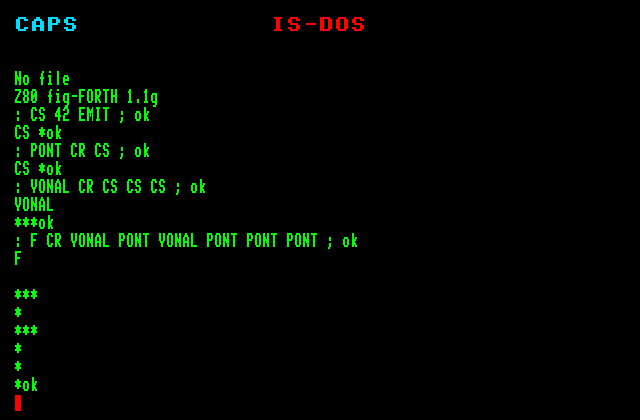
fig-Forth 1.1g
Adorján Noémi: Forth lépésről lépésre (1990)
Lektorálta: Csurgai László
Műszaki könyvkiadó
Tartalom
Bevezetés
A FORTH láncolt kódú interpretált nyelv, melyet Charles Moore kezdett el fejleszteni az 1960-as évek elején, a Kitt Peak obszervatórium teleszkópja irányítási problémáinak megoldása kapcsán. Más programnyelvekhez hasonlóan a FORTH-nak is több "nyelvjárása" létezik, ezek között néhány szabványos is van. Az egyik a FORTH 79, amelyet Leo Brodie ír le a "Starting Forth" című nagyszerű könyvben. Későbbi változat a klasszikusnak számító FIG-FORTH 1.1. (a FORTH 79 szabványhoz igazodva).
Mit jelent az, hogy FIG? FORTH INTEREST GROUP, PO BOX 1105, SAN CARLOS, CA 94070. Ez a FORTH terjesztésére, implementálásának és használatának segítésére alakult társaság. Nemcsak szabvány FORTH ajánlást dolgoztak ki, hanem, több egyéb hasznos kiadvány mellett 9 különböző processzorra közreadták a FORTH interpreter forráslistáját (amely részben az adott gép assembly nyelvében, részben pedig FORTH-ban van, a 8080-as forráslista megtalálható a letölthető csomagban Z80FORTH.Z80 néven) és a FORTH-szal kapcsolatos egyéb fontos tudnivalókat tartalmazó kézikönyvet (gyakorlatilag ingyen). Egy ilyen kézikönyv (FIG-FORTH INSTALLATION MANUAL) segítségével már nem nehéz FORTH interpretert írni, kis túlzással azt mondhatnánk, hogy bárki vállalkozhat rá.
A FORTH-szal való játszadozás közben látni fogjuk, hogy FORTH-ban mindent lehet. De nem mindent ajánlatos!
Ne lepődjön meg a gyakorlatlan programozó (a gyakorlott se), ha "vad" jelenségeket tapasztal. Lehet, hogy csak kis hibát követett el, s véletlenül tenyerelt rossz helyre. Ha nincs jobb ötlete, mindig lehet resetelni a gépet, újratölteni a FORTH-ot abban a tudatban, hogy ez már másokkal is előfordult.
A FORTH-ra legelfogultabb rajongója sem mondhatja, hogy könnyen tanulható. Előnyeit többek között annak köszönheti, hogy gépközeli nyelv (tehát használatához érteni kell egy kicsit a számítógép "lelkét"), hogy bővíthető, alakítható (tehát tudni kell valamennyire, hogyan működik maga a FORTH), kicsi a memóraigénye (a fig-FORTH itt bemutatásra kerülő változata mindössze 6656 byte!) és hogy sok benne az eredeti, szellemes, de nem feltétlenül könnyen érthető elgondolás. A FORTH megismerése tehát nem megy erőfeszítések nélkül. Mégis megéri, hiszen
A FORTH nagy része maga is FORTH-ban íródott. A FORTH alapszavak FORTH forrásszövegei bőséges példatárul szolgálnak, amelyből a szerző is jócskán merített. Mindenkinek, aki elszánta magát a FORTH tanulására, sok sikert és jó szórakozást!
1. Az első lépések
Töltsük be és indítsuk el a FORTH-ot! Ezt az IS-DOS elindítása után a Z80FORTH.COM file futtatásával tehetjük meg. Később másképp fogjuk indítani a FORTH-t.
A FORTH interpreter a verziószám kiírásával indul (ez az estünkben Z80 fig-FORTH 1.1g). A "No file" üzenet jelentésével később foglalkozunk. Ezután az interpreter várja, hogy adjunk neki egy parancssort. Addig vár, amíg a neki szóló sort be nem fejeztük. Honnan tudja, mikor fejeztük be? Onnan, hogy lenyomjuk a sor végét jelző ENTER billentyűt.
A begépelt sort az ENTER adja át a FORTH-nak; az ENTER lenyomásáig tehát más nem történik, mint az, hogy a FORTH ránk vár. |
Ezt érdemes megjegyezni, ha nem akarunk sok időt azzal tölteni, hogy az ENTER nélkül adott utasításaink végrehajtására várunk. Ha melléütöttünk, javíthatunk. Az ERASE billentyű lenyomásával törölhetjük az utolsó karaktert a sorból - természetesen csak az ENTER lenyomása előtt.
Kezdjük úgy, hogy mindjárt be is fejezzük: adjunk egy üres parancssort: ehhez csak az ENTER-t kell megnyomnunk egy üres sorban. A feleletként kapott OK azt jelenti, hogy a FORTH a mondottakat (esetünkben a nagy semmit) hiánytalanul végrehajtotta. Az OK után a FORTH a következő sor elejére várja újabb kívánságainkat. Egy egyszerű szó, amit megért:
CR
Az OK ezúttal egy sorral lejjebb jelenik meg, a FORTH kiírt egy kocsivissza és egy soremelés karaktert.
Akik OK helyett hibaüzenet kaptak, figyelmetlenek voltak és nem pontosan ugyanezt írták be
a FORTH-ban, minden, az interpreternek szóló utasítást nagybetűvel kell írnunk |
Hogy a hatás látványosabb legyen, írjuk most ugyanezt egy sorba többször! Ehhez azt kell tudnunk, hogy
az egyes szavakat egy soron belül (egy vagy több) szóközzel választjuk el egymástól |
Tehát, ha azt írjuk:
CR CR CR CR
a FORTH kiírja a négy üres sort és OK-val díjazza a szabályos feladatkiírást. Ha viszont azt írjuk, hogy
CRCR CR CR
akkor a FORTH az érthetetlen CRCR láttára megsértődik, és OK-ra sem méltatva minket, abbahagyja az egészet. A két "jó" CR-t már el sem olvassa, csak egy hibakódot kapunk. Máskor is ilyet kapunk, ha a FORTH számára ismeretlen szóval próbálkozunk. (A hibakódok "megfejtése" megtalálható a B függelékben.)
Játsszunk még "kiírósdit":
42 EMIT
Az EMIT szó kiírja azt a karaktert, amelyiknek a kódját megadtuk neki; a 42 a csillag kódja.
Definiáljunk egy csillagíró szót!
: CS 42 EMIT ;
Ezzel megírtuk első FORTH programunkat. Most már ez is ugyanolyan FORTH szó, mint akármelyik másik, tehát nevének leírásával futtatható:
CS
Sőt, új szavak alkotására is felhasználhatjuk:
: PONT CR CS ;
: VONAL CR CS CS CS ;
A példában minden szót kipróbáltunk, mielőtt újabb szavakban felhasználtuk volna őket. így lehet (és ajánlatos) "biztosra menni". A FORTH egyik legvonzóbb tulajdonsága éppen ez: az építőkövek, amelyekből a program végül összeáll, megírásuk után azonnal, külön-külön is kipróbálhatók.
A FORTH alapszavak nagy része ugyanígy FORTH-ban íródott, más alapszavak fel használásával. Például a SPACE szó. amely egy szóközt ír a képernyőre, így épül fel:
: SPACE 32 EMIT ;
A már ismert CR pedig így:
: CR 13 EMIT 10 EMIT ;
Az első lépések között kell megemlíteni a FORTH használatának utolsó lépését: a FORTH interpreterből a
BYE
szóval léphetünk ki szabályosan, adatvesztés nélkül.
1.1. A szótárról
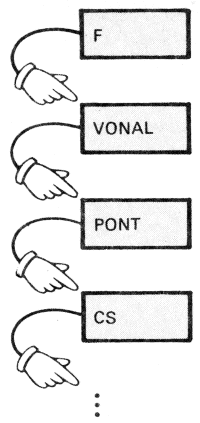 Mitől lett a CS, az F stb. végrehajtható szó? Mi történik, amikor ilyen "kettőspontos szódefiníciót" írunk?
Mitől lett a CS, az F stb. végrehajtható szó? Mi történik, amikor ilyen "kettőspontos szódefiníciót" írunk?
A FORTH a számára értelmezhető szavakat egy szótárban tartja. Betöltés után a szótárban a FORTH alapszavak vannak. Új szavak létrehozásával a szótárat - vagy, ha úgy tetszik, magát a FORTH nyelvet - bővítjük.
A szótári szavak neveit a VLIST (Vocabulary List; a vocabulary, ejtsd: vokébjulöri szó, jelentése: szótár) szóval írathatjuk ki a képernyőre. A VLIST hatására meginduló "szóáradat" bármely billentyű leütésével megállítható. Ha saját szavakat definiálunk és utána VLIST-tel szemügyre vesszük a szótárunkat, látjuk, hogy a legutoljára definiált szavak jelennek meg legelőször; előbbi működésünk után például a szótárlista valahogy így kezdődik: F VONAL PONT CS
A FORTH interpreter, mikor egy szót értelmezni akar, először is elkezdi azt a szótárban keresni. Mégpedig az utoljára definiált szónál; ebben talál adatot arról, hogy hol kezdődik az utolsó előttinek írt szó, így ha kell, ott folytatja a keresést, és így tovább. Ha tehát példánkban az F definíciója után írunk egy újabb F szót:
: F 70 EMIT ;
akkor az F szót "átdefiniáltuk"; a FORTH figyelmeztető hibajelzést ad és beírja az új szót a szótárba. Nézzük, mi az eredmény
F
A FORTH ezt a második F definíciót találta meg. (70 a nagy F kódja.)
Álljunk meg egy pillanatra!
Jó, jó, hogy a CS, F stb. attól végrehajtható, hogy benne van a szótárban. Beletettük, mikor definiáltuk őket. Az is igaz lehet, hogy az EMIT benne van. Hiszen alapszó. De mitől van benne a 42 meg a 70? Csak nincs benne az összes szám? Ha pedig valami nincs a szótárban, akkor miért nem szól miatta az interpreter, miért tesz úgy, mintha minden a legnagyobb rendben volna?
Elvből. Az elv az, hogy ami nem szótári szó, az biztosan szám, tehát a FORTH interpreter a szótárban való sikertelen keresés után megpróbálja számnak értelmezni a kapott karaktersorozatot. Ha nem megy ("számszerűtlen" karakterek vannak benne), akkor az tényleg hiba. Ha viszont igen, számról van szó, akkor ez a szám a verembe kerül.
1.2. Mi a verem?
A verem (angol neve stack, ejtsd: sztek) igen fontos része a FORTH-nak. Ebben "leveleznek" egymással az egyes szavak. Például az EMIT a veremben keresi annak a karakternek a kódját, amelyet ki kell írnia a képernyőre; miután kiírta, le is pusztítja a veremről.
Azért hívják veremnek, mert több dolgot (esetünkben több számot) lehet benne tartani; ezek közül mindig csak egyhez férünk hozzá: ahhoz, amelyik legutoljára került oda, vagyis "legfelül van".
Hogy ezt kitapasztalhassuk, egy új FORTH alapszót tanulunk.
Próbáljuk ki!
65
.
A veremre tettük a 65-öt (első sor), a ponttal "rákérdeztünk" (második sor). Vissza is írta! Egyúttal törölte is. Győződjünk meg erről! Írjunk még egy pontot! Hibajelzést kapunk, amely azt jelenti, hogy több elemet akartunk a veremből elhasználni, mint amennyi volt benne.
És ha nem? Könnyen előfordulhat, hogy a Kísérletező Olvasó már egy csomó mindent művelt, mire ide eljut. Esetleg már volt a veremben valami. A verem kiürítésének legegyszerűbb módja: begépelünk egy szót, amelyről tudjuk, hogy a FORTH nem ismeri. A "feldühödött" interpreter kiüríti a vermet; ha ezután próbálja ki valaki a fentieket, meglátja, hogy így igaz. A módszer hasznos lehet, mikor véletlenül rakjuk tele a vermet "szeméttel". (Mondjuk ciklusban felejtünk el valami fölöslegeset törölni.)
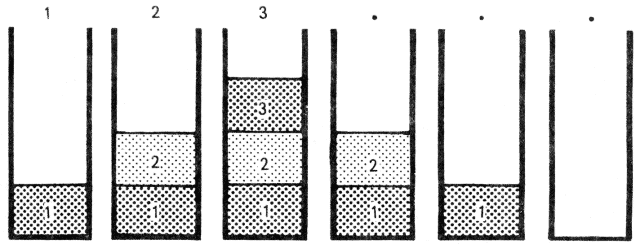
Próbáljuk ki ugyanezt több számmal:
1 2 3 . . .
Melyik számot fogja először kiírni? Azt, amelyik a verem tetején van, tehát amelyik utoljára került a verembe. Ezt egyúttal törli is; a következő pont tehát az alatta levő elemet írja ki és törli. A kapott válasz: 3 2 1 lesz. Az egyes lépések után a verem az alábbi ábra szerint néz ki.
1.3. Vissza a szótárhoz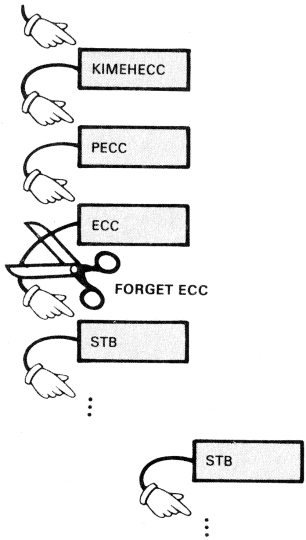
Lehetőségünk van a szótár szavait újradefiniálni, azaz egy szónévhez két (sőt több) meghatározást rendelni. Hasonló ez egy igazi értelmező szótárhoz, ahol egy címszóhoz több jelentés, meghatározás is tartozhat. Azt, hogy a sok jelentés közül melyiket használjuk, a szó környezete általában egyértelműen meghatározza. A FORTH ennél sokkal egyszerűbben dönt arról, hogy éppen amelyik jelentést kell figyelembe vennie. Egy adott szó végrehajtása mindig a legutolsó definíció törzsének végrehajtását jelenti. Ne felejtsük el viszont, hogy a szó újbóli definiálása nem jelenti az előző definíció (vagy definíciók) törlését! Ezek a szótárban továbbra is megmaradnak, csak éppen új szó "eltakarja" a jelentését. Ha egy szót újradefiniálunk, a FORTH 4-es hibakóddal figyelmeztet.
Még valami. Mi legyen, ha ráuntunk a definícióinkra, nem akarjuk őket tovább használni? Például átdefiniáltunk egy szót, de megbántuk.
A radikális megoldás: a COLD (hidegindítás) szó. Visszaállítja a szótárat, a vermet meg egy és más, eddig még nem ismertetett dolgot a betöltés utáni, eredeti állapotba. A szótár tehát a FORTH alapszókincset fogja tartalmazni.
A finomlelkű megoldás a FORGET (felejts) szó. A FORGET után (még ugyanabban a sorban) kell megadni az elfelejtendő szó nevét. Pl. ha a második F szavunkat vissza szeretnénk vonni:
FORGET F
A FORGET elfelejti a megadott szót, ezenkívül az utána definiált (tehát a szótárban "fölötte levő") szavakat.
Micsoda??? Mindent, amit utána definiáltunk?
Ez így van. Elvileg ugyanis bármelyik szóban, amelyet az elfelejtendő után írtunk, használhattuk ezt az éppen törölni kívánt szót! A FORTH szótár szavai egymásra épül(het)nek, nem lehet belőle csak úgy, "középről" törölni. (Meg lehet viszont őrizni szavaink forrásszövegét, hogy hogyan, arról lesz még szó. Most csak meg szeretnék nyugtatni mindenkit: nem kell majd egy hiba miatt mindig mindent újra begépelni!)
Melyik F szótól kezdve fog a FORGET felejteni, ha kettő is van? Szinte látatlanban meg lehet mondani: a "felsőtől", az utoljára definiálttól. A szavak keresése a szótárban, bármi célból történjen is, mindig felülről halad, ilyen irányban lehet a szótárat gyorsan végignézni. Ezzel példánkban kiássuk a régi, a csillagos F szót, és újra ez lesz az érvényes.
1.4. Számolni tanulunk - kicsit szokatlan lesz...
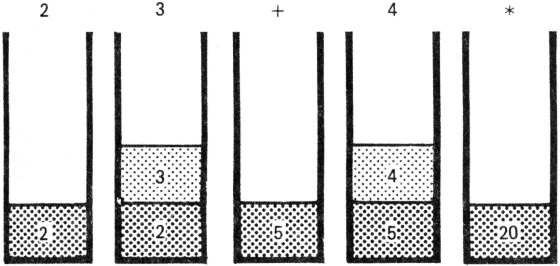
Miből áll a FORTH aritmetika? Természetesen FORTH szavakból. Ezek nevei olyan rövidek, hogy a naivabbak műveleti jelnek is vélhetik. A négy alapművelet: + , - , * , /. Mindegyik a vermen várja a két számot, amelyeken a műveletet végzi (azaz a művelet két operandusát); ezeket le is emeli a veremről és helyükbe a művelet eredménye kerül. Erre az alábbi. ábrán láthatunk példát.
(Az adott lépés után a veremben levő adatokat rajzoltuk meg.) A leírt 2 3 + 4 * sorozat ugyanazt a számítást végzi, mint a (mondjuk) BASIC nyelven írt (2+3)*4.
Az utóbbi, megszokottabb jelölésmódot infixnek nevezzük, szemben a FORTH (többeket visszariasztó) postfix jelölésével. Az elnevezések azt tükrözik, hogy a műveleti jel az infix írásmódban a két operandus között (in) van, a postfixben pedig az operandusok után (post).
A postfix megszokásához mankóul szolgálhat a következő:
Az operandusok sorrendje a postfix írásmódban ugyanaz, mint az infixben, csak a műveleti jel helye változik. |
| infix | postfix |
| 1 + 1 | 1 1 + |
| 2 - 4 | 2 4 - |
| 6 / 3 | 6 3 / |
Ez azt jelenti, hogy pl. kivonásnál a - szó a kivonandót várja a verem tetején, alatta pedig a kisebbítendőt. Ezt a FORTH programoknál így szokás dokumentálni:
( kisebbítendő kivonandó --- különbség )
Zárójelet azért szoktunk írni, mert így az egyes szavak hatása a veremre a FORTH forrásszövegben is feltüntethető.
A ( ugyanis FORTH alapszó. Működése: a záró zárójelig "takarja" a szöveget, amelyet az interpreternek adunk; így a nyitó és záró zárójel közötti részt az interpreter el sem olvassa, nemhogy végrehajtaná. Tessék kipróbálni! A nyitó és záró zárójelnek egy sorban kell lennie. Így lehet FORTH- ban dokumentálni.
A veremhatás jelölésének sémája:
( előtte --- utána )
Ha az elemek sorrendjét nézzük, egyszerűen úgy kell képzelni, mintha a vermet jobbra döntenénk.
A négy alapművelet veremhatása:
+ ( összeadandó1 összeadandó2 --- összeg )
- ( kisebbítendő kivonandó --- különbség )
* ( szorzandó1 szorzandó2 --- szorzat )
/ ( osztandó osztó --- hányados )
Ezzel az alapműveleteket bevezettük. Még annyit: a veremben egész számok vannak, a FORTH aritmetika egészaritmetika. Ennek megfelelően az osztás is egészosztás (tehát a hányados egészrészét kapjuk).
1.5. A verem átrendezése
A FORTH szavak elvárják, hogy a vermen a megfelelő sorrendben kapják a működésükhöz szükséges paramétereket. Ez nem mindig egyszerű. Időnként a paraméterek a veremben rossz sorrendben keletkeznek, lehet köztük felesleges, de az is előfordulhat, hogy valamelyikre még egyszer szükség lenne. Az ilyen gondok megoldására szolgálnak a következő szavak:
| SWAP | ( a b --- b a ) | megcseréli a két legfelső elemet; |
| DUP | ( a --- a a ) | megduplázza a legfelső elemet; |
| OVER | ( a b --- a b a ) | a második elemről készít egy másolatot a verem tetején; |
| ROT | ( a b c --- b c a ) | a harmadik elemet kiszedi alulról, és feldobja a tetőre; |
| DROP | ( a --- ) | eltávolítja a legfelső elemet. |
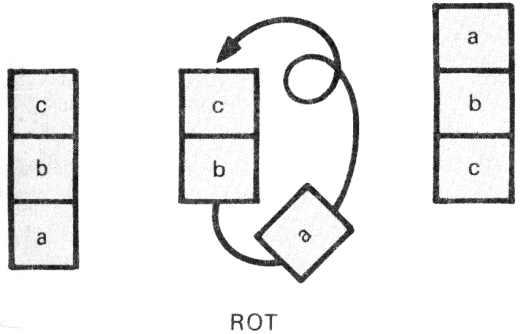
Írjunk például egy olyan szót, amelynek hatása a veremre:
( x y --- z ); ahol z=xy- (x+y).
Nem kezdhetjük a dolgot aritmetikai művelettel, hiszen akkor elveszítenénk az x-et meg az y-t a veremről. Valamilyen módon konzerválnunk kell őket. Jó fogás erre az OVER kétszeri alkalmazása. Az egyes lépések mellett feltüntettük, hogy a lépés után mi lesz a veremben; ez a felírási mód igen hasznos, amíg nem válunk a verem rutinos bűvészévé. (Senkit ne zavarjon, hogy a definíció többsoros! A FORTH ezt minden további nélkül megengedi.)
: XY
OVER
OVER
*
ROT
ROT
+
-
;( x y )
( x y x )
( x y x y )
( x y szorzat )
( x szorzat y )
( szorzat x y )
( szorzat összeg )
( z )
1.6. Hasznos, de nem szabványos szavak
Van néhány veremkezelő FORTH szó, amely nincs benne a FIG alapszókészletben, sok FORTH-ban azonban szerepel. A szavak forrásszövege a 7.3. szakaszban megtalálható, ha valaki használni akarja őket.
| DEPTH | ( --- n ) | (jelentése: mélység) a verem tetejére teszi a verem elemeinek (a DEPTH végrehajtása előtti) számát. |
| .STACK | ( --- ) | a STACK szóval kiírathatjuk a verem tartalmát. A .STACK nem változtatja meg a vermet. |
| PICK | ( n1 --- n2 ) | a verem tetejére másolja a verem n1-edik elemét. A 2 PICK ugyanúgy működik, mint az OVER, az 1 PICK úgy, mint a DUP. |
| ROLL | ( n --- ) | kiszedi a verem n-edik elemét és a verem tetejére teszi. A 3 ROLL a ROT, a 2 ROLL a SWAP szóval egyenlő hatású. A veremhatás szokásos jelölésével a ROLL működését csak pontatlanul írhatjuk le. |
1.7. Még egy szó a szöveg kiírásáról
A ." szó kiírja a képernyőre az utána megadott szöveget, egészen a legközelebbi jelig. A záró idézőjelnek a ." -el egy sorban kell lennie! Írjunk például egy olyan szót, amely a vermen talált két számot is, az összegüket is kiírja a képernyőre, szövegesen tisztázva, hogy melyik szám micsoda. A szó veremhatása: ( x y --- ).
: LOCSI-FECSI
OVER OVER
CR
." ez volt felul: " . CR
." ez volt alul: " . CR
+
. " osszeg: " . CR
;( x y --- )
( x y x y )
( x y x )
( x y )
( összeg )
Nem szabad megfeledkezni róla, hogy a ." után szóközt kell tennünk! Így jelezzük, hogy a ." külön szó. A szóköz nem számít bele a kiíratandó szövegbe.
Miról volt szó?
Az 1. fejezet összefoglalása
Az interpreterről:
Kérdezz-felelek alapon működik, egy sort (az ENTER-ig) vesz egy "kérdésnek".
A sort "szavanként" értelmezi; sor közben a szóköz karakterről veszi észre, hogy egy szónak vége van.
Egy ilyen "formális" szót úgy dolgoz fel. hogy
A szótárról:
Szavak vannak benne "mutatókkal" egymáshoz láncolva; a lánc a legutoljára definiált szónál kezdődik és a FORTH alapszókészlet van a végére fűzve.
Többször is szerepelhet benne egy név; a névvel történő hivatkozással a "legfelső", legutoljára definiált szót nevezzük meg az ilyen nevűek közül.
Tetszésünk szerint bővíthetjük (erre eddig még csak a kettőspontos definíciót tanultuk), de törölni belőle csak úgy lehet, hogy a törlendő szóval együtt az ösz- szes utána definiáltat is töröljük (a láncnak nem szedhetjük ki egyetlen szemét, az egész felső végét le kell kapcsolnunk).
A veremről:
Számok vannak benne, ezek közül mindig csak azt érjük el, amelyik utoljára került oda.
Két szóról, amely szöveggel dolgozik: a ( és a ."
Mindkettő valamilyen határolójelig veszi a mögötte álló szöveget.
A határolójelnek a szóval egy sorban kell lennie.
Az ember hajlamos megfeledkezni az utánuk járó szóközről, de ne tegye!
A tanult szavak:
| : | ( --- ) | Új szó definiálásának kezdete. |
| ; | ( --- ) | Kettőspontos szódefiníció vége. |
| FORGET | ( --- ) | Így használjuk: FORGET xxx , ahol xxx szótári szó. Ezt a szót az utána definiáltakkal együtt törli a szótárból. FORTH alapszót nem lehet törölni. |
| VLIST | ( --- ) | Kilistázza a képernyőre a szótári szavakat. A listázás bármely billentyű lenyomásával félbeszakítható. |
| ( | ( --- ) | A záró zárójelig tartó karaktersorozatot "lenyeli" az interpreter elől, a két zárójel közötti szövegnek nincs hatása (dokumentációs célokat szolgálhat). A nyitó és záró zárójelnek egy sorban kell lennie. |
| EMIT | ( c --- ) | Kiírja a vermen talált kódnak megfelelő karaktert a képernyőre. |
| SPACE | ( --- ) | Egy szóközt ír a képernyőre. |
| CR | ( --- ) | Egy kocsivissza és egy soremelés karaktert ír a képernyőre. |
| ." | ( --- ) | Kiírja a képernyőre az utána következő szöveget a záró "-ig. A szónak és a záró "-nek egy sorban kell lennie. |
| . | ( n --- ) | Kiírja a verem tetején levő számot és egy szóközt a képernyőre. A veremből kiveszi a számot. |
| + | ( n1 n2 --- n3 ) | A két felső elem összegét adja a vermen. |
| - | ( n1 n2 --- n3 ) | Az n1-n2 különbséget adja. |
| * | ( n1 n2 --- n3 ) | A két felső elem szorzatát adja. |
| / | ( n1 n2 --- n3 ) | Az n1/n2 hányadost adja. |
| DUP | ( n --- n n) | Megduplázza verem legfelső elemét. |
| SWAP | ( n1 n2 --- n2 n1 ) | Megcseréli a két legfelső elemet a veremben. |
| DROP | ( n --- ) | Eltávolítja a veremből a legfelső elemet. |
| OVER | ( n1 n2 --- n1 n2 n1 ) | A második elemről készít egy másolatot a verem tetején. |
| ROT | ( n1 n2 n3 --- n2 n3 n1 ) | A verem harmadik elemét kiszedi alulról, és feldobja a tetejére. |
| COLD | ( --- ) | "Hidegindítás". A szótárat, a vermet és még sok mindent visszaállít a betöltés utáni eredeti állapotba. |
Még nem említett, de az eddigiek alapján könnyen megérhető szavak:
| MIN | ( n1 n2 --- min ) | A két elem közül a kisebbet adja. |
| MAX | ( n1 n2 --- max ) | A két elem közül a nagyobbat adja. |
| MOD | ( n1 n2 --- m ) | Az n1/n2 osztás maradékát adja. |
| /MOD | ( n1 n2 --- m h) | Az n1/n2 osztás maradékát is, hányadosát is megkapjuk. |
| ABS | ( n --- n1 ) | Az n abszolút értékét adja. |
| MINUS | (n --- n1 ) | A kapott szám -1-szeresét adja. |
Példák
1.1 Mit válaszol az interpreter a következő sorokra?
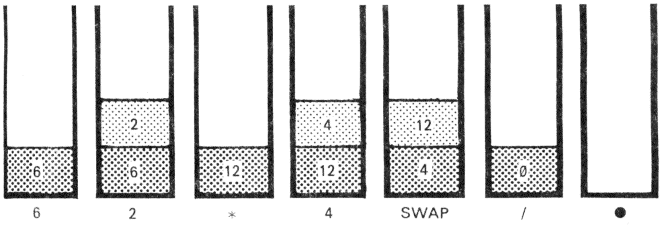
6 2 * 4 / .
A megjelenő szám: 3
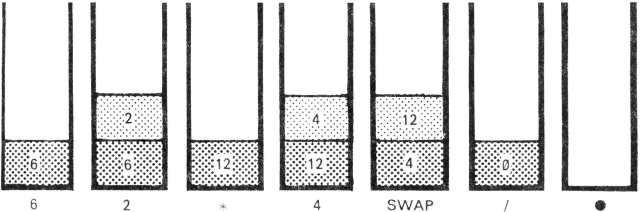
6 2 * 4 SWAP / .
A megjelenő szám: 0
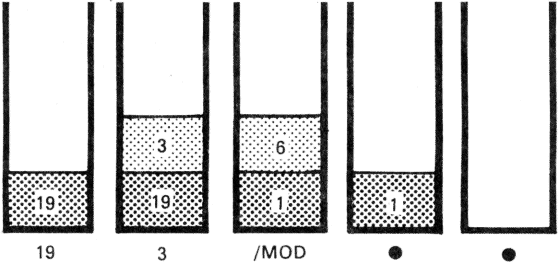
19 3 /MOD . .
A megjelenő számok: 6 1
1.2. Mi a veremhatása a következő szavaknak?
: ALUL-DUP OVER SWAP ;
: ALUL-DUP
OVER
SWAP
;
( x y )
( x y x )
( x x y )
: DUPLA-DUP OVER OVER ;
: DUPLA-DUP
OVER
OVER
;
( x y )
( x y x )
( x Y x y )
: 3CSERE ROT ROT SWAP ;
: 3CSERE
ROT
ROT
SWAP
;
( x y z )
( y z x )
( z x y )
( z y x )
1.3/a. Írjunk olyan szót, amelynek veremhatása: y=5x^2+6x+2
: A DUP DUP * 5 * SWAP 6 * + 2 + ;
1.3/b. Írjunk olyan szót, amelynek veremhatása: y=6x-(x^2-1)
: B DUP DUP * 1 - SWAP 6 * SWAP - ;
1.4. Írjunk egy **5 nevű szót, amely a verem legfelső elemét az ötödik hatványra emeli. Veremhatása tehát: ( x --- x^5 )
egy segéd szó, amely a verem felső elemét négyzetre emeli:
: **2 DUP * ;
ezt felhasználva:
: **5 DUP **2 **2 * ;
2. Összehasonlító és logikai műveletek
Hogyan hasonlítunk össze a FORTH-ban két számot? Természetesen az az első, hogy a veremre tesszük őket (így, mivel az operándusokat adjuk meg először, az összehasonlító műveletek írásmódja is postfix). Utána behívjuk valamelyik összehasonlító műveletet. Ezek a következők: <,>, = . Használatukhoz nem árt észben tartani, hogy
az operandusok sorrendje a postfix írásmódban ugyanaz, mint az infixben, csak a műveleti jel helye változik. |
A
2 3 <
művelet eredménye például az lesz, hogy a < egy igaz értékű jelzőt tesz a veremre.
2.1. A jelző
A jelző, angolul flag (ejtsd: fleg) arra való, hogy valaminek az igaz vagy hamis voltát jelezze. Ennek a két lehetőségnek az ábrázolására általában - így a FORTH-ban is - számokat használunk. FORTH-ban:
megállapodás szerint a jelző hamis, ha értéke 0, és igaz, ha bármi más. |
Az összehasonlító műveletek "jól nevelt" jelzőket szolgáltatnak, amelyek értéke 0 vagy 1.
Írjunk egy szót amely arról tudósít, hogy mit gondol a klaviatúránál ülő felhasználó! A tudósítás a veremre tett jelzővel történik. A felhasználó lelkivilágában pedig a következő kérdéssel mélyedünk el:
IGEN VAGY NEM ?
Most várunk, amíg megnyomja valamelyik billentyűt. A vermen akkor adunk igaz értéket, ha a felhasználó a nagy I betűt nyomta le. Ehhez meg kell tanulnunk azt a szót, amelyik kivárja, hogy valamelyik billentyűt megnyomják a billentyűzeten, s a billentyűnek megfelelő kódot a veremre teszi. Ez a szó a
KEY ( --- kód )
(A KEY (ejtsd: ki) angol szó több dolgot is jelent, itt valószínűleg a "billentyű" fordítás a legtalálóbb.) A KEY után minden megáll, amíg meg nem nyomunk egy billentyűt. A képernyőn nem látjuk, mit nyomtunk meg (nem írja vissza, mint máskor), csak, hogy az interpreter OK-t küld. A karakterkód a veremben van - EMIT-tel kiírathatjuk a karaktert vagy . -tal a kódját.
Kicsit kényelmesebb, ha az ember látja is. hogy mit ír. Íme egy program, amely a KEY-hez hasonlóan bevárja egy billentyű lenyomását és a veremre teszi a megfelelő kódot, sőt még ki is írja a karaktert a képernyőre:
: ECHO ( --- kod )
KEY DUP EMIT ;
Ezek után az igen-nem program (figyelembe véve, hogy az I betű kódja 73) a következő:
: I-V-N
." Igen, vagy Nem? "
ECHO
73 =
;
( --- jelző)
( a verem üres)
( a veremben a karakterkód,)
( majd a kívánt jelző)
2.2. Az eddig látott adattípusok
Két, már ismert szó:
| . | ( szám --- ) | kiírja a vermen talált számot a képernyőre; |
| EMIT | ( kód --- ) | kiírja a vermen megadott karakterkódnak megfelelő karaktert a képernyőre. |
Mindkettő egy elemet használ a veremről. A verem egy eleme egy 16 bites gépi szó. (Gépi szó: 16 jegyű, 2-es számrendszerbeli - azaz bináris - szám, másképpen: egy 16 elemű, 0 és 1 értékeket tartalmazó sorozat.) A . ezen egy 16 bites, előjeles számot feltételez (látni fogjuk, hogyan lehet ennél hosszabb számokkal dolgozni), az EMIT pedig egy karakterkódot, amely egyébként elférne 1 byte-on (8 biten). Az EMIT a 2 byte-ból álló gépi szónak az egyik byte-ját egyszerűen figyelmen kívül hagyja!
Adott esetben például a vermen 42 hever (binárisan; ugyanis a veremben csak gépi ábrázolású számok vannak). Honnan lehet tudni, hogy ez "melyik" 42: előjeles szám, a * karakter kódja, vagy - már tudjuk, ez is lehetséges - egy "igaz" jelző?
A FORTH-ban az adatok típusa csak attól függ, hogy milyen műveletet végzünk rajtuk. |
A 42 tehát karakterkód, ha az EMIT használja, és előjeles szám, ha a . .
A + például előjeles számnak tekinti a verem felső két elemét. Ha valaki mégis a KEY-vel kapott karakterkódot felejti ott, az vessen magára.
A szó veremhatásának leírásakor az elemeket jelölő betűk az elemek típusát is közlik. Az eddig látott típusok:
Így dokumentáljuk az összehasonlító műveleteket:
| < | ( n1 n2 --- f ) | igaz a jelző, ha n1 < n2; |
| > | ( n1 n2 --- f ) | igaz a jelző, ha n1 > n2; |
| = | ( n1 n2 --- f ) | igaz a jelző, ha n1 = n2; |
2.3. Miért kell egy jelzőnek "jól neveltnek" lennie?
Írjunk egy szót, amely egy jelzővel közli, hogy a veremben talált szám 0 és 9 közé esik-e.
A szó neve legyen 1 JEGY, veremhatása pedig: ( n --- f ).
Meg tudjuk már vizsgálni, hogy egy szám kisebb-e 10-nél (egész számokról lévén szó, ez ugyanaz, mintha a "nem nagyobb-e 9-nél" kérdésre válaszolnánk), és azt is, hogy nagyobb-e -1-nél. A két jelzőből egy ún. logikai ÉS művelettel kapjuk meg, hogy a két válasz egyszerre igaz-e.
A logikai ÉS két logikai értékből állít elő egy harmadikat: ha a két érték igaz volt, akkor a művelet eredménye igaz, egyébként hamis.
A jelzők közötti ÉS műveletet az AND FORTH alapszóval lehet megvalósítani. (AND magyarul: ÉS.)
Vigyázat: az AND a logikai "és" műveletet a két operandus bináris alakjának minden egyes bitjével elvégzi! Ha pl. a veremben 2 és 1 volt, azaz binárisan
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0
és
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1,
akkor a logikai ÉS eredménye
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0,
vagyis 0 lesz, mivel az egymásnak megfelelő bitek közül az egyik mindig 0. Holott mi a 2-t is, az 1-et is igaz értéknek tekintjük, így az AND-nek a mi logikánk szerint igaz értéket kellett volna adnia. Erről a kényelmetlenségről (amely más alkalommal kényelem) tudnunk kell, pillanatnyilag azonban fölösleges miatta aggódnunk; az összehasonlító műveletek "jól nevelt", 0 vagy 1 értékű jelzővel kedveskednek, amelyekkel nem állhat elő a fenti félrekapcsolás.
: 1JEGY
DUP -1 >
SWAP 10 <
AND
;
( n --- f )
( n f1 )
( f1 f2 )
A másik fontos művelet a logikai VAGY, amely szintén két logikai értékből ad egy harmadikat. Az eredmény igaz lesz, ha a két logikai érték közül legalább az egyik igaz. Tehát akkor és csak akkor kapunk hamis-at, ha mindkét operaridus hamis volt. Láthatóan ez a VAGY nem felel meg a magyar nyelv VAGY szavának. Magyarul ilyeneket mondunk:
"Vagy láng csap az ódon, vad vármegyeházra
vagy itt ül a lelkünk tovább, leigázva"
és ezt úgy értjük, hogy a két lehetőség kizárja egymást. Az előbbi VAGY-ot megengedő VAGY-nak hívjuk, hogy megkülönböztessük a magyar VAGY-ra jobban hasonlító kizáró VAGY-tól. A kizáró VAGY akkor ad igaz eredményt, ha a kapott logikai értékek közül az egyik igaz, a másik nem. VAGY-nak általában a megengedő VAGY-ot hívjuk, ha a kizáró VAGY-ra gondolunk, végigmondjuk a nevét. Ennek megfelelően a két FORTH szó: OR (VAGY) és XOR (eXclusive OR, Kizáró VAGY). Ezek is bitenként működnek, mint az AND, de az összehasonlító műveletektől kapott "jól nevelt" jelzőknél ez nem jelent különbséget.
Nézzük az 1 JEGY-gyei ellentétesen működő NEM-1JEGY ( n --- f ) szót, amely akkor ad igaz jelzőt, ha a kapott szám nem esik 0 és 9 közé (azaz kisebb 0-nál vagy nagyobb 9-nél):
: NEM-1JEGY
DUP 0 <
SWAP 9 >
OR
;
Az 1JEGY-gyel ellentétesen működő NEM-1JEGY-et persze könnyebb úgy megírni, hogy felhasználjuk az 1JEGY-et. Egy olyan művelet kell hozzá (negálás, komplementálás), amely megváltoztatja a vermen levő jelző jelentését: az igaz jelzőből 0-t, a hamis, azaz 0 értékű jelzőből 1-et csinál. Ez a szó nem szerepel a szabvány FIG-FORTH 1.1. alapszavak között, de sok FORTH-ban megvan, és megírni sem nehéz:
: NOT 0 = ;
Így a
: NEM-1JEGY 1JEGY NOT ;
működése ugyanaz lesz, mint az előbb definiált másik NEM-1EGY-é.
2.4. Gyorsműveletek
A legtöbb számítógépnek gyorsan működő gépi utasítása van arra, hogy valamit 1-gyel növeljen vagy csökkentsen, 2-vel szorozzon vagy osszon, megvizsgálja az előjelét. Ehhez képest az a sorozat, hogy 1 + (tegyél a veremre 1-et, hívd a + szót) lassú és nehézkes. Az ún. "gyorsműveletek" levágják a felesleges kanyarokat, és körülményeskedés nélkül elindítják a megfelelő gépi utasításokat. A gyorsműveletek:
| 1+ | ( n --- n1 ) | eggyel növeli n értékét; |
| 1- | ( n --- n1 ) | eggyel csökkenti n értékét; |
| 2+ | ( n --- n1 ) | n értékének a kétszeresét adja; |
| 2/ | ( n --- n1 ) | n értékének a felét adja; |
| 0= | ( n --- f ) | f akkor igaz, ha n = 0; |
| 0< | ( n --- f ) | f akkor igaz, ha n < 0. |
Láthatóan a gyorsműveleteket végző szavak hasonlóan néznek ki, mint az ugyanúgy működő lépésenkénti parancsok, csak egy szóba írjuk az operandust a műveleti jellel; az 1 + szó ugyanazt a műveletet végzi, mint az 1 + sorozat, csak gyorsabban.
A NOT művelet gyorsabb változata:
: NOT 0= ;
2.5. Hogyan tároljuk programjainkat?
Eddigi próbálkozásainkban az a bosszantó, hogy a programok szövegei nem maradnak meg, nem lehet őket kijavítva vagy változatlanul újra felhasználni.
