dBase II
Tartalom
1. Alapfogalmak
 A dBASE II relációs adatbáziskezelő rendszer segít adataink kezelésében és rendszerezésében. Ebben a mondatban több olyan fogalom van; amely többeknek ma még ismeretlen lehet. Először ezekkel kelt megismerkednünk. Akik már találkoztak ehhez hasonló programmal, ezt a fejezetet átlapozhatják.
A dBASE II relációs adatbáziskezelő rendszer segít adataink kezelésében és rendszerezésében. Ebben a mondatban több olyan fogalom van; amely többeknek ma még ismeretlen lehet. Először ezekkel kelt megismerkednünk. Akik már találkoztak ehhez hasonló programmal, ezt a fejezetet átlapozhatják.
1.1. Adatkezelés és adatbázis
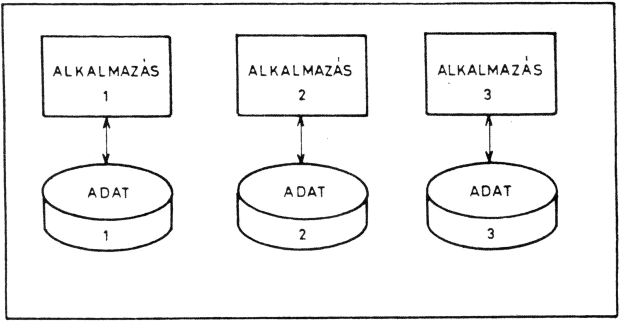
Ha adatainkat számítógéppel akarjuk feldolgozni, akkor el kell helyeznünk azokat valamilyen háttértárolón. Az adathordozókon elhelyezett ún. ÁLLOMÁNY egy összefüggő adathalmazt tartalmaz. Az adatfeldolgozás hőskorában minden állományhoz külön kellett készíteni egy programot, amely ezt az állományt kezelni tudta. Minden program csak a saját adatait használhatta, így azokat az adatokat, amelyek több alkalmazásnál is szerepeltek, több állományban is rögzíteni kellett. Ez a helypazarláson kívül a hibalehetőségeket is megnövelte.
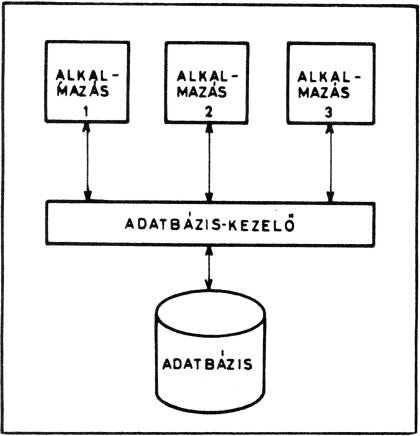
Az adatbázis-kezelő rendszerek segítségével - egy munkakörnyezetet tekintve - minden adatot a lehető legkevesebb helyen tudunk tárolni. Hamarosan látni fogjuk, hogy vannak olyan adataink, amelyek ismétlése elkerülhetetlen, éppen a további munka nagyobb kényelme érdekében. Ezek a többszörözések azonban nem jelentenek több rögzítési munkát, mivel ezt már helyettünk a számítógép végzi el, amely gyorsabb és megbízhatóbb. Az adatbázis-kezelő egy "zsilipként" kerül be az adatállományok és az egyes alkalmazások programjai közé. Bármely adathoz is szeretnénk hozzáférni, ezt csak az adatbázis-kezelőn keresztül tehetjük meg.
Az adatbázis-kezelő saját logikája szerint tartja nyilván az adatokat, ezt nekünk nem kell ismernünk ahhoz, hogy dolgozni tudjunk vele. Az adatok módosítása és használata igen egyszerű, és állományaink mindig napra, sőt percre készek, aktuálisak.
Az ADATBÁZIS tágabb fogalom, mint egy állomány, a háttértárolón fizikailag több állományban helyezkedhet el. (Az adatbázis és az állomány megnevezés hétköznapi szóhasználatunkban gyakran keveredik egymással.)
Az adatbázis-kezelő érdeme, hogy az egyes állományok szerkezetüktől, méretűktől és tartalmuktól függetlenül, egységes módon kezelhetők. Az adatok megváltoztatása, bővítése nem befolyásolja az eddig elkészített alkalmazások programjait.
Önálló programok és adatállományok
Az adatbázis-kezelő rendszer elve
1.2. A relációs adatbázis
Az adatbázisok felépítése - a bennük szereplő adatok kapcsolatainak kialakítása - többféle logikával valósítható meg. Régebben használták az ún. fastruktúrájú v. HIERARCHIKUS és az ún. HÁLÓS adatbázist. Mindkettőben valamilyen "szülő - gyermek" kapcsolatba hozhatók az adatok. A hierarchikus rendszerben minden adatnak tetszőleges számú leszármazottja, de csak egy őse lehet. A hálós rendszerben nemcsak több leszármazottja lehet egy adatnak, de több szülője is. Mindkét módszer bonyolult láncolólisták segítségével tartja nyilván az adatok összefüggéseit, így ezek tárigénye viszonylag kis állomány esetén is igen nagy lehet.
Mikroszámítógépes környezetben a leginkább elterjedt rendszerek ún. RELÁCIÓS adatbázisokat használják, amelyek felépítése talán a legérthetőbb. Ebben egy állomány adatainak (rekordjainak) kapcsolatai egy egyszerű - kétdimenziós - táblázat segítségével szemléltethetők.
| CIKKSZÁM | CIKKNÉV |
KÉSZLET | MINIMUM | HELY | ÁR |
| | | | | | |
| | | | | | |
| | | | | | |
Az egy egyedhez tartozó adatok egy sorban vannak (ez egy rekord) különböző egyedek azonos tulajdonságai pedig egymás alatt, egy oszlopban. Az oszlopot mezőnek nevezzük. A táblázat minden egyes bejegyzése egy-egy önállóan kezelhető érték. Egy oszlopon belül csak azonos típusú adat szerepeltethető (pl. szám vagy szöveg). Minden sor (rekord) önálló - összetartozó - egység, amelyek fizikai sorrendje általában lényegtelen. A rekordok számának növekedése az adatállományt nem teszi bonyolultabbá, legfeljebb "nagyobbá".
A relációs adatbázis-kezelőt akkor használjuk jól, ha az állományokban nem ismétlődnek feleslegesen az adatok. (PI. egy készletnyilvántartásban nem ismételgetjük az áru olyan jellemzőit, melyek a munka során végig változatlanok, hanem külön állományban helyezzük el.) Ezért a relációs adatbázist nem érdemes egyetlen állományban tárolni, hanem megfelelő módon több állományt kell készíteni.
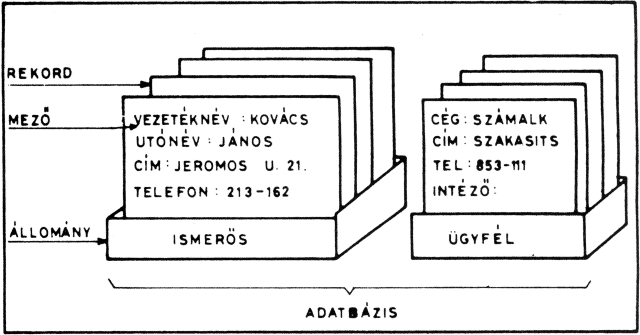
Példa egy adatbázis felépítésére
A munka során a különböző állományokban található, valamilyen értelemben összetartozó rekordokkal kell dolgozni. Ezek megtalálásában segít egyrészt az "azonosítómező", mely az egyedek (rekordok) egyértelmű azonosítására alkalmas. A gyakorlatban használt nyilvántartások többségénél a számítógépek bevezetése előtt is használtak ilyen jellegű adatot. Egy-egy tárgy vagy személy neve általában nem azonosít megbízhatóan (gondoljunk pl. arra, hogy hány dolgot kell bediktálni egy- egy nyilvántartásba a nevünkön kívül, hogy megkülönböztethetők legyünk névrokonainktól). Azonosítóként általában egy számsorozatot használunk, néha betűkkel kombinálva. (A fenti példában a "cikkszám" szolgál azonosítómezőként.)
A másik különleges mezőfajta a "kapcsolómező", mely két táblázatban az összetartozó rekordok közötti kapcsolat megteremtését végzi. Sokszor azonos az azonosítómezővel, hiszen a kapcsolatteremtésnél is valamilyen egyértelmű tulajdonságot célszerű választani. Az előző példában a "cikkszám" mező szerepelhet a KARTON állományon kívül a "NAPLO" nevű állományban is, ahol így azt tudjuk nyilvántartani, hogy az adott cikkszámú árúból mikor és ki vásárolt. Nagyon fontos, hogy kapcsolómezőt használva a "NAPLO" állományban nem kell az árú nevét, egységárát, készletét minden vásárlásnál megismételni, mert ezeket mind kikereshetjük a "KARTON" állományból, a megfelelően rövidre definiált cikkszám alapján.
A kapcsolómező így több állományban is szerepel, ezért érdemes néhány tulajdonságot betartani a definiálásakor: legyen minél rövidebb, hogy kis helyet foglaljon; legyen egyedi, pontosan azonosítsa a rekordot; és végül legyen számunkra könnyen kezelhető (ennek megvalósítása mindig a felhasználótól függ).
1.3. Az adatbázis-kezelő rendszerek fő funkciói
Az ilyen -általános célú- alkalmazói programtól elvárható tevékenységek:
- Adatbázis-állomány létrehozása (szerkezetének meghatározása)
- Adatbevitel, -módosítás, -törlés
- Adat szempont(ok)nak megfelelő adatok kiválasztása, megjelenítése
- Adatok rendezése különböző szempont(ok) szerint.
- Adatok és egyéb információk nyomtatása.
2. A dBase II
Mikroszámítógépes környezetben talán a legelterjedtebb adatbázis-kezelők a dBASE család tagjai. A programcsomag első kiadása 1979-ben látott napvilágot eredetileg az Ashton-Tate publikálta CP/M operációs rendszerre 1980-ban, amit később portolt Apple II-re és IBM PC-re. Mi a dBase II CP/M változatát fogjuk használni, ami alapvetően 8 bites számítógépekre készült.
2.1. A dBase II fő jellemzői
A dBASE II egy relációs adatbázis-kezelő rendszer. Parancsfelépítése angol nyelvű (de ENTEPRISE-ra készült - maszek - magyar nyelvű változat is). Meglévő adatállományainkat egyszerű parancsokkal bővíthetjük, módosíthatjuk. A szükséges információ másodpercek alatt kikereshető. A program egyszerre több szempont szerint is tud rendezni; egy időben kettő nyitott adatbázis-állományt tud kezelni, ezek tartózkodási helyét nem kell megjegyezni, mert a dBASE által adott hivatkozási nevük segítségével bármikor és bárhol megtalálhatók. Olyan parancsok és függvények állnak rendelkezésünkre, melyek a gyorsabb programfuttatást, tesztelést teszik lehetővé, használatukkal programjaink egyszerűbbek és ügyesebbek lehetnek.
2.2. A dBASE II állománytípusai
A használható, különböző típusú állományok egy részét a felhasználó saját igényei szerint állítja elő, a többit az adatbáziskezelő készíti el egyes dolgok adminisztrálására. (Végeredményben ezek létrejötte is tőlünk indul el, bizonyos parancsok kiadásakor.)
