Real | Real | |||
| MIN0 | Integer | Integer | |||
| MIN1 | Real | Integer | |||
| DMIN1 | Double | Double | |||
| Konverzió egészből valósba | 1 |
FLOAT | Integer | Real | |
| Konverzió valósból egészbe | 1 |
IFIX | Real | Integer | |
| Konverzió duplapontos. egészbe | 1 |
SNGL | Double | Real | |
| Konverzió valósból duplapontos. | 1 |
DBLE | Real | Double | |
| Előjelezés | Sign (a2)*|a| | 2 |
SIGN | Real | Real |
| ISIGN | Integer | Integer | |||
| DSIGN | Double | Double | |||
| Pozitív differencia | a1 - min(a1, a2) | 2 |
DIM | Real | Real |
| IDIM | Integer | Integer | |||
| Exponenciális függv. | e**a | 1 |
EXP | Real | Real |
| DEXP | Double | Double | |||
| Természetes logaritmus | log(a) = ln(a) | 1 |
ALOG | Real | Real |
| DLOG | Double | Double | |||
| Tízes alapú logaritmus | log10(a) | 1 |
ALOG10 | Real | Real |
| DLOG10 | Double | Double | |||
| Színuszfüggvény | sin (a) | 1 |
SIN | Real | Real |
| DSIN | Double | Double | |||
| Koszinuszföggvény | cos (a) | 1 |
COS | Real | Real |
| DCOS | Double | Double | |||
| Tangens hiperbolikus | tanh (a) = th (a) | 1 |
TANH | Real | Real |
| Négyzetgyökvonás | (a) ** 1/2 | 1 |
SQRT | Real | Real |
| DSQRT | Double | Double | |||
| Árkusz tangens főértéke | arctg (a) | 1 |
ATAN | Real | Real |
| DTAN | Double | Double | |||
| arctg (a1/a2) | 2 |
ATAN2 | Real | Real | |
| DATAN2 | Double | Double | |||
| Maradékképzés | a1 (mod a2) | 2 |
DMOD | Double | Double |
Nagyon fontos beszélnünk a függvények és argumentumaik típusáról. Minden függvény meghatározott típusú értékét vesz fel. Ezt a típust nevezzük a függvény típusának, vagy azt mondjuk, hogy ilyen típusú a függvény. Az argumentum (vagy argumentumok) típusának meg kell felelnie a függvény definíciójának. Az argumentum lehet megfelelő típusú aritmetikai kifejezés is.
Mint a fenti táblázatból látható, a standard függvények azonosítói úgy vannak megválasztva, hogy kezdőbetűik lehetőleg megfeleljenek az automatikus típusdeklaráció szabálynak (lásd a Második fejezet 3. pontját), vagy legalábbis kifejezzék a függvény típusát. Ezek közt a standard függvények közt számos konverziós eljárást is találunk, melyek segítségével eltérő típusú változót vagy kifejezést is beépíthetünk aritmetikai kifejezéseinkbe; például
B**2 + C*FLOAT(I*K)
valós típusú kifejezés, melyben az l*K tényező egész típusú, vagy
I + 10*K - IFIX(Q/T)
egész típusú kifejezés, melyben a Q/T tag valós típusú. Megtalálhatók a standard függvények között a leggyakrabban használt vények: SIN (X), COS (X), ALOG(X), ALOG10(X), EXP(X), ATAN (X), sőt ezeknek olyan változatai is, melyeket kétszeres pontosságú és komplex típusú kifejezésekben használhatunk. Külön jele van a négyzetgyökvonásnak: SQRT(X).
Ezeknek a függvényazonosítóknak az alkalmazását a FORTRAN nyelv elég bonyolult módon korlátozza. Ezért helyesen járunk el, ha csak a megfelelő standard függvények azonosítására használjuk fel őket.
Példa formula átírására aritmetikai kifejezéssé, a standard függvények felhasználásával:
A formula:
a kifejezés: SQRT(S*(S-A)*(S-B)*(S-C))
2.6. Relációk
Ha két aritmetikai kifejezés értékét összehasonlítjuk (relációba hozzuk), különféle megállapításokat tehetünk, pl.: egyenlőek, nem egyenlőek, az első nagyobb a másodiknál, az első nagyobb vagy egyenlő a másodikkal stb. Most vegyük magunknak a bátorságot és az értékek ismerete nélkül mondjuk ki, hogy pl. egyenlőek. Két eset lehetséges: ez az állításunk vagy megfelel a valóságnak, vagy nem. Ilyen állításokat a FORTRAN-ban ún. relációk segítségével írhatunk fel.
A FORTRAN nyelvben hatféle ún. relációjel van definiálva, ezek jelölése jelentésükkel együtt a következő:
Relációjel Jelentése .EQ.
.NE.
.GT.
.GE.
.LE.
.LT.egyenlő
nem egyenlő
nagyobb, mint
nagyobb vagy egyenlő
kisebb vagy egyenlő
kisebb, mint
A pontok a jelölések lényeges részét képezik.
Formálisan egy relációt úgy írunk fel, hogy két aritmetikai kifejezést egy relációjellel kötünk össze. (Ennek speciális esete, amikor valamelyik kifejezés egyetlen változó.) Relációba hozhatók azonos típusú aritmetikai kifejezések, kivéve a COMPLEX típusúakat, továbbá relációba hozhatók egymással a nem azonos típusú aritmetikai kifejezések közül a REAL típusúak a DOUBLE PRECISION típusúakkal. Például az
X**2 .GE. 4.0
olvasd: x^2 >= 4
és a
B**2 .LT. 4.0*A*C
olvasd: b^2 < 4ac
valamint az
A+B .EQ. C
olvasd: a+b = c
reláció valós kifejezéseket hasonlít össze az automatikus típusdeklarációs szabály szerint.
Attól függően, hogy X, A, B és C értéke a reláció kiértékelésekor mekkora, maga a reláció "értéke" lehet igaz, vagy hamis. Azt mondjuk, hogy a reláció felveszi az igaz vagy a hamis, a FORTRAN szintaxisa szerint a TRUE vagy a FALSE értékeket.
A relációk azok a legegyszerűbb programozási objektumok, amelyek ezeket a logikai értékeket vehetik fel. Kiértékelésük a két aritmetikai kifejezés kiértékelésével kezdődik.
Formális szempontból fel szeretnénk itt hívni arra a figyelmet, hogy valós típusú változók esetén az egyenlőség nagyon kevés esetben teljesül. Sok esetben célszerűbben járunk el, ha
A+B .EQ. C
helyett az
ABS(A+B-C) .LT. EPSIL
relációt írjuk programunkba, ahol EPSIL egy megfelelően kicsire választott szám.
2.7. Logikai változók, műveletek, kifejezések
A programozásban szükség lehet arra, hogy egy reláció logikai értékét, vagy valamely más logikai értéket későbbi felhasználáshoz, mint részeredményt megőrizzünk. Ilyen célra logikai változókat alkalmazhatunk.
Az automatikus típusdeklarálás szabálya nem gondoskodik a logikai változók azonosítóiról. Ezeket mindig speciális utasítással kell megadni (lásd a 4.1. pontot). Most célszerűségi okokból a logikai változók jelölésére L betűvel kezdődő azonosítókat fogunk használni.
Ahogyan két számérték közt aritmetikai műveleteket, ugyanúgy két logikai érték közt ún. logikai műveleteket lehet értelmezni. A formális és matematikai logikával összhangban, a FORTRAN nyelv is értelmez ilyen műveleteket, mégpedig a következőket:
Jele Jelentése .AND.
.OR.
.NOT.
.XOR.Logikai szorzás (konjunkció, olvasva "és")
Logikai összeadás (diszjunkció, olvasva "akár")
Tagadás (negáció, olvasva: "nem")
Kizárólagos vagy
Megjegyezzük, hogy az első három műveletől (AND, OR, NOT) a matematikai logika bonyolultabb műveletei mind felépíthetők. Ezért a szabvány több műveletet nem is ír elő, de a FORTRAN-80-ban implementálva van a XOR is.
A kétparaméteres logikai műveleteket 2x2 "bejáratú", ún. értéktáblázatokkal célszerű definiálni, mivel az "argumentumuk" csak kétféle logikai értéket vehetnek fel. Az értéktáblázatok a következők:
Logikai szorzás LA .AND. LB
TRUE FALSE TRUE TRUE FALSE FALSE FALSE FALSE
A táblázat bemenetein LA és LB értékeit, a megfelelő táblázatelemben az eredményt adtuk meg. Látható, hogy logikai szorzás csak akkor ad TRUE eredményt, ha mindkét komponens értéke TRUE.
Logikai összeadás: LA .OR. LB
TRUE FALSE TRUE TRUE TRUE FALSE TRUE FALSE
Látható, hogy a logikai összeadás eredménye csak akkor FALSE, ha mindkét komponens értéke FALSE.
Tagadás: .NOT. LA
Szemben az előzőekkel, a tagadás egyparaméteres művelet.
TRUE FALSE .NOT.LA FALSE TRUE Kizáró vagy: LA .XOR. LB
TRUE FALSE TRUE FALSE TRUE FALSE TRUE FALSE
A kizáró vagy művelet abban különbözik a diszjunkciótól, hogy nem engedi meg, hogy a két állítás logikai értéke egyszerre igaz legyen. A művelet eredménye akkor FALSE, ha mindkét állítás logikai értéke megegyezik.
Szemléltessük logikai műveleteinket! Vegyünk két relációt: I.GT.0 és J.GT.0. Ha ezek I és J aktuális értékétől függően teljesülnek, legyen LA, ill. LB értéke TRUE, ellenkező esetben FALSE. Mit jelent akkor a LA.AND.LB kifejezés értéke? Ha LA.AND.LB értéke TRUE, ez azt jelenti, hogy mind I, mind pedig J aktuális értéke nagyobb nullánál; ha LA.AND.LB értéke FALSE, akkor legalább egyikük nem nagyobb nullánál. Viszont LA.OR.LB értéke arra ad választ, hogy I vagy J közül legalább az egyik nagyobb-e, mint nulla; ha igen, akkor LA.OR.LB értéke TRUE, ellenkező esetben FALSE. A .NOT.LA tagadás értéke pedig arra ad választ, hogy I kisebb, vagy egyenlő-e zérusnál: ha igen, úgy .NOT.LA értéke TRUE, ha nem, úgy FALSE.
Ismerjük tehát a logikai műveleteket. Ezek segítségével háromegyszerű logikai kifejezést már fel is írtunk: LA.AND.LB, LA.OR.LB és .NOT.LA. Írjunk most fel néhány bonyolultabbat!
Vizsgáljuk meg a felírt logikai kifejezéseket! Eközben ismerkedjünk meg szerkezetükkel és kiértékelésük szabályaival!
Az 1. példa szerint logikai művelet végezhető relációval is; ilyenkor először kiértékelhetjük a relációt, majd logikai értékének felhasználásával a logikai műveletet végezzük el. például, ha a LA logikai változó értéke TRUE, viszont A = 3.2 és B=2.5, vagyis az A.LT.B reláció nem teljesül, azaz értéke FALSE, akkor a logikai szorzás (.AND.) művelete a FALSE végeredményre vezet.
A 2. logikai kifejezés kiértékelése két reláció kiértékelésével kezdődik: ha I = 0, akkor az I.EQ.0 reláció értéke TRUE, ellenkező esetben FALSE; ha J=2, akkor a J.EQ.2 reláció értéke TRUE, ellenkező esetben FALSE. Ha valamelyikük is a TRUE értéket veszi fel, a logikai összeadás művelete már a TRUE vlgeredményt adja.
A 3. kifejezés kiértékelését szintén egy reláció, m=j^2 kiértékelésével kell elkezdeni. Ezután bajba jutunk, mert nem tudjuk, hogy az .AND. vagy a .NOT. műveletet értékeljük ki előbb (precedencia?). 4. hasonló a 2. kifejezéshez, csupán az egyik relációban aritmetikai kifejezések szerepelnek.
5. kiértékelése szintén valamiféle precedenciaszabály ismeretét tételezi fel. 6-ból látható, hogy a műveletek elvégzésének sorrendjét itt is zárójelekkel lehet szabályozni.
Láthatjuk, hogy logikai kifejezésekbe aritmetikai kifejezések, relációjelek, logikai változók és a logikai műveletek jelei építhetők be zárójelek felhasználásával. A zárójelek alkalmazásának szabályai azonosak az aritmetikai kifejezések kapcsán elmondott szabályokkal. Szükségünk van viszont új precedencia szabályok felállítására és új szintaktikus osztályok definiálására. Ezek - definícióikkal együtt - a következők:
1. Elsődleges logikai kifejezések a következők:
- logikai konstans, azaz a .TRUE. vagy a .FALSE.
Ahogyan a számértéket a programban számkonstanssal is megadhatjuk, ugyanúgy a logikai érték megadásához a logikai konstansokat is felhasználhatjuk. A pontok a konstansokhoz hozzátartoznak.- logikai változó azonosító, pl.: LA
- reláció, pl.: I.LT.J
- logikai típusú függvény (lásd az Ötödik fejezet 3. pontját).
- zárójelbe zárt logikai kifejezés, pl.: (LA.OR.LB).
2. Logikai tényező lehet vagy egy elsődleges logikai kifejezés, vagy a .NOT. műveleti jel a mögötte álló elsődleges kifejezéssel együtt. PL: LA vagy .NOT.LA
3. A logikai tag logikai tényezők egy- vagy többelemű sorozata, amelyben az egyes tényezőket az .AND. műveleti jel választja el. Pl:
LA
LA.AND.LB
.NOT.LA.AND.LB4. A logikai kifejezés logikai tagok egy- vagy többelemű sorozata, amelyben az egyes tagokat az .OR. műveleti jel választja el. Pl.:
LA
LA.OR.LB.OR.LC
LA.AND.LB.OR.LC
Az utolsó kifejezésben például két tag szerepel: LA.AND.LB, illetve LC, melyek közül az első két tényezőből, LA-ból és LB-ből tevődik össze.
A definíciókból következik a logikai kifejezésekben szereplő műveleti jelek precedenciája:
Most már érthető 2. példa korábbi kiértékelési módja; 3. kiértékelése esetén előbb a .NOT. műveletet és később az AND. műveletet kell végrehajtani; 5-ben előbb az .AND. műveletet, később az .OR. műveletet kell végrehajtani.
Látható, hogy a logikai kifejezésekbe aritmetikai kifejezéseket lehet beépíteni. Ez azt sugallja, hogy ne különböztessük meg az aritmetikai és logikai kifejezéseket, hanem általában kifejezésről beszéljünk. Ebben az esetben természetesen az operandusok típusának meg kell felelniük a rájuk ható műveletek kívánalmainak. Ez a tendencia az ALGOL nyelvien méginkább érezhető.
A logikai műveletek kiértékelésének szabályai hasonlóak az aritmetikai kifejezések kiértékelésének szabályaihoz:
Hogy jobban lássuk szabályaink jelentőségét, példaképpen értékeljük ki a
LA.OR.LB.OR.LC.AND.(LP.OR.LQ).AND.(l**2.LT.9.OR.LD)
logikai kifejezést, ha LA = LC = LP = LD = FALSE, LB = LQ = TRUE és I=2
Ei-vel részeredményeket jelölünk!
Két úton járjunk most el:
1. A precedenciákhoz szigorúbban alkalmazkodó módszer szerint:
E1 = LP.OR.LQ = TRUE
E2 = I**2 = 4
E3 = 4.LT.9 = TRUE
E4 = E3.OR.LD = TRUE
E5 = LC.AND.E1 = FALSE
E6 = E5.AND.E4 = FALSE
E7 = LA.OR.LB = TRUE
E8 = E7.OR.E6 = TRUE, ami a végeredmény.
2. Az ALGOL nyelvben használt balról jobbra szabályhoz szigorúan alkalmazkodó módszer szerint (így is szabad!):
E1 = LA.OR.LB = TRUE, ami már a végeredmény, és ezért tovább nem is kell számolni, hiszen akárhány .OR. tagolná is tovább kifejezésünket, a közrezárt logikai tagok értékétől a végeredmény már nem függ: volt már egy TRUE értékű tag. Az eredmény természetesen nem függ a kiértékelési módszertől.
Más példa erre az utóbbi módszerre:
Értékeljük ki a fenti értékekkel a
LA.OR.I**2.LT.1.AND.(LP.OR.LQ).OR.LC.OR.{folytatás...}
logikai kifejezést!
E1 = LA = FALSE
tehát a következő tagot még ki kell értékelni.
E2 = I**2 = 4
E3 = 4.LT.1 = FALSE
E4 = E3.AND.{egy tényező} = FALSE. Mivel az első tényező FALSE volt, nem kell kiértékelni a második tényezőt. Át kell térni tehát a harmadik tagra E5 = LC = TRUE = E6, ez a végeredmény, függetlenül attól, mi van a harmadik .OR. jobb oldalán.
3.1. Az utasítások típusai a FORTRAN nyelvben
A FORTRAN utasításokat két csoportba soroljuk. A végrehajtható utasításokat általában a célprogram hajtja végre a futtatás során. A nem végrehajtható (vagy deklaratív) utasítások főként a fordítóprogramnak szólnak. Az előbbiek részletes ismertetése főként ennek a fejezetnek, az utóbbiaké pedig a Negyedik fejezetnek a tárgya.
A végrehajtható utasítások közé soroljuk az értékadó utasításokat, az ún. vezérlőutasításokat és a perifériakezelés több utasítását. Néhány vezérlőutasítás (CALL, RETURN) tárgyalása az Ötödik fejezetbe, a perifériakezelés egésze pedig a Hatodik fejezetbe került.
A végrehajtható utasítások ismeretében már el lehet készíteni olyan programrészleteket, amelyek a gyakorlatban előforduló problémákat oldanak meg.
3.2. Értékadó utasítások
Az értékadó utasítás három részből áll: bal oldali változóból, az értékadás jeléből és egy jobb oldali kifejezésből. Az értékadás jele a közismert egyenlőségjel: "=". Formálisan:
V = e
ahol V egy változó azonosító, = az értékadás jele és e egy kifejezés, mely lehet különféle típusú aritmetikai kifejezés vagy logikai kifejezés is.
Az értékadó utasítás hatására a V változó elveszti korábbi értékét (ha volt), és felveszi az e kifejezés aktuális értékét. Az értékadás csak abban az esetben hajtható végre egyszerűen, ha a V változó típusa megfelel az e kifejezés típusának. Aritmetikai változó nem vehet fel logikai értéket és logikai változó nem vehet fel számértéket. Ezért kétféle értékadó utasításról szokás beszélni: logikai és aritmetikai értékadó utasításról.
Logikai értékadó utasítás
Ha a V=e képletben V és e típusa egyaránt logikai, akkor logikai értékadó utasításról beszélünk. Példák:
LA = LB.AND.LC
LB = J.LT.12.OR.I.GT.0
LC = .TRUE.
Megjegyezzük, hogy a gyakorlati programozásban csak az utolsó alakú értékadó utasításban szokott ún. logikai konstans előfordulni. A pontok a logikai konstansok lényeges részei: konstansok .TRUE. és .FALSE., értékük rendre: TRUE és FALSE!
Aritmetikai értékadó utasítás
Ha a V=e képletben V és e egyaránt aritmetikai típusú, akkor aritmetikai értékadó utasításról beszélünk. Ha V és e mindketten aritmetikai típusúak ugyan, de típusuk nem megegyező, akkor az alábbi táblázat szerint a bal oldali változó e megfelelő függvényének értékét veszi fel; néhány esetben pedig meg van tiltva a típuspárosítás használata.
Típuseltérések aritmetikai értékadásnál:
V típusa: INTEGER REAL DOUBLE PRECISION Az E betű közönséges értékadást jelöl. Megjegyezzük, hogy az SNGL és IFIX konverziók "abszolút értékben lefelé" kerekítenek. A kétszeres pontosságú és egész típus között a konverzió két lépésben, a valós típuson keresztül megy végbe.
A következő két utasításban V és e típusa egyező: az elsőben INTEGER, a másodikban REAL:
I = 2*J + K**2
F = (B**2 - 4.0*A*C)/4.0/A**2
Egy példa arra az esetre, mikor V REAL, e pedig INTEGER típusú:
F = 2*K+K+1
És a "fordított" eset:
I = SQRT(A)
Az utolsó példa kapcsán fel kell hívni az olvasó ügyeiméi egy gyakori programozási hibára:
Legyen az A valós típusú változó "szándékolt" értéke 4.0. Elképzelhető, hogy kerekítési hibák folytán a gép 4-nél kb., 10^-12-nel kisebb értékkel számol. Ha a SQRT négyzetgyökvonó eljárás is lefelé hibázik "egy kicsit", SQRT(A) értéke biztosan kisebb, mint 2. Értékadás során a fenti táblázat szerint REAL típusú e és INTEGER típusú V esetében az IFIX konverziós eljárás kerül alkalmazásra és így az értékadó utasítás I-nek nem a 2, hanem az 1 értéket adja! Ezért helyesebb helyetet az
I = SQRT(A)+1E-8
utasítást használni. A 10^-8 érték megfelelő biztonságot nyújt a fent leírt effektus ellen.
Gyakran célszerű, hogy egyetlen bonyolultabb értékadó utasítást több utasításra bontsunk szét. Legyen például a feladat az
függvényérték kiszámítása a és b ismeretében. Megoldható a feladat egyetlen értékadó utasítással is:
Y = (A**2 + B**2 + SIN(A**2 + B**2)
1+ ALOG(SIN(A**2 + B**2)))/(A**2 + SQRT(
2B**2 + SIN(A**2 + B**2)) + ALOG(SIN(A*
3*2 + B**2)))
Ugyanezt a feladatot oldja meg a következő programrészlet:
W1 = A**2
W2 = B**2
Y = SIN(W1+W2)
W1 = W1+ALOG(Y)
W2 = W2+Y
Y = (W1+W2)/(W1+SQRT(W2))
Ebben a programrészletben felhasználtuk a W1 és W2 segédváltozókat (munkaváltozókat), sőt magát. Y-t is különféle részeredmények tárolására. A programrészlet végrehajtása során a számítógép csak kétszer emel négyzetre és egyszer keres szinuszt, illetve logaritmust.
3.3. Vezérlő utasítások és címkék
ASSIGN utasítás
A FORTRAN utasítások felírásuk sorrendjében kerülnek végrehajtásra, hacsak ezzel ellenkező végrehajtási módról külön intézkedés nem történik. A vezérlő utasítások szerepe éppen az, hogy a felírási sorrendtől eltérő megfelelő végrehajtási sorrendeket írjanak elő. Ezt általában úgy érik el, hogy megnevezik a soron következő utasítást, melynek ehhez természetesen "nevet kell adni". Ezek a "nevek" a FORTRAN nyelvben a címkék.
Ha egy FORTRAN utasítást címkével akarunk ellátni, akkor az utasítás első sorának 1-5 karakterpozíciójára 5-nél nem több jegyű egész számot írunk. Ez a számjegyekből álló karaktersorozat az utasítás címkéje. A vezérlésátadó utasításokba ezt a karaktersorozatot kell beírni, ha erre a címkére akarunk ugratni, azaz ha a program végrehajtását a címkével megjelölt utasítással akarjuk folytatni.
Speciális esetben a címkét a vezérlésátadó utasításban egy INTEGER típusú változó azonosító helyettesítheti (ld. kijelöli GOTO utasítás a következő alpontban). Ekkor e változó értéke címke kell, hogy legyen. Az ASSIGN utasítás arra szolgál, hogy INTEGER típusú változónak egy konkrét címkét adjon értékül. Alakja:
ASSIGN j TO i
ahol "j" cimke, "i" pedig INTEGER változó azonosító. Például:
ASSIGN 118 TO KAPCS
ASSIGN 21 TO IZIDOR
Az ilyenfajta utasítások későbbi felhasználás céljára "elraktározzák" a megfelelő címkéket. Hatásuk nem azonos a
KAPCS = 118
IZIDOR = 21
utasításokkal és egymást nem is helyettesíthetik, hiszen a "118" karaktersorozat nem azonos a 118 egész típusú számmal.
Magukat a vezérlő utasításokat jelölésük alapján csoportosítjuk. Beszélni fogunk különféle GOTO utasításokról, aritmetikai és logikai IF utasításról, ciklus, vagy DO utasításról, CONTINUE utasításról, végül a megállító utasításokról, azaz a STOP és a PAUSE utasításról.
Feltétlen vezérlésátadás. A feltétlen és a kijelölt GOTO utasítás
Ha azt akarjuk előírni, hogy egy utasítás után ne a sorrendben reá következő kerüljön végrehajtásra, hanem egy meghatározott másik, ezt az ún. feltétlen GOTO utasítással érhetjük el. Ennek formája:
GOTO j
ahol "j" cimke. Gyakori írásmód még a GO TO, a kettő között a FORTRAN nyelv nem tesz különbséget.
Tekintsük például a következő programrészletet:
F = A+B
GOTO 13
88 G = A-B
13 C = F+G
A részlet második utasítása után, a GOTO 13 utasítás hatására a 13-as címkéjű utasítás hajtódik végre. Ilyen esetben azt mondjuk, hogy a "vezérlés" a 13-as címkére adódik át, vagy ugrás történik a 13-as címkére stb.
Magának a GO TO utasításnak is lehet címkéje. Ha véletlenül ugyanazt a címkét viseli, mint amelyre ugrat, akkor, ha egyszer erre az utasításra sor került, a program ezt az utasítást lógja ismételni a végtelenségig. Például: 125 GOTO 125. Úgy is mondhatjuk, hogy a program "végtelen ciklusba" került. A fenti ciklus például egyetlen utasításból áll. Programozói hiba sokszor vezethet több utasítást tartalmazó végtelen ciklushoz, amelyekből hasonlóképpen nincs "kijárat".
Ha a GOTO utasításban a címke helyére egész változót írunk, melyet zárójelbe zárva és vesszővel elválasztva címkelista követ, például
GOTO KAPCS, (10,11)
GOTO IZIDOR,(3,8,10,15)
akkor ún. kijelölt GOTO utasítást írtunk fel. Az ugrás ilyenkor az egész változó értékének megfelelően történik. Ez az érték nem lehet tetszőleges, hanem szükséges, hogy megegyezzék az utána álló címkelista valamelyik értékével. Az égész változó ezt az értéket egy előzőleg végrehajtott ASSIGN utasításban kapta. Ha az egész változó több ASSIGN utasításban kapott értéket, mindig az utoljára végrehajtott ASSIGN utasítás a mérvadó.
Az ASSIGN utasítások és a megfelelő kijelölt GOTO utasítások közt tehát szoros kapcsolat van. Lássunk erre egy példát:
ASSIGN 10 TO KAPCS
R = 15.0
GO TO 153
10 BERUH1 = 48.6*F + 125.4*T
R=23.4
ASSIGN 11 TO KAPCS
GO TO 153
11 BERUH2 = 81.3*F + 42.8*T
...
153 W = R**2
F = 12.56637*W
T = 4.18879*R*W
GO TO KAPCS, (5,10,11,13,47)
...
A KAPCS változó először értékként felveszi a 10-es címkét, R pedig a 15.0 értéket, majd a programrészlet végére, a 153-as címkére történik ugratás. Itt az R sugarú gömb F felületét és T térfogatát számítjuk ki, és a KAPCS változó jelentésének megfelelően visszaugrunk a 10-es címkére. Itt a felszínt és térfogatot valamilyen empirikus formula szerint beruházási költség számítására használjuk fel. Ezután az egész procedúrát más állandókkal megismételjük. Látható, hogy a 153-as címkéül kezdődő programrészletet többször használtuk fel. Hasonló hatást érhetünk el a később tárgyalandó kiszámított GO TO utasítással is.
Elágaztatás előjel és nulla szerint Az aritmetikai IF utasítás
A FORTRAN nyelv igen célszerűen felhasználható és a számítógépekben igen gyorsan végrehajtható jellegzetes utasítása az aritmetikai IF utasítás. Alakja:
IF (e),j1,j2,j3
ahol e egész, valós, vagy kétszeres pontosságú aritmetikai kifejezést, j1, j2 és j3 pedig vesszőkkel elválasztott címkéket jelöl. (Lehetnek e címkék között azonosak is!) Például:
IF(I-J)10,11,7
IF(K)13,13,14
IF(B**2 - 4.0*A*C)15,16,16
IF(ABS(COS(X))-EPS)20,17,20
Az utasítás hatására kiértékelésre kerül a zárójelben levő aritmetikai kifejezés. Ha ennek értéke negatív, ugrás következik az első (j1) címkére, ha nulla, akkor a középső (j2) címkére, ha pozitív, akkor pedig az utolsó (j3) címkére.
Az első példában az aritmetikai kifejezés két egész szám különbsége. Tehát az ugrás előtt azt vizsgáljuk, hogy egyenlők-e, illetve melyikük nagyobb. A második példa szerint az e kifejezés lehet egyetlen változó azonosító. Ebben az esetben a vizsgálat az illető változó értékére vonatkozik. Be lehet építeni hosszabb valós kifejezést, pl. a másodfokú egyenlet diszkriminánsát is az aritmetikai IF utasítás zárójelébe (ld. 3. példa). Ez azonban általában nem célszerű, mert a kifejezés számértéke elvész, és ha a továbbiakban szükség lenne reá, újra ki kell számítani. A negyedik példa szerint az aritmetikai kifejezésben előfordulhatnak különféle függvények is. Ha azt akarjuk megállapítani egy valós, vagy kétszeres pontosságú értékről, hogy nulla-e, célszerűbb, ha azt vizsgáljuk, hogy abszolút értéke kisebb-e egy megadott kis pozitív számnál. Ugyanis a számológépek számábrázolási pontossága olyan nagy, hogy sok esetben teljesen felesleges ilyen szigorúsággal megkövetelni egy mennyiségtől, hogy az nulla legyen. Különben is, hn ez a mennyiség számítások eredményeként adódik, igen nagy kerekítési hiba terhelheti. Ezért az egzakt nullát a numerikus gyakorlatban annak megfelelő környezete szokta helyettesíteni.
Alkalmazási példaként írjunk egy olyan FORTRAN programrészletet, amely az ax^2 + bx + c = 0 másodfokú egyenlet valós gyökeit számítja ki. Tegyük fel, hogy a<>0.
W = 2.0*A
D = B**2 - 4.0*A*C
IF(D) 20,18,16
16 D = SQRT(D)
X1 = (D-B)/W
X2 = (-D-B)/W
GO TO 22
18 X1=(-B)/W
X2 = X1
GO TO 22
...
Programrészletünk pl. komplex gyökök esetén a 20-as címkére adja a vezérlést.
Az ICT FORTRAN megengedi, hogy az aritmetikai IF utasítás címtől közt a nulla számjegy is előforduljon, mint címke. Az ilyen "szimbolikus címke" hatására a vezérlés a rákövetkező FORTRAN utasításra adódik át.
Feltételes utasítás. A logikai IF utasítás
Egy FORTRAN utasítást egy feltétel teljesülésétől függően kihagyhatunk vagy elvégeztethetünk a logikai IF utasítás felhasználásával, melynek formája:
IF(LA),u
Ahol LA tetszőleges logikai kifejezés (pl.: reláció, logikai változó stb.), u pedig tetszőleges olyan FORTRAN utasítás, amely nem DO vagy másik logikai IF utasítás, nem ciklusutasítás, és melynek nincsen címkéje.
Az utasítás végrehajtása a logikai kifejezés értékelésével kezdődik. Amennyiben annak értéke TRUE, akkor u végrehajtása következik (ez a leggyakrabban GOTO utasítás szokott lenni). Ha értéke FALSE, u végrehajtása elmarad, a gép áttér a következő FORTRAN utasítás végrehajtására.
Például:
IF(A.GT.B) GO TO 125
IF(A.LT.0.0)A = -A
113 IF(I.GT.0.AND.J.LT.5) GOTO 8
Tekintsük a fenti - 3 db logikai IF utasításból álló - programrészletet! Ha a>b, akkor elugrik a program a 125-ös címkére. Ha a<=b, sorrakerül a második utasítás. Ha a<0, akkor a előjelet vált. A harmadik utasítás ugrást ír elő a 8-as címkére, ha egyidejűleg fennáll i>0 és j< 5. Itt látható az is, hogy magának a logikai IF utasításnak lehet címkéje, csupán a zárójel után következő u utasításnak nem!
A fenti példa helyett írható a következő szerkezet logikai IF utasítással:
IF(A-B)15,15,125
15 A = ABS(A)
113 IF (I) 17,17,16
16 IF(J-5) 8,17,17
17 ...
Ezzel a megoldással csupán az a kényelmetlenség jár, hogy a soron következő utasítást fel kell címkéznünk, amire egyébként nem volna szükség.
Többirányú elágaztatás. A kiszámított GOTO utasítás
Programok többirányú elágaztatására a FORTRAN nyelv még egy - a kijelölt GO TO utasításhoz hasonló - lehetőséget biztosít: az ún. kiszámított GOTO utasítást. Az utasítás alakja:
GOTO i,(j1,j2,...,jn)
ahol j1,j2,...jn sorozat címkék vesszőkkel elválasztott n elemű sorozata, i pedig INTEGER változó, melynek aktuális értékére az utasítás végrehajtásakor fenn kell állnia az
1 <= i <= n
összefüggésnek. Az utasítás hatása azonos a
GOTO ji
utasításéval, ahol ji a fenti címkelista i-edik eleme. Tehát i megmondja, hogy a lista hányadik elemének megfelelő utasításra kell ugrani.
A lista elemei között akárhány egyenlő is lehet.
Az ICT FORTRAN megengedi a listában a 0 "szimbolikus címke" használatát ugyanúgy, mint az aritmetikai IF utasításban. Ennek hatására most is a reákövetkező FORTRAN utasításra adódik át a vezérlés.
3.4. Indexes változók, tömbök. Indexkifejezések
Sok matematikai feladatban nagyszámú, valami módon összetartozó mennyiség között kell hasonló műveleteket elvégeznünk. Gondoljunk például két többelemű vektor skaláris szorzatának kiszámítására, vagy két n x n-es négyzetes mátrix összeszorzására. Ezeknek a műveleteknek a programozása eddigi eszközeinkkel nagyon nehézkes: minden vektorkomponens, minden mátrixelem számára külön jelölésre van szükség, minden egyes mátrixelemet külön utasítással kellene kiszámítani.
A vektorokkal és mátrixokkal való műveletek könnyen programozhatóak, ha felhasználjuk az indexes változókat, illetve a tömböket. A FORTRAN nyelvben a vektoroknak az ún. egydimenziós tömbök, a mátrixoknak a kétdimenziós tömbök feleltethetők meg. A tömböknek éppen úgy, mint a változóknak, azonosítóik vannak. A vektorok és mátrixok egyes komponenseinek, ill. elemeinek a tömbelemek vagy más szóval az indexes változók felelnek meg. Például: U(1), V(12), A(l,2), B(2,K), C(I,K)
Látjuk tehát, hogy a tömbelemeket vagy indexes változókat úgy jelöljük, hogy a tömbazonosítót zárójelpárba zárva követi az index, vagy követik - egymástól vesszővel elválasztva az indexek. Az indexek mindig egész típusú mennyiségek. Az indexek száma a FORTRAN nyelvben maximálisan három, azaz a FORTRAN-ban maximálisan három dimenziós tömbök vannak értelmezve. A tömbök méreteit, azaz a tömbök elemeinek számát összesen és az egyes dimenziókban véve a FORTRAN nyelv nem korlátozza. Tehát a FORTRAN kezelni tudja mind egy százkomponensű vektor, mind egy 8 x 8-as mátrix megfelelőit: a százelemű egydimenziós és a 8x8-as kétdimenziós tömböt.