Megtehetjük, hogy a programokat nem közvetlenül adjuk át az interpreternek, hanem valamilyen adathordozóra, az ún. screen-ekbe írjuk őket; itt bármikor javíthatók vagy elolvastathatók az interpreterrel. A screen (ejtsd: szkrín) szó magyarul képernyőt jelent, amit mi rövidítve kernyőnek fogunk nevezni.
A kernyő a szöveges információ tárolásának egysége. Egy kernyőben annyi szövegnek van hely, amennyit egyszerre kezelhetünk a képernyőn; ez 16 sor, egy sorban 64 karakterrel (vagyis 1 kernyő pontosan 1 kbyte információt tárolhat). A kernyőket minden FORTH a maga módján tárolja. A szabvány FORTH egy lemezt egyszerűen egy szektorhalmaznak tekint, amelyet feloszt magának kernyőkre (ez főleg a régebbi implementációkra igaz, melyek eleve kicsi lemezkapacitást feltételeznek). A fig-Forth ún. kernyőfile-okat használ, ezzel lehetővé téve, hogy ugyanazon a lemezen más file-okat is tarthassunk (akár több kernyőfile-t).
Amikor eddig elindítottuk a FORTH-interpretert, a "No file" üzenet arra figyelmeztetett, hogy nem választottunk ki kernyőfile-t, ilyenkor az interpretert csak "kérdezz-felelek" üzemmódban használhatjuk. Ha kernyőfile-t is be akarunk tölteni, ezt a Forth indításakor tehetjük meg, ha paraméterként megadjuk a kerőnyfile nevét is. Pl.:
Z80FORTH SCREENS.FRT
Ha betöltöttük a kívánt kernyőfile-t, hozzáláthatunk programunk megszerkesztéséhez, amihez természetesen valamiféle szövegszerkesztőre lesz szükségünk. A számítástechnika hőskorát idézi az a tény, hogy a fig-FORTH interpreter nem tartalmaz szövegszerkesztőt (editort)! A fig-FORTH-hoz mellékelt William F. Ragsdale alkotta editor maga is FORTH-ban íródott, amit használat előtt ugyanúgy be kell töltenünk, mint bármelyik más futtatni kívánt programunkat. Teljes képernyős szerkesztésről ne is álmodjunk, a parancssoros editort kezdetben szokni kell, később egész jól használhatóvá válik. Használatát a függelékben részletesen ismertetjük.
Ha megszerkesztettünk egy kernyőt, akkor a
LOAD ( n --- )
szóval átadhatjuk az interpreternek. A vermen a kernyő számát kell megadni. A LOAD hatására pontosan ugyanaz történik, mintha begépelnénk a megadott számú kernyőn található szöveget. Ha, mint többnyire, a kernyő definíciókat tartalmaz, akkor a betöltés, vagyis a LOAD hatására megjelennek a szótárban a definiált szavak.
Ha több egymás utáni kernyőt akarunk betölteni (mert például egy kernyőbe nem fér el a programunk), akkor a
-->
szót írjuk a kernyők végére. Betöltéskor ennek hatására az adott kernyő interpretálása abbamarad, és a következő kezd el betöltődni. A
;S
szó hatására a kernyő interpretálása megszakad, az interpreter ott folytatja, ahol a LOAD volt.
Az interpreternek szinte mindegy, hogy az adott pillanatban billentyűzetről vagy kernyőről kapja-e a vezérlést. Azt a karakterfolyamot, amelyet az interpreter értelmez, az angol nyelvű irodalom input stream-nek nevezi, ezt itt befolyamnak fordítjuk.
Egy kernyő szövegét a
LIST ( n --- )
szóval írathatjuk ki a képernyőre.
Megállapodás szerint minden képernyő legfelső sora tartalmaz valamilyen utalást a kernyő tartalmára. Ezt használja fel az
INDEX ( tól ig --- )
szó, amely nem szabvány ugyan, de sok FORTH alapszókészlet (így a fig-FORTH is) tartalmazza, és a 13. fejezet elolvasása után bárki meg is írhatja (ld. a 13/2. feladatot). Az INDEX kilistázza a megadott két szám közötti számú kernyők legfelső sorát és ezzel mintegy tartalomjegyzéket ad a kernyőinkről.
Elöljáróban még annyit kell megemlítenünk, hogy a
FLUSH ( --- )
szóval írhatjuk ki lemezre a módosított blokkokat.
Miról volt szó?
A 2. fejezet összefoglalása
Az összehasonlító műveletekről:
A vermen várják az operandusaikat; ezek sorrendje a megszokott, csak a <, >, = "műveleti jelek" helye változik (postfix jelölésmód).
Jelzőket tesznek a veremre.
A jelzőkről:
Igaz-at vagy hamis-at jelölnek: a 0 érték hamis-at jelent, a többi igaz-at. Lehetnek "jól neveltek" - ez azt jelenti, hogy az igaz jelző értéke mindig 1. Az összehasonlító műveletek ilyeneket szolgáltatnak.
A típusokról:
A FORTH nem tartja számon, hogy a verem melyik adata milyen típusú - ez a programozó dolga.
Az eddigi típusok és jelölésük:
ezek mind egy elemet foglalnak el a vermen (azaz egy 16 bites szót).
A logikai műveletekről:
Az ÉS akkor igaz, ha mindkét operandusa igaz.
A VAGY akkor hamis, ha mindkét operandusa hamis.
A kizáró VAGY akkor igaz, ha a két operandus közül az egyik igaz, a másik hamis.
A negálás: igaz-ból hamis-at csinál és fordítva.
És azok FORTH megvalósításáról:
Az AND (ÉS) OR (VAGY) és XOR (kizáró VAGY) a megfelelő logikai műveletet bitenként végzi. így, ha nem "jól nevelt" jelzőkre alkalmazzuk őket, tévútra vezethetnek.
A negálást a 0= szóval valósíthatjuk meg.
A gyorsműveletekről:
Nem jelentenek újfajta műveletet, csak a régiek néhány speciális esetének idő- és tártakarékosabb változatát.
A kernyőkről:
Szövegek tárolása lemezen vagy kazettán.
A kernyőket bármikor "betölthetjük" (LOAD), ekkor ugyanaz történik, mintha begépelnénk a kernyőn levő szöveget. A kernyők írására és karbantartására az editor programok szolgálnak.
A tanult szavak:
| < | ( n1 n2 --- f ) | f akkor igaz, ha n1 < n2. |
| > | ( n1 n2 --- f ) | f akkor igaz, ha n1 > n2. |
| = | ( n1 n2 --- f ) | f akkor igaz, ha n1 = n2. |
| AND | ( n1 n2 --- f ) | Bitenkénti logikai ÉS. |
| OR | ( n1 n2 --- f ) | Bitenkénti logikai VAGY. |
| XOR | ( n1 n2 --- f ) | Bitenkénti logikai kizáró VAGY. |
| 1+ | ( n --- n1 ) | n értékét 1-gyel növeli. |
| 1- | ( n --- n1 ) | n értékét 1-gyel csökkenti. |
| 2* | ( n --- n1 ) | n értékét 2-vel szorozza. |
| 2/ | ( n --- n1 ) | n értékét 2-vel osztja. |
| 0= | ( n --- n1 ) | f igaz, ha n=0. |
| 0< | ( n --- n1 ) | f igaz, ha n<0. |
| KEY | ( --- c ) | Kivárja, míg a billentyűzeten lenyomnak egy billentyűt, és a billentyűnek megfelelő karakterkódot adja a vermen. |
| LOAD | ( n --- ) | Betölti, "interpretálja" a megadott számú kernyőt. |
| --> | ( --- ) | Az adott kernyő interpretálásáról rátér a következőére. |
| LIST | ( n --- ) | Kernyő listázása a képernyőre. |
| ;S | ( --- ) | A kernyő interpretálásának befejezése. |
Példák
2.1. Írjunk olyan 3:0? ( n --- f ) szót, amely akkor ad igaz jelzőt, ha n osztható 3-mal!
: 3:0?
3 MOD
0 =
;
( n --- f )
( a veremben az osztás maradéka )
( akkor "igaz" a válasz, ha ez 0 )
2.2. Van egy dobozunk, amelynek hossza 100 cm, szélessége 65 cm, magassága 10 cm. Írjunk egy BELE? nevű szót, amely a vermen adott jelzővel megmondja, hogy a megadott hosszúságú, szélességű és magasságú akármicsoda belefér-e a dobozba? A szó veremhatása: ( hossz szélesség magasság --- f ). f akkor igaz, ha a hossz < 100, szélesség < 65 és a magasság < 10.
: BELE?
10 <
ROT
100 <
AND
SWAP 65
AND
;
2.3. Írjunk olyan 7-E ( n --- f ) szót, amely akkor ad igaz-at a vermen, ha az n szám tízes számrendszerbeli alakjában az utolsó jegy 7!
: 7-E ( n --- f )
ABS ( abszolút érték, ha a szám negatív lenne )
10 MOD ( ez az utolsó számjegy )
7 =
;
2.4. Írjuk meg az L-AND és L-OR ( f1 f2 --- f ) szavakat, amelyek nem bitenként végzik el a megfelelő logikai műveleteket, hanem a két jelző között. Tehát pl. 1 2 L-AND ne 0 értéket adjon, hanem (két igaz jelzőről lévén szó) 1-et. Mindkét szó "jól nevelt" jelzőt ajon.
Egy szó, amellyel "jól neveltté" tehetünk egy jelzőt:
: 1EL 0= 0= ;
Nekünk mindkét szóhoz a verem felső 2 elemét kell "jól neveltté" tenni:
: L-AND 1EL SWAP 1EL AND ;
: L-OR 1EL SWAP 1EL OR ;
3. A feltételes utasítás
Tudjuk már, hogyan kaphatunk jelzőt egy feltétel igaz vagy hamis voltáról. Most megtanuljuk, hogyan lehet a jelzőket használni.
3.1. Az IF ... ENDIF
Az IF ... ENDIF szerkezet működése: az IF megeszi a verem tetején levő jelzőt. Ha a jelző igaz, az IF és ENDIF közötti programrész végrehajtódik, ha nem, nem. Mielőtt példát mutatnánk rá, gyorsan szögezzük le:
Valamennyi szerkezet, amely vezérlésátadást tartalmaz (tehát a feltételes és ciklusképző utasítások), csakis definícióban használható! |
Írjunk egy olyan szót, amely ha 0 és 9 közötti számot talál a vermen, kiírja a képernyőre: EGYJEGYU. Természetesen felhasználjuk az előző fejezetben definiált 1JEGY ( n --- f ) szavunkat. Az új szó veremhatása: ( n --- )
: EGYJ 1JEGY IF ." egyjegyu" ENDIF CR ;
Az ENDIF-nek gyakran használt szinonimája a THEN. Más magas szintű programnyelvek a THEN-t teljesen másképp használják; mielőtt hagynánk magunkat megkeverni, legjobb, ha az eszünkbe véssük: ez más, a THEN itt ENDIF-et jelent!
Az IF-et és ENDIF-et nem használhatjuk egymás nélkül.
3.2. Az ELSE
Ha nemcsak egy adott feltétel teljesülésekor vannak teendőink, hanem az ellenkező esetben is, akkor ilyesféleképpen építjük a programunkat:
IF (itt van, amit akkor kell tenni, ha a jelző igaz);
ELSE (itt van, amit akkor kell tenni, ha nem)
ENDIF
Például:
: EGYJ
1JEGY IF ." egyjegyu"
ELSE ." nem egyjegyu"
ENDIF CR
;
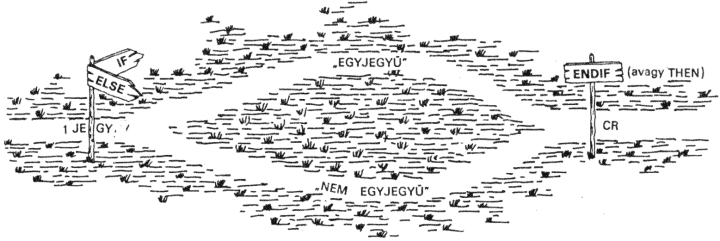
Olykor az ELSE ágon nincs más feladat, mint a jelzőről feleslegesen készült másolat eltávolítása. Hogy csak ennyiért ne kelljen ELSE ágat írni, van olyan FORTH alapszó, amely csak akkor duplázza a verem felső elemét, ha az nem 0.
-DUP ( n --- n n , ha n<>0) ( n --- n m ha n=0 )
3.3. Egymásba skatulyázva
Az IF vagy az ELSE ágon újabb, feltételtől függő teendőink lehetnek.
Például írjunk egy EVES-VAGYOK ( n --- ) programot, amely
választ ír ki. Például a 3 EVES-VAGYOK eredménye: GYEREK.
: EVES-VAGYOK
DUP
10 <
IF
." gyerek"
DROP
ELSE
20 <
IF ." kamasz"
ELSE ." felnott"
ENDIF
ENDIF
CR
;
( n --- )
( n n )
( n f1 )
( ha n<10)
( a munkát elvégeztük )
( de a vermen szemét maradt )
( ha n=>10 )
( f2 )
( ha 20-nál kisebb )
( ha nem )
Figyeljünk rá, hogy a "belső" IF-es szerkezet mindig teljes egészében a "külső"-nek valamelyik ágán van! Ez kulcs ahhoz, hogy egy FORTH szövegben melyik IF, ELSE és ENDIF tartozik össze. Ha látunk egy ilyesféle programrészletet:
IF A IF B ELSE C IF D ENDIF ENDIF ELSE E ENDIF
akkor ahhoz, hogy kiigazodjunk rajta, keressük meg a legbelső IF-et, és máris tudhatjuk, hogy az ENDIF-ek közül az utána leghamarabb jövő az övé! (Hasonló a helyzet a második legbelső IF-fel.) Láthatóan a második IF-nek ELSE ága is van:
és az egész második IF az elsőnek az igen ágán van. Legjobb az ilyen sorozatokat egy kicsit tagoltabban írni; valamivel áttekinthetőbb ugyanez a következőképp felírva:
IF
A
IF B
ELSE
C
IF D
ENDIF
ENDIF
ELSE E
ENDIF
vagyis úgy, hogy az összetartozó IF, ELSE és ENDIF egymás alá kerül, az adott ágon végrehajtandók pedig egy kicsit beljebb.
Miról volt szó?
A 3. fejezet összefoglalása
Az IF ... ELSE ... ENDIF szerkezetről:
Csak definícióban használható.
Az IF az egyetlen a három szó közül, amely változtat a vermen (elhasznál egy jelzőt).
Az ELSE elmaradhat.
Ha az IF igaz jelzőt talált a vermen, akkor az IF és az ELSE (ELSE hiányában az IF és az ENDIF) közötti programrész hajtódik végre, ha hamis-at, akkor az ELSE és ENDIF közötti (vagy ELSE hiányában semmi). A végrehajtás mindkét esetben az ENDIF után folytatódik.
Az ENDIF-nek a THEN szinonimája.
Ezek a szerkezetek bármilyen mélységben egymásba ágyazhatok.
Még egy veremkezelő szóról, a -DUP-ról:
Ha a vermen 0 van, nem csinál semmit, egyébként pedig ugyanazt, amit a DUP.
Példák
3.1. Írjunk egy SN ( n1 --- n2 ) szót, amely -1-et ad a vermen, ha n1 negatív, +1-et, ha pozitív és nullát, ha nulla!
: SN
DUP
IF
DUP ABS /
ENDIF
;
( n1 --- n2 )
( n1 n1 )
( ha n1<>0 )
( elosztjuk a számot a saját absz. értékével )
( ha n1 0 volt, akkor éppen a 0 van a vermen )
3.2. Írjunk egy SZOVEGEL ( n --- ) szót, amely a következő üzenetek valamelyikét írja ki n értékétől függően: NULLA, EGY, MINUSZ EGY, KETTO, MÍNUSZ KETTO, EGYEB.
: SZOVEGEL
DUP
IF
DUP
ABS 2 >
IF ." egyeb" DROP
ELSE
DUP
0< IF ." minusz " ENDIF
ABS
1 = IF ." egy"
ELSE ." ketto"
ENDIF
ENDIF
ELSE ." nulla" DROP
ENDIF
SPACE
;
3.3. Írjunk egy ALPHA ( --- ) nevű szót, amely egy karaktert vár a billentyűzetről, és
A számok kódjai 48 és 57 a nagybetűké 65 és 90 közé esnek.
Kétszer kell megvizsgálnunk, hogy a karakterünk valami és másvalami közé esik-e. Márpedig komoly FORTH programozó nem ír le kétszer semmit, inkább szót ír rá.
: ELEME
ROT SWAP OVER
< ROT ROT
>
OR 0=
;Így már könnyű (felhasználjuk a korábban készített ECHO szót is):
: ALPHA
ECHO CR
DUP 48 57 ELEME
IF ." szam" DROP
ELSE 65 90 ELEME
IF ." nagybetu"
ENDIF
ENDIF CR
;
3.4. Írjunk szót, amely eldönti a megadott évről, hogy az szökőév-e? Szökőévek a következők: minden néggyel osztható év, kivéve a százzal is oszthatókat. Szökőévek viszont a 400-zal osztható évek. Vagyis a századfordulók évei közül csak azok szökőévek, amelyek 400-zal is oszthatók. Az egyszerűbb megoldáshoz felhasználjuk az EXIT szót, amit az 5.1. fejezetben fogunk megismerni.
: LEAP-YEAR? ( ev --- f ) ( Szokoev? )
DUP 400 MOD 0= IF DROP 1 EXIT ENDIF
DUP 100 MOD 0= IF DROP 0 EXIT ENDIF
4 MOD 0=
;
Próbáljuk meg értelmezni a következő, tömörebb megoldást:
: LEAP-YEAR? ( ev --- f ) ( Szokoev? )
DUP 4 MOD 0=
OVER 16 MOD 0=
ROT 25 MOD 0=
NOT OR AND
;
3.5. Az eddig tanultakat felhasználva már ki tudjuk számolni Christian Zeller algoritmusával, hogy a megadott dátum a hét hányadik napja.
: WEEKDAY ( nap honap ev --- hetnapja)
( 1 hetfo, 2 kedd, ... , 7 vasarnap )
OVER 3 < IF
1- SWAP 12 + SWAP
ENDIF
100 /MOD
DUP 4 / SWAP 2* -
SWAP DUP 4 / + +
SWAP 1+ 13 5 */ + +
2- 7 MOD 1+
;
A WEEKDAY szót felhasználva bármelyik napról megmondhatjuk, hogy a hét hányadik napjára esett:
24 12 2000 WEEKDAY .
4.1. A visszatérési verem
A FORTH interpreter két vermet használ. Az egyiket már ismerjük: ez a számítási verem vagy adatverem, erre gondolunk, amikor egyszerűen csak veremről beszélünk. A másikat főleg maga az interpreter használja, legtöbbször arra, hogy ott jegyezze meg: egy szó lefuttatása (elugrás a megfelelő címre, az ott talált kód végrehajtása) után hova kell visszatérnie. Ezért visszatérési veremnek, röviden viremnek hívják.
A virem programjainkban a verem útban lévő elemeinek átmeneti tárolására használható, ha szem előtt tartjuk, hogy
a virem elemeit minden szónak (amely a virmet nem szándékosan és ravaszul használja a vezérlés módosítására) ugyanúgy kell hagynia, ahogy találta; a virem állapota csak egy-egy szón belül változhat. |
A virmet kezelő szavak (itt is, mint mindenütt, a számítási veremre vonatkozó veremhatást dokumentáljuk):
| >R | ( n --- ) | a verem legfelső elemét áthelyezi a viremre. |
| R> | ( --- n ) | a virem legfelső elemét áthelyezi a veremre. |
| R | ( --- n ) | a virem legfelső elemét átmásolja a verembe; a virem változatlanul marad. |
Egy feladat, amelyhez jól jön a virem: írassuk ki a képernyőre a verem legfelső 4 eleme közül a legnagyobbat! A verem végső soron maradjon változatlan.
: .MAX
DUP >R
OVER MAX
SWAP >R
>R OVER R>
MAX
OVER MAX
. R> R>
;
( n1 n2 n3 n4 --- n1 n2 n3 n4 )
( a viremen: n4 )
( m1 m2 m3 max3,4 )
( a viremen: n4 n3 )
( n1 n2 n1 max3,4 )
( n1 n2 max1,3,4 )
( n1 n2 max )
( n1 n2 n3 n4 )
Gyakori feladat, hogy egy értékről meg kell határozni, hogy a megadott értéktartományba esik-e. Írjunk erre egy szót:
: BETWEEN
SWAP
>R
OVER <
SWAP
R>
<
OR
0=
;
( n alsóh felsőh - jelző )
( n fh ah )
( n fh )
( n fh<n )
( fh<n n )
( fh<n n ah)
( fh<n n<ah )
( fh<n VAGY n<ah )
( jelző )
4.2. Lépegetés egyesével
A DO ... LOOP egy újabb szerkezet, amelyet csak szódefinícióbán használhatunk. Ciklusszervezésre való; arra, hogy a DO és LOOP közötti programrészt (a ciklusmagot) ismételtessük vele, miközben egy kitüntetett változó, az úgynevezett ciklusváltozó értéke folyamatosan nő vagy csökken. Szintaktikája a következő:
indexhatár kezdőérték DO szavak LOOP
Ebben az esetben a ciklusváltozó a ciklus magjának minden egyes végrehajtása után eggyel növekszik. A ciklusváltozó létrehozásáról a FORTH gondoskodik, azt kijelölnünk nem szükséges és nem is lehetséges. Az "kezdőérték" a ciklusváltozó kezdőértéke, az "indexatár" az az érték, amit ciklusváltozó már nem vesz fel. A kilépési feltételt a LOOP szó ellenőrzi. Ebből következik, hogy a ciklus magja legalább egyszer mindig lefut. Például írjuk le 10-szer: ORA ALATT NEM ENEKELEK.
: HAZI-FEL 10 0 DO CR ." ora alatt nem enekelek " LOOP ;
A DO ... LOOP tehát ún. indexes ciklus. Ez azt jelenti, hogy van valahol egy ciklusindex - röviden cindex - vagy ciklusszámláló, amely számolja, hogy a ciklusmag hányszor hajtódik végre. A cindex kezdőértékét és az indexhatárnak nevezett végértéket a DO-nak adjuk meg. A DO veremhatása: ( indexhatár kezdőérték --- ). A DO ezt a két értéket a viremre teszi. A ciklusmag futása alatt a virmen legfelül a cindex pillanatnyi értéke van, alatta pedig a ciklushatár. Így, ha a ciklusmagban fel akarjuk használni a cindexet, egyszerűen elővehetjük a viremről:
: ABC
CR
." A nagybetuk ASCII kodja:"
91 65
DO CR
R
DUP EMIT
SPACE
.
LOOP CR
;
( --- )
( ciklushatár, kezdőérték )
( ciklus )
( veremre tettük a cindex )
( pillanatnyi értékét )
( kiírjuk a karaktert )
( utána egy szóközt )
( majd magát a kódot )
( ciklus vége )
A ciklusmag első futásakor a cindex értéke a megadott kezdőérték (példánkban 65, az A betű kódja). A LOOP mindig eggyel növeli a cindexet és megnézi, nem érte-e el a ciklushatárt. Ha elérte, a ciklus befejeződik (a viremről eltakarítja a két felső értéket). így a ciklusmag akkor fut utoljára, mikor a cindex értéke eggyel kisebb az indexhatárnál. Az ABC utoljára a Z betűt írja ki, amelynek kódja 90.
4.3. IF-ekkel tarkítva
Az ABC kódtáblázata szépen ráférne a képernyőre, ha egy sorba nemcsak egy kódot írnánk, hanem - mondjuk - 10-et. Hogyan lehetne elérni, hogy csak akkor hajtódjék végre a ciklusmagban a CR, ha már kiírtunk 10 elemet? Azt fogjuk vizsgálni, hogy a cindex 10-zel osztva 5 maradékot ad-e. Ez legelőször lesz igaz (ha a kezdőérték 65), majd utána minden tízedik körnél.
: ABC
CR ." A nagybetuk ASCII kodja:"
91 65 DO
R 10 MOD 5 =
IF CR ENDIF
R DUP EMIT SPACE . 2 SPACES
LOOP
CR
;
Tudjuk, hogy a FORTH alapszavak egy része FORTH-ban íródott, még "alapabb" szavak felhasználásával. Ilyen a SPACES ( n --- ) is, amely a vermen adott számú szóközt ír a képernyőre. A SPACES lényegében egy DO ... LOOP-ba tett SPACE.
: SPACES
0 MAX
-DUP
IF
0 DO SPACE LOOP
ENDIF
;
( n --- )
( hogy a kezdőérték ne lehessen )
( nagyobb a ciklushatárnál )
( nem 0-szor kell végrehajtani? )
( ha n nem 0 )
A végrehajtás előtt azért kell megvizsgálni, nem-e nulla van a vermen, mert a DO . LOOP működéséből következik, hogy
A DO ... LOOP ciklusmagja legalább egyszer mindig végrehajtódik, még mielőtt a LOOP az első vizsgálatot elvégezné. |
4.4. Ciklusok egymás belsejében
Írjunk szorzótáblát! A táblának 10 sora és 10 oszlopa lesz. A 3. sor 4. helyére például a 3*4 szorzás eredményét írjuk.
A . nem alkalmas a táblázat írására, mert különböző hosszan írja ki az egy- és kétjegyű számokat. A
. R ( n m --- )
szó az n számot egy m szélességű mezőben jobbra igazítva írja ki (annyi szóközt ír elé, hogy a kiírt karakterek száma éppen m legyen). Táblánk elemei maximum 3 jegyűek, így ha 4 . R-rel írjuk ki őket, mindegyik elé kerül két szóköz (kivéve a 100-at), nem fognak "összeragadni".
1. változat: A táblázat n-edik sora úgy áll elő, hogy az 1, 2, . . . , 10 számokat végigszorozzuk n-nel és kiírjuk a szorzatokat:
: 1SOR
CR 11 1 DO
R
OVER *
4 .R
LOOP
DROP
;
( n --- )
( n )
( n cindex )
( a kiírandó szorzat )
( kiírás )
( nem hagyunk szemetet )
Maga a táblázat csak annyi, hogy az 1SOR-t ismételgetjük az 1, ... 10 számokkal:
: TABLA
11 1 DO R 1SOR LOOP CR ;
2. változat: Oldjuk meg ugyanezt egy szóban, egymásba ágyazott DO ... LOOP ciklusokkal! (A ciklushatárt a példában chat-tal a külsőt k-val, a belsőt pedig b-vel jelöljük.)
: TABLA
11 1 DO CR
11 1 DO
R> R> R
ROT ROT
>R >R
R * 4 .R
LOOP
LOOP CR
;
( a virmen: chat-k cindex-k )
( előássuk cindex-k-t a viremről )
( a vermen: cindex-b chat-b cindex-b )
( a vermen: cindex-k cindex-b chat-b )
( visszaállítjuk a virmet )
( kiírjuk a szorzatot )
3. változat: Ugyanez a megoldás, úgy hogy még időben vesszük elő a külső cindexet:
: TABLA
11 1 DO
CR R
11 1 DO
R
OVER *
4 .R
LOOP
DROP
LOOP CR
;
( itt még csak a külső ciklus )
( dolgai vannak a virmen )
( a vermen cindex-k )
( cindex-k cindex-b )
( itt szokták a kezdők elrontani, )
( hogy összeszorozzák őket, s mire)
( a ciklusmag másodszor futna )
( elvesztik a cindex-k-t )
( cindex-k nem kell már )
Sok FORTH-ban a cindexet az I, a külső cindexet (a verem harmadik elemét) a J, a még külsőbb cindexet (a verem ötödik elemét) a K szóval lehet előszedni. Mindhárom szó veremhatása ( --- n ). Ha az I és a J megvan a FORTH-unkban, akkor könnyebben is megírhatjuk a TABLA programot. A fig-Forth szótárában ugyan csak az I szó van meg, a párja a J szó hiányzik, de ez csak átmeneti állapot könyvünk következő pontjáig, így nézzük meg ezt a megoldást is!
4. változat: az I és J szavak felhasználásával:
: TABLA
11 1 DO
CR 11 1 DO
I J *
4 .R
LOOP
LOOP CR
;
4.5. Amit könnyű elrontani
Nézzük meg, hogyan működik az I szó, és írjuk meg a fig-Forth szótárából hiányzó J szót is! Az I-vel látszólag egyszerű dolgunk van, hiszen nem tesz egyebet, mint az R szó: a veremre másolja a virem legfelső elemét. És mégis, a kézenfekvő
: I R ;
definíció nem jó erre. Mikor ugyanis az I szóba belép az interpreter, akkor a viremre teszi azt a címet, ahova I-ből majd visszatér. Az I előbbi definíciója mellett ezt a címet kapnánk a vermen a cindex helyett. A jó megoldás a virem második elemét teszi a veremre:
: I R> R SWAP >R ;
Hasonlóan a J szóban a viremnek nem a harmadik, hanem a negyedik elemét kell előhalásznunk:
: J
R> R> R> R
SWAP >R
SWAP >R
SWAP >R
;( --- n )
( verem: vc n2 n1 n )
( verem: vc n2 n )
( verem: vc n )
( verem: n )
( virem: n )
( virem: n n1 )
( virem: n n1 n2 )
( virem: n n1 n2 vc )
Aki kísértésbe esik, hogy ne írja le háromszor a SWAP R> sorozatot, hanem szót vagy ciklust írjon rá, ám próbálja meg - csak vigyázzon, mert sem az új szó hívása, sem a ciklus indítása nem múlik el nyomtalanul a virem felett!
4.6. Kiszállás a ciklusból
Egy DO ... LOOP ciklust bármikor félbeszakíthatunk úgy, hogy a virmen található cindexet és ciklushatárt "összeigazítjuk". Éppen ezt teszi a LEAVE szó. A LEAVE hatására a legközelebbi LOOP úgy fogja találni, hogy a ciklust be kell fejeznie.
Például írjunk egy BETU ( --- n ) szót, amely egészen az ENTER-ig karaktereket vár a billentyűzetről (az ENTER kódja 13), de legfeljebb 20-at. A BETU a vermen visszaadja a kapott karakterek számát, a szóközöket nem számítva. A karakterek bevárását és hasonlítgatását egy DO ... LOOP ciklusba tesszük. A ciklus futása alatt mindvégig ott lesz a vermen egy számláló, amelyhez 1-et adunk minden "valódi" karakternél.
: BETU
0
20 0 DO
KEY DUP EMIT
DUP 13 =
IF LEAVE
DROP
ELSE
32 -
IF 1+
ENDIF
ENDIF
LOOP
;( --- n )
( ez lesz a számláló )
( számláló kód )
( ha ENTER volt, a legközelebbi )
( LOOP-nál kiszállunk )
( szóköz volt? )
( ha nem, növeljük a számlálót )
4.7. Másféle lépegetés
Agatha Christie egy regényének rövid tartalmi kivonata:
10 kicsi indián
9 kicsi indián
a kicsi indián
7 kicsi indián
6 kicsi indián
5 kicsi indián
4 kicsi indián
3 kicsi indián
2 kicsi indián
1 kicsi indián
0 kicsi indián
Hogyan lehet ezt kiíratni a képernyőre?
: MESE
11 0 DO
10 R -
CR 4 . R 2 SPACES ." kicsi indian"
LOOP CR
;
Ugyanez még egyszerűbben megy, ha a cindexet nem 1-esével, hanem -1-esével léptetjük. Erre való a DO ... +LOOP szerkezet. A +LOOP a LOOP-tól abban tér el, hogy
A fenti programocskát a DO ... +LOOP felhasználásával a következőképpen lehetne megírni:
: MESE
CR 0 10 DO
R
CR 4 . R 2 SPACES ." kicsi indian"
-1 +LOOP
CR
;
A +LOOP szóval természetesen tetszőleges lépésközzel lépegethetünk.
: MESE2
CR 42 2 DO
R DUP
CR 3 .R SPACE ." ember "
2/ 3 .R SPACE ." par"
2 +LOOP
CR
;
Miról volt szó?
A 4. fejezet összefoglalása
A visszatérési veremről, azaz viremről:
Ennek segítségével tér vissza az interpreter, ha elugrik egy szót végrehajtani.
Amikor tehát egy szónak vége van, a viremnek rendben kell lennie.
A virmen tartják a DO ... LOOP és a DO ... +LOOP ciklusok a cindexet és a ciklushatárt.
A virem kezelésénél arra is figyelni kell, hogy szó hívása új elemmel bővíti.
A DO ... LOOP, DO ... +LOOP ciklusokról:
Mindkettő indexes ciklus: egy ciklusszámláló (ciklusindex, cindex) segítségével figyeli, hányszor futott le a ciklusmag.
A cindex a virmen van, ott bármikor elérhető.
A DO-nak a ciklushatárt (a cindex végértékét) és a cindex kezdőértékét adjuk meg a vermen.
A LOOP egyesével növeli a cindexet (a vermet békén hagyja), a +LOOP an nyit ad hozzá, amennyit a vermen megadunk.
A ciklusokból a LEAVE szóval lehet "soron kívül" kiszállni; a LEAVE összeigazítja a virmen a cindexet és a ciklushatárt, így a legközelebbi LOOP vagy +LOOP "úgy fogja érezni", hogy vége a ciklusnak.
A DO ... LOOP, DO ... +LOOP, IF ... ELSE ... ENDIF szerkezetekről:
Tetszés szerint egymásba ágyazhatok.
Csak szódefinícióban használhatók.
Ugyanez igaz a többi szerkezetre is, amit még tanulunk.
A tanult szavak:
| >R | ( n --- ) | A verem legfelső elemét a viremre teszi. |
| R> | ( --- n ) | A virem legfelső elemét a veremre teszi. |
| R | ( --- n ) | A virem legfelső elemét a veremre másolja, a virem változatlan marad. |
| DO | ( n1 n2 --- ) | Indexes ciklus eleje. n1 a ciklushatár, n2 a kezdőérték. A LOOP vagy +LOOP szóval együtt használjuk. |
| LOOP | ( --- ) | Indexes ciklus ciklusmagjának vége. A cindexet eggyel növeli, és ellenőrzi, hogy elérte-e már a ciklushatárt. Ha nem, visszamegy a DO utánra. Ha igen, kiszáll a ciklusból. |
| +LOOP | ( n --- ) | Indexes ciklus ciklusmagjának vége. A cindexhez n-et ad, és megnézi, hogy nagyobb-e (ha n > 0) vagy kisebb-e (ha n < 0) már, mint a ciklushatár. Ha nem, visszamegy a DO utánra. Ha igen, kiszáll a ciklusból. |
| I | ( --- n ) | DO ... LOOP ciklusban használható. A cindex értékét a veremre másolja. |
| LEAVE | ( --- ) | DO ciklusban használjuk. Összeigazítja a virmen a cindexet és a ciklushatárt, ettől a legközelebbi LOOP vágy +LOOP kiszáll a ciklusból. |
| SPACES | ( n --- ) | n szóközt ír a képernyőre. |
| .R | ( n m --- ) | n-et egy m szélességű mezőben jobbra igazítva írja ki. |
Példák
4.1. Írjunk egy TEGLA ( n m --- ) szót, amely m sort ír ki. Ezek mindegyike n csillagól álljon!
: TEGLA
0 DO
DUP
CR
0 DO
42 EMIT
LOOP
LOOP
DROP CR
;( n m --- )
( m sort írunk )
( n-re minden sornál szükség lesz )
( egy n-szer végrehajtandó )
( ciklusban kiírjuk a csillagot )
4.2. Írjunk egy "szokásos" ASCII kódtáblázatot:
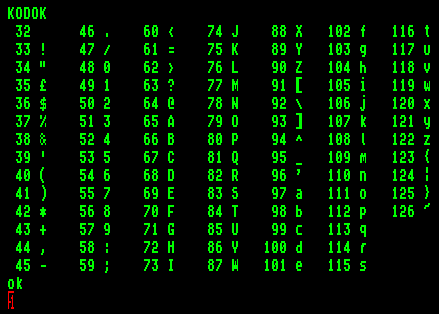
Az elemeket 7 oszlopba írjuk, az egymás utáni elemek egymás alatt vannak. Az első kiírandó kód a 32, az utolsó a 126.
: KODOK
14 0 DO
CR R
7 0 DO
32
OVER +
R 14 * +
DUP 127 < IF
DUP 3 .R
SPACE EMIT
3 SPACES
ELSE DROP
ENDIF
LOOP
DROP
LOOP CR
;
( 14 sor lesz)
( hányadik sornál tarunk )
( 7 elem egy sor )
( a táblázat kezdő eleme )
( a sor kezdő eleme )
( a sor aktuális eleme )
( 126-nál nagyobb )
( kódokat nem írunk ki )
4.3. A faktoriális kiszámítása: n! = 1 * 2 * 3 * . * n. Írjunk egy faktoriális számító F ( n --- n! ) szót! Ha 1-nél kisebb számot kapunk a vermen, 0-át adunk vissza.
: F
DUP 0 > IF
1
SWAP 1+
1 DO
R *
LOOP
ELSE DROP 0
ENDIF
;( n --- n! )
( ez lesz majd a sorozat )
( a vermen 1 és n+1 )
( a vermen a szorzat )
4.4. Az ún. Fibonacci-sor elemei: 1, 2, 3, 5, 8, ...,
A harmadik elemtől kezdve minden elem az előző kettő összege. Írjunk egy FIB (n1 --- n2 ) szót, amely a Fibonacci-sor n1-edik elemét teszi a veremre! Feltételezzük, hogy a vermen kapott szám 1-nél nem kisebb. A FIB szót úgy próbáljuk ki, hogy írassuk ki a sor első 16 elemét!
: FIB ( n1 --- n2)
DUP 3 < IF ( ha n1=1 vagy 2, akkor )
( a kivánt eredmény megegyezik n1-gyel )
ELSE
1 2 ROT 2 DO
SWAP OVER +
LOOP
SWAP DROP
ENDIF
;: FIBTEST CR 16 0 DO R FIB 5 .R LOOP CR ;
4.5. Írjunk olyan PRIM? ( n --- f ) szót, amely igaz értéket ad, ha n prímszám, azaz egyen és önmagán kívül nincs osztója! A +1, -1 nem számít prímnek.
Írjuk ki az 1 és 2000 közötti prímszámokat!
: PRIM?
ABS
DUP 2 > IF
1
OVER 2/ 2+ 2 DO
OVER R
MOD 0=
IF 0= LEAVE
ENDIF
LOOP
SWAP DROP
ELSE 2 =
ENDIF
;: PRIMTEST
CR 2000 1 DO
I PRIM? IF
I 5 .R
ENDIF
LOOP CR
;( n --- f )
( nem foglalkozunk külön )
( a negatív számokkal )
( ha R osztó, átbillentjük )
( a jelzőt )
( a nem vizsgált esetek )
( közül csak a 2 prim )
4.7. Jelenítsük meg a Pacal-háromszög első 13 sorát. (A Pascal-háromszög a matematikában a binomiális együtthatók háromszög alakban való elrendezése.)
: PASCTRIANGLE ( n --- )
CR DUP 0
DO
1 OVER 1- I - 2*
SPACES
I 1+ 0
DO
DUP 4 .R
J I
- * I 1+ /
LOOP
CR DROP
LOOP
DROP
;
13 PASCTRIANGLE
5.1. A végtelen ciklus (BEGIN ... AGAIN)
A BEGIN ... AGAIN szerkezettel a végtelenségig ismételtethetjük a BEGIN és AGAIN közötti ciklusmagot. Ilyen BEGIN ... AGAIN ciklusban fut maga a FORTH nyelven írt FORTH interpreter is, amelynek forrásával meg fogunk ismerkedni. (Valahogy így fest: BEGIN Olvass be egy sort! Hajtsd végre! AGAIN.)
A végtelen ciklusnak is véget vethetünk. Nézzük, hogyan működik a következő szó:
: EXIT R> DROP ;
például amikor így alkalmazzuk:
: BETUK ( --- )
BEGIN
KEY DUP EMIT
13 = IF CR EXIT ENDIF
AGAIN
;
Mikor a BETUK szó elkezd végrehajtódni, a virem tetejére az a cím kerül, ahol a BETUK végrehajtása után az interpreter folytatja a futást. Az EXIT-be való belépéskor az EXIT-ből (a BETUK-be) való visszatérés címe ennek tetejébe ül, de nem üldögél ott sokáig, mert az EXIT cselekménye éppen az, hogy őt onnan ledobja. Az EXIT tehát nem a BETUK-be tér vissza, hanem oda, ahova a BETUK-nek kéne, azaz a BETUK-et hívó szóba, így lehet egy szó befejezését kikényszeríteni.
Az EXIT több FORTH változatban alapszó, a FIG-FORTH 1.1-ben azonban nem.
5.2. Kiszállás a ciklus végén (BEGIN ... UNTIL)
A BEGIN ... UNTIL a két szó közötti ciklusmagot ismételgeti; a ciklusmag minden lefutása után az UNTIL megeszik egy jelzőt a veremről, eldöntendő, hogy visszamenjen-e a BEGIN-re, vagy menjen tovább.
Az UNTIL ( f --- ) akkor folytatja a ciklust, ha hamis jelzőt talál. |
Például írassuk ki a 200-nál kisebb prímszámokat! Felhasználjuk a 4.7. feladat PRIM? ( n --- f ) szavát, amely megmondja, hogy a vermen kapott szám prím-e.
: PRIMEK
CR 2
BEGIN
DUP 5 .R
BEGIN
1+ DUP PRIM?
UNTIL
DUP 199 >
UNTIL
DROP
;
( az első prímszám )
( kiírjuk )
( tovább keresünk )
( ha prímszám, kilépünk )
( ha már túl nagy, )
( kilépünk )
( kidobjuk a szemetet )
5.3. Kiszállás a ciklus közepén (BEGIN ... WHILE ... REPEAT)
A WHILE ( f --- ) a veremről elhasznált jelző segítségével ellenőrzi, nincs-e vége a ciklusnak.