Amikor mi adunk nevet egy új, létrehozandó állománynak, ezt csak a CP/M operációs rendszer szabályait figyelembe véve tehetjük meg (ezek a szabályok megegyeznek az MS-DOS szabályaival):
Az ún. elsődleges állománynév legfeljebb 8 karakteres lehet, betűvel kezdődjék, betűket és számjegyeket tartalmazhat. A jobb olvashatóság kedvéért az elsődleges névben szokás és megengedett használni az "aláhúzás" karaktert (_). Az elsődleges nevet követheti egy ponttal (.) kezdődő, ezenkívül még legfeljebb 3 karaktert - betűt és számjegyet - tartalmazó ún. kiterjesztés, mely általában az állomány tartalmára utaló típusjel. A dBASE II használata során legtöbbször elhagyható, mert a parancsok többsége automatikusan generál az elsődleges név mellé egy alapértelmezés szerinti kiterjesztést. Az alapértelmezés helyett megadhatunk mást is, de ilyenkor ezt az állományra való összes hivatkozáskor fel kell tüntetni. Ekkor az is problémát okozhat, hogy bizonyos parancsok szolgáltatásait nem tudjuk kihasználni, mert azok működésük során csak a szabványos típusjelű állományokat veszik figyelembe.
Vannak parancsok, melyek egyszerre több állományra vonatkozhatnak. Ezeknél használhatunk ún. nem egyértelmű állományneveket, melyek egy állománycsoportot azonosítanak. Ezek képzése követi az operációs rendszerben megszokott szabályokat:
a '*' karakter tetszőleges számú,
a '?' egyetlen tetszőleges karaktert helyettesít.
(Az operációs rendszerben szokás ezeket "joker" karaktereknek nevezni.) Például: az aktuális lemezegységen található olyan állományokra, melyeknek neve a "munka" szóval kezdődik, a "munka*.*" névvel hivatkozhatunk, az összes állomány jelölésére a "*.*" név alkalmas. (Ez csak az aktuális könyvtár állományait jelenti!)
Röviden tekintsük át a dBASE II által kezelt állománytípusokat. Tulajdonságaikat, szerepüket részletesebben a használatuk ismertetésekor vizsgáljuk. (Zárójelben megadjuk az eredeti angol elnevezést is.)
 Adatbázis-állomány (DATABASE FILE)
Adatbázis-állomány (DATABASE FILE)
.DBF típusjele van
A nyilvántartandó adatokat tartalmazza rekordokban és mezőkben, Legfeljebb 65535 rekordja lehet.- Indexállomány (INDEX FILE)
.NDX típusjele van
Logikailag rendezett adatbázis-állomány rekordsorrendjét tartalmazza. Formátumállomány (FORMAT FILE)
.FMT típusjele van.
Jelentések megjelenítéséhez szükséges parancsokat tartalmazza, melyek a felhasználó által definiált képernyőforma létrehozására alkalmasak. Szabványos szöveges (ASCII) állomány.
- Nyomtatási listaformátum állomány (REPORT FILE)
.FRM típusjele van
Az aktuális adatbázisról készítendő nyomtatott listákhoz szükséges információkat tartalmazza (REPORT parancs). Jelentésformátum állománynak is szokás nevezni.
- Memóriaállomány (MEMORY FILE)
.MEM típusjele van.
Legfeljebb 64 memóriaváltozó megőrzésére hozható létre, a memóriaváltozó nevét és értékét is tárolja.
- Parancs-, program- és procedúraállományok (COMMAND, PROGRAM, PROCEDURE FILE)
.CMD típusjelük van
Szöveges állományok olyan dBASE utasítások tárolására, amelyek végrehajtását egyetlen paranccsal elindíthatjuk.
- Szöveges állomány (TEXT FILE)
.TXT típusjele van
Szabványos ASCII szöveget tartalmaz. Segítségével szöveges információkat tárolhatunk, vagy más programnak átadhatunk (SET ALTERNATE, COPY parancsok).
2.3. Az adatbázis-állományok szerkezete
Munkánk az adatbázis-állományok körül forog, ezek tartalmazzák rekordokba (sorokba) és mezőkbe (oszlopokba) szervezve adatainkat. A táblázat felépítését létrehozáskor a felhasználónak kell meghatároznia. Ilyenkor kell megadni, hogy a táblázat egy sora (egy rekord) milyen mezőket tartalmazzon, és pontosan definiálni a megadott mezők tulajdonságait. Adatbázis-állomány létrehozásakor tartsuk szem előtt a méretkorlátozásokat (ld. a függelékben)!
A meződefiníció részei:
| Mezőnév | a mezők későbbi azonosítására szolgál - legfeljebb 10 karakter hosszú
- betűvel kezdődik
- betűt, számjegyet és aláhúzás karaktert tartalmazhat
- célszerű értelmes, a tartalomra utaló neveket választani |
| Mezőtípus |
definiáláskor egyetlen betűvel kell jelölni:
C = karakteres (character)
N =Numerikus (numeric)
L = logikai (logic) |
| Szélesség |
a mezőben tárolni kívánt karakterek vagy számjegyek maximális száma.
- numerikus mező esetén a tizedespont és a tizedesjegyek is beleszámítandók. Ilyenkor külön kell megadni, hogy a definiált teljes hosszból hány karakteren akarjuk tárolni a tizedes jegyeket.
- a logikai típusú mező hossza kötött, megváltoztatni nem lehet, megadni nem kell. |
2.4. Adattípusok
A dBASE II 3-féle adattípust ismer, ezeket élesen megkülönbözteti egymástól, a kifejezésekben típuskeveredést nem enged meg. (Mint láttuk, adatbázis-állomány mezője mind a három típust felveheti.)
Karakteres: nyomtatható (billentyűzetről beírható) karakterekből álló szöveg (legfeljebb 254 karakter hosszú lehet). Így gazdaságos tárolni minden olyan adatot, amellyel nem végzünk matematikai műveleteket.
Numerikus: előjeles szám (számjegyeket, tizedespontot, előjelet (+,-) tartalmazhatja. Ha egy adattal később matematikai műveleteket szeretnénk végezni, így kell nyilvántartani. A műveleteket és függvénykiértékeléseket 10 jegyig pontosan végzi el a rendszer.
- Logikai: mindig egyetlen karakter, a logikai IGAZ vagy HAMIS érték. Jelölésük:
IGAZ (TRUE/YES) = T, t
HAMIS (FALSE/NO) = F ,f
2.5. Állandók és változók
Adataink a munka során lehetnek változatlan értékűek (ezeket nevezzük állandóknak vagy konstansoknak) vagy változók. Az adatbázis-állományokon kívül tárolt adatok szintén háromféle típusúak lehetnek: karakteres, numerikus, logikai.Ha egy karaktert vagy karaktersorozatot (karakterláncot) állandóként akarunk a géppel közölni, ún. határolójelek közé kell tenni. A karakterlánc-határoló háromféle lehet:
felső vessző (aposztróf) 'xxxxxx'
idézőjel "--------"
szögletes zárójel [............]
Természetes, hogy a határolójel típusa a karakterlánc mindkét végén meg kell, hogy egyezzék, így a másik két határolójel a karakterlánc belsejében is szerepelhet.
A numerikus állandók (számok) a megszokott módon közölhetők a géppel.
Logikai állandók begépelésekor a megfelelő betűt (ld. az adattípusok ismertetésénél) két pont közé kell tenni (pl.".T.").
A változók végeredményben tároló helyek, amelyekre azonosító. (nevük) segítségével hivatkozhatunk, tartalmukat lekérdezhetjük, módosíthatjuk. A dBASE kétféle változót különböztet meg:
- változónak tekinti minden nyitott adatbázis összes mezőjét
- tárolhatunk az adatbázisoktól függetlenül is adatokat az memóriaváltozókban.
2.6. Memóriaváltozók
 Az adatbázisoktól független tártoló helyeket - megkülönböztetésül - memóriaváltozóknak nevezzük. Ezeket általában ideiglenes tárolásra használjuk (elsősorban programokban, pl. a felhasználótól való adatbekérésre, a végrehajtás ellenőrzésére).
Az adatbázisoktól független tártoló helyeket - megkülönböztetésül - memóriaváltozóknak nevezzük. Ezeket általában ideiglenes tárolásra használjuk (elsősorban programokban, pl. a felhasználótól való adatbekérésre, a végrehajtás ellenőrzésére).
Nevük ugyanolyan szabályok szerint képezhető, mint az adatbázismezőké, legtöbb esetben ugyanott és ugyani használhatók, mint a mezők. Ha egy memóriaváltozó neve megegyezik az aktuális adatbázis-állomány egy mezőjének nevével, akkor e név beírása mindig a mezőre vonatkozik. A memóriaváltozóra úgy tudunk hivatkozni, hogy neve elé írjuk "családnevét": egy "m" betűt és egy "nyilat" (pl. ha a változónk neve "datum", ezt az "m->datum" karaktersorozattal tudjuk megnevezni nyilat a kötőjelből és a nagyobb jelből kell összeállítani). Egyszerre legfeljebb 64 memóriaváltozónk lehet. A memóriaváltozók törölhetők vagy későbbi felhasználás céljából lemezes állományba is elmenthetők.
A változók deklarálására külön utasítás nincs. Egy eddig még nem íjuk használt memóriaváltozóra először csak olyan környezetben hivatkozhatunk, amelyből egyértelműen kiderül a memóriaváltozó típusa és mérete. Ez az értékadó utasításokkal valósítható meg, amelyek mind képesek egy új, adott nevű és típusú memóriaváltozó létrehozására. Ha már létezik egy ugyanilyen nevű, az megszűnik, felülíródik. Egyetlen parancs van, amely nem tud létrehozni új memóriaváltozót (a @...GET parancs), csak egy előzőleg definiált értékét tudja megváltoztatni (típusát, hosszát nem).
Ezzel végére értünk a dBASE II által használt objektumok ismertetésének. Volt szó állományokról, mezőkről, memóriaváltozókról. Láttuk, hogy minden objektumnak nevet kell adnunk, ennek szabályait szintén megismertük. Szeretnénk felhívni a figyelmet arra, hogy egyszer sem mondtuk, hogy bizonyos szavakat nem használhatunk objektumok elnevezésére. Erről nem véletlenül feledkeztünk meg, hanem egyszerűen azért nem említettük, mert ilyen szabály nincs. A dBASE II megengedi, hogy különböző állományainknak, változóinknak olyan nevet adjunk, amely egyébként egy parancsot vagy egy paramétert jelent. Azonban az ilyen nevű objektumok használata félreérthetővé teszi utasításainkat, nemcsak számunkra, de sokszor a dBASE számára is. Ezeket később nem biztos, hogy megfelelően tudjuk használni, néhánynak a további használata teljesen lehetetlenné válhat.
3. A dBase II használatba vétele
3.1. A dBASE II indítása
A program CP/M operációs rendszer alatt működik. Ez az ENTERPRISE felhasználóknak azt jelenti, hogy a CP/M-el kompatibilis IS-DOS elindítása után tudjuk a programot használni. A dBase működéséhez két file mindenképpen szükséges: DBASE.COM, DBASEOVR.COM, ezen kívül érdemes használni a help-file-t is: DBASEMSG.TXT.
A program indítása a
DBASE
Utasítással lehetséges.
A dBASE bejelentkezésekor egy pontot látunk a képernyő alján, ez a dBASE "parancsra várakozásának jele" (promptja), e mögé gépeljük parancsainkat. Ezt a sort nevezzük parancssornak. Mielőtt bármit csinálnánk adatbázis-kezelőnkkel, jegyezzünk meg, néhány jó tanácsot.
A program használata közben mindig nézzünk a képernyőre, hátha megjelent rajta egy nekünk szóló üzenet.
Elhagyni a programot csak és kizárólag az erre szolgáló
QUIT
paranccsal szabad.
Adataink érdekében ezt az utolsó szabályt soha ne szegjük meg, nagy, árat fizethetünk érte, különösen, ha olyan állomány marad lezáratlanul, amelyben előzőleg módosítottunk valamit.
Adatbázis-állományainkat más parancsokkal is lezárhatjuk, egyet közülük már most megemlítünk, mert ez majdnem tökéletesen alaphelyzetbe állítja a dBASE-t. E parancs formája:
CLEAR
Ez a parancs lezárja az összes adatbázis- és hozzá tartozó segédállományt, visszaáll az egyes számú munkaterületre, és megszünteti az összes létező memóriaváltozót.