Az indexes változók használatának főbb szabályai:
A standard indexkifejezések a következő egész kifejezés típusokból kerülhetnek ki (a továbbiakban c és k pozitív egész számokat, I egész változót jelöl):
típusok: példák: c*I+k
c*I-k
c*I
I+k
I-k
I
k2*I+5
8*J-3
2*K
L+2
M-1
N
4
A standard indexkifejezésekben nemcsak a számok és a változó típusa és értéke speciális, hanem az egyes "alkotórészek" sorrendje is kényeges. Ezek szerint pl. nem standard indexkifejezések a következők: 5+I, 6-J, -K+5
Ahhoz, hogy egy tömbelemmel számolni lehessen, az kell, hogy a megfelelő indexkifejezéseknek - így a bennük szereplő egész változóknak - értékük legyen. Továbbá az is szükséges, hogy az indexek száma megegyezzék a tömb deklarált dimenziójával, és az indexek aktuális értéke olyan pozitív egész szám legyen, mely nem haladja meg a tömbnek a megfelelő dimenzió "irányában" deklarált méretét.
A számítógép tehát a megfelelő tömbelemmel csak úgy tud dolgozni, hogy előbb kiértékeli az indexeket. Ebből következik, hogy bármiféle számolás mindig lassúbb indexes változóval, mint ha az indexes változó helyett közönséges változó szerepel.
3.5. Ciklusutasítások és használatuk
Eddigi ismereteinkkel egy ciklus szervezése a következő adminisztrációt követeli meg:
Tekintettel arra, hogy a ciklusok ilyen szervezése a programozói gyakorlatban rendkívül gyakori, a FORTRAN nyelv a ciklusok megadására összevont jelölést, külön utasítást vezetett be.
A DO utasítás és a CONTINUE utasítás
A FORTRAN nyelvben a ciklusutasítás általános alakja a következő:
DO k i=m1,m2,m3
vagy
DO k i=m1,m2
ahol
Mielőtt illusztrálnánk a DO ciklusutasítás használatát, vezessük be a FORTRAN nyelv legegyszerűbb utasítását, az üres utasítást, melynek egyedüli szerepe az, hogy címkét viselhet:
50 CONTINUE
Funkciója éppen az, hogy nem csinál semmit. Leggyakrabban a DO ciklusok záró, vagy utolsó utasításaként fordul elő, bár nem mindig kötelező ezen a helyen a CONTINUE utasítás használata.
Írjunk programot a vektorszorzásra:
T=0.0
DO 18 J=1,15
18 T = T+U(J)*V(J)
...
Írjunk programot mátrixszorzásra:
DO 21 I = 1,N
DO 20 K = 1,N
T = 0.0
DO 18 J = 1,N
18 T = T + A(I,J)*B(J,K)
20 C(I,K) = T
21 CONTINUE
Láthatjuk, hogy a külső ciklusok magjában a "beskatulyázott" ciklusok teljes egészükben benne vannak.
Állapítsuk meg, hogyan működik a
P = A(1)
Z = 2.0
DO 15 J = 3,N
Z = Z**2
15 P = P*Z+A(J)
...
programrészlet N különböző értékeire! Legyen N = 3, 4, 5, 2, 1!
Z és P értékei a ciklus elvégzése után, N különböző értékeire a következők:
N 3
4
5
2
1
16.0
256.0
4.0
4.0
16(4a1+a3)+a4
256(16(4a1+a3)+a4)+a5
4a1+a3
4a1+a3
Ciklusok egymásba skatulyázása
Mint ahogyan a mátrixszorzás példában már láttuk, a programozás során szükség lehet két vagy több ciklus egymásba skatulyázására. Ezen azt értjük, hogy a ciklusok egymáshoz viszonyítva úgy viselkednek, mint az aritmetikai kifejezésekben a zárójelpárok. Tehát egy ciklus akkor és csakis akkor van "beskatulyázva" egy külső - vagy külsőbb - ciklusba, ha minden utasítása hozzátartozik a külső ciklus magjához.
Egymásba skatulyázott ciklusok használatával kapcsolatban néhány szabályra külön fel kell hívni a figyelmet. Ezeket egyetlen "külső" és egyetlen "belső" ciklus viszonylatában tesszük szemléletessé:
Egyes gépi reprezentációk fordítóprogramjai nem tekintik hibásnak az olyan programokat, melyekben pl. a ciklusváltozó új értéket kap ciklus belsejében. Ilyen esetben előfordulhat azonos ciklusváltozó egymásba skatulyázott "hatáskörrel" rendelkező ciklusspecifikációban is. Azt, hogy ilyenkor a célprogram hogyan működik, csak a fordítóprogram ismeretében lehet megmondani. Ezért ez a tulajdonság sok programhibát tesz lehetővé.
Kiterjesztett hatáskörű ciklus
Az eddigiek alapján az olvasónak szemléletes képe van a programciklusról, így a ciklusmag fogalmáról is. Utóbbi a következőképpen definiálható: ciklusmagon azoknak az utasításoknak az összességét értjük, melyeket a ciklus lefutása során a program megismétel, illetve megismételhet; nem tartoznak viszont a ciklusmaghoz a ciklusszervezés adminisztratív utasításai.
Az előzőkben megismerkedtünk a DO utasítással, mint a FORTRAN nyelv ciklusutasításával. Láttuk, hogy ciklusok programozásának eléggé kényelmes, bár nem kizárólagos eszköze, hiszen nélküle is bármely ciklus programozható, sőt speciális esetekben előfordulhat, hogy a DO utasítást célszerű mellőzni. Jelen alpontban a ciklusmag és a DO utasítás kapcsolatát fogjuk pontosabban elemezni.
A ciklusparaméter beállításához és ellenőrzéséhez szükséges információkat a DO utasítás ciklusspecifikációjában vagy ún. ciklusspecifikációs részében lehet megadni. A DO utasításban szereplő címke a ciklusmag utolsó vagy záró utasítását adja meg. Eddigi ismereteink alapján még nem dönthető el, hogy ennek az utasításnak utolsó volta az utasítások végrehajtásának vagy felsorolásának sorrendjében értendő-e. Eddigi példáinkban minden esetben a ciklus záróutasítása mind végrehajtási, mind felírási sorrendben is utolsó volt. Az effektív fordítóprogramok és célprogramok konstruálásának könnyebbé tétele céljából ebben a kérdésben a FORTRAN a következő szabályokat írja elő:
DO 1 J = 1,3
1 ISZ(J) = 0
DO 5 I = 1,1000
DO 5 J = 1,3
KD = IT(I)-IP(J)
IF (KD) 5,2,5
2 IF (J-3) 3,25,3
3 IT(I) = IJ(I)
ISZ(J) = ISZ(J)+1
5 CONTINUE
...
25 IP(J) = 2*IP(J)-1
GOTO 3
...
Ez a programrészlet vizsgálja az IT(I) ezer elemű tömbben levő egész számok sorozatát. Ha talál benne olyan egész számot, amely IP(1), IP(2) vagy IP(3) valamelyikével megegyezik, akkor ezen elemeket kicseréli az IJ(1), IJ(2), illetve IJ(3) elemekre. Számolja azt, hogy melyik cseréből hány történt. Abban az esetben, amikor harmadik fajta cserét hajtana végre, a 2-es címkéjű utasítás a vezérlést a ciklusspecifikáció eredeti hatáskörén kívül fekvő 25-ös címkéjű utasításra adja. Itt IP(3) értéke megváltozik, azaz a ciklus ezentúl más számokkal fogja az IT(I) számokat összehasonlítani. Innen a vezérlés visszakerül az eredeti hatáskörbe.
A 25-ös címkéjű és az őt követő utasítás tehát a ciklusspecifikáció kiterjesztett hatáskörébe tartozik.
A FORTRAN nyelv a következő korlátozásokat és szabályokat állítja fel a DO ciklusok kiterjesztett hatáskörével kapcsolatban:
A kiterjesztett hatáskör ismeretében kissé bővebben kell magyaráznunk a DO utasítással kapcsolatos ismereteinket.
A kiterjesztett hatáskör bevétele a FORTRAN nyelvbe történeti okokra vezethető vissza. Azt kívánták a nyelv szerzői ezzel lehetővé tenni, hogy bizonyos javításokat és betoldásokat a programozó ne legyen kénytelen teljes egészében az adott ciklusok belsejében elvégezni, hanem bizonyos esetekben ezeket a program más részén is elhelyezhesse. Konkrét gépi reprezentációk sok esetben jóval rugalmasabban kezelik ezt a kérdést. Például az ICT FORTRAN be sem vezeti a kiterjesztett hatáskör fogalmát, hanem az egész kérdéskört egyetlen szabály kimondásával tarrtja kézben:
"Szabad egy ciklusspecifikáció hatáskörébe beugrani, ha előzőleg ugyanezen ciklusspecifikáció hatásköréből ugrottunk ki és közben nem adtunk értéket a ciklusspecifikáció paramétereinek és a ciklusváltozónak sem."
Ha a fordítóprogram feldolgozza az olyan forrásprogramokat is, melyekben a ciklusmag értékeket ad pl. a ciklusváltozónak, és hibajelzés sem ad, akkor a fordítóprogram pontos ismeretében egy ügyes programozó igen sok programozási fogást tud az egyes gépi reprezentációk lehetőségein belül megvalósítani. Igaz, egy ilyen rendszer sok hibalehetőségei is rejt magában, és biztosan kompatibilitási problémákat is okoz!
3.6. Megállító utasítások. A PAUSE és STOP utasítás
Befejezésül még két végrehajtható utasítással ismerkedünk meg, melyek a program futásának átmeneti, vagy végleges megállítására szolgálnak. Átmeneti megállítás érhető el a
PAUSE
vagy a
PAUSE c
ahol c maximum 6 karakterből álló karakterlánc. A karakterlánc üzenetként funkcionál, és tetszőleges karaktert (pl. betűt is) tartalmazhat.
Az utasítás hatására a program futása megáll, c üzenet hozzáférhetővé válik a kimeneti konzolon: megjelenik a monitoron, nyomtatón, vagy bizonyos jelzőlámpák kombinációjából leolvasható. Ezután a számológép kezelőjétől függ, hogy a programot továbbindítja-e. A továbbindíthatóság biztosítása szintén a PAUSE utasítás feladata: FORTRAN-80-ban a T billentyű megnyomása megszakítja a program futását, egyéb billentyű megnyomására folytatódik a program végrehajtása. Továbbindítás esetén a PAUSE utasítást követő FORTRAN nyelvű utasítás kerül végrehajtásra.
A végleges megállító utasítások a
STOP
és a
STOP c
melyek funkciója lényegesen egyszerűbb, mint a megfelelő PAUSE utasításoké: ilyenkor nincs biztosítva a továbbindíthatóság.
Tekintettel arra, hogy a programok megállítása szorosan összefügg a számológépek üzemével, ezen utasítások pontos hatása is a gépi reprezentációktól függő. A FORTRAN-80 a programfutás befejezésekor megjeleníti c üzenetet, melyre ugyanazok a megkötések érvényesek, mint a PAUSE utasításnál.
Egyéb gépi reprezentációban a c számra mások a kikötések: pl. lehet tízes vagy nyolcas számrendszerbeli szám is, ugyanakkor csak utolsó két jegye hozzáférhető. A STOP utasítás végrehajtásában is szerepet kaphat a paraméterként szereplő szám, például kinyomtatódik. Egyes gépi reprezentációk nem ismerik a STOP utasítást, hanem helyette a nem szabványos CALL EXIT utasítást használják.
4. Deklaratív utasítások (Nem végrehajtható utasítások)
A Harmadik fejezetben megismerkedtünk szinte valamennyi végrehajtható utasítással, csupán az input-output utasítások és a CALL, vagyis az eljáráshívó utasítás tárgyalása maradt hátra (ezeket a Hatodik fejezetben, illetve az Ötödik fejezet 3. pontjában ismertetjük).
4.1. A FORTRAN program szerkezete. A szegmensek
A megismert utasítások segítségével gyakorlatilag minden szóbajövő problémára tudunk megfelelő programrészletet készíteni. De - mint már korábban jeleztük - ahhoz, hogy ezek ti a részleteket a fordítóprogram megértse, további információkul van szüksége, amelyeket az ún. deklaratív, más néven nem végreható hajtható utasításokban adhatunk meg. Ha a végrehajtható és nem végrehajtható utasításokat meghatározott helyes sorrendben fűzzük össze, a fordítóprogram el fogja készíteni a feladni megoldásához szükséges célprogramot.
A programozói gyakorlat igen érdekes szempontját veszi figyelembe a FORTRAN nyelv, amikor lehetővé teszi nemcsak teljes, működőképes programoknak, hanem a programok bizonyos önállósággal rendelkező részeinek, az ún. programegységeknek, vagy szegmenseknek külön-külön lefordítását. így új programok esetleg gyorsan összeállíthatók kész, hibátlan szegmensekből, vagy pedig kidolgozásukon több programozó viszonylag függetlenül dolgozhat. A szegmensenkénti fordíthatóság elve természetesen megköveteli, hogy a különféle típusú utasítások helyes sorrendjét már a szegmenseken belül biztosítsuk. A szegmensek sorrendje és összefűzése, illetve a szegmensek együttműködésének biztosítása külön feladat, melyet az Ötödik fejezetben tárgyalunk.
Az ALGOL nyelvű programozásban jártas olvasó számára megjegyezzük, hogy a FORTRAN programok szegmensei nagyjából az ALGOL blokkok és eljárások megfelelőinek tekinthetők. Ezek a szegmensek azonban mellérendeltségi (és nem alárendeltségi) viszonyban vannak egymással.
Megállapításainkat szegmensekre fogjuk kimondani, hogy értelemszerűen átvihetőek legyenek több szegmensből álló programokra is. Ez alól egyetlen kivételt kell tennünk: az egy szegmensből álló program leírását vagy listáját mindig a PROGRAM utasítással fogjuk kezdeni és az END utasítással fogjuk befelezni (lásd az Ötödik fejezet 2. pontját). A PROGRAM utasítás alakja
PROGRAM sz
Az sz a főprogram neve, ami 1-6 alfanumerikus karakterből állhat, melynek első karaktere betű. A PROGRAM a főprogram első utasítása kell legyen, de használata nem kötelező. Ha egy fő programban nincs PROGRAM utasítás, akkor a fordító a $MAIN nevet rendeli a programhoz.
Az END utasítás az END betűk leírásából áll. Egyik utasításnak sem lehet címkéje.
A FORTRAN programok tehát szegmensekből, a szegmensek pedig utasításokból állnak. A szegmenseken belül megfelelő sorrendben kell elhelyezni a végrehajtható és nem végrehajtó utasításokat.
4.2. A nem végrehajtható utasítások fajtái. Az utasítások elhelyezése a szegmenseken belül.
A FORTRAN nyelv a következő nem végrehajtható utasításokat ismeri:
Ezen nem végrehajtható utasítások és a végrehajtható utasítások sorrendje nem lehet tetszőleges egy szegmensen belül. Bár erre vonatkozóan a nyelvdefiníció nem ad meg minden tudnivalót, a fontosabb gépi reprezentánsok ismeretében a következő két szabályt állíthatjuk fel:
A fordítóprogramok a specifikáló és kezdőértékadó utasításokat általában meghatározott sorrendben dolgozzák fel: típusdeklarációk, tömbdeklarációk, COMMON utasítások, EQUIVALENCE és DATA utasítások. Abból a célból, hogy ne kelljen a fordítóprogramnak ezeket az utasításokat külön sorba szedni, az egyes gépi reprezentánsok ezen utasítások között is kötelező megadási sorrendeket írhatnak elő. Megjegyezzük továbbá, hogy bár a FORTRAN nyelv definíciója nem zárja ki - a FORMAT utasítások mintájára - a DATA utasítások tetszőleges elhelyezését sem, de ez a legtöbb gépi reprezentációban tiltva van.
A sorrendiségen kívül itt említjük meg a nem végrehajtható utasítások néhány további általános tulajdonságát:
U j1,j2,...,jn
ahol U egy FORTRAN alapszót jelöl, mely megadja az utasítás fajtáját (sokszor elnevezését is), j1,j2,...,jn pedig egy N-elemű lista, amelyben a listaelemeket vesszők választják el egymástól. A lista állhat egyetlenegy listaelemből is. A listaelemek szerkezetét az egyes U alapszavak szabják meg, amint azt az egyes utasítások kapcsán részletesen tárgyalni fogjuk.
INTEGER A,B,C
és az
INTEGER A1,C1,DADA
utasítások egyesítése:
INTEGER A,B,C,A1,C1,DADA
Ezek előrebocsátása után áttérhetünk az egyes nemvégrehajtható utasítások részletes tárgyalására.
4.3. Típus- és tömbdeklarációk
Típusdeklarációk. Az INTEGER, REAL, DOUBLE PRECISION,és LOGICAL utasítás
Eddig az értékek és változók típusáról beszéltünk, megemlítve azt is, hogy a tömböknek, sőt a függvényértékeknek is van típusa. Ez azt jelenti, hogy ha egy szegmens belsejében található azonosító valamilyen változót, tömböt vagy függvényt jelöl, akkor egyben kifejezi az általa képviselt mennyiség típusát is; pl. I önmagában lehet az egész típusú változó azonosítója, az IABS azonosító egész típusú standard függvény azonosítója, stb.
Ismerjük a FORTRAN nyelv automatikus típusdeklarációs szabályát (ld. Második fejezet 3. pontját), mely szerint az I, J K, L, M és N betűvel kezdődő azonosítók egész típusú mennyiségeket jelölnek, a többi betűvel kezdődőek pedig valós típusúakat, hacsak ezzel ellentétes információt nem tartalmaz a szegmens. E szabály biztosítja INTEGER és REAL típusú mennyiségek típusának automatikus meghatározását. Sokszor előnyön lehet azonban, ha egy bizonyos azonosító típusát e szabálytól eltérő módon is előírhatjuk. DOUBLE PRECISION és LOGICAL típusú mennyiségekkel pedig amúgy is csak akkor tudunk számolni, ha előzőleg deklaráljuk őket. A típusdeklaráló utasítások segítségével mindez keresztülvihető. Az utasítás alakja
TÍPUS v1, v2, ..., vn
ahol TÍPUS helyén a következő alapszavak valamelyike áll:
INTEGER
INTEGER*1
INTEGER*2
INTEGER*4
REAL
REAL*4
REAL*8
DOUBLE PRECISION
LOGICAL
LOGICAL*1
LOGICAL*2
LOGICAL*4
BYTE
A Microsoft által bevezetett nem szabványos típusmegnevezések a tárban elfoglalt byte-okra utalnak, és többük ugyanazt a típust / foglalási egységet jelenti:
1 byte-os egész / logikai:
BYTE
INTEGER*1
LOGICAL2 byte-os egész:
INTEGER
INTEGER*2
LOGICAL*24 byte-os egész:
INTEGER*4
LOGICAL*44 byte-os valós szám:
REAL
REAL*48 byte-os valós szám:
DOUBLE PRECISION
REAL*8
Az v listaelemek pedig azon mennyiségek azonosítói, melyek típusát elő akartuk írni: változóké, tömböké vagy függvényeké, vagy pedig esetleg tömbdeklarátorok (lásd következő alpont). A deklaráció a lista minden elemére vonatkozik, függetlenül attól, hogy ez esetleg ellentmond-e az automatikus típusdeklarációs szabálynak.
A deklarációk tehát a listaelemekre vonatkozóan az automatikus típusdeklarációs szabályt hatályon kívül helyezik.
A típusdeklarációk általában a szegmens deklarációs részének elején helyezkednek el. Példák:
INTEGER A,A1,F2,M,Q7
DOUBLER PRECISION W,DW,Q
LOGICAL F1,F3,C9
REAL M1,M2,M3
Ügyeljünk arra, hogy ugyanaz az azonosító egyetlen szegmensen belül nem szerepelhet több típusdeklaráló utasításban.
Tömbdeklarációk. A DIMENSION utasítás
A Harmadik fejezet 4. pontjában foglalkoztunk az indexes változók használatával és megállapítottuk, hogy
Bár, mint a következő alpontban látni fogjuk, tömbök deklarációja más utasításokkal is elvégezhető, speciálisan tömbök deklarálására való a DIMENSION utasítás:
DIMENSION u1,u2,...,un
Például a
DIMENSION A(8), B(12,3,4), C(5,5)
utasítás három tömböt deklarál: az A nyolcelemű vektort; a B háromdimenziós tömböt, melynek indexei rendre maximálisan a 12, 3 és 4 értékeket vehetik fel; végül a C 5x5-ös mátrixot.
Ez a felírásmód (mely a típusdeklaráló és a DIMENSION utasításon kívül a COMMON utasításban is felléphet) speciális jelentésű: a zárójel tartalma megadja az indexek számát, valamint azt is, hogy az egyes indexek értéke + 1-től kezdve milyen maximális értéket vehet fel, azaz megadja a tömb méreteit. Az így felírt zárójeles szerkezeteket, mint pl. A(8) vagy B(12,3,4), tömbdeklarátoroknak nevezzük. (Ha a tömb egy szegmensből álló programban van deklarálva, a tömbdeklarátorban szereplő maximális indexek csakis pozitív egész számok lehetnek. (Az Ötödik fejezet 4. pontjában látni fogjuk, hogy mikor használható egész szám helyett egész típusú változó azonosítója.)
További példák:
DIMENSION ITER(12,3),LOG(25,4)
DIMENSION LA(4,2500),B(2,2,2)
A típus- és tömbdeklarációk kölcsönhatása
Tekintsük a következő programrészletet:
INTEGER F, F1, F2, U
REAL M1, M2, IZA, GOOL
DIMENSION F(15), U(7,2), IZA(8,6), B(12)
Az előző alpontok szerint könnyen értelmezhető e részlet: bizonyos azonosítók típusát az első két utasítás adja meg; a GOOL azonosító felsorolása a középső utasításban felesleges (mivel az automatikus típusdeklarációval összhangban van), de nem hibás; a harmadik, a DIMENSION utasításban olyan tömbök is deklarálva vannak, amelyeknek a típusát az előző utasítások adják meg.
A fejezet első alpontjában megemlítettük azt, hogy típusdeklaráló utasításban is előfordulhat tömbdeklarátor. Ennek segítségével a bemutatott programrészlet a következő egyenértékű formában is felírható:
INTEGER F(15),F1,F2,U(7,2)
REAL M1,M2,IZA(8,6),GOOL,B(12)
A FORTRAN nyelvben tehát tömbök deklarálására nem csak egy lehetőség van. Bemutatunk még néhány példát:
INTEGER ELEMEK (12,4), B, INONE
DIMENSION B(2), D(13,6)
LOGICAL F1, F2, F3, FG(12,12), CIO
DIMENSION CIO(13), FLUX(25,10,18)
DOUBLE PRECISION MATR(15,15), W, K
A részletek elemzését az olvasóra bízzuk.
Felhívjuk a figyelmet arra, hogy a tömbméreteket a COMMON utasítás (lásd az Ötödik fejezet 5. pontját) segítségével is meg lehet adni. Azonban mindenképpen be kell tartani a kivetkező szabályokat:
Szorítkozzunk tárgyalásunkban arra az esetre, amikor egy-egy ekvivalencia-csoporton belül az egyes elemek típusa azonos, például REAL. Ebben az esetben majdnem mindegy, hogy egy bizonyos végrehajtható utasításba a csoport melyik elemét írom be. Ha egy szegmens elején fel volt írva az EQUIVALENCE (A,B), (D(1),E(3)), (Q,P(11,2)) utasítás , a szegmens következő részletei ugyanarra az eredményre vezetnek:
DET = D(1)-A
IF(DET) 1,2,3
1 C = ABS(E(3))
2 C = C+Q
3 CONTINUE
...
DET = E(3)-A
IF(DET) 1,2,3
1 C = ABS(D(1))
2 C = C+P(11,2)
3 CONTINUE
...
DET = E(3)-B
IF(DET) 1,2,3
1 C = ABS(E(3))
2 C = C+Q
3 CONTINUE
A számítás időszükséglete természetesen nem azonos, hiszen indexes változókkal mindig lassúbb a számolás.
Az EQUIVALENCE (C(2),F(5)), (C(6),G(6),H(1,7)) utasítás ekvivalencia-csoportjaiban tömbelemek vannak. Ebben az esetben az EQUIVALENCE utasítás különösen érdekes tulajdonságokat mutat. Mint láttuk, a tömbelemek meghatározott sorrendben helyezkednek el a memóriában. Ez fennáll például az utasítás első ekvivalencia-csoportjában előfordult C és F tömbökre is. De ha C(2) és F(5) azonos címen helyezkedik el, akkor ennek alapján azonos címeken kell elhelyezkednie a C(1), F(4), a C(3), F(6), a C(4), F(7) stb. elempároknak is. Ebből következik, hogy ha tömbelemek szerepelnek ekvivalencia-csoportban, akkor az ilyen csoport ekvivalenciába hoz további elemeket is a tömbelemek címe szerint.
A példában szereplő tömbök deklarátorai, melyek tehát a maximális indexeket tartalmazzák, C(8), F(10), G(10) és H(2,9). Az első ekvivalencia-csoport hatását az alábbi ábrán láthatjuk:
Tehát a (C(1), F(4)) elempártól a (C(7), F(10)) párig teljes a megfeleltetés. Sőt, ilyen esetben van értelme az F(11) elemről is beszélni: az ekvivalencia-csoport hatására az F tömb "megnyúlt". A FORTRAN nyelv megengedi az EQUIVALENCE utasítás hatására megnyúlt tömbök ilyen pótlólagos elemeivel való számolást is. Ugyanakkor tilos egy tömb két különböző elemét ekvivalenciába hozni!
Az utasítás második ekvivalencia-csoportjának hatása:
Most a H tömb hatására "nyúlik meg" a C és a G tömb.
Végül vegyük észre, hogy a most részletesen taglalt két ekvivalencia-csoport mindegyikében szerepelt a C tömb. De ha a C tömbnek megvan a helye a memóriában, akkor hozzá viszonyítva az F, G és H tömbök is megszabott helyre kerülnek. Tehát pl. F és H elemei közt is létrejön bizonyos megfelelés. Ezért beszélhetünk a két ekvivalencia-csoport együttes hatásáról, melyet a következő ábrán szemléltetünk.
Ha a két utasítás
EQUIVALENCE (A,B), (D(1),E(3)), (Q,P(11,2))
EQUIVALENCE (C(2),F(5)), (C(6),G(6),H(1,7))
összes ekvivalencia-csoportjának hatását összességében vizsgáljuk, a következőket vehetjük észre.
Példa bonyolultabb, logikailag nem különböző ekvivalencia-csoportokra, ha a megfelelő tömbdeklarátorok R(2,3), S(2,7). T(14), U(13) és V(4,2):
EQUIVALENCE(R(2,3),T(4)), (U(13),V(1,2)),
1(T(12),S(2,3),U(2))
Ezek együttes hatása:
Az ábrázolás megkönnyítése céljából, most elhagytuk a tömbök "megnyúlásának" szemléltetését.
A továbbiakban az így összekapcsolódó csoportokat együtt báziscsoportnak nevezzük. Minden báziscsoportban van legalább egy olyan tömb, amely a báziscsoport hatására a "leghosszabb" lesz: az ábrán ez a memóriában először kezdődő, ezért az ábrán balra kinyúló R tömb. Az ilyen tömb azonosítóját bázisazonosítónak nevezzük, mivel a báziscsoport többi elemének a memóriában való elhelyezkedését e tömb kezdetéhez viszonyítjuk. A többi elem ettől mindig jobbra esik.
Eddigi megállapításaink alapján kimondhatjuk, hogy:
Sőt, most már megadhatjuk az ekvivalencia-csoportok felírására vonatkozó egyetlen szintaktikus szabályt:
Példák ellentmondásos ekvivalencia-csoportokra: Önmaguknak ellentmondó ekvivalencia-csoportok:
(A(10),B(5),A(3)), (X(5),X(7))
hiszen egy tömb két eleme - mint itt A (10) és A (3) - nem kerülhet ugyanabba a memóriarekeszbe. Egymásnak ellentmondó ekvivalencia-csoportok:
(A(10),B(5)) és (A(13),B(10))
(X(5),Y(8,6)) és (X(3),Y(9,6))
hiszen pl. első ekvivalencia-csoportjából az következik, hogy A (13) a B(8) elemmel kerül azonos rekeszbe, nem pedig B(10)-zel, amit a második ekvivalencia-csoport ír elő.
(V(1,1),S(2,3)), (R(1,3),V(2,1))
Ezek az ekvivalencia-csoportok az előzőleg felírt ekvivalenciák összességének mondanak ellent.
Láthatjuk, hogy az EQUIVALENCE utasítás segítségével annyira ellenőrizhetjük programunk memóriakezelését, amennyire csak óhajtjuk. De, hogy munkánk még egyszerűbb legyen, a következő könnyítést is megengedik a FORTRAN nyelv szabályai:
Például a
EQUIVALENCE(R(2,3),T(4)), (U(13),V(1,2)),
1(T(12),S(2,3),U(2))
utasítással a következő utasítás is egyenértékű:
EQUIVALENCE (R(6),T(4)), (U(13),V(5)),
1(T(12),S(6),U(2))
Jelen pontban meg kell még emlékeznünk az olyan ekvivalencia-csoportokról is, melyek egy memóriarekeszhez különféle típusú mennyiségeket rendelnek. A FORTRAN nyelv szabályai kimondják, hogy ilyen esetben is csak egyféle típusú érték lehet a memóriarekeszben, és csak az ennek megfelelő típusú változóknak, tömbelemeknek van értéke. Az ilyenfajta ekvivalencia kizárólag arra használható, hogy a szegmens egyik részében ugyanezt a memóriarekeszt más részeredmények tárolására tudjuk felhasználni, mint a szegmens másik részében.
Változók és COMMON blokk egymáshoz rendelhetők. Pl.:
COMMON /X/A,B,C
EQUIVALENCE (A,D)
Ebben az esetben az A és D változók osztoznak az X blokk első tárolóegységében.
4.5. Kezdőérték adás. A DATA utasítás
Programjainkban előfordulhatnak olyan számadatok, matematikai állandók, melyekkel sokat dolgozik a program és várható, hogy bármikor is kívánjuk a programot felhasználni, értékük nem fog megváltozni. Ilyen számadat lehet például a PI, vagy az e szám stb.
A FORTRAN nyelvnek külön utasítása van arra, hogy bizonyos változóknak ilyen célból értéket adjon. Ennek a segítségével például a Pl változónak adhatom a 3.141592653589793238 számértéket, mint kezdőértéket, és a továbbiakban a képletekben előforduló Pl változó ezt a számértéket fogja jelenteni. Az utasítás alakja:
DATA l1,l2,..., ln
ahol az listaelemek speciális szerkezetű kettős listák; egy ilyen lk listaelem alakja a következő:
t1,t2,...,rk/d1,d2,...,dk/
Az r és d listaelemek száma egyenlő és kölcsönösen megfelelnek egymásnak. Az r listaelemek indexes vagy index nélküli változók, a két ferde vonal közé zárt d listaelemek pedig, a nekik rendre megfelelő kezdőértékek. Például:
DATA KETTO, NEGY, PI/2,4,3.14159/,
1FEL, OTOD, HATOD/0.5,0.2,0.16666667/
Az utasítás hatására a 2 kezdőértéket kapja a KETTO INTEGER típusú változó, a 4 kezdőértéket kapja a NEGY változó, stb., végül az 1/6 kezdőértéket kapja a HATOD REAL típusú változó (ha a változók típusát az automatikus típusdeklarációs szabály szabja meg).
A "kezdőérték" kifejezés itt azt jelenti, hogy a program lefordítása után mindaddig, míg a program értéküket meg nem változtatja, a változók értéke a megfelelő kezdőérték lesz; illetve a változónak megfelelő memóriarekeszben a kívánt érték található. (Olyan számológépek esetén, amelyekbe a célprogramokat futtatás előtt "betöltik" vagy "betáplálják" a memóriába, jogosabb lenne talán a betöltési érték kifejezés használata.) Maga a DATA utasítás azonban nem zárja ki azt, hogy a programban később pl. egy értékadó utasítással a kezdőértékkel rendelkező változó értékét megváltoztassuk.
Mint a példa utasítás is mutatja, a ferde vonalak közt felsorolt konstansok típusa megegyezik a megfelelő változók típusával. Ezenkívül megadhatunk szövegkonstanst is (lásd a következő alpontot).
Szabad ugyanazt a kezdőértéket több változónak is adni, például:
DATA A(1),A(2),B,BB/4.5, 2.5, 2.5, 2.5/
A FORTRAN nyelv megengedi, hogy ezt az utasítást a következő egyszerűsített jelöléssel írhassuk fel:
DATA A(1),A(2),B,BB/4.5, 3*2.5/
azaz szabad a konstansok listájában ismétlési tényezőket alkalmazni.
Másik példa:
DIMENSION C(7)
DATA A, B, C(1), C(3) / 14.73, -8.1, 2*7.5/
A következő változók kapnak értéket:
A=14.73, B=-8.1, C(l)=7.5, C(3)=7.5
Ügyelni kell arra, hogy a DATA utasítások ne mondjanak ellent EQUIVALENCE utasításoknak! Egy memóriarekeszben csak egyetlen kezdőérték tárolható, de viszont az ekvivalencia-utasítás két vagy több változóhoz ugyanazt a memóriarekeszt rendelheti. E változók közül csak egynek adhatunk kezdőértékei, ami egyben az összes ugyanilyen típusú ekvivalenciába hozott változónak is közös kezdőértéke lesz. Elemezzünk néhány deklarációs részt ebből a szempontból!
Tekintsük a következő deklarációs részt:
LOGICAL L(5), L1(10)
INTEGER IA(15), IB(15)
REAL A(15), B(15)
EQUIVALENCE (L(1), IA(1), A(1)),
1(L1(1),IA(6)), (IB(1), B(1))
DATA L(1),L(2),IA(3),IA(4),A(5),A(6)/.TRUE.,
1.FALSE.,1,2,3.0,4.0/
Itt 2-2 logikai, egész és valós tömb deklarációját látjuk. A felírt három ekvivalencia-csoport két báziscsoportot definiál: az első báziscsoportba tartozik az A, IA, L és L1 tömb. Közülük csak az L tömb "nyúlik meg". A második báziscsoportba az egymással ekvivalens, de különféle típusú B és IB tömbök tartoznak.
Az első báziscsoport első hat memóriarekeszébe egy DATA utasítás kezdőértékeket tesz. Az utasítás formailag helyes, hiszen a változók és a konstansok típusa egymásnak megfelel. Látunk itt példát logikai kezdőérték adásra is. De a DATA utasítás nincs ellentmondásban az EQUIVALENCE utasítással sem, hiszen egy rekeszbe csak egy kezdőérték kerül. Például az L(1), IA(1) és A(1) indexes változók közül a LOGICAL típusú L(1) tömbelemnek van TRUE kezdőértéke. Amíg a program futása során IA(1) vagy A(1) értéket nem kap, a logikai tömbelemnek lesz értéke és az aritmetikaiaknak nem lesz. Például, ha végrehajtásra kerül az
IA(1)=10
utasítás, akkor L(1) értéke ezzel egy időben elvész és egy egész értéket fog a memóriarekesz őrizni. Ha más egész típusú változó is ekvivalens lenne IA(1)-gyel, az is megkapná most a 10 értéket. Az A(1) valós típusú változónak természetesen még most sincs értéke.
Másik példa:
LOGICAL FI(10)
INTEGER IA(15), IB(15)
REAL A(10), AA(15), B(20), BB(15)
EQUIVALENCE (FI(2),IA(1),A(1),AA(1)),
1(AA(15),B(5)), (B(6),BB(1),IB(1))
DATA FI(7),FI(8),FI(9),FI(10),IA(5),IA(6),
1A(11),A(12)/4*.TRUE.,2*1,2*1.0/
Látható, hogy ismétlési tényezőket bármilyen típusú konstans előtt használhatunk. Most egyetlen báziscsoport van megadva három ekvivalencia-csoport segítségével, melyek nem tartalmaznak felesleges információt; a bázisazonosító a FI logikai Tömbazonosító. A DATA utasításban hiba van: FI(7)-nek és IA(6)-nak nem lehet egyszerre kezdőértéket adni, hiszen hozzájuk azonos memóriarekesz tartozik!