A WHILE ( f --- ) akkor folytatja a ciklust, ha igaz jelzőt talál. |
Az igaz jelzőre a WHILE továbbengedi a programot: végrehajtódik a WHILE és REPEAT közötti programrész, majd a REPEAT (feltétel nélkül) visszamegy a BEGIN-re. Ha pedig a WHILE hamis jelzőt talál, a program a REPEAT utáni szavakkal folytatódik. Például:
: TURELMES
BEGIN
CR ." Kersz spenotot? (I vagy N ) "KEY DUP EMIT
73 -
WHILE( a vermen a válasz )
( az I betű kódja? )( ide akkor jutunk, ha nem I betű volt )
CR ." Helytelen válasz, próbáljuk újra!"
( innen visszamegy a vezérlés a BEGIN-re )REPEAT ( ide akkor jutunk, ha I betű volt )
CR ." Ennek igazan orulok!" CR
;
Miról volt szó?
Az 5. fejezet összefoglalása
A tanult szavak:
| BEGIN | ( --- ) | Ciklus kezdetét jelöli ki. A BEGIN ... UNTIL, a BEGIN ... WHILE ... REPEAT és a BEGIN ... AGAIN szerkezetben használjuk |
| AGAIN | ( --- ) | Feltétel nélkül visszatér a BEGIN-re. |
| UNTIL | (f --- ) | Ha hamis jelzőt kap, visszatér a BEGIN-re, ha nem, a program továbbsétál, ki a ciklusból. |
| WHILE | (f --- ) | Ha igaz jelzőt kap, a program továbbsétál a REPEAT-ig, onnan feltétel nélkül visszamegy a BEGIN-re. Ha nem, a program a REPEAT mögé ugrik ki a ciklusból. |
| REPEAT | ( --- ) | Feltétel nélkül visszatér a BEGIN-re. |
| EXIT | ( --- ) | Visszatérés egy szóból az őt hívó szóba. |
A szerkezetek (az IF, az indexes és index nélküli ciklusok) tetszőleges mélységben egymásba ágyazhatok. A kulcsszavak megfelelő párosítását az interpreter ellenőrzi, és nem fordítja le a szót, ha valamit nem talál rendben.
Példák
5.1. Mi a különbség az 5. fejezet TURELMES szavának és az alábbi változatnak a működése között?
: TURELMES
BEGIN
CR ." Kersz spenotot? (I vagy N ) "
KEY DUP EMIT
73 = IF EXIT ENDIF
CR ." Helytelen valasz, probaljuk ujra!"
AGAIN
CR ." Ennek igazan orulok!" CR
;A témában felhasználtuk a szintén az 5. fejezetben definiált EXIT szót is. A ciklus itt is az I betű hatására marad abba. Csakhogy az EXIT nemcsak a ciklusból, hanem magából a szóból is kiszáll: az AGAIN utáni örvendező felirat nem fog megjelenni.
5.2. Írjunk egy LOG2 (n1 --- n2 ) szót! Ha n1 pozitív, n2 legyen olyan szám, amire a 2^n2 <= n1. Ha nem, n2 legyen 0.
: LOG2
0 MAX DUP
IF
0 >R
1
BEGIN
2*
R> 1+ >R
OVER OVER <
UNTIL
DROP
DROP
R>
1-
ENDIF
;
( n1 --- n2 )
( ha pozitív számot kaptunk )
( a viremben állítjuk elő a kitevőt )
( viremben lesz az aktuális hatvány )
( a vermen n1 és a hatvány )
( következő hatvány )
( következő kitevő )
( "túlnőttuk" n1-et? )
( ha igen, vége a ciklusnak )
( a hatványra nincs szükség )
( n1 se kell )
( ez az első kitevő, amelyiknél )
( "túlnőttünk", az előző a jó )
( ha nem pozitív számot kaptunk, )
( a vermen lévő 0 éppen jó )
6.1. Előjeles és előjel nélküli értékek
Etessük meg az interpreterrel a következő parancssort:
65535 .
A kapott válasz: -1
Pedig mi nem -1-et tettünk a veremre. Vagy mégis?
A 65535 16 biten ábrázolva:
1111 1111 1111 1111
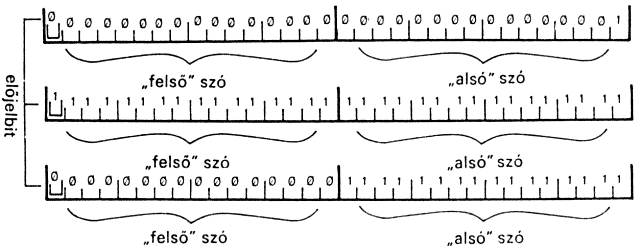
A . szó a vermen talált számot előjelesnek tekinti, azaz az első bitet előjelbitnek, és ha az 1, akkor a számot negatívnak. A negatív számokat úgy szokás ábrázolni, hogy a számot és ellentettjét ábrázoló két bináris sorozat összege 0 legyen. Ez 16 biten úgy megy, hogy a -1-et és 1-et jelentő szám összege 2^16 , azaz:
1 0000 0000 0000 0000
(a magas helyértékű 1 már kicsordul a tizenhat bitből, maradnak a 0 jegyek). És valóban:
+
vagy, hogy az otthonosabb tízes számrendszernél maradjunk:
65535 + 1 = 65536 = 2^16
Ugyanezt visszafelé is eljátszhatjuk; azt a szót kell hozzá ismernünk, amelyik előjel nélkülinek tekinti a verem tetején levő számot, és így írja ki.
U. ( u --- )
Az U betű a szó nevében és a veremhatás jelölésében az "unsigned" (előjel nélküli) angol szó rövidítése.
A
-2 U.
parancssorra a válasz: 65534. (Mivel a 2-t a 65534 egészíti ki 2^16-ra).
6.2. Mi lesz a túl nagy számokkal?
Látjuk, hogy 16 biten 2^16-1 = 65535-nél nagyobb szám nem létezhet. A nagyobb értékek első jegyei egyszerűen "lecsordulnak", elvesznek.
A
65536 .
parancsorra a válasz: 0. (A bináris ábrázolás: 1 0000 0000 0000 0000).
A
35537 .
parancsorra a válasz: 1. (a bináris ábrázolás: 1 0000 0000 0000 0001)
Hasonlóképpen a
35537 30000 + .
hatására is 1 a válasz. A FORTH a túlcsordulást nem kezeli, magunknak kell rá figyelni.
6.3. A duplaszavak
Ha egy szám nem fér el egy szóban, akkor ábrázolhatjuk kettőben, azaz: egy 32 bites duplaszóban.
A duplaszó a vermen úgy helyezkedik el, hogy a magasabb helyértékű szava (az "eleje") van felül. |
Tehát pl. az
1 0
sorozattal egy 1 értékű duplaszót tettünk a verembe. Erről a
D. ( d --- )
szó segítségével győződhetünk meg; ez kiírja a képernyőre a duplaszót, amely a verem két felső eleméből áll:
1 0 D. (a válasz: 1)
-1 -1 D. (a válasz: -1)
-1 0 D. (a válasz 65535)
A kiíratott duplaszavak binárisan az alábbi ábrán láthatók.
A D. szó nevében és a veremhatás jelölésében a d betű a doubleword angol szó rövidítése, bár akár a magyar "duplaszó" változaté is lehetne.
Kevésbé körmönfont módon is lehet a verembe duplaszavakat csalni. Ugyanis:
azokat a számokat, amelyekben tizedespont van, az interpreter duplaszóba konvertálja. |
Például:
100. D.
10.0 D.
1.0.0. D.
10. D.
431567. D.
Látjuk, hogy
a veremre tett duplaszó értékét a tizedespont helye nem befolyásolja. |
Meg fogjuk tudni állapítani, hogy hol volt a tizedespont (11.2.).
A duplaszavak éppúgy lehetnek előjelesek vagy előjel nélküliek, mint a szavak. Az előjel nélküli duplaszó jelölése a veremhatás leírásánál: ud.
A veremhatás leírásában a d, ud jelölés duplaszót, azaz két elemet jelent. |
A fejezet végén szerepelnek a duplaszavas és a vegyes aritmetika szavai, itt csak megemlítjük, hogy pár egyszavas műveletnek megvan a duplaszavas megfelelője is, ami hiányzik a fig-Forth szókészletéből, a példákban párat elkészítjük.
egyszavas: duplaszavas: . D. + D+ ABS DABS MINUS DMINUS DUP 2DUP .R D.R
6.4. Egy álcázott duplaszavas művelet
A most követ következő műveletek ugyan nem szükségesek, de meglétük pontossági vagy sebességi követelményekkel indokolható, és persze a kényelme sem utolsó szempont.
Szorzást és osztást kombinál a következő szó:
*/ ( n1 n2 n3 --- n4 )
ahol n4=(n1*n2)/n3. Az n1*n2 szorzatot a */ duplaszóban tárolja, így nem fordulhat elő, hogy a szorzás túlcsordulást eredményezzen. Ugyanezt teszi a
*/MOD (n1 n2 n3 --- maradék hányados )
szó is, csak megkapjuk az osztás hányadosát is.
Miben különbözik például a */ a * /-től? A magyarázat egyszerű a */ a szorzás elvégzése után az eredményt 32 biten tárolja, ami azt jelenti, hogy a szám akár 2^31 is lehet,
míg a * / szekvencia esetén az esetleges átvitelek figyelmen kívül maradnak. Ugyanezek vonatkoznak értelemszerűen a */MOD-ra is.
Lássunk egy példát! Számítsuk ki 3800-bak a 43 százalékát!
3800 43 100 */ .
az eredmény 1634. Míg a második változat:
3800 43 * 100 / .
323-at ad eredményül. A második megoldás a túlcsordulás miatt hibás.
Miról volt szó?
A 6. fejezet összefoglalása
Az előjel nélküli, a duplaszavas és az előjel nélküli duplaszavas értékeket kezelő szavak:
| U. | ( u --- ) | Kiírja a vermen talált előjel nélküli értéket a képernyőre, utána pedig egy szóközt. |
| U* | ( u1 u2 --- ud ) | Összeszorozza a vermen található előjel nélküli értékeket; duplaszavas, előjel nélküli szorzatot ad. |
| U/ | ( u1 u2 --- u2 u3 ) | Duplaszót oszt egyszavas értékkel, a visszaadott u2 az osztás maradéka, u3 a hányados. Valamennyi érték előjel nélküli. |
| U< | ( u1 u2 --- f ) | Előjel nélküli értékek összehasonlítása. f igaz, ha u1< u2. |
| D. | ( d --- ) | Kiírja a vermen talált duplaszót, utána egy szóközt. |
| D.R | ( d n --- ) | Kiírja a vermen talált duplaszót egy n szélességű mezőben. |
| D+ | ( d1 d2 --- d ) | Duplaszavak (duplaszavas) összegét adja. |
| DABS | ( d --- d1 ) | Duplaszó abszolút értékét adja. |
| DMINUS | ( d --- -d) | Duplaszót negál. |
| M* | ( n1 n2 --- d ) | Egyszavas értékeket szoroz, duplaszavas eredményt ad. |
| M/ | ( d n1 --- n2 n3 ) | Duplaszót oszt egyszavas értékkel; a visszaadott n2 az osztás maradéka, n3 a hányados. Valamennyi érték előjeles. (Az U/ előjeles változata.) |
| M/MOD | ( ud1 u2 --- u3 ud4 ) | Duplaszót oszt egyszavas értékkel; ud4 a duplaszavas hányados, u3 az osztás maradéka. |
Jelölések a veremhatás leírásában:
E két utóbbi a vermen két elemet jelöl.
Példák
6.1. Írjuk meg a veremkezelő műveletek duplaszavas változatát:
2DROP (n1 n2 --- ) avagy ( d --- )
: 2DROP DROP DROP ;
2SWAP (n1 n2 n3 n4 --- n3 n4 n1 n2 ) avagy ( d1 d2 --- d2 d1 )
: 2SWAP ( n1 n2 n3 n4 --- n3 n4 n1 n2 )
>R ( n1 n2 n3 )
ROT ( n2 n3 n1 )
ROT ( n3 n1 n2 )
R> ( n3 n1 n2 n4 )
ROT ( n3 n2 n4 n1 )
ROT ( n3 n4 n1 n2 )
;2OVER ( d1 d2 --- d1 d2 d1 )
: 2OVER ( d1 d2 --- d1 d2 d1 )
>R >R ( d1 )
2DUP ( d1 d1 )
R> R> ( d1 d1 d2 )
2SWAP ( d1 d2 d1 )
;2ROT ( d1 d2 d3 --- d2 d3 d1 )
: 2ROT ( d1 d2 d3 --- d2 d3 d1 )
>R >R ( d1 d2 )
2SWAP ( d2 d1 )
R> R> ( d2 d1 d3 )
2SWAP ( d2 d3 d1 )
;2PICK (duplapontos PICK)
: 2PICK
DUP + DUP 1+ PICK SWAP PICK
;2ROLL (duplapontos ROLL)
: 2ROLL
DUP + DUP 1+ ROLL SWAP ROLL
;
6.2. Írjunk további duplaszavas műveleteket a már meglévők felhasználásával!
D- ( d1 d2 --- d-kölünbség )
: D- DMINUS D+ ;
D= ( d1 d2 --- f ), f igaz, ha d1=d2
: D= DMINUS 0= SWAP 0= AND ;
avagy, kihasználva, hogy az OR csak akkor ad nullát eredményül, ha mindkét operandus 0 volt:
: D= DMINUS OR 0= ;
D< ( d1 d2 --- f ), f igaz, ha d1<d2
: D- 0< SWAP DROP ;
Itt azt használjuk ki, hogy a duplaszavas különbség akkor negatív, ha a felső szóban az előjelbit 1, erre a 0< szóval kérdezhetünk.
7.1. Byte-os műveletek
A számítógép memóriája számozott és számukkal címezhető byte-ok sorozata. A FORTH memóriakezelő szavai ezeket a byte-okat szabadon olvashatóvá és felülírhatóvá teszik, függetlenül attól, hogy az interpreter kódjának közepén, a veremben vagy pedig valami "szelídebb" helyen vannak. A programozó dolga, hogy ne nyúlkáljon rossz helyekre. Egy jó cím a nyúlkálásra, ahol átmenetileg adatot tárolhatunk: az ún. pad (ejtsd ped). A pad szó jegyzettömböt, blokkot jelent. A pad címét a
PAD ( --- cím )
szó szolgáltatja.
Vigyázat! A pad a szótárterület fölött van, mégpedig állandó távolságra a szótár tetejétől (az utoljára definiált szó utáni byte-tól). Ezért mikor új szavakat definiálunk vagy felejtjük a régieket, a pad helye változik. Legjobb, ha a padbe tett adatokat még ugyanabban a szóban felhasználjuk, amelyikben odatettük ezeket. Tartós adatmegőrzésre a változók szolgálnak, amelyekről a 8. fejezetben lesz szó.
A memória byte-jait kezelő szavak:
| C@ | ( cím --- c ) | a cím-en tárolt byte tartalmát adja meg; |
| C! | ( c cím --- ) | a c értéket a cím-en levő byte-on tárolja (a byte eddigi tartalma elvész). |
A veremhatás leírásában a cím memóriacímet jelent; típusára nézve ez egyszavas, előjel nélküli érték.
Írjunk egy szót, amely karaktereket vár a klaviatúráról, egészen az ENTER-ig, az ENTER után pedig visszaírja a kapott karaktersorozatot! A backspace karakterre (amelynek kódja 8) szavunk úgy reagál, hogy törli az utoljára beolvasott karaktert. A karaktereket kiírásig tartjuk a padben.
: VISSZAIR
PAD
BEGIN
KEY DUP 13 -
WHILE
( --- )
( ide kerül az első karakter )
( vermen a következő karakter címe )
( akkor lesz hamis, ha ENTER volt )( ide akkor jutunk, ha még nem volt ENTER ) DUP 8 =
IF DROP
DUP
PAD -
IF 1- ENDIF
ELSE
OVER C!
1+
ENDIF
REPEAT
( backspace volt ? )
( nem akarunk többet törölni, )
( mint amennyi van? )
( ha nem )
( tároljuk a kódot )
( a következő kódot egyel odébb )
( kell majd tárolnunk )( ide az ENTER hatására jutunk )
( a vermen a cím kód )DROP PAD
DO R C@
EMIT LOOP
;( az első kiírandó karakter címe )
A karakterek kiíratását a TYPE alapszóval is megoldhattuk volna. A TYPE más, byte-sorozatokat kezelő alapszavakkal együtt megtalálható a fejezet végi szójegyzékben. Karaktersorozatok beolvasásának kényelmes eszköze az
EXPECT ( cim max --- )
szó, amely a klaviatúráról beolvasott karaktereket a megadott cím-től kezdve leteszi a memóriába. A karakterek beolvasása az első kocsivisszáig vagy "max" számú karakter beolvasásáig tart. A sorozat végére a memóriában bináris nullák kerülnek. A backspace karakter törli a sorozat utoljára beírt karakterét.
7.2. Szavas és duplaszavas műveletek
A memóriában nemcsak 8 bites, azaz byte-os értékeket tartunk, hanem szavasakat és duplaszavasakat is.
Az erre szolgáló szavak:
| @ | ( cim --- tartalom ) | a cím-en és az utána következő címen levő 2 byte-ot, azaz szót teszi a veremre; |
| ! | ( n cím --- ) | az n 16 bites értéket a cím-en és az utána következő byte-on tárolja (a 2 byte előző tartalma elvész); |
| 2@ | ( cím --- d-tartalom ) | a cím-en és az utána következő 3 byte-on tárolt duplaszót teszi a verembe. |
| 2! | ( d cím --- ) | a duplaszót a cím-en meg az utána következő 3 byte-on tárolja (a 4 byte előző tartalma elvész). |
Tehát a
0 PAD 2!
sorral a PAD, PAD+1, PAD+2 és PAD+3 címeken levő byte-okat nulláztuk.
7.3. Kényelmes veremkezelés
A memóriát kezelő szavakkal "soron kívül" belepiszkálhatunk a verembe is, hiszen végső soron az is csak egy memóriaterület. Mindössze azt kell hozzá tudni, hogy milyen címeken terül el a verem. Az
SP@ ( --- cím )
szó a verem (SP @ végrehajtása előtti) tetejének a címét adja, azaz, ha a verem nem üres, a legfelső elem címét.
Ha tehát a verem nem üres, akkor az
SP@ @
sorozat egyenértékű egy DUP művelettel. Ha kísérletezünk egy kicsit a veremmel és az SP@ szóval, hamar rájöhetünk, hogy az SP@ annál kisebb címet ad, minél több elem van a veremben.
A verem a memóriacímekkel ellentétes irányban, "lefelé" növekszik. |
A verem fenekének a címét, azt a címet, amelyet az SP@ szó üres verem esetén ad, a FORTH egy állandó címen őrzi; ez utóbbi címet az S0 szó teszi a veremre. A verem feneke tehát az
S0 @
címen van. (Lásd a következő ábrát.)
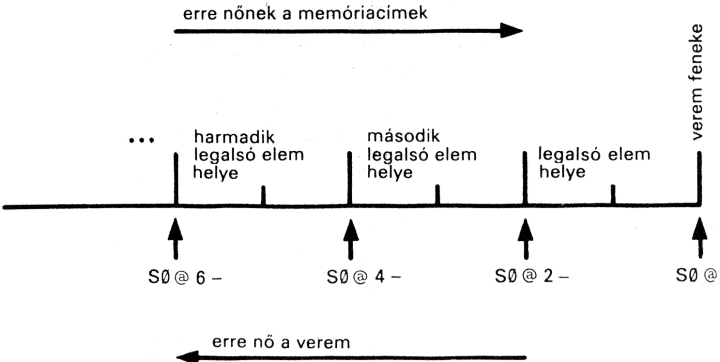
Most már megírhatjuk az 1.6. szakaszban szereplő, nem szabványos veremkezelő szavakat (DEPTH, .STACK, PICK és ROLL). Ezek forrásszövegét annak érdemes elolvasnia, aki szívesen tanul más programjából; elvi újdonságot egyik sem nyújt.
: DEPTH
SP@
S0 @
- MINUS
2 /
;( --- veremmélység )
( a teteje )
( a feneke )
( ennyi byte-pt foglalnak a verem elemei )
( tehát ennyi elem van )
: .STACK ( --- )
SP@ S0 @ =
IF
CR ." stack is empty"
ELSE
SP@ S0 @ SWAP ( tetejétől az aljág )
DO CR R @ 5 .R 2 +LOOP
ENDIF CR
;
Mielőtt a PICK és ROLL szavakat megírnánk, tűnődjünk el: mit teszünk, ha valaki túl mélyen akar a verem fenekére nézni? Mi történjen, ha valaki a verem két eleme közül a harmadikat akarja elővenni? Tételezzük fel, hogy ez csak programozói tévedés lehet, és óvjuk meg a programozót tévedése következményeitől, azaz állítsunk le mindent! Erre való a
QUIT
szó. A QUIT "minden szinten szinte mindent" félbeszakít és visszaadja a vezérlést a külső interpreternek, amely új parancssort kezd el várni. A QUIT-tel félbeszakított programfutást nem követi OK.
A PICK szövege különösebb magyarázat nélkül is követhető.
: PICK ( n --- n1 )
DEPTH 1- (veremmélység n nélkül )
OVER <
IF ( ha a veremben n-nél kevesebb elem van )
." PICK error" QUIT
ELSE
SP@ ( a veremtető, azaz n címe )
SWAP 2* ( 2*n )
+ @
ENDIF
;
A verem a PICK indításakor:
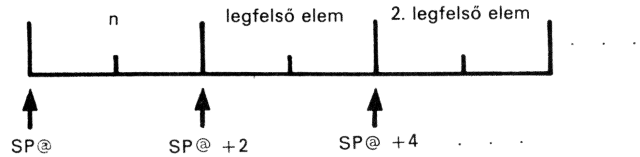
Az n ROLL (n most a veremre tett számot jelenti) először egy PICK-kel a verem tetejére másolja az n-edik legfelső elemet, amelyet "fel kell dobnia", majd egy DO ... LOOP ciklussal rámásolja a "régi" n-edik elemre az n-1-ediket, az n-1-edikre az n-2-ediket stb. Végül az n-1-ediktől kezdve minden elem "lejjebb csúszott", legfelül pedig 2 példány van az n-edikből; a felesleges felsőt eldobjuk.
: ROLL
DUP >R
PICK
( "félreteszünk" egy példányt )
( a tetőre másoljuk az n. elemet )( DO ... LOOP ciklusban másolunk ) SP@
DUP 2+
SWAP R> 2* +
DO
R 2- @
R !
-2 +LOOP
DROP
;( a veremtető címe )
( az eredeti legfelső elem címe )
( az eredeti n. elem címe )
( a másolandó elem )
( ide másolunk )
( eldobjuk az n. elem felesleges )
( példányát )
Miról volt szó?
A 7. fejezet összefoglalása
A 7. fejezetben tanult szavak:
| @ | ( cím --- n ) | A cím 16 bites tartalmát adja. |
| ! | ( n cím --- ) | A cím-től kezdve 2 byte-on tárolja n-et. |
| C@ | ( cím c --- ) | A cím 8 bites tartalmát adja. |
| C! | ( c cím --- ) | A cím-en levő byte-ban tárolja a c-t. |
| PAD | ( --- cím ) | Átmeneti tárolásra alkalmas memóriaterület címe. Ez a cím változik, ha a szótár méretét változtatjuk (új szavakat definiálunk, "felejtünk" stb.) |
| QUIT | ( ---- ) | A programfutás megszakítása. A QUIT hatására az interpreternek megadott parancssor értelmezése félbemarad, az interpreter új parancssort vár. |
| EXPECT | ( cím max --- ) | Szöveg beolvasása a billentyűzetről a cím-re. A törlés karakterrel az utoljára bevitt karakter törölhető. A beolvasás az első kocsivissza karakterig, vagy a "max" számú karakter (a törölteket nem számítva) beolvasásáig folytatódik. A memóriában a szöveg végére (egy vagy több) bináris 0 kerül. |
| S0 | ( --- cím ) | A verem fenekének a címét adja. |
| SP@ | ( --- cím ) | A verem tetejének (a legfelső elemnek, ha a verem nem üres ) (az SP@ végrehajtása előtti) címét adja. Ha üres a verem, akkor ez a cím megegyezik az S0 @ adta címmel. |
Byte-sorozatokat kezelő, kényelmes alapszavak:
| TYPE | ( cím hossz --- ) | Kiírja a cím-en lévő karaktersorozatot, a megadott hosszon. |
| CMOVE | ( honnan hová hossz --- ) | Byte-sorozat mozgatása egyik címről a másikra. Az átvitel az alacsonyabb címeken kezdődik. |
| FILL | ( cím hossz karakter --- ) | A memóriát a cím-től kezdve hossz számú karakterrel tölti fel. |
| ERASE | ( cím hossz --- ) | A memóriát a cím-től kezdve hossz számú 0 byte-tal tölti fel. |
| BLANKS | ( cím hossz --- ) | A memóriát a cím-től kezdve hossz számú szóközzel tölti fel. |
Példák
7.1.a. Hogyan írnánk meg a 2@ ( cím --- d-tartalom ) és 2! (d cím --- ) szavakat?
: 2@ ( cím --- d-tartalom )
DUP @ ( az első memóriaszó tartalma )
SWAP 2+ @ (a másodiké )
;: 2! ( d-tartalom cím )
>R ( a viremre tesszük a címet )
R 2 + ! ( a második memóriaszót töltjük fel először )
R> ! ( az elsőt másodszor )
;
7.1.b. Hogyan írnánk meg a TYPE ( cím hossz --- ) szót?
FIG változat:
: TYPE
-DUP IF
OVER +
SWAP DO
R C@ EMIT
LOOP
ELSE DROP
ENDIF
;( cím hossz ---)
( ha a hossz nem 0 )
( a két cím közötti byte-ok )
( kiírása )
( ha 0 volt, a vermen a cím van )
7.1.c. Hogyan írnánk meg a CMOVE (tól ig hossz --- ) szót?
Egy FORTH megoldás:
: CMOVE
0 DO
OVER C@
OVER C!
1+ SWAP 1+ SWAP
LOOP
DROP DROP
;( tól ig hossz ---)
( előveszünk egy byte-ot )
( letesszük a másik helyre )
( mindkét címet növeljük )
( a két cím már nem kell )Általában azonban (így a fig-Forth-ban is) a CMOVE nem FORTH-ban, hanem gépi kódban írt szó.
7.1.d. Hogyan írnánk meg a FILL (cím hossz byte --- ) szót?
A FIG megoldás:
: FILL
SWAP >R
OVER C!
DUP 1+ R> 1-
CMOVE
;
( cím hossz byte --- )
( cím byte )
( cím )
( cím cím+1 hossz-1)
7.1.e. Hogyan írnánk meg az ERASE és BLANKS szavakat?
FIG változat:
: ERASE 0 FILL ;
: BLANKS BL FILL ;
7.2. Miért nem jó a DEPTH így?
: DEPTH ( --- veremmélység )
S0 @ ( a feneke )
SP@ ( a teteje )
- 2 /
;Az első S0 egy új elemet tesz a veremre, az SP@ már nem az eredeti állapotban találja. Ez a változat helyesen:
: DEPTH ( --- veremmélység )
S0 @ ( a feneke )
SP@ ( a teteje )
- 2 /
1-
;
7. 3. Sok FORTH-ban van olyan S<> ( cím1 cím2 hossz --- f ) szó, amely a cím1-en és cím 2-őn kezdődő hossz hosszúságú karaktersorozatot hasonlítja össze, de a fig-Forth-ban nincs. A visszaadott jelző hamis, azaz 0, ha a két karaktersorozat megegyezik, pozitív, ha az első nagyobb, negatív, ha a második. (A két egyforma hosszúságú karaktersorozat akkor egyforma, ha a megfelelő karaktereik megegyeznek; ha nem, akkor az első meg nem egyező karakterpár kódjának összehasonlítása adja a kettő közötti relációt.) Írjuk meg az S<> szót!
: S<>
0 PAD !( cím1 cím2 hossz --- f) ( ez lesz a jelző,amelyet visszaadunk )
( kezdetben feltételezzük, hogy a két sorozat )
( megegyezik, ha mégse, megváltoztatjuk )0 DO
OVER C@ OVER C@
-DUP IF
PAD !
LEAVE
ENDIF
1+ SWAP 1+ SWAP
LOOP
DROP DROP
PAD @
;
( a két karakterkód különbsége )
( ha a két karakter különböző )
( akkor ez lesz a válaszjelző )
( és befejezzük a műveletet )
( továbblépünk a címekkel )
( a címek már nem kellenek )
( "elővesszük" a jelzőt )
7.4. Ha a TYPE ( cím hossz --- ) szóval találomra íratunk ki egy memóriaterületet, akkor igen furcsa dolgok történnek, hiszen a kiíratandók között mindenféle vezérlőkarakterek is vannak. Írjunk egy olyan TYPE2 ( cím hossz --- ) szót, amely a 32 és 126 közötti kódú karaktereket (írásjelek, számjegyek,nagybetűk, kisbetűk) kiírja, a többi helyére pontot ír!
A program szinte szóról szóra megegyezik a TYPE-pal, csak a karakterek kiírása előtt kell a vezérlőkaraktereket a pont kódjával (56) helyetesíteni:
: TYPE2
-DUP IF
OVER + SWAP DO
R C@
DUP DUP
32 < SWAP 126 > OR
IF
DROP 46
ENDIF
EMIT
LOOP
ELSE DROP
ENDIF
;
( cím hossz --- )
( ha vezérlőkarakter, )
( kicseréljük )
( kiírjuk a karaktert)A TYPE2-t például így próbálhatjuk ki:
PAD 6 65 FILL PAD 3 ERASE PAD 6 TYPE2 A kapott válasz: ... AAA
7.5. Írjunk egy BOTTOM ( --- n ) szót, amely a verem legalsó elemét a verem tetejére másolja!
: BOTTOM
SP@ S0 @ - IF ( van valami a veremben? )
S0 @ 2- @
ELSE ." stack is empty" QUIT
ENDIF
;
8.1. Egy biztos hely: a változó
Vannak adatok, amelyekre időnként szükség lehet (a verem fenekének címe, a szótár tetejének címe, saját számlálóink), de nem mindig. Az ilyeneket nem tarthatjuk a vermen, mert belebolondulnánk, ha még ezeket is kerülgetnünk kéne, sem a padben, amelynek időnként megváltozik a címe. Erre vannak a FORTH-ban (is) a változók, amelyek ugyanúgy szótári szavak, mint az aritmetika vagy a ciklusszervezés szavai.
A FORTH változók úgy működnek, hogy a veremre tesznek egy címet; ezen a címen tárolhatjuk a 16 bites adatot, amelynek megőrzésére a változót létrehoztuk. |
A FORTH interpreter maga is használ változókat, ezek az ún. rendszerváltozók.
8.1. Példák rendszerváltozókra
8.2.0. Az S0
Az S0 szó, amellyel a 7.3.-ban ismerkedtünk meg, egy rendszerváltozó.
8.2.1. A BASE
A BASE (ejtsd: béz, jelentése: alap) változó a kiíráskor, beolvasáskor használt számrendszer alapszámát tartalmazza. Eddig ez mindig 10 volt. Ha mondjuk, a 2-es számrendszerben akarunk dolgozni, akkor ennek a változónak az értékét 2-re állítjuk:
2 BASE ( a veremre teszi a változó címét )
! ( amelyre ezzel a művelettel 2-t tettünk )
Próbálgassuk, milyen az élet kettes számrendszerben:
1 1 + .
A 9-es számjegyet például most nem veszi be az interpreter "gyomra", hiszen kettes számrendszerben vagyunk, ahol ennek semmi értelme. Meglepetten tapasztalja viszont a kísérletező Olvasó, hogy a 2, 3 számok - amelyek szintén "értelmetlenek", működnek. Ennek az az oka, hogy az első néhány szám benne van a szótárban; ezeket gyakran használjuk. Az interpreter munkáját gyorsítja, hogy "készen találja" őket, nem kell konvertálnia.
A leggyakrabban használt két számrendszer a 10-es és a 16-os; ezek beállítására vannak FORTH alapszavak. Működésük a forrásszövegükből világos:
: DECIMAL 10 BASE ! ;
: HEX 16 BASE ! ;
Hogyan tudhatjuk meg, hogy az adott pillanatban mi a konverzió alapszáma? Egyszerű, mondhatnánk meggondolatlanul, csak elő kell venni a változóból az alapszámot és kiíratni:
BASE @ .
Válaszként 10-et kapunk Mit tudtunk meg ebből? Hogy a számrendszer alapszámát az adott rendszerben egy 1 és egy 0 jegy ábrázolja, vagyis hogy megegyezik a számrendszer alapszámával. Többre megyünk, ha az eggyel kisebb számot íratjuk ki:
BASE @ 1- .
Ebből a válaszból tudhatjuk, hogy B, azaz 11 a legkisebb egyjegyű szám, ezek szerint a 12-es számrendszerben vagyunk.
Állítsuk most 5-re az alapszámot, és definiáljunk új szól az 5-ös számrendszerben:
5 BASE !
: KIIR 10 . ;
Mi történik, ha a KIIR-t a 10-es számrendszerben próbáljuk ki? Eredményül 5-öt kapunk.
A szótári szavakban binárisan vannak a számok, a KIÍR definíciójakor 0000 0000 0000 0101 került oda, ez a tízes számrendszerben 5.
8.2.2. Az OUT
Tudjuk már, hogy a képernyőre író FORTH alapszavak mind az EMIT-tel írják ki az egyes karaktereket. Az EMIT eggyel növeli az OUT (ejtsd: aut, jelentése: ki) változó tartalmát, így, ha az OUT-ot nullázzuk, utána bármikor megtudhatjuk, hogy a nullázás óta hány karakter került a képernyőre.
Képzeljük el például, hogy egyforma sorokat akarunk egymás alá írni, amelyek két (előre nem tudni, milyen hosszú) számból állnak; azt kívánjuk, hogy az első szám a képernyősor 3., a második pedig a 13. pozíciójában kezdődjék. Feltesszük, hogy a két szám a vermen van. Megírjuk azt a szót, amely a fentiek szerint írja ki őket:
: BALRA-TABULAL
CR 0 OUT !
3 SPACES
.
( n1 n2 --- )
( nullázzuk az OUT változót )
( 3 szóköz )
( kiírjuk az első számot )( az OUT tartalma most: hány karaktert írtunk )
( már ebbe a sorba )13 OUT @ -
SPACES .
;( 13-ra egészítjük ki a kiírt )
( karalterek számát, majd kiírjuk )
( a masodik számot )
8.3. Új változók létrehozása
Saját változókat a VARIABLE ( n --- ) szóval definiálhatunk. A vermen várt érték a változó kezdőértéke. A változó nevét közvetlenül a VARIABLE után kell megadnunk:
0 VARIABLE SAJAT
Ezzel a SAJAT szó megjelenik a szótárunkban (mint arról VLIST-tel egy pillanat alatt meggyőződhetünk). Működése: a változó címét a veremre teszi. Vagyis, ha leírjuk a SAJAT azonosítót, a verem tetejére kerül a változó számára lefoglalt memória címe. Így a változó értékét a 7.2. pontban megismert @ utasítással vehetjük elő, illetve a ! utasítással változtathatjuk meg.
Képzeljük el például, hogy listát készítünk a nyomtatón (a ki-készülék átállításával). Hogy mifélét, azt nem tudni, egy biztos: 60 sornak kell egy oldalon lennie. Új sort a listázó program mindig a CR szóval fog kezdeni. Definiáljuk át úgy a CR szót, hogy 60 soronként lapot dobjon (12 EMIT), és a laptetőre írja ki, hogy hányadik lapnál tart!
Mivel nem tudjuk, mi történik listázás közben a veremmel, meg egyszerűbb is így, a sorokat és lapokat egy-egy változóban számláljuk:
0 VARIABLE SORSZ
0 VARIABLE LAPSZ
Mindkét változót eggyel kell majd növelgetnünk. Eddigi ismereteink szerint egy változó tartalmát valahogy így növelnénk 1-gyel:
SORSZ @ ( elővesszük a tartalmat )
1+
SORSZ ! ( a növelt értéket visszatesszük )
A változókhoz (vagy bármely memóriaszóhoz) való hozzáadást egyszerűsítő FORTH alapszó a
+! ( n cím --- )
amely a cím-en levő egyszavas értékhez hozzáadja n-et, és az összeget a cím-en tárolja. A +!-t valahogy így írhatnánk meg, ha még nem lenne:
: +!
SWAP OVER
@
+
SWAP !
;
( n cím --- )
( cím n cím )
( cím n régi-tartalom )
( cím új-tartalom )
Ezzel növelhetjük a SORSZ tartalmát:
1 SORSZ +!
Sorok, lapok és egyebek számolgatásánál gyakran kell a változókat éppen 1-gyel növelni. Talán érdemes rá külön szót bevezetni, amely felhasználja az 1+ gyorsműveletet:
: INC ( cím --- )
DUP @
1+ SWAP !
;
A nyomtató programnak a következő dolgokat kell 60 sor kiírása után tenni:
: LAPDOB
12 EMIT
0 SORSZ !
LAPSZ @ .
." . lap" CR
LAPSZ INC
;
( --- )
( lapdobás )
( a sorszámlálás újrakezdése )
( a lapszám kiírása )
( a lapszámláló növelése )
A kiírást mindjárt lapdobással fogjuk kezdeni; ez a megfelelő pillanat a LAPSZ kezdőértékének beállítására is:
: ELSO-LAPDOB
1 LAPSZ ! LAPDOB
;
A listázóprogram dolga lesz, hogy a listázást az ELSO-LAPDOB hívásával kezdje. Az átdefiniált CR:
: CR
SORSZ INC ( növeljük a sorszámlálót )
SORSZ @ 60 = ( lap vége?)
IF LAPDOB
ELSE CR
ENDIF
;
8.4. Konstansok
Ha egy értéket úgy akarunk megőrizni a szótárban, hogy soha nem változtatjuk, akkor egyszerűbb olyan szavakat használni, amelyek az értéknek nem a címét, hanem magát az értéket adják a vermen. Ezek a konstansok. Ilyenek például az 1, 2, 3 szavak, amelyek benne vannak a szótárban és az 1, 2, 3 értéket teszik a veremre. Ilyen a BL, amelytől a szóköz kódját kapjuk.
Saját konstansainkat a
CONSTANT ( n --- )
szóval definiálhatjuk. A dolog meglehetősen hasonlít a változók definiálására. Például:
42 CONSTANT CSIL-KOD
ezzel a CSIL-KOD nevű konstans szót definiáltuk. A CSIL-KOD 42-t tesz a veremre.
Miról volt szó?
A 8. fejezet összefoglalása
A 8. fejezetben tanult szavak:
| VARIABLE | ( n --- ) | Változót definiáló szó. így használjuk: n VARIABLE xxx. Ezzel létrehoztunk egy xxx nevű szótári szót. Az xxx szó úgy működik, hogy a veremre teszi a változó címét. Ezen a címen a változó létrejöttekor az n kezdőérték van. |
| CONSTANT | ( n --- ) | Konstansot definiáló szó. így használjuk: n CONSTANT yyyy. Ezzel létrehoztunk egy yyyy nevű szótári szót. Az yyyy úgy működik, hogy a veremre teszi a konstans értékét: ez az az érték, amelyet a konstans létrehozásakor a vermen megadtunk. |
Rendszerváltozók:
| BASE | ( --- cím ) | A számok ki-, ill. beírásakor zajló kon-verziók alapszáma. |
| OUT | ( --- cím ) | Ennek a változónak az értékét az EMIT (minden egyes karakterkiírás) eggyel növeli. Így felhasználhatjuk arra, hogy a kiírt karakterek számát figyeljük és szabályozzuk. |
Egyéb szavak:
| HEX | ( --- ) | A BASE értékét 16-ra állítja. |
| DECIMAL | ( --- ) | A BASE értékét 10-re állítja. |
| +! | ( n cím --- ) | A cím 16 bites tartalmához hozzáadja n-et, az eredményt a cím-cn tárolja. |
Példák
8.1. A ? ( cím --- ) alapszó forrásszövege:
: ? @ . ;
Kiírja a cím-en lévő 16 bites, előjeles értéket. Ha pl. A egy változó, akkor az
A ?
sorral az A értékét íratjuk ki.
8.2. Írjunk egy := ( cím1 cím2 --- ) szót, amely a cím2-n levő 16 bites értéket átmásolja a cím1-re
(tehát pl. ha A és B két változó, akkor az A B := művelettel az A-nak a B értékét adjuk)!
: = ( cím1 cím2 --- )
@ SWAP !
;
8.3. Írjunk egy .BASE ( --- ) szót, amely a BASE tartalmát decimálisán írja a képernyőre, de nem rontja el! (Vagy pontosabban: elrontás után visszaállítja.)
: .BASE)
BASE @ DUP
DECIMAL
.
BASE !
;( --- )
( most rontottuk el a BASE-t )
( de van még egy példány az eredtiből )
( így vissza tudjuk állítani )
9. Hol változik a változó? Ismerkedés a szótárral
9.1. A szótármutató
A FORTH programozás során a szótár mérete állandóan változik. Hogy éppen hol van a szótár "teteje", a szótár utáni első szabad hely, ahova a következő szótári szó kerül majd, azt az interpreter a DP (Dictionary Pointer, ejtsd: diksöneri pointer, jelentése: szótármutató) rendszerváltozóban tartja. A DP változó értékét sokat használjuk, ezért kiolvasására külön alapszó van:
: HERE ( --- cím )
DP @ ;
A 7.1. szakaszban volt szó arról, hogy a pad a szótár tetejétől állandó távolságra van. A jelenséget megmagyarázza a PAD szó forrásszövege:
: PAD HERE 68 + ;
9.2. Mi van a szótárban?
Egy szótárelem a következő részekből áll:
A paramétermező - teljesen önkényesen "paramzőnek" rövidítjük - fizikailag a szó legvégén van. így változó definiálása után a szótármutató pontosan az új változó paramzője mögé mutat. Ha ekkor a szótármutató értékét 1-gyel, 2-vel stb. növeljük, akkor ezzel megtoldjuk a változó paramzőjét 1, 2 stb. byte-tal. A szótármutató növelésére szolgáló alapszó, az ALLOT forrásszövege:
: ALLOT (n --- )
DP +! ;
Az ALLOT utasítás n darab byte-ot lefoglal az operatív tár felhasználói szótár utáni részében. Végrehajtása után a DP rendszerváltozó a lefoglalt terület utáni első szabad byte-ra mutat. Például egy 80 karakter hosszú karakterfüzér számára így foglalhatunk helyet:
80 ALLOT
9.3. Hosszú változók
Ezzel a kezünkben van a lehetőség arra, hogy duplaszavas vagy hosszabb változókat definiáljunk.