Ha két lemezegységgel dogozunk, és munkalemezt cserélünk, azt a
RESET [<meghajtó>]
paranccsal jelezhetjük a rendszernek az új file-ok megnyitása előtt. A dBASE file-jait tartalmazó rendszerlemezt sose vegyük ki a meghajtóból munka közben, és ne váltsunk lemezt, mielőtt az összes file-t bezárnánk.
A dBASE II-nek vannak ún. könnyezeti paraméterei, melyek különböző használati működési módokat tesznek lehetővé. Vannak köztük ún. környezeti kapcsolók, melyeknek kétféle "állása" lehet, és vannak olyanok, amelyek egy felhasználó által pontosított értéket állítanak be (szokás "set" parancsoknak is nevezni ezeket, mert a megfelelő beállító parancs minden esetben a SET kulcsszóval kezdődik). Ezek megfelelő kapcsolgatásával, beállításával elérhetjük, hogy a feladathoz, munkastílusunkhoz legjobban illeszkedő környezetet alakítsunk ki magunknak.
A dBASE II adatbázis-kezelőt kétféleképpen lehet használni:
A dBASE-t használhatjuk interpreterként, ilyenkor a begépeli parancsaink azonnal értelmeződnek, és amennyiben lehetséges, végrehajtódnak. Hibáinkra az adatbázis-kezelő azonnal reagál a hibaüzenetek megjelenítésével.
Ha már készítettünk magunknak (vagy más készített nekünk) egy programot a dBASE segítségével, akkor ezen a programot keresztül is használhatjuk az adatbázis-kezelőt. Ilyenkor már a futtatott programon múlik, mennyire látszik, hogy valójában a dBASE-el dolgozunk.
3.2. A dBASE II parancsnyelve
Amikor interpreterként (párbeszédes módban) használjuk a dBASE-t, parancsainkat közvetlenül a parancssorba gépeljük be. Ilyenkor bizonyos szabályokat be kell tartanunk annak érdekében, hogy utasításainkat a gép is megértse és értelmes módon végrehajtsa. Rendelkezünk ugyanakkor néhány olyan lehetőséggel, amelyek a mi kényelmünket szolgálják. Minden parancsot külön kell begépelnünk és befejezésül az 'ENTER' billentyűt megnyomnunk. Nincs lehetőség arra, hogy egyszerre - egy sorban - több utasítást adjunk ki!
3.2.1. A parancskiadás szabályai
-
Minden utasításnak parancsszóval kell kezdődnie - általában ez az alapparancs - és a szintaktikai leírásban található formának meg kell felelnie (ld. függelék), csak a megadott paraméterek szerepeltethetők benne.
A parancsszót követő paraméterek, opciók tetszőleges sorrendben gépelhetők be, de a paramétert bevezető kulcsszó nem szakítható el a hozzá tartozó kifejezéstől. (PI. a "TO <állománynév>" parancsrészletben szereplő két szó között csak szóközök szerepelhetnek.)
Egy parancs legfeljebb 254 karakterből állhat, ha túllépjük a képernyő szélességét, a dBASE a következő sorban folytatja a parancsot, de ez ne zavarjon bennünket. Az 'ENTER' billentyűt csak a végrehajtás kezdeményezésére nyomjuk meg!
A kulcsszavakat, paramétereket egymástól egy vagy több szóközzel kell elválasztani. (Ezek a szóközök is beleszámítanak a 254 karakterbe.)
-
A kulcsszavak és függvénynevek (a szintaktikai leírásban ezeket csupa nagybetűvel írtuk) rövidíthetők az első négy karakterükkel. (Pl. DISPLAY STRUCTURE helyett DISP STRU írható.) Ha további betűket írunk ki, akkor azoknak is helyesek kell lenniük.
A kulcsszavak, memóriaváltozó-, függvény-, állomány- és mezőnevek kis- és nagybetűkkel egyaránt, de vegyesen is írhatók (pl. DISPLAY = Display = dispLAY).
Mint korábban már említettük, a dBASE II-nek nincsenek fenntartott szavai, a kulcsszavak bármilyen objektum (állomány vagy változó) elnevezésére használhatók, csakhogy ezekkel később nagyon nehezen vágy egyáltalán nem tudunk boldogulni.
-
A 8 funkcióbillentyűnek alapértelmezésben nincs funkciója, de ha a program indítása előtt definiáljuk őket, használhatjuk a dBase-ben. (A funkcióbillentyűk definiálását célszerű egy BAT-file-ban elvégezni, az
EPDOS FKEY parancsa segítségével.) A 8. Funkcióbillentyűt ne használjuk, mert a dBase nem szereti.
Programíráskor az ún. páros parancsok egyik fele sem hagyható el, és meghatározott sorrendben, illetve formában használandók (ilyenek: DO WHILE - ENDDO; DO CASE - ENDCASE; IF - ENDIF; TEXT - ENDTEXT).
3.2.2. Szintaktika
A parancsok felépítését, formai szabályait nevezzük. szintaktikának. Párbeszédes használatkor ezeket mindig szem előtt kell. tartanunk, ellenkező esetben rosszul vagy egyáltalán nem tudja végrehajtani utasításainkat a gép.
A parancsok általános szerkezete (amelyek tanulmányozásával képel kapunk a dBASE nyelvi logikájáról, és későbbi szóhasználatunkat is tisztázhatjuk) a következő:
PARANCSSZÓ [PARAMÉTERSZÓ <objektum>]
A PARANCSSZÓ írja elő a tevékenységet, melyet el akarunk végezni, a paraméterek mondják meg, hogy mivel és hogyan kell elvégezni. Minden paraméterhez tartozik egy kulcsszó (PARAMÉTERSZÓ), de sokszor ez elhagyható.
A parancsok leírásában használt jelöléseket egy példa segítségével mutatjuk be (magáról a parancsról majd később lesz szó).
Nézzük például a következő parancsot:
USE <állománynév> [INDEX <indexállománynév>]
Jelölések:
- A [...] közti paraméterek, parancsrészletek elhagyhatók, használatuk nem kötelező.
A <...> közé írt szöveget a felhasználónak kell a megfelelő tartalommal pontosan megadni (pl. "<állománynév>" helyett "karton" írható). A [ ],< > jelek nem részei a parancsoknak, ezeket begépelni nem szabad. (Figyelem: parancsokban a "[" és a "]" jelet karaktersorozat határolójeleként értelmezi a rendszer!)
A különböző "listák" elemeit vesszővel (,) kell egymástól elválasztani, vessző másutt nem szerepelhet.
- A NAGYbetűs szavak pontosan úgy írandók (eltekintve a rövidítéstől), ahogyan a leírásban látható
3.2.3. A rekordkezelő parancsok szerkezete
A parancsok egy jelentős része az előírt tevékenységet kifejezetten az adatbázis rekordjaival végzi (pl. megjelenít, másol, töröl stb.) ezeket hívjuk rekordkezelő parancsoknak. Általános szerkezetük:
PARANCSSZÓ [<érvényességi kör>] [WHILE <feltétel>] [FOR <feltétel>]
Nézzük végig az egyes paramétereket!
Az érvényességi kör (scope)
Az adatbázisnak azt a részét határozza meg, amelyen a parancsot végre kell hajtani. Az alapértelmezés általában az "aktuális rekord" néhány parancsnál "ALL" (= minden), azaz a teljes adatbázis. (A FOR és WHILE paraméterek megváltoztatják az alapértelmezést; mellettük az "ALL" érvényességi kör megjelölés használata felesleges, az nem változtatja meg a parancsban részt vevő rekordok körét.)
Az "<érvényességi kör>" lehet:
| RECORD <n> | az n. rekordon hajtja végre a parancsot. |
| NEXT <n> | az aktuálistól kezdve a darab rekordon (beleértve a aktuálisat is). |
| ALL | az adatbázis-állomány összes elérhető rekordján végrehajtja a parancsot. |
Ha az alapértelmezés az "aktuális rekord", és más érvényességi kört nem írunk ki, a parancs azon a rekordon hajtódik végre, amelyre a rekord mutató ( "record pointer") mutat.. Minden megnyitott adatbázisunkhoz tartozik egy rekordmutató, mely közvetlenül megnyitás után a logikai rendben első rekordra mutat. Bizonyos parancsok közvetlenül állítják a rekordmutatót egy adott rekordra, mások közvetve, a parancsvégrehajtás, közben mozdítják el korábbi helyéről. Általában elmondható, hogy a rekordmutató azt a rekordot címzi meg, amelyikkel az adatbázis-kezelő utoljára foglalkozott. Az "ALL" érvényességi körű parancsok végrehajtása után a rekordmutató az utolsó rekord utáni, nemlétező rekordot (annak sorszámát) jelöli ki.
Kifejezés (expression)
 A kifejezés különböző műveleti jelekkel (operátorokkal) összekapcsolt, vagy a megengedett függvények argumentumában elhelyezett állandókból és változókból áll. Az operátorok két oldalán azonos típusú adatnak kell szerepelnie. Különböző típusok esetén konverziós függvényeket használhatunk. A kifejezés a kiértékeléskor kapott eredménytől függően lehet karakteres (erre a továbbiakban "Kkif" rövidítést használunk), numerikus ("Nkif") és logikai ("Lkif") típusú.
A kifejezés különböző műveleti jelekkel (operátorokkal) összekapcsolt, vagy a megengedett függvények argumentumában elhelyezett állandókból és változókból áll. Az operátorok két oldalán azonos típusú adatnak kell szerepelnie. Különböző típusok esetén konverziós függvényeket használhatunk. A kifejezés a kiértékeléskor kapott eredménytől függően lehet karakteres (erre a továbbiakban "Kkif" rövidítést használunk), numerikus ("Nkif") és logikai ("Lkif") típusú.
Feltétel (condition)
A feltétel olyan kifejezés, amelynek értéke logikai típusú (általában összehasonlító vagy logikai műveletek eredménye, vagy logikai értéket szolgáltató függvényhívás).
A WHILE és FOR paraméter
Hasonlóan az érvényességi körhöz, ez a két paraméter is a parancsban részt vevő rekordok körét változtatja meg. Ennél a két paraméternél azonban nem a rekord állományon belül elfoglalt helye, hanem tartalmának tulajdonságai töltik be a döntő szerepet. Minden olyan parancsnak paramétere, amelynél érvényességi kör is megadható.
A WHILE paraméter a rekordmutató aktuális pozíciójától kezdi vizsgálni a rekordokat, magát a parancsot csak akkor hajtja végre, ha a feltétel igaznak bizonyul. Az első olyan rekordon, amelyre a feltétel nem teljesül, befejeződik a parancs végrehajtása. A paraméter működéséből következik, hogy "ALL" érvényességi kör használata ilyenkor felesleges, nem változtat a parancsvégrehajtás mikéntjén "NEXT" érvényességi körrel lehetséges, hogy nem a feltétel hamissá válása, hanem az érvényességi kör vége állítja meg a parancs végrehajtását.
A FOR paraméter az érvényességi kör alapértelmezését átírja "ALL' értékre, tehát a végrehajtás a rekordmutató pillanatnyi tartalmától függetlenül mindig a logikailag legelső rekordon kezdődik, és az adatbázis végéig tart. A parancsban előírt műveletet a dBASE mindazokon a rekordokon elvégzi, amelyekre a feltétel kiértékelése "igaz" értékel szolgáltat. FOR paraméter mellett a "NEXT érvényességi kör használata befolyásolhatja, hogy mely rekordokon értékelődik ki a feltétel.
"RECORD <n>" érvényességi kör mindkét paraméter mellett ugyanazt eredményezi: ha a feltétel "igaz", a parancs végrehajtódik az adott sorszámú rekordon.