Az EQUIVALENCE és DATA utasításokkal kapcsolatos további szabályokkal a COMMON utasítással kapcsolatban fogunk megismerkedni (lásd Ötödik fejezet 5. és 6. pontot).
Szövegkonstansok
Eddig találkoztunk különféle típusú számkonstansokkal, s a két logikai konstanssal (.TRUE. és .FALSE.). De a számítások során felmerülhet annak a szükségessége is, hogy a program betűkből vagy számokból - azaz karakterekből - szövegeket állítson össze, ilyen szövegeket a számítási eredmények között kiírjon, vagy az adatok egyeztetése és kezelése kedvéért velük együtt szövegeket beolvasson. Ezeket a szövegeket szokás string-eknek is nevezni, bár a FORTRAN nyelvben a Hollerith konstans elnevezés a szokásos.
A szövegek tárolásához a FORTRAN nyelvben nem kell különleges, pl. szöveg-típusú változó, hanem bármiféle eddig tárgyalt típusú változó felhasználható erre a célra. Hogy a memória kihasználás gazdaságosabb legyen, az egyes gépi reprezentációkban egy változó több karaktert tárolhat. Ezt lehelővé teszi, hogy a gépi jelkészlet ábrázolására a számológépek 6-8 db kettes számrendszerbeli számjegyet - ún. bitet - használnak, míg egy változó ábrázolására szolgáló memóriarekesz 24, 36 vagy 48 bitből állhat. Egy karakter tárolásához egy byte szükséges. Ezek szerint 4, 6 vagy 8 karaktert tartalmazhat a változó. Az egy változóban tárolható karakterek számát a továbbiakban g-vel jelöljük és elemszélességnek. A karaktereket balról jobbra számozzuk. Ilyenkor azt mondjuk, hogy a változónak karakter típusú értéke van. Az egyes gépi reprezentációkban az ASA FORTRAN-ban nem szabályozott módon értelmezhető a változó "tartalma", mint karaktersozat. Az értelmezés szabályait, illetve a karaktereket a megfelelő számítógép karakter- és számábrázolási szabályai szabják meg. FORTRAN-80-ban legfeljebb 8 karraktert tárolhat a DOUBLE PRECISION, legfeljebb 4 karaktert a REAL vagy INTEGER*4 típusú változó, legfeljebb 2 karaktert az INTEGER*2 és egy karaktert a LOGICAL típusú.
Felmerül a kérdés, hogyan vehet fel egy változó karakter típusú értéket. Ennek egyik módja az, hogy DATA utasításban a változónak karakter típusú kezdőértéket adunk. Erre is használhatók a FORTRAN nyelv szövegkonstansai. Alakjuk:
nHh1,h2,..,hn
ahol
Például:
8HFORTFILE
12HPISZKOS FRED
11HHOVANSCSINA
22HA FAJHO 1-ES TABLAZATA
Tegyük fel, hogy g értéke pl. 8 (mint FORTRAN-80-ban DOUBLE PRECISION típus esetén). Értelmezzük akkor a következő DATA utasítást:
DATA A(8),A(6),A(4),A(1)/8HFORTFlLE,
112HPISZKOS FRED,11HHOVANSCSINA,
222HA FAJHO 1-ES TABLAZATA/
Először A(8) felveszi a FORTFILE szöveg értéket. Ezután A(6)-ba bekerül a "PISZKOS " szövegrész (szóközzel a végén), de a FRED szővén az A(7) tömbelembe csúszik át és 4 db szóközzel egészítődik ki: A(7) tartalma: "FRED ". Hasonlóképpen alakul ki az A tömb többi elemének tartalma is:
A(4) = "HOVANSCS"
A(5) = "INA " (5 db szóköz)
A(1) = "A FAJHO "
A(2) = "1-es TAB"
A(3) = "LAZATA " (2 db szóköz)
Látjuk tehát, hogy bár csak 4 db indexes változó szerepel, az utasításban, 8 db kapott szöveg típusú kezdőértéket, mivel egyes szövegek hossza meghaladta a g = 8 értéket. Ami az egyes változókból, mint szabad hely kimaradt volna, oda a szükséges számban betűköz karakterek kerültek.
Bár a szabványos ASA FORTRAN nyelv ezt a kérdést nem szabályozza, sok gépi reprezentációban külön eljárásokat dolgoztak ki arra, hogy a változók belsejéből tetszőleges sorszámú karaktert ki tudjanak emelni, a karaktereket átcsoportosítsák stb. Ezek a karaktermanipulációk például az ICT FORTRAN-ban jól ki vannak fejlesztve, Fortran-80-ban viszont nincsenek. Ebben a könyvben a szövegkonstansokkal a továbbiakban a CALL utasítás (lásd az Ötödik fejezet 3. pontját) és az INPUT-OUTPUT utasítások (lásd a 6. fejezetet) kapcsán fogunk még találkozni.
Végül egy gyakorlati tanács: programjaink írásakor ügyeljünk arra, hogy lehetőleg ne nyúljon át szövegkonstans a következő sorba: inkább adjunk meg több rövidebb szövegkonstanst. Egyes gépi reprezentációkban ugyanis a folytatósorokba való áttérés kérdése nincs ilyen esetben tökéletesen megoldva!
DATA utasításban a szövegkonstansok más típusú konstansokkal tetszőlegesen keverhetők. Továbbá, ha egy változó szövegkonstans értéket kapott, az összes vele ekvivalenciába hozott bármilyen típusú változó is ugyanazt a szövegkonstanst veszi fel értékül.
4.6. Automatikus típusdeklarálás. Az IMPLICIT utasítás.
Mint a 2.3. pontban már említettük, a nyelv sajátossága, hogy nem kötelező minden változót deklarációs utasításban deklarálni. Ha a végrehajtható utasításokban olyan változónév fordul elő, amit nem deklaráltunk, akkor a fordítóprogram az automatikus típusdeklarálás szabályának megfelelően ad a bevezetendő változónak típust. Az így deklarált változó típusa a név első betűjéből állapítható meg, alapértelmezés szerint: az I,J,K,L,M,N betűkkel kezdődő azonosító egész típusú, a többi pedig valós típusú lesz. Ettől a szabálytól az IMPLICIT utasítással térhetünk el:
IMPLICIT T1(tartomány) ,T2(tartomány) ,...,Tn(tartomány)
Ahol T tetszőleges típus (INTEGER, REAL, LOGICAL, DOUBLE PRECISION, BYTE, INTEGER*1, INTEGER*2, INTEGER*4, REAL*4, REAL*8), a tartomány pedig az alfabetikus karakterek listája, vesszővel vagy kötőjellel elválasztva.
Példa:
IMPLICIT INTEGER(A,W-Z), REAL(B-V)
utasítás hatására minden A, W, X, Y, Z betűvel kezdődő - másképpen nem deklarált - változó INTEGER típusú lesz. Minden B-V betűkkel kezdődő változó pedig REAL típusú lesz. Ez az alapértelmezett definíciónak a
IMPLICIT INTEGER(I-N),REAL(A-H,O-Z)
Az IMPLICIT utasításoknak blokkonként minden más specifikációs utasítás előtt kell megjelenniük. Ha az IMPLICIT utasítás mégis bármely típus vagy tömbdeklarációs utasítás után szerepel, a már deklarált változók típusai nem módusulnak.
4.7. Utasításfüggvények
Tegyük fel, hogy szegmensünkben több helyen van szükség arra, hogy kiszámítsuk a
CH(X) = 1.0+X**2*(0.5+X**2*(1.0/24.0+x**2/720.0))
függvényt. Például szeretnénk leírni a következő utasításokat:
A = CH(B)
W = A**2
C(13) = CH(F-5.0)+CH(F+5.0)
C(14) = A-C(13)
azt akarjuk, hogy az utasításokban CH a megfelelő függvényt jelentse ugyanúgy, ahogy a COS azonosító standard külső függvényt azonosít. A FORTRAN-ban erre valók az ún. utasításfüggvények. Például, ha a deklarációs rész végére felírjuk a CH(X) = 1.0+X**2*(0.5+X**2*(1.0/24.0+x**2/720.0)) utasítást, a szegmens belsejében a kívánt jelentést érhetjük el. Az egyenlőségjel bal oldalán szerepel a CH utasításfüggvény azonosító, melyet zárójelbe zárva követ a független változó. Ez itt "csak" formális paraméter, hiszen a programrészletben változó azonosító vagy kifejezés helyettesíti, melyeket aktuális paraméternek nevezünk. A formális és aktuális paraméterek fogalmával az Ötödik fejezetben részletesen foglalkozunk.
A FORTRAN nyelvben az utasításfüggvényeket a deklarációs rész végén lehet
f(a1, a2, ..., an)=e
alakú utasításokkal megadni, ahol f az utasításfüggvény azonosítója az a-k az ún. formális paraméterek, melyeknek száma legalább egy. A formális paraméterek tetszőleges nem indexes változó azonosítók lehetnek. Szerepük kettős: 1. megadják a paraméterek típusát és sorrendjét; 2. szerepelhetnek az e kifejezésben. Az e kifejezés és az f utasításfüggvény típusa olyan kell, hogy legyen, ami megfelel az
f = e
értékadó utasítás végrehajthatósági feltételeinek. Az e kifejezésben szerepelhet nem szövegtípusú konstans, belső és külső standard függvény azonosítója, sőt előzőleg definiált utasításfüggvény azonosítója is más függvényeljárások (lásd az Ötödik fejezet 3. pontját) azonosítóival együtt, továbbá a szegmens minden olyan indexes és index nélküli változója, melynek azonosítóját nem használtuk formális paraméter azonosításra.
Az utasításfüggvényeket ugyanúgy használhatjuk a szegmensben, mint a belső standard függvényeket. Az aktuális paraméterek típusának pedig meg kell egyezniük a megfelelő formális paraméterek típusával.
Példák:
A háromszög területét az oldalak függvényében például a kivetkező utasításfüggvényekkel is definiálni lehet:
S(X1,X2,X3) = (X1+X2+X3)/2.0
TER(X1,X2,X3) = SQRT(S(X1,X2,X3)*(S(X1,X2,X3)-
1X1)*(S(X1,X2,X3)-X2)*(S(X1,X2,X3)-X3))
Bevezethetünk saját célra logikai utasításfüggvényeket is:
LOGICAL EQI,L1,L2
EQI(L1,L2)=(L1.AND.L2).OR.(.NOT.L1.AND..NOT.L2)
Egy példa arra, hogy különböző típusú argumentumokat is lehet használni:
DOUBLE PRECISION DBL,Y
DBL(Y,N) = (Y**N + Y**(-N))/A(2)
5. Több szegmensből álló FORTRAN programok
5.1. Bevezetés
Könyvünk előző fejezeteiből merített ismereteink alapján most már képesek vagyunk - a ki- és bevitel műveleteitől eltekintve - mindazt FORTRAN-ban leírni, ami e nyelvben egyáltalán leírható. Úgy tűnik tehát, hogy nincs más hátra, mint a ki- és bevitel elsajátítása, és aztán bátran nekivághatunk akármilyen bonyolult programok megírásának.
Elvileg ez így is van, ha azonban megkísérelnénk egy valamennyire is összetett feladatot úgy beprogramozni, hogy nem bontanánk szét kisebb részfeladatokra, akkor hamarosan szemben találnánk magunkat több előre nem látott nehézséggel.
Először is, egy ilyen egyetlen részből álló mamut-program nehezen áttekinthető, működését nem lehet nyomon követni, ezért funkcionális ellenőrzése ("belövése") igen hosszadalmas. Tekintve, hogy az idő pénz (főként, ha gépidőről van szó), ez önmagában is nyomós érv amellett, hogy a nagy programokat mindig célszerű valahogyan feldarabolni.
Egy másik szempont, hogy a legtöbb gyakorlati programozási feladat visszavezethető a numerikus analízis valamelyik alapfeladatára (differenciálegyenlet megoldása, mátrixalgebra és aritmetika, transzcendens egyenlet megoldása stb.), vagy ilyen alapfeladatok kombinációjára. Mivel szinte minden számolóközpontban találhatók ezeknek az alapfeladatoknak a megoldására irodalmilag feldolgozott és számtalan változatban beprogramozott eljárások, semmiképpen sem volna gazdaságos ezek megírását minden esetben újra kezdeni. A megoldás kézenfekvő: a kész eljárásokat át kell venni és "előregyártott elem"-ként beépíteni a készülő programba. Ezzel mind a program megírásakor, mind a kipróbáláskor időt takaríthatunk meg, feltéve, hogy a beépített eljárás már előzőleg alaposan ellenőrizve volt.
Ezzel kapcsolatban azonban jelentkezik egy nehézség is. Tegyük fel, hogy előttünk valaki megírt egy FORTRAN programot, amely négyzetes mátrixok invertálására alkalmas, még pedig 25x25-ös mátrixokra készítette és a mátrixot A-val, az inverzet AINV-vel jelölte. Nekünk ez a program tulajdonképpen megfelelne, de feladatunkban a mátrix rendszáma nem 25, hanem 20, neve nem A, hanem X, az inverz azonosítója pedig nem AINV, hanem Y. Hogyan tudjuk ezt a programot a mi feladatunkra adaptálni?
Elvileg igen egyszerűen: nem kell egyebet tennünk, mint átjelölnünk az egészet A-ról X-re, AINV-ről Y-ra és 25-ről 20-ra. Tegyük fel, hogy három hibát vétettünk, az átíráskor; ebből kettő kiderült az összeolvasás során, a harmadik "átcsúszott". Majd elkészül az egész program és egy próbafeladatot hibásan végez el. Mit lehet tenni: az invertáló program működését nem ismerjük pontosan, ezért felkeressük a szerzőt, aki a program írása óta eltelt két év alatt réges-régen elfelejtette az egész eljárás logikáját, de azért néhánynapos fejtörés (és esetleg néhány gépi próba) után megmutatja azt az egyetlen változót, amelyet egyetlen helyen mégiscsak elmulasztottunk átjelölni.
Ez az út nyílván nem járható. Különböző helyeken és időben készült programrészeknek egyetlen programmá való egyesítése csak akkor lehet megfelelő hatásfokú, ha az egyes részleteknek saját hatáskörükön belül önálló jelölésrendszerük van, és ezt nem kell az összeépítés közben kézileg átalakítani. Példánkból láthatóan az ilyen előregyártott programok hajlékonyságához az is szükséges, hogy bizonyos paramétereket, mint pl. a mátrix rendszáma, változóként lehessen megadni.
A fentebb felsorolt programozási és programozói igényeket kívánja kielégíteni a FORTRAN nyelvben a programok szegmentálásának lehetősége. Ennek a lehetőségnek főbb jellemzői a következők:
A FORTRAN-ban kétféle - a fenti jellemzőknek megfelelő - típusú szegmens létezik:
E fejezet további pontjaiban a programszegmentálás kérdéseit ismertetjük. A következő 2. pont a szegmentált programok formai felépítésével foglalkozik. Ezt követőleg a 3. pontban a programszegmensek említett "átjelölési" funkcióit (paraméterátvétel, paramétercsere) tárgyaljuk, majd a deklaráló utasítások használatát érintő olyan szabályokat ismertetünk, amelyeknek csak több szegmensből álló programok esetén van jelentőségük (4-6. pontok). A 7. pontban egy újabb deklaráló utasítást (EXTERNAL) ismerünk meg, amelyet ugyancsak szegmentált programokban használunk.
5.2. Szegmensnyitó és -záró utasítások. Szegmentált programok szerkezete
Egy teljes FORTRAN program egy vagy több programszegmensből állhat. Minden egyes szegmens szegmensnyitó utasítással kezdődik, és szegmenszáró utasítással végződik. A szegmensnyitó utasítások az ASA FORTRAN-ban a
SUBROUTINE
és a
FUNCTION
utasítások. (Van egy harmadik, speciális szegmensnyitó utasítás is, a BLOCK DATA, ezzel a 6. pontban foglalkozunk.) A szegmenszáró utasítás az
END
utasítás. Az END utasítás nem folytatható folytatósorban.
A SUBROUTINE és a FUNCTION utasítások szintaxisát egyelőre nem részletezve, egy több szegmensből álló program szerkezete a következő:
SUBROUTINE S1
...
END
SUBROUTINE S2
...
END
SUBROUTINE S3
...
END
Itt S1, S2, S3 az egyes szegmensek maximum 6 karakterből álló azonosítói. Mindegyik szegmens a SUBROUTINE utasítástól az END utasításig teljed. Példánk egy három szegmensből álló programot mutat. Ebben bármelyik SUBROUTINE utasítás helyett állhat FUNCTION (vagy BLOCK DATA, lásd később) utasítás is.
Mint már említettük és a példában láttuk, minden egyes szegmens egy szegmensnyitó utasítással kezdődik. Ezt a szegmens deklarációs része követi az utasításfüggvények deklarációival együtt (ha ilyen van), és végül a végrehajtható utasítások. A szegmenst az END utasítás zárja le. Az itt leírt szerkezet mindenfajta szegmensre érvényes, legfeljebb bizonyos összetevők hiányozhatnak.
Gépi reprezentációs nyelvekben definiálni szoktak egy negyedik szegmensnyitó utasítástípust is, amely a program ún. fő szegmensének élén áll. Ennek az utasításnak a neve lehet gépi reprezentációtól függően PROGRAM, MASTER, MAIN stb. (Fortran-80-ban: PROGRAM). A fő szegmens jelentőségére később visszatérünk.
A SUBROUTINE utasítás alakja:
SUBROUTINE S(A1, A2, ..., AN)
vagy
SUBROUTINE S
A kerek zárójelek közé zárt A1, A2, ..., AN lista az ún. formális paraméterek listája. A. listaelemek tetszőleges azonosítók lehetnek. Mint a második változatból látható, a lista lehet üres, amely esetben a kerek zárójelek is hiányoznak. "S" a szubrutin neve (azonosítója); szintén tetszőleges azonosító.
A FUNCTION utasítás alakja:
FUNCTION F(A1, A2, ..., AN)
vagy
t FUNCTION F(A1, A2, ..., AN)
ahol F a szegmens neve (az ilyen szegmenst nem szubrutinnak, hanem függvénynek nevezzük); A1, A2, ...,AN pedig formális paraméterek, akárcsak a SUBROUTINE utasításban. F és az A paraméterek tetszőleges azonosítók lehetnek. A második alakban t a típusdeklaráló INTEGER, REAL, DOUBLE PRECISION vagy LOGICAL alapszavak valamelyike. Ez a típusdeklaráló alapszó hiányozhat a szegmensnyitó utasításból. A SUBROUTINE utasítással ellentétben azonban a FUNCTION utasításban nem hiányozhat a formális paraméterek listája! A FUNCTION utasításnak mindig kell hogy legyen legalább egy formális paramétere. Ennek a szabálynak az okát a későbbiekben értjük majd meg.
Példák a szegmensnyitó utasításokra:
SUBROUTINE GYUFA(X, Y, W, Z)
SUBROUTINE NAMIEZ
FUNCTION VAZMI(EZ, AZ)
INTEGER FUNCTION CSORT(I)
Példáink rendre az ismertetett lehetőségek egy-egy illusztrációját adják. Amint az utolsó példából látható, a formális paraméterek listája - bármilyen típusban - lehet egy elemű, amely esetben természetesen az elválasztó vessző elmarad.
Az eddigiekben a FORTRAN programok szerkezetét kizárólag statikusan vizsgáltuk. Az egyes programszegmensek dinamikus kapcsolatára igen sok szabály vonatkozik, amelyeket a következő ponttól kezdve, fokozatosan tekintünk át.
5.3. Szubrutinok és függvények aktivizálása. Aktuális és formális paraméterek
SUBROUTINE szegmensek. A CALL és a RETURN utasítás
Mielőtt a szubrutin szegmensek használatának szabályaira rátérnénk, bemutatunk azokra néhány gyakorlati példát.
1. Példa:
T
együk fel, hogy olyan programot akarunk írni, amelyben többször és különböző helyeken kell bizonyos változókon síkbeli ortogonális transzformációt végezni. (Szemléletesen: a síkbeli derékszögű koordinátarendszert fí szöggel kívánjuk elforgatni és sok pont új koordinátáira van szükségünk.) Mint ismeretes, valamely x és y skaláris változókra alkalmazott síkbeli ortogonális transzformáció a következő képletek alapján hajtható végre:
u = x cos fí + y sin fí
v = -x sin fí+ y cos fí
Olyan FORTRAN programszegmensre lenne tehát szükségünk, amely ezt az átalakítást könnyen, lehetőleg kevés adminisztrációs utasítással végzi el, különböző transzformálandó változókon és különböző elforgatási szögekre. Ilyen FORTRAN szegmens lehet a következő:
SUBROUTINE ORTOG(X,Y,U,V,FI)
U = X*COS(FI) + Y*SIN(FI)
V = -X*SIN(FI) + Y*COS(FI)
RETURN
END
Tegyük fel most, hogy ortogonális transzformációt kívánunk végezni a P és Q programbeli változókon, a szöggel, és a transzformált változókat a programban R-rel és S-sel jelöltük. Hogyan végezhető el ez a transzformáció az eljárás segítségével?
A megoldás: programunkban leírjuk a következő "szubrutinhívó" utasítást:
CALL ORTOG(P,Q,R,S,ALFA)
Ennek hatására az eljárás (szubrutin) aktivizálódik, azaz végrehajtódik a CALL utasításban megadott ún. aktuális paraméterekkel. A szubrutin végrehajtásakor az aktuális paraméterek a formális paraméterek helyére lépnek, vagyis a szubrutin úgy működik, mintha annak minden egyes formális paramétere helyett a megfelelő aktuális paraméter állna. Esetünkben ez azt jelenti, hogy a szubrutin végrehajtásakor X helyébe P, Y helyébe Q, U helyébe R, V helyébe S, és végül FI helyébe ALFA helyettesítődik. A gép tehát a CALL utasítás alapján a következő utasításokkal megegyező hatású műveleteket végez:
R = P*COS (ALFA) + Q*SIN (ALFA)
S = -P*SIN (ALFA) + Q*COS (ALFA)
(a RETURN utasítás jelentésére később visszatérünk).
Előfordulhat, hogy ugyanabban a programban, amelyben az imént az ORTOG eljárást aktivizáltuk, egy másik helyen is szükség van ortogonális transzformációra, azonban ezúttal nem P, Q, R, S és ALFA paraméterekkel, hanem (rendre) A-val, B-vel, C-vel, D-vel és THETA-val. Eljárásunk most is változatlanul alkalmazható, csupán az aktivizáló CALL utasítást kell megváltoztatni:
CALL ORTOG (A,B,C,D,THETA)
Az utasítás hatására a következő FORTRAN utasításokkal egyenértékű műveletek elvégzésére kerül sor:
C = A*COS (THETA) + B*SIN (THETA)
D = -A*SIN(THETA) + B*COS (THETA)
Aktuális paraméterként nemcsak változót, hanem kifejezést is megadhatunk, amennyiben annak típusa megegyezik a megfelelő formális paraméter típusával, és amennyiben ez nem vezet értelmetlenségre. Megengedett például a következő CALL utasítás:
CALL ORTOG (A1**2-A2**2, A1+A2, R, S, BETA)
Az ORTOG szubrutinban U, V és FI, jellegüket tekintve, "kimenő" (azaz eredményt megadó) paraméterek, ezért ezeknek értelemszerűen nem feleltethetünk meg kifejezés-paramétert. Ugyanakkor a két "bemenő" paraméter, X és Y helyett - mint a példában is tettük - írhatunk aritmetikai kifejezést, és ez nyilván azt jelenti, - példánknál maradva - hogy az ORTOG eljárás X = A1**2-A2**2-tel és Y = A1+A2-vel hajtódik végre.
Az előzők alapján nyilvánvaló a paraméterek "formális", ill. "aktuális" jelzője. A szubrutin szegmens sohasem a formális paraméterekkel, hanem mindig a helyükbe lépő aktuális paraméterekkel hajtódik végre. A formális paraméterek a SUBROUTINE szegmens leírásában csak a felhasználandó aktuális paraméterek szimbólumai.
Az eddigiekben nem részleteztük, hogy tulajdonképpen hol, milyen programrészben helyezkednek el a bemutatott CALL utasítások. Az előző pontban szerzett ismereteink alapján látjuk, hogy az ORTOG teljes programszegmens, első utasítása szegmensnyitó utasítás, utolsó utasítása pedig END utasítás. Az őt aktivizáló utasításnak nyilván valamelyik másik szegmensben kell elhelyezkednie. Egy SUBROUTINE szegmenst mindig egy másik szegmensnek kell aktivizálnia. Az aktivizálás eszköze a CALL utasítás. A CALL hatására - ideiglenesen - a vezérlés "átlép" a CALL utáni azonosítóval megjelölt szegmensbe, végrehajtja annak utasításait, majd "dolga végeztével" visszatér az őt aktivizáló szegmensbe, és ez utóbbinak utasításait a CALL-t követő FORTRAN utasítástól kezdve, folytatólag hajtja végre.
Honnan tudja meg a gép, hogy egy adott szegmensben teljesítette a feladatát, és visszatérhet az őt aktivizáló szegmensbe? Ennek a visszatérésnek az engedélyezésére van a RETURN utasítás. A RETURN a szegmens logikai végét jelenti, vagyis azt a pontot jelöli ki, ahol ki lehet lépni a SUBROUTINE szegmensből és vissza lehet térni az aktivizáló szegmensbe. Ilyen pont egy adott szegmensben esetleg több is lehet, és ennek megfelelően egy szegmensben több RETURN utasítás is előfordulhat. Általában minden SUBROUTINE szegmensben kell legalább egy RETURN utasításnak lennie. (Ugyanez érvényes a FUNCTION szegmensekre is.) Minthogy azonban egy szegmensnek csak egy fizikai vége van, tehát bármely szegmensben egy és csak egy END utasítás lehet.
Mivel a SUBROUTINE szegmenseket mindig egy másik szegmens aktivizálja (és ugyanez a helyzet a FUNCTION szegmensekkel is), nyilvánvaló, hogy ennek az aktivizálási folyamatnak valahol el kell indulnia; azaz minden programban kell lennie egy olyan szegmensnek, amelyet nem egy másik szegmens aktivizál, hanem például a gépkezelő, aki a vezérlőpultról elindítja a program végrehajtását. Szabatosabban fogalmazva, minden végrehajtható FORTRAN programban kell lennie egy legelső végrehajtható utasításnak, ahonnan az egész számítási folyamat elindul. Azt a programszegmenst, amely ezt az utasítást tartalmazza, a FORTRAN program fő szegmensének nevezzük. Az ASA FORTRAN nem határozza meg, hogy milyen módon kell ezt a szegmenst megjelölni, és a gépi reprezentációs nyelvek különféle speciális szegmensnyitó utasításokat vezetnek be erre a célra. Ilyenek a már említett PROGRAM, MASTER, MAIN stb. utasítások. A program első végrehajtható utasítása általában a fő szegmens első végrehajtható utasításával egyezik meg, de a gépi reprezentációs nyelvek esetleg ettől eltérően is meghatározhatják a program kezdetét. Minthogy a továbbiakban mindenképpen szükségünk lesz valamilyen megállapodásra a program első végrehajtható utasítására és fő szegmensére nézve, mint ahogyan a Negyedik fejezet 1. pontjában jeleztük, a jövőben a fő szegmens jelölésére a PROGRAM szegmensnyitó utasítást fogjuk használni, és a program kezdetének a PROGRAM szegmens első végrehajtható utasítását tekintjük. Hangsúlyozzuk azonban, hogy ez gépi reprezentációból átcsempészett konvenció.
Eredeti példánkra, az ORTOG szubrutinra, valamint annak különböző aktivizálásaira visszatérve, egy szubrutint használó teljes FORTRAN programnak a következő sematikus szerkezete lehet:
PROGRAM KULACS
...
CALL ORTOG (P,Q,R,S,ALFA)
...
CALL ORTOG(A,B,C,D,THETA)
...
CALL ORTOG(A1**2-A2**2, A1+A2, R, S, BETA)
...
END
SUBROUTINE ORTOG(X,Y,U,V,FI)
...
END
Mint látható, két szegmensből áll a program, egy főprogramból és egy szubrutinból. Ennek természetesen nem kell szükségképpen így lennie; egy MASTER szegmensnek lehet több szubrutinja, és ezek a szubrutinok egymást is aktivizálhatják. Tehát magukban a SUBROUTINE szegmensekben is lehetnek CALL utasítások, amelyek más SUBROUTINE szegmensek aktivizálására szólítanak fel. Mivel a RETURN utasítás végrehajtásakor a vezérlés mindig az aktivizáló szegmensbe tér vissza, ily módon szubrutin hívások tetszőleges hosszúságú láncolata jöhet létre, amelynek kiinduló pontja - és általában végpontja is - a MASTER szegmens. Azért általában, mert egy FORTRAN program végrehajtása megszakadhat egy, a MASTER-től különböző szegmensben is, amennyiben a gép ebben a szegmensben egy STOP utasítást hajt végre. Ez azonban csak kivételes esetekben szokásos, főként akkor, ha a SUBROUTINE szegmens által előírt valamilyen számítási feladat nem végezhető el, és a megállás éppen a feladat elvégezhetetlenségére kívánja felhívni a figyelmet (pl. negatív számból történő valós gyökvonás, szinguláris mátrix invertálása stb.). A tipikus programszervezés olyan, hogy a feladat eredményes befejezését nyugtázó STOP utasítás a MASTER szegmensben van elhelyezve.
2. példa:
Legyen a feladat SUBROUTINE szegmens írása másodfokú algebrai egyenlet általános megoldására, figyelembe véve az elfajult esetek, valamint a komplex gyökök lehetőségét is. Jelölje a megoldandó másodfokú egyenletet
ax^2 + bx + c =0
ahol az a, b és c együtthatók tetszőleges valós számok lehetnek. Az a = b=0 eset teljesen elfajult, ekkor az egyenlet megoldhatatlan. Ebben az esetben hajtsunk végre egy STOP utasítást! Az a = 0, de b<>0 esetben az egyenlet lineárissá fajul; ekkor a két gyököt tekintsük megegyezőnek, és ezek x1 = x2 = c/b-vel egyenlők. Végül, ha a<>0, akkor válasszuk szét a valós és komplex gyökök esetét.
Eljárásunk formális paraméterei a következők: jelölje A, B és C az együtthatókat, X1R, X1I, X2R és X2I pedig rendre az x1, és x2 gyök valós és képzetes részét. Vagyis A, B és C "bemenő" paraméterek, a többi négy pedig "kimenő" - azaz eredményt adó - paraméter. Szubrutin szegmensük a következő:
SUBROUTINE QVDSLV(A, B, C, X1R, X1I, X2R, X2I)
IF(A.EQ.0.0.AND.B.EQ.0.0) STOP 77
IF(A.EQ.0.0) GO TO 1
DISKR = B**2-4.*A*C
ROOT = SQRT(ABS(DISKR))
IF(DISKR) 2,3,3
3 X1I = 0
X2I = 0
X1R = (-B+ROOT)/(2.0*A)
X2R = (-B-ROOT)/(2.*A)
IF(ABS(X1R)-ABS(X2R)) 4,4,5
4 X1R = C/(X2R*A)
RETURN
5 X2R = C/(X1R*A)
RETURN
2 X1R = -B/(2.*A)
X2R = X1R
X1I = ROOT/(2.*A)
X2I = -X1I
RETURN
1 X1I = 0
X2I = 0
X1R = -C/B
X2R = X1R
RETURN
END
A szubrutinnak a különböző aleseteknek megfelelően négy visszatérési pontja van. Két valós gyök esetén két további alesetet választottunk szét aszerint, hogy a gyökök közül melyiknek nagyobb az abszolút értéke. A megoldóképletből csak a nagyobb abszolút értékű valós gyököt célszerű számítani, a kisebb kiszámításához ajánlatosabb a gyökök és együtthatók összefüggésének felhasználása. Ily módon elkerülhetjük a kisebbik abszolút értékű gyök kiszámításakor a kivonási jegyveszteséget.
Most - miután már kialakult valamelyes szemléletes képünk a több szegmensből álló programokról és ezek használatáról - áttérünk a paraméter átadás - átvétel szabályainak szabatos tárgyalására. A cél annak tisztázása, hogy milyenek lehetnek egy eljárás formális, ill. aktuális paraméterei, milyen kapcsolatban vannak ezek egymással, és hogyan kell őket megadni.
Annyit már az 5.2. pontban is mondottunk a formális paraméterekről, hogy tetszőleges azonosítók lehetnek. Ez igaz is, a kérdés azonban az, hogy milyen programozási objektumoknak lehetnek az azonosítói? E kérdésre a válasz a következő: a formális paraméterek azonosítói jelölhetnek skaláris változót, tömböt vagy másik szegmenst. A formális paraméterekhez hozzárendelt aktuális paraméterek megadási szabályai a következők (ezeket részben már az előzőkben megismertük, most azonban összefoglalva közöljük):
A fenti szabályok némelyikéhez szükséges bizonyos magyarázatot fűznünk.
A 3. szabály első részének mondanivalóját abban jelölhetjük meg, hogy a FORTRAN nyelvben az aktuális paraméter kifejezések átvétele érték szerint történik. Ez azt jelenti, hogy a gép előbb kiszámítja a kifejezés értékét, majd ezután tér a szubrutin végrehajtására, és a formális paraméterre való hivatkozások a végrehajtás folyamán erre az értékre történő hivatkozásokba mennek át. A hangsúly itt azon van, hogy az eljárás aktivizálása az aktuális paraméter kifejezések kiértékelésével kezdődik, és a gép ezt a műveletet a szubrutin végrehajtása közben többször már nem ismétli meg.
Az olvasónak úgy tűnhet, hogy itt érdemén felüli nyomatékkal hangsúlyozunk egy trivialitást, hiszen mi sem természetesebb, mint az, hogy az aktuális paramétert egyszer előre kiszámítjuk, majd a továbbiakban ezzel az értékkel dolgozunk. A helyzet azonban az, hogy nem is túlzottan nagy ügyeskedéssel lehet olyan FORTRAN programot írni, amelyben a behívott szegmens menet közben megváltoztatja valamelyik aktuális paraméter kifejezésének értékét és ebben az esetben nem közömbös, hogy az ezt követő hivatkozásoknál a kifejezésnek az eredeti (vagyis a behíváskor viselt), vagy pedig a módosított (vagyis a szubrutin végrehajtása során előállított) értéke veendő figyelembe.
Ezt a kérdést egyébként az ALGOL 60 nyelv ismerői szokták élére állítani. Ott ugyanis megkülönböztetünk ún. érték szerinti és név szerinti paraméter átvételt. A kérdés az, hogy a kettő közül melyiknek felel meg a FORTRAN nyelv paraméter átvételi rendszere?
A válasz: egyiknek sem. Az ALGOL nyelv terminológiájával fogalmazva, a pontos helyzet a következő:
A negyedik paraméter átvételi szabály szerint formális paraméter tömbnek megfeleltethetünk aktuális paraméterként nemcsak tömböt, hanem indexes változót is. A következőkben ezt fejtjük ki kissé részletesebben.
Az említett lehetőség módot ad a formális paraméter tömb "kezdetének" a kijelölésére. Az ilyen paraméter megadásakor ugyanis a fordítóprogram az aktuálisként megadott tömbelemet azonosítja a formális paraméter tömb első elemével, "ettől az elemtől kezdve" számítja a formális paramétert.