87 VARIABLE DUPLA
88 HERE !
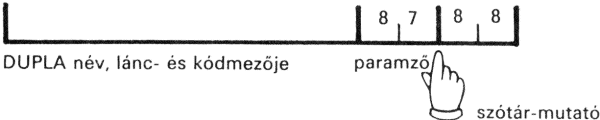
2 ALLOT

A DUPLA tehát két szavas, az első szó kezdőértéke 87, a másodiké 88.
A paramzőbe való kezdőérték-tárolásra, egyúttal a paramző "tágítására" valók a következő alapszavak:
: , ( n --- )
HERE !
2 ALLOT
;: C, ( c --- )
HERE C!
1 ALLOT
;
A , utasítás az adatvermen található 16 bites szám alsó 8 bitjét helyezi a felhasználói szótár végére. A DP értéke eggyel nő.
A C, utasítás a vermen található 16 bites szám alsó 8 bitjét helyezi a felhasználói szótár végére. A DP értéke eggyel nő.
Az előbbi sorozatot tehát így is írhattuk volna:
87 VARIABLE DUPLA 88 ,
Most már tudunk vektorokat, hosszabb adatsorokat definiálni. Fontos tudni, hogy erre vannak a FORTH-nak sokkal kényelmesebb eszközei is - a 15. fejezetben fogunk velük találkozni -, itt csak azért definiálunk vektort, hogy jobban értsük a FORTH működését (így például a 15. fejezetet is).
Definiáljunk például egy 10-elemű "szavas" vektort! Ennek paramzője 20 byte-os lesz; a
0 VARIABLE VECTOR
által definiált VECTOR 2 byte-os paramzőjét 18 byte-tal kell megtoldanunk:
18 ALLOT
A vektor úgy ér valamit, ha az elemeire külön-külön hivatkozhatunk. Megírjuk tehát az IK-ELEM ( n --- cím ) szót, amely az elem indexét (sorszámát) várja a vermen, és a címét adja vissza:
: IK-ELEM
2*
VECTOR +
2 -
;(n --- cím)
( egy elem 2 byte )
( az 1 indexű elem azon a címen )
( kezdődik, amelyet a VECTOR ad )
Miról volt szó?
A 9. fejezet összefoglalása
A 9. fejezetben tanult szavak:
| DP | ( --- cím ) | Rendszerváltozó. Az interpreter a szótár "tetejének", a szótár utáni első szabad byte-nak a címét tartja benne. |
| HERE | ( --- cím ) | A DP rendszerváltozó értékét adja. |
| ALLOT | ( n --- ) | DP értékéhez n-et ad. |
| , | ( n --- ) | Az n-et a HERE címen, egy szón tárolja, a szótármutató (DP) értékét 2-vel növeli. |
| C, | ( c --- ) | Az n-et a HERE címen, 1 byte-on tárolja, a szótármutató (DP) értékét 1-gyel növeli. |
Példák
9.1. írjunk egy ceruza-nyilvántartó rendszert! A rendszer háromféle ceruzát tart számon:
0 CONSTANT PIROS
1 CONSTANT KEK
2 CONSTANT ZOLD
Hozzunk létre egy 3-elemű változót, amelyben az egyes ceruzaszámlálókat tarthatjuk. A ceruzaszámlálók kezdeti értéke 0 legyen. Ezután a következő szavakat írjuk meg:
CERUZA-BE ( n szín --- )
A megadott n értékkel növeli a színnek megfelelő ceruzaszámlálót. Tehát pl.:
1 ZOLD CERUZA-BE
(ami ugyanaz, mintha ezt írtuk volna: 1 2 CERUZA-BE )
hatására a zöld ceruzák számlálója eggyel nő.
CERUZA-KI ( n szín --- )
Ha a színnek megfelelő ceruzaszámláló értéke legalább n, levon belőle n-et. Ha nem, hibajelzést ad, a számláló értékét pedig változatlanul hagyja.
A ceruzaszámlálásra használható "hosszú változó" leírása:
0 VARIABLE CK 0 , 0 ,
Definiáljunk egy SZLO ( szín --- cím ) szót, amely a szín kódjából előállítja a színnek megfelelő ceruzaszámláló dímét:
: SZLO
2*
CK +
;( szín --- cím )
( a szín kódját 2-vel szorozzuk, mivel )
( a számlálók szavasak )
( az első számláló címe )Innen már egyszerű dolgunk van:
: CERUZA-BE ( n szín --- )
SZLO +!
;: CERUZA-KI ( n szín --- )
SZLO
OVER OVER @
> IF ." nincs annyi "
DROP DROP
ELSE
SWAP MINUS SWAP +!
ENDIF
;: CERUZAK ( szín --- )
SZLO @ .
;
9.2. Írjunk egy NULLA ( n --- ) szót, amely n darab 0 értékű byte-tal toldja meg az előtte definiált változó paramzőjét. Tehát pl. a
0 VARIABLE HUSZ 18 NULLA
parancssor egy 20 byte-os paramzőjű változót hoz létre; ebből 2 byte-ot a VARIABLE, 18 db 0 kezdőértékű byte-ot pedig a NULLA.
: NULLA ( n --- )
0 DO 0 C, LOOP ;
10.1. A FORTH-füzérek
A szövegek, számok, amelyeket beolvasunk vagy kiírunk, a memóriában karakterfüzéreket alkotnak. (A karakterfüzér angol elnevezése string, ejtsd: sztring.) Egy ilyen füzérrel akkor tudunk dolgozni, ha ismerjük a kezdőcímét és a hosszát. A FORTH-ban gyakori tárolási mód: a füzért az ún. hosszúságbyte-tal kezdjük, amely a füzér hosszát tartalmazza, és ezután jönnek a karakterkódok. Az így tárolt füzért FORTH-füzérnek nevezzük. Ismerkedjünk meg a COUNT alapszóval, amely a FORTH-füzér címéből előállítja az első karakter címét és a füzér hosszát (azaz a TYPE kiíró szó hívásához szükséges paramétereket)!
A "LOVE" szót tartalmazó FORTH füzér byte-jai:
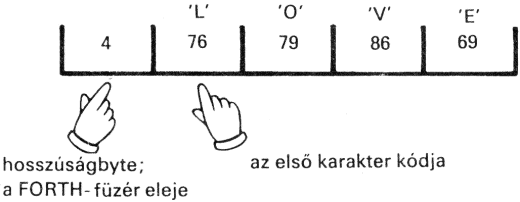
A COUNT szó forrása:
: COUNT ( ff-cím --- cím hossz )
DUP 1+ ( az első karakter címe )
SWAP C@ ( a hosszúság-byte tartalma )
;
FORTH-füzér alakjában szolgáltatja a szövegeket a FORTH interpreter egyik lelke, a WORD szó is.
WORD ( c --- )
(ejtsd: vörd, jelentése: szó) tördeli a befolyamot a vermen megadott határolókarakter alapján. Azaz: a WORD beolvassa a befolyam karaktereit, egészen a határolóig, átállítja a megfelelő rendszerváltozókat (hogy a legközelebbi WORD ott kezdje az olvasást, ahol ez befejezte), a beolvasott szöveget pedig FORTH-füzér formájában a HERE címre teszi. A WORD a sor végét mindenképpen határolónak érzi. Vigyázat, a kernyőknél (l. a 2.5. szakaszt) egészen másképp érzékeli a sor végét; mi (mondjuk) 64 karakteres sorokat látunk, ezek végét azonban nem jelzi a memóriában különleges karakter, mint a terminálról beadott sorokét!
Egy példa a WORD alkalmazására a LEVEL szó, amelyet így lehet majd használni:
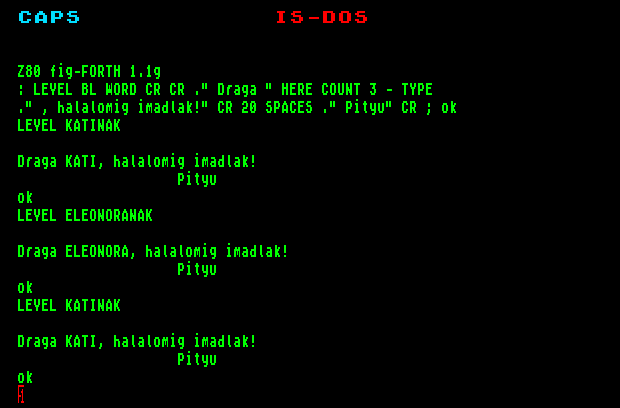
Lássuk a megvalósulást:
: LEVEL
BL ( a szóköz kódját adó konstans )
WORD ( beolvassa a LEVEL után megadott nevet )( az első szóközig és FORTH-füzér formájában )
( leteszi a HERE címre )CR CR
." Draga "
HERE COUNT
3 - TYPE
." , halalomig imadlak!"
CR 20 SPACES
." Pityu" CR
;( új sorban kezdjük )
( a név címe, hossza )
( "-nak", "-nek" nem kell )
Látom már lelki szemeimmel az Ödönök, Róbertek, Elemérek szemrehányó tekintetét, az Évákról és Annákról nem is beszélve. Miért csak a Pityuk élete legyen könnyű? A WORD-öt lehet egy szóban kétszer is hívni; tehetjük a feladó nevét is változtathatóvá:
: .NEV
( ez olvassa be, írja ki a címzett és feladó nevét )
BL WORD
HERE COUNT 3 - ( "nak", "tol", stb )
TYPE
;: LEVEL ( --- )
CR CR
." Draga " .NEV
." halalomig imadlak"
CR 20 SPACES .NEV CR
;
A szó használata:
LEVEL JENONEK LUJZATOL
A Kísérletező Olvasó esetleg kipróbálja a következőt:
BL WORD ABRAKADABRA HERE COUNT TYPE
és azt várja, hogy az ABRAKADABRA szót kapja válaszul, hiszen azt olvasta be a WORD. Ehelyett a TYPE szót fogja kapni, mivel az interpreter a parancssorok elemzésére maga is a WORD-öt használja, így, mire a TYPE végrehajtódik, az utolsónak végrehajtott WORD őt rámolta a HERE címre.
10.3. Honnan ismerős? (WORD-del működő alapszavak)
A WORD-ben az a szokatlan, hogy nemcsak a veremről vesz adatot, hanem maga mögül, a befolyamból is kivesz egy szövegrészt és felhasználja. A jelenséggel már találkoztunk egyes FORTH alapszavaknál; ezek a szavak mind a WORD-öt hívják.
A legegyszerűbb ilyen alapszó a ( , amelynek a forrásával is megismerkedünk:
: ( 41 WORD ;
(41 a záró zárójel kódja). A nyitó zárójel beolvassa, amit maga mögött talál, egészen a záró zárójelig (vagy a sor végéig). A WORD úgy állítja át a megfelelő rendszerváltozókat, hogy az interpreter legközelebb a záró zárójel utánról olvasson; így a befolyamnak a két zárójel közötti része egyszerűen nem rúg labdába. A ( szóhoz a 16. fejezetben még lesz egy megjegyzés.
A másik alapszó teljes forrásával később (szintén a 16. fejezetben) ismerkedünk meg, itt csak egy csökkent értékű változatot láthatunk:
: ." 34 WORD HERE COUNT TYPE ;
(34 az idézőjel kódja). A WORD beolvassa a befolyamot az idézőjelig és FORTH-füzér formájában elhelyezi a HERE címen; innen egy COUNT TYPE sorozattal kiíratható.
Mennyivel tud ennél többet az igazi ." szó? A különbség akkor látszik, mikor a szót definíció belsejében akarjuk használni. Az igazi ." a definícióban megadott szöveget írja ki, az itteni változat a definiált szó végrehajtódásakor olvassa el a befolyamból a kiírandó szöveget.
WORD-del olvassa be az elfelejtendő szó nevét a FORGET is.
A WORD munkál minden olyan szó belsejében, amellyel más szavakat definiálhatunk: VARIABLE CONSTANT :
Pontosabban, a CREATE szó hozza létre az új szótárelemet, a CREATE pedig a WORD- del olvassa be a létrehozandó szótárelem nevét.
Miról volt szó?
A 10. fejezet összefoglalása
A tanult szavak:
| WORD | ( c --- ) | A c határolókarakterig beolvassa a befolyamot; a beolvasott szöveget FORTH-füzér formájában a HERE címre teszi. |
| COUNT | ( ff-cím --- cím hossz ) | FORTH-füzér kezdőcíméből előállítja a karaktersorozat címét és hosszát. |
Példák
10.1. Írjunk egy PELDANY ( n --- ) szót, amely beolvassa az utána megadott szöveget a sor végéig, és a beolvasott sort annyiszor írja le, amennyit a vermen megadtunk neki! Például:
4 PELDANY HULL A HO ES HOZIK
Ha a WORD-nek olyan határolókaraktert adtunk meg, amilyen a befolyamban nem fordulhat elő, akkor a WORD a sor végéig fog olvasni. Ilyen kód például az 1 (nem karakterkód):
: PELDANY ( n --- )
1 WORD
0 DO CR HERE COUNT TYPE LOOP
;
10.2. Írjunk egy ORD ( --- c ) szót, amely az utána megadott ( és szóközzel megtoldott betű kódját teszi a veremre! Pl:
ORD C .
: ORD ( --- c )
BL WORD HERE 1+ ( kikerüljük a számlálót )
C@
;
11.1. Megfelelő típushoz megfelelő kiíratás
A . .R D. egyöntetűen egy-két számjegy-előállító alapszóra épül. Ugyanezekkel az alapszavakkal mi is bármikor írhatunk hasonló szavakat, amelyek valamilyen formában kiírják a vermen levő, adott típusú értéket. A vermen levő bináris érték kiírható számjegyekké konvertálását a <# szó kezdi el és a #> fejezi be.
A konvertált jegyeket előállító szavakat (#, #S, HOLD, SIGN) a <# hívása után, a #> hívása előtt futtathatjuk. |
Mint láthatjuk, több FORTH szóban is szerepel a # karakter. Hogy ne töltsünk feleslegesen sok időt ezen karakter keresésével, jegyezzünk meg egy fontos dolgot:
Az angol billentyűzetű gépeken nincsen # karakter, helyette minden esetben a £ karaktert kell használnunk. |
A konverzió során a memóriában létrejön a konvertált jegyekből és kiegészítő jelekből álló füzér, amelynek címét és hosszát a #> a veremre teszi (így TYPE-pal kiírathatjuk).
Aki már próbált egy számot az egyik számrendszerből a másikba átírni, az tudja, hogy ez csak visszafelé, az utolsó jegytől kezdve megy. A konvertáló szavak is "visszafelé hordanak":
a kiíratandó karakterekből álló füzér hátulról kezdve készül el. A füzér utolsó (elsőnek elkészülő) byte-ja a pad első byte-ja. |
(Ne csodálkozzunk tehát, ha a konvertáló szavak elrontják a pad elején tárolt adatainkat!)
A
# ( ud1 --- ud2 )
szó beilleszti a füzérbe a (hátulról) következő jegyet.
Működése: az ud1 előjel nélküli duplaszót elosztja a BASE tartalmával. Az ud2 hányadost a veremre teszi, hogy a konverzió folytatódhasson; kikalkulálja a maradékból a megfelelő számrendszerbeli számjegy kódját és beírja a füzérbe.
A
#S
végigkonvertálja a vermen levő előjel nélküli duplaszót, annyi jegyet tesz a már előállítottak elé, amennyi szükséges (tehát értéktelen, vezető nullákat nem). A vermen egy duplaszavas 0 marad.
A #S forrása egyébként:
: #S ( ud --- dupla-0 )
BEGIN
# ( egy jegy)
2DUP OR 0= ( a vermen heverő duplaszó 0? )
UNTIL ( ha nem 0 volt az utolsó duplaszó, folytatjuk )
;
A duplaszót, amelyben a konverzió részeredményeit tartottuk, a
#>
dobja el a veremről.
A #, igy a #S is a BASE-nek megfelelő számrendszerbeli jegyeket állít elő.
A
HOLD ( c--- )
szó beírja a kapott c karaktert az eddig konvertált jegyek elé.
Ha például duplaszavas, előjel nélküli számot akarunk úgy kiíratni, hogy az utolsó két jegy tizedesjegynek látszódjék:
: 2TJE
<#
# #
46 HOLD
#S
#>
TYPE
;
( ud --- )
( konverzió eleje )
( előállt a két utolsó jegy )
( tizedespont )
( további jegyek )
( konverzió vége )
Vagy, ha magunk szeretnénk a vermen megadni, hogy hány tizedesjegy legyen:
: TJE
<#
0 DO # LOOP
46 HOLD
#S
#>
TYPE
;
( ud tizedesjegyek --- )
( konverzió eleje )
( tizedesjegyek )
( tizedespont )
( meg a többiek)
( konverzió vége )
Ha előjel nélküli, egyszavas értéket akarunk kiíratni, az sem gond. Könnyen csinálhatunk belőle kétszavasat, hiszen (pozitív számról lévén szó) a duplaszavas érték magasabb helyi értékű szava 0, egyszerűen ezt kell csak a veremre tenni. Az U. egy lehetséges forrása például:
: U.
0
<# #S #>
TYPE SPACE
;
( ud --- )
( konverzió eleje )
( előállt a két utolsó jegy )
( tizedespont )
( további jegyek )
( konverzió vége )
Többnyire azonban előjeles értékekkel dolgozunk. Ehhez meg kell ismerkednünk a
SIGN ( n d --- d )
szóval, amely szintén a <# és #> között használatos. A SIGN az n (azaz a verem harmadik eleme) előjelétől függően tesz a konvertált sorozatba mínuszjelet vagy sem. Például a . egy lehetséges forrása:
: .
DUP ABS
0
<# #S SIGN #>
TYPE SPACE
;
( n --- )
( a felső példánynak nincs előjele )
( könnyű belőle előjel nélküli )
( duplaszót csinálni )
A <# utasítássor SIGN #> szekvencia előjeles duplapontos számok átalakítására használható. Ekkor az adatvermen a szám abszolút értéke alatt ott kell lenni a szám felső két bájtjának, hogy a SIGN helyesen működjék. Ezt a következő utasítássorozattal készíthetjük elő:
SWAP OVER DABS
Szimpla előjeles egész számok esetén a veremszintek a következőképpen alakulnak: legalul a szám, felette a szám abszolút értéke, legfelül egy 0.
Példa::
8-jegyű előjeles számokat kell kiíratni a következő formában: xx,xxx,xxx. A vessző ASCII kódja 44.
: PRINT SWAP OVER DABS <£ £ £ £ 44 HOLD £ £ £ 44 HOLD £S SIGN £> TYPE ;
-1234567.8 PRINT
Végül egy szellemes példa Leó Brodie-tól, a STARTING FORTH című könyvből:
Tegyük fel, hogy a vermen heverő duplaszó a másodpercek száma, és mi óra:perc:másodperc formában akarjuk kiíratni ezt az időtartamot. Lavíroznunk kell a 10-es és a 6-os számrendszer között.
: SEXTAL
6 BASE ! ;: :OO
#
SEXTAL
#
DECIMAL
58 HOLD
;
( áttérés a 6-os számrendszerre )
( egy decimális jegy előállítása )
( egy "szextális" jegy elállítása )
( kettőspont )
A fenti programocska, ha jobban belegondolunk, a 60-nal való osztás maradékát írja ki, mégpedig tízes számrendszerben. (A hányadost pedig továbbadja a vermen.) így a kívánt szót már könnyen megírhatjuk:
: SEC ( ud --- )
<# :OO :OO #S #> TYPE SPACE
;
11.2. Mit kapunk a NUMBER-től?
Tudjuk az első fejezetből, hogy az interpreter a kapott szavakat először a szótárban keresi, s ha nem találja, akkor megpróbálja számnak értelmezni. Ez utóbbit a
NUMBER ( cím --- d )
hívásával teszi. A NUMBER a megadott című FORTH-füzérből megpróbálja (a BASE alapján) előállítani a megfelelő értékű duplaszót. Ha nem megy, hibajelzés kíséretében "elszáll" - azaz a QUIT hívásával abbahagyja a sor interpretálását. Ha viszont a füzér az előjelen és esetleg egy tizedesponton kívül csupa, az adott számrendszerben értelmezhető jegyből állt, akkor a veremre teszi a (tizedespont figyelembevétele nélkül kiszámított) duplaszavas, bináris értéket; ezenkívül a DPL rendszerváltozóba leteszi a tizedesjegyek számát. Ha nem volt tizedespont, a DPL értéke -1. (Az interpreter, mikor a befolyamban talált számokat elemzi, a DPL -1 értékénél eldobja a konvertált duplaszó magasabb helyértékű szavát; ezt látjuk mi úgy, hogy egyszavas értéket kaptunk.)
Példa: "prefix" szorzás a tizedespont figyelembevételével. A "*" szót így lehet majd használni:
"*" 1,2 -0.2
A számokat a WORD-del olvassuk be és a NUMBER-rel elemezzük:
: "*"
2 0 DO
BL WORD
HERE NUMBER
DROP
DPL @
0 MAX
LOOP
( --- )
( két számot olvasunk be)
( a FORTH füzér a HERE címen )
( konvertálás duplaszóba )
( majd egy szóba )
( tizedesjegyek száma )
( ha DPL -1, nem volt )
( tizedesjegy )( a vermen: érték 1 dpl1 érték 2 dpl2 ) >R SWAP >R
M*
>R DUP R> DABS
R> R> +
<# -DUP IF
0 DO # LOOP
46 HOLD
ENDIF
#S SIGN #>
TYPE SPACE
;( érték1 érték 2 )
( duplaszavas szorzat )
( előkészítés konverzióhoz )
( tizedesjegyek száma )
11.3. Konverzió karakterből számjeggyé
Ezt az átalakítást a DIGIT utasítás ( c n1 --- n2 igaz ) végzi. A c számot egy karakter ASCII kódjaként értelmezi, és n1 számrendszert alapul véve megkísérli számmá, számjeggyé konvertálni. Ha a karakter létező számjegye a számrendszernek, ezt a verem második szintjére (n2), a verem tetejére pedig logikai igaz értéket (1) tesz. Ellenkező esetben csupán egy hamis (0) értéket kapunk.
Például a "3" karakter ASCII kódja 51, ezt alakítsuk számmá a tízes számrendszerben:
51 10 DIGIT ..
A kapott eredmény: 1 3
Az "A" betű kódja 65:
65 10 DIGIT .
Az eredmény: 0
De
65 16 DIGIT . .
eredménye: 1 10
Miról volt szó?
A 11. fejezet összefoglalása
A tanult szavak:
| <# | ( --- ) | Számkonverzió (binárisról karakteresre) kezdete. |
| # | ( ud1 --- ud2 ) | A következő karakterkódot generálja az
output (kimenő) karaktersorozatba. A továbbadott duplaszavas érték a további karakterek előállításához kell (ez a BASE tartalmával való osztás hányadosa, a karakterkód pedig a maradékból keletkezik). A <# és #> szavak között használható. |
| #S | ( ud1 --- duplaszavas-0 ) | Számjegykódokat generál az output karaktersorozatba mindaddig, amíg az osztogatás során a konvertálandó duplaszó értéke el nem fogy; azaz a konvertált karaktersorozatban az értékes jegyek (és csak ezek) jelennek meg. A <# és a #> szavak között használható. |
| HOLD | ( c --- ) | Beilleszti a c karaktert az output karaktersorozatba. A <# és #> szavak között használható. |
| SIGN | ( n d --- d ) | Egy - jelet illeszt az output karaktersorozatba, ha n negatív. A <# és #> szavak között használható. |
| #> | ( ud --- cím hossz ) | Konverzió befejezése. Eldobja a veremről a konverzió közben használt duplaszót, helyette a konvertált karaktersorozat címét és hosszát teszi a veremre. |
| NUMBER | ( cím --- d ) | A cím-en kezdődő FORTH-füzért konvertálja a d előjeles duplaszóba, a BASE értékének megfelelően. Ha a konvertálandó FORTH-füzér tartalmaz tizedespontot, akkor a tizedesponttól jobbra levő jegyek számát a DPL rendszerváltozóba teszi; ha nem, a DPL értéke -1 lesz. Ha a konverzió nem hajtható végre, a programfutás hibajelzés kíséretében megszakad. |
| DPL | ( --- cím ) | Rendszerváltozó. A NUMBER a tizedesjegyek számát teszi bele. |
Példák
11.1. Írjunk egy T ( n tizedesjegyek --- ) szót, amely az előjeles, egyszavas n értéket a megadott számú tizedesjeggyel írja ki!
: T ( n tizedesjegyek --- )
> R DUP ABS
0 ( előjel ud-érték )
<# R> ( a tizedesjegyek száma )
-DUP IF ( ha van tizedesjegy )
0 DO # LOOP 46 HOLD
ENDIF
#S SIGN
#> TYPE
;
11.2. Írjunk egy .L ( n mezőszélesség --- ) szót, amely az n értéket a megadott szélességű mezőben balra igazítva írja ki, azaz ha a kiírandó sorozat rövidebb, megtoldja a szükséges számú szóközzel, ha hosszabb, levágja belőle az alacsony helyi értékű jegyeket.
: .L
>R DUP ABS 0
<# #S SIGN #>
R MIN
SWAP OVER
TYPE
R> SWAP -
SPACES
;
( n mezőszélesség --- )
( vermen a konvertált sorozat )
( címe és hossza )
( ha kell, levágjuk a felesleget )
( a vermen: hossz cím hossz )
( a vermen: hossz )
( ha kell, szóközök )
11.3. Írjunk egy % ( százalékláb --- ) szót, amely maga mögül, a befolyamból szedi a százalékalapot, és a szükséges számú tizedesjeggyel kiírja a százalékértéket! Feltételezzük, hogy a százalékalap értékes jegyei elférnek egy szón, és, hogy a százalékalapot tizedesponttal adták meg. Például:
50 % 24.4
12 % 3.
Feledékenyek számára: százalékérték = százalékalap*százalékláb/100.
: %
BL WORD
HERE NUMBER
DROP M*
SWAP OVER DABS
<# DPL @
2+
0 DO # LOOP
46 HOLD #S SIGN
#> TYPE SPACE
;
( n --- )
( %alap karakteresen )
( %alap konverzió )
( duplaszón a %érték )
( előkészítés kiiratáshoz )
( ennyi tizedes volt a %alapban )
( a 100-zal való osztást a )
( tizedespont tologatásával )
( jelezzük )
11.4. Mi lehet a SIGN forrása?
A FIG megoldás:
: SIGN
ROT 0< IF 45 HOLD ENDIF ;
12. Szótárak
A szó belső ábrázolása:
12.1. A szótárelemek láncolása
A szótár minden elemének tehát van egy láncmezője, ez fűzi össze a szótár szavait. A láncmező egy mutatót tartalmaz az előző szó névmezőjére, vagy (a szótár "legalsó" eleménél) 0-t. Az ' (aposztróf i, ( --- pfa ) szó szolgál arra, hogy egy szó nevéből annak pfa-ját megkapjuk. A ' közvetlen szó. Ezért szódefiníció belsejében, ha azt akarjuk, hogy az ' csak az adott szó végrehajtásakor jusson érvényre, előtte a [C0MPILE]-t kell alkalmaznunk. (Erre példákat is fogunk látni ).
Ha egy szó névmezőjének címét ismerjük, akkor a megfelelő címkonverziós FORTH alapszavakkal a többi mező címét is előállíthatjuk:
| PFA | ( ncím --- pcím ) | egy szótárelem névmezőcíméből előállítja a paramző címét; |
| NFA | ( pcím --- ncím ) | a paramző címéből adja a névmező címét; |
| CFA | ( pmcím --- kcím ) | a paramző címéből adja a kódmező címét; |
| LFA | ( pcím --- lcím ) | a paramző címéből adja a láncmező címét. |
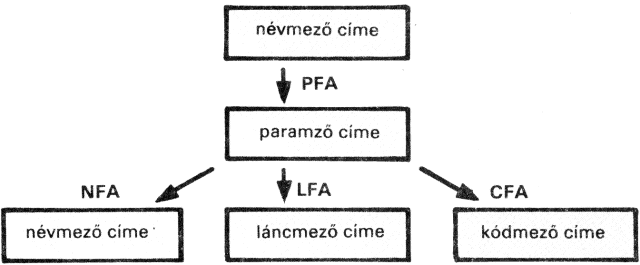
Egy szó névmezőjének címéből tehát így kapjuk meg az előtte definiált szó névmezőjének címét:
PFA ( paramező címe )
LFA ( láncmező címe )
@ ( láncmező tartalma = az előző szó névmezőjének címe )
Következő példánk ADDESS szavát felhasználhatjuk arra, hogy egy tetszőleges szóhoz tartozó bejegyzés négy meghatározó címét kiírassuk.
: ADDRESS ( --- pfa cfa lfa nfa )
[COMPILE] ' DUP DUP DUP
CFA ROT LFA ROT NFA ;
: .ADDRESS ADDRESS
CR ." NFA = " U. CR ." LFA = " U.
CR ." CFA = " U. CR ." PFA = " U.
;
Példa a használatára:
HEX DUP .ADDRESS
Figyeljük meg a [COMPILE] alkalmazását az ADDRESS szóban! Ha ez nem lenne ott az ' előtt, akkor az '-ot követő DUP paramezőcíme kerülne a veremre az ADDRESS definíciója közben. Így viszont az csak a .ADDRESS végrehajtásakor jut érvényre, tehát bemenő paramétere a DUP lesz.
Tudunk tehát a láncon haladni; még egy szó, amellyel megtaláljuk a lánc elejét (a legutoljára definiált szó nfa címét):
| LATEST | ( --- ncím ) | Az utoljára definiált szótári szó névmezőjének címét adja. |
A névmezőben a szó neve "majdnem" FORTH-füzér formájában van; a különbség az, hogy a névmező hosszúságbyte-jának első három bitje nem tartozik a hosszhoz, egyéb információkat tartalmaz. Így a szó nevét nem a COUNT TYPE sorozattal íratjuk ki, hanem egy külön erre szolgáló szóval:
| ID. | ( ncím --- ) | kiírja annak a szónak a nevét, amelynek névmezőcimét a vermen találja. |
Készítsünk például egy ELOZO nevű szót, amely kiírja azt, hogy egy megadott szó csatolómezője melyik szóra mutat.
: ELOZO [COMPILE] ' LFA @ ID. ;
A következőképpen lehet tehát az utoljára definiált szó nevét kiíratni:
: UTOLSO LATEST ID. ;
Abban az esetben, ha egy szó névmezője egyik végének címét ismerjük és a másik vég címére vagyunk kíváncsiak, a TRAVERSE ( cím1 n --- cím2 ) szót kell használnunk.
Most már akár ki is listázhatjuk a szótárunkat:
: VLIST2
80 OUT !
LATEST
BEGIN
OUT @
70 > IF
CR 0 OUT !
ENDIF
DUP ID.
SPACE SPACE
PFA LFA @
DUP 0=
UNTIL
DROP
;
( a lista új sorban kezdődik )
( a vermen: ncím )
( nem írunk túl okat egy sorba? )
( név kiírása )
( következő névmezőcím )
( ha a láncmezőben 0 van, vége )
( a szótárnak )
Miben különbözik ez a jól ismert VLIST-tőI? Először is nem áll le, ha a billentyűzeten megnyomunk egy gombot. Ezen könnyen segíthetünk, csak a
?TERMINAL ( --- f )
szót kell ismernünk; ez akkor ad igaz jelzőt, ha a billentyűzeten megnyomtak egy billentyűt (mi meg nem kezeltük le a KEY szóval). Másodszor nem ugyanazt a szótárat listázza, amelyiket a VLIST. Hogy ezt hogy kell érteni? Kiderül a következő szakaszban.
12.2. Kereső és láncoló szótár
Zavarba hozó, hogy két olyan szó jelentése között kell különbséget tenni, amelyeket egyformán "szótár"-nak fordítunk. Az egyik a dictionary (diksöneri) szó, (pl. a DP: Dictionary Pointer rendszerváltozó nevében találkoztunk vele), amely "fizikai" szótárat jelent, a másik a vocabulary (vokébjulöri) (a VLIST, Vocabulary List szó nevéből ismerős), amely "logikai" szótár, szavak mutatókkal összeláncolt sorozata. A FORTH-ban egy "fizikai" szótár több "logikait" tartalmazhat; a FORTH szótáron kívül többnyire van EDITOR és ASSEMBLER szótár is. Alapesetben a FORTH szótárban vagyunk; ekkor pl. az EDITOR szótár szavait az interpreter egyszerűen nem találja meg, nem ismeri fel.
Ahhoz, hogy az EDITOR szótár szavait használhassuk, az EDITOR-t kell kereső szótárrá tenni. (A "kereső szótár" meglehetősen szabad fordítása az eredeti "context vocabulary", kontext szótár kifejezésnek.) A szótárak közül egy adott pillanatban egyetlen lehet kereső szótár.
Két logikai lánc, fizikailag összekeverve
Az interpreter az interpretálandó szavakat a kereső (context) szótárban keresi. Egy szótár neve az adott szótárat teszi kereső szótárrá. |
Tehát pl. az
EDITOR
parancssorral "láthatóvá tettük" az EDITOR szótár szavait (ha előtte betöltöttük azt). Felesleges azon aggódni, hogyan leszünk meg az EDITOR-ban a FORTH alapszókészlet nélkül:
Minden szótár szavaihoz hozzá vannak láncolva annak a szótárnak a szavai, amelyben az adott szótárat definiálták. |
Végső soron ez azt jelenti, hogy
a FORTH szótár szavai minden kereső szótárból látszanak. |
Látjuk ezt, ha az EDITOR szó végrehajtása után egy VLIST-et csinálunk. A szabvány VLIST ugyanis a kereső szótárat listázza. Arról is rögtön meggyőződhetünk, hogy a mi VLIST2 programunk nem ezt teszi, hiszen nem írja ki az EDITOR szótár szavait. A LATEST szó, amellyel programunk kezdődik, nem a kereső, hanem a láncoló szótár legfelső szavának címét adja.
Láncoló (eredetileg current) szótár is csak egy van egy adott pillanatban.
Az újonnan definiált szavak a láncoló szótárba kerülnek. |
A szótár nevével csak a kereső szótárat változtatjuk meg; ha azt kívánjuk, hogy a láncoló szótár is ugyanaz legyen, akkor a
DEFINITIONS
szót kell használnunk, amely hozzáigazítja a láncoló szótárat a keresőhöz, a kettő meg fog egyezni.
Fordított irányban igazítja össze a két szótárat a definíciókat bevezető : szó: ez a keresőt állítja át úgy, hogy megegyezzen a láncolóval.
Egy régi ismerős, a FORGET új tulajdonsága: csak akkor működik, ha a kereső és láncoló szótár megegyezik, egyébként hibajelzéssel megszakad.
12.3. Saját szótáraink
Magunk is elkülöníthetjük az egyik szókészletet a másiktól, létrehozhatunk saját szótárakat. A szótárt definiáló
VOCABULARY
szó után kell az új szótár nevét megadni (ahogy eddig is láttuk a definiáló szavaknál). Szótár definiálása után az IMMEDIATE szót is meg szokás adni, amellyel később foglalkozunk (lásd a 16. fejezetet). Ha például írunk egy felhasználói programot, de nem akarjuk a felhasználó orrára kötni, hogy melyek a program felépítése közben megírt segédszavak, akkor ezeket a segédszavakat eldughatjuk egy külön szótárba:
VOCRBULRRY REJTETT IMMEDIATE
Mikor a "rejtett" szavakat írjuk, ezt tesszük kereső és láncoló szótárrá:
REJTETT ( ettől lett kereső )
DEFINITIONS ( ettől meg láncoló )
Ha a kisegítő szavak megírásával készen vagyunk, akkor a FORTH szótárban szeretnénk létrehozni a végeredményt:
FORTH DEFINITIONS
: VEGSO ( ámde a programban használni akarjuk )
( a REJTETT szavakat )
REJTETT
( itt jöhet a program szövege )
;
Az, hogy a REJTETT szó fordítás közben hajtódik végre és nem a VEGSO futásakor, az IMMEDIATE eredménye.
Mivel a : elállítja a kereső szótárat, ha másik szót is akarunk a REJTETT szavak felhasználásával definiálni, akkor a következő kettőspont után ismét át kell állítanunk a kereső szótárat:
: VEGSO2 REJTETT
( itt jöhet a program szövege )
;
12.4. Az ASSEMBLER szótár
Gépi kódú törzzsel rendelkező szavakat mi is létrehozhatunk a beépített assembler segítségével. A fordító használata előtt az azt tartalmazó screen-eket be kell tölteni:
12 LOAD
és a szótárt az ASSEMBLER szóval ki kell jelölni.
A gépi kódú törzzsel rendelkező szót két módon hozhatjuk létre. Az első mód: a szódefinícióban a kettőspont helyett CODE, a pontosvessző helyett C; szót használjuk, a szó törzse pedig assembly és FORT utasításokat tartalmaz.
CODE név utasítások C;
A másik módszere a ;CODE szó használata
: név ... ;CODE utasítások C;
Itt a ;CODE hatására befejeződik a név szó definíciója, és sor kerül a ;CODE és C; közötti utasítások gépi kóddá fordítására. A név és a CODE között valamilyen definiáló utasítássorozatnak kell lennie (például <BUILDS-nek, ld. 15. fejezet). Ezen utasítássorozat a <BUILDS és DOES> közötti utasításokhoz hasonló feladatokat végezhet. A DOES> és a CODE között mindössze annyi a különbség, hogy az előbbinél FORTH-ban, az utóbbiban ASSEMBLER formában írhatjuk meg a végrehajtási algoritmust. Ezután a
név gépikód
végrehajtása a következőt eredményezi: előbb lefut a név ;CODE-ig tartó (FORTH-ban írt) törzse, majd létrejön a gépikód nevű szó, amelynek végrehajtása az adott gépi kód végrehajtását jelenti. Ezt a módszert ritkábban használjuk, mint a CODE . C; szerkezetet.
Lássuk most, mik lehetnek az "utasítások" Először is lehetnek tetszőleges FORTH szavak. Ezek (függetlenül attól, hogy közvetlenek-e vagy sem) azonnal végrehajtódnak. Általában címek kiszámítását végzik. Lehetnek assembly utasítások, amelyeket a FORTH filozófiájának megfelelően a fordított lengyel formátumhoz hasonlóan kell leírni. A FORT assembler INTEL mnemonikokat használ.
Lássunk néhány példát:
MOV C,A
MVI A,7FH
JMP 3000H
A C MOV
7F A MVI
30000 JMP
Az összes többi utasítás hasonló módon képezhető.
Emellett lehetőség van a következő magas szintű szerkezetek használatára:
IF .. ELSE .. THEN
BEGIN .. WHILE .. REPEAT
BEGIN .. AGAIN
Ezek nem tévesztendők össze a FORTH hasonló szerkezeteivel. Ezekből gépi kódú utasítások fordulnak: feltételes vagy feltétel nélküli ugrások. A vezérlő utasítások az adott processzor lehetséges feltételvizsgálatai. Az i8080 esetén például CS (if Carry Set), PE (if Parity Even), 0=, 0<. Ezek ellentettjeit a NOT assembler operátorral állíthatjuk elő. A keletkező vezérlési szerkezet viszont a FORTH-belivel egyezik meg.
A gépi kódú szó végén minden esetben egy ugrásnak kell lennie arra címre, ahol a FORTH program folytatható. fig-FORTH-ban erre a PCIX szó szolgál.
A következő szabályokat kell betartani, amikor az assembler használatával hozunk létre szavakat:
Egy példa két szám összeadására:
CODE FOO
H POP
D POP
D DAD
H PUSH
PCIX
C;( n1 n2 --- n1+n2 )
( első szám a veremből HL-be)
( második szám a veremből DE-be)
( HL + DE )
( eredmény a verembe )
( ugrás NEXT-re )
( definíció vége )
Miról volt szó?
A 12. fejezet összefoglalása
A tanult szavak:
| PFA | ( ncím --- pcím ) | Egy szótárelem névmezőcíméből előállítja a paramző címét. |
| NFA | ( pcím --- ncím ) | A paramző címéből adja a névmező címét. |
| LFA | ( pcím --- lcím ) | A paramző címéből adja a láncmező címét. |
| CFA | (pcím --- kcím ) | A paramző címéből adja a kódmező címét. |
| LATEST | ( --- ncím ) | A láncoló szótár legfelső elemének névmezőcímét adja. |
| ID. | ( ncím --- ) | Annak a szótárelemnek a nevét írja ki, amelynek a névmezőcímét a vermen találta. |
| FORTH | ( --- ) | Szótárak. A nevükkel lehet őket kereső szótárrá tenni. |
| EDITOR | ( --- ) | Szótárak. A nevükkel lehet őket kereső szótárrá tenni. |
| ASSEMBLER | ( --- ) | Szótárak. A nevükkel lehet őket kereső szótárrá tenni. |
| ?TERMINAL | ( --- f ) | A visszaadott jelző akkor igaz, ha lenyomtak egy billentyűt a billentyűzeten. |
| DEFINITIONS | ( --- ) | A láncoló szótárat a kereső szótárhoz igazítja. |
| VOCABULARY | ( --- ) | Definiáló szó, így használjuk: VOCABULARY xxx Ezzel egy xxx nevű szótárat hoztunk létre. |
Példák
12.1. Írjuk meg a 12.1. szakaszban látott VLIST2-nek egy olyan változatát, amely bármely billentyű lenyomására abbahagyja a listázást!
: VLIST
80 OUT !
LATEST
BEGIN
OUT @
70 > IF
CR 0 OUT !
ENDIF
DUP ID.