A két paraméter együtt is használható. Ekkor a WHILE-nak van prioritása, azaz a WHILE feltétele határozza meg a végrehajtás befejezésének pillanatát. Használható például olyan szituációkban, amikor az adatbázis egy adott részletén (amiről nem tudjuk, hogy hány darabból áll, csak azt, hogy egy adott feltételnek eleget tevő rekordokat tartalmaz) további feltételtől függően szeretnénk egy parancsot végrehajtani. (Ezt elérhetnénk másképpen is, pl. FOR paraméter használatával és összetett, logikai műveleteket tartalmazó feltétel megfogalmazásával, de ekkor minden rekordon végig kell mennie az adatbázis-kezelőnek, és ez bizony időbe telik.)
3.3. A munkaterületek használata
A dBASE II egyszerre 2 nyitott adatbázis-állományt tud kezelni. Ezek egymástól függetlenek, mindkettőn egy adatbázis-állomány és a hozzá tartozó egyéb típusú állományok tarthatók nyitva. Minkét munkaterületen önálló, alapértelmezés szerint a másiktól független rekordmutató van, segítségükkel két munkaterület között később logikai kapcsolatot tudunk létesíteni.
A dBASE elindításakor az első munkaterület az aktuális. A két munkaterület neve PRIMARY (az első), SECONDARY (második). A munkaterületek között váltani s SELECT paranccsal tudunk:
SELECT PRIMARY
SELECT SECONDARY
Ha a két munkaterületen mégis egyszerre szeretnénk mozgatni a rekordmutatókat, a
SET LINKAGE ON
beállítása után tehetjük meg. Ezután a két rekordmutatót egyszerre mozgatják azok a parancsok, melye a rekordmutatót egyesével léptetik.
A kiadott parancsok túlnyomó többsége arra a munkaterületre vonatkozik, amelyen kiadtuk. A memóriaváltozók nincsenek munkaterülethez kötve, azokat bárhonnan elérhetjük és módosíthatjuk.
4. Kiegészítő tevékenységek
Első lépésként egy kicsit ismerkedjünk meg adatbázis-kezelőnk környezeti lehetőségeivel, vagyis a legfontosabb környezeti paraméterekkel és néhány más jellegű paranccsal, melyek szintén a kényelmünket szolgálják. Ezek mind olyan általános tevékenységek, amelyeket jó, ha már a kezdet kezdetén elsajátítunk, hogy a későbbiekben, a komoly munka során könnyedén dolgozhassunk velük.
4.1. Segélykérés
 Amennyiben szeretnénk megismerni a dBASE II segítségnyújtó részét, a következő parancsot keli használnunk:
Amennyiben szeretnénk megismerni a dBASE II segítségnyújtó részét, a következő parancsot keli használnunk:
HELP [<kulcsszó>]
A parancs szintaktikájából következik, hogy kérhetünk vele általános segítséget (HELP formában) vagy információkat egy konkrét parancs működéséről. Egy-egy parancsról maximum egy képernyőoldalnyi tudnivaló íródik ki a monitorra. Ez gyakorlatilag a parancs pontos szintaktikáját és néhány példát tartalmaz.
Ha elrontottuk egy parancs beírását, a rendszer UNKNOW COMMAND, vagy SYNTAX ERROR üzenettel válaszol, és megkérdezi, hogy kívánjuk-e módosítani a parancsot. (Módosítani nem érdemes, mert körülményesebb, mint újraírni az egészet.)
Ha kellőképpen összekuszáltuk a képernyőt, az
ERASE
Paranccsal letörölhetjük.
4.2. Környezeti paraméterek
Alakítsuk olyanra a környezetünket, hogy kényelmesen dolgozhassunk! Ezt a már említett környezeti paraméterek segítségével valósíthatjuk meg. Sajnos a dBase II kényelmi szolgáltatásai jelentősen elmaradnak a későbbi váltizatoktól, de azért egy pár alapvető paramétert beállíthatunk. Itt nem soroljuk fel az összes paramétert, az egyes témakörökhöz kapcsolódó lehetőségeket később ismertetjük.
Munkánk során igen rövid idő alatt tapasztalhatjuk, hogy néha nagyon "hangosan" dolgozik a dBASE, ugyanis az adatbevitelek egy részét hangjelzéssel kíséri. Ha magunkat vagy kollégáinkat (esetleg a szomszédot) nem szeretnénk nagyon zavarni, kapcsoljuk ezt ki:
SET BELL OFF
A kapcsolóknál mindig a kívánt állapotot kell a parancsba begépelni
(ON = be; OFF = ki). A függelék szintaktikai leírásában az alap értelmezést írtuk nagybetűkkel és a párját kisbetűkkel.
A dBase elvileg lehetőséget ad dupla intenzitású karakterek használatára:
SET INTENSITY ON
Enterprise verziók többségében azonban ez a funkció nem működik.
Működik viszont adatbevitelkor az adott mező hosszúságát jelző határoló | jelek kijelzése. Ha erre mégsem lenne szükségünk, kikapcsolhatjuk:
SET COLON OFF
A következő beállító parancsokban már jobban tükröződhet a saját stílusunk. A parancsban szereplő "TO" szócskáról könnyedén felismerhetők ezek a felhasználói értéket fogadó paraméterek.
Először is - feltételezve, hogy az "A:" lemezegységről indítottuk a dBASE-t, de nem ott szeretnénk tárolni adatállományainkat - irányítsuk át az aktuális meghajtóegységet egy másik eszközre. Ezt a
SET DEFAULT TO [<meghajtóegység>]
parancs végzi el. Például az imént feltételezett szituációban a következő parancsot kell begépelnünk:
SET DEFAULT TO B:
A parancs végrehajtása után az adatbázis-kezelő minden állományt a "B:" meghajtóegységen keres, illetve ott helyez el.
A rendszerdátumot a dBase induláskor megkérdezi, azonban ha ott nem adtuk meg, vagy szeretnénk megváltoztatni, a
SET DATE TO <xx/xx/xx>
A dátumot nap / hónap / év formátumban kell megadni.
4.3. Párhuzamos nyomtatás és kimeneti állomány
Kezdők számára érdekes és tanulságos dolog egy-egy feladat megoldása után újra végignézni a kiadott parancsokat és azok végrehajtásának eredményét. A dBASE II erre kétféle lehetőséget is nyújt. Az egyik, ha ún. párhuzamos nyomtatást valósítunk meg, azaz minden parancs, amit kiadunk, és azok képernyőn megjelenő eredménye egyúttal ki is lesz nyomtatva. Ezt egy egyszerű paraméter elintézi nekünk, ha "ON" értékre állítjuk:
SET PRINT ON
Amíg nem kapcsoljuk ki (SET PRINT OFF paranccsal) a paramétert, a rendszer mindent nyomtat, kivéve a teljesképernyős szerkesztő parancsokat (ezeknél csak maga a parancs jelenik meg a nyomtatón).
A képernyőre való kiírást is hasonlóan szabályozhatjuk.
Ha éppen nincs nyomtatónk, akkor is van lehetőségünk arra, hogy munkánkat időrendben megőrizzük és később újra átnézzük. Ezt a feladatot egy szöveges állomány oldja meg, amely megnyitása után ugyanazokat a "sorokat" tárolja lemezen, amelyeket az előző paraméter segítségével kinyomtathattunk. Az állományba a parancsok kimenete (eredménye) kerül, ezért nevezzük ezt kimeneti állománynak! Kezelését két környezeti paraméter végzi. Készíteni vagy egy meglévőt megnyitni a következő paranccsal kell:
SET ALTERNATE TO [<állománynév>]
Ha az állománynévben nem adunk meg típusjelet, automatikusan a feltételezett ".TXT" lép életbe. Ha a parancsban megadott nevű állomány még nem található a lemezen, létrehoz egyet, ha már van ilyen, azt figyelmeztetés vagy egyéb üzenet nélkül felülírja. Az állomány nyitva marad, amíg külön paranccsal le nem zárjuk.
A kimeneti állomány megnyitása után a kiadott parancsok nem tárolódnak benne, ehhez előbb a paraméter (kapcsoló jellegű) párját "ON" értékre kell állítani a
SET ALTERNATE ON
paranccsal. Ez az ALTERNATE paraméter lehetőséget ad arra, hogy ne kerüljön minden kiadott parancs az állományba. A paraméter "OFF" értékre állításával bármikor elérhető, hogy az újabb, immáron bekapcsolj parancsig kiadott utasításainkat ne tárolja a dBASE.
A kimeneti állomány a
SET ALTERNATE TO
paranccsal zárható le. Erre akkor van szükség, amikor csak a kimeneti állományt szeretnénk lezárni (nem befolyásolja a más jellegű állományok állapotát). A "TO" szócskával végződő, környezeti paramétert beállító parancsoknál sokszor fogunk találkozni ilyen "üres", érték nélküli parancsformával. Többségüknél a így kiadott parancs az alaphelyzet visszaállítását, állománykezelő paraméter esetén az adott állomány lezárását jelenti. Ha nyitott kimenti állomány mellett megnyitunk egy újat, akkor a régit lezárja, egyszerre csak egy kimeneti állomány lehet nyitva.
A nyomtatott információ a papíron a nyomtató első karakterhelyén kezdődik, de egy környezeti paraméter segítségével ezt is meg változtatni:
SET MARGIN TO <Nkif>
Az adott numerikus kifejezés értékének megfelelően bal oldali margót állíthatunk így be (ennyivel beljebb kezdi a nyomtatást). Alapértelmi szerint a bal margó 0, ez jelenti azt, hogy rögtön a papír szélén kezdi sorokat.
A nyomtatott listák jó, ha lap tetején kezdődnek, ezért szükség lehet a lapdobást kiváltó parancsra:
EJECT
4.4. A dBASE állapotkijelzése
Az adatbázis-kezelő jelenlegi állapotáról nyújt áttekintő képet a
DISPLAY STATUS
parancs. Ha van nyitott adatbázisunk vagy katalógusunk, arról kiírja, hogy melyik munkaterületen. Megjelenik az alapértelmezett meghajtóegység neve, és ha kimeneti állomány nyitva van, azt is kijelzi. A parancs kimenetének végén listát kapunk a legfontosabb környezeti daraméterek (elsősorban a kapcsolók) állapotáról. E képernyőoldal kezdete előtt megjelenik egy felirat ("Waiting" - "várakozás, nyomjunk meg egy gombot a folytatáshoz"), és megáll a szöveg monitorra írása, csak amikor eleget tettünk a felszólításnak és megnyomtunk egy tetszőleges billentyűt, akkor folytatódik az információk megjelenítése (tetszőleges billentyűként érdemes a szóközbillentyűt használni).
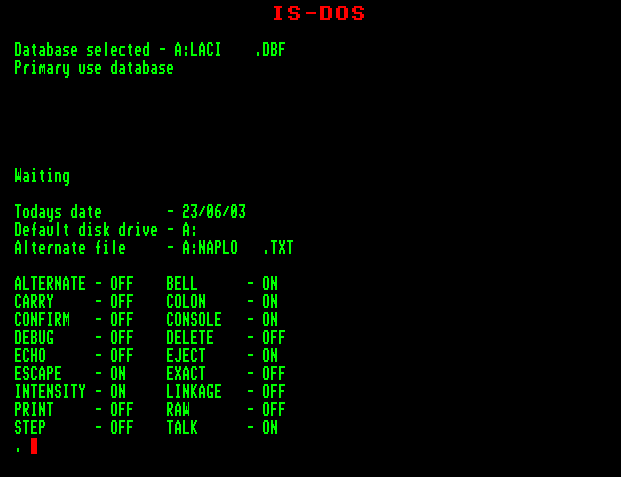
Ezt a parancsot kiadhatjuk LIST STATUS formában is, így nem jelenik meg a "WAITING" felirat.