Példa:
Tegyük fel, hogy rendelkezésünkre áll egy FORTRAN szubrutin, amely 20 elemű vektorok skaláris szorzatának kiszámítására alkalmas. A feladat 5 ilyen skaláris szorzás elvégzése. Az említett feladatot természetesen megoldhatjuk "elemi" eszközökkel is, azonban a "tömb-tömbelem" megfeleltetés a programot lényegesen egyszerűsítheti. Álljon itt mindkét lehetséges megoldás!
Mindkettőben szükség van a skaláris szorzást végző szubrutinra, mely a következő alakú lehet:
SUBROUTINE SKLMLT(U, V, SZORZAT)
DIMENSION U(20), V(20)
SZORZAT = 0.0
DO 1 I = 1,20
1 SZORZAT = SZORZAT + U(I)*V(I)
RETURN
END
A feladat megoldása elemi eszközökkel:
PROGRAM TRIVI
DIMENSION A1(20),B1(20),A2(20),B2(20),
XA3(20),B3(20),A4(20),B4(20),A5(20),B5(20)
READ A1,B1,A2,B2,A3,B3,A4,B4,A5,B5
CALL SKLMLT(A1,B1,RES1)
CALL SKLMLT(A2,B2,RES2)
CALL SKLMLT(A3,B3,RES3)
CALL SKLMLT(A4,B4,RES4)
CALL SKLMLT(A5,B5,RES5)
...
STOP
...
END
A program elején álló READ utasítás a számításban résztvevő tíz vektor beolvastatását szimbolizálja. Ezt öt szubrutinhívó utasítás követi, amelyek különböző paraméterek esetén kiszámíttatják az egyes skalárszorzatokat. A program az eredmények kiíratásával végződhet.
Lássuk most, mennyiben lehet segítségünkre a feladat megoldásában, ha a tömbparamétert indexes változó aktuális paraméterrel helyettesítjük. A módosított MASTER szegmens a következő:
PROGRAM AGYAF
DIMENSION A(100),B(100),RES(5)
READ A,B
DO 1 I = 1,5
1 CALL SKLMLT (A(20*I-19),B(20*I-19),RES(I))
...
STOP
...
END
Ebben a programváltozatban - az előzővel ellentétben - mindössze három vektort deklarálunk, amelyek közül az első kettő a skalárisán összeszorzandó vektorok elemeit tartalmazza. Ezeknek a vektoroknak egy-egy 20 elemből álló "szakasza" alkot egy vektortényezőt, és ezeken egy DO ciklusban haladunk végig. A szorzásban résztvevő 20 elemű vektorok - a méretet az SKLMLT szubrutin deklarációs része határozza meg - kezdete az első ciklusban A(1) és B(1), a másodikban A(21) és B(21), a harmadikban A(41) és B(41), stb. A DO ciklus lehetővé tette, hogy az eredményeket is egy vektornak az elemeiben helyezzük el.
A formális paraméter tömb elemeire kikötött korlátozásnak, úgy hisszük, most már világos az értelme: azt fejezi ki, hogy a formális paraméter tömb akkor sem nyúlhat túl az aktuális tömbön, ha a paraméter hozzárendelés folytán a formális tömböt nem az aktuális tömb első eleménél "kezdjük meg".
A tömb-tömbelem hozzárendelésnek hasznos gyakorlati alkalmazásai vannak, ha a dinamikus indexhatárok lehetőségével kombinálva alkalmazzuk.
FUNCTION szegmensek és alkalmazásaik
Az előző alpontban megismerkedtünk a SUBROUTINE szegmensek felírási és hívási szabályaival. Az ott megismert szabályok legnagyobb része a FUNCTION szegmensekre is érvényes, ezért utóbbiakkal már jóval rövidebben végezhetünk.
A FUNCTION és a SUBROUTINE szegmensek között a leglényegesebb különbség az, hogy a FUNCTION szegmensek azonosítójához a szegmens végrehajtása egy - szám-, vagy logikai - értéket rendel, míg a SUBROUTINE szegmensek esetén ilyen érték hozzárendelésére nem kerül sor. Ezenkívül a FUNCTION szegmensek aktivizálásának módja is eltér a SUBROUTINE szegmensekétől, amennyiben az előbbiek behívása nem CALL utasítással, hanem az aritmetikai utasításfüggvények (lásd a Negyedik fejezet 6. pontját) mintájára történik.
A függvények meghatározására szolgáló FUNCTION szegmensek nyitó utasításának formai szabályait már az 5.2. pontban megismertük. A szegmensnyitó utasításon kívül van azonban a FUNCTION szegmenseknek még egy ismérvük, amely szorosan összefügg a FUNCTION szegmens által meghatározott érték meghatározásával:
Minden FUNCTION szegmensben a szegmens azonosítójának legalább egyszer skaláris változó módjára elő kell fordulnia valamelyik végrehajtható utasításban, és ezen előfordulások között kell olyannak is lennie, amely a szegmens nevével jelzett változó értékét meghatározza. A szegmens végrehajtásának bármilyen lefutása mellett legalább egy ilyen értékmeghatározásra sor kell hogy kerüljön. A szegmens nevével azonosított skaláris változó azon értékét, amelyet a szegmens RETURN utasításának végrehajtása pillanatában visel, a szegmens által generált függvény-értéknek nevezzük.
Példa:
Írjunk FUNCTION szegmenst az sh x (hiperbolikus szinusz) függvény kiszámítására! A számítás során felhasználhatjuk a függvény ismert Taylor-sorfejtését. A bemutatandó eljárás első változatának egyetlen paramétere van, a függvény argumentuma. A FORTRAN program a következő:
FUNCTION SH(X)
Z = X**2
SH = X
WORK = X
K = 3
1 WORK = Z/FLOAT(K*(K-1))*WORK
2 SH=SH+WORK
3 IF(WORK/SH.LT.1E-7) RETURN
K = K+2
GO TO 1
END
Figyeljük meg a programban az SH szegmensazonosítónak a szerepét! A szegmens eleget tesz az ASA FORTRAN ama szabályának, mely szerint a szegmensazonosítónak a szegmensben skaláris változó szerepében legalább egyszer elő kell fordulnia: itt négy ilyen előfordulás van, melyek közül kettő "aktív", azaz meghatározza, ill. módosítja SH értékét. Az is teljesül, hogy a RETURN végrehajtása pillanatában a szegmens azonosítójának értékkel kell bírnia, mert a RETURN eléréséig minimálisan két (de esetleg jóval több) értékadás történt az SH változóra. A program a Taylor-sor tagjait addig generálja és összegezi, amíg a járulékos tag - a WORK programbeli változó - értéke a sor többi tagjához képest elhanyagolhatóan kicsinnyé nem válik.
Az ALGOL nyelv ismerői feltehetőleg észrevették, hogy itt ismét szembetűnő eltérés van a két nyelv szabályai között, amennyiben a FORTRAN megengedi a szegmens azonosítójának "passzív", előfordulását a szegmens végrehajtható utasításaiban, az ALGOL viszont kifejezetten megtiltja, illetőleg az eljárás rekurzív aktivizálásaként értelmezi. Ha a programot ALGOL-ba kívánnánk átírni, akkor az SH azonosítót a 2-es és a 3-as címkével megjelölt utasításokban szereplő aritmetikai kifejezésből valamilyen programozási fogás alkalmazásával el kellene tüntetnünk.
A végrehajtható utasításokkal ellentétben, deklaratív utasításokban nem fordulhat elő a FUNCTION szegmens azonosítója: a FUNCTION utasítást kivéve, a szegmens azonosítója semmilyen deklaratív utasításban nem szerepelhet.
Bizonyos gépi reprezentációs nyelvek - egyetlen kivételként - megengedik a FUNCTION szegmens nevének típusdeklaráló utasításban való megjelenését, mint pl.:
FUNCTION EGESZF(I)
INTEGER EGESZF
Hangsúlyozzuk, hogy az ilyen deklaráció ellenkezik az ASA FORTRAN szabályaival. ASA FORTRAN-ban helyesen így fest:
INTEGER FUNCTION EGESZF(I)
Itt az INTEGER típusdeklaráló szó az előállítandó függvényérték típusát jelöli ki. Ilyen típusdeklaráció hiányában a típus az azonosító első betűje alapján, a szokott módon, az automatikus típusdeklaráció szerint határozódik meg.
Akárcsak a SUBROUTINE szegmenseknek, a függvényeknek is tetszőleges számú formális paraméterük lehet, és ily módon FUNCTION szegmens segítségével akárhány változós függvények is előállíthatók. Az SH függvény például tartalmazhatja formális paraméterként az elérendő relatív pontosságot A megfelelő módosított változat (csak az eltérő utasításokat írtuk ki):
FUNCTION SH(X,EPS)
...
3 IF(WORK/SH.LT.EPS) RETURN
...
A FUNCTION szegmensek aktivizálására vonatkozóan már említettük, hogy azokat a standard függvényekhez, vagy az aritmetikai utasítás függvényekhez hasonlóan, azonosítójuk és aktuális paramétereik megadásával hívhatjuk be. Akárcsak a már ismert függvényfajták, a FUNCTION szegmensek azonosítója is beírható aritmetikai, ill. logikai kifejezésekbe, és azonosítójuk ilyen előfordulása a függvényeljárás aktivizálását jelenti. Például:
V = A+SH(B**2-COS(RO))
a példa az SH FUNCTION szegmens egy lehetséges aktivizálását mutatja.
A következő példa egy FVERT nevű FUNCTION szegmens aktivizálását illusztrálja
IF(FVERT(X+DELTAX).GT.BETA) GO TO 2
Végül egy logikai értéket előállító függvény használatára látunk példát:
IF(LOGF(BOLEAN)) LOGIC = .TRUE.
Utóbbi szegmensnyitó és első deklaratív utasítása a következő lehet:
LOGICAL FUNCTION LOGF(ARG)
LOGICAL ARG
...
A paraméterátvételre vonatkozó szabályok a FUNCTION szegmensekre pontosan ugyanúgy érvényesek, mint a SUBROUTINE szegmensekre, így azokat nem ismételjük meg. Talán a 9. szabályról érdemes annyit megjegyeznünk, hogy a SH(SH(X)) típusú aktivizálások annak nem mondanak ellent, mert a "belső" aktivizálás ebben az esetben előbb befejeződik (végrehajtódik a "belső" RETURN), és csak ezután kezdődik meg a "külső" aktivizálás. Tehát a függvényhivatkozások ilyen módon egymásba skatulyázhatok.
Van az ASA FORTRAN nyelvnek néhány olyan járulékos szabálya, amely csak a FUNCTION szegmensekre vonatkozik. A következőkben ezekkel foglalkozunk.
Mellékhatáson azt értjük, hogy valamely eljárás megváltoztatja az őt behívó szegmens bizonyos változóinak értékét, és ezáltal egyes kifejezések értéke a kiszámítás sorrendjétől függővé válik. Ilyen példát igen könnyű felírni:
INTEGER FUNCTION CSEL(l,K)
CSEL = I+K
K = I+1
RETURN
END
Aktivizáljuk a CSEL függvényt a következő utasításokkal:
J = 2
N = CSEL(2,J)+J
A CSEL függvény kiértékelése J értékét 3-ra növeli. Ezért attól függően, hogy az összeg kiértékelését J értékének megjegyzésével, vagy a CSEL függvény kiszámításával kezdjük, N a 6, vagy a 7 értéket veszi fel. A kifejezés persze nem korrekt az ASA FORTRAN ama szabálya miatt, amely szerint az elemi matematika azonosságainak (kommutatív, asszociatív és disztributív törvény) - az esetleges kerekítési hibák hatásától eltekintve - a FORTRAN kifejezésekre is teljesülniük kell (lásd a Második fejezet 5. pontját).
Az iménti 2. szabály bizonyos formális védelmet nyújt a mellékhatások ellen, kikötve, hogy a kétszeri aktivizálásnak - azonos paraméterek mellett - azonos eredményt kell adnia. Az (5.43) függvény ezt a kikötést éppen nem teljesíti, mert pl. az
N = CSEL(2,J) + CSEL(2,J)
értékadó utasításban a függvény eltérő értékeket szolgáltat az első és második aktivizáláskor. A szabály által nyújtott védelem azonban csak részleges, mert egy ebből a szempontból kifogástalan eljárásnak is lehet mellékhatása. Még az sem nyújtana teljes biztonságot, ha megtiltanánk a FUNCTION szegmensekben a "mellékértékek" generálását (a CSEL függvény második paramétere ilyen mellékérték, és az adott esetben ez okozza a bajt), mert a közös adatmezők (lásd az Ötödik fejezet 5. pontját) nyújtotta lehetőségekkel visszaélve, még mindig lehetne mellékhatásos függvényeket felírni. Az egyértelmű megoldást - amint az ALGOL nyelvben így is van - csak a szigorú balról jobbra szabály biztosítja, ez azonban gátja a kifejezések kiszámításában az optimalizálási lehetőségek kihasználásának.
Befejezésül felhívjuk a figyelmet arra a tényre, hogy az aritmetikai utasítás függvények és a FUNCTION szegmensek között nem az a leglényegesebb különbség, hogy az előbbiek csak egyetlen aritmetikai kifejezéssel megoldható formulák kiszámítására használhatók, míg a FUNCTION szegmensek bonyolultabb számítási eljárásokkal megadható függvénykapcsolatok kiszámíttatására is alkalmasak. A legfontosabb eltérés az, hogy az aritmetikai utasítás függvények azonosítója nem szegmensközi azonosító, így az utasítás függvények csak abban a szegmensben használhatók, amelyben deklaráljuk őket. A FUNCTION szegmensek viszont a program bármely szegmenséből aktivizálhatók.
5.4. Dinamikus indexhatárok
Az eddig megismert, tömbparamétereken operáló eljárások (pl. SKLMLT eljárás) rugalmas felhasználásának az az akadálya, hogy a szubrutin megírásakor előre lerögzítettük a formális paraméter tömb méreteit. Ez nyilván nem kedvező, mert egy olyan szubrutint, amelyet 10X10-es tömbök szorzására írtunk meg, nem használhatunk fel, ha a feladat történetesen 20x20-as méretet írna elő. Már az 1. pontban felmerült a tömbméret rugalmas megválasztásának problémája. A jelen pontban ennek módozataival ismerkedünk meg.
Az ASA FORTRAN lehetőséget ad arra, hogy a SUBROUTINE és FUNCTION szegmensekben deklarált formális paraméter tömbök méretét változóként definiáljuk. Ilyen esetben a DIMENSION (vagy típusdeklaráló) utasításban az indexhatárokat jelző számok helyett index nélküli, egész változók is állhatnak, melyeknek maguknak is formális paramétereknek kell lenniük, a szegmens aktivizálásakor aktuális értékkel kell rendelkezniük, és értéküket a szegmens végrehajtása során nem szabad megváltoztatniuk. A méretet definiáló változók aktuális értékeinek olyannak kell lenniük, hogy - akárcsak skaláris indexhatárok esetén - a formális tömb beleférjen az aktuális tömbbe. Az ily módon deklarált formális tömbről azt mondjuk, hogy dinamikus indexhatárai vannak.
Példa:
Írjunk függvényt a mátrixszorzás elvégzésére, úgy, hogy az tetszőleges méretű mátrixok szorzására alkalmas legyen dinamikus indexhatárok alkalmazásával:
SUBROUTINE MTXMLT(A,B,C,L,M,N)
DIMENSION A(L,M), B(M,N), C(L,N)
DO 1 I = 1,L
DO 1 J = 1,N
WORK = 0.0
DO 2 K = 1,M
2 WORK = WORK + A(I,K)*B(KJ)
1 C(I,J) = WORK
RETURN
END
Az eljárást mindjárt úgy írtuk át, hogy alkalmas legyen tetszőleges - nem okvetlenül négyzetes - mátrixok összeszorzására. Ha az összeszorzandó mátrixok pl. 10x5, ill. 5x20 méretűek, akkor a megfelelő szubrutinhívó utasítás
CALL MTXMLT(X,Y,Z,10,5,20)
lehet. Az eredménymátrixnak 10X20-asnak kell lennie.
A dinamikus indexhatárok alkalmazásában éppen az az eset a tipikus, amikor az aktuális és a formális tömb mérete nem egyezik meg. A programokat ugyanis rendszerint úgy írják, hogy a MASTER szegmensben a tömbök méretét az előfordulható legnagyobbra deklarálják, míg a tényleges méretek ezt általában nem érik el. Tegyük fel pl., hogy olyan feladatunk van, amelyben változó méretű mátrixokat kell összeszoroztatnunk, és az előfordulható maximális méret 20 X 20-as, az aktuális méretek azonban ennél kisebbek is lehetnek. Ebben az esetben a MASTER szegmens szervezése a következő:
PROGRAM PLD
DIMENSION X(400),Y(400),Z(400)
READ (...) L,M,N
LIMIT = L*M
DO 10 I=1, LIMIT
X(I) =...
10 CONTINUE
LIMIT = M*N
DO 20 I=1,LIMIT
Y(I) = ...
20 CONTINUE
CALL MTXMLT(X,Y,Z,L,M,N)
...
STOP
END
Ebben a példában a MASTER szegmens tömbjeit egyméretűként deklaráljuk, maximálisan 400 elemmel, ami éppen egy 20x20-as mátrix elemszámának felel meg. A két DO ciklus az egyes tömbök elemeinek előállítását szimbolizálja. A tömbelemek előállítása után kerül sor a mátrixszorzásra. Ez egyben példa arra is, hogy kétindexes formális paraméternek egyindexes aktuális paramétert feleltetünk meg. Ez nem hiba, a megszorítások csakis az elemszámra vonatkoznak, a méretek (dimenziók) számát nem érintik.
Felmerül a kérdés, hogy miért nem lehet, vagy miért nem célszerű ilyen esetben az aktuális paramétert is annyi indexesként deklarálni, mint ahány indexes a formális paraméter? Ennek oka, hogy ha az aktuális és a formális paraméter index-határai különbözők - a jelen példában is ez lenne a helyzet -, akkor a formális és az aktuális paraméter tömb címfüggvénye különböző. Ezt azonnal belátjuk, ha meggondoljuk, hogy az aktuális paraméter címfüggvénye - 20 X 20-as méretet feltételezve -
f(l,J) = I - 1+ 20(J-1) + X
míg a CALL MTXMLT(X,Y,Z,10,5,20) szubrutinhívás számadataival, az MTXMLT eljárás A formális paraméteréé
g(I,J) = l - 1 + 10(J-1) + X
(Az additív állandó itt az aktuális-formális paraméter megfeleltetés miatt X és nem A!)
A lényeg az, hogy a paraméter megfeleltetés csak a tömbkezdetek egyeztetését jelenti, de mindkét tömb megőrzi a saját címfüggvényét. Ennek nyilvánvaló következménye, hogy ha a MASTER szegmensben értéket adunk mondjuk az X tömb (3,2) indexű elemének, akkor ez az MTXMLT szegmensben nem az A(3,2) tömbelemre, hanem ennek a tömbnek egy másik (történetesen (3,3) indexű) elemére jelent értékadást; az X tömb (3,4) indexű elemének pedig az A tömb egyik eleme sem felel meg. Jól vigyázzunk tehát! Ha az aktuális és formális tömb méretszáma megegyezik, de indexhatáraik különböznek, akkor az azonos számindexekkel megjelölt elemek az aktuális és a formális paraméterben nem ugyanazon a helyen vannak a memóriában, és a megfelelő tömbelemek indexeit a következési függvényeknek esetenkénti átszámítása alapján kell meghatározni. Ezt legegyszerűbben a PLD példán bemutatott módon kerülhetjük el.
Még mindig az iménti példánál maradva, feltehetnénk a kérdést, nem lehetne-e azt memória szempontjából gazdaságosabban megoldani? A program ugyanis a benne szereplő mátrixok számára lefoglal 400 + 400 + 400 = 1200 tömbelem helyet, amit általában igen rosszul használ ki. A deklarációk ily módon történő megadása ugyanis nem teszi lehetővé pl. egy 25 X 25-ös mátrixnak egy 25 X 6-ossal való összeszorzását, annak ellenére, hogy ennek a feladatnak a megoldásához 1200-nál kevesebb (625 + 150 + 150 = 925) tömbelem helyre lenne szükség.
A megoldás ötletét a következő program adja: ne deklaráljunk három egyenként 400 elemű tömböt, hanem egyetlen 1200 eleműt, és ezt az aktuális méretektől függően bontsuk fel három részre. Jelöljük ezt a tömböt XYZ-vel! Az előbbi program megfelelően módosított változata a következő:
MASTER PLD
DIMENSION XYZ(1200)
READ (...) L, M, N
LIMIT = L*M
DO 10 1=1, LIMIT1
...
XYZ(I) =...
10 CONTINUE
LIMIT2 = M*N
DO 20 I =1,LIMIT2
...
IND = I + LIMIT1
XYZ(IND) = ...
20 CONTINUE
I = LIMIT1 + 1
K = LIMIT1 + LIMIT2 + 1
CALL MTXMLT(XYZ(1), XYZ(I), XYZ(K), L, M, N)
...
STOP
END
Ha pl., mint kiindulási problémánkban, L = 25, M = 25 és N = 6, akkor a mátrixszorzás szubrutinjában az A mátrix az XYZ tömb első eleménél kezdődik, és mérete 25x25-ös; a B mátrix az XYZ tömb 626-odik eleménél kezdődik és mérete 25x6-os, és végül a C mátrix az XYZ tömb 776-odik eleménél kezdődik és mérete ugyancsak 26x6-os. XYZ utolsó 275 eleme határozatlan és nincs kihasználva. Egy ilyen szerkezetű program teljesen rugalmasan használható tetszőleges méretű tömbök összeszorzására; az egyetlen megkötés, hogy a feladatban szereplő tömbelemek száma ne haladja meg az 1200-at.
5.5. Közös adatmezők. A COMMON utasítás
Az előző két pontban megismerkedtünk az aktuális és formális paraméterek fogalmával, mint a több szegmensből álló programokban a belső kapcsolat fenntartásának eszközével. Láttuk, hogy a behívott szegmensek az aktuális paraméterekből veszik a bemenő információt, és az eredményeket ugyancsak a formális-aktuális paramétercsere közbejöttével adják vissza a behívó szegmensnek.
Ebben a pontban látni fogjuk, hogy a paramétercsere nem kizárólagos módja a szegmensek közti információcserének. A FORTRAN nyelv lehetőséget ad arra, hogy a program különböző szegmenseinek legyen egy vagy több közös "felvevő" és "lerakodó" helye - közös adatmezeje -, amelyhez a "társulásban résztvevő" szegmensek mindegyike hozzáférhet, és az akár saját maga, akár más szegmensek által oda elhelyezett értékeket a további számításokban felhasználhatja.
A közös adatmezők a FORTRAN nyelvben a COMMON utasítással deklarálhatok. Az utasítás alakja:
COMMON/BLOKK1/1.lsita/BLOKK2/2.lista/BLOKKn/n.lista
ahol BLOKK1, BLOKK2, ..., BLOKKn tetszőleges azonosítók ("blokknevek"), az 1. lista, 2. lista, n. lista pedig a típusdeklaráló utasításokban (lásd Negyedik fejezet 3. pontját) szereplő listákkal azonos konstrukciójú sorozatok. (Vagyis azonosítókból és tömbdeklarátorokból álló sorozatok.) A blokknevek 1-6 alfanumerikus karakterekből álló azonosítók lehetnek, amelyek első karakterének betűnek kell lennie.
A BLOKK1, ..., BLOKKn azonosítók (blokknevek) bármelyike lehet üres, amely esetben az elválasztó törtvonalak között nem áll karaktersorozat. Kizárólag BLOKK1 esetében a két elválasztó törtvonal is elmaradhat, ha az azonosító üres. Példák COMMON utasításokra:
COMMON/ADATOK/X(100),Y(20,20),Z/SZAMOK/PI,E,RYNOLD
COMMON/FILE/A(2500)//B(2500)
COMMON//WORK(40,40)
COMMON WORK(40,40)
Az első példában az első blokknév ADATOK, a második SZAMOK.
Második példában az első blokknév FILE, a második üres, vagy más szóval blank.
A harmadik és negyedik példa teljesen egyenértékű, csupán az elsőben kitettük a két fölösleges törtvonalat, a másodikban nem. (Figyelem, a blank blokknév törtvonalai csak akkor hagyhatók el, ha az a COMMON utasítás első blokkneve. A második példában a két törtvonal nem fölösleges!)
A közös adatmezők deklarálásának lényegéhez tartozik, hogy ugyanaz a blokknév COMMON utasításokban a programnak egynél több szegmensében is előfordul. Valamely közös adatmező használatára azok a szegmensek "társulnak", amelyekben ugyanaz a blokknév COMMON utasításban előfordul. A közös adatmezők számára a fordítóprogram a memóriában egy-egy meghatározott részt jelöl ki, és ennek a résznek a rekeszeihez a "társulásiban résztvevő valamennyi szegmens hozzáférhet.
A blokknevet követő deklarációs lista a közös adatmezőhöz tartozó skaláris vagy indexes változókat határozza meg. A lista elemei által elfoglalt memóriarekeszek számát a közös adatmező hosszának nevezzük. Az első példában az ADATOK nevű adatmező hossza 501 egység, a SZAMOK nevű adatmező hossza 3 egység; a harmadikban, ill. a negyedik példában a blank adatmező hossza 1600 egység. A közös adatmezők deklarálásának alapszabálya, hogy a nem blank adatmezők hosszát minden rájuk hivatkozó COMMON utasításban egyenlően kell megadni. (Blank adatmezőkre ez a megkötés nem vonatkozik.)
Tekintsük példának a már vizsgált SH X-et generáló FUNCTION szegmenst! A közös adatmezőhöz tartozó (a továbbiakban röviden common) változók egy tipikus alkalmazási területe a mellékparamétereknek (mint pl. EPS és K) átadása, ill. átvétele. A program egy ilyen módosított változata lehet a következő:
FUNCTION SH(X)
COMMON/PARAMS/EPS,K
...
END
Természetesen a behívó szegmensnek is tartalmaznia kell a PARAMS nevű közös adatmező deklarációját:
PROGRAM BEHIVO
COMMON/PARAMS/EPS,K
...
EPS = 1.0E-06
G = SH(2.49666532)
L = K/2+1
...
END
A BEHIVO szegmens az SH függvény egy lehetséges aktivizálását mutatja. Mielőtt az SH szegmenst hívnánk, értéket adunk az EPS common változónak. Ezt az értéket az SH szegmens a számításban fel tudja használni. Ugyanakkor a szegmens végrehajtása közben keletkezett K értéket a BEHOVO program találja további felhasználásra készen a közös adatmezőben. Az utolsó utasítás a felhasználás módját illusztrálja: az L változó a sorfejtés tagjainak számát veszi fel értékként.
Bár az előbbi példa alapján erre lehetne következtetni, egyáltalán nem kötelező a közös adatmezőhöz tartozó változókat minden szegmensben ugyanazzal az azonosítóval ellátni. A BEHIVO-ban például ugyanolyan helyes volna - természetesen a szegmens többi utasításának átjelölése mellett - a következő COMMON utasítás is:
COMMON/PARAMS/ETA, N
amely esetben az SH szegmens EPS változójának a BEHIVo szegmens ETA változója, SH K változójának pedig BEHIVO N változója felelne meg.
Ehhez hasonló egymáshoz rendeléssel már korábban is találkoztunk az EQUIVALENCE utasítással kapcsolatban (lásd a Negyedik fejezet 4. pontját). A lényeges különbség az, hogy míg az EQUIVALENCE mindig ugyanazon szegmens különböző változóinak azonosságát mondja ki, addig a COMMON utasítás különböző szegmensekben deklarált változók azonosságát deklarálja. Ezek a változók a különböző szegmensekben különböző nevekkel is lehetnek ellátva, de azonosságuk fokozott hangsúlyozása céljából sok esetben célszerű ugyanannak az azonosítónak a használata.
A COMMON utasítás felhasználható a közös adatmezőbeli tömbök indexhatárainak deklarálására is, az utasításban alkalmazott tömbdeklarátorok segítségével. Azonban a tömbméretek DIMENSION vagy típusdeklaráló utasításokban is deklarálhatók, akárcsak a nem közös adatmezőhöz tartozó - a továbbiakban lokális - változóké. Ha egy közös adatmezőhöz tartozó tömbnek a méreteit nem magában a COMMON utasításban deklaráljuk, akkor a közös adatmezőhöz tartozásának kinyilvánítására elegendő felsorolni a tömb azonosítóját a megfelelő blokknév után. Ezzel kapcsolatban emlékeztetünk arra a fontos szabályra, amely szerint minden tömb azonosítója egy szegmensben csak egyszer fordulhat elő tömbdeklarátor alkotórészeként.
Valamely közös adatmező szerkezetén (struktúráján) az illető adatmező felosztását értjük különböző skaláris, ill. indexes változókra. A közös adatmezők alkalmazásának fontos szabálya, hogy ugyanannak a közös adatmezőnek különböző szegmensekben eltérő szerkezete lehet. Ez azt jelenti, hogy a programozónak jogában áll különböző szegmensekben ugyanazt a közös adatmezőt eltérő módon felosztani skaláris változókra és tömbökre. Ilyen esetben a különböző szegmensek common változóinak egymáshoz rendelését a változóknak a közös adatmező kezdetéhez viszonyított relatív helyzete határozza meg.
Példa:
Tegyük fel, hogy valamely program A szegmensében az alábbi COMMON utasítás van elhelyezve:
COMMON/BLOKK/R(15,15),S(20,20),T(5,5)
A közös adatmező hossza 15x15 + 20x20 + 5x5 = 650 egység. Ezt a 650 egységnyi közös adatmezőt a B szegmensben a következő struktúrával is deklarálhatjuk:
COMMON/BLOKK/CSONT(10,10),BOR(20,20),SOR(150)
Az egyes indexes változók között a közös adatmezőben elfoglalt relatív helyzetük szerint a következő azonossági kapcsolatok jönnek létre:
A közös adatmező elrendezését az A és B szegmensben:
Természetes, hogy ha különböző szegmensekben ugyanazt a közös adatmezőt különböző szerkezettel deklaráljuk, akkor az információ átadás-átvétel programozása során gondosan ügyelni kell a blokk változóinak azonossági kapcsolataira, nehogy programozási hiba következtében a másik szegmens bizonyos változóit elrontsuk.
Eddigi példáinkban hallgatólag feltettük, hogy az egymáshoz rendelt common változók mindegyik szegmensben azonos típusúak. Ha ez nem teljesül, akkor két dologra kell ügyelnünk:
Néhány további szabály a közös adatmezőkkel kapcsolatban:
Ha az ekvivalencia-csoportban common változó is van, akkor az EQUIVALENCE utasítás hatása lényegesen eltér a Negyedik fejezet 4. pontjában leírt sémától. A szabályok a következők:
A következőkben példákkal illusztráljuk a különböző szabályokat.
A 3. szabály azt mondja ki, hogy - eltérően a lokális változók ekvivalenciájának esetétől - a közös adatmezőben fellépő ekvivalencia "nem tolja szét" a közös adatmező tömbjeit. Tekintsük pl. a következő deklarációkat:
DIMENSION X(10)
COMMON/PELDA/A(5),B(5),C(5)
EQUIVALENCE(X(4),B(2))
Ennek hatására nemcsak az X és B vektorok lépnek ekvivalenciába, hanem az X és A, ill. X és C vektorok is, hiszen a COMMON utasítás B-hez képest A és C helyzetét meghatározza. Nevezetesen, az X vektor első eleme ekvivalens A(4)-gyel, X(2) ekvivalens A(5)-tel stb., továbbá X(8) ekvivalens C(1)-gyel, X(9) C(2)-vel stb. Az eltérés a lokális változók esetétől szembetűnő.
A 4. szabályra úgy kapunk példát, hogy az előző példában X-et 10 helyett 15 eleműként deklaráljuk. Ebben az esetben az X vektor vége "kinyúlik" a PELDA közös adatmezőből. A közös adatmező meghosszabbítása azt jelenti, hogy a valódi méret nem 15, hanem 18 egység lesz.
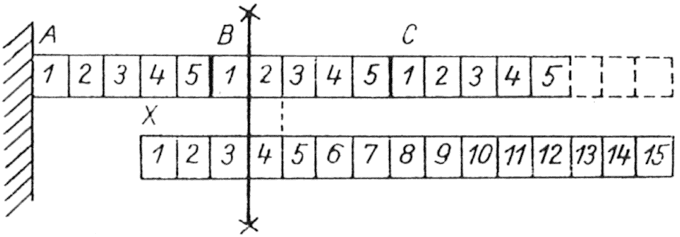
Végül az 5. szabályba ütköző - hibás - ekvivalenciához jutunk, ha a példában az utolsó utasítás helyébe az
EQUIVALENCE(X(8),B(2))
utasítást írjuk. Ebben az esetben az X vektor eleje "kilóg" a közös adatmező kezdete elé. A közös adatmezőt bal felé nem lehet megnyújtani.
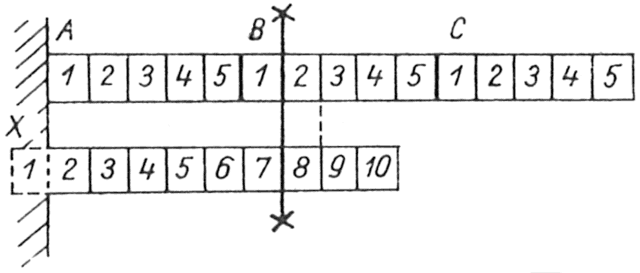
Láttuk az előzőkben, hogy a közös adatmezők használata alternatív lehetőség az aktuális-formális paramétercseréhez képest a szegmensközi információcsere megszervezésére. Mindaz, ami közös adatmezőkkel megoldható, megoldható aktuális-formális paramétercserével is. (Ezen állítás fordítottja nem érvényes!) Jogos tehát a kérdés, hogy milyen szempontok szerint választhatjuk egyik vagy másik megoldást, mikor melyik a célszerűbb?
Előrebocsátjuk, hogy erre merev szabályt adni nem lehet, és az alábbiakban valóban csak célszerűségi szempontokat adunk. Ha a programozó nem is tartja magát ezekhez, ettől programja még kifogástalanul működhet, legfeljebb kissé kevésbé lesz hatékony.
Az elsődleges választási szempont mindig a tárgyprogram térbeli (helyfoglalás szerinti) és időbeli (vagyis gépidő felhasználás szerinti) optimalizálása. Ezen belül általában a gépidő a fontosabb, hacsak a program helyfoglalása nem olyan nagy, hogy már fennáll a memóriakapacitás túllépésének veszélye. A közös adatmezők mind gépidő, mind helyfoglalás szempontjából sok esetben gazdaságosabbak a paramétercserénél. A fordítóprogram ugyanis a paraméterátvétel szervezésére utasításokat fordít a célprogramba, amelyek növelik annak hosszát, végrehajtásuk pedig időbe kerül. Ilyen utasítások beépítésére közös adatmezők esetén nem kerül sor, ezért a tárgyprogram gyorsabb és rövidebb lehet.
Egyúttal figyelembe kell azonban azt is venni, hogy a paramétercsere - rendeltetése folytán - módot ad az átjelölésre, tehát ugyanazt a számítási eljárást különböző azonosítóval ellátott objektumokon is el lehet végezni. Ha ugyanezt a feladatot közös adatmezőhöz tartozó változókkal vagy tömbökkel akarjuk megoldani, általában értékadó utasításokat kell végrehajtatnunk, amelyek a megfelelő változókat a közös adatmezőbe továbbítják. Ha tömbökről van szó, ez többszörös ciklusok beépítését teheti szükségessé, ami általában már nem gazdaságos. Ilyenkor tehát kívánatosabb a paramétercserével dolgozni, mert a tömbparaméterek átvétele nem jár az összes tömbelem áthelyezésével.
További szempontot ad a dinamikus indexhatárok alkalmazásának lehetősége (lásd a 5.4. pontot). Tudjuk, hogy dinamikus indexhatárokat csak formális paraméter tömbnek lehet adni, common tömbnek nem. Amennyiben tehát dinamikus tömbméret megállapítása válik szükségessé, az ilyen tömböt okvetlenül formális paraméterként kell kezelni.