SPACE SPACE
PFA LFA @
DUP 0=
?TERMINAL OR
UNTIL
DROP
;
12.2. Írassuk ki a szótárból azokat a neveket, amelyek nyitó zárójellel kezdődnek, mégpedig tabulálva, vagyis minden név után annyi szóközt írunk, hogy a kiírt karakterek száma 13-mal osztható legyen. Ha egy sorban 51 karakternél több van, a következő nevet új sorba írjuk.
: LIST(
80 OUT !
LATEST
BEGIN
DUP 1+
C@
40 = IF( --- )
( átlépjük a hosszúságbyte-ot )
( ez tehát a név első karaktere )
( ha nyitó zárójel )OUT @ 51 > IF
CR 0 OUT !
ENDIF
DUP ID.
13 OUT @ 13 MOD - SPACES
ENDIF
PFA LFA @
DUP 0=
UNTIL
DROP
;
Murphy egyik, nem a legpozitívabb életérzést sugalló törvénye szerint "minden program a rendelkezésre álló memória határáig nő." Ennek a valóságmagra épülő felismerésnek következményei már régóta foglalkoztatják a számítógépes szakembereket. A számukra legérdekesebb megoldás lehetővé teszi a nagy kapacitású háttértárak (többnyire mágneslemez) operatív térként való felhasználását. Ezt a módszert nevezik virtuális (látszólagos) memóriakezelésnek. Lényege a következő: az operatív tárban kijelölnek néhány meghatározott nagyságú területet (blokkpuffereket). A mágneslemez egységeken az információtárolás fizikai blokkokban történik (ezek mérete CP/M alatt 128 byte), ezek közül azonban egyszerre többet használnak egy egységként az adatforgalom során. Ezeket a logikailag összefüggő blokkokat logikai blokknak, a továbbiakban blokknak nevezzük. A blokkpufferek mérete megegyezik e blokkok méretével (ezek értéke általában 1024 byte). Az igazi érdekesség az adatátvitelt ellenőrző programban van. Ugyanis ez a program megjelöli a behozott blokkokat, és ha már az összes blokkpuffer betelt, de újabb blokk behozására van szükség, akkor azt a blokkot, amelyre legrégebben volt hivatkozás, visszaírja a mágneslemezegységre.
A fenti módszert a FORTH rendszerekben is alkalmazzák, a mikroszámítógépek többnyire 64 kbájtos memóriáját így több száz kilobájtra bővítik.
13.1. Alapok
Mire ide eljut, az Olvasó bizonyára rengeteg programot írt már. Nagy részüket kernyőre szerkesztette, hogy javíthassa őket (lásd. 2.5. fejezet).
A kernyők az ún. virtuális memóriában vannak. A virtuális memória a memória kiegészítése lemezes kernyőfile-lal. A virtuális szó itt látszólagosat jelent. A virtuális memória elnevezés azt tükrözi, hogy a virtuális memória blokkjait - bár adathordozón vannak - programozáskor úgy látjuk, mintha a memóriában lennének. Mégpedig azért látjuk úgy, mert a
BLOCK ( blokksorszám --- memóriacím )
szó gondoskodik róla, hogy a blokk, amelyre hivatkozunk, beolvasódjék a memóriába, ha eddig nem volt ott; a visszakapott címtől kezdve megtaláljuk a memóriában a blokk tartalmát.
A blokk itt az olvasás-írás fizikai egységét jelenti, általában (lemezről lévén szó) egy szektort.
A B/BUF rendszerkonstans megadja, hogy egy blokk hány byte hosszú. Ha feltesszük, hogy a virtuális memóriában szöveges adatok vannak, akkor így lehet az adott sorszámú blokk tartalmát kiíratni:
: BTYPE ( blokkszám --- )
BLOCK ( cím )
B/BUF (cím blokkhossz )
TYPE
;
A BTYPE szóval való nézelődés általában azt mutatja, hogy a blokkok egy-egy kernyőrészletet tartalmaznak; a 4. kernyő körül pedig a hibaüzenetek vannak (lásd 13.3. fejezet).
A BLOCK szó:
|
Az utóbbi esetben nem fordulunk a lemezhez; időt takarítunk meg anélkül, hogy erre programíráskor ügyelnünk kéne.
A virtuális memória blokkjait az interpreter a memória ún. blokkpuffereiben tartja. A BLOCK végignézi, hogy nincs-e a keresett blokk valamelyik blokkpufferben; ha megtalálta, akkor a blokkpuffer címét kapjuk, ha nem, akkor beolvas, de melyik pufferbe?
A válasz egyszerű, ha van üres blokkpuffer. A blokkpufferek azonban kevesen vannak a virtuális memória blokkjaihoz képest. Többnyire valamelyik foglalt blokkpuffert kell felülírni. Mi történik ilyenkor a puffért foglaló blokkal? Elvész a tartalma, vagy visszaíródik az adathordozóra?
Ezt mi magunk döntjük el. Ha nem teszünk semmit, a puffer tartalma nem íródik vissza, tehát csak olvassuk a virtuális memóriát. Azt, hogy egy adott blokkot majd vissza
is akarunk íratni, a blokkra való hivatkozás (BLOCK) után az
UPDATE ( --- )
szóval közöljük. Ettől az adott blokk "update-elt", vagyis módosított lesz. A szóhasználat egy kicsit félrevezető; a blokkpuffer tartalmát majd ezután fogjuk módosítani, az adathordozó blokkjait pedig még később, mikor a pufferre szükség van, vagy mikor minden módosított puffért visszaírunk.
Az UPDATE mindig arra a blokkra vonatkozik, amelyre a legutoljára hivatkoztunk a BLOCK szóval. |
(Ez egyszerűen úgy történik, hogy a BLOCK leteszi a PREV rendszerváltozóba a blokk számát, az UPDATE pedig ott találja meg).
Az összes módosított blokkot a
FLUSH ( --- )
szóval írathatjuk ki (például, mikor felállunk a gép mellől). Ha viszont vissza szeretnénk csinálni mindazt, amit a blokkpufferekben elkevertünk, az
EMPTY-BUFFERS ( --- )
után tiszta lappal indulhatunk; az interpreter üresnek tekinti az összes blokkpuffert, anélkül, hogy egyet is visszaírna (vagy a blokkpufferek tényleges tartalmát megváltoztatná. Az EMPTY-BUFFERS nem a puffereket törli, hanem a pufferek nyilvántartását írja át.)
Hogy a virtuális memóriában tárolt szövegeket ugyanúgy végrehajtathatjuk az interpreterrel, mint a billentyűzetről beírtakat, az (többek között) azon múlik, hogy az interpreternek mindig a WORD adja át a következő interpretálandó szót. A WORD a BLK rendszerváltozó tartalmától függően működik:
A WORD az IN rendszerváltozóban tartja nyilván, hogy hol tartott a parancspufferben vagy az éppen nyilvántartott blokkban. Egy szó beolvasása után az IN tartalma a szó hosszával növekszik, így a WORD legközelebb a következő szónál fog keresni.
A BLOCK, az UPDATE, a FLUSH és az EMPTY-BUFFERS a virtuális memóriakezelés alapjai. A fejezet további részei ezek használatát mutatják be FORTH alapszavak és egy szövegszerkesztő legalapvetőbb szavainak felépítésén keresztül.
13.2. Kernyőkezelő alapszavak
A kernyők mérete nem szokott a blokkhosszal egyezni; egy kernyő tárolásához általában több blokk szükséges. Hogy az adott FORTH-ban mennyi, azt a B/SCR rendszerkonstans adja. A fig-Forth esetében 8 blokk tesz ki egy kernyőt. A kernyők folyamatosan, egymás utáni sorszámú blokkokon terülnek el.
A kernyők, blokkok és a kernyősorok számozása 0-tól indul.
Nézzük meg, hogyan működik a (LINE) ( sorszám kernyőszám --- cím hossz ) alapszó, amely a megadott számú kernyő megadott számú sorának címét és hosszát adja. Tehát pl. a 0 2 (LINE) TYPE a 2. kernyő 0-adik, azaz legfelső sorát írja a képernyőre.
Ahhoz, hogy a keresett sor címét kiszámíthassuk (vagy egyáltalán biztosak lehessünk benne, hogy a memóriában van), tudnunk kell, melyik blokkba esik.
A sort tartalmazó kernyő első blokkjának száma: B/SCR*kernyőszám (mert a virtuális memóriában "kernyőszám" darab, egyenként B/SCR blokkból álló kernyő előzi meg).
A sort a kernyőn belül sorhossz*sorszám karakter előzi meg, tehát annyi blokk, amennyi ebbe belefér. Azaz: a
(sorhossz*sorszám)/blokkhossz
hányados adja meg, hogy a kernyő elejétől még hány blokk előzi meg a sorunkat tartalmazó blokkot, a maradék pedig, hogy a blokkon belül még hány karakter a sort. A sorhosszat a C/L rendszerkonstans adja.
Ezek után a program szövege:
: (LINE)
>R
C/L
B/BUF
*/MOD
( sorsz kernyősz --- cím hossz )
( sorsz )
( sorsz sorhossz )
( sorsz sorhossz blokkhossz )
( a maradék: a blokkon belül a sort )( megelőző karakterek száma )
( a hányados : a kernyő elejétől a sort)
( tartalmazó blokkot megelőző blokkok száma )R>
B/SCR *
+
BLOCK
+
C/L
;( kernyőszám vissza a viremből )
( a kernyő kezdőblokkja )
( a sort tartalmazó blokkot megelőző )
( blokkok száma )
( a sort tartalmazó blokk kezdőcíme )
( a sor kezdőcíme )
( sorhossz )
Ha jobban megnézzük, a (LINE) akkor is működik, ha a megadott sor nincs is a megadott kernyőn (pl. ha a 16 sorosak a kernyőink és a 0. kernyő 18. sorát keressük, ugyanazt kapjuk, mintha az 1. kernyő 2. sorát adtuk volna meg).
A kernyőket listázó LIST alapszó a
.LINE ( sorszám kernyőszám --- )
szóra épül; ez kiírja a megadott sort. A .LINE hívja az eddig még nem tanult
-TRAILING ( cím hossz --- cím hossz2 )
alapszót. A -TRAILING a címével és hosszával megadott karaktersorozat végéről levágja a szóközöket: úgy módosítja a hosszt, hogy a szóközből álló rész ne értődjék bele.
: .LINE ( sorszám kernyőszám --- )
(LINE)
-TRAILING ( hogy ne kelljen a felesleges )
TYPE ( szóközöket kivárni )
;
A FORTH editorok gyakran egy aktuális kernyő soraira vonatkozó műveletekből állnak. Az aktuális kernyő számát az SCR rendszerváltozó tartalmazza. Például a LIST (lásd. 2.5. fejezet) is aktuálissá teszi a kilistázott kernyőt, azaz a számát elhelyezi a SCR változóban.
: LIST ( kernyősz --- )
DECIMAL CR
DUP SCR ! ( akuálissá tettük a kernyőt )
." SCR # " . ( kiírjuk a kernyő számát )
16 0 DO ( jöhetnek a kernyősorok )
CR R 3 .R SPACE ( a sor száma )
R SCR @ .LINE ( a sor tartalma )
LOOP
CR
;
13.3. Szabványos hibakezelés
A FORTH alapszavak a hiba észlelésekor az ERROR szót indítják, amely a vermen várja a hiba sorszámát. Az ERROR tevékenysége a WARNING rendszerváltozó értékétől függően háromféle lehet:
Ha a WARNING 1, akkor ez azt jelenti, hogy van virtuális memória, ahonnan a hibaüzenet szövegét vehetjük. A hibaüzenetek a 4. kernyő elejétől kezdődnek; a hiba sorszáma mondja meg, hogy az innen számított hányadik sorban van az üzenet. A hibasorszám túlmutathat a 4. kernyő sorain, sőt, negatív is lehet. Az üzenet kiírása után az ERROR QUIT-tel tér vissza a legfelső szintre.
Ha a WARNING 0, a hibajelzés a virtuális memória használata nélkül, a hibaszám kiírásával történik. Például a 17. sorszámú hibajelzése:
MSG £ 17
(itt a MSG a message, üzenet szó rövidítése). A hiba kiírása után QUIT következik. A FORTH indítása után ez az alapértelmezett mód.
Ha a WARNING -1, akkor ún. "felhasználó által definiált megszakítás" történik; amíg nem definiálunk saját megszakítási eljárást, addig ilyenkor egyszerűen az ABORT szó hajtódik végre. Az ABORT ugyanazt teszi, amit a QUIT, és ezenkívül még
Saját megszakítási eljárást később tanulunk definiálni (lásd 14.4.3. fejezet).
Az ERROR mindhárom esetben kiüríti a vermet és beleteszi az IN és BLK rendszerváltozók tartalmát. A hibasorszámok jelentése megtalálható a függelékben.
Programjainkban többnyire a
?ERROR ( jelző --- hibasorszám )
szót használjuk hibajelzésre. A jelző azt jelzi, bekövetkezett-e a megadott sorszámú hiba. Az ?ERROR forrásszövege:
: ?ERROR ( jelző hibasorszám --- )
SWAP IF ERROR
ELSE DROP
ENDIF
;
Az érdeklődők, akik szívesen látnak sok példát az eddig tanultakra, olvassák el az ERROR és az ERROR-t alkotó legfontosabb szavak forrását is:
: ERROR
WARNING @
0 < IF
(ABORT)
ENDIF
( hibasorsz --- in blk )
( felhasználói megszakítás )( ide csak akkor jutunk, ha a WARNING )
( nem negatív )HERE COUNT
TYPE
." ?"
MESSAGE
SP!
IN @ BLK @
QUIT
;( kiírjuk a szót, amelyet a WORD)
( utoljára olvasott )
( ez a szó írja ki a hibaüzenetet )
( ez a szó kiűríti a vermet )
: (ABORT)
ABORT
;
( felhasználói megszakítás )
A hibaüzenetet kiíró szó a MESSAGE:
: MESSAGE
WARNING @
IF
-DUP IF
4 .LINE SPACE
ENDIF
ELSE
." MSG £ " .
ENDIF
;( hibasorsz --- )
( ha WARNING nem 0 )
( ha a hibasorsz nem 0 )
( ha WARNING 0 )
13.4. Szemelvények egy editorból
A fig-FORTH-hoz mellékelt, William F. Ragsdale alkotta editorból fogunk egy részt megismerni; annyit, amennyi kényelmetlenül, de elég a kernyők karbantartásához. Az editor ismertetőjét a C függelékben lehet megtalálni. Itt főleg a szavak felépítésével, forrásszövegével foglalkozunk.
Először is, az editor szavait tartalmazó szótár létrehozása a feladatunk.
VOCABULARY EDITOR IMMEDIATE
Ez lesz a kereső és láncoló szótár:
EDITOR DEFINITIONS
Az editor szavainak írásakor tizenhatos számrendszerben dolgozunk:
HEX
A sorok szövegének átmeneti tárolására a pad szolgál. Első szavunk, a TEXT beolvassa egy sor szövegét a befolyamból és FORTH-füzér formájában a padbe teszi. A vermen a szöveg határolókarakterét várja.
: TEXT
HERE C/L 1+
BLANKS
WORD( c --- )
( a szótár feletti rész )
( feltöltése szóközökkel )
( a szöveg beolvasása az adott )( határolókarakterekkel, átvisszük a PAD-be )
( a szöveget; a CMOVE-nak adandó adatok: )HERE
PAD
C/L 1+
CMOVE
;( honnan )
( hova )
( hányat )
A következő építőkövünk a LINE, amely megmondja, hogy az aktuális kernyő melyik sora hol van. Egy kernyő attól aktuális, hogy a száma az SCR változóban van.
A LINE ellenőrzi, hogy a kapott sorszám 0 és 15 közé esik-e. Eközben persze felteszi, hogy egy kernyő 16 soros.
: LINE
DUP
FFF0 AND( sorszám --- cím )
( egy szám akkor esik 0 és 15 közé )( ha a hexadecimális alakja egyjegyű )
( ekkor ez a bitenkénti ÉS 0-át ad )17 ?ERROR
SCR @
(LINE)
DROP
;( ha nem 0-át kapunk "elszáll" )
( a program )
( sor címe )
( és hossza )
Erre épül a
-MOVE ( cím sorsz --- )
amely a megadott címről egy sort másol be az aktuális kernyő megadott számú sorába:
: -MOVE ( cím sorsz --- )
LINE ( a cím, ahova mozgatunk )
C/L CMOVE
UPDATE
;
Az editor első "felhasználói szava" az E (erase, azaz törlés), amely szóközökkel írja felül a megadott számú sort:
: E ( sorsz --- )
LINE ( a törlendő sor címe )
C/L BLANKS
UPDATE
;
Az S (spread; beékelés) szóval a megadott sort úgy üríthetjük ki, hogy tartalmát az alatta levő sorokéval együtt lejjebb toljuk és a helyét szóközökkel töltjük fel. A kernyő utolsó sora elvész.
: S
DUP 1-
0E
DO
R LINE
R 1+
-MOVE
-1 +LOOP
E
;( sorsz --- )
( az első sor, amelyet nem kell )
( mozgatni )
( az utolsó sor, amelyet mozgatunk )
( a ciklus hátulról előre halad )
( mozgatandó sor )
( ebbe a sorba írjuk )
( a vermen a sorszám egy példánya )
( maradt )
( a sor törlése szóközökkel )
A H (hold; megőriz) bemásolja az aktuális kernyő megadott számú sorát a padbe, FORTH-füzér formájában.
: H
LINE
PAD 1+
C/L
DUP PAD C!
CMOVE
;( sorsz --- )
( a cím, ahonnan másolunk )
( ide másolunk )
( hosszuságbyte a pad elejére )
A D (delete; törlés) szóval kiirtjuk a megadott számú sort; az alatta levő kernyő- sorok eggyel feljebb vándorolnak, az utolsó sor szóközökkel íródik felül. A törölt sor megmarad a pad-ben.
: D
DUP H
0F
DUP ROT
DO
R 1+
LINE
R -MOVE
LOOP
E
;( sorsz --- )
( a sor a pad-be kerül )
( utolsó kernyősor száma )
( a verem tetején a sorsz )
( ez a sor megy feljebb )
( a vermen a 0F egy példánya maradt )
( az utolsó sor törlése szóközökkel )
Az R (replace; helyettesítés) a megadott kernyősort felülírja a padben tárolt szöveggel.
: R ( sorsz --- )
PAD 1+ SWAP -MOVE ;
A P (put; elhelyez) szóval felülírjuk a megadott kernyősort azzal a szöveggel, amelyet a P után írunk (sor végéig):
: P
1
TEXT
R
;( sorsz --- )
( 1 kódú karakter nincs a billentyűzeten )
( a TEXT a sor végéig fog olvasni )
( a TEXT a padbe olvas, az R innen másol )
Az I (insert; beszúrás) szó az R-hez hasonlóan a megadott sorba írja a padben levő szöveget, de a sort felülírás előtt az alatta levőkkel együtt lejjebb tolja.
: I ( sorsz --- )
DUP S R ;
Még egy szó, amely az egész kernyőt kezeli: a CLEAR ( kernyőszám --- ), ez törli a megadott kernyőt.
: CLEAR
SCR !
10 0 DO
FORTH
R
EDITOR
E
LOOP
;( sorsz --- )
( a kernyőt aktuálissá tesszük )
( 16 sor )
( az R szót a FORTH szótárából )
( kell venni )
Miról volt szó?
A 13. fejezet összefoglalása
A tanult szavak:
| BLOCK | ( n --- cím ) | Az n-edik blokkot tartalmazó blokkpuffer memóriacímét adja. Ha a blokk nincs a memóriában, akkor beolvassa abba a blokkpufferbe, amelyre a legrégebben hivatkoztunk utoljára. Ha módosí-tott puffért írt felül, akkor ennek tartalmát előbb visszaírja a virtuális memóriába. |
| UPDATE | ( --- ) | Módosítottnak jelöli azt a blokkot, amelyre a BLOCK szóval utoljára hivatkoztunk (a blokk számát a PREV rendszerváltozóban találja). Ez azt jelenti, hogy az interpreter a blokkot visszaírja a virtuális memóriába, mielőtt az őt tartalmazó blokkpuffert, másra használná. |
| FLUSH | ( --- ) | Kiírja a virtuális memóriába a módosított blokkokat. |
| EMPTY-BUFFERS | ( --- ) | A blokkpufferek nyilvántartását változtatja meg; valamennyit üresnek tekinti (anélkül, hogy a módosított blokkokat visszaírná a virtuális memóriába). |
| PREV | ( --- cím ) | Ebben a rendszerváltozóban őrződik annak a blokknak a száma, amelyre a BLOCK utoljára hivatkozott. |
| B/BUF | ( --- n ) | Rendszerkonstans; a blokkhossz byte-okban. |
A WORD által használt rendszerváltozók:
| BLK | ( --- cím ) | A blokk száma, ahonnan a WORD a befolyamot olvassa. Ha 0, akkor a befolyam a terminálról érkezik, a WORD a parancspufferből olvas. |
| TIB | ( --- cím ) | A parancspuffer címét tartalmazó rendszerváltozó. |
| IN | ( --- cím ) | Azt mutatja, hogy a blokkpufferen vagy a parancspufferen belül a WORD hol kezd el legközelebb olvasni. |
Kernyőkezelés:
| B/SCR | ( --- n ) | Rendszerkonstans: az egy kernyőben levő blokkok száma. |
| C/L | ( --- n ) | Rendszerkonstans: a kernyő sorainak hossza. |
| (LINE) | ( sorsz kernyő --- cím hossz ) | A megadott számú kernyő megadott sorának memóriacímét és hosszát adja. |
| .LINE | ( sorsz kernyő --- ) | Kiírja a megadott sort. |
| SCR | ( --- cím ) | Rendszerváltozó; az editorok használják az aktuális kernyő számának tárolására. |
A hibakezelés szavai:
| ERROR | ( hibasz --- blk in ) | Az adott számú hiba észlelésekor végrehajtandó eljárás. Ha a WARNING változó értéke 1, akkor a virtuális memória 4. kernyőjének elejétől számított "hibasorszám"-adik sort írja ki hibajelzésként. (A sorszám lehet negatív is, vagy túlmutathat a 4. kernyőn.) Ha a WARNING 0, akkor a hibát csak a számával azonosítja a hibaüzenet. Ha a WARNING -1, akkor az (ABORT) szó hajtódik végre, amelyet magunk is módosíthatunk (lásd 14.4.3. fejezet). A BLK és IN változók tartalmát kapjuk a vermen, hogy a hibát azonosíthassuk. A hibakezelés QUIT-tel zárul. |
| (ABORT) | "Felhasználó által definiált megszakítás", lásd 14.4.3. fejezet. Ha nem definiálunk megszakítási eljárást, az ABORT szót hajtja végre. |
|
| WARNING | ( --- cím ) | Rendszerváltozó; a hibakezelés módjáról tartalmaz információt (ld. ERROR). |
| ?ERROR | ( f hibasz --- ) | Ha f igaz, akkor a megadott sorszámú hibára indít hibakezelési eljárást. |
| MESSAGE | ( n --- ) | A WARNING értékének megfelelően kiírja a megadott sorszámhoz a hibaüzenetet: ha a WARNING 0, a sorszámot, ha nem, a 4. kernyő 0. sorától számított n-edik sort. |
Egyéb szavak:
| -TRAILING | ( cím hossz --- cím hossz2) | A címével és hosszával megadott füzér hosszát úgy változtatja meg, hogy ne tartalmazza a szöveg végén levő szóközöket. |
| ABORT | Kiüríti a vermeket, a kereső és a láncoló szótárat FORTH-ra, a konverziók alapszámát 10-re állítja. Az éppen interpretált sort vagy kernyőt megszakítva új parancssort vár. |
|
| SP! | A verem kiürítése. |
Az editor szavait lásd a C függelékben.
Példák
A feladatmegoldások kipróbálása előtt érdemes a virtuális memóriáról félretenni egy má?solatot. Az ember így bátrabban kísérletezik.
13.1. (Leo Brodie után, szabadon). A virtuális memória 25. kernyőjében vannak a hölgyek, minden sorban egy.
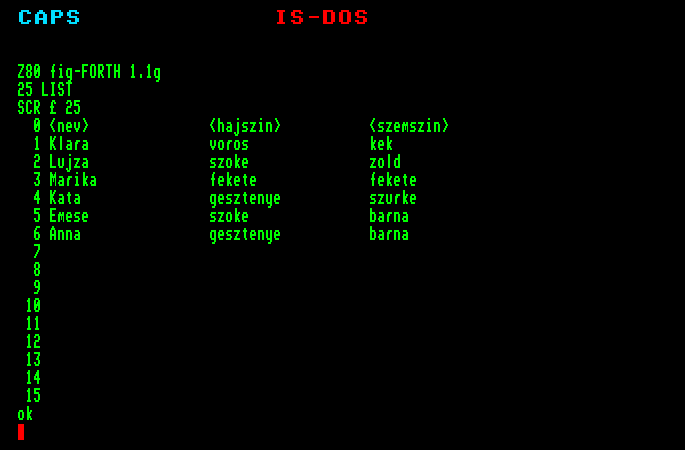
A sor elején a hölgy neve,a 21. karaktertől kezdve a hajszíne,a a 40. karaktertől kezdve a szemszíne (tehát mind a három mező 20 karakter hosszú ). Írjunk egy LEVEL ( n --- ) szót, amely a sor számát várja a vermen, és kiírja a következő levelet:
Draga <név> !
Lazba jovok, ha eszembe jut <szemszín>
szemed, <hajszín> hajad. Gyere holnap,
vegyel fel <szemszin> ruhat, igy ervenyesul
szep szemed
Leo
Például:
Előfordulhat, hogy a levél írója némileg állhatatlan: megváltoztatja a szemszín kezdőpozícióját, beljebb akarja kezdeni a levél sorait, vagy nem a 25. kernyőt akarja használni. Ezért a név, hajszín és szemszín kiíratását kiemeljük egy-egy szóba; ezekből is külön szóba tesszük a hölgyet tartalmazó sor kezdőcímét. Így könnyű lesz változtatni, ha valaki meggondolja magát.
0 VARIABLE LIN
: SOR ( --- cim ) LIN @ 25 (LINE) DROP ;
: .NEV SOR 20 -TRAILING TYPE ;
: .HAJ SOR 20 + 20 -TRAILING TYPE ;
: .SZEM SOR 40 + 20 -TRAILING TYPE ;
: UJSOR CR 10 SPACES ;A főprogramnak a levél feltöltésén kívül a LIN változó feltöltéséről kell gondoskodnia:
: LEVEL ( sorsz --- )
LIN !
CR UJSOR 5 SPACES
." Draga " .NEV ." !"
CR UJSOR ." Lazba jovok, ha eszembe jut ".SZEM
UJSOR ." szemed, " .HAJ ." hajad. Gyere holnap,"
UJSOR ." vegyel fel " .SZEM ." ruhat, igy ervenyesul"
UJSOR ." szep szemed."
UJSOR 7 SPACES ." Leo" CR
;
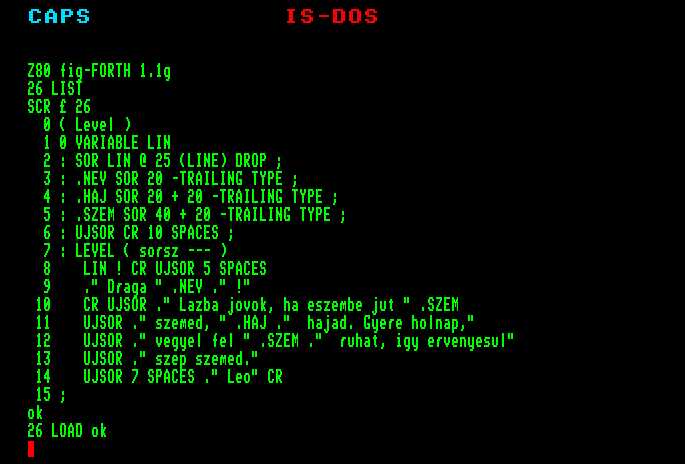
13.2. Hogyan írnánk meg az INDEX ( tól ig --- ) szót, amely két megadott határ között kilistázza a kernyők 0. sorát (a "tól" és "ig" számú kernyőt is beleértve). A listázás maradjon abba, ha a billentyűzeten lenyomnak egy billentyűt.
: INDEX ( tol ig --- )
1+ SWAP DO
CR 0 R (LINE) -TRAILING TYPE
?TERMINAL IF LEAVE ENDIF
LOOP
;
13.3. Mi lehet a -TRAILING forrása?
A FIG megoldás:
: -TRAILING
DUP 0 DO
2DUP +
1- C@
BL - IF
LEAVE
ELSE
1-
ENDIF
LOOP
;( cím hossz --- cím hossz1 )
( a vermen: cím hossz )
( a füzér utáni cím )
( a füzér utolsó karaktere )
( ha nem szóköz, )
( készen vagyunk a levágással )
( ha szóköz, )
( tovább rövidítünk )
14. A szótár és a címinterpreter
14.1. Kettőspontos szavak
A FORTH programozás legalapvetőbb mozzanata: már meglevő szavakra új, célunkhoz közelebb vivő szavakat építeni, hogy később ezekre tovább építhessünk. Az ilyen, más szavakból összeállított szavak mutatókat tartalmaznak az őket alkotó szavakra; működésük lényege az őket alkotó szavak végrehajtása a mutatók alapján. A mutatóknak ezt a fajta kiértékelését egy pici, gyors programocska, az ún. belső interpreter vagy címinterpreter végzi. (Sok múlik azon, hogy a címinterpreter gyors legyen, hiszen a FORTH szavak végrehajtásakor nagyrészt ő fut.)
Ha egy szódefiníciót kettősponttal kezdünk, akkor ezzel azt közöljük, hogy az új szó régebbi szavakból fog felépülni. így, mivel szótári szavak működését a kódmező tartalma határozza meg,
valamennyi, kettősponttal definiált szó kódmezőjében a címinterpreter címe van. |
A mutatók, amelyeken majd a címinterpreternek tovább kell mennie, a kettőspontos szavak paramzőjében vannak; ezek a szót alkotó szavak kódmezőcímei.
Példa a kettőspontos definícióra:
: .PAD PAD C@ . ;
A létrehozott szótárelem:
névmező: .PAD láncmező: előző szó névmezőcíme kódmező: címinterpreter címe paramező: PAD kódmezőcíme C@ kódmezőcíme . kódmezőcíme ;S kódmezőcíme
A kettőspontos szavak paramzőjében az utolsó kódmezőcím a ;S szóé; ez a szó küldi vissza a címinterpretert a hívó szóba. (A ;S szóval a 2.5. szakaszban már találkoztunk: hatására befejeződik a kernyő interpretálása.) A ;S kódmezőcímét a ; szó bűvöli bele az új szó paramzőjébe.
14.2. Primitívák
A FORTH szavak jó részét tehát a címinterpreter működteti: sorra elmegy a címekre, ahová a szó paramzőjében talált mutatók küldik. Ott esetleg újabb mutatókat talál, amelyeken továbbmehet. A sok küldözgetésnek egyszer vége kell, hogy szakadjon: előbb-utóbb valamelyik hívott szónak ki kell rukkolnia vele, hogy mit is kell csinálni. Ezeket a végső szavakat, amelyek tehát nem más szavakra utaló mutatókat, hanem végrehajtható gépi kódokat tartalmaznak, primitíváknak nevezzük. A primitívák kódmezőjében a mutató a primitiva saját paramzőjébe mutat. A paramzőben gépi kód van, ez hajtódik végre, mikor a primitívát futtatjuk. A primitívák létezése alapja az alábbi kijelentésnek:
Amit egy gépen lehet, azt a rajta futó FORTH-ban is lehet. |
A primitívákat arra is felhasználhatjuk, hogy az operációs rendszer rutinjait hívjuk vele, így beépíthetjük az adott operációs rendszer file-kezelő rendszerét vagy bármely más szolgáltatását. Ezt persze egy gépfüggetlen CP/M program készítője nem teheti meg a létező összes géptípusra, ezt nekünk kellene megtennünk az általunk használt gépen. Ha jobban ki akarjuk használni az ENTERPRISE operációs rendszerének képességeit, a gépspecifikus IS-FORTH a jobb választás.
Primitívák létrehozására az ASSEMBLER szótár szavai szolgálnak, ezek teszik lehetővé, hogy gépi kódok helyett mnemonikokat használjunk, hogy az assembler programozásban is a rendelkezésünkre álljanak a vezérlési struktúrák stb.
14.3. Változók és konstansok
Valamennyi változó ugyanúgy működik: a veremre teszi azt a címet, ahol a változó értéke van. így talán nem meglepő, hogy változóink kódmezői mind ugyanazt a címet tartalmazzák. Annál meglepőbb, hogy a rendszerváltozóké (BLK, IN, DPL stb.) nem ugyanaz. Az ilyen különleges változók:
| HLD | R# | CSP | FLD | DPL |
| BASE | STATE | CURRENT | CONTEXT | SCR |
| OUT | IN | BLK | VOC-LINK | DP |
| FENCE | WARNING | WIDTH | TIB | R0 |
| S0 |
A rendszerváltozók (USER, ejtsd: júzer változók) egy táblázatban vannak. A táblázat egy részét a COLD (hidegindítás) szó feltölti a kezdeti értékekkel, amelyeket a rendszer az ún. "betöltési paraméterek területén" tárol (az interpreter működéséhez szükséges egyéb fontos adatokkal együtt. Így áll vissza a COLD után - többek között - a szótár eredeti állapota, ami többnyire definícióink törlését jelenti.
User változókat a USER szóval definiálhatunk. Leírása megtalálható a fejezet végén, bár ennek "mezei" felhasználói programok írói számára nincs nagy jelentősége. A USER változók használata - mint láttuk - ugyanaz, mint a közönséges változóké, csak a kulisszák mögött van eltérés.
A konstansok kódmezője is egyforma: mind arra a kódra mutat, amely a paramző tartalmát a veremre teszi. Így egy szótári szó kódmezőjéből megállapíthatjuk, hogy kettőspontos szóról, primitíváról vagy egyébről van szó.
14.4. Trükkös futtatások
Egy szó végrehajtásának szokásos módja: a nevével hivatkozunk rá, az interpreter majd ebből tudja, mit kell vele tennie. Végre lehet azonban egy szót a kódcíme alapján is hajtatni, végső soron egyébként az interpreter is ezt teszi. Hogy az ezzel kapcsolatos mókákat kiélvezhessük, legelőször is tudnunk kell, hogyan állíthatjuk elő egy szótári szó kódmező- (vagy bármilyen egyéb) címét. Erre való a
-FIND
szó, amely a befolyam következő szavát megpróbálja a szótárban megkeresni. Ha megtalálta, visszaadja a szó paramzőcímét, a névmezőből a hosszúságbyte-ot és egy igaz jelzőt. Ha nem, csak egy hamis jelzőt ad.
14.4.1. Az EXECUTE
Az
EXECUTE ( kódmezőcím --- )
az a szó, amely végrehajtja a vermen megadott kódmezőcímű másik szót.
Tegyük fel, hogy a szótárnak csak az ilyen vagy amolyan tulajdonságú szavait (a primitívákat, a USER változókat stb.) szeretnénk kiíratni. Az ilyesfajta listákat készítő programok szerkezete teljesen egyforma - mind végigmegy a szótárláncon, és minden szóról eldönti, ki kell-e írnia azt a szót vagy nem. Ez a döntés az egyetlen részlet, amely változik, mikor primitívák helyett (mondjuk) konstansokat akarunk listázni. Tegyük hát ezt a döntést egy külön "döntő szóba", s a listázóprogramnak majd megadjuk, hogy melyik döntő szó alapján listázzon.
Feltesszük, hogy a döntő szó egy paramzőcímet vár a vermen és egy jelzőt ad, amely a kiíratandó szavaknál igaz, a többieknél hamis lesz. Például a zárójellel kezdődő szavak kiíratásához a döntő szó:
: (SZAVAK ( pmcím --- f )
NFA ( névmezőcím )
1+ C@ ( a név első karaktere )
40 =
;
Megírjuk a szólistázó EZEK-A programot, amely után a befolyamban csak megadjuk majd a döntő szó nevét, valahogy így:
EZEK-A (SZAVAK
Megkönnyítjük a dolgunkat, ha a döntő szó paramzőcímének tárolására egy változót vezetünk be:
0 VARIABLE DONTO-PMC
a ugyanis a DONTO-PMC már a döntő szó paramzőcímét tartalmazza, akkor így dönthetjük el egy szóról, hogy kiírjuk-e:
: KELL-E ( pmcím --- f )
DONTO-PMC @ CFA
EXECUTE ( végrehajtjuk a "döntő" szót )
;
Egy szó kiírása
: KIIR ( pmcím --- )
OUT @ 35 > ( a sorok ne legyenek túl hosszúak )
IF CR 0 OUT !
ENDIF
NFA ID.
;
Maga a program:
: EZEK-A
80 OUT !
-FIND 0= 5 ?ERROR
DROP DONTO-PMC !
LATEST
BEGIN
PFA DUP DUP
KELL-E
IF KIIR
ELSE DROP
ENDIF
LFA @
DUP 0= UNTIL
DROP CR
;( --- )
( a KIIR rögtön új sort kezd )
( "elszáll", ha nincs döntő szó )
( legfelső szó névmezőcíme )
( következő szó névmezőcíme )
( pmcím pmcím pmcím )
( pmcím pmcím jelző )
( továbblépünk )
14.4.2. Változatok a -FIND-re
Tegyük fel, hogy az előbbi EZEK-A szóhoz egy VALTOZOK ( pmc --- f ) döntő szót akarunk írni, amely akkor ad igaz jelzőt, ha a kapott paramzőcím egy (VARIABLE-val definiált) változóé.
Tudjuk, hogy a változók kódmezői mind ugyanazt a címet tartalmazzák, csak éppen nem tudjuk, melyik ez a cím. De megtudhatjuk, elég hozzá egyetlenegy változó:
0 VARIABLE A
Ennek kódmezőjében a
-FIND A DROP DROP CFA @
cím van; ha már a veremre bűvöltük valahogy, mindjárt be is építhetjük egy konstansba, hogy használni tudjuk:
CONSTANT A-CIM
Így már könnyű dolgunk van:
: VALTOZOK ( pmcím --- f )
CFA @ A-CIM = ;
Az A-CIM konstans bevezetését a ' szó használatával úszhatjuk meg. A ' a befolyam következő szavának a paramzőcímét adja, lényegében tehát ugyanúgy működik, mint a -FIND, csak:
Ha a ' szót definícióban használjuk, akkor a definíció szövegéből szedi a szót, amelynek paramzőcímét keresi; a megtalált paramzőcímét pedig befordítja a definícióba. |
(Mindezt pontosabban is megértjük majd a 16. fejezetben.)
Így a definíció pillanatában eldől, hogy van-e ilyen szó; a ' nem is ad visszajelzőt (egyébként hosszúságbyte-ot sem). Ha nem szótári szót kerestetünk vele, egyszerűen elszáll (a 13.3. szakaszban megismert ERROR szót hívja).
A VALTOZOK másik változata tehát, amelyhez az A-CIM konstansot nem kell bevezetni:
: VALTOZOK (pmcím --- f )
CFA @
' A CFA @
=
;
Ha nem a szótár tetejétől kezdve akarunk keresni, vagy nem a befolyamban akarjuk megadni a keresendő szó nevét, akkor a
(FIND)
szót használhatjuk, amelynek leírása a függelékben megtalálható.
14.4.3. A felhasználó által definiált megszakítás
A címbeli fogalommal a 13.3. szakaszban, a szabványos hibakezelésnél találkoztunk. Ha a WARNING változó értéke -1, akkor az ERROR az (ABORT) nevű szóra adja a vezérlést, amely - ha nem teszünk semmit - az ABORT szót hajtja végre. Már tudjuk, ez azt jelenti, hogy az (ABORT) paramzőjében az ABORT kódmezőcíme van. Ha más megszakítási eljárást akarunk, akkor erre egy szót írunk, pl.:
: SAJAT CR ." En mar nemsokara bucsuzom" ABORT ;
és ennek a kódmezőcímét helyezzük el az (ABORT) paramzőjében:
' SAJAT CFA ' (ABORT) !
Miról volt szó?