4.5. Operációsrendszer-funkciók
Természetesen lehetőségünk van a lemezen lévő állományok megtekintésére. Ezt a
DISPLAY FILES [ON <meghajtó>] [LIKE <filenévtípus>]
Tehetjük meg. A parancs alapértelmezés szerint csak a .DBF kiterjesztésű adatbázis állományokat jeleníti meg (valamint az utolsó módosításuk dátumát), amennyiben a lemezen lévő összes file-ra kiváncsiak vagyunk, használnunk kell a LIKE paramétert:
DISPLAY FILES LIKE *.*
A dBase (minimális) lehetőséget ad a legalapvetőbb operációsrendszer funkciók elvégzésére. Tekintsük át, hogyan lehet általános, operációsrendszer-funkciót megvalósítani!
Tetszőleges, már létező állomány átnevezése:
RENAME <állomány régi neve> TO <állomány új neve>
A parancs csak egyértelmű állománynevekkel tud dolgozni, azaz nem adható meg állománycsoport a '*' vagy a '?' karakter segítségével. Azokat az állományokat, amelyeket dBase-ből nyitottunk meg és még nincsenek lezárva, nem lehet átnevezni.
A feleslegesnek ítélt állományokat törölhetjük is a lemezről a
DELETE FILE <állománynév>
paranccsal. A parancsban nem használhatunk joker karaktereket (*, ?), tehát az állományainkat csak egyenként törölhetjük.
4.6. A beépített "zsebkalkulátor"
A dBase egyik parancsa alkalmas arra, hogy a párbeszédes munka során bizonyos dolgokat megkérdezhessünk az adatbázis-kezelőtől (pl. egy kifejezés eredményét, egy változó értékét).
A parancs a következőképpen néz ki:
? <kifejezés[lista]>
Matematikai műveleteknél az eredményben annyi tizedesjegy szerepel, mint a tényezőkben. (Tehát pl. a 11/4 helyett érdemes 11.0000/4 kifejezést beírni.) Paraméterlista beírása szerint a matematikai műveletek a prioritási sorrend szerint hajtódnak végre.
Ha egy memória-változó értékére vagyunk kíváncsiak a '?' paranccsal lekérdezhetjük. Hasonlóan a beépített függvényekhez. Ha a beállított dátumot szeretnénk lekérdezni, a következő paranccsal tehetjük meg:
? DATE()
A date függvény "nn/hh/éé" alakban, szövegfüzér formában adja meg a rendszerdátumot.
A "?" parancshoz hasonlóan működik a "??" parancs, de itt a válasz nem a következő sorban fog megjelenni, hanem abban a sorban, amiben állunk. E tulajdonsága miatt inkább csak programkészítéskor van jelentősége. |
 |
Aritmetikai műveletek (a végrehajtásuk sorrendjében):
| ^ vagy ** | hatványozás |
| * , / | szorzás, osztás |
| +, - | összeadás, kivonás |
Karakterlánc műveletek:
| + |
Konkatenáció (öszefűzés) |
| - |
konkatenáció, a köztes szóközöket a lánc végére helyezve |
| $ |
Részkarakterlánc keresése (összehasonlító művelet) |
4.7. A memóriaváltozók interaktív használata
Röviden tekintsük át azokat a parancsokat, lehetőségeket, amelyek a memóriaváltozók interaktív, párbeszédes kezelésében rendelkezésünkre állnak (most nem említjük azokat a parancsokat, amelyek kifejezetten programban használatosak).
A legfontosabb tevékenység az értékadás, mely egyúttal a memóriaváltozó definiálását is jelenti. Ezt az alábbi paranccsal tehetjük meg:
STORE <kifejezés> TO <memóriaváltozóflista]>
A parancs létrehozza a memóriaváltozó(ka)t a megadott névvel és a kifejezésnek megfelelő típussal. Ha ilyen nevű memóriaváltozó már létezik, azt szó nélkül felülírja, a régi megszűnik.
A STORE parancs különlegessége, hogy használatakor egyszerre több memóriaváltozónak is adhatjuk ugyanazt az értéket:
STORE 1 TO i,j,k,l
A dátum típusú memóriaváltozó létrehozásához felhasználhatjuk rendszerdátumot lekérdező DATE() függvényt:
STORE DATE() TO datum
Minden értékadó utasítás végrehajtása után megjelenik a képernyőn a "parancsvégrehajtás eredménye", az az érték, amit végül is a memóriaváltozó őriz. Ez most nagyon hasznos, mert így az ellenőrzéshez nem kell külön egy "?" parancsot kiadnunk. Később azonban, különösen programban, nagyon zavaró lehet ez az állandó "visszabeszélés", ráadásul nem ez az egyetlen így működő parancs, mely a végrehajtásáról üzenetet küld. Ezek az "üzenetek" is letilthatók egy környezeti paraméter felhasználásával:
SET TALK OFF
A parancs végrehajtása után a sikeres parancsvégrehajtásokról nem kapunk felvilágosítást, csak az esetleges hibaüzenetek jelennek meg a képernyőn.
Az összes aktív (létező) memóriaváltozóról (azoknak típusáról), és a még felhasználható tárterület méretéről kaphatunk részletes információt a
DISPLAY MEMORY
parancs segítségével (ennek a parancsnak is létezik LIST kulcsszóval kezdődő párja).
A feleslegessé vált memóriaváltozók megszüntetésére, az általuk elfoglalt hely felszabadítására külön parancsot kell használni. Megadhatjuk konkrétan a megszüntetni kívánt memóriaváltozók nevét a
RELEASE <memóriaváltozólista]>
parancsban. De megadhatunk egy csoportot is a következő formában:
RELEASE ALL [LIKE I EXCEPT <memóriaváltozó-csoport>]
Ha csupán az "ALL" paramétert írjuk ki, minden memóriaváltozót töröl, a "LIKE" vagy "EXCEPT" paraméterek egyikével egy csoportot szüntet meg. (A "like" jelentése hasonló, az "except" kivételt jelent.) A csoportot "nem egyértelmű memóriaváltozó-névvel" lehet azonosítani (a '*' és a '?' karakter segítségével). A LIKE paraméter a csoportba tartozókon hajtatja végre a parancsot (ezeket törli), az EXCEPT pedig a csoport elemein kívül az összes többin.
Példa a csoportos törlésre (ha most N, N1, N2, N10, V7 nevű memóriaváltozók vannak):
RELEASE ALL LIKE N? (törli az N,N1,N2 nevűeket)
RELEASE ALL LIKE N?? (törli az N,N1,N2,N10 nevűeket)
RELEASE ALL EXCEPT ?1* (törli az N1,N10 nevűeket)
Az összes memóriaváltozót törli a
CLEAR
parancs is. A RELEASE ALL és ez utóbbi forma végrehajtása között programokban különbség van, erre ott visszatérünk.
Ha memóriaváltozóinkat később felhasználáshoz meg szeretnénk őrizni lemezre menthetők'. Alapértelmezés szerint a rendszer minden aktív memória-változót elment a megadott nevű állományba. Ez az ún. memóriaállomány (memory file), típusjele, ha nem adunk meg mást, ".MEM".
A mentést a
SAVE TO <állománynév> [ALL LIKE I EXCEPT <memóriaváltozó-csoport>]
paranccsal végezhetjük. A LIKE és EXCEPT paraméter az imént ismertetett módon működik, használatukkor az ALL szócskát is ki kell írni.
A lemezen tárolt memóriaállományból minden memóriaváltozót egyszerre lehet visszatölteni a
RESTORE FROM <állománynév>
paranccsal. Hatására az eddig aktív memóriaváltozók megszűnnek és a állományból betöltöttek kezdenek élni.
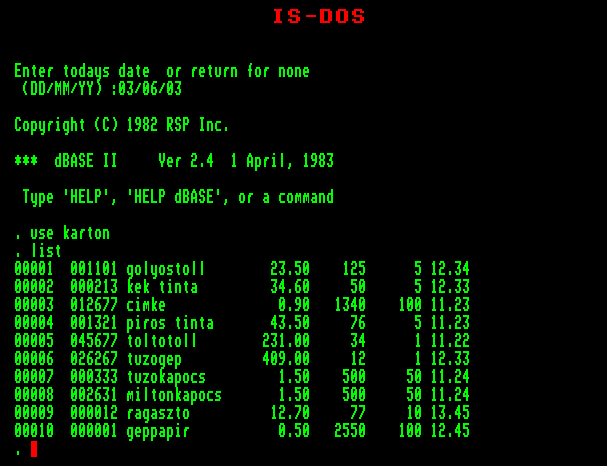
5. Adatbázis-állományok használata
A hosszú előkészítés után ebben a fejezetben megismerkedünk azokkal a legfontosabb parancsokkal, melyek lehetővé teszik egy adatbázis használatát. Bemutatjuk az adatbázis-állomány készítési módját, a rekordok feltöltését, módosítását. Megismerkedünk néhány adatmegjelenítési lehetőséggel.
5.1. Adatbázis-állomány létrehozása
Adatbázis-állomány felépítéséhez többféle parancs közül választhatunk, ám ezek között csupán egyetlen olyan van, amellyel az indításkor mintegy a "semmiből" készíthetünk új állományt. Ez pedig a
CREATE <állománynév>
parancs. Példaként adjuk ki a
CREATE karton
parancsot. (A "karton" a lemezes állomány neve lesz.) Körültekintően járjunk el a parancs kiadásakor, mert ha olyan állomány nevet választunk ami már létezik a lemezen, azt kérdezés nélkül felülírja a dBase!
Ha az állománynévben nem adunk meg kiterjesztést, adatbázisunk automatikusan ".DBF" típusjelet kap. Ehelyett bármilyen hárombetűs jelzést adhatunk neki, de akkor azt mindig le kell írni, ha erre a lemezes állományra szeretnénk hivatkozni.
A CREATE parancs a teljesképernyő-szerkesztő parancsokhoz hasonlóan működik. Egymás után kell megadnunk a leendő adatbázisunk mezőinek pontos definícióját. Egy mező különböző tulajdonságai egy sorba kerülnek. Az adatbázisok szerkezetének leírásakor ismertetet szabályok szerint kell megadnunk:
-
a mező nevét
-
a mező típusát (egyetlen karaktert, a típus kezdőbetűjét kell leütni)
-
a mező szélességét - csak karakteres és numerikus típusnál van értelme
-
a tizedesjegyek számát - ha numerikus mezőt definiáltunk
|
 |
Bármilyen hibás (nem megengedett) karaktert vagy értéket írunk be definícióba, azonnal figyelmeztetést kapunk, és amíg ki nem javítottuk nem mehetünk tovább. Az egyes elemeket (a mintának megfelelően vesszővel kell elválasztani.)
A CREATE parancs végrehajtását és ezzel az új adatbázis-állomány létrehozását befejezhetjük egy üres mezőnév bevitelével ('ENTER' megnyomása), ekkor valóban lemezre kerül az új állomány.
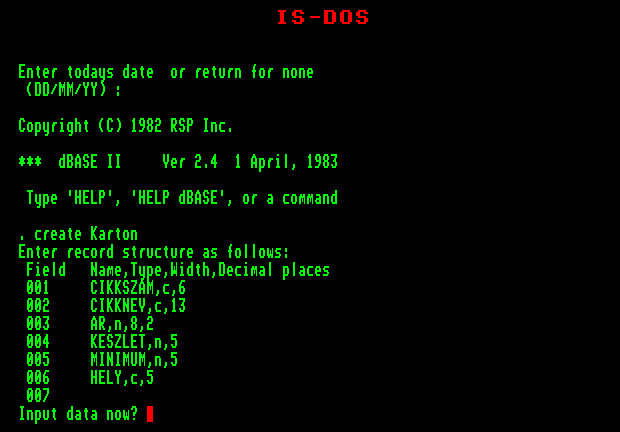
Már most jegyezzük meg, hogy a dBASE használata során bármikor, ha úgy érezzük, nem akarjuk a kiadott parancsot befejeztetni, esetleg az éppen kiadás előtt álló parancsot szeretnénk "elfelejteni", semmissé tenni, nyomjuk meg az 'ESC' feliratú billentyűt ("escape" = szökés, menekülés). Néhány esetben a módosítások elmentése még az 'ESC' segítségével sem úszható meg. Ezekre az adott helyen mindig külön felhívjuk a figyelmet, 'de nem árt már most megjegyezni, hogy általában azok az információk, `amelyek egyszer már lekerültek a képernyőről - hogy továbbiak jelenhessenek meg - rögtön tárolódtak is.