Összefoglalva, ha egy szegmens egy programban valamennyi aktivizálása során mindig ugyanazon változón vagy tömbön végez műveleteket és eközben mérete sem változik, akkor az ilyen változót vagy tömböt célszerűbb közös adatmezőbe tenni. Ha viszont a szegmens különböző aktivizálások során más és más azonosítóval ellátott objektumokon operál, vagy a tömbméretet dinamikusan kell deklarálnunk, akkor a tömböt formális paraméterként kezeljük.
Ehhez még annyit kell hozzátennünk, hogy "közhasználatra" bocsátott matematikai eljárások, szubrutinok FORTRAN programjaiban lehetőség szerint kerüljük közös adatmezők deklarálását, mert az ilyen szubrutin beépítésekor külön kell gondoskodnunk a behívó szegmensekben az azonos nevű közös adatmező deklarálásáról.
5.6. Közös adatmezőkben szereplő változók kezdőértékének beállítása
BLOCK DATA szegmensek
Említettük az előző pontban, hogy common változóknak közönséges programszegmensekben nem szabad DATA utasítással értéket adni. A jelen pontban a common változók kezdőértékének megadási módját ismerjük meg.
A common változók kezdőértékének beállítására a FORTRAN nyelv egy speciális szegmensfajtát definiál, az ún. BLOCK DATA szegmenst, melynek az a specialitása, hogy nem tartalmaz végrehajtható utasításokat. A szegmensnyitó utasítás
BLOCK DATA
Mint látható, ez az utasítás annyiban is különleges, hogy nem szerepel benne szegmensnév.
A fordítóprogramok - a gépi reprezentációtól függő módon - a BLOCK DATA szegmens részére fiktív szegmensnevet generálnak, amely pl. megegyezhet a szegmensben szereplő első közös adatmező nevével.
A szegmensnyitó utasítást követően a BLOCK DATA szegmens ugyanúgy folytatódik, mint egy közönséges szegmens: szabályos deklarációs rész következik, mely értelemszerűen mindig tartalmaz COMMON és DATA utasításokat. A deklarációs részt közvetlenül az END utasítás követi; végrehajtható utasítások a szegmensben nem lehetnek.
1. példa :
Tegyük fel, hogy az XXXX nevű közös adatmezőbe kívánunk kezdőértékeket elhelyezni: az X tízelemű vektor minden egyes elemét 1.0-val, az Y ötelemű vektor elemeit pedig rendre 1.0; 2.0; 3.0; 4.0 és 5.0 értékekkel kívánjuk feltölteni. A feladatot a következő BLOCK DATA szegmens oldhatja meg:
BLOCK DATA
COMMON/XXXX/X(10),Y(5)
DATA X(1),X(2),X(3),X(4),X(5),X(6),
1X(7),X(8),X(9),X(10)/10*1.0/,
2Y(1),Y(2),Y(3),Y(4),Y(5)/1.0,2.0,3.0,
34.0,5.0/
END
Ez a példa némileg rámutat az ASA FORTRAN DATA utasításának hiányosságára: a beállítandó változók teljes listáját fel kell sorolni, nem írhatunk a listába tömbazonosítót. A gépi reprezentációk ezt általában pótolják; többnyire megengedett a következő tömör írásmód is:
BLOCK DATA
COMMON/XXXX/X(10),Y(5)
DATA X/10*1.0/Y/1.0,2.0,3.0,4.0,5.0/
END
Sőt, van olyan gépi reprezentáció is, amelyben a DATA utasításban megengedettek ún. összetett listaelemek, amelyeket az ASA FORTRAN ki- és beviteli utasításokban használ (lásd a Hatodik fejezet 2. pontját).
2. példa:
Szerepeljen a program valamelyik - nem BLOCK DATA - szegmensében a következő deklaráció:
SUBROUTINE MASIK (...)
...
COMMON/BLOKK/A(5),B(5),C(5)
Kezdőértéket akarunk adni az A vektor első és a C vektor utolsó elemének: A(1)-nek az 5.0, C(5)-nek pedig a 3.35 értéket. A feladat BLOCK DATA szegmens írása, amely elvégzi ezt az értékadást.
BLOCK DATA
DIMENSION B(13)
COMMON/BLOKK/A,B,C
DATA A,C/5.0,3.35/
END
A példa több dolgot kíván illusztrálni. Először is emlékeztet arra, hogy különböző szegmensekben - és ez a BLOCK DATA szegmensre is vonatkozik - az azonosítókat eltérő módon is használhatjuk, és jogunk van a közös adatmezők "átszervezéséhez" is. Mint látható, éltünk is ezzel a joggal, és az A és C azonosítókat vektor helyett skalárok azonosítására használtuk fel, a B vektort pedig "átméreteztük". A BLOCK DATA szegmensbeli A, a közös adatmezők megfeleltetési szabályai szerint, a MASIK szegmens A(1)-ének, a BLOCK DATA-beli C pedig MASIK C(5)-jének felel meg. A DATA utasítás tehát a megfelelő helyre teszi be az értékeket.
A másik érdekesség, amelyre fel kívánjuk hívni a figyelmet, a B azonosítónak puszta jelenléte a BLOCK DATA szegmensben. Észrevehetjük, hogy B nem lép fel a DATA utasításban, egyetlen feladata a helykitöltés. Alkalmazása nem meglepő, hiszen eleve tudjuk, hogy a nem blank közös adatmezőket mindig azonos méretűnek kell deklarálni, és B ezt biztosítja. Látjuk tehát, hogy ha egy közös adatmező nem minden változójának akarunk kezdőértéket adni, a BLOCK DATA szegmensben helykitöltő változók deklarálása válhat szükségessé. Egyébként nemcsak BLOCK DATA szegmenseknek lehetnek helykitöltő változói; előfordulhat, hogy valamely szegmens egy közös adatmezőt csak részben használ, mégis - a méretek egyeztetése és a változók közti helyes megfeleltetés biztosítása érdekében - helykitöltő változókat kell deklarálnunk.
A BLOCK DATA szegmensben ekvivalenciákat is deklarálhatunk, de erre ritkábban van szükség. Ekvivalenciák általában úgy kerülnek a BLOCK DATA szegmensbe, hogy valamelyik másik szegmens deklarációs részét egyszerűen bemásoljuk a BLOCK DATA utasítás alá, és ezt egészítjük ki a kezdőérték adó DATA utasítással, (Ez ugyanis a BLOCK DATA szegmens készítésének egyik standard technikája. Természetesen olyan szegmenst kell választani, amelyben minden érintett közös adatmező szerepel.)
Kezdőérték adást az ASA FORTRAN csakis nem blank adatmezőkhöz tartozó változókra nézve enged meg. Blank közös adatmezőkhöz tartozó változóknak kezdőértéket adni még BLOCK DATA szegmensben is tilos.
5.7. Szegmensnevek alkalmazása aktuális és formális paraméterként
Az EXTERNAL utasítás
Eddigi tárgyalásainkban csupa olyan SUBROUTINE és FUNCTION szegmenst láttunk, amelynek formális paraméterei skaláris változók vagy tömbök, bár az 5.3. pontban jeleztük, hogy a formális, ill. aktuális paraméterek között szegmens-azonosítók is előfordulhatnak. Ebben a pontban szegmensazonosítók paraméterként történő felhasználásának szabályaival ismerkedünk meg.
Felvetődik a kérdés, hogy mi teszi egyáltalában szükségessé szegmenseknek paraméterként történő alkalmazását. Ennek szükségessége leggyakrabban úgy merül fel, hogy egy olyan szubrutint kívánunk írni, amely valamely előre nem meghatározott függvényen operál. Ilyen például egy transzcendens egyenletet megoldó program, amely tetszőleges megoldandó egyenlet esetén működésképes kell hogy legyen. Egy ilyen szubrutin természetesen hívja a bal oldali függvényt generáló FUNCTION szegmenst. Szerepelnek tehát benne F(X) alakú függvényhivatkozások, azonban az, hogy milyen konkrét függvényt jelent az F azonosító, csak akkor határozódik meg, amikor mellékeljük az F-et generáló szegmenst. Első pillanatban úgy tűnik, hogy ezt a feladatot eddigi ismereteink alapján is meg tudjuk oldani, hiszen nem kell mást tennünk, mint megírni az F FUNCTION szegmenst, és hozzácsatolni az egyenletmegoldó szubrutinhoz. Ha azonban ugyanazon programon belül ugyanazt az egyenletmegoldó szegmenst két különböző bal oldali függvényre - mondjuk F-re és G-re - alkalmazni kívánjuk, már baj van, mert ha az egyenletmegoldó szegmensben a bal oldali függvényt F-fel jelöltük, nem tudjuk megértetni a géppel, hogy másodszor ne az F-en, hanem a G-n operáljon.
Ezzel tehát ismét elérkeztünk a korábbról már ismerős "átkeresztelési" problémához, amelynek megoldását, mint láttuk, az aktuális-formális paramétercsere adta meg.
Lássunk mindjárt egy konkrét példát! Írjunk SUBROUTINE szegmenst, amely a húrmódszer alapján megoldja az f(x) = 0 egyenletet. Mint ismeretes, a húrmódszer alkalmazásához két kezdőértékre van szükség, mondjuk a-ra és b-re, mégpedig úgy, hogy f(a)>0 és f(b) < 0 (vagy fordítva) teljesüljön. A húrmódszer iterációs eljárás, amelyben a gyök soron következő közelítését a függvény e két pontját összekötő húr és az x-tengely metszéspontjaként állítjuk elő (lásd az ábrát!).
Az iterációs formula a következő:
(i = 1, 2, ...; x0 = a)
A formulához fel kell tenni, hogy f(x) első és második deriváltja az [a, b] intervallumban sehol sem tűnik el, és hogy f(a) és f(x1) egyező előjelűek (ellenkező esetben b helyett a írandó). Az iteráció a "lassan, de biztosan" konvergáló eljárások körébe tartozik. Az ezt az eljárást realizáló FORTRAN szegmens a következő lehet:
SUBROUTINE SOLVE(A,B,X,F,EPS,N,SIKER)
LOGICAL SIKER
SIKER = .TRUE.
N = 0
FA = F(A)
FB = F(B)
IF(FA*FB) 1,2,3
3 SIKER = .FALSE.
RETURN
2 X = A
IF(ABS(FB).LT.ABS(FA))X = B
RETURN
1 N = 1
XE = (A*FB - B*FA)/(FB-FA)
BX = B
IF(F(XE)*FA) 4,5,5
4 BX = A
FB = FA
C ELOKESZITES VEGE, ITERACIO KEZDETE
5 N = N+1
FE = F(XE)
X = (XE*FB-BX*FE)/(FB-FE)
IF(ABS((XE-X)/X).LT.EPS) RETURN
XE = X
GO TO 5
END
Az iterációs formula egyszerűsége ellenére a program nem olyan egyszerű, mint első pillanatban várná az ember. Ennek oka, hogy az eljárás megbízható működése érdekében a programba néhány aprólékos adminisztratív manipulációt is be kellett iktatnunk. Ezek egyike a kezdőértékek ellenőrzése. Ha az A és B kezdőértékek helyén a függvényértékek azonos előjelűek, az eljárás eredménytelenül azonnal véget ér. Az eredménytelenséget a SIKER logikai kimenő paraméter FALSE állapota jelzi. Ebben az esetben az X és N kimenő paraméterek értéke (utóbbi az iterációs lépéseket számlálja) határozatlan marad.
Amennyiben véletlenül az A és B kezdőértékek valamelyike éppen a pontos gyök volna, a program nem kezd iterálni, hanem szintén azonnal kilép a szegmensből, de ezúttal természetesen SIKER egyenlő TRUE-val, hiszen a gyökmeghatározás eredményes volt. Minthogy azonban iterációra nem került sor, az N kimenő paraméter értéke zérus.
Az X változó a mindenkori xi+1-et, az XE változó pedig a mindenkori xi-t tárolja. A még korábbi iteráltak az iteráció folyamán nem őrződnek meg.
Ennyit magáról az eljárásról, és most lássuk, hogyan lehet SUBROUTINE szegmenst a gyakorlatban használni?
Oldjuk meg a SOLVE egyenletmegoldó program segítségével a következő két transzcendens egyenletet:
xe^x - 1=0
és
tg x - x = 0
Az első egyenletnek x = 0.5 és x = 1.0 között, a másodiknak pedig x = 3.2 és x=4.6 között van egy-egy gyöke, tehát kezdőértéknek ezek az értékek választhatók. A megkívánt pontosság mindkét gyökre legyen 10^-6, tehát ezt az értéket válasszuk EPS-nek. A megoldásokat a GYOK1, ill. GYOK2 változóknak, az iterációs lépésszámokat az N1, ill. N2 változóknak adjuk át. A "válaszparaméterek" legyenek a logikai típusú BOOLE1 és BOOLE2 változók. A megoldandó egyenletek bal oldali függvényeit generáló FUNCTION szegmensek azonosítói legyenek EQ1 és EQ2.
PROGRAM KOCSOG
LOGICAL BOOLE1,BOOLE2
EXTERNAL EQ1,EQ2
CALL SOLVE(0.5,1.0,GYOK1,EQ1,0.1E-5,N1,BOOLE1)
CALL SOLVE(3.2,4.6,GYOK2,EQ2,0.1E-5,N2,BOOLE2)
IF(.NOT.BOOLE1.OR.NOT.BOOLE2) STOP 01
WRITE (...) N1,GYOK1,N2,GYOK2
STOP
...
END
FUNCTION EQ1(X)
EQ1 = X*EXP(X)-1
RETURN
END
FUNCTION EQ2(X)
EQ2 = SIN(X)/COS(X) - X
RETURN
END
A PROGRAM szegmens lényeges része a két CALL utasítás, amely kétszer egymásután behívja a SOLVE húrmódszerrel dolgozó szubrutint, a két egyenlet megoldására. Az F formális paraméternek első esetben EQ1, második esetben EQ2 felel meg. A program a kiszámított GYOK1 és GYOK2 megoldások, valamint az N1 és N2 lépésszámok kinyomtatásával ér véget. A programban úgyszólván ránézésre minden világos, csupán a PROGRAM szegmens harmadik sorában találunk egy ismeretlen utasítást, az EXTERNAL-t. Kérdés, mit jelent ez, és hogyan kell használni?
Formálisan az EXTERNAL utasítás az EXTERNAL alapszóból és egy listából áll.
EXTERNAL u1, u2, ..., un
A lista elemei szegmensazonosítók (nem okvetlenül FUNCTION szegmensek azonosítói).
Az EXTERNAL listára azokat a szegmensazonosítókat kell felvenni, amelyek valamely szegmens aktivizálásában aktuális paraméterként szerepelnek. EQ1 és EQ2 példánkban ilyen szegmensek. Jól jegyezzük meg, hogy az EXTERNAL utasítás mindig a behívó, nem pedig a behívott szegmensben szerepel. Ez utóbbi szabály főként az ALGOL nyelv ismerői számára tűnhet szokatlannak, az ALGOL-ban ugyanis az EXTERNAL utasítás analógiája a specifikációs részben szereplő procedure specifikáció, ez azonban az aktivizált, és nem az aktivizáló eljárásban van elhelyezve.
Az EXTERNAL utasításra a CALL utasítások helyes lefordításához van szükség. Az aktuális paraméterként fellépő szegmensazonosítóról ugyanis a fordítóprogram semmi módon nem tudná felismerni, hogy az nem egy eddig nem szerepelt skaláris változó. A zavart az okozza, hogy amikor a szegmensazonosító aktuális paraméterként szerepel, elveszti azokat az ismérveket, amelyek alapján a fordítóprogram őt egyébként fel szokta ismerni. Az idegen szegmens azonosítójának ismérvei ui. a CALL alapszó (SUBROUTINE szegmensek esetén), ill. az azonosítót követő bal zárójel (FUNCTION szegmensek esetén). A bal zárójel természetesen utalhatna indexes változóra is, ebben az esetben azonban a változónak valahol kellene hogy legyen egy tömbdeklarációja. Ennek hiányában a fordítóprogram szegmensazonosítót vélelmez. (Ebből következik, hogy a tévedésből nem deklarált tömböket a fordítóprogram gyakran FUNCTION szegmens azonosítójának értelmezi, és nem jelzi hibaként.)
Amikor a szegmensazonosító aktuális paraméterként lép fel, az említett ismérvek egyike sem fordul elő, így szükség van valamiféle kiegészítő információra, amely közli a fordítóprogrammal, hogy itt szegmensazonosítóról van szó.
Természetesen, ha a fordítóprogramnak egyszerre adnák oda az összes lefordítandó szegmenst, akkor a szegmensek összessége alapján felismerné a szegmensazonosítókat. Csakhogy éppen külön-külön adják a szegmenseket fordítani, és a szegmensenkénti fordíthatóság elve következtében gondoskodni kell arról, hogy egyetlen magában álló szegmensről is helyes fordítás készüljön. Ez a pontos magyarázata az EXTERNAL utasítás bevezetésének.
Az EXTERNAL utasítás bárhol előfordulhat a szegmens deklarációs részében.
Mint mondtuk, az EXTERNAL listán csakis szegmensazonosítók szerepelhetnek. Emlékeztetünk rá, hogy az utasításfüggvények azonosítói nem szegmensazonosítók, minthogy az utasításfüggvények nem számítanak szegmensnek. Ezek azonosítója tehát nem szerepelhet EXTERNAL utasításban, és utasításfüggvény nem is adható meg aktuális paraméterként, ha a megfelelő formális paraméter FUNCTION szegmens azonosítója. Ezért, bármilyen rövidek is a példában EQ1 és EQ2 programjai, nem deklarálhattuk azokat utasítás függvényként.
A standard könyvtári függvények közül a külső standard függvények azonosítói szegmensazonosítónak számítanak, és ezért szerepelhetnek aktuális paraméterként és EXTERNAL utasításban. Ezzel szemben a belső standard függvények azonosítói lényegében úgy viselkednek, mint az utasítás függvények, tehát nem lehetnek szubrutinhívás aktuális paraméterei, és nem szerepelhetnek EXTERNAL utasításban. Ez a külső és belső standard függvények között a programozót érintő egyetlen lényeges különbség.
5.8. Szabályok az azonosítók használatára és az aktuális értékek meghatározására
Az előző fejezetekben megismert szabályok nagyrészt tartalmazzák az azonosítók használatára vonatkozó rendelkezéseket, mégis hasznosnak véljük ezen szabályok külön összefoglalását. Ugyancsak hasznosnak látszik azoknak az effektusoknak az összefoglalása, amelyek meghatározhatnak - vagy éppenséggel határozatlanná tehetnek - egy azonosítóhoz rendelt értéket. Mivel a ki- és beviteli utasításoknak is lehet ilyen hatása, itt említünk meg néhány ezekre vonatkozó szabályt is, bár tárgyalásukra csak a következő - Hatodik - fejezetben kerül sor.
Mint tudjuk, az azonosítókat két alapcsoportba sorolhatjuk. Ezek:
A szegmensen belüli azonosítók jellemzője, hogy csak a szegmens "határain" belül érvényesek, minden szegmens önálló értelmet tulajdoníthat nekik, és a különböző szegmensekben érvényes értelmezésük egymástól teljesen független.
A szegmensközi azonosítók ezzel szemben nem definiálhatók különböző szegmensekben egymástól függetlenül; egy adott szegmensben meghatározott definíciójuk más szegmensekre is kihat.
Az azonosítók használatára vonatkozó főbb szabályokat táblázatokban foglaltuk össze. A táblázatok oszlopaiban az utasítástípusok, soraiban pedig az azonosító fajták állnak. A sorok és oszlopok kereszteződésében álló "+" jel azt jelenti, hogy az adott azonosító fajta az adott utasítástípusban használható, a "-" jel pedig azt jelenti, hogy nem használható. A zárójelben álló számok a táblázathoz fűzött megjegyzések valamelyikére utalnak.
A változók értékének meghatározására vonatkozó szabályokat összefoglalandó, emlékeztetünk a változók értékét meghatározó operációkra. Ezek a következők:
a) értékadó utasítás végrehajtása;
b) DO utasítás végrehajtása és összetett cikluslista elem értelmezése (lásd Hatodik fejezet);
c) beolvasási utasítások végrehajtása (lásd Hatodik fejezet);
d) ASSIGN utasítás végrehajtása;
e) közös adatmezőn keresztül történő adatcsere;
f) ekvivalenciák által meghatározott megfeleltetés révén történő adatcsere;
g) aktuális-formális paramétercsere;
h) kezdőérték megállapítása DATA utasítás segítségével.
Az a) - d) alatti operációk közös jellemzője, hogy ezekben az érték meghatározása explicit módon megy végbe; az utasításban minden esetben magának a meghatározandó változónak az azonosítója szerepel. Ezzel szemben az e) - g) utasítások az érintett változó valamelyik hozzárendeltjének értékét változtatják meg és ez közvetve hat vissza az érintett változó értékére. Ez utóbbi esetben implicit értékmeghatározásról beszélhetünk. A h) alatti értékmeghatározás lehet explicit is és implicit is.
A szegmensen belüli azonosítók használata
Azonosító |
Típisdekl. | DIMENSION | COMMON | EQUIVAL. | DATA | EXTERNAL | Egyéb végrehajtó | Aktuális param. |
utasításban |
||||||||
| Formális maraméter Tömb és indexes vált. Skaláris változó Szegmensazonosító |
+ (1) + + (2) |
+ (1) - - |
- - - |
- - - |
- - - |
- - + |
- + + (4) |
+ + + (3) |
| Nem formális paraméter COMMON Tömb és indexes vált. Skaláris változó |
+ + |
+ - |
+ + |
+ (5) + (5) |
+ (6) + (6) |
- - |
+ + |
+ + |
| Nem formális araméter és nem COMMON Tömb és indexes vált. Skaláris változó Utasításfüggvény |
+ + + |
+ - - |
- - - |
+ - - |
+ - - |
- - - |
+ + + |
|
Megjegyzések a táblázathoz:
A szegmensközi azonosítók használata
Azonosító |
SUBROUTINE FUNCTION |
Típus deklaráló |
EXTERNAL |
Egyéb deklaráló |
Egyéb végrehajtó (6) |
Aktuális paraméterként |
utasításban |
||||||
| Belső standard függvény | - |
+ (2) |
- |
+ (1) |
+ (5) |
- |
| Külső standard függvény | + (1) |
+ (2) |
+ |
+ (1) |
+ (5) |
+ (3) |
| FORTRAN szegmens azonosítója | + |
+ (2) |
+ |
- |
+ |
+ |
| Közös adatmező neve | - |
+ (4) |
- |
+ (4) |
+ (4) |
+ (4) |
Megjegyzések a táblázathoz:
Változók egymáshoz rendelését az aktuális-formális paramétercsere, valamint a COMMON és az EQUIVALENCE utasítás hozhatja létre. A FORTRAN nyelv szabályai az explicit és az implicit értékmeghatározás hatását általában egyenértékűnek tekintik. Erre vonatkozik az az alapvető szabály, amely szerint egy adott változó értékének explicit meghatározása maga után vonja valamennyi azonos típusú hozzárendelt változó értékének implicit meghatározását. Hangsúlyozzuk, hogy ez csak az azonos típusú hozzárendelt változókra vonatkozik. Az eltérő típusú hozzárendelt változók értéke az explicit értékadással egyidejűleg meghatározatlanná válik.
Egyetlen megszorítás terheli az implicit értékadást: indexként, valamint kijelölt GOTO utasításban használt változó értékét csak explicite szabad meghatározni; ilyen célú felhasználás szempontjából az implicite meghatározott változó értéke határozatlannak tekintendő.
Az értékek meghatározására, ill. határozatlanná tételére vonatkozó fontosabb szabályok a következők:
5.9 Előre definiált alprogramok
A 2.4. pontban megismert aritmetikai függvényeken felül a FORTRAN rendelkezik néhány további előre definiált eljárással és függvénnyel.
A RAN függvény egy véletlenszám-generátor A generált véletlen szám valós típusú 0 és 1 közé eső (az egyet nem éri el) decimális szám. A függvényt pl. a következő utasítással hívjuk meg:
v = RAN(x)
ahol x REAL típusú változó, x a függvény paramétere. A paraméter előjele határozza meg elvileg, hogy milyen eljárás segítségével számítja ki az interpreter a következő (ál)véletlen számot:
Sajnos azonban bármilyen paraméterrel hívjuk meg, konstans értéket ad. Használható helyette a következő függvény:
FUNCTION RND(IY)
IY = IY*899
IF (IY .LT. 0) IY = IY + 32767 + 1
RND=FLOAT(IY)/32767.
RETURN
END
A függvény 5 számjegyű paraméterét a főprogramból kell bekérni, pl. az alábbi módon:
WRITE(1,99)
99 FORMAT(///,' RANDOM NUMBER (5 DIGITS) ')
READ(1,98) IX
98 FORMAT(I5)
A PEEK(x) függvény az INTEGER típusú argumentumként megadott sorszámú memóriacímen lévő 0 és 255 közé eső byte értékét adja vissza.
Az INP függvény közvetlen hozzáférést tesz lehetővé az I/O portokhoz. Az INP(x) lekérdezi a x port állapotát. x 0 és 255 közé eső 8 bites érték, ahogy az eredmény is.
A POKE eljárással egy tetszőleges memóriacímre közvetlenül beírhatunk 8 bites értéket. Alakja:
CALL POKE(i,b)
Az első INTEGER típusú paraméter a memória címet, a második 8 bites érték a tárolandó byte-ot adja meg.
Az OUT eljárás egy portra ír ki egy értéket:
CALL OUT(b1,b2)
Ami a b1 portra írja ki a b2 értéket. Mindkét paraméter 1 byte-os.
6.1. Perifériális egységek és külső tárolók
Könyvünk előző fejezeteiben megismertük a különböző FORTRAN utasításokat, valamint az adat- és változó deklarációk módozatait. Egy igen fontos témakör azonban még hátra van, mégpedig a perifériális egységekkel és a külső tárolókkal való adatcsere műveleteinek ismertetése. A megfelelő FORTRAN utasításokat a következő ponttól kezdve tárgyaljuk; a jelen pontban kissé elkanyarodunk a FORTRAN nyelvtől, és a számológépek perifériális egységeinek néhány olyan történeti tulajdonságát foglaljuk össze, amelyek ismeretére a későbbiekben szükségünk lesz.
Régebben általában élesen megkülönböztették, és a gép külön funkcionális egységének tekintették az ún. "perifériális" egységeket (lyukszalag- vagy lyukkártyaolvasó és -lyukasztó berendezések, sornyomtató stb.), valamint az ún. "külső tároló" egységeket (mágnesszalagos egységek, dob- és lemezmemóriák, lemezmeghajtók, stb.). Ez a megkülönböztetés egyre kevésbé indokolt, mert - mint látni fogjuk - mindezek az egységek programozástechnikai szempontból csaknem teljesen egyformán viselkednek.
Az első fogalom, amellyel a perifériákkal kapcsolatban meg kell ismerkednünk, a rekord. (A rekord szónak nincs elfogadott magyar megfelelője, így a szövegben kénytelenek vagyunk ezt használni.) Ezen az információnak valamely olyan egységét értjük, amelyhez a perifériális átvitelek folyamán - azaz a periféria "egyetlen működése során" - mindig csakis egészében férhetünk hozzá. Egy rekord pl. a lyukkártyás átvitelek esetében egy kártya, a sornyomtatón egy sor, a lyukszalagon az olvasóberendezést vezérlő két "soremelés" (newline, vagy line feed) karakter közti rész információtartalma stb. Rekordok formájában tároljuk az információt a mágnesszalagokon, mágneslemezen is, file-okban. A rekord tehát az a legkisebb információ-mennyiség, amelyet egy adott periféria egyszerre át tud vinni (a beolvasást és a kiírást a továbbiakban közös néven átvitelnek nevezzük).
A rekord szemléletes fogalmából is kitűnik, hogy egy adott perifériális egység rekordjaihoz nem akármilyen sorrendben férhetünk hozzá: a rekordoknak szigorúan kötött sorrendjük van. Ezt pl. kártyaolvasó esetében a lyukkártyák sorrendje, sornyomtatón a kinyomtatott sorok egymásutánja szabja meg. Ahhoz, hogy a periféria k-adik rekordját átvihessük, előzőleg át kell vinnünk (esetleg átugratnunk) az első k-1 rekordot, a k-adik rekord átvitele után pedig csak a k+1-edik rekord van számunkra közvetlenül hozzáférhető helyzetben. Ettől a kötött sorrendtől csak véletlen hozzáférésű háttértárral (ilyen a lemezmeghajtó) lehet eltérni.
A rekordról kialakult szemléletes képünkhöz az is hozzá tartozik, hogy a FORTRAN nyelv kifejleszésekor az átvitel sorrendje általában nem volt megfordítható; azaz ha a perifériális átvitel során egyszer eljutottunk egy adott rekordig, akkor az őt megelőző rekordokra nem térhetünk többé vissza. A lyukkártyaolvasó berendezés pl. az elolvasott kártyákat bedobja egy gyűjtőbe, ahonnan nem tudja újra elővenni. Hasonlóan nem tudja visszahúzni a lyukszalagolvasó az egyszer már beolvasott lyukszalag részt. Ez a tulajdonság azonban már nem bármely perifériális egységre jellemző, mert például a mágnesszalagos egységek képesek visszacsévélési (visszalépési) művelet végzésére, és így az egyszer már átvitt vagy átugratott rekordok újra hozzáférhetővé tehetők. Ennek megfelelően a FORTRAN nyelv tartalmaz visszalépési utasításokat is, ezeket azonban nyilván csak olyan perifériákra szabad kiadni, amelyek azt képesek végrehajtani.
Az olyan információtároló berendezéseket, amelyeken az egyes rekordok csak meghatározott sorrendben egymás után, vagy esetleg fordított sorrendben is elérhetők, soros hozzáférésű információhordozónak, soros hozzáférésű tárolónak nevezzük. Az ASA FORTRAN szempontjából minden perifériális egység soros hozzáférésű, a FORTRAN-80 azonban van lehetőség véletlen sorrendben elérni a rekordokat. Megjegyezzük, hogy a nagy elektronikus adatfeldolgozó rendszereknek is általában voltak ún. kötetlen hozzáférésű külső tárolói is, amelyekre az jellemző, hogy minden bennük tárolt információ - sorrendi kötöttség nélkül - bármely időpillanatban egyenlő mértékben elérhető. Ebbe a kategóriába tartoznak pl. a mágneslemez (disk) és mágnesdob memóriák. A kötetlen hozzáférésű külső tárolók - jellegüket tekintve - a központi memóriára emlékeztetnek, ui. általában számozott (címezett) memóriarekeszekre vannak felosztva, és az egyes rekeszek tartalma a címre való hivatkozás segítségével érhető el. A FORTRAN nyelv ilyen tárolók kezelésére nem ad direkt apparátust; ezt úgy kell érteni, hogy ha vannak egy gépnek kötetlen hozzáférésű külső tárolói, a FORTRAN felhasználó számára ezek is soros hozzáférésűek, az információt valóságos műszaki tulajdonságaiktól függetlenül - esetleg definíciószerűen meghatározott - rekordokban tárolják. Tehát ebben az esetben a gép programrendszere szimulálja a programozó számára a soros elérésű tároló tulajdonságait. (Megjegyezzük, hogy ez nem feltétlenül előny.)
A perifériális átviteli utasításokat minden esetben - egy vagy több - teljes rekordra adjuk ki. Egy rekord általában (de nem feltétlenül) egynél több adatot tartalmaz. Egy lyukkártyáról pl. nemcsak egy, hanem több változó értékét is beolvashatjuk, a sornyomtató egy sorában pedig egynél több számot is kiírathatunk.
A FORTRAN nyelv szempontjából az információ tárolásának két formáját különböztetjük meg. Az egyiket karakterformának, a másikat bináris formának nevezzük. A bináris forma angol neve "unformatted", a karakterformáé "formatted". A magyar szaknyelvben az előbbit "kötetlen formátumú" vagy "formázatlan", az utóbbit pedig "kötött formátumú" vagy "formázott" információábrázolásnak szokták nevezni. Ezeket az elnevezéseket nem tartjuk szerencsésnek, mert nem fejezik ki eléggé a fogalom lényegét.
A karakterforma az információnak az a megjelenési módja, ahogyan az a gép külső egységein (lyukkártya, lyukszalag, sornyomtató) megjelenik. A karakterformájú információ alfanumerikus jelekből (vagyis betűk, számok, írásjelek és vezérlő karakterek) áll, és vagy közvetlenül "olvasható" (pl. a sornyomtatón), vagy "leíratható". Ezt a szemléletes képet ki kell azonban egészítenünk azzal, hogy karakterformájú információt tartalmazhatnak a gép külső tárolói (főként a mágnesszalagok), de a központi memória is. Ilyenkor az egyes karakterek (betűk, számok stb.) bizonyos bitkombinációkkal vannak kódolva. Minden számológépnek van egy ún. belső karakterkódja, amely azt határozza meg, hogy az illető gép jelkészletében létező karaktereket milyen módon ábrázoljuk nullák és egyesek segítségével. Egy karaktert a belső kódban általában 6-8 bitből álló jelsorozatokkal ábrázolunk. A karakterformájú információt szokás még BCD (Binary Coded Decimai, binárisan kódolt decimális) információnak is nevezni.
A karakterformával szemben megkülönböztetjük a bináris ábrázolásmódot. Ez elsősorban a központi memória ábrázolási rendszere, de megjelenhet a külső tárolókon is. A bináris információ nem karakterek egymás mellé állított kódjaiból áll, hanem olyan bináris jelsorozatokból, amelyeken a gép közvetlenül el tudja végezni az utasításrendszerében meghatározott műveleteket. (A számadatok az aritmetika által előírt formában ábrázoltak, a negatív számok a gépre jellemző - pl. komplementáris - ábrázolásban) A bináris ábrázolás-módban tárolt információ tehát - a karakterformájúval ellentétben - minden előzetes átalakítás (konverzió) nélkül felhasználható további számításokra. Éppen ezért a további számítások céljaira megőrzött számadatokat (közbülső és részeredmények) tároljuk ily módon, míg a karakterforma a be- és kimenő adatok ábrázolási módja. A FORTRAN nyelvben vannak utasítások mind bináris, mind karakterformájú információ átvitelére.
Karakterformájú, röviden karakterinformáció átvitele esetén az átvitt rekord mindig karakterek - fix vagy változó hosszúságú - sorozata. A karaktereket 1-től folytatólagosan megszámozzuk. Beszélhetünk egy rekord karakterpozícióiról; ezen az egyes karakterek "helyét" értjük a rekordon. A fix hosszúságú rekordokkal operáló tárolóegységekben minden rekordnak ugyanannyi karakterpozíciója van (pl. lyukkártya), a változó rekordhosszúságú tárolókban ez a szám változhat (lyukszalag). A kettő között előfordul egy átmenet is, mégpedig a maximált rekordhossz; itt a rekordoknak nem kell meghatározott hosszúságúaknak lenniük, de a karakterpozíciók száma nem haladhat meg egy előírt korlátot. Bizonyos gépi reprezentációkban ilyenek a mágnesszalagos egységek. Hangsúlyozzuk, hogy a rekordhosszt az illető gép vagy perifériális egység sajátságai szabják meg, nem pedig a FORTRAN nyelv definíciói. A CP/M operációs rendszer alatt a file rekordhossza 128 bájt (1 szektor). Ha a WRITE utasítás nem visz át elegendő adatot a rekord 128 bájtig történő kitöltéséhez, akkor a rekord vége nullákkal (NULL karakterekkel) lesz kitöltve.