A 14. fejezet összefoglalása
A tanult szavak:
| -FIND | ( --- pmc hosszúságbyte igazjelző ) vagy ( --- hamisjelző ) |
Beolvassa a befolyam következő szavát (szóközig), és megkeresi a szótárban. Ha megtalálta, a szó paramzőcímét, a névmezőjéből a hosszúságbyte-ot és egy igaz jelzőt ad. Ha nem, csak egy hamis jelzőt kapunk. |
| ' | ( --- pmc ) | A befolyam következő szavának paramzőcímét adja. Definícióban a keresendő szót a definíció szövegéből veszi, a címet befordítja a definícióba. |
| EXECUTE | ( kódmezőcím --- ) | Végrehajtja azt a szót, amelynek kód mezőcímét a vermen megadtuk. |
| USER | ( relcím --- ) | Definiáló szó. A vele definiált ún. USER változók egy táblázatban helyezkednek el; a definiáláskor megadott relatív cím a USER változó értékének a táblázaton belüli helyét adja meg. Ez a relatív cím van a USER változók paramzőjében. A USER változókat ugyanúgy használjuk, mint a VARIABLE szóval definiáltakat; ezek is a változó címét teszik a veremre. |
| ;S | ( --- ) | Az a szó, amelynek végrehajtása befejezi a kettőspontos szavak futását. |
Példák
14.1. Készítsünk egy listát a USER változókról! (Egy ilyen lista található a fejezet elején.)
: USEREK ( pmcím --- f )
CFA @
' IN CFA @ =
;Ezek után a lista kiírása:
EZEK-A USEREK
14.2. Készítsünk listát a primitívákról!
Hasonlóan az előző feladathoz csak a döntő szót írjuk meg. A primitívákat onnan lehet megismerni, hogy a kódmezőjükben a mutató a saját paramezőjükre mutat:
: PRIMITIVAK ( pmcím --- f )
DUP CFA @ = ;Ezek után a lista kiírása:
EZEK-A PRIMITIVAK
14.3. Írjunk egy RAJZOL ( --- ) szót, amellyel függvények grafikonjait rajzolhatjuk meg! A függvények ( x --- y ) veremhatású szavak; ha egy ilyen szó nevét a RAJZOL után megadjuk, akkor a RAJZOL megmutatja nekünk a függvényt a -10 és 10 pontok között. Például:
RAJZOL 2/
vagy
: F1 DUP * 6 / 6 - MINUS ;
RAJZOL F1
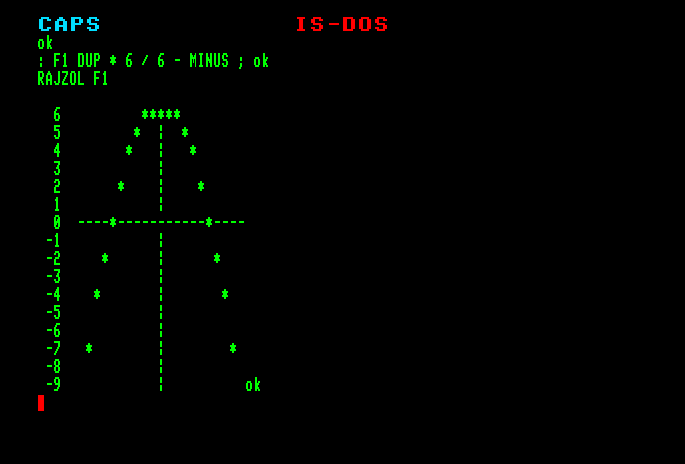
Hogy kényelmesebb legyen az életünk, a függvény kódmezőcíme számára létrehozunk egy változót:
0 VARIABLE KMCI
Ha a KMCI már a függvény kódmezőcímét tartalmazza, akkor egy függvényhívás ilyen alakú:
: FHIV ( n1 --- n2 )
KMCI @ EXECUTE ;A függvényrajzolás a -10 és 10 között felvett minimális és maximális érték között történik. A grafikon egy sorát író program (a vermen azt várja, hogy milyen függvényértéknek felel meg a sor):
: 1SOR ( n --- )
CR DUP 3 .R 2 SPACES
11 -10 DO
R FHIV OVER =
IF 42 ( ha a fv.érték a sornak megfelelő )
ELSE
DUP 0= IF ( ha a 0. sorban vagyunk, )
45 ( vízszintes vonal )
ELSE R 0= IF (ha a 0. oszlopban vagyunk, )
124 ( függőleges vonal )
ELSE BL ENDIF
ENDIF
ENDIF
EMIT
LOOP DROP
;A főprogram feladata, hogy a minimális és maximális függvényérték közöti értékekre az 1SOR-t lefuttassa.
: RAJZOL ( --- )
CR -FIND
IF
DROP CFA KMCI !
0 DUP ( a min. és max. kezdőértéke )
11 -10 DO
R FHIV MAX
SWAP R FHIV MIN SWAP
LOOP
DO R 1SOR -1 +LOOP
ELSE ." Nincs ilyen szo!"
ENDIF
;
15. Saját gyártmányú definiáló szavak
Aki kevesli a FORTH alapszavak nyújtotta adatstruktúra választékot, azaz nemcsak egyszavas változókat és konstansokat definiáló szavakra vágyik, hanem vektort, mátrixot, dupla- vagy triplaszavas változót definiáló szavakra is, az kénytelen ezeket maga megírni. Tegyük fel például, hogy valaki lépten-nyomon 2 byte-os elemekből álló vektorokat használ. Az lenne jó, ha a vektorok valahogy automatikusan tudhatnák magukról, hogy mit kell tenniük, ha valamelyik elemükhöz hozzá akarunk férni.
A változókról és konstansokról tudjuk, hogy az értéküket a paramzőjükben tárolják. Nem lesz ez másképp a saját kitalációjú adatszerkezetekkel sem; a vektor elemeit is a vektorként definiált szó paramzőjében tartjuk. A vektorok pedig, hasonlóan a változók-hoz és konstansokhoz, egyformán működnek: valamennyi vektor kódmezőjéből ugyanoda mutat a kódmutató.
A definiáló szavak két eljárást tartalmaznak:
Amit definiáláskor kell tenni; lényegében a definiálandó szó paramzőjének kialakítása.
Változóknál, konstansoknál ez annyi, hogy a vermen megadott értéket a paramzőben tároljuk; a szótármutatót kettővel növeljük, hogy a tárolt 16 bites érték "védett" területen legyen.
Amit majd a definiált szavak tesznek: annak a kódnak a cselekménye, ahová majd a definiáló szóval létrehozott szavak kódmezőjében a mutatók mutatnak.
Változóknál ez annyi, hogy a paramző címét a veremre tesszük; konstansoknál pedig a paramző 16 bites tartalmát tesszük a veremre.
Ennek megfelelően a definiáló szavakat két felvonásban írjuk meg:
<BUILDS
(első felvonás: amit definiáláskor teszünk).
A szótármutató definiáláskor a definiálandó szó paramzőjének elejére mutat. |
DOES>
(második felvonás: ezt teszik a definiált szavak).
A DOES> utáni eljárás elején a definiált szó paramzőjének címe van a vermen. |
Írjunk például duplaszavas konstanst definiáló 2CONSTANT ( d --- ) szót! A definiáláskor a vermen várt érték a konstans értéke; ezt teszi majd a veremre a definiált szó. Tehát pl. a
3.1415926 2CONSTANT PI
egy PI nevű duplaszavas konstanst fog létrehozni:
PI D.
Lássuk a 2CONSTANT definícióját:
: 2CONSTANT
<BUILDS
HERE 2!
4 ALLOT
DOES>
2@
;( d --- )
( tároljuk a paramezőben a duplaszót )
( arrébb húzzuk a szótárpointert )
( a vermen a paramezőcím )
Térjünk rá a vektorokra! Megírjuk a VECTOR ( n --- ) definiáló szót, amely a vektor (16 bites) elemeinek számát várja a vermen; a vektor paramzőjében minden elem számára lefoglal 2 byte-ot. A VECTOR-ral definiált szavak pedig a veremre tett indexből kiszámítják a megadott indexű elem címét és visszaadják a vermen.
: VECTOR ( n --- )
<BUILDS
2* ALLOT
DOES> ( a vermen: index, paramezőcím )
SWAP
1- ( 1-től kezdődnek az idexek, nem 0-tól )
2* +
;
Ezzel így definiálunk például egy 10-elemű vektort:
10 VECTOR TIZ
A TIZ szó veremhatása: ( index --- elemcím ). Az így definiált vektorok remekül működnek, amíg jó indexeket adunk nekik; baj csak akkor van, ha kicsit félreindexelünk, ekkor ugyanis könnyen beletörölhetünk a szótárba. Az elővigyázatosság azt diktálja, hogy a vektorok ellenőrizzék a kapott indexet és álljanak le, ha az nem felel meg a méretezésüknek. Ehhez a vektor méretét is tárolnunk kell valahol, s mivel máshol nemigen tarthatjuk, erre is a paramzőt kell használnunk. Ilyenkor, amikor az adatszerkezet paramzője többféle adatot is tartalmaz, legjobb a paramzőt a szó megírása előtt megtervezni (sőt, le is írni, mert programíráskor már más bajunk van).

Ezután hozzálátunk a programíráshoz:
: VECTOR
<BUILDS
DUP ,
2* ALLOT
DOES>
>R
( tároljuk a vektor elemszámát )
( helyfoglalás az elemek számára )
( félretesszük a paramező címét, )
( a vermen az index marad )DUP 1 < OVER R @ > OR
IF ." Rossz index!" QUIT
ELSE 2 * R> +
ENDIF
;
Karakterfüzér-konstans létrehozása
Példánk fordításidőben a TEXT Szót (ld. 13.4. pont) felhasználva beolvas egy karakterfüzért a bemeneti pufferből a PAD-re, ezt eltárolja DP-től, majd ALLOT-tal helyet foglal le neki. A füzér hossza DP-re, a füzér DP+1-re kerül. Futásidőben a DOES> utáni rész ezt a fűzért kiírja.
: $CONSTANT
<BUILDS
13 TEXT
PAD C@
1+ DUP
PAD HERE
ROT CMOVE
ALLOT
DOES>
COUNT TYPE
;
( CR-ig beolvassa a füzért)
( PAD-re a bemeneti pufferből)
( hossz. )
( hossz+1 hossz+1 )
( hossz+1 hossz+1 PAD DP )
( hossz+1 byte másolása DP-re )
( DP növelése hossz+1-gyel )
Használata:
$CONSTANT WELC Hello, en vagyok a szamitogep!
WELC
Végül írunk egy olyan definiáló szót, amellyel szövegkiíró szavakat hozhatunk létre. A szó neve .TEXT lesz; definiáláskor kell neki megadni a kiírandó szó nevét. Például a
.TEXT PLD SZAMRENDSZEREM KETTES, EN VAGYOK A TETTES
sorral a PLD ( --- ) szót definiáltuk; ez kiírja a szöveget, amelyet definiáláskor megadtunk neki (a sor végéig).
A kiírandó szöveget FORTH-füzér formájában a kiíró szó paramzőjében fogjuk tartani:
: .TEXT
<BUILDS
1 WORD
( ezzek a FORTH-füzér éppen a HERE )( címre, azaz az új szó paramezőjébe kerül ) HERE C@
1+
ALLOT
DOES>
COUNT TYPE
;( szöveg hossza )
( hosszúságbyte-tal együtt )
( a szótárpointert a szöveg mög )
( állítjuk )
Írunk egy szót, amely egy ilyen .TEXT-tel definiált szóról megmondja, mekkora a szó által kiírt szöveg hossza. A SZHOSSZ ( --- n ) szót így lehet majd használni:
SZHOSSZ PLD .
: SZHOSSZ ( --- n )
-FIND ( a szó megkeresése a szótárban )
IF DROP
2+
C@
ELSE ." Nincs ilyen szo " QUIT
ENDIF
;
Példák
15.1. Írjunk egy 2VARIABLE ( d --- ) definiáló szót, amely duplaszavas változókat definiál a vermen megadott kezdőértékkel! A változók a paramzőjük kezdőcímét tegyék a veremre.
: 2VARIABLE ( d --- )
<BUILDS 2! 4 ALLOT DOES> ;
15.2. Írjunk egy MATRIX ( maxsor maxoszl --- ) definiáló szót, amellyel mátrixokat lehet definiálni, például így:
5 6 MATRIX A
Ekkor az A egy 5-soros, 6-oszlopos mátrix, amelynek veremhatása: ( sor oszlop ---- elemcím ). Tehát az
1 2 A
paranccsal A első sora második elemének címét tesszük a veremre. A
6 6 A
parancsra (tehát ha a sor vagy oszlop számát a mátrix létrehozásakor megadott határokon kívül adjuk meg) az A "szálljon el".
A mátrixok paramezőjében a sorok és oszlopok számát kell tárolnunk; továbbá helyet kell foglalnunk a mátrix elemei számára. Mondjuk a sorok és oszlopok számát a paramező első illetve második szavában tároljuk; ezután jönnek majd az elemek, mégpedig egy-egy szóban, sorfolytonosan.
A mátrixoknak kétszer is ellenőrizniük kell, hogy egy megadott érték 1 és egy bizonyos maximum közé esik-e. Írjunk hát erre egy ELL ( n max-cím ---) szót, amely nem tesz semmit, ha az n 1 és a max-címen levő érték közé esik, de elszáll, ha nem:: ELL ( n max-cím )
@ OVER < ( max < n ? )
SWAP 1 < ( n < 1 ? )
OR
IF ." Baj van az indexhatarral!" QUIT ENDIF
;Megírjuk magát a MATRIX-ot. Definiáláskor a MATRIX leteszi a paramezőbe a maxsor, maxoszl értékeket, és az elemek számára 2*maxsor*maxoszl byte helyet foglal. A MATRIX-szal definiált szavak a vermen adott sorszám és oszlopszám ellenőrzése után kiszámítják a megfelelő elem címét, ami nem más, mint:
paramezőcím + 4 + 2*[(sorszám-1)*sorhossz + (oszlopszám-1)]
Már csak azt kell szem előtt tartanunk, hogy a sorhossz nem más, mint maxoszl és máris kódolhatunk:
: MATRIX ( maxsor maxoszlop --- )
<BUILDS
OVER OVER SWAP , ,
* 2* ALLOT
DOES> ( a vermen sor oszlop pmcím )
>R ( a pmcímet a virembe tesszük, )
( sokat fogjuk használni )
OVER OVER
R 2+ ELL ( oszlop OK? )
R ELL ( sor OK? )
( nem baj, hogy az ELL esetleg elszáll úgy, )
( hogy a virmen nincs rend. A QUIT majd )
( rendet csinál )
1- SWAP 1-
R 2+ @ * ( [sorsz-1]*sorhossz )
+ 2*
R> + 4 +
;
15.3. Írjunk egy KIIR ( --- ) mátrixkiíró szót a MATRIX-szal definiált szavakhoz, amely soronként írja ki a mátrix elemeit! A mátrix nevét a KIIR után kell megadni, például így:
KIIR A
A KIIR szálljon el, ha nem MATRIX-szal definiált szót kap.
A kényelem kedvéért létrehozunk egy változót, amelyben a kiírandó mátrix paramezőcímét tartjuk majd:
0 VARIABLE MXPC
Így tudjuk majd a mátrix méreteit a veremre csalni:
: MERET ( --- maxoszl maxsor )
MXPC @ 2 + ( a paramezőcím a FORTH két "saját" )
( byte-jának megkerülsével )
DUP 2+ @ ( maxoszl )
SWAP @ ( maxsor )
;Ezt persze az előző megoldáshoz írtuk; másféle paramezőbeosztáshoz nem jó.
Egy mátrixelem előkeresése így megy majd:: ELEM (sor oszl --- cím )
MXPC @ CFA EXECUTE
;Ha feltesszük, hogy már definiáltunk a MATRIX-szal egy A szót, akkor ellenőrizhetjük, hogy az MXPC-ben a mátrix paramezője van-e:
: MX? ( --- )
' A CFA @ MXPC @ CFA @ -
IF ( ha nem ua van a kódmezőben )
." Ez nem matrix!" QUIT ENDIF
;A KIIR ezek után gyerekjáték:
: KIIR ( --- )
-FIND
IF DROP MXPC !
MX? ( ha nem mátrix, a KIIR elszáll )
MERET ( maxoszlop maxsor )
1+ 1 DO CR R ( 1 sor kiírása )
OVER 1+ 1 DO
DUP R ELEM @ 6 .R
LOOP DROP
LOOP DROP CR
ELSE ." Nincs ilyen szo!" QUIT
ENDIF
;A mátrixok látványos, gyors feltöltése hasonlóan mehet:
: FELTOLT ( --- )
-FIND
IF DROP MXPC !
MX? ( ha nem mátrix, elszáll )
MERET ( maxoszlop max sor )
1+ 1 DO R
OVER 1+ 1 DO
DUP R OVER 10 * OVER +
ROT ROT ELEM !
LOOP DROP
LOOP DROP
ELSE ." Nincs ilyen szo!" QUIT
ENDIF
;
15.4. Írjunk egy TAB ( n --- ) definiáló szót, amelynek definiálásakor a vermen a végrehajtandó szavak számát kell megadni, az új szó neve után pedig a végrehajtandó szavakat (a nevükkel)! A TAB-bal létrehozott szavak a vermen várják, hogy a definiáláskor beolvasott szavak közül hányadikat hajtsák végre, és ha a sorszám értelmes, végre is hajtják.
: TAB
<BUILDS
0 DO -FIND
IF DROP CFA ,
ELSE HERE COUNT TYPE
." nincs a szotarban" QUIT
ENDIF
LOOP
DOES> >R
DUP 1 < OVER R @ > OR IF
." Rossz szam!" QUIT ENDIF
1- 2* R> + @ EXECUTE
;
16.1. Amikor az interpreter fordít
A kettőspontos szódefiníciókat bevezető : szó létrehozza az új szó név-, kód- és láncmezőjét, majd ún. fordítási állapotba teszi az interpretert. Ez annyit jelent, hogy az interpreter a befolyam szavait nem hajtja végre, hanem előkeresi a kódmezőcímüket és a szóval tárolja a HERE címen (az éppen létrejövő szó paramzőjében).
Hogy a befolyamban talált szavakat az interpreter végrehajtja vagy lefordítja, az a STATE rendszerváltozó (USER változó) értékétől függ. Ha a STATE értéke nem 0, akkor a befolyam szavai lefordítódnak. |
Ennek megfelelően, ha a STATE 0, végrehajtási, ha nem, fordítási állapotról beszélünk.
A STATE értékét (többek között) a definíciókat bevezető : és a befejező ; szó állítja.
16.2. Amikor az interpreter mégsem fordít
Nézzünk egy meglehetősen közönséges definíciót:
: COUNT DUP 1+ SWAP C@ ;
A fentiek és a 14.1. szakaszban mondottak szerint a COUNT paramzője így néz ki:
DUP kódmezőcíme 1+ kódmezőcíme SWAP kódmezőcíme C@ kódmezőcíme ;S kódmezőcíme
Egészítsük most ki ugyanezt a definíciót egy kommenttel:
: COUNT ( ff-cim --- cim hossz ) DUP 1+ SWAP C@ ;
A fentiekből az következne, hogy a második COUNT paramzőjében megjelenik a ( szó kódmezőcíme (hiszen a ( szó feltűnésekor a STATE nem 0, a rendszer fordítási állapotban van). A józan ész viszont azt súgja, hogy a két definíció eredménye azonos kell, hogy legyen, ha egyszer csak egy kommentben térnek el egymástól. A józan észnek van igaza: a fordítási állapotban sem minden szó fordítódik le. A szabályt erősítő kivételek az azonnali (immediate, ejtsd: immediét) szavak.
Az azonnali szavak akkor sem fordítódnak le, mikor az interpreter fordítási állapotban van; valahányszor az interpreter felleli őket, azonnal végrehajtódnak. |
A ( egy azonnali szó. Azonnali szavakat magunk is írhatunk; csak az kell hozzá, hogy a szó definíciója után a friss szót az
IMMEDIATE
szóval azonnalivá tegyük:
: JELENT ( --- )
CR LATEST ID. ." definicioja megkezdodott "
; IMMEDIATE
Ha a JELENT-et kettőspontos szódefinícióban használjuk, akkor a definiálás alatt kiíródik a jelentés, az egész dolognak viszont semmi hatása a keletkező új szóra. Íme tehát a harmadik definíció, amely pontosan ugyanolyan paramzőt hoz létre, mint az előző kettő:
: COUNT3 JELENT DUP 1+ SWAP C@ ;
Egy szó azonnali vagy nem azonnali voltát a névmező hosszúságbyte-jának második bitje, az ún. precedenciabit dönti el. Az IMMEDIATE tehát egyszerűen 1-re állítja az utoljára definiált szó precedenciabitjét.
16.3. Amikor mi fordítunk az interpreter helyett (a COMPILE)
Hogyan működik a ." szó, mikor definícióban használjuk? A kiírandó szöveget a definícióból szedi, tehát azonnali szó kell, hogy legyen (így tudja csak a szöveget a definícióból fordítási idő alatt beolvasni). Kell, hogy legyen viszont egy olyan szó is, amely igenis befordítódik a keletkező szó paramzőjébe, különben nincs, aki a szöveget futási idő alatt kiírja. Ez a szó a
(.")
"Fordító szó" (compiling word) a neve azoknak az azonnali szavaknak, amelyek egy másik szó (a "futó szó") kódmezőcímét és a futó szó munkájához szükséges adatokat (mezőbeli paramétereket) teszik a paramzőbe. |
Esetünkben a ." a fordító szó, a (.") a futó szó, a kiíratandó szöveg pedig a mezőbeli paraméter.
Ha van egy definíció, amelyben a ." szót használtuk:
: RENDBEN ." OK" ;
akkor annak a paramzője:
A (.") szó gondoskodik arról, hogy az utána levő FORTH-füzér a ki-készülékre menjen, és arról is, hogy ezt a füzért a címinterpreter átlépje, ne próbálja meg a füzér byte-jait kódmezőcímnek értelmezni. Ehhez felhasználja, hogy működése alatt a virmen a saját visszatérési címét találja, ami éppen a kiíratandó füzér címe: innen írja ki a szöveget, majd úgy manipulálja a virmet, hogy a visszatérési cím a füzér utánra mutasson.
: (.")
R COUNT
DUP 1+
R> + >R
TYPE
;
( a vermen a füzér hossza és címe )
( a teljes füzérhosszt hozzáadjuk a )
( visszatérési címhez )
Ha egy azonnali szótól azt kívánjuk, hogy egy másik (futó) szót lefordítson, akkor a
COMPILE
szót kell használnunk. A ." például a
COMPILE (.")
sorozattal csalja be a (.") kódmezőcímét a paramzőbe.
A COMPILE szó lefordítja a mögötte álló szót, azaz elhelyezi a kódmezőcímét a HERE címen.
A ." megvizsgálja, hogy fordítási állapot van-e:
: ."
34 ( a " határoló karakter kódja )
STATE @ IF
COMPILE (.")
WORD
HERE C@ ( a szótárpointert a füzér )
1+ ALLOT ( mögé állítjuk )
ELSE ( nem fordítás, végrehajtás )
WORD HERE COUNT TYPE
ENDIF
;
16.4. Literálok
A literálok azok a számok, amelyeket a definícióban adunk meg; ezeket az interpreter beírja a paramzőbe. A literálokat kezelő futó szó a
LIT
Például a
: .HAT 6 . ;
szóban a 6 egy literál. A szó paramzője a így néz ki:
LIT kódmezőcíme 6 . kódmezőcíme ;S kódmezőcíme
A LIT gondoskodik róla, hogy a .HAT futásakor a 6 a veremre kerüljön, és arról is, hogy a címinterpreter a 6-ot ne nézze végrehajtási címnek.
Előfordulhat, hogy a szódefinícióban használandó érték egy művelet eredménye; mondjuk, azt akarjuk felhasználni, hogy egy nap perceinek száma 60*24. Ezt ugyan ki lehet számolni előre, de akkor nem látszik rajta, hogy mi ez és hogyan számoltuk ki; a szorzást be is lehet írni a definíció szövegébe, de akkor minden egyes futáskor végrehajtódik, ami időpocsékolás. Ehelyett azt is megtehetjük, hogy a fordítási állapotot a
[
szóval megszüntetjük, előállítjuk a vermen a kívánt értéket, és a
]
szóval visszatérünk a fordítási állapotba. A vermen levő értéket a LITERAL szó fogja literálként a paramzőbe fordítani:
: PERCEK [ 60 24 * ] LITERAL . ." perces egy nap ";
A LITERAL szó természetesen azonnali. Ha definícióban használjuk, a LIT futó szót fordítja be, mögé, mezőbeli paraméterként a vermen levő értéket. Ha nem definícióban használjuk, a LITERAL nem csinál semmit.
Az utoljára tanult három szó forrása:
HEX : [ 0 STATE ! ; IMMEDIATE
: ] 192 STATE ! ; IMMEDIATE
; LITERAL
STATE @ IF COMPILE LIT , ENDIF
; IMMEDIATE
16.5. Azonnali szavak elhalasztása (a [COMPILE])
Hogyan működik a ' szó? Azonnali szónak kell lennie, hiszen fordításkor keresi meg a szótárban a mögötte álló szó címét. A cím azután (ha a ' -t definícióban használtuk) literálként jelenik meg a paramzőben.
Ebben nincs olyan, amit meg ne tudnánk írni:
: '
-FIND
0= 0 ?ERROR ( ha nincs ilyen szó, elszáll )
DROP (a vermen a paramezőcím )
STATE @ IF ( fordításkor )
COMPILE LIT ,
ENDIF
; IMMEDIATE
Ha valaki összeveti a program végét a LITERAL forrásszövegével, látja, hogy teljesen egyformák. Viszont a LITERAL-t nem írhatjuk bele a ' szövegébe: a LITERAL azonnali, és mi nem akarjuk, hogy ' definíciója alatt hajtódjék végre. Ehelyett azt kívánjuk, hogy a ' használatakor fejtse ki összes "azonnali" tevékenységét. Ezt teszi lehetővé a
[COMPILE]
szó, amely a mögötte álló szó azonnali viselkedését erre az egy alkalomra megszünteti. A ' szó eredeti, FIG forrása:
: '
-FIND
0= 0 ?ERROR ( ha nincs ilyen szó, elszáll )
DROP
[COMPILE] LITERAL
; IMMEDIATE
Most már megismerkedhetünk a LITERAL duplaszavas változatának a DLITERAL-nak a forrásával is:
: DLITERAL
STATE @ IF ( fordítási állapot )
SWAP ( az alsó elemet kell előbb a veremre tenni )
[COMPILE] LITERAL [COMPILE] LITERAL
ENDIF
; IMMEDIATE
Miról volt szó?
A 16. fejezet összefoglalása
A tanult szavak:
| STATE | ( --- cím ) | USER változó. Ha értéke 0, akkor az interpreter végrehajtja, ha nem, akkor lefordítja az interpretálandó szavakat (végrehajtási és fordítási állapot). |
| IMMEDIATE | Az utoljára definiált szót azonnalivá teszi (1-re állítja az ún. precedenciabitjét). Ez azt jelenti, hogy a szó fordítási állapotban sem fordítódik le; ha mégis le akarjuk fordítani, a [COMPILE] szót kell használnunk. |
|
| [COMPILE] | Egyetlen alkalomra megszünteti a mögötte álló szó azonnali viselkedését. Így lehet azonnali szavakat lefordítani. | |
| COMPILE | Azonnali szavakban használjuk. Lefordítja az utána álló szót. | |
| [ | Fordítási állapotba teszi a rendszert. | |
| ] | Végrehajtási állapotba teszi a rendszert. | |
| LIT | ( --- n ) | Futó szó, amely a mögötte álló egyszavas mezőbeli paramétert a veremre teszi. |
| LITERAL | fordításkor: ( n --- ) a lefordított szó futása alatt: ( --- n ) végrehajtáskor: ( n --- n ) Fordítási állapotban literálnak fordítja a vermen talált értéket, azaz: a LIT futó szót fordítja és mögé egyszavas mezőbeli paraméternek n-et. Így futáskor az n érték a veremre kerül. Végrehajtási állapotban nincs hatása. |
|
| DLITERAL | fordításkor: ( d --- ) a lefordított szó futása alatt: ( --- d ) végrehajtáskor: ( d --- d ) Fordítási állapotban literálnak fordítja a vermen talált duplaszavas értéket, amely így a lefordított szó futásakor a veremre kerül. Végrehajtási állapotban nincs hatása. |
|
| (.") | A ." fordította futó szó. Kiírja a ki-készülékre a FORTH-füzért, amely a paramzőben mögötte áll. |
Példák
16.1. Készítsünk egy listát a szótár azonnali szavairól!
Az azonnali szavak hosszúságbyte-jának második bitje 1. Így, ha ezt a hosszúságbyte-ot a veremre tesszük és a bináris
0000 0000 0100 0000
azaz hexadecimális 40 értékkel alkotott logikai ÉS eredményét nézzük, akkor éppen a megfelelő jelzőt kapjuk:
: AZONNALIAK ( pmcím --- jelző )
NFA C@
[ HEX 40 DECIMAL ] LITERAL AND
;A 14. fejezetben megismert EZEK-A szó felhasználásával könnyű a befejezés:
EZEK-A AZONNALIAK
16.2. Írjunk egy KNYO ( --- ) szót, amely ha definícióban használjuk, a definiált szó kiírja, hogy a definíció hányas kernyőn van! Tehát ha pl. a
: HOL-VAN KNYO ;
szöveget a 12. kernyőről töltöttük be, akkor a HOL-VAN működése során azt írja ki: "12. kernyorol jottem"
: KNYO
[ BLK @ B/SCR / ] LITERAL
. ." . kernyorol jottem ";
;
16.3. Írjunk egy ."" szót, amelyet ugyanúgy használhatunk definícióban, mint a ." szót, de a lefordított szó a szöveg kiírása előtt új sort kezd!
: .""
COMPILE CR [COMPILE] ."
; IMMEDIATE
16.4. Definiáljuk át úgy a ; szót, hogy a definíció befejezését szöveggel jelezze.
: ;
LATEST ID . ( utoljára definiált szó neve )
." definicio vege "
[COMPILE] ; (normál befejezés )
; IMMEDIATE
16.5. Mi lehet a [COMPILE] forrása?
: [COMPILE]
-FIND 0= 0 ?ERROR DROP CFA ,
; IMMEDIATE
17. Hogyan készül
a vezérlési struktúra?
Ebben a fejezetben felboncolunk néhány már ismert vezérlési struktúrát és megismerkedünk egy nem szabványos, de közkézen forgó struktúra, a CASE forrásával. (A CASE FORTH-beli megoldása Charles Eaker neve alatt vonult be a halhatatlanságba.) A fejezet elolvasását azoknak ajánljuk, akik meghitt ismeretséget akarnak kötni a fordító szavakkal vagy vezérlési struktúrákat akarnak irni. Akik nem, azok beérhetik a CASE működésének leírásával (lásd 17.5.1.), szükség esetén a teljes megértés nélkül is felhasználhatják a CASE kulcsszavainak forrását.
17.1. A futó szavak
A vezérlések egy feltételes és egy feltétel nélküli elágazás segítségével működnek. Mindkettő maga mögött, a paramzőben keresi az elágazási címet (ez a cím tehát mezőbeli paraméter). Az elágazási címek a mezőbeli paraméter címéhez képest relatívak (tehát azt mondják meg, hogy a paramétertől hány byte-nyira kell elugrani). Ez azért jó, mert így az ugrás paraméterezése nem függ attól, hogy az ugrás a memória melyik címén van.
A két szó:
| BRANCH | ( --- ) | feltétel nélküli ugrás a mezőbeli paraméterként megadott (relatív) címre; |
| 0BRANCH | ( --- ) | ha a kapott jelző hamis, elugrik a mezőbeli paraméterként megadott (relatív) címre. |
Valóságos processzorok esetén a vezérlésátadás a programszámláló megváltoztatását jelenti. Ezzel a program futása nem a sorban következő utasítással folytatódik, hanem egy másik, általunk kijelölt pontról. A programszámláló értékét kétféleképpen lehet megváltoztatni. Az első esetben a processzor kiolvassa a memóriából az ugrási címet, és ezt a PC-be tölti. A másik lehetőség, hogy a memóriában nem az ugrási cím van. hanem egy olyan érték, amelyet az aktuális programszámláló tartalmához adva megkapjuk a folytatási címet. (Ha ez pozitív, akkor előre, ha negatív, akkor visszafelé ugrás történik a programban).
A FORTH ezen második típusú vezérlésátadást alkalmazza. A program számláló szerepét itt az IP regiszter veszi át. A szótárban a BRANCH címe utáni memóriaszóban kell elhelyezni az ugráshoz szükséges eltolást. A működési mechanizmus a következő: amikor a BRANCH-ra kerül a vezérlés, az IP-ben az a cím van, ahol a BRANCH címe volt. A BRANCH hozzáadja az IP-hez az őt követő eltolást, és ezzel az IP most a felfűzött kód más pontjára fog mutatni. A BRANCH-et követő NEXT az IP-t kettővel növeli, és ahova az most mutat, az lesz az ugrás után végrehajtott első szó.
A 0BRANCH működése egyetlen ponton tér el a BRANCH-től: az ugrás csak akkor hajtódik végre, ha a verem tetején nulla van. Ellenkező esetben a felfűzött kód végrehajtása a 0BRANCH-et követő eltolás utáni szóval folytatódik. Mindkét esetben törlődik a verem legfelső eleme.
Egy példán keresztül könnyebb megérteni. Mondjuk, így definiálunk egy szót:
: PELDA BEGIN EGY KETTO AGIN ;
(itt EGY és KETTO már definiált, nem azonnali szavak).
Tegyük fel, hogy a PELDA paramzője a 2000 címen kezdődik. Ekkor:
A BRANCH-nek a 2000 abszolút címre kell visszamennie. A mezőbeli paraméterben ez a cím a paraméter címéhez (2006) relatívan szerepel, a mezőbeli paraméter értéke tehát 2000-2006=-6 lesz.
A BRANCH után a paraméter értéke akkor is -6 lesz, ha nem a 2000, hanem bármelyik más címen kezdődik a PELDA paramzője. Ezért jó a relatív címzés.
A paramzőt a ;S szó kódmezőcíme zárja (jelen esetben a 2008 címen); ettől fejezi majd be a címinterpreter a szó interpretálását.
Nézzük meg egy ismert szó paramzőjét:
A #S forrása:
: #S BEGIN # OVER OVER OR 0= UNTIL ;
Paramezője:
(A BRANCH tehát 12 byte-nyit ugrik vissza, amikor ugrik; ott találja # kódmezőcímét.)
A ?ERROR (lásd 13.3.) forrása:
: ?ERROR SWAP IF ERROR ELSE DROP ENDIF ;
paramezője:
A BRANCH és a 0BRANCH paraméterezésén kívül azt is érdemes megfigyelni, hogy egyes szavak (BEGIN, ENDIF) semmiféle kódmezőcímet nem fordítanak a paramzőbe, a feladatuk csak az, hogy kijelöljék, hova kell ugrani az UNTIL-tól vagy az ELSE-től.
17.2. Ellenőrzések
Az ellenőrző szavak a ?ERROR ( hibajelző hibasorszám --- ) szót hívják, amely hiba esetén mindent félbeszakít egy QUIT-tel (lásd 13.3. fejezet). A ?ERROR-nak a hibajelzőn kívül a hiba természetét tükröző hibasorszámot is meg kell adni. Az Olvasó 4. kernyőjének megfelelő soraiban ott vannak a megfelelő hibaüzenetek.
A COMP szó azt ellenőrzi, hogy a vezérlési struktúrákat csakugyan fordítási állapotban használjuk-e. Forrása:
: ?COMP ( --- )
STATE @ 0= 17 ?ERROR ;
A kulcsszavak megfelelő párosítását úgy ellenőrizzük, hogy a nyitó kulcsszó (mondjuk, a BEGIN) a veremre tesz egy számot, a névjegyét (a BEGIN pl. 1-et), az AGAIN pedig csak akkor hajlandó lefordítódni, ha a vermen 1-et talál. A párosítást ellenőrző szó:
: ?PAIRS ( n ---)
- 19 ?ERROR ;
A fordító szavaknak a fordítás végén ugyanúgy kell a vermet hátrahagyniuk, ahogyan találták. Ennek ellenőrzésére külön rendszerváltozó, a CSP szolgál. A veremmutató pillanatnyi értékét a
!CSP ( --- )
szóval tehetjük a változóba; a
?CSP ( --- )
szóval ellenőrizhetjük, hogy a verem állása ugyanaz, mint a CSP-ben rögzített helyzet. A két szó forrása:
: !CSP SP@ CSP ! ; : ?CSP SP@ CSP @ - 20 ?ERROR ;
A !CSP -t a : , a ?CSP -t a ; szó hívja; a CASE -nál látjuk majd, hogy máskor is hasznosak lehetnek.
17.3. A BEGIN, az AGAIN és az UNTIL
A BEGIN nem fordít semmit a paramzőbe; az a feladata, hogy a vele párosított szavaknak megüzenje, hová kell visszaugrani. Így a BEGIN cselekményének lényege: fordításkor a veremre teszi a szótármutató értékét; ez az a cím, ahova majd a ciklusmag első szava fordítódik, ide kell tehát majd visszaugrani. A veremre még egy 1 érték is kerül, ez a BEGIN névjegye.
: BEGIN
?COMP
HERE
1
; IMMEDIATE( --- ugráscím névjegy ) ( fordításkor )
( ha nem fordítás közben használjuk, )
( a BEGIN "elszáll" )
( ugrási cím )
( névjegy )
A ?COMP szó arra szolgál, hogy megakadályozza a BEGIN interpreter állapotban való használatát. (A vezérlési szerkezetek csak szódefiníció belsejében használhatóak.) A ?COMP fordítás állapotában semmit nem csinál, de interpreter módban hibajelzést ad. A szó ellentettje a ?EXEC. Ez akkor jelez hibát, ha végrehajtására fordítás közben kerül sor.
Mivel most szódefiníció közben vagyunk, a ?COMP nem jelez hibát, ls végrehajtódik a HERE szó. Ezzel a verembe kerül DP rendszerváltozó értéke. Ezután az egyes kerül a veremre, amelynek szerepére az AGAIN-nél derül fény.
A visszaugrás relatív címét a BACK szó teszi a paramzőbe:
: BACK
HERE
-
,
;( ugráscím --- )
( ide kerül a paraméter )
( levonjuk a vermen lévő címből, így )
( kapunk relatív címet )
( a kapott címet a paramezőben tároljuk )
Így az AGAIN:
: AGAIN
1 ?PAIRS
COMPILE BRANCH
BACK
; IMMEDIATE( ugráscím névjegy --- ) ( fordításkor )
( volt BEGIN? )
( az "ugrató" szó fordítása )
( ugrási cím fordítása )
Elsőnek egy egyes kerül a veremre. Most két egyes van a veremben, alattuk a DP értéke a BEGIN végrehajtásakor. Ezt követően hívódik meg a ?PAIRS (párok?) szó. Megvizsgálja, hogy a verem tetején lévő két szám egyenlő-e. Ha igen, akkor semmi sem történik, ha viszont nem azok, akkor a ?PAIRS hibajelzést generál. A két számot persze mindkét esetben levesz a veremről. Így tudja a FORTH megvizsgálni, hogy egy vezérlési szerkezetnek van-e eleje. "Itt vagyok!" jelzi a BEGIN a maga 1-ével. "Lássuk, volt-e BEGIN?" - kérdezi az AGAIN az 1-el és a ?PAIRS-el. Persze kérdés az is, hogy mi van akkor, ha volt BEGIN, de elfelejtettük leírni az AGAIN-t. Ekkor sincs baj, mert így meg a BEGIN egyesét semmi sem használja fel, a ; elérésekor tehát a veremmutató nem egyezik meg a CSP-ben tárolt értékkel, ezért most is hibajelzést kapunk. A leírt ellenőrzési eljárást használja a többi vezérlési szerkezet is. A módszer nem nyújt száz százalékos védelmet a csonka szerkezetek ellen, de az esetek nagy többségébenez is kielégítő biztonsággal jelzi a hibákat.
Ha a ?PAIRS nem talált hibát, a két egyest levette a veremről. Most jön a COMPILE ami befordítja a szótárba az utána álló szó címét. Így a BRANCH kódmezőcíme bekerül a szótár következő üres memóriaszavába. Ezután kerül sor a BACK szóra.
Az UNTIL az AGAIN-től csak abban különbözik, hogy a visszaugrás feltételes.
: UNTIL
1 ?PAIRS
COMPILE 0BRANCH
BACK
; IMMEDIATE( ugráscím névjegy --- ) ( fordításkor )
( volt BEGIN? )
( az "ugrató" szó fordítása )
( ugrási cím fordítása )
17.4. Az IF, az ELSE és az ENDIF
A BACK csak a szótárban visszafelé, az alacsonyabb címek felé történt ugrások megvalósítását segíti elő. Előrefelé történő ugrások kiszámítása sem sokkal bonyolultabb. Itt egyedül az jelent problémát, hogy tudjuk az ugrási eltolás helyét, de értékét még nem ismerjük.
Az IF a 0BRANCH szót fordítja a paramzőbe, amely hamis jelzőre az ELSE ágra vagy az ENDIF utánra ugrik. Csakhogy amikor az IF fordít, akkor még nem tudni, hol lesz az ELSE ág vagy az ENDIF, a 0BRANCH paraméterét tehát utólag kell majd beírni. Az IF pillanatában csak annyit segíthetünk magunkon, hogy a vermen megjegyezzük, hová is kell majd kerülnie az ugrási címnek:
: IF ( --- paramétercím névjegy ) ( fordításkor ) COMPILE 0BRANCH ( feltételes ugrás ) HERE
0 ,
2
; IMMEDIATE( paramétercím )
( kuhagyjuk a paraméter helyét )
( névjegy )
Ha nincs ELSE, akkor az ENDIF helyezi el a megadott paramétereimen a relatív ugrási címet:
: ENDIF
?COMP
2 ?PAIRS
HERE
OVER -
SWAP !
; IMMEDIATE( --- paramétercím névjegy ) ( fordításkor )
( ez az abszolút ugrási cím )
( most lett relatív )
( helyretettük a paramétert )
Ha ELSE is van, akkor bonyolultabb a helyzet:
Az IF-be tehát az ELSE fogja az ugrási címet beírni, "szóról szóra" ugyanúgy, ahogy az ENDIF. Az ENDIF pedig az ELSE-től kapja a címet, ahová az ugrási címet tennie kell.
: ENDIF
2 ?PAIRS( par.cím1 névjegy --- par.cím2 névjegy )
( fordításkor )COMPILE BRANCH ( az igaz ág vége ) HERE
0 ,( ezt a címet adjuk tovább )
( ugrási cím helye )( most mutat a szótármutató a hamis ág elejére ) SWAP 2 ( a vermen: par.cim2 par.cím 1 2 ) [COMPILE] ENDIF ( rel. cím par.cím1-re ) 2
; IMMEDIATE( névjegy )
17.5. Egy nem szabványos struktúra: a CASE
17.5.1. Hogyan használjuk?
A CASE szerkezet arra való, hogy egy értéktől (nevezzük ezt elágaztató értéknek) függően különböző dolgokat műveltethessünk. A CASE szó várja futáskor a vermen az elágaztató értéket, amelytől a cselekmény függ. Az egyes ágakat az OF és ENDOF szavak közt írjuk le; ilyen OF ág akárhány lehet. Futáskor az OF-nak a vermen adjuk meg, hogy az adott OF ágat milyen elágaztató értéknél kell végrehajtani. Ha a CASE-nek adott elágaztató érték egyik OF ágra sem tereli a programot, akkor az utolsó ENDOF és a szerkezet végét jelző ENDCASE közti egyéb rész hajtódik végre. Az elágaztató értéket az igazi OF dobja el a veremről, így ha az egyéb rész fut, akkor ott van a verem tetején, eltávolításáról pedig az ENDCASE gondoskodik.