Az adatbázis-szerkezet lemezre mentése után még egy kérdésre kell válaszolnunk: "Input data now? (Y / N)" (= Most töltünk be rekordokat?). Ha az 'Y' leütésével jelezzük adatbeviteli szándékunkat, akkor a dBASE egymás után, rekordonként nevükkel együtt kiírja az üres 'mezőket, melyeket teljesképernyő-szerkesztő módon kitölthetünk. A rekordok felvitelének befejezése egy üres rekord bevitelével vagy a 'CTRL'+'Q' billentyűk megnyomásával történik.
Később, ha már kezelni tudjuk létrehozott adatbázis-állományainkat, visszatérünk az adatbázis-készítés további lehetőségeire (ld. az "Adatbázis készítése meglévő állományok felhasználásával" című fejezetet). Ne feledjük el, hogy a CREATE parancs nem alkalmas régi állomány módosítására!
5.2. Adatbázis használatba vétele
A létrehozott, lemezen tárolt állományainkat használat előtt meg kell nyitni, mielőtt tartalmát lekérdeznénk vagy módosítanánk. Adatbázis megnyitására egyetlen parancs használható:
USE <adatbázisállomány-név>
Ez a parancs ".DBF'" típusjelet feltételez, ha nem adunk meg mást, és csak adatbázis megnyitására alkalmas. Egy munkaterületen csak egy adatbázis fér el, így egy másik állomány azaz egy új USE parancs - lezárja az előzőleg megnyitottat. Több állomány egyidejű nyitva tartásához minden új ESE előtt a SELECT parancs segítségével át kell költöznünk a másik munkaterületre.
A különböző területen megnyitott állományaink tartalmához bárhonnan hozzáférünk, de a rekordmutatót csak a kiválasztott munkaterületen tudjuk mozgatni. Ezért ezt megkülönböztetésül "aktív" adatbázis-állománynak is nevezzük.
Az adatbázis-állományokban vannak a legfontosabb információk, a nyilvántartandó adatok, ezért ezek gondos lezárására mindig nagyon ügyeljünk. A dBASE igyekszik kevés lemezműveletet végezni, így a nyitva felejtett állományok a legközelebbi megnyitáskor nem biztos, hogy tartalmaznak minden bevitt adatot. (Az ilyen balesetek úgy kerülhetők el a legkönnyebben, hogy betartjuk a szabályt, és mindig QUIIT paranccsal lépünk ki az adatbázis-kezelőből. Ez ugyanis mind szükséges információt felvezet a lemezekre is, mielőtt visszalépne operációs rendszerbe.)
Egy adatbázis-állomány lezárása azt is jelenti, hogy azok a segédállományok, amelyek szorosan hozzá tartoznak, azaz nélküle nem létezhetnek, szintén lezáródnak. (Ilyen az index- és a formátumállomány valamint ide tartozik a memória-állomány is.)
Az aktuális, kiválasztott munkaterületen megnyitott adatbázist a
USE
parancs zárja le.
Az adatbázisok megfelelő használata érdekében nem engedhetjük meg magunknak, hogy elfelejtsük, milyen szerkezettel hoztuk létre őket. Ha a körülmények szerencsétlen összejátszása miatt ez mégis megtörténik, könnyen kaphatunk hibaüzenetet. Ilyenkor nagyon hasznos, ha kiíratjuk magunknak újra a pontos szerkezetleírást. Ezt valósítja meg a
DISPLAY STRUCTURE
parancs, amely az aktív adatbázisról nyújt bőséges információt.
A parancs kiírta az adatbázis nevét, rekordjainak számát, az utolsó -aktualizálás dátumát, az egyes mezők nevét, típusát, hosszát és egy rekord teljes hosszát. Ne ijedjünk meg, a számítógép nem felejtett el összeadni. Egy rekord teljes hossza egy byte-tal mindig nagyobb, mint a mezők hosszának összege. A dBASE ezt az egy karakternyi helyet is tárolásra használja. Hogy pontosan mit ír bele, azt az adatrekordok törléséről szóló fejezetben áruljuk el.
5.3. A rekordmutató egyszerű mozgatása az adatbázisban
Egy új adatbázis készítése és azonnali feltöltése után a rekordmutató az adatbázis végén van, egy lemezen található állomány megnyitása után pedig a legelső rekordon.
Az adatbázis rekordjaira vonatkozó parancsaink következményeként a rekordmutató legtöbbször elmozdul előző helyéről, és az utolsó "kézbevett" rekordra áll. A rekordmutatót azonban mi magunk is beállíthatjuk egy adott helyre a következő parancsok valamelyikével:
GOTO <n>
GO <n>
<n>
forma közvetlenül az "n"-edik sorszámú rekordra állítja a rekordmutatót
A rekordok sorszámukat a rögzítés során, folyamatosan emelkedő rendben kapják, ezt a rögzítési sorrendet nevezzük fizikai sorrendnek. Az adatbázisok rendezése után egy ettől általában eltérő logikai rendet is felvehetnek a rekordok. A logikai rendben másként is lehet mozgatni a rekordmutatót, erre a rendezési lehetőségeknél visszatérünk.
5.4. Adatok megjelenítése az adatbázisból
Rekordok megjelenítésére alapvetően két parancs áll rendelkezésünkre. Ezek egymástól az alapparancsban különböznek, de megadható paraméterek ugyanazok. Az egyik parancs folyamatos listázza a megadott rekordokat (LIST kulcsszóval), a másik pedig képernyő oldalanként megáll és megvárja, hogy elolvassuk a monitorra kiírt információkat (DISPLAY kulcsszóval). Az interaktív munka során utóbbit használjuk gyakrabban, éppen működési módja miatt.
A két parancs sok lehetséges paramétere közül egyesével nézzük végig a fontosabbakat. (Ezt a módszert később is követni fogjuk, bonyolultabb parancsok ismertetésénél.)
A legfontosabb paraméter az érvényességi kör, mely a parancs formájából láthatóan elhagyható. Hatására az érvényességi körbe eső rekordokat a képernyőre írja a rendszer.
DISPLAY [<érvényességi kör>]
Nézzünk végig a lehetséges érvényességi kört:
| DISPLAY |
az aktuális rekordot (amin a rekordmutató áll) jeleníti meg |
| DISPLAY RECORD x |
a x. rekordot jeleníti meg (a rekordmutató az x. rekordra áll) |
| DISPLAY NEXT x |
az aktuális rekordtól x számú rekordott jelenít meg (a rekordmutató az utolsó megjelenített rekordra áll) |
| DISPLAY ALL |
az adatbázis összes rekordját megjeleníti (a rekordmutató az utolsó rekordra áll) |
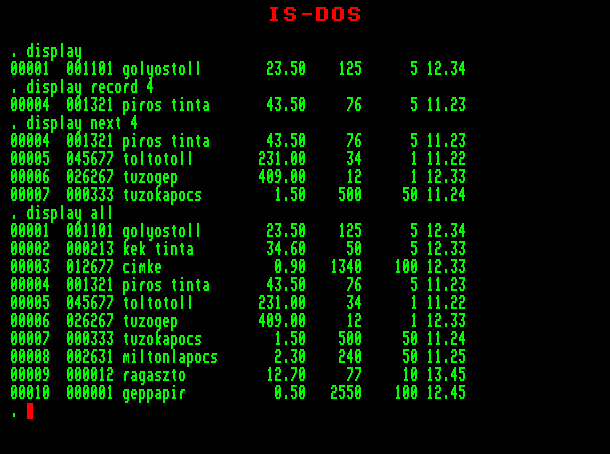
Gyakran előfordul, hogy a DISPLAY utasítással megjelenített rekordok nem férnek ki egy képernyőre. Ilyenkor a "képernyő végén" megjelenő felirat: "Waiting", amely arra szólít fel bennünket, hogy a listázás folytatásához nyomjunk meg egy tetszőleges billentyűt.
Bármely példában megadhatjuk a LIST kulcsszót a DISPLAY helyett. A LIST érvényességi körének alapértelmezése "ALL", azaz minden rekordot kiír. További különbség, hogy folyamatosan, megállás nélkül listáz.
Mindkét parancs táblázatosan jeleníti meg a rekordok tartalmát. Az első oszlopban olvasható rekordsorszámok a rekordok fizikai (rögzítési) sorrendjét tükrözik. Ez sokszor nagyon lényeges információ, ezért ennek kikapcsolásáról minden egyes listázási parancsban külön gondoskodnunk a DISPLAY és LIST parancsok "OFF" paraméter szerepeltetésével:
LIST OFF
DISPLAY OFF
Egy olyan lista készítése után, ahol az adatbázis végéig kell kiírni rekordokat ("ALL" érvényességi körrel), a rekordmutató az adatbázis végére mutat. Ha megadjuk, hogy egy konkrét rekordot írjon ki (DISPLAY RECORD <n>), akkor a rekordmutató visszakerül az adatbázis belsejébe. Ugyanezt elérhetjük a GOTO paranccsal is.
A DISPLAY és LIST parancsban paraméterként megadható kifejezésekből álló lista is a következő módon:
LIST [<kifejezéslista>]
Ez nyújt lehetőséget annak a gyakori igénynek a megoldására, hogy az aktív adatbázis mezői közül csak néhányat jelenítsünk meg (a mezőnév önmagában kifejezésnek számít, hiszen változó).
Ha egy állományunk például túl "széles", egy-egy rekord nem fér el a képernyőn, ezért két sorban jelenik meg. Ez a forma meglehetősen olvashatatlan. Ilyenkor elég, ha azokat a mezőket íratjuk ki, melyekre éppen kíváncsiak vagyunk.
LIST mezőnév1, mezőnév2
Használhatjuk a DISPLAY parancsot is "ALL" érvényességi körrel. Ha ez utóbbit választjuk, akkor ez már két paraméter egyidejű használatát lenti, ne felejtsük el, hogy ezek sorrendje nem lényeges. Az alábbi két parancs mindegyike helyes:
DISPLAY ALL mezőnév1, mezőnév2
DISPLAY mezőnév1, mezőnév2 ALL
Az aktuális rekord mezőire hivatkozhatunk a "?" parancsban is. Például a
? mezőnév1, mezőnév2
az aktuális rekord mezőnév1, és mezőnév2 mezőit jeleníti meg (ez egy szép mondat...)
5.4. Numerikus mezők összege
Az adatbázisból nemcsak rekordonként tudunk adatokat megjeleníteni, lehetőségünk van numerikus mezők összegének vagy átlagának kiíratására is. Egy vagy több, számokat tartalmazó oszlopot összegez a
SUM [<kifejezéslista>] [TO <memóriaváltozó-lista>][<érvényességi kör>] [FOR <feltétel>][WHILE <feltétel>]
parancs. Ha memóriaváltozóba akarjuk helyezni az eredményt, pontosan annyi nevet kell felsorolnunk, ahány numerikus kifejezést megadtunk; ha nincs kifejezéslista, akkor az aktív adatbázis minden numerikus mezőjét összegzi. A FOR és WHILE paraméterek segítségével megadott feltétel az összegzésben részt vevő rekordok körét tudjuk befolyásolni.