Minden karakterinformáció átviteli utasításhoz meg kell adnunk bizonyos kísérő információt, amely beviteli utasítások esetén a rekord "szétosztásáról", kiviteli utasítások esetén pedig a rekord "összeállításáról" rendelkezik. Lényegében ez a kísérő információ határozza meg a kapcsolatot a beolvasandó (kiíratandó) programbeli változók, és az input (output) rekord karakterpozíciói között; másként szólva, ez adja meg a belső (bináris) és a külső (karakter) ábrázolás közti konverziós műveletekre vonatkozó utasításokat. Ezek az utasítások többek közt arra vonatkoznak, hogy hány tizedesjegyre kell kerekíteni a gép belsejében tárolt bináris végeredményt; milyen fejléceket és magyarázó feliratokat kell elhelyezni az eredménylapon; hol, és milyen formában találja a gép a beolvasandó számokat az input lyukkártyán; hol van olyan rész a szalagon, amelyet ki lehet hagyni. Mindez a segédinformáció összességében meghatározza a rekord formátumát és egyes részei specifikálják a karakterformáról a bináris formára vagy visszafelé való áttérés módozatait. A FORTRAN nyelvben a segédinformációt az ún. FORMAT utasítás tartalmazza, melynek szoros kapcsolata, kölcsönhatása van a megfelelő READ (beolvasás), ill. WRITE (kiírás) utasításokkal. Ennek a kölcsönhatásnak a szabályait a 6.5. pontban tárgyaljuk majd.
Bár a fentiekben általánosságban elmondottak a mágnesszalagos külső tárolóegységekre is vonatkoznak, ez utóbbiakkal röviden külön is foglalkozunk. Ezt az indokolja, hogy a mágnesszalagos egységeknek néhány olyan tulajdonsága van, amelyek egyéb külső tárolóknál és perifériáknál nincsenek meg. ilyen pl. a már említett visszalépési és újrabeolvasási lehetőség. A mágnesszalagos egységekkel kapcsolatban - de más külső tárolók esetében is - értelmezni szokták az információnak egy, a rekordnál magasabb egységét, melynek neve file. A file-t (akárcsak a rekordot) nehéz lenne szabatosan definiálni; ezen a fogalmon valamilyen értelemben összetartozó adatoknak több rekordból álló összességét értik. Szabatos definíció helyett inkább szemléletesen azt mondjuk, hogy file pl. egy mágnes-szalag tekercs, amelyen valamely program adatai vannak tárolva, vagy a mágneslemez memóriának egy adott program számára fenntartott része. A file azonosítására általában egy file-név, továbbá néhány egyéb adat szolgál, melyeknek célja, hogy kétséget kizáróan biztosítsák a file megkülönböztethetőségét minden más file-tól. Ennek jelentőségét megértjük, ha meggondoljuk, hogy nagyobb számolóközpontokban több száz, sőt több ezer mágnesszalag tekercset is tárolhatnak, és ezeknek pontosan és félreérthetetlenül azonosíthatóknak kell lenniük.
A file azonosítását biztosító információ mágnesszalagok esetében a file legelső rekordjában van elhelyezve. Ezt a rekordot - amely tehát nem adatokat hordoz, hanem csupán azonosítási célokra van fenntartva - header label-nek nevezzük. Az ide írandó információ megadásának módját, valamint a megadandó információ pontos tartalmát az egyes gépi reprezentációk kézikönyvei írják le; ezekre nézve az ASA FORTRAN nem tesz előírásokat.
Ugyancsak különleges szerepe van a file utolsó rekordjának, melynek neve trailer label. Ez a file végét jelzi, vagyis azt a körülményt, hogy a file-ban nincs több információs rekord. A trailer label írására külön FORTRAN utasítás van (ENDFILE - lásd a 6.3. pontot). A FORTRAN programokat úgy kell megszerkeszteni, hogy mielőtt a program futása bármely okból megáll vagy megszakad, az írásra használt mágnes-szalagokra trailer label kerüljön. Ennek hiányában a felírt információ visszaolvasásakor hibajelzés léphet fel. A trailer label írásának műveletét a file lezárásának nevezzük.
Végezetül megjegyezzük, hogy a trailer label megfelelője egyes egyéb információhordozókon is előfordul. Lyukkártya esetében pl. lezáró rekordnak szokás tekinteni az olyan lyukkártyát, amelynek első négy oszlopában egy-egy csillag karakter van, a többi karakterpozíciója pedig üres. Egyes gépi reprezentációs nyelvek definiálnak lezáró rekordot lyukszalagon is. Akárcsak a kártya esetében, itt is az "end of file" rekord bizonyos meghatározott karakterek egymásutánjából áll. A gép beolvasás után megvizsgálja, hogy a beolvasott rekord információs vagy end of file rekord-e, és ha programozási hiba folytán információs rekord helyett end of file rekordot talál, akkor hibajelzést generál.
6.2. A READ és WRITE utasítások szintaxisa és szemantikája
Az ASA FORTRAN mindössze két be- és kiviteli utasítást definiál, mégpedig egyet a beolvasásra (READ), egyet pedig a kiírásra (WRITE). Az ASA FORTRAN lényeges vonása, hogy bármilyen perifériális egységen történjék is az átvitel, annak vezérlését ugyanazok az utasítások végzik. Ez azt jelenti, hogy akár nyomtatjuk egy program eredményeit, akár szalagra lyukasztjuk, a kiíró utasítás mindenképpen a WRITE. Ez lényeges könnyítést jelent abban az esetben, ha egy programot át kell alakítani egyik perifériatípus használatáról egy másik típusú periféria használatára.
Ez a tulajdonsága azonban nem minden FORTRAN változatnak van meg; "egzotikus" változatokban pl. a nyomtatást a PRINT, a kártyalyukasztást a PUNCH, a mágnesszalagról történő be-, ill. kivitelt READ INPUT TAPE, ill. WRITE OUTPUT TAPE utasítások jelölik, és az itt felsoroltakon kívül további be- és kiviteli utasítások is definiálva vannak.
Szintaktikus szempontból a beolvasási és kiírási utasítások a következő alakúak:
READ (u,f,ERR=L1,END=L2) L
READ (u,f,ERR=L1,END=L2)
READ (u,f) L
READ (u) L
WRITE(u,f,ERR=L1,END=L2) L
WRITE(u,f,ERR=L1,END=L2)
WRITE (u,f) L
WRITE (u) L
A fentiekben u és f előjeltelen egész számok lehetnek, L pedig az ún. I/O lista (Az I/O az angol Input - Output (be- és kivitel) szópár rövidítése.) Ez utóbbi szintaxisára később térünk vissza. u lehet index nélküli egész változó is.
A fenti utasítások közül az 1-3., 5-7. alak karakterátvitelt, a második és negyedik pedig bináris átvitelt jelent. Ennek a pontnak a hátralevő részében főként az I/O lista szintaxisával és szemantikájával foglalkozunk, és ebből a szempontból nem lényeges, hogy bináris, vagy karakterátvitelről van-e szó, és hogy az "átvitel" beolvasást, vagy kiírást jelent-e. Mielőtt azonban rátérnénk az I/O lista részletes tárgyalására, röviden beszélnünk kell az utasításokban szereplő u, ill. f, L1, L2 számokról.
Az I/O lista nélküli alak - WRITE(u,f) - a FORMAT utasításban megadott karakterfüzérek írásra használható. Ebben esetben nincs szükség változólistára. Például:
WRITE(1,26)
26 FORMAT ('H CONVERSION')
Azt várnánk, hogy az ASA FORTRAN tartalmaz valamiféle deklarációs utasításokat, amelyek segítségével deklarálni lehetne a logikai perifériaszámok és a konkrét perifériális egységek egymáshoz rendelését. Ilyen utasításokat azonban az ASA FORTRAN-ban nem definiálnak; ezek az egyes gépi reprezentációs nyelvekben vannak megvalósítva. FORTRAN-80-ban a READ és WRITE utasítások automatikusan megnyitják az egységszámhoz tartozó eszközt, vagy az OPEN szubrutin kell használni. CP/M alatt az OPEN hívás alakja:
CALL OPEN (u,f,d)
ahol:
Példa:
CALL OPEN (6,11HCALENDARTXT,0)
Ha egy nem létező file-t nyitunk meg, az OPEN szubrutin egy null (üres) file-t hoz létre a kiválasztott meghajtón. Ha létező file-t nyitunk meg és szekvenciálisan írunk bele, törlődik a file meglévő tartalma. A FORTRAN-80 tartalmaz olyan nyelvi bővítést, amivel lemezmeghajtó esetében véletlenszerű sorrendben is elérhetjük a rekordokat: a READ vagy WRITE utasításban a REC=n paramétert kell megadnunk - END helyett. Pl.:
I = 10
WRITE (6,20,REC=I,ERR=50) X,Y,Z
A programrészlet a 10. rekordot írja a 6-os egységszámon megnyitott file-ba. Ha létezik egy korábbi 10. rekord, akkor azt átírja. Ha nem létezik a 10. rekord, a fájl kiterjesztésre kerül, hogy létrehozza az új rekordot. Bármilyen kísérlet nem létező rekord olvasására I/O hibát eredményez.
Az l/O listák szintaxisa és szemantikája
Formailag az L lista vagy egyetlen listaelemből, vagy listaelemek egymástól vesszővel elválasztott sorozatából áll, vagy pedig üres. A listaelemek kétfélék lehetnek, mégpedig: egyszerű listaelemek és belső ciklusutasítást tartalmazó - a továbbiakban összetett - listaelemek.
Egyszerű listaelemek lehetnek:
Egyetlen magában álló egyszerű listaelem, vagy egyszerű listaelemek egymástól vesszővel elválasztott sorozata alkothat egy ún. egyszerű I/O listát. Tehát egyszerű listának minden eleme egyszerű listaelem.
Példák egyszerű I/O listára:
A, B, Q(4,3), S, R(I,J)
G
Az első példa többelemű lista, a második egyelemű lista. A szereplő A, B, S és G azonosítók akár skaláris, akár indexes változók (tömbök) azonosítói lehetnek.
Összetett I/O listaelemhez oly módon juthatunk, hogy egy tetszőleges (tehát nem okvetlenül egyszerű) I/O lista után vesszőt teszünk, ezt követőleg egy ún. belső ciklus specifikációt helyezünk el, majd az így kapott jelsorozatot zárójelbe zárjuk.
A belső ciklus specifikáció alakja a következő:
l = m1,m2,m3
vagy
l = m1,m2
ahol l index nélküli egész változó, m1, m2, m3 pedig pozitív egész szám, vagy pozitív egész értékkel bíró egész változó lehet (vö. Harmadik fejezet 5, pont, DO utasítás). Példák összetett listaelemre:
(A, B, Q(4,3), S, R(l,J), J = 1,21,2)
(U(l), V(l), W(l), l = 1,N)
Mint látható, az első összetett listaelemet oly módon állítottuk elő a A, B, Q(4,3), S, R(I,J) egyszerű listából, hogy hozzáillesztettük a J = 1,21,2 típusú belső ciklus specifikációt, és a kapott jelsorozatot zárójelbe zártuk. Hasonlóan, a második összetett listaelem egy háromelemű egyszerű listából, és egy hozzáillesztett I = m1,m2 típusú belső ciklus specifikációból áll.
Az összetett I/O listaelemek ugyanúgy használhatók I/O listák felépítésére, mint az egyszerűek. Az olyan listát, amelynek van összetett eleme, összetett I/O listának nevezzük. Példák összetett I/O listákra:
(A(l), l = 1,M), (B(l), l = 1,M)
X, Y, (G(K), K = l,J,2)
Az első lista két összetett elemből, a második lista pedig két egyszerű, és egy összetett elemből áll.
Ezzel lényegében felsoroltuk az I/O listák megszerkesztésével kapcsolatos szintaktikus szabályokat, azonban az eddig elmondottak további, összetettebb kombinációk létrehozását is lehetővé teszik.
Az összetett listaelem definíciójakor azt mondottuk, hogy képzésében nem okvetlenül egyszerű listából kell kiindulnunk. Nézzük meg most, milyen jelsorozat jön létre, ha egy összetett listaelem előállításához összetett listából indulunk ki? Tekintsük pl. a (A, B, Q(4,3), S, R(I,J), J = 1,21,2) összetett listaelemet, amelyet felfoghatunk egyelemű összetett listaként is. Hajtsuk végre az összetett listaelem előállítására leírt eljárást: tegyünk a lista után vesszőt, illesszünk hozzá egy belső ciklus specifikációt, majd zárjuk az így kapott jelsorozatot zárójelbe! Az eredmény egy "kétszeresen összetett" listaelem:
((A, B, Q(4,3), S, R(l,J), J = 1, 21,2), l = 1,22,7)
A szintaxisból nyilvánvaló, hogy ezt az eljárást akárhányszoros mélységben tovább lehetne folytatni.
Hasonlóan képezhetünk összetett listaelemet a (A(l), I = 1,M), (B(l), I = 1,M) összetett listából:
((A(l), l = 1,M), (B(l), l = 1,M), K = 1,5)
Végül egy harmadik példa, melyhez hasonlók a gyakorlati programozásban igen gyakran fordulnak elő:
(K, (J, (l, (A(I,J,K)), l = 1, N), J = 1,M), K = 1,L)
Befejezésül még egy rövid szintaktikai megjegyzés: az I/O listák szintaxisa (ellentétben pl. az aritmetikai kifejezések szintaxisával) nem tűri a redundáns zárójelek alkalmazását. Ez alól egyetlen kivétel van: nem számít szintaktikus hibának, ha az egyszerű I/O listákat egyetlen (de csakis egyetlen) redundáns zárójelpárral vesszük körül. Tehát szintaktikusan helyes pl. a következő READ utasítás:
READ (5) (A, B, C)
viszont már szintaktikusan hibás
READ (5) ((A, B, C))
Áttérünk most az I/O listák szemantikájának tárgyalására.
Az I/O listák mindig be- és kiviteli utasítások részei, mégpedig kijelölik az átvitelben résztvevő számadatokat (amelyek mindig bizonyos programbeli változók aktuális értékei), beleértve a sorrendiséget is.
Az I/O listák pontos értelmezését a következő szabályok adják:
Van egy negyedik szabály is, amely az összetett I/O listaelemekre vonatkozik.
Példák:
1. Tekintsük a következő kiírási utasítást:
WRITE (5) F,G,A
ahol F és G skaláris változók, A pedig 3x3-as tömb. E feltevés mellett a példa összesen 11 szám kiírását jelenti. Az output periférián az aktuális értékek a következő sorrendben jelennek meg: F, G, A(1,1), A(2,1), A(3,1), A(1,2), A(2,2), A(3,2), A(1,3), A(2,3), A(3,3). A kiírás után valamennyi változó aktuális értéke változatlan marad.
2. Legyenek R és Q mindketten x2-es tömbök. Ekkor a
READ (4) R,Q
beolvasási utasítás összesen 8 szám beolvasását írja elő. Az input periférián soron következő nyolc szám beolvasódik az R(1,1), R(2,1), R(1,2), R(2,2), Q(1,1), Q(2,1), Q(1,2), Q(2,2) tömbelemekbe. Már e helyen nem árt felhívni a figyelmet arra, hogy bármilyen beolvasási műveletről legyen is szó, a bemenő adatokat úgy kell előkészíteni a program számára, hogy azok az input információhordozón a megfelelő sorrendben kövessék egymást (példánkban előbb az R tömb, majd a Q tömb elemeit kell felvinnünk, mindkettőt oszlopfolytonosan).
Az összetett I/O-listák szemantikájának tisztázása céljából először az összetett I/O listaelemek szemantikájával foglalkozunk.
Mint már láttuk, az összetett I/O listaelem formálisan a következő alakú:
(L, l = m1,m2,m3)
illetőleg
(L, l = m1,m2)
Az összetett listaelemek csoportos átvitel végrehajtására szóló utasítást jelentenek, a következők szerint:
A fentiekből kitűnik, hogy az összetett l/O listaelemek értelmezése teljesen analóg a DO utasítások szemantikájával.
Példák:
1. Tekintsük a (U(l), V(l), W(l), l = 1,N) összetett cikluslista-elemet:
Ennek értelmezése a következő:
- Az I ciklusváltozó felveszi az m1 értéket, esetünkben 1-et.
- Ezen aktuális érték mellett átvitelre kerülnek az l/O lista elemei, nevezetesen U(1), V(1) és W(1).
- Minthogy példánkban a belső ciklus specifikáció I = m1,m2 típusú, a ciklusváltozó értéke eggyel növelődik.
- Megvizsgálódik, hogy I értéke meghaladta-e már az N-et (feltesszük pl., hogy N = 5).
- Mivel még nem haladta meg, visszatérés a 2. pontra; ennek végrehajtása ezúttal az U(2), V(2) és W(2) elemek átvitelét jelenti.
- Az átvitel addig folytatódik, míg I el nem érte az N = 5 értéket (az átvitel még ezzel az értékkel is végrehajtódik).
Végeredményben - feltéve, hogy N = 5 -, az összetett cikluslista-elem az U, V és W vektorok elemeinek a következő sorrendű átvitelét jelenti: U(1), V(1), W(1), U(2), V(2), W(2), U(3), V(3), W(3), U(4), V(4), W(4), U(5), V(5), W(5).
2. Tekintsük (A, B, Q(4,3), S, R(I,J), J = 1,21,2)-et, és legyen I aktuális értéke 8. Ezen feltevés alapján a listaelem értelmezése a következő:
- J felveszi a kezdőértéket, 1-et.
- Átvitelre kerülnek az I/O lista megfelelő elemei: A, B, Q(4,3), S és R(8,1).
- J értéke összehasonlítódik az előírt végértékkel, 21-gyei. Az összehasonlítás eredménye negatív; J a végértéket még nem haladta meg.
- J értéke megnövelődik a növekményparaméter értékével, 2-vel. Adódik J = 3.
- Átvitelre kerülnek a J = 3-nak megfelelő listaelemek. Ezek: A, B, Q(4,3), S és R(8,3).
- A leírt eljárásnak a fentiek szerinti ismétlésével az l/O listaelem az átvitel következő sorrendjét írja elő:
A, B, Q(4,3), S, R(8,1),
A, B, Q(4,3), S, R(8,3),
A, B, Q(4,3), S, R(8,5),
...
A, B, Q(4,3), S, R(8,21).Az eredményt közelebbről megvizsgálva észrevesszük, hogy az I/O listának azok az elemei, amelyek nem függnek a J ciklusváltozótól, többször is átvitelre kerülnek, míg azok, amelyek függnek a ciklusváltozótól, csak egyszer. Ezért általában a belső ciklust elsősorban olyan listaelemekkel kapcsolatban alkalmaztuk, amelyek függnek a ciklusváltozótól, de ha célunk ugyanannak az elemnek többszöri átvitele, akkor ettől el is térhetünk.
3. Tekintsük a következő l/O listaelemet, mely az első példában vizsgált (U(l), V(l), W(l), I = 1,N) elem egészen csekély módosításával áll elő:
(l, U(l), V(l), W(I), l = 1,N)
Az eltérés, mint látjuk, abban van, hogy az összelett listaelemben szereplő l/O lista tartalmazza a ciklusváltozót. Ezt kiviteli utasítások esetén megengedi az ASA FORTRAN, beolvasási utasításokra viszont megtiltja.
Az ismertetett szemantikai szabályok alkalmazásával - ismét feltéve, hogy N = 5 -, a következő kiírási sorrend adódik: 1, U(1), V(1), W(1), 2, U(2), V(2), W(2), 3, U(3), V(3), W(3), 4, U(4), V(4), W(4), 5, U(5), V(5), W(5). Az output rekordon tehát minden egyes kiírási ciklusban megjelenik a ciklusváltozó aktuális értéke is. Ezt a fogást felhasználhatjuk pl. a sornyomtatón kiíratott számanyag sorainak megszámozására.
Visszatérünk most arra a kérdésre, hogy a harmadik példában (l, U(l), V(l), W(I), l = 1,N) miért nem lehet egy READ listának is eleme? Erre a következő szemantikai szabály ad választ: az összetett I/O listaelemeknek olyannak kell lenniük, hogy a végrehajtott átvitelek sem a ciklusváltozónak, sem pedig a kezdőérték-, növekmény- és végérték-paramétereknek az értékét ne változtassák meg. A már ismert szemantikai szabályok szerint a kiírási jellegű átvitelek nem változtatják meg az átvitt változók értékét, tehát ez a szabály csak a READ utasításokra jelent korlátozást. A harmadik példa ennek nem tesz eleget, minthogy az input perifériáról beolvasott számadatok megváltoztatnák l értékét.
Az egyszerű I/O listák, valamint az összetett l/O listaelemek értelmezésével kapcsolatos szabályok ismeretében most már könnyen elintézhetjük az összetett listák szemantikáját is. A már ismert szabályokhoz ugyanis csupán egyetlen újabbat kell hozzátennünk (a korábbi számozás szerint ez a szabály a 4-es sorszámot viseli):
Mint az előzőkben láttuk, az összetett listaelemek részként tartalmazhatnak összetett I/O listákat. Magától értetődik, hogy ezeket a "belső" listákat is az imént megismert szabályok szerint kell átvinni; vagyis azok a szabályok, amelyek az "egészre" vonatkoznak, egyszersmind érvényesek annak egy részére is. A matematikában az ilyen szabályokat rekurzívnek szokás nevezni, és azt is mondhatjuk, hogy az összetett listaelem ebben az értelemben rekurzív fogalom. Hasonlóan rekurzív fogalom pl. az aritmetikai kifejezés, melynek egy zárójelekkel elhatárolt része ismét aritmetikai kifejezés, és a kiszámítási szabályok is rekurzívek, amennyiben a zárójelekkel elhatárolt részt ugyanúgy kell kiszámítani, mint magát a teljes kifejezést.
Példák:
1. Legyenek A és B 3x3-as tömbök, és tekintsük a következő - egyelemű, összetett - I/O listát:
((A(I,J), B(I,J), I = 1,3), J = 1,3)
Legelőször J felveszi az 1 értéket. Ezután át kell vinnünk az I/O lista elemeit. Ez jelen esetben maga is egyelemű összetett lista, melynek átvitele - figyelembe véve, hogy J-t most rögzítettük - a következő tömbelemek átvitelét jelenti (sorrendben): A(1,1), B(1,1), A(2,1), B(2,1), A(3,1), B(3,1). Ezután, megnövelve J értékét, a következő tömbelemek kerülnek átvitelre: A(1,2), B(1,2), A(2,2), B(2,2), A(3,2), B(3,2); végül J = 3-mal A(1,3), B(1,3), A(2,3), B(2,3), A(3,3), B(3,3). Figyeljünk arra, hogy ez nem ugyanaz, mintha az l/O lista egyszerűen így festene: A, B
2. Írjunk I/O listát a 10x10-es G tömb elemeinek sorfolytonos átvitelére!
Megoldás:((G(I,J), J = 1,10), I = 1,10)
Ez ismét nem egyenértékű az egyetlen G elemből álló I/O listával.
Végezetül még megjegyezzük, hogy a DO utasításokhoz hasonlóan a többszörösen összetett l/O listák esetében is a legbelső ciklus kerül legtöbbször végrehajtásra, más szóval a legbelső ciklusváltozó változik a "leggyorsabban". Ez természetesen nem új szemantikai szabály, hanem az előzők összefoglalása, a gyakorlati programozás szempontjából azonban hasznos, mert tömören kifejezi az eddig elmondottak lényegét.
6.3. Bináris formájú átvitelek
Az előző pontban tárgyalt értelmezési szabályok alapján már csaknem teljes egészében ismerjük a bináris átvitelek szemantikáját is. Mindössze egyetlen nyitott kérdés maradt, mégpedig az, hogy milyen kapcsolatban van az l/O lista és a periférián rögzített l/O rekord? Közelebbről, hogyan darabolódik fel az output lista output rekordokra, illetve hány rekordot kell beolvastatnunk egy input lista feldolgozása közben?
Erre a kérdésre roppant egyszerű a válasz: bináris átvitelek esetén az I/O lista egyetlen rekord átvitelét jelenti. Ezt másként úgy is megfogalmazhatjuk, hogy a rekordhosszt az I/O lista határozza meg. (Ez az egyszerű szabály a karakter formájú információátvitel esetében nem érvényes!)
Az iménti szabályt kiírási műveletekre úgy kell értenünk, hogy valahányszor a gép hozzákezd egy WRITE utasítás végrehajtásához, mindannyiszor új rekordot nyit, és az output lista által meghatározott valamennyi számadatot egyetlen rekordban helyezi el. A bináris kiírás tehát nem darabolja fel az output listát több rekordra, akárhány elem kiírása legyen is előírva.
Beolvasási műveletekre az említett szemantikai szabály azt jelenti, hogy valamennyi beolvasandó számadatnak ugyanabban a rekordban kell elhelyezve lennie; a bináris beolvasási művelet végrehajtásának megkezdésekor a gép új rekordot kezd, és további rekordokat a beolvasási művelet végrehajtása közben megkezdeni már nem lehet.
A rekord fogalmával kapcsolatban szükségesnek tartjuk megjegyezni, hogy a konkrét perifériális egységekre értelmezett rekord fogalom, és az ASA FORTRAN-ban értelmezett rekord fogalom között eltérés lehet, amennyiben a perifériális egységen megjelenő ún. fizikai rekord lehet nagyobb is, és kisebb is, mint egy FORTRAN nyelvbeli, ún. logikai rekord. A gép programozási rendszere ilyen esetben gondoskodik arról, hogy a logikai rekordot automatikusan szétbontsa több fizikai rekordra, illetve hogy több logikai rekordból összeállítson egy fizikai rekordot. Mi a továbbiakban rekordon mindig logikai rekordot értünk.
Mindenfajta beolvasási művelettel kapcsolatban ügyelni kell arra, hogy az input rekord ne tartalmazzon kevesebb számadatot, mint amennyinek beolvasását az input lista előírja, vagyis hogy az input rekord ne legyen túl rövid. Több számadatot tartalmazhat az input rekord, de nem szabad megfeledkeznünk arról, hogy a rekord végén álló fölös számadatok a beolvasás során figyelmen kívül maradnak, és hogy rekord közepébe "belekapni" semmiféle READ utasítás sem képes.
Az l/O utasítások szemantikai szabályait ki kell még egészítenünk az üres lista esetével. Az üres l/O listájú
Karakter formájú információátvitelekre a fentiek nem vonatkoznak; a megfelelő szabályokat a 6.4. pontban tárgyaljuk.
Röviden áttekintjük az ún. szalagkezelő / lemezkezelő utasításokat. Ezek nem információt visznek át, hanem eredetileg - erre utal az elnevezésük is - a mágnesszalagnak a kívánt helyzetbe való beállítását vagy lezárását intézik. Mindhárom utasítás működése attól függ, hogy a megadott logikai perifériaszámhoz milyen egység van társítva: képernyőre vagy nyomtatóra irányuló műveleteknél a három művelet nem csinál semmit. Ha az egységszám lemezmeghajtóra vonatkozik, az ENDFILE és REWIND parancsok lehetővé teszik a file-ok további vezérlését a futó programból:
BACKSPACE u
REWIND u
ENDFILE u
ahol u a mágnesszalagos egység logikai perifériaszáma. (Előjeltelen egész szám, vagy index nélküli egész változó lehet.)
A BACKSPACE utasítás a mágnesszalagon egy rekorddal való visszalépést jelent, hatására a mágnesszalag a megelőző rekord elé áll. A FORTRAN-80-ban nincs implementálva.
A REWIND utasítás eredetileg a szalag teljes visszacsévélését idézi elő: végrehajtásának eredményeként a szalag első adatrekordja beolvasásra készen áll. Lemezes rendszerben bezárja a file-t, majd újra megnyitja.
Az előző két utasításra az a közös szemantikai szabály érvényes, hogy ha a szalag az utasítás végrehajtása előtt már visszacsévélt állapotban volt, akkor mindkettő teljesen hatástalan.
A harmadik szalagkezelő utasítás, az ENDFILE, lezárja a file-t. A megnyitott file-ok a programfutás befejezésekor is lezárásra kerülnek.
Egyes, régebbi gépi reprezentációs nyelvek az ENDFILE utasítás használatát nemcsak mágnesszalagos / mágneslemezes egységekre engedélyezik, hanem pl. lyukszalag vagy lyukkártya output esetére is. Megjegyzendő, hogy az ASA FORTRAN jelentés sem kifejezetten mágnesszalagos egységről beszél, hanem "soros elérésű file"-ról, amelyen azonban hallgatólag mágnesszalagos egységet értenek.
6.4. Karakterátvitelek. A FORMAT utasítás
Az előző pontban megismerkedtünk a bináris átvitelekkel; ezek jellemzője az, hogy az átvitelben résztvevő perifériális egységen az információ ugyanolyan ábrázolású, mint ahogyan a központi memóriában megjelenik; vagyis az átvitelt nem kísérik konverziós vagy kódváltási műveletek. Ezzel szemben a karakterátvitel mindig együtt jár a külső ábrázolásmódról a belsőre való áttéréssel, ami általában kód- és számrendszerváltást jelent. (Mint látni fogjuk, bizonyos átvitelfajtáknál csak kódváltást.)
Mint már az 1. pontban is jeleztük, a karakterátvitelek minden esetében specifikálni kell az átvitellel együtt elvégzendő kód- és számrendszer-konverziós műveleteket, valamint a rekord elrendezését a külső tárolón. Ezt az információt az l/O utasításhoz mellékelt FORMAT utasítás tartalmazza. A FORMAT utasítás karakterátvitelek esetében részben átveszi a rekordhossz meghatározását is. Annyi a karakterátvitelekre is érvényes, hogy az I/O lista kezdete egyben rekordkezdetet és vége egyben rekordvéget is jelent, az "egy I/O lista - egy rekord" elv azonban már nem áll fenn, amennyiben a FORMAT utasítás rendelkezhet úgy is, hogy az I/O listának a külső tárolón egynél több rekord feleljen meg.
A karakterátviteli I/O utasítások formáját a 2. pontban már megadtuk. Az utasításokban szereplő f az I/O utasításhoz rendelt FORMAT utasítás címkéje, vagy pedig valamely programbeli tömb azonosítója. Ugyanaz a FORMAT utasítás lehet egyszerre hozzárendelve több I/O utasításhoz is, más szóval, ugyanaz az f címke több I/O utasításban is előfordulhat. Mivel a FORMAT utasítások önmagukban sohasem fordulnak elő, hanem mindig csak valamely I/O utasítással kapcsolatban, FORMAT utasítás sohasem állhat címke nélkül.
A FORMAT utasítás alakja a következő:
f FORMAT (F)
ahol f előjeltelen egész (címke), F pedig az ún. FORMAT-lista. A FORMAT listát mindig kerek zárójelbe zárjuk.
Formálisan az F lista egymástól elhatároló jelekkel elválasztott specifikációk vagy specifikációcsoportok sorozata, elején és végén tetszőleges számú törtvonal-karakter is állhat. Elhatároló jel a vessző és a törtvonal. A vessző a FORMAT listában kizárólag elhatároló jelként lép fel, ezzel szemben a törtvonalnak van önálló szemantikai jelentése is (új rekord kezdése).
A FORMAT listán kétféle specifikáció fordulhat elő:
A konverziós specifikációkhoz mindig tartozik egy - az I/O lista által meghatározott - adat, és a specifikáció az ezen elvégzendő számrendszer-, vagy kódváltást határozza meg. Ellentétben a konverziós specifikációkkal, a szerkesztési specifikációkhoz nincs az I/O listának egyetlen eleme sem hozzárendelve. Ez utóbbiak célja a külső tárolón a rekord szerkezetének meghatározása: meghatározzák a rekord "külső formáját", azaz pl. a sornyomtató esetében a nyomtatási képet.
Az alábbiakban szükségünk lesz még két fogalomra, mégpedig a mező és a mezőszélesség fogalmára. Mezőn a rekordnak azt a részét értjük, amely a FORMAT lista egyetlen elemének vezérlete alatt kerül átvitelre. Ha ez az elem konverziós specifikáció, akkor a megfelelő mező a rekordon egy számadat. Az ilyen mezőt numerikus mezőnek nevezzük. A sornyomtatón pl. az egy sorban kinyomtatott számok mindegyike egy-egy numerikus mező. Ha a specifikáció szövegátvitelt ír elő, akkor ennek a rekordon alfanumerikus (vagy Hollerith) mező felel meg. A sornyomtató példájánál maradva, az eredménytáblázat fejléceiben szereplő szövegek, feliratok Hollerith (alfanumerikus) mezők.
Valamely mező szélességén a mező által elfoglalt karakter-pozíciók számát értjük. Numerikus mezők szélességének kiszámításakor a numerikus mezőhöz tartozó minden karaktert (előjel, tizedespont stb.) figyelembe kell venni. A továbbiakban a mezőszélességet mindig w-vel jelöljük. Például a -5.3047E-02 számra w = 11.
Bevezetjük még a következő jelölést is: bármely szám tizedespont utáni tizedes jegyeinek számát d-vel jelöljük, d-be csak a decimális mantissza törtrészének jegyeit számítjuk bele, az esetleges decimális exponens jegyeit nem. Így pl. az előbbi számpéldában d=4.
A soron következő alpontokban rendre áttekintjük az egyes specifikációtípusokat. A 6.5. pontban visszatérünk a FORMAT lista egészét érintő szabályok ismertetésére.
a) Egész számok konverziója. Az I specifikáció
Egész (INTEGER) típusú változók értékeinek beolvasásához és kiíratásához az I konverziós specifikációt alkalmazzuk, melynek alakja:
Iw
ahol w - megállapodásunknak megfelelően - a mezőszélességet jelenti, vagyis azt határozza meg, hogy a perifériális rekordokon az átviendő egész szám hány karakterpozíciót foglal el.
Output I specifikációval
Kiírási típusú átvitelek során, ha az átvinni kívánt szám nem tartalmaz annyi számjegyet, amennyi a w mezőszélességnek megfelel, a gép a számot a mező jobb oldali, azaz magasabb sorszámú karakterpozícióira írja ki, a bal oldali, fel nem használt karakterpozíciókra pedig betűköz karakterek (space) kerülnek.
Format specifikáció I6
I6
I3
I4
-23261
126
-226
-23261
126
-226Példa:
Legyenek a programnak K1, K2 és K3 egész típusú változói, aktuális értékeik pedig rendre legyenek 12397, -3540 és 32000 írjunk WRITE utasítást, amely sornyomtatón kiírja ezeket az értékeket!
Mielőtt megtervezzük a nyomtatási képet, vagyis az output formátumot, mindenekelőtt meg kell becsülnünk a kiíratandó egész mennyiségek nagyságrendjét, mert e nélkül nem tudjuk megállapítani a mezőszélességeket. Általános elvként azt tartsuk szem előtt, hogy egy w-1 jegyű egész szám kiírására az output rekordon legalább w karakterpozíciót kell fenntartanunk, egy karakterpozíciót ui. az előjel számára biztosítunk. Tegyük fel, hogy K1, K2 és K3 abszolút értéke maximálisan 99999 lehet, azaz: e számok legfeljebb ötjegyűek. (Történetesen pillanatnyilag K2 aktuális értéke négyjegyű, de erre természetesen nem lehetünk tekintettel.) Előző szabályunk szerint legalább 6 karakterpozíciót kell az output rekordon mindegyikük számára fenntartanunk. Nézzük meg, milyen nyomtatási képhez jutunk, ha w = 6-ot választunk! Legyen a kiírási utasítás, a megfelelő FORMAT utasítással együtt,WRITE(2,15) K1,K2,K3
15 FORMAT(I6,I6,I6)végrehajtása után a következő nyomtatási képhez jutunk:
˘12397˘-3540˘32000
(Itt és a következőkben a szóköz karaktereket ˘ jel fogja szimbolizálni.)