Szintaxisa a követlező:
CASE (n --- )
n1 OF szóssor1 ENDOF ( ha n=n1 )
n2 OF szóssor2 ENDOF ( ha n=n2 )
...
nn OF szóssorn ENDOF ( ha n=nn )
szósor.egyéb ( ha n<>n1, n2 ... nn )
ENDCASE
Ha például a német nyelvű felhasználókat a G, az angol nyelvűeket az E, a franciákat az F betű jelzi, akkor ez lehet egy elköszönő felirat:
: VISZLAT ( nyelvkód --- )
CASE
71 OF ( G betű )
." auf Wiedersehen"
ENDOF
69 OF ( E betű )
." good bye"
ENDOF
70 OF ( F betű )
." au revoir"
ENDOF
( egyéb )
." mit kezdjek veled?"
ENDCASE
;
17.5.2. A kulcsszavak forrása
Az eddigiekhez képest az az újdonság, hogy a CASE struktúrának van egy akárhányszor ismételhető eleme, az OF ... ENDOF ág. Minden ENDOF után az ENDCASE-re kell menni, de persze (fordításkor) egyiknél sem tudni még, hogy hol van. Így az ENDCASE-nek kell a veremre tett paramétercímekre beírogatni az ugrási címeket; hogy hány helyre, annak kiszámításához a CSP változót hívja segítségül.
Az ENDCASE és az ENDOF-ok utólag írnak be ugrási címeket az ENDOF-ok, ill. az OF-ok generálta ugrásokhoz. Mivel ezt az utólag való beírást az ENDIF megcsinálja, ha megkapja a paraméter címét és egy 2 értékű névjegyet, az ENDCASE és az ENDOF őt mozgósítja erre a feladatra.
: CASE
?COMP
CSP @
!CSP
4
; IMMEDIATE( névjegy --- ) ( fordításkor )
( mivel a CSP-t elrontjuk, illik )
( megőrizni az eedeti értéket )
( CSP-be a veremmutató pillanatnyi értéke )
( névjegy ): OF
4 ?PAIRS
( névjegy --- paramétercím névjegy )
( fordításkor )
( volt CASE? )COMPILE OVER (az elágaztató érték összevetése az )
COMPILE = ( az of-értékkel )
COMPILE 0BRANCH ( ha nem =, az ENDOF utánra megyünk )HERE
0 ,
( ide jön majd az ugrási cím )
( ugrási cím helye )COMPILE DROP ( ha ez az igazi OF, az elágaztató )
5
; IMMEDIATE
( értékre már nincs szükség )
( az OF névjegye ): ENDOF
5 ?PAIRS( par.cím1 névjegy1 --- par.cím2 névjegy2 )
( fordításkor )
( volt OF? )COMPILE BRANCH (az OF ág végéről az ENDCASE-re )
HERE
0 ,
SWAP 2( megyünk )
( par.cím2 )
( paraméter helye )
( készülés az ENDIF-re )[COMPILE] ENDIF 4
; IMMEDIATE( névjegy2 )
Ha az utolsó OF ág sem az igazi, akkor az utolsó ENDOF utánra megy a program. Ott nincs további kérdezősködés: ami ott van, az végrehatódik. Az elágaztató érték közben a vermen felejtődik - majd az ENDCASE eldobja.
: ENDCASE
4 ?PAIRSCOMPILE DROP ( ide akkor jut majd futáskor a )
BEGIN
SP@ CSP
@ = 0=
WHILE
2( program, ha egyik OF sem volt az igazi )
( s a vermen maradt az elágaztató érték )
( az ENDOF-ok ugrási címei )
( míg el nem fogyott, amit az ENDOF-ok )
( a veremre tettek )
( névjegy az ENDIF-nek )[COMPILE] ENDIF REPEAT
CSP !
; IMMEDIATE
( ezért őriztük meg a vermen a CSP )
( eredeti értékét )
18. Még egy FORTH program: a szöveginterpreter
Az eddig tanultak összefoglalásaképpen megnézzük, hogyan működik a FORTH interpreter.
Betöltés után a vezérlés a COLD (hidegindítás) szóra adódik. A COLD törli a blokkpuffereket, beállítja a virtuális memória és a terminál adatait, bizonyos USER változókat az ún. betöltési paraméterek területéről szabványos kezdeti értékekkel tölt fel. Ezután hívja az ABORT szót. Az ABORT szövege magáért beszél:
: ABORT
SP! ( a vermet kiürítő primitíva )
DECIMAL
?STACK
CR .CPU ( a processzor típusát írja ki )
." fig- FORTH 1.1g"
FORTH
DEFINITIOS
QUIT
;
A szöveginterpretert a QUIT mozgósítja. A QUIT a megfelelő változók inicializálása után ciklusban sorokat olvas a terminálról és átadja őket az INTERPRET szónak. A beolvasást a QUERY végzi. A QUERY az EXPECT-et hívja, úgy paraméterezve, hogy az a billentyűzetről olvasott sort a parancspufferbe tegye; ezen kívül 0-ra állítja az IN értékét:
: QUERY
TIB @
80
EXPECT
0 IN !
;
( a cím, ahova az EXPECT majd a beolvasott )
( szöveget teszi )
( max. szöveghossz az EXPECT számára )
A QUERY-n és az INTERPRET-en kívül újdonság lesz még az QUIT szövegében az RP! primitiva; ez a virmet állítja vissza kezdeti, üres állapotába.
: QUIT
0 BLK !
[COMPILE] [
BEGIN
RP CR
QUERY
INTERPRET
STATE @
( a terminálról olvasunk )
( végrehajtási állapotba megyünk )
( virem ürítés )
( új sor )
( parancssor beolvasás )
( parancssor végrehajtás )0= IF ." ok" ENDIF ( ha nem definíció közepén )
AGAIN
;( van sor vége, jöhet az ok )
A szöveginterpreter nagyjából azonos az INTERPRET szóval. Az iNTERPRET szavanként dolgozza fel a befolyamot (amelyet a BLK és IN rendszerváltozók jelölnek ki neki). A szavakra tördelést természetesen a WORD végzi, amely az INTERPRET szövegében a -FIND-be bújtatva szerepel.
Ha a -FIND sikeresen keresett a szótárban, akkor az interpreternek el kell döntenie, hogy a szótári szó végrehajtódjék vagy lefordítódjék. Ez a döntés (ha a STATE lehetséges értékei ügyesen vannak választva) egyetlen összehasonlításba sűríthető: a szó névmezőjének hosszúságbyte-ját hasonlítjuk a STATE értékeivel.
Akit érdekel "bitekre menően": A STATE, ha nem 0 (azaz nem végrehajtási állapotot jelez), akkor hexadecimális C0, azaz binárisan 1100 0000. A szavak névmezőjének hosszúságbyte-jában az első bit mindig 1. így végrehajtási állapotban a STATE értéke mindig kisebb lesz, mint a hosszúság-byte-é. Fordítási állapotban a STATE értéke csak az azonnali szavak hosszúságbyte-jánál lesz kisebb (ezeknél a hosszúságbyte második bitje, a precedenciabit 1). Akkor kell tehát a szót végrehajtani, ha a STATE értéke kisebb, mint a hosszúságbyte-é.
Ha a szót nem találtuk a szótárban, akkor a NUMBER veszi kezelésbe, vagyis megpróbálja konvertálni Ha nem megy, a NUMBER egy 0 ERROR-ral elszáll (visszamegy a QUIT-re). Sikeres konverzió után már csak azt kell eldönteni, hogy egyszavas vagy duplaszavas értékről van szó (volt-e tizedespont), azaz a LITERAL vagy a DLITERAL kapja meg a feladatot. Mindkettő csak akkor tesz bármit is, ha fordítási állapotban vagyunk.
Az INTERPRET a ?STACK szóval ellenőrzi, hogy nem használtunk-e több elemet, mint amennyi volt a veremben, vagy nem halmoztuk-e túl a vermet (mert az is véges). A ?STACK mindkét esetben hibaüzenetet ad és visszamegy a QUIT-re.
: INTERPRET
BEGIN
-FIND
IF
STATE @ <
IF
CFA ,
ELSE
( szótárelem;a vermen a hosszúságbyte )
( a kapott jelző hamis, ha STATE 0, )
( vagy a szó azonnali )
( fordítunk )
( letesszük a kezdőcímet a HERE címre )
( végrehajtás )CFA EXECUTE ENDIF
?STACK
ELSE
HERE NUMBER
DPL @ 1+
IF
( nincs ilyen nevű szótárelem )
( konverzió )
( ide akkor jutunk, ha a konverzió )
( sikerült, a NUMER nem szált el )
( a DPL nem -1, volt tizedespont )[COMPILE] DLITERAL ELSE
DROP( egyszavas érték ) [COMPILE] LITERAL ENDIF
?STACK
ENDIF
AGAIN
;
Mi történik, ha az interpretálandó szöveg úgy hozza, hogy a parancspufferről át kell térnünk egy kernyő interpretálására? A LOAD szövege megadja a választ:
: LOAD
BLK @ >R
IN @ >R
0 IN !
B/SCR *
BLK !
INTERPRET
R> IN !
R> BLK !
;
( kernyőszám )
( a viremben megjegyezzük, hol hagytuk )
( abba a LOAD-ot tartalmazó szöveg )
( interpretálását )
( a blokk elején kezdjük )
( a kernyő első blokkja )
Egy LOAD tehát egy újabb INTERPRET-et hív, azaz egy újabb BEGIN ... AGAIN ciklust indít (amely ezúttal a kernyő blokkjaiból kezdi kapkodni a szavakat). Akármelyik (külső, belső, esetleg még belsőbb) BEGIN ... AGAIN ciklusról van szó, egyszer minden kernyő és parancssor interpretálásának véget kell érnie. A végszó a null szó (a nevét a szótárlistákban és dokumentációkban x-nek szoktuk látni), amelynek neve egyetlen bináris nulla byte. Ezért jó, hogy az EXPECT (tehát a QUIT hívta QUERY is) bináris nullát vagy nullákat tesz a beolvasott szöveg után; ezért van (bár erről eddig nem volt szó) a blokk- pufferek végén is bináris 0. A bináris 0 (amellett, hogy a WORD számára mindig határoló) tehát szótári szó.
Az alábbi forrás nem a szabványos FIG, hanem egy könnyebben érthető változat:
: X ( "null")
BLK @
IF
1 BLK +!
0 IN !
BLK @ B/SCR
MOD 0=
( ha blokkpufferből dolgozunk )IF ( ha az új kernyőkezdését jelentené) ?EXEC
R> DROP
ENDIF
ELSE
R> DROP
ENDIF
;( ha fordítási állapotban értünk )
( a kernyő végére, QUIT-re futunk )
( nem a hívó szóba megyünk vissza, )
( hanem eggyel "még visszább" )
( nem a hívó szóba megyünk vissza, )
( hanem eggyel "még visszább" )
A null szó nemcsak az interpretálásnak, hanem ennek a könyvnek is végszava. Sok sikert és jó munkát a FORTH alkalmazásához!
A) függelék
A FIG-FORTH 1.1. szójegyzék
A szójegyzék a FIG-FORTH 1.1. Installation Manual szójegyzéke alapján készült. Szavai közül sokkal találkozhattunk a szövegben, ezt a zárójelbe tett fejezetszámok vagy feladatszámok jelzik, minden további magyarázat nélkül, pl.:
A többi utalás a szójegyzék eredeti szövegéből való és a szójegyzék szavaira utal.
Vannak olyan szavak, amelyeknek a veremhatása nincs jelölve. Ezeknek vagy nincsen veremhatása (FORGET), vagy nem lehet ezzel a technikával jelölni (a COLD pl. kiüríti a vermet).
A veremhatás leírásakor használt jelölések:
b byte-os érték, c karakter (tehát szintén byte-os érték), n egyszavas, előjeles érték, u egyszavas, előjel nélküli érték, d duplaszavas, előjeles érték (tehát 2 elem a veremben), ud duplaszavas, előjel nélküli érték (2 elem), f jelző, igaz igaz értékű jelző, hamis hamis értékű jelző, cím egyszavas, előjel nélküli érték, ! ( n cím --- )
A 16 bites n értéket a címen tárolja (7.2.).!CSP
A CSP változóba teszi a veremmutató pillanatnyi értékét (17.2.)# ( ud1 --- ud2 )
Számok karaktersorozattá konvertálásakor, a <# és #> szó között használjuk. A következő karakterkódot generálja az output karaktersorozatba. A továbbadott duplaszavas érték a további karakterek előállításához szükséges (ez a BASE tartalmával való osztás hányadosa, a karakterkód a maradékból keletkezik). (11.1.)#> ( ud --- cím hossz )
Számok karaktersorozattá konvertálásának befejezése. Az output karaktersorozat címét és hosszát teszi a veremre, így ezt a TYPE szóval rögtön kiírathatjuk (11.1.).#S ( ud1 --- ud2 )
Számok karaktersorozattá konvertálásakor, a <# és #> szó között használjuk. A # szó ismételt hívásával karakterkódokat generál az output karaktersorozatba mindaddig, amíg értékes jegy van, azaz, amíg a további konverzióhoz előállított hányados nem 0. (11.1.).' ( --- cím )
Így használjuk:
' nnnn.
Az nnnn szótár szó paramzőcímét adja a vermen. Ha definícióban használjuk, a címet literálként az éppen definiált szóba fordítja. Ha nincs ilyen szótári szó, a sor interpretálása a megfelelő hibaüzenet mellett megszakad (14 4.2. és 16.5.).( ( --- )
Így használjuk:
( cccc )
A ) határolóig tartó kommentet figyelmen kívül hagyja. A ) határolónak a ( szóval egy sorban kell lennie! Definícióban ugyanúgy használható, mint végrehajtási állapotban. Ne feledkezzünk meg a ( utáni szóhatároló szóközről! (1.4., 10.3., 16.2.)(.") ( --- )
A ." szó fordította futó szó, amely kiírja az utána álló (paramzőbeli) szöveget (16.3.).(;CODE) ( --- )
A ;CODE fordította futó szó, amely a legutoljára definiált szó kódmezőjében a mutatót a paramzőben tárolt kódokra állítja (l. ;CODE).(+LOOP) ( n --- )
A +LOOP fordította futó szó, amely a cindexet n-nel növeli és megvizsgálja, vége van-e már a ciklusnak.(ABORT)
A WARNING változó -1 értékénél végrehajtódó felhasználó által definiált megszakítás. Ha nem változtatjuk meg, az ABORT szót hívja (13.3., 14.4.3.).(DO) ( n1 n2 --- )
A DO által fordított futó szó, amely a cindex kezdőértékét és a ciklushatárt a viremre teszi.(FIND)
( cím1 cím2 --- pmcím hosszúság-byte igaz ) vagy
( cím1 cím2 --- hamis )
A cím2 névmező címtől keresi a szótárban a cím1-en kezdődő FORTH-füzérrel megadott nevet. Ha megtalálta, a paramzőcímét, a névmező hosszúságbyte-ját és egy igaz jelzőt ad, ha nem, csak egy hamis jelzőt kapunk. A FIND hívja.(LINE) ( n1 n2 --- cím hossz )
Az n2-edik kernyő n1-edik sorának diszkpufferbeli címét és teljes sorhosszát adja (13.2.).(LOOP)
A LOOP által fordított szó, amely növeli a cindexet és ellenőrzi, nincs-e vége a ciklusnak.(NUMBER) ( d1 cím1 --- d2 cím2 )
A cím1+1-en kezdődő karaktersorozatot a BASE-nek megfelelően duplaszóba konvertálja és hozzáadja a vermen kapott d1-hez, így kapjuk d2-t. cím2 az első nem konvertálható karakter címe. A NUMBER hívja.[
Kettőspontos definícióban használjuk.
: xxxx [ szavak ] többi ;
Felfüggeszti a fordítást. A [ utáni szavak nem fordítódnak le, hanem végrehajtódnak, egészen a ] -ig. Ld. LITERAL, ] (16.4.).[COMPILE]
Lefordítja a mögötte álló azonnali szót (amely a [COMPILE] nélkül nem fordítódna le, hanem végrehajtódna) (16.5.).]
A fordítási állapot visszaállítása. Ld. ] (16.4.).* ( n1 n2 --- szorzat )
Két előjeles szám előjeles szorzatát adja (1.4.).*/ ( n1 n2 n3 --- n4 )
Az n4=(n1*n2)/n3 hányadost adja. Minden szám előjeles. Az n1*n2 szorzatot duplaszóban tárolja, ez nagyobb pontosságot tesz lehetővé, mint az n1 n2 * n3 / sorozat (6.4.).*/MOD ( n1 n2 n3--- n4 n5 )
Az (n1*n2)/n3 osztás n5 hányadosát és n4 maradékát adja. Az n1*n2 szorzatot duplaszóban tárolja. Valamennyi érték előjeles (6.4.).+ ( n1 n2 --- összeg )
Két előjeles szám előjeles összegét adja (1.4.).+! ( n cím --- )
Az n előjeles számot a cím-en levő 16 bites értékhez adja, az összeget a cím-en tárolja (8.3.).+- ( n1 n2 --- n3 )
Ha n1 negatív, n3=-n2, ha nem, n3=n2.+BUF ( cím1 --- cím2 f )
A cim1 diszkpuffercímből adja a következő diszkpuffer cím2 címét. A visszaadott jelző akkor hamis, ha a cím2 a PREV változóban nyilvántartott puffer címe.+LOOP
( n1 --- ) ( futáskor )
( cím n2 --- ) ( fordításkor )
Kettőspontos definícióban használhatjuk a következő formában:
DO ... n1 +LOOP
Futáskor a +LOOP dönti el, hogy a vezérlés visszamenjen-e a DO-ra. n1-et a cindexhez adja és az összeget, azaz az új cindexet a ciklushatárhoz hasonlítja. (A cindex és a ciklushatár a ciklus futása alatt a virmen van.) Addig megy vissza a DO-ra, amíg az új cindex a ciklushatárnál nagyobb vagy egyenlő (n1>0), ill. kisebb vagy egyenlő (n1<0) nem lesz. A ciklusból való kilépéskor a cindexet és a ciklushatárt eltávolítja a viremről (4.7.). Fordításkor a (+LOOP) futó szót és a DO által a veremre tett cím?ből a szótármutatóhoz képest relatív ugrási címet fordítja. Az n2 érték a fordítás alatti hibaellenőrzést szolgálja.+ORIGIN ( n --- cím )
A kapott cím a betöltési paraméterek területének címe, n-nel növelve., ( n --- )
Az n értékét a szótármutató által mutatott helyen tárolja; a szótármutató értékét 2-vel növeli (9.3.).- ( n1 n2 --- különbség )
Az n1-n2 különbséget adja (1.4.).--> ( --- )
A kernyő interpretálásáról rátér a következőére (2.5.).-DUP
( n1 --- n1 ) (ha n1=0)
( n1 --- n1 n1 ) (ha n1<>0)
n1-et csak akkor duplázza, ha n1<>0. Általában közvetlenül az IF előtt használjuk, hogy megtakarítsuk az egyetlen DROP-ot tartalmazó ELSE ág írását (3.2.).-FIND
( --- pmcím hosszúságbyte igaz ) (ha megtalálta)
( --- hamis ) (hanem)
A befolyam következő (szóközzel határolt) szavát keresi a szótárban. Ha megtalálta, a paramzőcímét, a névmező hosszúságbyte-ját és egy igaz jelzőt ad. Ha nem, csak egy hamis jelzőt kapunk (14.4.).-TRAILING ( cím n1 --- cím n2 )
A cím-en levő karaktersorozat n1 hosszát változtatja meg úgy, hogy abba a sorozat végén levő szóközök ne értődjenek bele (13.2.).. ( n --- )
Kiírja az n számot, a BASE-nek megfelelően konvertálva, utána egy szóközt (1.2.).." ( --- )
A következőképpen használjuk:
." cccc "
Ha definícióban használjuk, befordítja az új szóba a cccc szöveget egy futó szóval együtt, amely futáskor kiírja a szöveget a ki-készülékre. Definíción kívül használva a cccc szöveget rögtön kiírja (1.7., 10.3., 16.3.)..CPU ( --- )
A processzor típusát adja, azaz esetünkben a Z80 üzenetet adja.. LINE ( sor kernyő --- )
A megadott számú kernyő megadott sorát (a sorvégi szóközök nélkül) a ki-készülékre írja (13.2.)..R ( n1 n2 --- )
Az n1 számot egy n2 hosszúságú mezőben jobbra igazítva írja ki (4.4.)./ ( n1 n2 --- hányados )
Az n1/n2 előjeles hányadost adja a vermen (1.4.)./MOD ( n1 n2 --- maradék hányados )
Az n1/n2 osztás maradékát és előjeles hányadosát adja. A maradéknak ugyanaz az előjele, mint az osztóé.0
1
2
3 ( --- n )
Gyakran használt számok, amelyek ezért konstansként megvannak a szótárban (8.2.1., 8.4.).0< ( n --- f )
A kapott jelző akkor igaz, ha n<0 (2.4.).0= ( n --- f )
A kapott jelző akkor igaz, ha n = 0 (2.4.).0BRANCH ( f --- )
A feltételes elágazást megvalósító futó szó. Ha f hamis, akkor a 0BRANCH utáni mezőbeli paraméterrel nő az a cím, ahol a címinterpreter a munkáját folytatja (a paraméter negatív is lehet, ez jelenti a visszafelé ugrást). Az IF, UNTIL, WHILE szavak fordítják (többek között) (17.1.).1- ( n1 --- n2 )
n1-et 1-gyel csökkenti (2.4.).1+ ( n1 --- n2 )
n1-et 1-gyel növeli (2.4.).2- ( n1 --- n2 )
n1-et 2-vel csökkenti (2.4.).2+ ( n1 --- n2 )
n1-et 2-vel növeli (2.4.).2* ( n1 --- n2 )
n1 értékét 2-vel szorozza.2/ ( n1 --- n2 )
n1 értékét 2-vel osztja.2! ( d cím --- )
A duplaszót a cím-en meg az utána következő 3 byte-on tárolja (a 4 byte előző tartalma elvész).2@ ( cím --- d-tartalom )
a cím-en és az utána következő 3 byte-on tárolt duplaszót teszi a verembe.2DUP ( n1 n2 --- n1 n2 n1 n2 )
A verem tetején lévő duplaszót a verem tetejére másolja (6.3.).:
Úgynevezett kettőspontos szavak létrehozására használjuk.
: cccc . ;
Létrehoz egy szótárelemet cccc néven, amelybe az utána következő FORTH szavakat fordítja a ; -ig vagy a ;CODE-ig. A szöveginterpreter addig fordít, amíg a STATE állapotjelző értéke nem 0. A CONTEXT szótár ugyanaz lesz, mint a CURRENT (1.1.).;
A kettőspontos szódefiníció befejezése. Leállítja a fordítást; az ;S futó szót fordítja (1.1.).;CODE
Így használjuk:
: cccc ... ;CODE assembler mnemonikok
Leállítja a fordítást, befejezi az új cccc definiáló szót a (;CODE) befordításával. A CONTEXT szótárat az ASSEMBLER-re állítja, amely a ;CODE utáni mnemonikokat gépi kódra fordítja. Ha ezek után a cccc szóval definiálunk, cccc nnnn , akkor az nnnn szó a cccc után megadott gépi kódokat fogja végrehajtani. A cccc-ben a ;CODE előtt kell lennie egy definiáló szónak.;S ( --- )
Leállítja egy kernyő interpretálását (2.5.). Kettőspontos definíciók végére ezt a futó szót fordítja a ; szó (14.1.).< ( n1 n2 --- f )
A visszaadott jelző igaz, ha n1 <n2 (2.).<#
Számok karaktersorozattá konvertálásának kezdete. A konverzió egy duplaszón dolgozik, a szöveget a pad-nél állítja elő (11.1.).<BUILDS
Kettőspontos definícióban használjuk, így:
cccc <BUILDS ... DOES> ... ;
A létrehozott cccc szó definiáló szó lesz; futásakor a <BUILDS egy új szótárelemet hoz létre:
cccc nnnn
A létrehozott nnnn szótárelem a cccc definíciójában, a DOES> után leírt eljárást hívja. Mikor az nnnn szó elkezd futni, a saját paramzőcímét találja a vermen (15.).= ( n1 n2 --- f )
A kapott jelző igaz, ha n1=n2 (2.).> ( n1 n2 --- f )
A kapott jelző igaz, ha n1>n2 (2.2.).>R ( n --- )
A viremre teszi a verem legfelső elemét. Definíción belül általában a R> szóval kiegyensúlyozva használjuk (4.1.).? ( cím --- )
A cím-en levő 16 bites számot kiírja a ki-készülékre (8.1. feladat).?COMP
Hibaüzenettel megszakítja a futást, ha nem fordítási állapotban hívjuk (17.2.).?CSP
Hibaüzenettel megszakítja a futást, ha a veremmutató értéke a CSP változóban őrzött értéktől különbözik (17.2.).?ERROR ( f hibasorsz --- )
A megadott sorszámú hibaüzenettel megszakítja a futást, ha a jelző igaz (13.3.).?EXEC
Hibaüzenettel megszakítja a futást, ha fordítási állapotban hívjuk.?LOADING
Hibaüzenettel megszakítja a futást, ha nem kernyőről hívjuk.?PAIRS ( n1 n2 --- )
Hibaüzenettel megszakítja a futást, ha n1<>n2. A hibaüzenet a vezérlési struktúrák kulcsszavainak rossz párosítását jelzi (17.2.).?STACK
Hibaüzenettel megszakítja a futást, ha a verem alá- vagy túlcsordult (18.).?TERMINAL ( --- f )
Teszteli, hogy a terminálról érkezett-e megszakítás, (legtöbbször: megnyomták-e valamelyik billentyűt). (12.1.).@ ( cím ---- n )
A cím 16 bites tartalmát adja (7.2.).ABORT
Kiüríti a vermet, a virmet, és végrehajtási állapotba tér. A vezérlést a terminálra adja; installációfüggő üzenetet ad (13.3.).ABS ( n --- u )
Az n szám abszolút értékét adja (1.).AGAIN ( cím n --- ) ( fordításkor )
Definícióban használjuk:
BEGIN ... AGAIN
Futáskor az AGAIN a BEGIN-re adja a vezérlést. A vermet változatlanul hagyja. A ciklus nem ér véget (hacsak egy R> DROP nem hajtódik végre egy hívási szinttel lejjebb) (5.1.).
Fordításkor a BRANCH szót fordítja, a HERE-től a vermen kapott címre való elágazással. Az n a fordítás alatti hibaellenőrzésre való (17. 3.).ALLOT ( n --- )
Az n előjeles számot a DP szótármutatóhoz adja. Helyfoglalásra, a memória szervezésére használjuk (9.3.).AND ( n1 n2 --- n )
Bitenkénti ÉS műveletet hajt végre n1 és n2 között (2.3.).B/BUF ( --- n )
Konstans; a diszkpufferek hosszát adja, azt a hosszat, amelyen a BLOCK a virtuális memóriát olvassa (13.1.).B/SCR ( --- n )
Konstans, azt adja meg, hogy hány blokkból áll egy kernyő. Konvenció szerint a kernyők mérete: egy kernyő 1024 byte, 16 db 64 karakteres sor (13.2.).BACK ( cím --- )
A HERE-ről a vermen adott címre való ugráshoz a relatív címet számítja. A kiszámított címet a szótárba fordítja (17.3.).BASE ( --- cím )
User változó; az input és output konverziók alapszáma (8.2.1.).BDOS
BEGIN ( cím --- n ) (fordításkor)
Definícióban használjuk:
BEGIN ... UNTIL,
BEGIN ... AGAIN,
BEGIN ... WHILE ... REPEAT
Futáskor a BEGIN jelzi a ciklusmag elejét, ez a visszatérési pont a megfelelő UNTIL, AGAIN vagy REPEAT számára. Az UNTIL akkor tér vissza a BEGIN-re, ha a verem tetején talált jelző hamis, az AGAIN és a REPEAT mindig visszatér (5.1., 5.2., 5.3.). Fordításkor a BEGIN a visszatérési címet és a (fordításkori hibaellenőrzést szolgáló) n számot hagyja a vermen (17.3.).BL ( --- c )
A szóköz kódját adó konstans (8.4.).BLANKS ( cím hossz --- )
A cím-en kezdődő, hossz hosszúságú memóriaterületet szóközzel tölti fel (7.1. e. feladat).BLK ( --- cím )
User változó, az éppen interpretált blokk számát tartalmazza. Ha 0, akkor az interpreter a parancspufferből dolgozik (13.1.).BLOCK ( n --- cím ) Az n-edik blokkot tartalmazó diszkpuffer címét adja. Ha a blokk nincs a memóriában, akkor beolvasódik, mégpedig abba a pufferbe, amelyre a legrégebben hivatkoztunk utoljára. Ha a blokk beolvasására kiszemelt pufferben módosított blokk volt, akkor ez előbb kikerül a lemezre. Ld. még BUFFER, UPDATE, FLUSH (13.1.).
BRANCH
A feltétel nélküli elágazást megvalósító futó szó. Az utána jövő mezőbeli paraméterrel növeli azt a címet, ahol a címinterpreter a munkáját folytatja (a paraméter negatív is lehet, ez mutatja a visszafelé ugrást). Az ELSE, az AGAIN és a REPEAT fordítja (17.1.).BUFFER ( n --- cím )
A soron következő diszkpuffert az n-edik blokkhoz tartozóként könyveli el. Ha a puffer előző tartalma módosított volt, akkor az kiíródik a lemezre. Az n-edik blokk beolvasása nem történik meg. A kapott cím a puffer első adattárolásra szolgáló címe.BYE
Kilépés a FORTH interpreterből. A módosított blokkokat kiírja kilépés előtt (a FLUSH szót hajtja végre), de megerősítést nem vár.C! ( b cím --- )
A b 8 bitjét tárolja a megadott címen (7.1.).C, ( b --- )
A b 8 bitjét a szótár következő szabad byte-jában tárolja, a szótármutató értékét növeli (9.3.).C/L ( --- b )
Rendszerkonstans. A kernyő sorainak hosszát adja (karakterekben), azaz a fig-Forth-nál 64-et (13.2.).C@ ( cím --- b )
A cím 8 bites tartalmát adja (7.1.).CFA ( pmc --- kódmezőcím )
Egy szótári szó paramétermező-címéből előállítja a kódmezőcímet (12.1.).CMOVE ( honnan hová hányat --- )
A megadott számú byte-ot a honnan címről a hová címre mozgatja. Az alacsonyabb címen levő byte-ok íródnak át először (7.1.c. feladat).COLD
Az ún. hidegindítás. A szótárat a minimális szabványra állítja és ABORT-tal újraindít. Terminálról hívható, programjaink törlésére és a rendszer újraindítására (1.3., 18.).COMPILE
Amikor a COMPILE-t tartalmazó szó végrehajtódik, a COMPILE-t követő szó kódmezőcíme a szótárba fordítódik. Ezzel kezelhetünk bizonyos különleges fordítási szituációkat (16.3.).CONSTANT ( n --- )
Definiáló szó, így használjuk:
n CONSTANT cccc
Az így létrehozott cccc nevű szó paramzőjében az n szám van. Ha ezek után a cccc szó végrehajtódik, az n értéket a veremre teszi (8.4.).CONTEXT ( --- cím )
User változó; egy mutatót tartalmaz a kereső szótárra.COUNT ( cím1 --- cím2 hossz )
A cím1-en kezdődő FORTH-füzér szövegének címét (ami nem más, mint cím1+1) és a szöveg hosszát (a cím1-en levő hosszúságbyte tartalmát) adja. A COUNT-ot általában a TYPE előtt használják (10.1.).CR ( --- )
Egy kocsivissza és egy soremelés karaktert ír a ki-készülékre (1.).CREATE
Definiáló szó, így használjuk:
CREATE cccc
A létrehozott cccc szó kódmezője a szó paramzőcímét tartalmazza, a paramző üres (a CREATE után tetszésünk szerint feltölthetjük). Az új szó a láncoló szótárban jön létre. A definíciót a ; szóval zárhatjuk le.CURRENT
User változó, annak a szótárnak a mutatóját tartalmazza, amelybe az újonnan definiált szavak kerülnek.CSP ( --- cím )
User változó a veremmutató értékének átmeneti tárolására. Fordítás alatti hibaellenőrzésre használjuk (17.2.).D+ ( d1 d2 --- d-összeg )
A két duplaszavas érték duplaszavas összegét adja (6.).D+- ( d1 n --- d2 )
Ha n negatív, d2=-d1, ha nem, d2=d1.D. ( d --- )
Kiírja a d duplaszó értékét a ki-készülékre, utána egy szóközt. A verem felső eleme a nagyobb helyértékű rész. A konverzió a BASE értékének megfelelően történik (6.3.).D.R ( d n --- )
Kiírja a d duplaszavas értéket egy n hosszúságú mezőben jobbra igazítva (6.3.).DABS ( d --- ud )
A d duplaszó ud abszolút értékét adja (6.3.).DECIMAL ( --- )
A BASE értékét 10-re állítja (így a számok kiírása és beolvasása tízes számrendszerben történik) (8.2.1.).DEFINITIONS
Így használjuk:
cccc DEFINITIONS
A láncoló szótárat hozzáigazítja a kereső szótárhoz. A cccc szótárnév végrehajtása a cccc-t teszi kereső szótárrá, a DEFINITIONS után pedig a láncoló szótár is a cccc lesz (12.2.).DIGIT
( c n1 --- n2 igaz ) (sikeres konverzió)
( c n1 --- hamis ) (sikertelen konverzió)
A c karakterkódot az n1 alapszám szerint az n2 bináris megfelelőjére konvertálja. Ha a konverzió sikerült, egy igaz jelzőt ad. Ha a konverzió nem lehetséges, csak egy hamis jelzőt kapunk.DIGIT ( --- b )
Rendszerváltozó. Az utolsó lemezművelet eredményét jelzi. 0 esetén nem volt hiba.DISK-ERROR
DLITERAL
( d --- d ) (végrehajtási állapotban)
( d --- ) (fordításkor)
Fordításkor a vermen talált duplaszavas értéket duplaszavas literálnak fordítja. A lefordított szó futáskor majd a veremre teszi a d számot. Végrehajtási állapotban nincs hatása (16.4.).DMINUS ( d1 --- d2 )
A duplaszavas d1 helyett a (duplaszavas) 1-szeresét adja vissza (6.).DO
( n1 n2 --- ) (futáskor)
( --- cím n ) (fordításkor)
Kettőspontos definícióban használjuk:
DO .. LOOP
DO ... +LOOP
Futáskor a DO egy indexes ciklust indít, amelynek ciklushatára n1, a cindex kezdőértéke pedig n2. A DO ezeket az értékeket eltávolítja a veremről. Mikor a LOOP-hoz ér a program, a cindex eggyel nő. A program a LOOP-tól addig megy mindig a DO utánra vissza, míg a cindex el nem éri vagy meg nem haladja a ciklushatárt. A ciklus befezése a cindex és a ciklushatár eltávolítását is jelenti, n1-et és n2-t futáskor kell megadni, ezek más műveletek eredményei is lehetnek. A ciklusmagon belül a cindex aktuális értékét az I szóval másolhatjuk a veremre. Ld. I, LOOP,+LOOP. LEAVE (4.2., 4.7.).
Fordításkor a (DO) futó szót fordítja, a ciklusmag elejének címét és a fordításkori hibaellenőrzést szolgáló n értéket hagyja a vermen.DOES>
A <BUILDS szóval együtt használjuk. Ld. <BUILDS (15.).DP ( --- cím )
User változó, a szótármutató. A szótár fölötti első szabad memóriacímre mutat. Értéke a HERE szóval olvasható, az ALLOT szóval változtatható (9.1.).DPL ( --- cím )
User változó, a NUMBER által utoljára olvasott szám tizedespont utáni jegyeinek számát tartalmazza. Ha nem volt tizedespont, az értéke - 1. (11.2.).DR0
A 0 sorszámú lemezmeghajtót teszi aktuálissá.DR1
Az 1 sorszámú lemezmeghajtót teszi aktuálissá. A DR0 és a DR1 Szó a kernyő-file elérési útját nem módosítja, csak az OFFSET változó tartalmát.DROP ( n --- )
Eltávolítja a verem legfelső elemét (1.5.).DUP ( n --- n n )
Megkettőzi a verem legfelső elemét (1.5.).ELSE ( cím1 n1 --- cím2 n2 ) (fordításkor)
Kettőspontos definícióban használjuk:
IF ... ELSE ... ENDIF.
Futáskor az ELSE az IF-et követő igaz ág végét jelzi. Az igaz ág végéről az ENDIF utánra ugrik. Veremhatása nincs (3.2.). Fordításkor a BRANCH szót fordítja, helyet foglal az ugrási cím számára, a hamis ág cím2 címét és a fordításkori hibaellenőrzést szolgáló n2 számot hagyja a vermen. Az IF fordította ugrás címét a cím1 és HERE értékekből számítja, és a kapott relatív címet cím1-en tárolja (17.4.).EMIT ( c --- )
A c kódú karaktert kiírja a ki-készülékre (1.). Az OUT változó értékét eggyel növeli (ld., 8.2.2.).EMPTY-BUFFERS
Valamennyi blokkpuffert üresnek könyveli el, esetleg anélkül, hogy tartalmát megváltoztatná. A módosított blokkok nem íródnak ki. A lemez első használata előtti inicializáló eljárásként is szolgál (13.1.).ENCLOSE ( cím1 c --- cím1 n1 n2 n3 )
A WORD által hívott szövegelemző primitiva. A vermen kapott c a határolókarakter, cím1 az elemzendő szöveg kezdőcíme. A visszaadott n1, n2, n3 címek a cím1-hez képest relatívak, n1 a cím1 utáni első, c-től különböző karakter címe, n2 az n1 címen kezdődő szöveg utáni első határolókarakteré, n3 az első nem elemzett karakteré. A bináris nullát a szó a c értékétől függetlenül határolókaraktemek tekinti.END
Az UNTIL szinonimája.ENDIF ( cím n --- ) (fordításkor)
Kettőspontos definícióban használjuk:
IF ... ENDIF
IF ... ELSE ... ENDIF
Futáskor az ENDIF az IF-től vagy az ELSE-től való ugrás helyét jelöli ki. A THEN az ENDIF szinonimája. Ld. még IF és ELSE (3.1.). Fordításkor az ENDIF kiszámítja a cím-tői a HERE-re való előreugrás relatív címét és a cím-en tárolja. Az n szám a fordításkori hibaellenőrzést szolgálja (17.4.).ERASE ( cím n --- )
A cím-től kezdve n byte-ot nulláz (7.1.e. feladat).ERROR ( n --- in blk )
Hibajelzést ad és újraindítja a rendszert. A végrehajtott eljárás a WARNING értékétől függ. Ha a WARNING 1, a 4. kernyő 0-adik sorától számított n-edik sor íródik ki hibaüzenetként. (Az n negatív is lehet, túl is mutathat a 4. kernyőn.) Ha a WARNING 0, az n szám íródik ki hibaüzenetként (nincs virtuális memória). Ha a WARNING -1, az (ABORT) szó hajtódik végre, amely az ABORT-ot hívja. Az (ABORT) működését a programozó megváltoztathatja (14.4.3.). Az IN és BLK rendszerváltozók értéke a veremre kerül, így a hiba lokalizálható. A rendszer újraindítása a QUIT szóval történik. (13.3.)EXECUTE ( cím --- )
Végrehajtja a szót, amelynek kódmezőcíme a vermen van (14.4.1.).EXPECT ( cím karakterszám --- )
Karaktereket olvas be a terminálról a cím-re a kocsivisszáig vagy a megadott karakterszám eléréséig. A szöveg végére egy vagy több bináris 0 kerül (7.1.).EXTEND
FCB
FENCE ( --- cím )
User változó. Azt a címet tartalmazza, amelynél alacsonyabb címről a FORGET nem törölhet (a szótár védett).FILL ( cím hossz b --- )
A memóriát a cím-től hossz darab b értékű byte-tal tölti fel (7.1.d. feladat).FIRST ( --- n )
Konstans; a legelső blokkpuffer címét adja.FLD ( --- cím )
User változó; a FIG-FORTH nem használja.FLUSH
Kiírja lemezre az összes módosított blokkot.FORGET
Így használjuk:
FORGET cccc
Törli a cccc nevű szótárelemet az összes felette levővel együtt. Ha a kereső és láncoló szótár nem egyezik meg, hibajelzést kapunk. (1.3.)FORTH
Az elsődleges szótár neve. Végrehajtása a FORTH-ot teszi kereső szótárrá. A FORTH szó azonnali, így fordításkor végrehajtódik. (12.2.)HERE ( --- cím )
A szótár feletti első szabad byte címét adja (9.1.).HEX ( --- )
A konverziók alapszámát 16-ra (hexadecimálisra) állítja (8.2.1.).HLD ( -- cím )
User változó. Számok karaktersorozattá konvertálásakor az utoljára konvertált karakter címét tartalmazza.HOLD ( c --- )
Számok karaktersorozattá konvertálásakor, a <# és #>szó között használjuk. Az output karaktersorozatba beíra a c kódú karaktert; pl. 2E HOLD egy tizedespontot tesz ki (11.1.).I ( --- n )
DO ... LOOP ciklusban használjuk; a cindex értékét a veremre teszi (4.1., 4.4.).ID. ( cím --- )
Kiírja a szótárelem nevét, amelynek a névmezőcíme a vermen van (12.1.).IF
( f --- ) (futáskor)
( --- cím n ) (fordításkor)
Kettőspontos definícióban használjuk:
IF (igaz rész) ... ENDIF IF (igaz rész) ... ELSE (hamis rész) ENDIF
Futáskor az IF a kapott jelző alapján eldönti, hogy az igaz rész vagy a hamis rész hajtódjék végre. Ha a kapott jelző igaz, az igaz rész fut le, ha nem, az ELSE utáni hamis rész (ha van). Mindkét esetben az ENDIF után folytatódik a program. Ha az ELSE rész hiányzik és a kapott jelző hamis, az IF-től egyenesen az ENDIF utánra kerül a vezérlés (3.1., 3.2.). Fordításkor a 0BRANCH-ot fordítja és helyet hagy az ugrási címnek. A cím és n az ugrási cím későbbi befordításához, ill. fordításkori hibaellenőrzéséhez kell (17.4.).IMMEDIATE
Azonnalivá teszi az utoljára definiált szót (beállítja a precedencíabitjét). Ez azt jelenti, hogy ha az azonnali szót definícióban használjuk, akkor fordításkor fog végrehajtódni, és nem fordítódik bele az új szóba. Azonnali szavakat a [COMPILE] szóval fordíthatunk le. (16.2.)IN ( --- cím )
User változó; annak a szövegnek a (parancspuffer vagy blokk-puffer elejéhez képest relatív) címét tartalmazza, amelyet a WORD legközelebb olvas majd. Az IN értékét a WORD használja és állítja (13.1.).INDEX ( tói ig --- )
A két határ között kiírja a kernyők első sorait (amelyek konvenció szerint a kernyő tartalmára utaló kommentek) (2.5.).INTERPRET
A külső szöveginterpreter, amely a befolyam (terminálról vagy diszkről érkező) szavait a STATE-nek megfelelően végrehajtja vagy lefordítja. Ha a szót a
szótárban nem találja, a BASE értékének megfelelően konvertálja. Ha ez sem megy, hibajelzést kapunk. A szöveget a WORD tagolja szavakra. Ha egy szám tizedespontot tartalmaz, duplaszavassá konvertálja; a tizedespontnak más hatása nincs (ld. NUMBER). (18.)KEY ( --- c )
A terminálon következőnek leütött billentyű kódját adja (2.1.).LATEST ( --- cím )
A láncoló szótár legfelső elemének névmezőcímét adja (12.1.).LEAVE
DO ... LOOP vagy DO ... +LOOP ciklusban használjuk. A ciklushatár értékét a cindexéhez igazítja, ezzel elérve, hogy a legközelebbi LOOP-nál vagy +LOOP-nál véget érjen a ciklus. A cindex értéke változatlan marad (4.6.).LFA ( pmc --- láncmezőcím )
Egy szótárelem paramezőcíméből adja a láncmezőcímét (12.1.).LIMIT ( --- cím )
Konstans; az utolsó diszkpufferként elérhető memóriacímet adja. Általában a rendszer számára is ez a legmagasabb memóriacím.LIST ( n --- )
Kiírja a ki-készülékre az n-edik kernyő szövegét. Az SCR változó a LIST után a kilistázott kernyő számát fogja tartalmazni (2.5., 13.2.).LIT ( --- n )
Kettőspontos definícióban, 16 bites szám lefordítása előtt az interpreter a LIT-et fordítja. Futáskor a LIT a mögötte levő mezőbeli paramétert a veremre teszi (16.4.).LITERAL
( n --- ) (fordításkor)
( n --- n ) (végrehajtási állapotban)
Fordítási állapotban a vermen talált értéket 16 bites literálnak fordítja. (A szó azonnali, így fordításkor hajtódik végre.) Tipikus használata a következő.