5.5. Válogatás az adatbázisból adott szempontok szerint
Adatbázis használatakor általában a rekordoknak csupán egy részén kívánunk elvégezni egy-egy tevékenységet. Ezek a rekordok többnyire nem férnek bele a lehetséges érvényességi körökbe, mert nem egymást követően lettek rögzítve, és így az adatbázis különböző pontjairól kell őket összeválogatni. Szerencsére a WHILE és FOR paraméterek parancsvégrehajtás közben tudják elvégezni ezt a válogatást, így egyetlen utasítás kiadásával minden megfelelő rekordon elvégeztethető a művelet.
A parancsszintaktika ismertetésénél már leírtuk, hogy e két paraméter között milyen különbségek vannak, most példákkal is illusztráljuk ezeket.
A "KARTON" nevű állományban ugyanarról a helyről indulva nézzük meg működésüket. Először adjunk ki egy DISPLAY parancsot FOR paraméterrel:
Minden olyan rekordból kiírta a megadott három mezőt, amely kielégíti a feltételt, azaz "ar" nevű mezőjében egy tíznél kisebb szám van (anélkül, hogy külön kiírtuk volna, az érvényességi kör nem csupán az aktuális rekord, ez is a FOR paraméter műve). A rekordmutató az állomány végére került. | 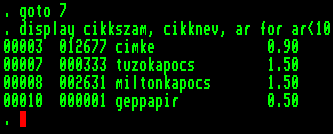 |
Most ugyanolyan feltételekkel, de WHILE paramétert szerepeltetve hajtassuk végre a parancsot:
A rekordmutató ugyanott állt, feltételnek ugyanazt adtuk meg, az eredmény mégis más, nem vizsgálta meg az aktuális rekord előtti részt, és a kilences rekordon megállt (ez az első, amelyre nem teljesül a feltétel, a továbbiakban ez az aktuális rekord). Vegyük észre, hogy ezek paraméterek is csereberélhetők. | 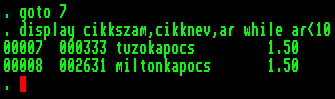 |
Válogatás ürügyén remek alkalmunk nyílik néhány különleges függvény, illetve művelet bemutatására, hiszen a WHILE és FOR paraméterekben megadott feltételek szerepelhetnek sok más parancs után is.
Tekintettel arra, hogy a leggyakrabban karakteres mezővel dolgozunk, ebben kell a legtöbbször válogatni is. Ezzel kapcsolatban legfontosabb, amit meg kell jegyeznünk, hogy a számítógép számára pl. a "b" és a "B" betűk annyira különböznek egymástól, mint mondjuk egy újszülött víziló a saját anyjától: több közös vonásuk van, de semmiképp sem tekinthetők azonosnak.
Ha rákeresnénk a "címke" cikknévre a következő utasítással:
LIST FOR CIKKNEV="CIMKE"
Akkor bizony a "címke" nem jelenik meg, mivel az adatbázisunkban kisbetűvel írtuk, és mi nagybetűvel kerestünk rá. A probléma megoldására használhatjuk a nagybetűssé konvertáló "!" függvényt:
LIST FOR !(CIKKNEV)="CIMKE"
(Az egyenlőség megvizsgálása előtt a "cikknev" mező tartalmát a dBASE "fejben" átalakítja nagybetűssé és így végzi el az összehasonlítást. A mező tényleges tartalma nem változik.)
|
 |
A dBASE alapértelmezés szerint karakterláncok összehasonlításánál nem követel meg pontos egyezést, megengedett a különböző szöveghosszúság. Tehát pl. 'ABC' = 'ABCDEF'. Ez keresésnél nagyobb rugalmasságot biztosít, de ha mégis pontos egyezést szeretnénk előírni, azt a
SET EXACT ON
paranccsal tehetjük meg. E környezeti paraméter bekapcsolását követően két karakterláncot már csak akkor talál egyenlőnek a rendszer, ha valóban betűről betűre megegyeznek. (Kivéve, ha olyan adatmezőt hasonlítunk össze a karakterlánccal, melynek a tartalma nem tölti ki a teljes szélességet. Ilyenkor a mező végén lévő szóközöket az összehasonlításnál nem veszi figyelembe.)
-
Természetesen senki nem akadályoz meg benne, hogy akár összevont feltételeket is vizsgáljunk a logikai ÉS / VAGY fügvények segítségével:
LIST FOR CIKKNEV="címke" .or. CIKKNEV="tuzogep"
LIST FOR HELY="11.23" .AND. AR>10
Nagyon hasznos lehet szöveges adatok keresésénél a "$" relációs operátor, amellyel rész-karakterláncokat kereshetünk. Keressük meg például, milyen tintáink vannak készleten (melyik cikknévben szerepel a "tinta" karakterlánc):
LIST CIKKNEV,AR FOR "tinta" $ CIKKNEV
-
A "$" fügvény arra is alkalmas, hogy egy string tetszőleges részét kiolvassuk:
$ (KIF. vagy VÁLTOZÓ vagy KARAKTERLÁNC,KEZDET,HOSSZ)
Példa: ? $("Enterprise", 5,4)
-
Válogatási szempont lehet, hogy egy bizonyos karakter, vagy szövegrész melyik pozícióban található először. Részkarakter-láncokat kereshetünk egy tetszőleges kifejezésben a "@" fügvénnyel:
@ (karakterlánc1,karakterlánc2)
@ (változó1,változó2)
A függvény az első karakterláncot keresi meg a másodikban, értékként azt a számot adja, amelyik sorszámú karakterhelyen kezdődően megtalálta. Ha nem találja, akkor nullát kapunk.
Például a ? @ ("ABLAK","KISABLAK") kifejezés értéke 4 lesz.
| Figyelem!!! Attól függően, hogy milyen karakterkészletet használunk, lehet, hogy nem találjuk a "@" jelet, ez ne zavarjon minket, helyette a nagy 'Á' betűt kell használni, amit PC billentyűzetről az 'SHIFT+0' megnyomásával csalhatunk elő. A @ karakter használatára később is szükségünk lesz, tehát ezt jól jegyezzük meg. |
Mivel a rekordkeresésnek elsősorban programíráskor van jelentősége, nem árt, ha tudjuk hány rekord felel meg az adott keresési feltételnek. Erre szolgál a
COUNT [<érvényességi kör>] [WHILE <feltétel>] [FOR <feltétel>] [TO <memóriaváltozó>]
ami az adott érvényességi körbe eső rekordok összeszámlálására, számának kijelzésére vagy memóriaváltozóba helyezésére szolgál.
5.6. Az adatbázis karbantartása
Az adatbázisok használatakor szinte naponta kell meglévő rekordjainkat módosítani, esetleg egyet-egyet megszűntetni, vagy új rekordokat az adatbázisba illeszteni, azaz a rekordokat naprakész állapotban kell tartani. Ezt a tevékenységet nevezhetjük az adatbázis karbantartásának.
5.6.1. Rekordok hozzáfűzése, módosítása
Az adatbázis végéhez az
APPEND
parancs segítségével új rekordokat fűzhetünk (a parancs végrehajtása kísértetiesen hasonló a CREATE parancsban végrehajtott rekordfeltöltéshez). Ha meggondoljuk magunkat, és mégsem szeretnénk új rekordot létrehozni a CTRL+Q segítségével megszakíthatjuk a bevitelt.
Ha az egymás után rögzítendő rekordok sok hasonló adatot tartalmaznak, hasznos lehet, ha adatbevitelnél a dBASE az egyes mezőkbe bemásolja az előző rekord adatait. Ezt a szolgáltatást a
SET CARRY ON
paraméterrel kapcsolhatjuk be. Mivel ez számít ritkább esetnek, az alapértelmezés a kikapcsolt állapot.
Az adatbázis belsejébe új rekordot szúrhatunk be a
INSERT [BEFORE] [BLANK]
panccsal. Opció nélkül az aktuális rekord mögé helyezi el az új rekordot. BEFORE opcióval (before = előtt) az aktuális rekord elé kerül az rekord (a rekordmutató nem mozdul el, a mögötte elhelyezkedő rekordok eggyel hátrébb lépnek, eggyel megnő a sorszámuk). A beszúrás után rögtön feltölthetjük adatokkal a rekordot (hasonlóan az APPEND parancsnál látottakhoz). Amennyiben nem kívánjuk az új rekordot adatokkal feltölteni, csak egy üres rekordot kívánunk beszúrni az adatbázisunka, használjuk a BLANK opciót.
Létező rekordjainkat az EDIT vagy CHANGE parancs segítségével módosíthatjuk, a két parancs azonos paraméterekkel rendelkezhet, működésük némileg eltérő. Az EDIT utasítással teljes képernyős módban szerkeszthetjük a rekordot:
EDIT - a kívánt rekordtól kezdjük a szerkesztést és folytathatjuk addig, amíg ki nem lépünk belőle (CTRL+Q) (Nem támogatja a dBase II összes változata!)
EDIT x - az x rekordtól kezdjük a szerkesztést.
A CHANGE parancs használata némileg összetettebb. Itt nem, teljes képernyős módban szerkeszthetjük a feltételeinknek megfelelő rekordjaink kívánt mezőjét:
CHANGE [<érvényességi kör>] FIELD <mezőlista>
A parancsban használható a WHILE és FOR paraméter. Vegyük észre, hogy a FIELD szó nem hagyható el! Ezzel az utasítással a "KARTON" állományunkban könnyen módosíthatjuk a 100Ft-nál drágább termékek árát:
CHANGE FOR AR>100 FIELD AR
Több rekord "egyidejű" javítását teszi lehetővé a
BROWSE
parancs. A rekordok táblázatos formában jelennek meg (egy rekord egy sor, egyszerre legfeljebb 19 rekord), az aktuális rekordtól kezdődően. A táblázatban lépegetve tetszőlegesen módosíthatjuk a mezők tartalmát, de nincs lehetőségünk új rekordok hozzáfűzésére.
Ha a tárolt információ hosszabb, mint 80 karakter, akkor a tábla jobb széle "kilóg" a képből, de a szerkesztő billentyűkkel (CTRL + Z, CTRL + B) ugyanúgy elérhetők a kilógó mezők. Ha ezt kényelmetlennek találnánk, és amúgy sem szeretnénk a rekordok minden mezőjét módosítani, a
BROWSE FIELDS <mezőlista>
parancs csak a felsorolt mezőket jeleníti meg, csak ezeket lehet módosítani.
 Az ismertetett parancsok mind interaktív módon engedik javítani a rekordok tartalmát. Egyik sem alkalmas arra, hogy egy létező memóriaváltozó értékét helyezze el a mezőben, erre külön parancs szolgál, melyet gyakrabban használunk a programban, ezért a programozásról szóló részben térünk ki rá.
Az ismertetett parancsok mind interaktív módon engedik javítani a rekordok tartalmát. Egyik sem alkalmas arra, hogy egy létező memóriaváltozó értékét helyezze el a mezőben, erre külön parancs szolgál, melyet gyakrabban használunk a programban, ezért a programozásról szóló részben térünk ki rá.