E nyomtatási képpel kapcsolatban megjegyezzük először is, hogy a pozitív előjel helyett mindig betűköz karakter nyomtatódik. Így az első számot a lapszéltől, valamint a harmadik számot a másodiktól elválasztó egyetlen betűköz a pozitív előjel helyett áll. Az első számot a másodiktól elválasztó betűköz ezzel szemben azért került az output rekordra, mert K2 nem tölti ki a rendelkezésre álló hat karakterpozíciót, hanem csak ötöt, lévén négyjegyű szám negatív előjellel. Emlékeztetünk iménti szabályunkra, mely szerint ilyen esetben a mező bal szélén keletkeznek a betűköz karakterek. Ezt úgy fejezzük ki, hogy kiírási átvitelek során a numerikus mezők az output rekordon jobbról tömörítve jelennek meg.
Példánkra visszatérve, látjuk, hogy a kapott nyomtatási kép nem nagyon tetszetős, mivel a számok szinte egymásra vannak zsúfolva. Különösen szembetűnne ez, ha történetesen K2 értéke nem -3540 volna, hanem -11400. Ebben az esetben ui. a kiírási utasításpár hatására a következő nyomtatási kép jönne létre:12397-11400˘432000
azaz K1 és K2 között egyetlen elválasztó karakter sem állna.
Tetszetősebb a nyomtatási kép, ha kihasználjuk a jobbról tömörítési szabályt az output rekord "levegősebbé" tételére. Ezt azzal érhetjük el, hogy az I specifikációban a minimálisnál nagyobb w értéket adunk meg. Pl:15 FORMAT(I11,I11,I11)
Az egyes számok most már jól elkülönülnek, mert legalább öt betűköz karakter választja el őket.
A jobbról tömörítési szabályt felhasználhatjuk a kiírt számok középre állítására is, ha ismeijük a sornyomtató egy sorában a karakterpozíciók számát. Az általánosan használatban levő sornyomtatókon ez a szám 120 vagy 160. A továbbiakban feltesszük, hogy a rendelkezésünkre álló sornyomtató 120 pozíciós. Módosítsuk feladatunkat úgy, hogy írjuk elő a három szám sorközépre állítását is!
Ha fenntartjuk azt a kikötésünket is, hogy az egyes számokat 5-5 betűköz karakter válassza el, ha elfoglalják a maximális hat karakterpozíciót, akkor a következőképpen kell számolnunk: a K1-nek megfelelő numerikus mező hat pozíciót foglal el az output rekordon, K2 és K3 pedig egyenként 11-11 pozíciót. A három numerikus mező együttesen tehát összesen 28-at. Fennmarad tehát 120-28 = 92 pozíció, ezt kell megfeleznünk a bal és a jobb margó között. Végeredményben a három számot a következő FORMAT utasítással állíttathatjuk sorközépre:15 FORMAT(I52,I11,I11)
A fenti formátum hatására 46 betűköz karakter nyomtatódik K1 elé, ami által a három szám sorközépre kerül.
Annak érdekében, hogy belássuk, hogy a FORMAT utasítás valóban úgy működik, ahogy várjuk tőle, hivatkozunk a 6.4. pont bevezetőjében említett szemantikai szabályra, amely szerint az l/O lista kezdete rekordkezdetet, vége pedig rekordvéget jelent. Amikor tehát a gép elkezdi végrehajtani a példában szereplő WRITE utasítást, mindenekelőtt új rekordot nyit, ami a sornyomtató esetében új sor kezdését jelenti. Ezt követően átviszi (azaz kinyomtatja) az l/O lista első elemét, a FORMAT utasítás első konverziós specifikációjának megfelelően. Ez esetünkben az I52 specifikáció; az output rekord első, 52 karakter szélességű numerikus mezejének utolsó hat karakterében elhelyeződik a K1 szám aktuális értéke (az előjel helyett itt szintén betűköz karakter áll). A második l/O listaelem a második konverziós specifikáció szerint nyomtatódik, ez a K2 szám, a neki megfelelő specifikáció I11. Az eljárás hasonló az előzőhöz, a kapott numerikus mező első öt karakterpozíciójára betűköz kerül, a többi a kinyomtatandó számot tartalmazza (itt a negatív előjel is elfoglal egy pozíciót). Ugyanígy történik a harmadik szám kinyomtatása is. Több l/O listaelem nem lévén, a sornyomtató e sorának további részeibe nem kerül információ, így automatikusan létrejön az ugyancsak 46 karakter szélességű jobb margó.
Amint az előbbiekből látható, a karakterátvitelek végrehajtása az l/O és a FORMAT lista párhuzamos átvizsgálása és értelmezése alapján történik. Ennek a műveletnek elég bonyolult "játékszabályai" vannak, melyeket a 6.5. pontban tárgyalunk.A FORMAT utasítások írásának kényelmesebbé tétele céljából bevezették az egyes specifikációk elé írható ún. ismétlési tényezőket. Az ismétlési tényező egy előjeltelen egész szám, amely azt jelenti, hogy az adott specifikációt az átvitel folyamán hányszor kell figyelembe venni. A FORMAT(I11,I11,I11) specifikációt például a következőképpen rövidíthetjük:
15 FORMAT(3I11)
a FORMAT(I52,I11,I11) specifikáció lehetséges rövidítése pedig:
15 FORMAT(I52,2I11)
Ismétlési tényezőt tehát akkor alkalmazhatunk, ha két vagy több teljesen megegyező specifikáció kerül egymás mellé a FORMAT listán. Mint az előző példán is láthattuk, az nS alakú listaelem - ahol az n előjeltelen egész szám az ismétlési tényező, S pedig tetszőleges specifikáció H (lásd h)) és / (lásd /J) kivételével - definíciószerűen egyenértékű az S, S, ..., S (n-szer) listarészlettel.
Input I specifikációval
Vizsgáljuk most az I specifikáció jelentését beolvasási műveletek esetére. Általában, ha egy konverziós specifikáció hatását beolvasási műveletekre tárgyaljuk, mindig két kérdést kell tisztáznunk:
- az adott specifikációhoz milyen számok engedhetők meg az input információhordozón;
- az adatokat a beolvasáskor a gép hogyan értelmezi.
Ami az első kérdést illeti, az I specifikáció esetében az input periférián megjelenő numerikus mezőnek a FORTRAN nyelv definícióinak megfelelő egész számnak kell lennie (vagy előjellel ellátva, vagy anélkül).
A beolvasott információ értelmezésének tekintetében már bizonyos óvatossággal kell eljárnunk. A kiviteli művelet tárgyalása során megismertük a jobbról tömörítés szabályát. Lényegében ez érvényes a beolvasásra is: az input rekordon megjelenő numerikus mezőt a gép jobbról tömörítettnek tekinti: a mező bal szélén álló esetleges betűköz karaktereket a beolvasáskor nem veszi figyelembe, a jobb szélen állókat pedig zérusnak tekinti.
Format specifikáció I4
I4
I7
I4
-124
˘˘6732˘
1˘2˘
-124
67320
1020
Végezetül kimondunk még egy általános elvet, amely a FORMAT utasítás szemantikájában következetesen végigvonul: ha egy karakter-átviteli WRITE utasítással kiíratunk bizonyos mennyiségeket, majd ugyanezeket a mennyiségeket azonos FORMAT szerint visszaolvastatjuk, akkor - az esetleges kerekítési hibáktól eltekintve - ugyanazokat a számokat kell visszakapnunk. Ez az elv magyaráz meg egyes szemantikai szabályokat, amelyek önmagukban esetleg első pillanatban illogikusnak tűnhetnek (pl. a P kiegészítő specifikációra vonatkozó szabályok).
b) Fixpontos, valós számkonverzió. Az F specifikáció
Az előző alpontban megismert I konverziós specifikáció akkor alkalmazható, ha a megfelelő l/O listaelem egész típusú változó. Valós változók átvitelére háromféle konverziós lehetőségünk van, mégpedig az F specifikáció, melyet a jelen alpontban tárgyalunk, továbbá az E specifikáció (c) pont) és a G specifikáció (d) pont).
Az F specifikáció alakja a korábban bevezetett jelölésekkel:
Fw.d
Output F specifikációval
Kiírási utasításokban a d szám azt mondja meg, hogy hány tizedesjegyre kell a kiíratandó változó aktuális értékét kerekíteni. A w mezőszélességre ugyanaz érvényes, mint az I specifikáció esetében: a gép a kiíratandó számot a rendelkezésre álló output mezőben jobbról tömörítve helyezi el, és a mező bal oldalán megmaradó, fel nem használt karakterpozíciók betűköz karakterekkel töltődnek fel. Ha az érték több mezőpozíciót igényel, mint amennyit w lehetővé tesz, akkor az érték első w-1 számjegye jelenik meg, előtte egy csillag.
Format specifikáció F10.4
F7.1
F8.4
F6.4
F7.3
-4786.361
8.7E-2
4739.76
-5.6
-4786.4
˘˘0.0870
*.7600
˘-5.600Példa:
1. Tegyük fel, hogy (12 értékes decimális jegyre történő belső számábrázolást feltételezve) X aktuális értéke -0.363844055713, Y aktuális értéke 3892.18485004 és Z aktuális értéke -20.0996337781.WRITE (1,5) X,Y,Z
5 FORMAT (F11.8, F8.2, F8.4)Ekkor fenti FORMAT hatására a következő nyomtatási kép jön létre:
-0.36384406˘3892.18-20.0996
2. Eddigi ismereteink birtokában most hozzáfoghatunk egy jóval bonyolultabb kiíratási feladathoz. Tegyük fel, hogy adva van a memóriában egy 12x12-tes mátrix, és ezt kell sorfolytonosan kiíratnunk. A sornyomtató egy sorában a mátrix egy sora kell hogy álljon, és a sorokat meg is akarjuk számozni, mert ezzel a nyomtatási kép áttekinthetőbbé válik. Feltesszük, hogy a mátrix elemei abszolút értékben kisebbek, mint 100; a kiírást 3 tizedesjegyre követeljük meg.
Megoldás: Mindenekelőtt kiszámítjuk, hogy egy-egy sorban hány karakterpozíciót kell felhasználni. Minthogy egy sorban 12 valós szám és egy (egész) sorszám nyomtatását követeljük meg, és az előzők szerint a nyomtatáshoz minden egyes valós mátrixelem számára legalább 2+3+2 = 7 pozícióra van szükségünk, a sorszámnak pedig legalább két pozíciót kell fenntartanunk (A sorszám mindig pozitív, így az előjel számára jelen esetben nem szükséges helyet kihagynunk.), tehát soronként legalább 12x7 + 2 = 86 nyomtatási pozícióra van szükségünk; így elválasztó betűközökre és margóra marad 120-86 = 34 karakterpozíció. 13 darab egy sorban nyomtatott számnak 12 "köze" van; ha számonként 2-2 elválasztó betűközzel számolunk, akkor margóra marad 10 pozíció, amit megfelezve, 5-5 karakter szélességű bal és jobb margóhoz jutunk.
Mindezen meggondolások figyelembevételével, a kiírási programrészlet a következő:DO 12 I=1,12
12 WRITE (5,8)(I,A(I,J),J = 1,12)
8 FORMAT (I7, 12F9.3)A kiírást a 12-es címkéjű WRITE utasítás realizálja. Az utasítás I/O listája egy egyszerű és egy összetett listaelemből áll. Az I/O listán szereplő I ciklusváltozó kinyomtatása útján kapjuk a lap bal szélén a sorszámot.
Annak megértéséhez, hogy miért szerveztük a ciklust éppen így, azaz miért helyeztük a sor (I) szerinti ciklust egy DO utasítás vezérlete alá, és miért van az oszlop (J) szerinti ciklus az I/O listában elhelyezve, emlékeztetünk arra a szemantikai szabályra, amely szerint az I/O utasítás végrehajtásának megkezdése új rekord megnyitásával jár együtt. A szervezési megoldás tehát automatikusan biztosítja, hogy a gép a mátrix minden egyes sorának kinyomtatását új sornyomtató sorban kezdje, a mátrix azonos sorában álló elemek pedig azonos sornyomtató sorba kerüljenek.
A későbbiekben látni fogjuk, hogy az explicit DO ciklusra valójában nincs szükség, korrekt megoldás a következő is:WRITE (5,8)((I,A(I,J) J=1,12), I=1,12)
8 FORMAT (17,12F9.3)Input F specifikációval
Mindenekelőtt emlékeztetünk arra, hogy beviteli utasítások végrehajtásakor a gép a beolvasott numerikus mező bal oldalán álló betűköz karaktereket figyelmen kívül hagyja, míg a mező jobb oldalán álló betűköz karaktereket zérusnak tekinti. Ez a szabály érvényes a valós fixpontos specifikációra is, tehát ha a beolvasott numerikus mezőben álló szám nem jobbról tömörített, akkor beolvasáskor az alacsony helyi értékű pozíciókban megfelelő számú zérussal egészül ki.
Mielőtt ennek következményeit kifejtenék, mindjárt kimondjuk a valós beolvasási konverzió két további alapszabályát is:
- Ha a beolvasott mezőben nincs tizedespont-karakter (azaz a beolvasott szám formailag egész), akkor d az "elvágandó" tizedesjegyek számát határozza meg.
Az F konverzióval való bevitelkor az input mező tetszőleges olyan számot tartalmazhat, amely az ASA FORTRAN nyelv definíciói értelmében "szám"-nak (azaz egész, vagy valós számnak) tekinthető. Tehát nem követeljük meg, hogy az input mező pontosan ugyanolyan legyen, mint amilyent ugyanaz az F specifikáció egy kiviteli utasításban létrehozott volna.
E szabályoknak a valós számok bevitelére nézve két fontos következménye van:
- ha a beolvasott valós szám tartalmaz tizedespontot, akkor nem feltétlenül kell az input mezőben jobbról tömörítve elhelyezkednie, mert a jobb oldali kiegészítő zérusok "értéktelenek", és a számot nem változtatják meg;
- ha viszont a beolvasott szám nem tartalmaz tizedespontot, akkor a jobbról tömörítés lényeges, mert a kiegészítő zérusok - akárcsak az egész számok esetében - a beolvasott számnak 10 megfelelő hatványával való szorzását jelentik.
Ha egy beolvasásra kerülő valós mennyiség esetében az input mező decimális exponenst is tartalmaz, akkor a kitevőben a pozitív előjel betűközzel helyettesíthető. (Tehát nemcsak a szám pozitív előjele helyett állhat betűköz, hanem a kitevő pozitív előjele helyett is.)
Az ASA FORTRAN egyébként úgy rendelkezik, hogy numerikus mezőben minden betűköz karakter zérusnak számít, kivéve a szám elején állókat, amelyek ignorálandók. A legtöbb gépi reprezentáció azonban a számok belsejében álló betűközöket illegális karakterként jelzi, ezért zérusoknak betűközzel való helyettesítését nyomatékosan ellenjavalljuk.Ebben az alpontban a valós beviteli konverzióra vonatkozó tudnivalókat az F specifikációra mondottuk el. Ezek azonban egyben az E és a G specifikációkra is vonatkoznak (lásd a következő két alpontot), mivel beviteli utasítások esetén az F, az E és a G specifikáció teljesen egyenértékű, csak a kiírási műveletekre különböző a hatásuk. Ennélfogva a következő két alpontban csak kiírási műveletekkel foglalkozunk.
c) Lebegőpontos, valós számkonverzió, Az E specifikáció
A korábban bevezetett jelölésekkel az E specifikáció alakja
Ew.d
Output E specifikációval
E specifikáció segítségével a program valós változóinak aktuális értékét decimális normálalakban írhatjuk ki, mely egy 0.1 és 1 közé eső, d számú tizedesjegyből álló decimális mantisszából, és egy két jegyből álló decimális karakterisztikából tevődik össze. A specifikáció hatására kiírt szám alakja tehát±0.yy..yE±yy
ahol minden y egy-egy decimális számjegyet szimbolizál, a + jel helyett pedig egyes gépi reprezentációkban betűköz karakter áll. Vagyis:
Látható, hogy a decimális exponens összesen 4 karakterpozíciót foglal el az output mezőben, a szám előjele, a kötelező zérus és a tizedespont együttesen hármat, így ha d számú jegyet kívánunk kiíratni, akkor legalább w = d+7 kell hogy legyen.
Az E specifikáció előnye az F specifikációval szemben, hogy a szám nagyságától függetlenül mindig előre ismert számú karakterpozíciót igényel. Ha az F specifikáció esetében a kiíratandó szám véletlenül nem olyan nagyságrendű, mint amilyennek vártuk - azaz túl nagy, vagy túl kicsi -, akkor vagy egyáltalán nem fér bele a számára fenntartott mezőbe ("kicsordul" belőle), vagy a konverzió közben minden értékes számjegye eltűnik, és zérusként jelenik meg (ez az ún. "alulcsordulás" esete). Az E specifikáció esetében ez nem történhet meg; a számot az output rekordban mindig adott relatív pontossággal (adott számú értékes jegyre) kapjuk.
Format specifikáció E12.5
E14.7
E13.4
E8.2
-32672.354
-0.0012321
76321.73
-˘.3267235E˘05
˘˘-˘.1232E-02
˘.76E˘05Példa:
Legyen adva három, egyenként 20 elemű vektorunk, A, B és C. A vektorok elemeinek nagyságrendje előre nem ismert. A feladat a vektorok elemeinek kiíratása a sornyomtatón, mégpedig oly módon, hogy mindegyik sorban, középre állítva, három szám álljon, A-nak, B-nek és C-nek egy-egy azonos indexű eleme. Az egyes vektorelemeket 6 tizedesjegyre nyomtassuk. A sorokat számozzuk is meg!
Megoldás: Tekintve, hogy példánkban d = 6, az egyes valós számok kinyomtatásához legalább w = 13 mezőszélességet kell előírnunk. A sorszám kétjegyű, tehát kinyomtatása 2 karakterpozíciót igényel. A példa szövege nem írja elő az elválasztó betűköz karakterek számát; a tapasztalat szerint az elválasztó betűközök optimális száma 5-10, mert ilyen értékek mellett a számok már jól elkülönítettek, de a nyomtatási kép még nem folyik szét. Válasszuk önkényesen az elválasztó betűközök számát 8-nak! A már ismert számítási eljárás szerint - az elválasztó betűközöket is beleszámítva - a kinyomtatás 65 karakterpozíciót igényel, margóra tehát 55 pozíció marad. A bal margót 27 karakterpozíció szélességűnek választva, a megoldás a következő:DO 4 I = 1, 20
4 WRITE (5,12) I,A(I),B(I),C(I)
12 FORMAT (I29,3E21.6)Megjegyezzük, hogy a FORMAT utasítás akárhol állhat a programban, nem kell, hogy közvetlenül a hozzá tartozó l/O utasítás után következzék. Sőt, az áttekinthetőség érdekében sokszor célszerű a FORMAT utasításokat a szegmenst lezáró END elé összegyűjteni.
Szükségesnek tartjuk megjegyezni azt is, hogy a FORMAT - nem végrehajtható utasítás lévén - nem lehet egy DO ciklus lezáró utasítása. A példákban is, a DO lezárására mindig végrehajtható utasítást alkalmaztunk. Tilos természetesen a vezérlésátadás is a FORMAT utasításra.Input E specifikációval
Input utasítások esetén az E specifikáció teljesen egyenértékű az F specifikációval.
d) Valós számkonverzió előírt számú decimális jegyre. A G specifikáció
Az előző két alpontban megismertük a fixpontos és a decimális lebegőpontos konverziós lehetőségeket. A jelen alpontban bemutatandó konverziótípus bizonyos átmenetet jelent az, előző kettő között.
Láttuk a hogy fixpontos F konverzió esetében a d számmal a tizedespont utáni decimális jegyek számát specifikáljuk, míg az egész jegyek számát lényegében a mezőszélességgel adjuk meg. Ebből következik, hogy a specifikáció csak akkor alkalmazható a túl- és alulcsordulás veszélye nélkül, ha a kiíratandó mennyiség nagyságrendje nem ingadozik túlságosan nagy határok között. Lényeges, hogy a kiíratandó mennyiség abszolút értékének egy jó felső becslését ismerjük, mert enélkül nem tudjuk helyesen megválasztani a mezőszélességet.
A fenti nehézségek az E specifikáció kapcsán nem merülnek fel, viszont a tapasztalat szerint a lebegőpontos formátumban kiíratott számok vizuálisan valamivel nehezebben áttekinthetők, mint a fixpontosak. Ezt a két hátrányos tulajdonságot kívánja optimálisan kiküszöbölni a G specifikáció. Tekintettel arra, hogy input esetén az F és E specifikációk hatása azonos, ettől a G specifikáció hatása sem tér el. A továbbiakban tehát csak az output esetével foglalkozunk.
Output G specifikációval
A G specifikációval kiíratott számok általában nem tartalmaznak decimális exponenst, de itt nem a tizedespont utáni, hanem az értékes decimális jegyek számát írjuk elő. A gép a kiíratandó számot d számú értékes decimális jegyre íratja ki, miközben a tizedespont oda kerül, ahová a szám nagyságrendje megkívánja.
A G specifikáció alakja:Gw.d
ahol w a mezőszélesség, d pedig az értékes decimális jegyek száma. Felhívjuk a figyelmet arra, hogy d értelmezésében a G specifikáció eltér az általános megállapodástól. A kiíratás eredményeként megjelenő numerikus mező jobb szélén 4 betűköz karakter áll, amelyek a túl- vagy alulcsordulás esetére fenntartott karakterpozíciók helyét töltik ki (lásd alább).
Példák:
1. Legyen a pillanatnyilag feldolgozott FORMAT specifikáció:G13.6
A következő táblázat a kiíratandó változó különböző értékeire azoknak az output rekordon megjelenő képét mutatja be:
A változó értéke: A kiírt alak:
-0.445862
1.35468*10^3
-22.6458998
128907-0.445862˘˘˘˘
˘˘1354.68˘˘˘˘
˘-22.6459˘˘˘˘
˘˘128907.˘˘˘˘A gép tehát mindig 6 értékes jegyre nyomtat, a tizedespont pedig a kinyomtatandó szám nagyságrendjétől függően "vándorol" a számon belül. Valódi tizedestörtek esetén a gép még egy zérus egész részt is nyomtat, akárcsak az F specifikáció esetében.
Azonnal felvetődik a kérdés, mi történik abban az esetben, ha a szám nagyságrendje olyan, hogy a tizedespont "vándorlása" közben a számon kívülre kerülne? Példánknál maradva, hogyan nyomtatná ki a gép az adott specifikáció mellett a 12 890 700, vagy a -0.00445862 számokat? Erre a kérdésre a feleletet a következő szemantikai szabály adja meg: Ha a kiíratandó mennyiség nagyságrendje miatt a tizedespont a kiírt számon kívülre esne, akkor automatikusan át kell térni a lebegőpontos kiírási módra, azaz ilyen esetben a Gw.d specifikáció egyenértékű az Ew.d specifikációval. (A tizedespont eshet a szám jobb vagy bal szélére.) A számok jobb szélén fenntartott betűköz karakterek ilyen esetben az E specifikációnak megfelelő decimális exponens elhelyezésére szolgálnak. A két példaként adott szám tehát a következő formátum szerint nyomtatódik:
A változó értéke: A kiírt alak:
12 890 700
-0.00445862˘0.128907E 08
-0.445862E-02
Legyen A tízelemű valós vektor; egyes értékei legyenek a következők:
A(1)=23.7788543
A(2)=0.00599607554
A(3)=157.632544
A(4)=-0.0768905332
A(5)=12490356.805
A(6)=0.00000673500765
A(7)=56.7543928
A(8)=907623890.74
A(9)=-0.3452877907
A(10)=-0.000000764999802
Tekintsük a következő FORTRAN programrészletet:
DO 2 I=1,10
2 WRITE (1,9) I,A(I),A(I),A(I)
9 FORMAT (I5,E16.6,F16.6,G16.6)
Mi történik a program hatására, és milyen nyomtatási kép jön létre az átvitelek elvégzése után?
Megoldás: Könnyű látni, hogy a program az A vektor elemeit nyomtattatja ki képernyőre, mégpedig - sorszámozott sorokban - minden elemet háromszor, egyszer E, egyszer F és egyszer G specifikáció mellett. A program tehát a különböző valós konverziós specifikáció összehasonlításához készít illusztratív nyomtatási képet. Az eredménylap a következő:

A táblázaton jól összehasonlítható a háromféle konverziós specifikáció az előforduló különböző nyomtatási esetekben. Vegyük sorra ezeket!
Milyen következtetéseket vonhatunk le a táblázatból?
Felhívjuk az olvasó figyelmét arra is, nem szabad azt várnia, hogy egy konverziós specifikáció több értékes jegyet adhat, mint amennyi a gépi számábrázolás véges pontosságából eleve adódik. Ha tehát valamely gép a valós mennyiségeket 12 decimális jegyre ábrázolja, akkor hiába íratjuk ki valamelyik valós változóját pl. E20.13 specifikációval, a mantissza kiírt jegyei közül az utolsó néhány biztosan teljesen értéktelen. Nem szabad megfeledkeznünk arról sem, hogy a számrendszerváltási algoritmus maga is bizonyos kerekítési hibával járhat, így a kiírt számok utolsó jegyének helyességében mindenképpen kételkednünk kell. Ez mindegyik konverziós specifikációra egyaránt érvényes.
e) Kétszeres pontosságú mennyiségek átvitele. A D specifikáció
Kétszeres pontosságú (vagyis DOUBLE PRECISION típusú) mennyiségek átvitelére a D konverziós specifikációt használhatjuk, melynek alakja:
Dw.d
ahol d és w jelentése az előzőkből ismert.
A D specifikáció teljesen azonosan viselkedik az E specifikációval, csak megfelelő l/O listaelemnek DOUBLE PRECISION típusúnak kell lennie, és kinyomtatáskor az eredménylapon az exponenst nem E, hanem D betű jelzi.
A D specifikációval beolvastatott numerikus mezőnek nem kell feltétlenül "D betűs", decimális normálalakú számnak lennie; lehet bármiféle decimális numerikus mező, akárcsak az E, F vagy G specifikáció esetén. A beolvasott szám kétszeres pontosságú lebegőpontos ábrázolásúra konvertálódik, és elhelyeződik az l/O listaelemnek megfelelő változóban. (Valójában az input rekord decimális konstansaiban a D betűnek semmiféle jelentősége nincs, mert azt, hogy egy numerikus mezőt egyszeres vagy kétszeres pontosságúra konvertálunk, nem a D betű jelenléte vagy jelen nem léte dönti el, hanem az I/O listaelem típusa.)
Az ASA FORTRAN nem határozza meg, hogy mi történik, ha kétszeres pontosságú mennyiségeket egyszeres pontosságú specifikációk mellett íratnak ki. Ez általában nem hiba, de a kiírt szám csak annyi értékes jegyet tartalmaz, amennyi az egyszeres pontosságú számábrázolásnak megfelel.
f) Logikai mennyiségek átvitele. Az L specifikáció
Logikai változók átvitelére az L konverziós specifikációi használjuk, melynek alakja
Lw
A specifikációnak megfelelő I/O listaelemnek logikai (LOGICAL típusú) változónak kell lennie.
Ha ezt a specifikációt kiviteli műveletben alkalmazzuk, akkor a kiírt output mező első w-1 karaktere betűköz karakter, utolsó karaktere pedig egy T vagy egy F betű, aszerint, hogy a változó aktuális értéke TRUE vagy FALSE.
Beolvasási műveletekben az L specifikációnak megfelelő karaktermezőt esetleg tetszőleges számú betűköz karakter vezetheti be, majd egy T vagy F betűvel kezdődő tetszőleges jelsorozatnak kell következnie. Ha a jelsorozat T betűvel kezdődik, akkor a beolvasandó logikai változó a TRUE értékel veszi fel, ha pedig F betűvel, akkor a FALSE értéket.
Példák:
Format specifikáció L1
L1
L5
L7
<>0
<>0
=0
T
˘˘˘˘T
˘˘˘˘˘˘F
Itt felhívjuk a figyelmet egy kis következetlenségre. A numerikus konverziós specifikációknál megszoktuk - és ez természetes is -, hogy az egyes kiviteli konverziók eredményeként az output rekordon egy, az ASA FORTRAN szintaxisának megfelelő numerikus mező jelenik meg. Hasonlóan, ha az input rekordon egy a "konstans" szintaktikus kategóriába tartozó jelsorozat áll, akkor ez a megfelelő specifikációk segítségével beolvastatható és konvertálható. Ez az L konverzióra nem teljesül, mert a logikai konstansok alakja .TRUE., ill. .FALSE., a kivitel során pedig nem ezek keletkeznek az output rekordon, és beolvasáskor sem fogadhatók el logikai bemenő adatként.
g) Szöveg beolvasása és kiírása. Az A specifikáció
Adatfeldolgozási feladatokkal kapcsolatban gyakran célszerű a program minden bemenő adatkötegét kiegészíteni valamilyen bevezető karaktersorozattal, melynek segítségével az eredménylapon azonosíthatjuk a különböző adatkötegekhez tartozó eredményeket. Különösen fontos ez akkor, ha a bemenő adatsorozatok száma igen nagy, és egy futtatási menet után nagyszámú, de egymástól kevéssé különböző eredményt kapunk. Ez a helyzet pl. méréskiértékelő programok esetében. Ha ugyanaz a program egyszerre dolgoz fel több - esetleg különböző forrásból származó - adatsorozatot, az eredmények azonosítása el sem képzelhető jól megválasztott informatív szövegek nélkül. Ezek tartalmazhatják az adatsorozat sorszámát (vagy valamely egyéb kódszámát), az adatfelvételezés dátumát, helyét, a felvételező személy nevét stb.
A bevált programozási technika az, hogy ezeket az azonosító szövegeket a bemenő adatokkal együtt beolvastatjuk, majd az eredménylapra változtatás nélkül kiíratjuk. Szükségünk van tehát valamilyen átviteli specifikációra, amelyet elsősorban akkor alkalmazunk, ha szövegeket kívánunk előbb beolvasni, majd (ugyanezen specifikációval) később kiíratni. Erre való az A specifikáció, melynek alakja
Aw
és ahol w jelentése, mint a következőkben látni fogjuk, eltér megszokott értelmezésétől.
Annak érdekében, hogy szabatosan kifejthessük az A specifikációval kapcsolatos szabályokat, bevezetünk egy újabb fogalmat és egy jelölést. A mezőszélesség mintájára, elemszélességnek nevezzük és g-vel jelöljük az l/O lista pillanatnyilag feldolgozás alatt álló elemében tárolható karakterek számát. Emlékeztetünk rá - lásd a Negyedik fejezet 5. pontját -, hogy bármilyen típusú változó tartalmazhat numerikus információ helyett karakterinformációt is. Hogy ez esetben hány karaktert tartalmazhat, az függ a konkrét gépi reprezentációtól, és a változó típusától. Fortran-80-ban:
A g szám a pillanatnyi l/O listaelemben tárolható karakterek számát jelenti, tehát arra a változóra vonatkozik, amelyiknek tartalmát éppen átvisszük.
Mielőtt az A specifikáció szemantikájába mélyebben belemennénk, tekintsük azt a gyakorlatilag legfontosabb esetet, amikor az elem- és a mezőszélesség megegyezik, azaz w = g. Kiviteli utasítás esetén egy ilyen specifikáció hatására a változóban tárolt, g számú karakterből álló szöveg kiíródik az output rekordra, és azon egy g szélességű karaktermezőt hoz létre. Beviteli utasításban az input rekord soron következő w karaktere beolvasódik, elhelyeződik az aktuális l/O listaelemben, és - w = g lévén - ezzel éppen kitölti annak valamennyi karakterpozícióját.
A w>g esetben, tehát amikor a mezőszélesség nagyobb, mint az elemszélesség, a beolvasandó input mező nem fér el teljes egészében az l/O listaelemben. Az idevonatkozó szintaktikus szabály: Ha az input karaktermező szélessége meghaladja az l/O listaelem szélességét, akkor a gép az input mező utolsó g számú karakterét helyezi el a megfelelő változóban, az ezt megelőző karaktereket pedig nem veszi figyelembe.
A kiírás esetére szóló szabály pedig: Ha a kiíratandó változó elemszélessége kisebb, mint az output mező specifikált szélessége, akkor a változóban tárolt karakterek az output mező utolsó g karakterét foglalják el, az ezt megelőző karakterek pedig betűközökkel töltődnek fel.
A w>g esetben lényegében a jobbról tömörítési elv érvényesül, amit a numerikus konverzióknál már megszoktunk. (A később tárgyalandó esetben viszont a balról tömörítésre látunk majd egy példát.)
Nem árt felhívni a figyelmet arra a körülményre, hogy a w>g specifikáció melletti beolvasás és ugyanezen specifikációval való visszaíratás közben általában w-g számú karaktert elveszítünk. Ez persze nem feltétlenül baj, sőt, bizonyos esetekben ki is használhatjuk fölösleges karakterek ignorálására.
A w<g esetben az input karaktermező nem tölti ki az aktuális l/O listaelemet. A megfelelő szemantikai szabály most balról (és nem jobbról!) tömörítést ír elő: Ha az input karaktermező szélessége nem éri el az l/O listaelem szélességét, akkor a gép az input mező karaktereit a változó első w karakterpozíciójában helyezi el, a fennmaradó w-g számú karakterpozíció pedig betűköz karakterekkel töltődik fel.
Format specifikáció A1
A2
A3
A4
A7
AB
ABCD
ABCD
ABCD
INTEGER
REAL
REAL
REAL
AB
ABC
ABCD
˘˘˘ABCD
A kiírás esetére szóló szabály a következő: Ha a kiíratandó változó elemszélessége meghaladja az output mező specifikált szélességét, akkor a kiíratandó változó első w karaktere íródik ki, a fennmaradó w-g számú karakter nem vesz részt az átvitelben.
A szabályokból következik, hogy ha valamilyen karakter-információt az elemszélességnél kisebb szélességű mezőkre bontunk, és úgy olvastatjuk be és íratjuk vissza, akkor nem vesztünk információt, csak a szükségesnél több memóriarekeszt kötünk le a szöveg tárolására.
h) Szöveg beolvasása és kiírása. A H specifikáció
Szövegek beolvasására és kiíratására az előző alpontban megismert lehetőségeken kívül használható egy további átviteli specifikáció is, melyet a H betűvel jelölünk.
A H specifikáció, ellentétben az A specifikációval, a szerkesztési specifikációk kategóriájába tartozik. Mint már említettük - lásd a 6.4. pont bevezető részét -, a konverziós és a szerkesztési specifikációk között az a különbség, hogy az utóbbiakhoz nem tartozik az l/O listának eleme.
A H specifikáció alakilag Hollerith konstans:
wHXX...X
vagy
'XX...X'
ahol az X-ek tetszőleges alfanumerikus karaktereket jelölnek.
Kiírási utasításokban a H specifikáció maga határozza meg a kiírandó karaktereket: hatására a H betű után álló w számú karakter kiíródik az output rekordra. A H specifikációnak beolvasási utasításokkal kapcsolatos szerepére később térünk vissza.
A H specifikációt magyarázó szövegek, fejlécek, feliratok kinyomtatására használjuk.
Példák:
1. Írjunk FORTRAN utasítást a következő szöveg kiírására:A PROGRAM EREDMENYEI
Megoldás. A kiírandó szöveg 20 karakterből áll, tehát a specifikációban w = 20. A megfelelő kiírási utasítások:
WRITE (1,12)
12 FORMAT (20HA PROGRAM EREDMENYEI)A példa érdekessége, hogy a WRITE utasításnak egyáltalában nincs l/O listája. Bináris átvitelek esetében ez egy üres rekord kiírását jelentette, karakterátvitelek esetében nem feltétlenül. Az utasításpárban sem üres a kiírt rekord, hanem a példa által előírt 20 karakterből álló szöveget tartalmazza. Ezt a szöveget magában a FORMAT utasításban adtuk meg.