: xxxx [ számítások ] LITERAL ... ;
(A fordítás a számítások idejére felfüggesztődik.) Végrehajtási állapotban nincs hatása (16.4.).LOAD ( n --- )
Az n-edik kernyőt kezdi el interpretálni. Az interpretálás (a kernyő betöltése) a kernyő végén vagy a ;S szó hatására ér véget. Ld. ;S és --> (2.5., 18.).LOOP ( cím n ---) (fordításkor)
Kettőspontos definícióban használjuk:
DO ... LOOP
Futáskor a LOOP a cindex és a ciklushatárértékéből eldönti, hogy visszamenjen-e a vezérlés a DO-ra. A cindex-et 1-gyel növeli és összehasonlítja a ciklushatárral. Addig megy vissza a DO-ra, amíg a cindex el nem éri vagy meg nem haladja a ciklushatárt. Ha elérte, a cindexet és a ciklushatárt eldobja, a programot továbbengedi (4.2.). Fordításkor a (LOOP) szót fordítja, a címet a DO-ra való visszaugrás címének kiszámítására használja. Az n a fordításkori hibaellenőrzést szolgálja.M* ( n1 n2 --- d )
Kevert művelet: két egyszavas érték duplaszavas szorzatát adja (6.).M/ ( d n1 --- n2 n3 )
Kevert művelet: a d/n1 osztás előjeles n2 maradékát és n3 hányadosát adja (6.).M/MOD ( ud1 u2 --- u3 ud4 )
Előjel nélküli kevert művelet: az ud1/u2 osztás u3 maradékát és ud4 duplaszavas hányadosát adja (6.).MAX ( n1 n2 --- max )
A két szám nagyobbikát adja (1.)MESSAGE ( n --- )
Kiírja a ki-készülékre a 4. kernyő 0-adik sorától számított n-edik kernyősort (n lehet negatív is). Ha a WARNING 0 (mert pl. nincs virtuális memória), csak az n számot írja ki (13.3.).MIN ( n1 n2 --- min )
A két szám közül a kisebbiket adja (1.).MINUS ( n1 --- n2 )
n2 = -n1 (1.).MOD ( n1 n2 --- mod )
Az n1/n2 osztás maradékát adja, n1 előjelével.NFA ( pmcím --- névmezőcím )
Egy szótárelem paramzőcíméből a névmező címét adja (12.1.).NOOP ( --- )
Nincs műveletvégzés (üres szó).NUMBER ( cím --- d )
A cím-en kezdődő FORTH-füzért egy előjeles, duplaszavas értékké konvertálja (a BASE értékének megfelelően). Ha a szöveg tar-talmazott tizedespontot, akkor ennek pozíciója megőrződik a DPL változóban, de a tizedespontnak más hatása nincsen. Ha a konverzió nem lehetséges, hibajelzést kapunk (11.2.).OFFSET ( --- cím )
OR ( n1 n2 --- or )
Bitenkénti megengedő vagy logikai művelet (2.3.).OUT ( --- cím )
User változó, az EMIT növeli. A programozó változtathatja vagy vizsgálhatja, hogy a kiírás formátumát vezérelje (8.2.2.).OVER ( n1 n2 --- n1 n2 n1 )
A verem második elemét a verem tetejére másolja (1.5.).P! (b b2 --- )
b1 értéket a b2 számú Z80-as portra írja.P@ ( b1 --- b2 )
b1 számú Z80-as port értékét b2-be olvassa.PAD (--- cím )
A szövegtárolásra használt puffer címét adja; ez a puffer a HERE-től állandó távolságra van (7.1., 9.1.).PFA ( névmezőcím --- paramzőcím )
Egy szótári szó névmezőcíméből a paramzőcímet adja (12.1.).PREV ( --- cím )
Változó; az utoljára hivatkozott blokkpuffer számát tartalmazza. Az UPDATE parancs ezt a puffert fogja módosítottnak jelölni (13.1.).QUERY
Beolvas a terminálról egy sort az ENTER megnyomásáig, de maximum 80 karaktert. A szöveget a TIB által tartalmazott címre teszi, az IN változót 0-ra állítja (18.).QUIT
Kiüríti a virmet, leállítja a fordítást és visszaadja a vezérlést a terminálra (7.3., 18.).R ( --- n )
A virem legfelső elemét a veremre másolja (4.1.).R/W ( cím b1 b2 --- )
Ez a fig-FORTH blokk író-olvasó szava. Ha b2=0, akkor írunk a lemezre, egyébként olvasunk. A b1 jelöli az átvinni kívánt blokk sorszámát, a cím pedig az átvitelhez felhasználandó puffer kezdőcíme.R# ( --- cím )
User változó, az editorok használják a kurzorpozíció tárolására.R> ( --- n )
A virem legfelső elemét a veremre teszi. Ld. >R és R (4.1.).R0 ( --- cím )
User változó, a viremmutató kezdeti értékét tartalmazza.REPEAT ( cím n --- ) (fordításkor)
Kettőspontos definícióban használjuk:
BEGIN ... WHILE ... REPEAT
Futáskor a REPEAT feltétel nélkül visszaadja a vezérlést a BEGIN utánra (5.3.).ROT ( n1 n2 n3 --- n2 n3 n1 )
A verem harmadik elemét felülre teszi (1.5.).RP!
A viremmutatót inicializálja az, R0 változóban őrzött értékkel.RP@ ( --- cím )
Azt a memóracímet adja, ahová a virem-mutató pillanatnyilag mutat.S->D ( n --- d )
Az n előjeles szám duplaszavas megfelelőjét adja.S0 ( --- cím )
User változó, a veremmutató kezdeti értékét tartalmazza (ld. SP!) (7.3.).SCR ( --- cím )
User változó; az aktuális (a LIST-tel legutoljára listázott) kernyő számát tartalmazza (13.2., 13.4.).SIGN ( n d --- d )
Számok karaktersorozattá konvertálásakor, a <# és #> szavak között használjuk. Ha n negatív, akkor beilleszt egy - jelet az output karaktersorozatba. Az n-et eltávolítja a veremről, de a fölötte levő duplaszót békén hagyja (11.1.).SMUDGE
Az ún. "smudge bit" állítására szolgál. A "smudge bit" a szavak névmezőjében a hosszúságbyte 3. bitje. Ezzel lehet a definíció végén érvényesíteni a szavakat, így a be nem fejezett definíciók érvénytelenek, az interpreter nem is találja meg őket.SP!
A veremmutatót inicializálja az S0-ban tárolt értékkel.SP@ ( --- cím )
A veremmutató (SP@ végrehajtása előtti) értékét adja (pl. 1 2 SP@ @ . . . eredménye: 2 2 1 ) (7.3.).SPACE
Egy szóközt ír a ki-készülékre (1.).SPACES ( n --- )
n db szóközt ír a ki-készülékre (4.3.).STATE ( --- cím )
User változó, a rendszer fordítási vagy végrehajtási állapotát jelzi. A nem 0 érték fordítást jelent (16.1.).SWAP ( n1 n2 --- n2 n1 )
Megcseréli a verem két felső elemét (1.5.).TASK
Üres szó, az egyes alkalmazások elkülönítésére használjuk. Ha a TASK-ot saját szavaink előtt fordítjuk, akkor szavainkat (az alkalmazást) egyszerre törölhetjük, a TASK FORGET-tel való elfelejtésével.THEN
Az ENDIF szinonimája.TIB ( --- cím )
User változó, a parancspuffer címét tartalmazza (13.1.).TOGGLE ( cím b --- )
Komplementálja a cím tartalmát a b bitminta szerint.TRAVERSE ( cím1 n --- cím2 )
Átlépi egy FORTH szó névmezőjét. A cím1 a névmező hosszúságbyte-jának vagy utolsó betűjének címe. Ha n=1, akkor a névmező elejéről a végére, ha n=-1, akkor a végéről az elejére megyünk. A visszaadott cím2 a névmező másik végének címe.TRIAD ( kernyősz --- )
3 kernyőt listáz a ki-készülékre: ezek között szerepel a megadott számú is, az elsőnek a száma pedig osztható 3-mal. Mivel általában ennyi fér el egy sornyomtató lapra, formatált listát nyerhetünk. Ha a ki-készülék nem sornyomtató, az egyes kernyők listázása tetszőleges billentyű megnyomásával megszakítható.TYPE ( cím karakterszám --- )
A cím-től kezdve a megadott számú karaktert kiírja a ki-készülékre (7.1.; 7.1.b. feladat).U* ( u1 u2 --- ud )
Két előjel nélküli szám duplaszavas, előjel nélküli szorzatát adja (6.).U. ( u --- )
Kiírja a vermen talált előjel nélküli értéket a képernyőre, utána pedig egy szóközt (6.1.).U/ ( ud u1 --- u2 u3 )
Az ud/u1 osztás u2 maradékát és u3 hányadosát adja. Valamennyi érték előjel nélküli, ud duplaszavas (6.).U< ( u1 u2 --- f )
Összehasonlítja a két vermen talált előjel nélküli értéket. f igaz, ha u1< u2.UNTIL
( f --- ) (futáskor)
( cím n --- ) (fordításkor)
Kettőspontos definícióban használjuk:
BEGIN ... UNTIL
Futáskor az UNTIL feltételesen (a kapott jelző hamis értékénél) visszaadja a vezérlést a BEGIN utánra; ha a kapott jelző igaz, továbbmegy (5.2.). Fordításkor a 0BRANCH-et fordítja és a HERE-től a cím-re való elágazás címét. Az n a fordítás alatti hibaellenőrzést szolgálja (17.3.).UPDATE
Az utoljára hivatkozott blokkot (amelynek száma a PREV változóban van) módosítottnak jelöli meg. Ha a blokkot tartalmazó puffer ezután másik blokk tárolására fog kelleni, akkor a blokk kiíródik a lemezre (13.1.).USE ( --- cím )
Változó. A következőnek felhasználandó blokkpuffer számát tartalmazza (amelyik pufferbe a legrégebben írtunk).USER ( n --- )
Definiáló szó, így használjuk:
n USER cccc
Ezzel egy cccc user változót hozunk létre. A cccc paramzőjébe n kerül; n a user változó relatív címe a user változók táblázatának az elejéhez képest. Ha cccc ezek után végrehajtódik, a változó címét (a táblázat címének és n-nek az összegét) teszi a veremre (14.3.).VARIABLE ( n --- )
Definiáló szó, így használjuk:
n VARIABLE cccc
A VARIABLE egy cccc szót hoz létre, amelynek paramzőjét n-re inicializálja. Ha ezek után cccc végrehajtódik, a paramzőcíme kerül a veremre. Így kiolvashatjuk vagy megváltoztathatjuk a változó értékét (8.3.).VLIST
Kiírja a kereső szótár neveit. Tetszőleges billentyű lenyomása) hatására a listázás félbeszakad (1.1., 12.1.).VOC-LINK ( --- cím )
User változó, az utoljára definiált szótárra tartalmaz mutatót. A szótárnevek össze vannak láncolva.VOCABULARY
Definiáló szó, így használjuk:
VOCABULARY cccc
Ezzel egy cccc szótárat hozunk létre, cccc végrehajtása őt magát teszi kereső szótárrá, a
cccc DEFINITIONS
sorozat cccc-t láncoló szótárrá is teszi. A cccc tartalmazza annak a szótárnak a szavait, amelyben cccc-t létrehoztuk. így valamennyi szótár tartalmazza a FORTH szótár szavait. A szótárneveket azonnalinak szokás definiálni. (12.3.)WARM
Az ún. melegindítás. Valamennyi blokkpuffert üresnek könyveli el, a módosított blokkok így nem íródnak ki. Kiüríti a vermet és a virmet, majd végrehajtási állapotba tér.WARNING ( --- cím )
User változó, a hibaüzenetek kiírását vezérli. Ha értéke 1, és van virtuális memória akkor a 4. kernyő elejétől vannak a hibaüzenetek. Ha 0, a hibaüzenet a hibát csak a számával azonosítja. Ha -1, az (ABORT) szót (felhasználó definiálta megszakítás, 14.4.3.) hajtja végre. Ld. MESSAGE, ERROR (13.3.).WHILE
( f --- ) (futáskor)
( cím1 n1 --- cím1 n1 cím2 n2 ) (fordításkor)
Kettőspontos definícióban használjuk.
BEGIN ... WHILE (igaz rész) ... REPEAT
Futáskor a WHILE cselekménye a kapott jelzőtől függ. Ha a jelző igaz, továbbengedi a programot az igaz részre, amely a REPEAT-ig tart. A REPEAT visszaadja a vezérlést a BEGIN utánra. Ha a jelző hamis, a vezérlés a REPEAT utánra adódik. Fordításkor a WHILE a 0BRANCH-et fordítja és az ugrási cím cím2 címét teszi a veremre. Ennek segítségével fogja a REPEAT az ugrási címet befordítani.WIDTH ( --- cím )
User változó, a maximális szóhosszat tartalmazza. Ez 1 és 31 között lehet; ha nem teszünk semmit, értéke 31.WORD ( c --- )
Beolvassa az interpretálandó karaktersorozat (befolyam) következő részletét a c határolókarakterig. A beolvasott részt FORTH-füzér formájában a HERE címre teszi. A szöveg végére egy vagy több szóközt fűz. A beolvasandó szöveg előtti c karaktereket nem veszi figyelembe. Ha a BLK értéke 0, a szöveget a parancspufferből, ha nem, a BLK-bán tárolt számú blokkból veszi. Ld. BLK, IN (10.; 13.1.).XOR ( n1 n2 --- xor )
A két érték közti bitenkénti kizáró VAGY művelet eredményét adja (2.3.).
A Forth Extensions bővítmény szavai:
2DROP ( d --- )
Eltávolítja a verem tetején lévő duplaszót (6.1. feladat).2OVER ( d1 d2 --- d1 d2 d1 )
A verem második duplaszavát a verem tetejére másolja (6.1. feladat).2ROT ( d1 d2 d3 --- d2 d3 d1 )
A verem harmadik duplaszavát a felülre teszi (6.1. feladat).2SWAP ( d1 d2 --- d2 d1 )
Megcseréli a verem két felső duplaszavát (6.1. feladat)..STACK ( --- )
Kilistázza a verem tartalmát. A .STACK nem változtatja meg a vermet (1.6., 7.3.)CASE ... OF ... ENDOF ... ENDCASE
Egy értéktől függő vezérlési szerkezet (17.5.)CLS ( --- )
Törli a képernyőt. (12-es karakterkódot küld ki a ki-készülékre.)D- ( d1 d2 --- d-kölünbség )
A d1 és d2 duplaszó különbségét (d1-d2) adja (6.2. feladat).D= ( d1 d2 --- f )
A kapott jelző igaz, ha d1 és d2 duplaszó egyenlőek (6.2. feladat).D< ( d1 d2 --- f )
A kapott jelző igaz, ha d2 duplaszó nagyobb mint d1 duplaszó (6.2. feladat).DEPTH ( --- n )
A verem tetejére teszi a verem elemeinek (a DEPTH végrehajtása előtti) számát (1.6., 7.3.)FREE ( --- )
Kiírja a még felhasználható szabad memória méretét byte-okban.INK ( b --- )
A tinta színét állítja be b értékének megfelelően (Ld. IS-DOS Felhasználói kézikönyv).J ( --- n )
A külső cindexet a veremre teszi (4.4., 4.5.).PICK ( n1 --- n2 )
A verem tetejére másolja a verem n1-edik elemét (1.6., 7.3.)RND ( n --- )
0 és n-1 közötti véletlenszámot tesz a verembe.ROLL ( n --- )
Kiszedi a verem n-edik elemét és a verem tetejére teszi (1.6., 7.3.).SN (n1 --- n2)
-1-et ad a vermen, ha n1 negatív, +1-et, ha pozitív és 0-t, ha nulla.
| Hibasorszám | Hibaüzenet | |
| dec | hex | |
| 0 | 0 | ? Nincs ilyen szó a szótárban. |
| 1 | 1 | empty stack Üres a verem. |
| 2 | 2 | dictionary full Nincs több hely a szótárban. |
| 3 | 3 | has incorrect address mode Rossz címzési mód. |
| 4 | 4 | isn't unique Van már ilyen név a szótárban. |
| 5 | 5 | |
| 6 | 6 | disc range? Nincs ilyen blokk a virtuális memóriában. |
| 7 | 7 | full stack Megtelt a verem. |
| 8 | 8 | disc error! Diszkhiba. |
| 9 | 9 | |
| 10 | A | |
| 11 | B | |
| 12 | C | |
| 13 | D | |
| 14 | E | |
| 15 | F | |
| 16 | 10 | |
| 17 | 11 | compilation only, use in definition Csak definícióban használható. |
| 18 | 12 | execution only Csak végrehajtási állaőotban használható. |
| 19 | 13 | conditionals not paired A vezérlési struktúrák kulcsszavainak párosítása nem megfelelő. |
| 20 | 14 | definition not finished Befejezetlen definíció. |
| 21 | 15 | in protected dictionary A szótár védett részében van. |
| 22 | 16 | use only when loading Csak betöktéskor használható. |
| 23 | 17 | off current editing screen Nincs az aktuális kernyön. |
| 24 | 18 | declare vocabulary |
A 0. sorszámú hibához nem tartozik hibaüzenet, ezt akkor kapjuk, ha olyan szóval próbálkozunk, ami nincs a szótárban és számként sem értelmezhető.
C) Függelék
A szövegszerkesztő (editor)
A Ragsdale-féle ditor maga is FORTH-ban íródott, így használat előtt be kell tölteni a virtuális memóriából. Az editor - a konvenciók szerint - a 7. kernyőtől kezdődik, az editor 2.0-ás változata 5 kernyőt foglal el. Ezért betöltése a
7 LOAD
utasítással lehetséges. Az editor először betölti a FORTH Extensions bővítményt (melynek szavait az A függelék végén ismertettünk), létrehozza a saját szótárát, ebbe definiálja az editor szavait, végül a WARNING rendszerváltozót 1-be állítja (bekapcsolja a hibaüzenetek kijelzését. (Megjegyzés: a FORTH Extensions-t az editor betöltése nélkül is használhatjuk, ilyenkor a 17-es kernyőtől kell betöltenünk.)
Az editor szavai:
TEXT ( c --- )
A c határolókarakterig beolvassa a befolyam szövegét és elhelyezi az előzőleg szóközzel feltöltött pad-ben.LINE ( n --- cím )
Az aktuális kernyő n-edik sorának címét adja.WHERE ( blk in --- )
Az ERROR által hátrahagyott paraméterek felhasználásával kiírja a hibát tartalmazó kernyő és sor számát, valamint a hibás sort.#LOCATE ( --- spoz sorsz )
Az aktuális karakterpozíció adatait adja: a karaktert tartalmazó sor számát (sorsz), és, hogy a soron belül hányadik karakterről van szó (spoz).#LEAD ( --- sorcím spoz )
Az aktuális karakterpozíció adatait adja: a karaktert tartalmazó sor memóriacímét és, hogy a soron belül hányadik karakterről van szó.#LAG ( --- karcím sorhossz )
Az aktuális karakterpozíció memóriacímét (karcím) és a karaktertől az őt tartalmazó sor végéig levő karakterek számát (sorhossz) adja.-MOVE ( cím sorsz --- )
A cím-en levő sort beírja az aktuális kernyő megadott számú sorába.
Az eddig ismertetett szavakat az editor többi szavai használják, a felhasználónak nem javasolt a használatuk. Az editor "felhasználói" szavai:
B ( --- )
Az aktuális karakterpozíciót visszahúzzuk a pad-ben levő szöveg hosszával.C ( --- )
A befolyam következő sorában megadott szöveget az aktuális karakterpozíció után szúrja be.D ( sorsz --- )
Törli a megadott számú sort az aktuális kernyőről, de szövegét megőrzi a padben (így azt átmozgathatjuk máshova).E ( sorsz --- )
Az aktuális kernyő megadott számú sorát szóközökkel tölti fel.F ( --- )
A befolyam következő sorát keresi az aktuális kernyőben.H ( sorsz --- )
Az aktuális kernyő megadott számú sorát a padbe másolja.I ( sorsz --- )
A megadott számú sorba beszúrja a padben levő sort (a többi sort lejjebb tolja).L ( --- )
Az aktuális kernyőt listázza. A lista után kiírja mégegyszer az aktuális sort.M ( n --- )
Az aktuális karakterpozíciót n-nel növeli, kiírja az új pozíciót tartalmazó sort.N ( --- )
A pad-ben levő FORTH-füzér következő előfordulását keresi; kiírja az új karakterpozíciót tartalmazó sort.P ( sorsz --- )
A megadott számú sort a befolyam következő sorával helyettesíti.R ( sorsz --- )
A megadott számú sort a padben levő sorral helyettesíti.S ( sorsz --- )
Az aktuális kernyő sorait a sorsz-adiktól kezdve lejjebb tolja, az n-edik sort szóközzel tölti fel.T ( sorsz --- )
Az aktuális karakterpozíció a megadott számú sor eleje lesz; kiírja az új pozíciót tartalmazó sort.X ( --- )
A befolyam következő sorában megadott szöveget megkeresi az aktuális kernyőben és törli.CLEAR ( kernyőszám --- )
A megadott számú kernyőt feltölti szóközzel és aktuálissá teszi.COPY ( kernyőszám1 kernyőszám2 --- )
Az első kernyő tartalmát átmásolja a másodikba.DELETE ( n --- )
Törli az aktuális karakterpozíció előtti n darab karaktert; a sor végét szóközzel tölti fel.FIND ( --- )
A pad-ben levő FORTH-füzérrel megadott szöveget keresi az aktuális kernyő soraiban. Ha nem találja, hibajelzést ad, és a kernyő eleje lesz az aktuális karakterpozíció. Ha megtalálja, az aktuális karakterpozíció a szöveg vége lesz.TILL ( --- )
A befolyam következő sorában megadott szöveget megkeresi az aktuális karakterpozíciót tartalmazó sorban és törli a kurzor és a szöveg vége közötti részt.TOP ( --- )
Az aktuális karakterpozíció a kernyő első karaktere lesz.TS ( --- )
Az aktuális kernyőt listázza.1LINE ( --- f )
Az aktuális kernyő aktuális karakterpozíciót tartalmazó sorában, az aktuális karakterpozíció után keresi a pad-beli FORTH-füzérrel megadott szöveget, f akkor lesz igaz, ha megtalálta; ekkor a megtalált szöveg vége lesz az aktuális karakterpozíció. Ha nem találta meg, f hamis, az aktuális karakterpozíció pedig a sor vége.
Megjegyzés: Egy kernyő azért aktuális, mert az SCR változó annak a sorszámát tartalmazza. A kernyőn belüli karakterpozíció (kurzorpozíció) attól aktuális, hogy a R£ változó annak a sorszámát (a kernyő elejéhez képest relatív címét) tartalmazza.
Gyakorlati tanácsok egy kernyő megszerkesztéséhez:
Először az INDEX szóval keressünk egy nekünk tetsző (üres) kernyőt. Ha egy korábbi kernyő tartalma feleslegessé vált és oda szeretnénk új programot bevinni, a CLEAR paranccsal törölhetjük. Az editor szavai használata előtt ne felejtsük az EDITOR szóval alapértelmezetté tenni annak szótárát!
Ha megvan a kiszemelt kernyő, először aktuálissá kell tennünk, ehhez a legpraktikusabb a LIST szót használni, mert rögtön meg is tekinthetjük annak aktuális tartalmát. Ezután már elég az editor L szavát használnunk az aktuális kernyő listázáshoz. Az aktuális kernyő sorainak bevitelére a P parancsot használhatjuk. Példa a használatára:
0 P : TABLA ( szorzotabla )
1 P 11 1 DO
2 P CR 11 1 DO
3 P I J * 4 .R
4 P LOOP
5 P LOOP CR
6 P ;
Természetesen a sorokat nem kötelező beljebb kezdeni, sőt írhatjuk a szavakat egy sorba, maximum 64 karakter hosszan. Az ennél hosszabb sorok vége elvész, erre nekünk kell figyelnünk! A P is szó, így utána kell egy szóközt hagyni, de ez nem számít bele a sor hosszába. A sorokat természetesen nem kötelező növekvő sorrendben bevinni és hagyhatunk üres sorokat is esetleg az áttekinthetőség kedvéért.
Ha egy sort be szeretnénk utólag valahova szúrni, azt az S szóval érdemes megtenni. Egy sort másolhatunk is a H és az I szavak egymás utáni használatával. Sor átmozgatására a D és az I szavakat használhatjuk egymás után. Nem csak egy kernyőn belül mozgathatunk / másolhatunk, de ekkor a két szó használata között kernyőt is kell váltanunk (célszerűen most is a LIST szó használatával).
D) Függelék
A fig-Forth memóriafelosztása
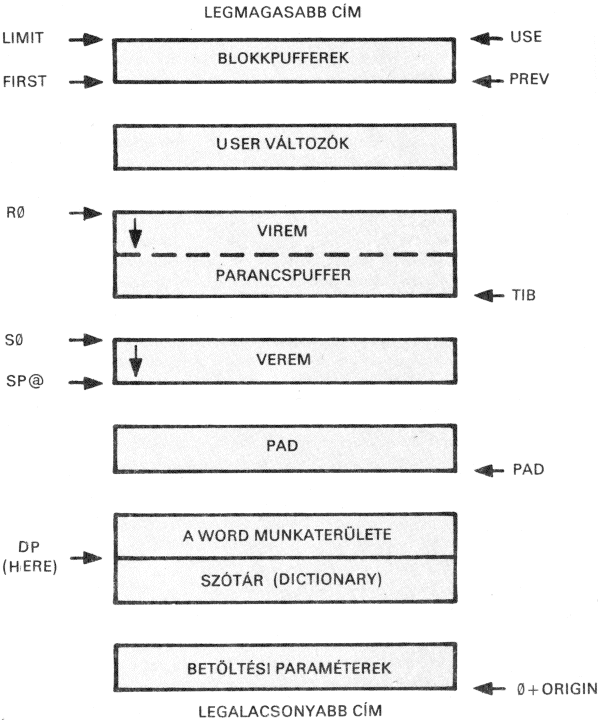
E) Függelék
Szakkifejezések; idegen szavak és fordításaik jegyzéke
adatverem
l. verem
aktuális kernyő
A szövegszerkesztő programokban (editorokban) előforduló fogalom: az a kernyő, amelyet éppen szerkesztünk. Számának tárolására az SCR user változó szolgál, az alapszavak közül a LIST állítja (a kilistázott kernyő számát teszi bele) (13.2.; 13.4.).
azonnali szó (immediate szó)
Olyan szótári szó, amely akkor sem fordítódik le, ha az interpreter kettőspontos definícióban (fordítási állapotban) találkozik vele. Ehelyett rögtön az új szó fordításakor végrehajtódik. Az azonnali szavakat az különbözteti meg, hogy a precedencia-bitjük 1. (16.1.)
befolyam (input stream)
Az a karaktersorozat, amelyet a szöveginterpreter feldolgoz. Ez lehet a terminálról adott parancssor vagy (a LOAD szó végrehajtásakor) egy kernyő szövege. Az interpretálandó karaktersorozat végét bináris 0 jelzi. (2.5., 18.)
belső interpreter
l. címinterpreter.
betöltési paraméter (boot-up parameter, származtatási paraméter, origin parameter)
A rendszer működéséhez szükséges adatok, pl. egyes user változók kezdőértéke, a hidegindítás végrehajtási címe stb. A betöltési paraméterek területéről a +ORIGIN szóval kaphatunk címeket.
bináris
Kettes számrendszerbeli. A számítógép memóriájában programjaink és adataink binárisan vannak tárolva, ezért gyakran egyszerűen a gépi ábrázolás kifejezés helyett használjuk a bináris szót.
blokkpuffer (diszkpuffer)
A virtuális memória blokkjainak tárolására szolgáló puffer (memóriaterület) (13.1.).
boot-up parameter
l. betöltési paraméter.
ciklusindex
l. cindex.
ciklushatár
l. indexhatár.
ciklusszámláló
l. cindex.
címinterpreter (belső interpreter)
Az a program, amely végrehajtja a kettősponttal definiált szavakat: elmegy azokra a címekre, amelyekre a szó paramzőjében talált mutatók küldik és végrehajtja az ott talált szótári szót (ami esetleg a címinterpreter újabb hívását jelenti). (14.1.)
cindex (ciklusindex, ciklusszámláló)
A ciklusmag futásainak számlálója (4.1.).
cold start
l. hidegindítás.
colon definition
l. kettőspontos szó.
compilee
l. fordító szó.
compiling word
l. fordító szó.
context szótár
l. kereső szótár.
current szótár
l. láncoló szótár
decimális
10-es számrendszerbeli,
decompiler
Az a program, amely szótári szavakat fejt vissza, hogy a lefordított szóról megtudhassuk, milyen szavakkal definiálták őket.
definiáló szó
Olyan szó, amely végrehajtódásakor újabb szót hoz létre. Az új szó nevét többnyire a definiáló szó után kell megadni. A definiáló alapszavak a szótárelem létrehozására a CREATE szót hívják. Definiáló alapszavak: : (1.); VARIABLE (8.3.); CONSTANT (8.4.); VOCABULARY (12.3.); <BUILDS (15.).
dictionaiy
l. szótár.
dictionary pointer
l. szótármutató.
diszkpuffer
l. blokkpuffer.
execution address
l. kódmezőcím.
felhasználó által definiált megszakítás
A szabványos megszakítás mellett a felhasználó is definiálhat az igényeinek megfelelő megszakítást (14.4.3.).
fig
FORTH INTEREST GROUP, PO BOX 1105, SAN CARLOS, CA 94070. A bevezetőben van róla szó.
flag
l. jelző
fordítási állapot
Amikor az interpreter fordítási állapotban van (a STATE értéke nem 0), akkor a szótárban megtalált szavakat nem hajtja végre, hanem lefordítja (kivétel: azonnali szavak) (16.1.).
fordítási idő
Az az idő, amikor egy szó fordítása történik (szemben a későbbi, futási idővel, amikor a lefordított szó végrehajtódik).
fordító szó (compilee, compiling word)
Olyan szó, amely más szavak fordításakor tesz a fordítandó szó paramétermezőjébe értékeket, címeket stb. (16.2.).
FORTH-füzér
Karaktersorozat, amelynek első byte-ja (a hosszúság-byte) a sorozat (hosszúság-byte nélküli) hosszát tartalmazza (10.1.).
futási idő
Az az idő, amikor egy szó végrehajtódik (szemben a korábbi fordítási idővel, amikor a szó a szótárban létrejön).
futó szó (runtime procedure)
Olyan szó, amelynek címét egy fordító szó írja be az éppen fordítódó szó paramzőjébe (amely így az éppen fordítódó szó futásakor fog végrehajtódni (16.2.).
füzér (string)
teljes neve: karakterfüzér.
hexadecimális
16-os számrendszerbeli.
hidegindítás (cold start)
A rendszer újraindítása saját szavaink és a diszkpufferek törlésével (18.).
hosszúság-byte
A FORTH-füzér első, a szöveghosszot tartalmazó byte-ja (10.1.), ill. a névmező ehhez hasonló byte-ja. L. névmező, l. a 12.1. szakaszt.
immediate szó
l. azonnali szó.
indexhatár (ciklushatár)
A cindex végértéke, amelynél a ciklus befejeződik (4.2.).
infix jelölésmód
A műveletek megszokott jelölése. Ilyenkor a műveleti jel az operandusok között van, szemben a FORTH postfix jelölésmódjával.
inline paraméter
l. mezőbeli paraméter.
input stream
l. befolyam.
interpreter
A FORTH rendszerben kétféle programot is szokás interpreternek nevezni. Az egyik a külső interpreter vagy szöveginterpreter (l. szöveginterpreter), a másik a belső interpreter vagy címinterpreter (l. címinterpreter).
jelző (flag)
Egy állítás igaz vagy hamis voltát jelző szám. FORTH-ban a 0 érték hamis, bármely már érték igaz (2.1.).
kereső szótár (context szótár)
Az a szótár (vocabulary), amelyben az interpreter a végrehajtandó szavakat keresi. Ilyen szótár mindig csak egy van, azonban bármikor kijelölhetünk helyette egy másikat (12.2.).
kernyő (screen)
A virtuális memóriában tárolt szövegek karbantartásának, betöltésének egysége. Általában 16 darab 64 karakteres sorból áll (2.5.; 13.2.).
kettőspontos szó (colon definition)
A : definiáló szóval létrehozott szó; más FORTH szavak és literálok kombinációja. Első leírása az 1. fejezet elején van. Végrehajtásáról a 14.1. szakasz, a : és ; közötti fordítás különböző módjairól a 16. fejezet szól.
ki-készülék (selected output device)
Az a készülék, amelyre az EMIT és rajta keresztül az összes kiírást végző FORTH alapszó ír. Alapesetben ez a terminál.
kódmező
A szótári szavaknak az a mezője, amely a végrehajtandó programra (pl. címinterpreter) tartalmaz mutatót (9.1.; 12.1.).
kódmezőcím (execution address)
A kódmező címe.
komment
A program szövegéhez fűzött megjegyzés, amelynek nincsen hatása a program végrehajtására. FORTH-ban a kommentet a ( szóval lehet bevezetni és a ) határolóig tart (1.4.).
külső interpreter
l. szöveginterpreter.
láncmező
A szótári szavaknak az a mezője, amellyel a szavak össze vannak láncolva (minden szó láncmezője az őt megelőző szóra tartalmaz mutatót) (9.1.; 12.1.).
láncoló szótár (current szótár)
Az a szótár, amelybe az újonnan definiált szavak kerülnek (12.2.).
literál
Kettőspontos definícióban használt szám (16.4.).
melegindítás (warm start)
A rendszer újraindítása a szótár és a blokkpufferek változatlanul hagyásával.
mezőbeli paraméter (inline parameter)
A kettőspontos szavak paramezőjében tárolt, a futó szavak munkájához szükséges paraméter (16.2.).
módosított blokk (módosított puffer, updated block)
Olyan, a memóriába beolvasott blokkja a virtuális memóriának, amelyet módosítottnak könyveltünk el. Ez azt jelenti, hogy a blokk visszaíródik a virtuális memóriába, mielőtt az őt tartalmazó puffert másra használnánk (13.1.).
módosított puffer
l. módosított blokk.
névmező
A szótárelemnek a nevet tartalmazó mezője. Első byte-ja az ún. hosszúság-byte; ennek alacsony helyértékű 5 bitje csakugyan a név hosszát tartalmazza. A hosszúság-byte legmagasabb helyértékű bitjének értéke egyezményesen 1, a második bit az ún. precedenciabit, a harmadik pedig a smudge bit. L. precedenciabit, smudge bit; 9.1. és 12.1. szakasz.
null szó
Szótári szó, amelynek neve egyetlen 0 értékű byte. Ez a szó fejezi be a sorok és a blokkok interpretálását (mindkettőt bináris 0 zárja). A null szót a szótárak és dokumentációk x-szel jelölik (18.).
origin parameter
l. betöltési paraméter.
pad
Ejtsd: ped. Átmeneti adattárolásra szolgáló memóriaterület (7.1.; 9.1.).
paramétermező
l. paramző.
paramző (paramétermező)
A szótári szavaknak az a mezője, amely a szó működéséhez szükséges adatokat tartalmazza, mindazt, amit a névmező, kódmező és láncmező nem (9.2.; 12.1.). Nagy szerepet játszik saját definiáló szavak írásánál (15.), a kettőspontos szavak fordítási trükkjeinél (16.).
parancspuffer (terminal input buffer)
Az a puffer, ahol a terminálról beolvasott parancssor őrződik. Kezdőcímét a TIB user változó tartalmazza.
postfix jelölésmód
A műveleteknek az a fajta jelölése, amelyben a műveleti jel az operandusok után szerepel, szemben a megszokott infix-szel, mikor a műveletijei a két operandus között van (1.4.).
precedenciabit
A szavak névmezőjének hosszúságbyte-jában van; azonnali szavaknál az értéke 1, a többinél 0. L. névmező és l. a 16.1. szakaszt.
primitíva
Olyan szótári szó, amelynek kódmezőjében a mutató a saját paramezőjére mutat, a paramezőben pedig az a gépi kód van, amely a szó futásakor végrehajtódik (14.2.).
prímszám
Olyan egész szám, amelynek 1-en és önmagán kívül nincs osztója.
rendszerkonstans
Olyan konstans, amely FORTH alapszó. Másban nem különbözik az általunk létrehozott konstansoktól (8.4.).
rendszerváltozó
A FORTH interpreter működéséhez szükséges változó. Olykor a user változókat hívják így (l. user változó).
retum stack
l. virem.
runtime procedure
l. futó szó.
screen
l. kernyő.
selected output device
l. ki-készülék.
smudge bit
A szavak névmezőjében az érvényesítő bit. Arra szolgál, hogy a befejezetlen szavakat az interpreter ne hajtsa végre (ezeket meg sem találja a szótárban). A SMUDGE szó állítja. (Kettőspontos szavak smudge bitjét például a ; szó állítja érvényes-re), l. névmező.
stack
l. verem.
stack pointer
l. veremmutató.
string
l. füzér.
számítási verem
l. verem.
származtatási paraméter
l. betöltési paraméter.
szó
Háromféle értelemben fordul elő:
szótárelem (szótári szó)
A FORTH-ban tulajdonképpen ez a program. Felépítését l. a 9.1. és a 12.1. szakaszokban.
szótár (vocabulary)
Szótárelemek láncra fűzött sorozata (12.2.).
szótár (dictionary)
Szótárelemek halmaza. Ezek több vocabulary-ba lehetnek összeláncolva (12.2.).
szótári szó
l. szótárelem.
szótármutató (dictionary pointer)
A FORTH szótár feletti első szabad címet tartalmazó user változó (9.1.).
szöveginterpreter (külső interpreter)
Az a FORTH nyelvű program, amely a FORTH nyelvű szövegeket értelmezi. Működésének vázlata az 1. fejezet végén, forrásszövege a 18. fejezetben található.
terminál input buffer
l. parancspuffer.
updated block
l. módosított blokk.
user változó
A USER szóval létrehozott változó, többnyire a szöveginterpreter belső változója. A user változók egy táblázatban vannak, így értéküket egyszerre lehet inicializálni. A user változók és a VARIABLE szóval létrehozott változók használata megegyezik (a felépítésük, működésük kissé eltér) (14.4.).
végrehajtási állapot
Az interpretemek az az állapota, mikor a megtalált szótári szavakat nem fordítja le, hanem végrehajtja. A STATE változó 0 értéke jelzi.
verem (számítási verem, adatverem, stack)
A FORTH szavak paraméterátadásának fő eszköze (1.2.; 7.3.).
veremmutató (stack pointer)
A verem tetejének a címe (7.3.).
virem (visszatérési verem, return stack)
Az a verem, amelyben a FORTH az egyes szavakból való visszatérés címét őrzi. Saját programozási céljainkra is használhatjuk (4.1.).
virtuális memória
A FORTH forrásszövegek és egyéb adatok tárolására szolgáló lemezterület vagy kazetta (2.5.; 13.1.).
visszatérési verem
l. virem.
vocabulary
l. szótár,
warm start
l. melegindítás.