2. Legyen VAL egy valós típusú tömb, melynek 10 sora és három oszlopa van. Jelentsék a tömb egyes sorai bizonyos árucikkek árát dollárban, svájci frankban és nyugatnémet márkában. Feltesszük, hogy olyan árucikkekről van szó, amelyeknek ára egyik pénznemben sem éri el a százezret. Az árakat két tizedes pontosságig kell kiíratni. Minden számadat elé nyomtassuk ki a megfelelő pénznem rövidítését (dollár = $, svájci frank = SFR, márka = DM). A táblázat lapközépre állítását ezúttal nem követeljük meg, mindössze 5 karakter szélességű bal margót írunk elő. írjuk fel a megfelelő kiíró utasításokat!
Megoldás: Ismert nagyságrendű valós változókról lévén szó, az F specifikációt célszerű használni, mégpedig a két tizedes pontosságra való tekintettel d=2 választással. Ötjegyű egész résszel kell számolnunk, tehát a b) alpontban mondottak szerint a mezőszélesség (legalább) w = 9 kell legyen. Maradjunk tehát az F9.2 specifikációnál!
A bal margó és az elválasztó betűközök problémáját ezúttal úgy oldjuk meg, hogy minden egyes szám elé H specifikációval szövegként kinyomtatunk öt betűköz karaktert, és ezt követően a megfelelő valutarövidítést. Magát a programot a már ismert fogások felhasználásával állítottuk össze. A megoldás a következő:DO 2 I = 1,10
2 WRITE (5,8)(VAL(I,J),J=1,3)
8 FORMAT (6H˘˘˘˘˘$,F9.2,
x8H˘˘˘˘˘SFR,F9.2,7H˘˘˘˘˘DM,F9.2)a példából láthatjuk, hogy betűközöket H specifikációval is nyomtathatunk, bár nagyobb számú betűköz esetén ez nem kényelmes és van egyéb módja is (lásd a következő alpontot).
Ismételten emlékeztetünk arra, hogy a H specifikációnak az l/O listán nem felel meg elem; az I/O lista (az összetett listaelemet dinamikusan értelmezve) tehát 3 elem átvitelét specifikálja, a FORMAT lista pedig 6 elemből áll.
A H specifikációt alkalmazhatjuk beolvasási utasításokban is. Rendeltetése hasonló az A specifikációéhoz: Hollerith mezők beolvastatása, későbbi visszahatás céljából. (A FORTRAN felhasználók nagy része ezt a lehetőséget nem ismeri és ezért nem is használja, pedig sok esetben igen jó szolgálatot tehet.)
Az ASA FORTRAN definíciói szerint ha egy READ utasításhoz rendelt FORMAT utasításban H specifikáció fordul elő, akkor ez karakterbeolvasást jelent magába a FORMAT utasításba.
"Beolvasás magába a FORMAT utasításba" - ezt kissé közelebbről meg kell világítanunk. Arról van szó, hogy ha valamely szöveget H specifikációval beolvastatunk egy adott FORMAT utasításba, majd később ugyanezen FORMAT utasítás szerint kiíratunk valamit, akkor ezen későbbi kiíratáskor a FORMAT úgy fog viselkedni, mintha a megfelelő H specifikációba az imént beolvasott szöveg volna beírva. Gyakorlatilag ezt úgy alkalmazzuk, hogy amikor írjuk a programot, a H specifikációba betűközöket írunk be, majd a specifikációt mintegy "kitöltjük" az input rekordról beolvasott Hollerith mezővel.
Hollerith-konstansoknak folytatósorban történő folytatásakor azonban bizonyos óvatossággal kell eljárnunk. Gondosan ügyelni kell ugyanis arra, hogy a programsort teljesen végigírjuk a 72. karakterpozícióig bezárólag. Egyéb utasítások esetén - mint tudjuk - ez nem lényeges, bárhol abbahagyhatjuk a sort, és kitéve a folytatás jelzését, áttérhetünk egy újabb sorra. Itt nem. A gép a beolvasáskor ugyanis automatikusan a 72. karakterpozícióig számítja a Hollerith-konstanst, és ha az nem terjed eddig, akkor a ki nem használt pozíciókat betűköznek tekinti, és beleszámítja a konstansba. Ennek következtében egyrészt nem kívánt betűköz karakterek kerülnek a konstansba, másrészt a mezőszélességgel baj lesz, mert a beolvasott (észlelt) karakterek száma nem egyezik meg a karakterek kívánt számával. Ez általában végrehajtási hibát okoz a program futásakor, mert a gép nem találja meg a Hollerith-konstans utáni FORMAT lista-elemet.
A H specifikációnak egy igen hasznos és kényelmesen alkalmazható változata van. Ebben a változatban a specifikációban elmarad a mezőszélességet jelző w szám és a H betű; ezek helyett a Hollerith mezőt egyszerűen aposztróf jelek közé tehetjük. Tehát az 5HSANDOR specifikáció így is írható: 'SANDOR'. Ez azért nagyon kényelmes, mert a programozónak nem kell megszámlálnia a Hollerith konstans karaktereit. Ebben az esetben a karakterláncon belüli aposztróf karaktert két egymást követő aposztróf jelöli.
i) Helykitöltés. Az X specifikáció
Betűközöknek az output rekordra való kiírására már eddig három lehetőséget ismertünk meg. Betűköz karakterekkel tölthetjük fel az output numerikus mezők bal szélső karaktereit, ha a mezőszélességet nagyobbra választjuk, mint amennyire u szám kiírásához feltétlenül szükség van. Erre az a) - f) alpontokban láttunk példákat. A másik lehetőség betűközök kiírására a H specifikáció, amelyben a betűközöket "szövegként" adhatjuk meg. Kiírathatunk betűközöket ezenkívül A specifikációval is.
Mindezekben a specifikáció típusokban azonban a betűközök kiírása csak mintegy "melléktermékként" adódik. Most megismerkedünk azzal a szerkesztési specifikációval, amely kifejezetten erre a célra szolgál, és amelyet beolvasási utasításokban az input mező bizonyos karaktereinek ignorálására használhatunk fel.
E specifikáció alakja:
wX
Kiírási utasításokban ez w számú betűköz karakter kiírását jelenti az output rekordra. Beolvasás esetén a gép figyelmen kívül hagyja (átugorja) az input rekord soron következő w karakterét.
Format specifikáció FORMAT (1HA,4X,2HBC)
FORMAT (3X,4HABCD,1X)
A˘˘˘˘BC
˘˘˘ABCD˘
A FORMAT utasításban az X specifikációk biztosítják az input szempontjából közömbös szövegek és betűközök átugratását.
Format specifikáció FORMAT (F4.1,3X,F3.0)
FORMAT (7X,I3)
12.5ABC120
1234567012
12.5, 120
012
j) Új rekord megnyitása. A vessző és a ferde törtvonal mint elhatároló jelek
Eddigi ismereteink alapján egy FORMAT utasításban mindig csak egyetlen rekord formátumát tudjuk megadni: ha új rekordot kell nyitnunk (pl. soremelés), mindig új átviteli utasítást kell kezdenünk. Most megtanuljuk, hogyan kezdhetünk új rekordot átvitel közben, hogyan írhatunk ki teljesen üres rekordokat, és beolvasáskor hogyan ugrathatunk át teljes rekordokat.
Az új rekord megnyitását előíró jel a ferde törtvonal: /. Ez nem specifikáció, hanem olyan elhatároló jel, melynek önálló szemantikai jelentése is van. Elhatároló jelként pótolja u FORMAT lista egyes elemeit elválasztó vesszőt. Ha egy FORMAT listában két E specifikációt kell elkülönítenünk, akkor ezt a formális szempontból teljesen egyenértékű kővetkező alakok bármelyikével megtehetjük:
E13.6/E15.8
E13.6/,E15.8
E13.6,/,E15.8
Két specifikáció között nemcsak egy, hanem akárhány ferde törtvonal is állhat, azonban - a törtvonalnak konkrét jelentése lévén - azok száma nem választható meg tetszőlegesen. Szintaktikusan helyes pl. a következő felírásmód is:
E13.6///E15.8
azonban ennek jelentése eltér az előző formák jelentésétől (a részletes szabályokat lásd alább).
A vesszőnek, mint elhatároló jelnek a használatáról még annyit kell tudnunk, hogy az nem sokszorozható (közvetlenül egymás után nem állhat több vessző), azaz az előbbi példával ellentétben szintaktikusan hibás
E13.6,,,E15.8
A példákhoz hasonlóan viszont - nem kötelezően - elhelyezhetők vesszők az egyes törtvonalak között:
E13.6//,/E15.8
E13.6,/,//,E15.8
stb. A szintaktikusan helyesen elhelyezett vessző nem módosítja a FORMAT lista értelmét.
Mint mondottuk, a törtvonal jelentése a FORMAT listában új rekord megnyitása. Kiírási (WRITE) utasítások esetében ez azt jelenti, hogy a kiírás a következő rekordban (azaz új sorban, vagy újabb kártyán stb.) folytatódik, beolvasási utasításokban pedig hatására a kurrens input rekord esetleg még hátralevő része ignorálódik, és a beolvasás a soron következő rekord elejétől folytatódik. Több, egymás mellett elhelyezett törtvonal megfelelő számú üres rekord kiírását, ill. több rekord átugratását jelenti.
Kiírási utasításokhoz rendelt FORMAT utasításban a FORMAT lista elején vagy végén elhelyezett k számú törtvonal k számú üres rekord, a FORMAT lista közepén elhelyezett k számú törtvonal k-1 számú üres rekord kiírását jelenti. Speciálisan a FORMAT lista középen álló egyetlen törtvonal hatására a kiírás a soron következő rekordban folytatódik (soremelés).
Beolvasási utasításokhoz rendelt FORMAT utasításban, a FORMAT lista elején vagy végén elhelyezett k számú törtvonal k számú input rekord át ugratását (kihagyását), a FORMAT lista közepén elhelyezett k számit törtvonal k-1 számú input rekord átugratását (kihagyását) eredményezi. Speciálisan a FORMAT lista közepén álló egyetlen törtvonal áttérést jelent a soron következő rekordra.
Példa:
egyen R egy 15 X 15-ös valós mátrix. A feladat e mátrix elemeinek sorfolytonos kiíratása hatjegyű mantisszával, decimális normálalakban. A fenti pontosságú kiíratáshoz E13.6 specifikációt kell alkalmaznunk, és így egy mátrixsor nem fér el a sornyomtató egy sorában. Tördeljük tehát mindegyik mátrixsort három sornyomtató sorra! Annak érdekében, hogy az egyes mátrixsorok jól láthatóan el legyenek választva, mindegyik mátrixsor (azaz minden harmadik sornyomtató sor) után hagyjunk ki egy üres sort! Írjuk fel a megfelelő kiíratási programrészt!
Megoldás:DO 1 I=1,15
1 WRITE (5,12)(A(I,J),J = 1,15)
12 FORMAT(E30.6, 4E18.6/E30.6, 4E18.6/E30.6, 4E18.6/)A 12-es FORMAT utasításban találunk törtvonalat mind a lista közepén, mind a lista végén. A lista közepén elhelyezett törtvonalak a sorváltást biztosítják; itt nincs sorkihagyás (üres rekord). A FORMAT lista végén elhelyezett törtvonal viszont a feladat által megkövetelt üres sor kihagyásáról gondoskodik. A specifikációkat úgy adtuk meg, hogy a számanyag lapközépre kerüljön, és az egyes számok között 5-5 elválasztó betűköz karakter is álljon. A középre állítást és a betűköz nyomtatást a "hagyományos" módon, a mezőszélesség növelésével érjük el.
k) Vezérlő karakterek
Ebben az alpontban néhány olyan lehetőséget ismerünk meg, amelyeket ugyancsak a nyomtatási kép vertikális elrendezésének kialakításában használhatunk fel. Az egész alpont kizárólag sornyomtató outputra vonatkozik. Ha szövegfüzért írunk képernyőre, ne írjunk az első karakterpozícióba (azt szóközzel töltsük fel), a szövegfüzér második karaktere kerül a képernyő bal szélére!
A sornyomtatón keresztül kiadott output rekord 1-es számú (bal szélső) karakterpozíciójának a gép különleges értelmet tulajdonít: nem nyomtatja ki, hanem ún. vezérlő karakterként értelmezi.
A legfontosabb és leggyakrabban használt vezérlő karakter az 1-es számjegy. Jelentése: új lap nyitása a sornyomtatón. Ha tehát az output rekord bal szélső karakterpozícióján egy 1-es számjegy áll, akkor a rekord nem csupán a következő sorban, hanem a következő lap első sorában nyomtatódik. Magát az 1-es számjegyet a gép nem nyomtatja ki.
Azt, hogy az output rekord első karaktere 1-es számjegy legyen, sokféleképpen el lehet érni, de leggyakrabban erre a célra a H specifikációt szokták alkalmazni.
A következő vezérlő karakter a 0-j számjegy. Jelentése: dupla soremelés. Hatására a kurrens sornyomtató sor előtt a gép kiír egy üres sort ugyanúgy, mintha a FORMAT specifikáció egy törtvonal karakterrel kezdődne. Használata szintén H specifikációval a legcélszerűbb; ez többnyire az 1H0 specifikáció. Mivel a törtvonal karakter segítségével azonos hatás érhető el, ezért ez a vezérlő karakter nélkülözhető.
A harmadik vezérlő karakter a "+" jel. Ennek hatására a rekord kiírásakor a sornyomtató egyáltalában nem emel sort, tehát az új rekordot az előzőre írja rá. Elég ritkán, főként speciális nyomtatások esetén (ábrák, grafikonok nyomtatása stb.) alkalmazzák, amikor az output rekordot valamely oknál fogva csak több részletben lehet kiírni. Ilyenkor az első kiíráskor a később kitöltendő karakterpozíciókra betűközöket íratunk, majd a későbbi "újrányomtatások" folyamán fokozatosan kitöltjük ezeket a helyeket.
Konkrét gépi reprezentációkban további specifikus vezérlő karakterek is lehetnek.
Ne feledkezzünk meg arról, hogy az első karakterpozícióban álló karaktert a gép mindig vezérlő karakterként értelmezi, akármilyen céllal is írattuk azt eredetileg oda. Ha pl. a FORMAT lista első eleme egy I3 specifikáció, és a kiíratandó egész változó aktuális értéke mondjuk 176, akkor a sornyomtató az 1-es számjegyet lapváltásra szóló utasításnak tekinti, és a kinyomtatás eredménye a 76-os szám a következő lap Idején.
Végezetül ismételten emlékeztetjük az olvasót arra, hogy a vezérlő karakterek kizárólag a sornyomtatóra vonatkozólag "vezérlők", egyéb output perifériákon ugyanúgy kiíródnak, mint a többi karakter. Azok a karakterek, amelyeknek nincs meghatározott vezérlési jelentése, a kiírás során eltűnnek, vagyis az, első pozíción álló karakter sohasem kerül kinyomtatásra.
l) Decimális normálótényező. A P kiegészítő specifikáció
A P kiegészítő specifikáció segítségével a valós konverziós specifikációk (E, F, G és D) hatását módosíthatjuk. A kiegészítő specifikáció alakja:
nP
ahol n tetszőleges (pozitív, zérus vagy negatív) egész szám. Ez nem önálló specifikáció; mindig egy valós konverziós specifikáció előtt áll. Példák a kiegészítő specifikáció elhelyezésére:
3PF9.4 -2P3E15.8 0PG16.7
A kiegészítő specifikáció megelőzi mind a konverziós specifikációt, mind az esetleges ismétlési tényezőt.
A READ utasításhoz rendelt FORMAT-ban előforduló P kiegészítő specifikáció hatása a következő:
Ha a P kiegészítő specifikációt tartalmazó FORMAT utasítás egy WRITE utasítást vezérel, akkor a normálótényező hatása attól függően más és más, hogy a kivitel milyen konverzióval megy végbe:
Ezek a szabályok összhangban vannak egy, az a) alpontban kimondott elvvel: ha egy mennyiséget valamely specifikáció szerint kiíratunk, majd ugyanezen specifikáció szerint később visszaolvastatjuk, ugyanazt a számot kell, hogy visszakapjuk. Ennek megfelelően, ha az F specifikációval kiíratott mennyiségek a kimeneti konverzió közben 10^n-nel szorzódnak, szükségszerű, hogy visszaolvasáskor 10^n-nel osztódjanak. Továbbá, ha a kimeneti konverzió közben a normálótényező nem változtatja meg a decimális exponensű szám értékét, akkor a decimális exponensű számokra beolvasáskor is hatástalan kell legyen. A G specifikáció - sajnos - nem teljesíti a fenti elvet, mert ha a szám olyan, hogy a kinyomtatáskor exponens nélküli szám keletkezik, akkor ennek normálótényező hatása alatt történő visszaolvasásakor a visszakapott szám különbözik a kiírttól.
A P kiegészítő specifikációra még a következő szabály is vonatkozik: a normálótényező hatása nemcsak arra a konverziós specifikációra érvényesül, amely előtt el van helyezve, hanem minden E, F, G vagy D specifikációra, amely a FORMAT listán sorrendben ez után kerül értelmezésre. Amikor a gép értelmezni kezdi a FORMAT listát, zérus normálótényezőt tételez fel mindaddig, amíg egy ettől különbözőt nem talál. Ha egyszer a FORMAT listában előfordult egy zérustól különböző normálótényező, akkor ez marad érvényben mindaddig, amíg a kiértékelés folyamán egy újabb normálótényező (azaz egy újabb P kiegészítő specifikáció) ezt meg nem változtatja. A zérus normálótényezőre a 0P kiegészítő specifikáció segítségével térhetünk vissza.
Talán nem árt felhívni a figyelmet egy apróságra, amely esetleg elkerülné az olvasó figyelmét. Arról van szó, hogy az értékes jegyek száma szempontjából a normálótényező másként viselkedik az F, és másként az E specifikáció esetén. Az F specifikációnál az történik, hogy a szám előbb megszorzódik tíznek a normálótényező által előírt hatványával, majd az eredmény kiíratódik az adott specifikáció szerint. Itt tehát az értékes jegyek száma aszerint nő vagy csökken, hogy a normálótényező hatványkitevője pozitív vagy negatív-e. Az E specifikáció esetében a normálótényező működésének mechanizmusa pontosan a következő: 1P normálásra a szám "elfoglalja" a közönséges lebegőpontos nyomtatásnál kihasználatlan, tizedespont előtti helyi értéket, vagyis ezzel eggyel megnöveli az értékes jegyek számát. A normálótényező további növelése nem ad újabb értékes jegyeket, mert amennyivel több jegy kerül a tizedespont elé, annyival kevesebb áll mögötte. Ha a normálótényező negatív, akkor a mantissza előtt értéktelen zérusok jelennek meg, ezért az ebből eredő jegyveszteség elkerülése céljából a mezőszélességet megfelelően növelnünk kell.
6.5. A FORMAT és az I/O lista kölcsönhatása.
FORMAT lista elhelyezése tömbökben
Az előző pontban megismertük a FORMAT lista különböző lehetséges elemeit és ezek funkcióját. Ebben a pontban olyan szabályokat ismerünk meg, amelyek nem a FORMAT lista egyik vagy másik elemére vonatkoznak, hanem a lista egészére. Közelebbről, olyan szabályokról lesz szó, amelyek arra nézve adnak útmutatást, hogyan történik a FORMAT és az I/O listák elemeinek egymáshoz rendelése.
Ilyen szabályokat már az eddigiekben is megismertünk. Láttuk, hogy mind az I/O, mind a FORMAT lista értelmezése balról jobbra halad, és az egymáshoz rendelés lényegében az "egyet innen, egyet onnan" elv alapján megy végbe. Azért csak lényegében, mert mindkét listában lehetnek "többszörös" elemek is. Az I/O lista többszörös elemei a tömbazonosítók (melyek a tömb valamennyi elemének átvitelét előírják - lásd a 2. pontot) és az összetett I/O listaelemek (melyek szintén valamilyen elemcsoport átvitelére adnak utasítást). Minthogy minden átvitelre kerülő változóhoz kell hozzárendelve lennie egy FORMAT listaelemnek, egy többszörös I/O listaelemhez annyi FORMAT listaelemre van szükségünk, amennyi az I/O listaelem szerint átviendő változók száma. Azonban a FORMAT listának is lehetnek többszörös elemei, mégpedig - eddigi ismereteink szerint - azok az elemek (specifikációk), amelyek előtt ismétlési tényező áll. A kétféle lista együttes feldolgozása során az "egyet innen, egyet onnan" elvet tehát szabatosan úgy kell érteni, hogy mindkét listában minden egyes elemet multiplicitásával (ismétlési számával) veszünk figyelembe.
Ebben a pontban egy olyan lehetőséget ismerünk meg, amely lehetővé teszi, hogy FORMAT listaelemek egy csoportját (tehát nemcsak egyetlen FORMAT listaelemet) elláthassunk ismétlési tényezővel, és ily módon FORMAT listaelem-csoportokat képezzünk.
Ilyen összetett FORMAT listaelemhez - vagy, ahogy nevezni szokták, ismétlési csoporthoz - jutunk, ha a FORMAT lista tetszőleges részét kerek zárójelek közé zárjuk, és a kezdő-zárójel elé egy pozitív egész ismétlési tényezőt írunk.
Például ilyen ismétlési csoportot tartalmaz a következő FORMAT utasítás:
FORMAT(1H1,56X,8HTABLAZAT,///,15X,5(I10,F8.3))
Itt az ismétlési csoport két FORMAT listaelemből, I10-ből és F8.3-ból áll; az ismétlési tényező az 5-ös szám. Egy ismétlési csoport akárhány FORMAT listaelemet tartalmazhat.
Az ismétlési csoport lényegében rövidített írásmód; egyetlen eltéréstől eltekintve (lásd alább) egyenértékű azzal, mintha a csoport elemeit annyiszor egymás mellé írtuk volna, amennyi az ismétlési tényező. A példát tekintve, az 5(I10, F8.3) ismétlési csoport egyenértékű a következővel:
I10,F8.3,I10,F8.3,I10,F8.3,I10,F8.3,I10,F8.3
A FORMAT lista értelmezésekor tehát az összetett FORMAT listaelemet annyiszor kell figyelembe venni, amennyi az ismétlési tényező - ugyanúgy, mint ahogy ezt az ismétlési tényezővel ellátott specifikáció kapcsán is láttuk (pl. 5F9.6).
A karakterátvitelre vonatkozó eddigi valamennyi példánk közös vonása volt, hogy az l/O lista és a FORMAT lista elemeinek száma - a multiplicitásokat is figyelembe véve - megegyezett, vagyis az "egy innen, egy onnan" elv alkalmazása esetén a két listának egyszerre értünk a végére. Következő feladatunk annak a tisztázása, hogy mi történik abban az esetben, ha ez nem teljesül, tehát a két lista párhuzamos feldolgozása során valamelyik előbb ér véget, mint a másik?
Egyszerűbb a helyzet, ha az I/O listának érünk előbb a végére. Ebben az esetben az átvitel véget ér, és a FORMAT lista fel nem dolgozott elemei figyelmen kívül maradnak.
Jóval bonyolultabb eset, ha a FORMAT lista véget ér, az I/O listának pedig még vannak fel nem dolgozott elemei. Erre az esetre a következő szemantikai szabályok az irányadók:
A 2. szabályból nyilvánvaló, hogy a FORMAT listának az utolsó ismétlési csoportot megelőző részére többé nem térünk vissza, tehát e részt mindenképpen csak egyszer "járjuk be", míg az utolsó ismétlési csoportot és az utána álló részt a szükségtől függően esetleg többször is.
Példák:
1. Tekintsük a következő kiírási utasítást:
WRITE (5,8)(X1(I),Y1(l),X2(I),Y2(I), I = 1,20)
8 FORMAT(1H1,//51X,18HA VEKTOROK ELEMEI:///,
X36X,2HX1,13X,2HY1,13X,2HX2,13X,2HY2///,
X1(33X,2(F7.4 5X,E13.6,5X)))
Mielőtt a kiírás részleteibe bocsátkoznánk, vegyük észre, hogy a 8-as címkéjű FORMAT utasításban egy kétszeresen egymásba skatulyázott ismétlési csoportból álló rendszer található, melyek közül a belsőnek az ismétlési tényezője 2, a külsőé a formális jelentőségű 1 (lásd alább!). Az ismétlési csoportok kétszeres mélységig egymásba skatulyázhatok. (A legtöbb gépi reprezentációban az ismétlési csoportok tetszőleges mélységben is egymásba skatulyázhatok.)
Ugyancsak az ismétlési csoportok szintaxisára vonatkozik a következő szabály: Az ismétlési tényező elhagyható a csoport kezdőzárójele előtt; ebben az esetben 1-nek vesszük. A példabeli FORMAT utasítás külső ismétlési csoportjának tényezőjét tehát akár el is hagyhattuk volna.
A példa jelentésére térve, először is megállapíthatjuk, hogy az négy húszelemű vektornak, X1-nek, Y1-nek, X2-nek és Y2-nek a kinyomtatását írja elő. Kérdés azonban, milyen formátum szerint történik a kinyomtatás? A FORMAT lista mindenesetre egy sereg szerkesztési specifikációval kezdődik: új lap nyitása, kétsoros felső margó, egy címszöveg, két üres sor, egy fejléc, és végül két újabb üres sor. Ezután következik a külső ismétlési csoport, amely egy 33 karakter szélességű bal margóval kezdődik, majd eljutunk a belső ismétlési csoporthoz. Ebben vannak a konverziós specifikációk. Az első F7.4 specifikáció szerint kiíródik X1(1), majd öt betűköz karakter, és az E13.6 specifikáció szerint Y1(1) aktuális értéke következik. Ezt újabb öt betűköz karakter követi, amivel elérkezniük a belső ismétlési csoport végéhez. Ennek ismétlési tényezője 2, ezért most vissza kell térnünk az F7.4 specifikációra. Ennek vezérlete alatt nyomtatódik X2(1), majd - az előzőkhöz hasonlóan - öt betűköz kinyomtatása után az E13.6 specifikáció szerint Y2(1).
Most már elérkeztünk a belső ismétlési csoport végéhez, és egyben a külsőéhez is, hiszen ez utóbbi ismétlési tényezője 1 volt. A FORMAT lista tehát véget ért, azonban még egy sereg elem vár kiírásra. A FORMAT lista értelmezésére vonatkozó szabály szerint ilyenkor vissza kell mennünk a FORMAT listában a "legközelebbi" jobb oldali zárójelig (a 2a szabályban pontosan meghatároztuk, hogy ez mit jelent), meg kell keresnünk az ennek megfelelő bal oldali zárójelet, és innen kezdve újra kell értelmeznünk a FORMAT listát. A leírtak szerint a külső ismétlési csoport kezdetére jutottunk vissza, tehát az X1(2), Y1(2), X2(2) és Y2(2) elemeket rendre F7.4, E13.6, F7.4 és E13.6 specifikációk szerint nyomtatjuk ki. Ezt követően újra visszatérünk a külső ismétlési csoport elejére, és így nyomtatjuk ki a 3-as indexű vektorelemeket,stb.
Ez a FORMAT utasítás tehát táblázatosán nyomtatja ki a négy vektor elemeit, az azonos indexűeket egy sorban, és a számokat 5-5 betűköz karakterrel elválasztva.
A példán láthatjuk, hogy a cím, a fejléc és a táblázat nyomtatása egyetlen WRITE utasítással elintézhető, míg eddigi ismereteink szerint ehhez legalább kettőre lett volna szükség, és az utóbbit egy 20 menetes DO ciklusba kellett volna beágyazni. A program kidolgozását "hagyományos" programozási eszközök felhasználásával az olvasóra bízzuk.
Az egész példában a sarkalatos fogás az 1-es ismétlési tényezővel ellátott külső ismétlési csoport alkalmazása. Vegyük észre, hogy ebben nem is az ismétlés a lényeg, hiszen valójában ismétlés nem is történik. A csoport rendeltetése annak a helynek a kijelölése, ahonnan kezdve a FORMAT lista értelmezését újra kell kezdeni.
2. Legyen a memóriában egy 30x30-as valós tömbünk. A feladat e tömb elemeinek sorfolytonos kinyomtatása, a következő formátum szerint:
Mindez nem különösebben nehéz feladat, érdekessé a következő - utolsó - kikötés teszi:
Megoldás:
WRITE(5,8)((B(I,J),J = 1,30,)I = 1,30)
8 FORMAT(6)5(10X,E15.8,5E17.8,5/),/),1H1)
Ez a FORMAT utasítás is tartalmaz egy kétszeresen egymásba skatulyázott ismétlési csoportot. A belső egyszerű specifikációs lista, amely egyetlen sornyomtató sor formátumát határozza meg: 10 karakternyi bal margó, és hat E15.8 formátummal kinyomtatott szám, amelyek két-két betűköz karakterrel vannak elválasztva. A lista végén egy ferde törtvonal karakter jelzi, hogy a hatodik szám után új sort kell nyitni. A belső ismétlési csoport együtthatója 5, vagyis öt sor kinyomtatása után át lehet térni a külső ismétlési csoport soron következő elemének értelmezésére. Ez ismét egy ferde törtvonal karakter, tehát szintén új sor nyitását írja elő; az előzővel együtt ez egy üres sor kihagyását jelenti. Ily módon jön létre mátrixsoronként egy-egy elválasztó üres sor. Ha már hatszor megtörtént az üres sor kihagyása, akkor befejeztük a külső ismétlési csoport értelmezését, és áttérhetünk a FORMAT lista soron következő elemének feldolgozására. Ez egy "új lap" specifikáció, hatására a gép új lapot nyit, majd visszatér a külső ismétlési csoport elejére. A nyomtatás az előzőkhöz hasonlóan folytatódik egészen addig, míg a WRITE lista elemei el nem fogytak.
Ez a példa önmagában is jól illusztrálja a jelen alpontban részletezett szabályokat, de még ki is egészíthetjük azzal, hogy a nyomtatás előtt is előírjuk új lap nyitását, valamint egy cím felirat elhelyezését. Az ily módon kibővített FORMAT utasítás pl. a következő lehet (a WRITE változatlan, így azt nem ismételjük meg):
8 FORMAT(1H1,///52X,17HA B MATRIX ELEMEI///,
X6(5(10X,E15.8,5E17.8,/),/),1H1)
Bár a karakterátvitelek eddig megismert módszerei - amint azt a tárgyalt példák is bizonyítják - igen sokféle formaszerkesztési lehetőséget biztosítanak, egy szempontból az általunk megismert FORMAT utasítások kétségkívül kissé merevek. A baj alapvetően az, hogy a FORMAT utasítást, a FORMAT listával együtt, a program írásakor le kell rögzítenünk, és azt a program futása folyamán nem változtathatjuk meg pl. a programbeli változók értékétől függően. Röviden szólva, hiányoljuk, hogy a FORMAT utasításnak nem lehet "értéket adni", (Egy ilyen lehetőséget ugyan megismertünk a 4.h alpontban, ez azonban nagyon korlátozott.)
Az alábbiakban egy módszert ismertetünk, mely bizonyon határok között lehetővé teszi a FORMAT lista "menet közbeni" (azaz a program végrehajtása folyamán történő) megváltoztatását.
Az ASA FORTRAN szintaktikus szabályai megengedik, hogy a READ (u,f) L és WRITE (u,f) L karakterátviteli utasításokban f tömbazonosító lehessen. Ebben az esetben a FORMAT listát - az őt bezáró kezdő- és végzárójellel együtt - abban a tömbben kell elhelyezni, amelynek azonosítója az átviteli utasításban el van helyezve. (Maga a FORMAT szó nem tartozik a listához.) Egyetlen megkötés, hogy az ilyen FORMAT lista nem tartalmazhat H specifikációt. Ennek a lehetőségnek, mint erre már utaltunk, az a gyakorlati haszna, hogy - a programok adatsorozataival együtt - karakterinformációként beolvastathatjuk az input és output formátumot is. Minthogy az így beolvastatott FORMAT listán nem szerepelhet H specifikáció, ily módon nem szervezhetjük új lap nyitását, valamint címfeliratok nyomtatását. Ezek megoldása a 4. g), h) és k) alpontokban leírtak szerint végezhető.
6.6. Az ENCODE, DECODE utasítás
A DECODE utasítás ASCII formátumú adatokat továbbít a formátum specifikáció szerint egy tömbváltozóba. A DECODE tehát a READ utasítással analóg, mivel ASCII-ről belső formátumra konvertál (szöveg típusú adatokat pl. INTEGER típusba). Az ENCODE utasítás ennek ellenkezőjét végzi: a megadott formátumú adatokat ASCII formátumba alakítja.
ENCODE(a,f) L
DECODE(a,f) L
ahol
Ügyelni kell arra, hogy a tömb mindig elég nagy legyen ahhoz, hogy az összes feldolgozott adatot tartalmazza. Túlcsordulás ellenőrzés nincs, ilyen esetben az ENCODE valószínűleg törli a tömb utáni fontos adatokat.
7. A program fordítása
A programcsomag szövegszerkesztőt nem tartalmaz, a programszöveg szerkesztésére tetszőleges szövegszerkesztő használható, de célszer olyat használni, ami kiírja a kurzor pillanatnyi pozíciójának koordinátáit.
A futtatható állomány elkészítése két lépésben történik. (Pár rövidke programmal való próbálkozás után megtudjuk, miért aratott a Turbo Pascal keretrendszre akkora sikert a maga korában...) Első lépés a program lefordítása. A fordító az F80 paranccsal indítható, betöltés után a '*' (csillag) jel jelzi, hogy a program várja parancsaainkat. A fordítást végző parancs alakja:
fnév1,fnév2=fnév3
ahol
A file-nevekben meghajtójel megadható, két meghajtó használata eseté javasolt is másik meghajtóra fordítani a diszkpörgetés idejének csökkentése végett.
A file nevek megadásakor viszont a kiterjesztést nem szükséges megadni. Ha nem adunk meg kiterjesztést, a programcsomag valamennyi eleme a szokványos kiterjesztéseket használja:
Az fnév1 (objektum-file neve) elhagyható, ebben az esetben az objektum-file neve azonos lesz a forrásprogram nevével.
Ha fnév2 elmarad, nem jön létre lista-file.
Legegyszerűbb esetben tehát a fordítást végző parancs:
=fnév3
A fordítást végző parancsban a file nevek után opcionális feladatot ellátó kapcsolók is megadhatóak. Több kapcsoló is használható egyszerre, mindegyik kapcsoló előtt / (per) jelnek kell lennie.
A fordító kétféle hibát kezel: A - kérdőjellel jelölt - figyelmeztetések és a - százalékjellel jelölt - végzetes hibákat. Mindkét esetben kijelzi a fordító a hiba helyét is. Végzetes hiba előfordulásakor le is áll a fordító. Figyelmeztetés esetén azonban a lefordított program helyes működése nem valószínű...
A fordítóból a CTRL+C vagy STOP billentyűkombinációval lehet kilépni.
Második lépésben a lefordított áthelyezhető kódot össze kell fűzni, a FORTRAN rutinjait tartalmazó FORLIB.REL könyvtárral (ha más könyvtári rutingyűjteményt használunk, azzal is). Ezt a LINK-80 programmal lehet elvégezni, amit az L80 paranccsal lehet betölteni, de parancssoból is használható. Ennek legegyszerűbb formája:
L80 fnév/e,/n
Ami a megadott nevű .REL kiterjesztésű file-ból elkészíti a futtatható .COM kiterjesztésű állományt.
Itt is igaz, hogy sok diszkpörgetést megspórolunk, ha az új file másik meghajtón hozzuk létre. Pl.:
L80 a:calendar/e,b:calendar/n
8. Futásidejű hibák
A futás közben fellépő hibáknál nem kapunk hibaüzenetet, csak kétjegyű hibakódot. Ezek jelentése:
Figyelmeztetések:
A programfutás megszakadását okozó végzetes hibák:
A hiba előfordulásának címét is megkapjuk, ennek ismeretében a lista-file-ban történő kutakodás révén kerülhetünk közelebb a hiba sikeres javításához.