5.6.2. Rekordok törlése az adatbázisból
Egy rekord törlése nem csupán azt jelenti, hogy tartalmát töröljük hanem azt is, hogy maga a rekord megszűnik, eggyel kevesebb rekordja lesz az adatbázis-állománynak. A rekordok emelkedő sorszámozása helyreáll, minden rekord, amely a törölt után helyezkedett el, eggyel "előbbre lép" (eggyel csökken a sorszáma). Bizonyos körbe tartozó (valamilyen feltételt kielégítő) rekordok törölhetők két lépésben. Először meg kell jelölnünk azokat a rekordokat, amelyeket törölni szándékozunk ("törlésre jelölés"), majd egy külön paranccsal lehet elvégezni a megjelöltek tényleges törlését. A
DELETE [<érvényességi kör>] [WHILE <feltétel>] [FOR <feltétel>]
parancs törlésre jelöli az érvényességi körbe tartozó, az esetleges feltételeket kielégítő rekordokat. Az érvényességi kör alapértelmezés szerint az aktuális rekord (azaz NEXT 1). A parancs végrehajtása után a program közli velünk, hány rekordot jelöltünk törlésre. A törlésre jelölt állapotot a LIST és DISPLAY parancs eredményében (a kiírt listában) a rekordsorszám és a rekord tényleges, tartalma között megjelenő csillag ("*") jelzi. Példaképpen jelöljük törlésre a "KARTON" állományból a száznál kisebb készlettel rendelkező árucikkeket, és nézzük meg a rekordok listáját:
DELETE FOR KESZLET<100
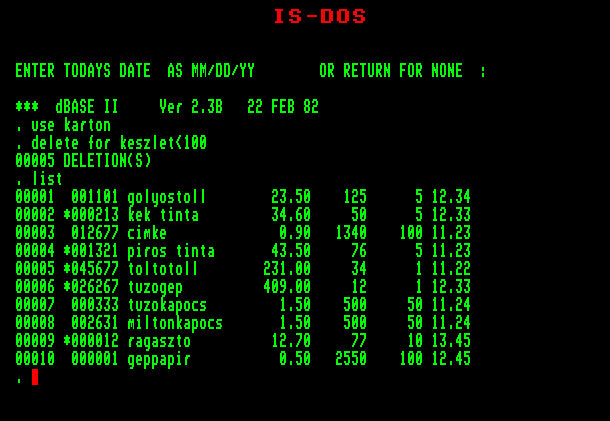
Törlésre jelölést végezhetünk a már ismertetett teljesképernyő-szerkesztő módon működő rekordmódosító parancsok végrehajtása közben is (APPEND, EDIT, BROWSE): a törlendő rekordon állva a CTRL+U billentyűket kell megnyomni. Ezután a felső sorban megjelenik a "DELETED" felirat. A törlésre kijelölést végző billentyűkombináció kapcsolóként működik, ugyanazon a rekordon való ismételt megnyomása visszaállítja a kiindulási állapotot.
Egy környezeti paraméter segítségével a törlésre jelölt rekordok elrejthetők a további parancsok elől, mintha már megtörtént volna a tényleges törlés. Ha a
SET DELETED ON
parancsot adjuk ki, a törlésre jelölt rekordokat nem veszik figyelembe az parancsok, amelyek érvényességi köre több rekordot ölel fel (ALL, illetve FOR vagy WHILE paraméter szerepel bennük), nem jelennek meg a képernyőn. (Azok a parancsok, amelyeknek ilyen paramétere nem lehet, minden rekordot figyelembe vesznek az előírt tevékenység elvégzésekor, tartalmuktól és tulajdonságaiktól függetlenül.) A törlésre jelölt rekordok elrejtése után ezek nem jelennek meg például az adatbázisról készíttetett listában, azonban a rekordsorszámok nem folyamatosan követik egymást: a törlésre jelölt rekordjaink fizikailag még léteznek.
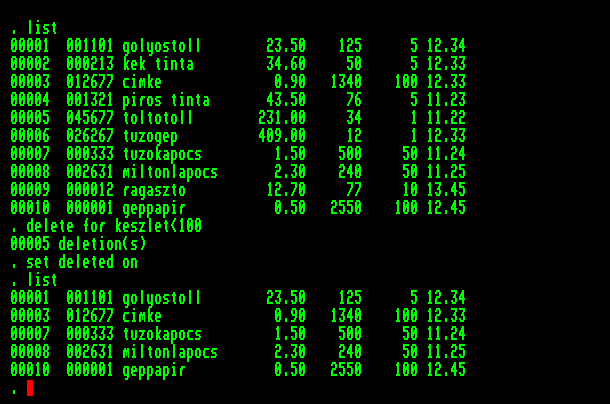
Vegyük észre, hogy ezen a listán látszik valami turpisság, hiszen a rekordsorszámok nem folyamatosan követik egymást: Törlésre jelölt rekordjaink fizikailag még léteznek. Dolgozni is lehet velük, ha a parancsban konkrétan utalunk rájuk:
GOTO 2
DISPLAY
vagy
DISPLAY RECORD 2
Mindkét változatban akadály nélkül hozzáférhetünk egy törlésre jelölt rekordhoz is, de csak ebben a konkretizált formában lehetséges.
A rekordok törlésre jelölt tulajdonságát programból is tudjuk ellenőrizni a "*" függvény segítségével. Ez logikai értéket ad vissza, és akkor "igaz", ha az aktuális rekord törlésre van jelölve. E függvény felhasználásával készíthetünk az adatbázisról olyan listát is, amelyben csak a törlésre jelölt rekordok szerepelnek:
SET DELETED OFF
LIST FOR *

A * függvény visszatérési értékét nem kell semmivel összehasonlítani, az már önmagában igaz vagy hamis értékű.
A dBASE a rekordok törlésre jelöltségét az adatbázisban tára (azaz a lemezes állományba is felírja), mégpedig abban a "felesleges" byte-ban, amellyel hosszabb egy rekord, mint a mezők hosszának összege.
A törlésre jelöltséget meg lehet szüntetni (a rekordokat "vissza lehet hívni") a
RECALL [<érvényességi kör>] [WHILE <feltétel>] [FOR <feltétel>]
paranccsal. Az érvényességi kör alapértelmezése itt is az aktuális rekord. Az "elrejtett" rekordokhoz ez a parancs is csak akkor fér hozzá, ha konkrétan hivatkozunk rájuk. Végrehajtáskor a DELETE parancshoz hasonlóan közli, hány rekordot "hívtunk vissza".
A törlésre jelölt rekordok végleges megszűntetése (tényleges törlése) a
PACK
paranccsal történik. Ez a kiadás pillanatában törlésre jelölt összes rekordot törli, és helyreállítja az egyesével növekvő sorszámozást. Az így megszüntetett rekordok semmilyen módon nem nyerhetők vissza.
6. Adatbázisok rendezése
Adataink rendezése több szempontból szükséges lehet. Például az adatbázisról készített listákat mi magunk is szeretjük rendezve látni, ezekben hamarabb megtaláljuk a keresett rekordot. Ez utóbbi szempontból a dBASE is jobban kedveli a rendezett állományokat. Néhány parancs működése közben feltételezi, hogy a rekordok rendezve vannak mások nem is működnek, ha az adatbázis rekordjai nem rendezettek. A dBASE II kétféle módon tud rendezni. Az egyik fizikailag átrendezi a rekordokat, a másik csak a logikai sorrendjüket tartja nyilván egy segédállományban, ezt nevezzük indexállománynak.
6.1. Adatrekordok fizikai rendezése
A SORT parancs egy másolatot készít az aktív adatbázisról, a rekordok a logikai rendnek megfelelő sorrendben kerülnek az új állományba. Az így készült állomány tehát fizikailag rendezett (a fizikai rekordsorrend megegyezik a logikai renddel).
A parancs alakja:
SORT ON <mezőnév> TO <új állománynév> [DESCENDING]
Az új állomány közönséges adatbázis-állomány, típusjele alapértelmezés szerint ".DBF" lesz. A rendezés után az eredeti állomány marad nyitva, ha az újat akarjuk a továbbiakban használni, azt előbb meg kell nyitni. A rendezés alapértelmezés szerint növekvő sorrend szerint történik. Numerikus mezők esetében ez a rendezés egyértelmű. Karakteres mezőn az ASCII kódtáblázat alapján végzi a rendezést, szerencsére ebben ABC rendben vannak a betűk, de minden nagybetű megelőzi a kisbetűket. (De senki ne várja, hogy a magyar ékezetes betűket tartalmazó szavak a megfelelő helyre kerüljenek...) Ebben a rendben például a "anita" a "Zita" mögé kerül. Ez persze csak az angol abc betűire vonatkozik, a magyar karakterkészlettel ez a program még nem tud tökéletesen hozni). A DESCENDIG opció használatával kérhetünk csökkenő sorrendbe történő rendezést is.
A rendezett állomány a lemezen jön létre, használatához először meg kelt nyitni. Ettől kezdve ugyanúgy kezelhető, mint bármely más adatbázis-állomány, ezért amikor módosítjuk a rekordok tartalmát, a rendezettség megszűnhet (ha új rekordot fűzünk hozzá, akkor nagy valószínűséggel meg is szűnik), és újra kell rendezni.
|
 |
6.2. Adatbázis logikai rendesése
A logikai rendezés - indexelés - egy segédállományt hoz létre a rekordok sorrendjének (és a rendezési kulcs) tárolására. Ilyenkor a rekordok fizikai sorrendje nem változik, és az indexállomány - ha meg van nyitva - minden módosításkor aktualizálódik. Ez az utóbbi tulajdonsága is indokolja, hogy sokkal gyakrabban használjuk, mint a SORT parancsot. A dBASE is ezt a módszert támogatja inkább, az indexelt állományokban ugyanis néhány fontos műveletet gyorsabban tud elvégezni.
Az indexállományok elkészítésére egyetlen parancsot használhatunk:
INDEX ON <kulcskifejezés> TO <indexállomány neve>
 Indexelni csak növekvő sorrendben lehet. Vigyázni kell azonban arra, hogy a karakteres kulcskifejezések értéke nem lehet hosszabb 99 karakternél (más típusnál ezt a korlátot nem lehet megközelíteni sem). Logikai típusú mező itt sem szerepelhet. Az indexelési parancsban érvényességi kör nem adható meg, az egész állományt indexeli (még a törlésre jelölt, elrejtett rekordok is). Az indexállomány típusjele ".NDX". Az indexállomány létrejötte után azonnal aktivizálódik, és ettől kezdve minden parancs az ebben előírt sorrendben "látja" az adatbázist. Ezt nevezzük logikai sorrendnek, a rekordok a parancsok által meghatározott műveletekben mindig ebben a sorrendben vesznek részt. Az INDEX parancs segítségével egy adatbázishoz tetszőleges számú indexállomány készíthető. Ez a parancs végrehajtása előtt lezárja az aktuális adatbázis jelenleg nyitott indexállományait - ha vannak ilyenek -, csak az éppen elkészült marad aktív állapotban.
Indexelni csak növekvő sorrendben lehet. Vigyázni kell azonban arra, hogy a karakteres kulcskifejezések értéke nem lehet hosszabb 99 karakternél (más típusnál ezt a korlátot nem lehet megközelíteni sem). Logikai típusú mező itt sem szerepelhet. Az indexelési parancsban érvényességi kör nem adható meg, az egész állományt indexeli (még a törlésre jelölt, elrejtett rekordok is). Az indexállomány típusjele ".NDX". Az indexállomány létrejötte után azonnal aktivizálódik, és ettől kezdve minden parancs az ebben előírt sorrendben "látja" az adatbázist. Ezt nevezzük logikai sorrendnek, a rekordok a parancsok által meghatározott műveletekben mindig ebben a sorrendben vesznek részt. Az INDEX parancs segítségével egy adatbázishoz tetszőleges számú indexállomány készíthető. Ez a parancs végrehajtása előtt lezárja az aktuális adatbázis jelenleg nyitott indexállományait - ha vannak ilyenek -, csak az éppen elkészült marad aktív állapotban.
A szükséges indexelések elvégzése (az indexállományok után az adott adatbázishoz egyszerre több, de legfeljebb 7 indexállományt nyithatunk meg a
SET INDEX TO <indexállomány-lista>
paranccsal. Rögtön az adatbázis megnyitásakor is aktivizálhatók az állományok a
USE <adatbázisnév> INDEX <indexállomány-lista>
parancs formával. A felsorolásban elsőként megadott indexállomány lesz a főindex (master index), amely meghatározza a logikai sorrendet, minden további megnyitott indexállomány is aktualizálódik az adatbázisban végzett módosítások nyomán.
Ha egy indexállomány nincs nyitva, amikor módosítani kellene (például új rekordok hozzáfűzésekor), akkor megnyitása után a módosításokról nem tud, rossz sorrendben listáz az új rekordokat egyáltalán nem veszi figyelembe. (Ezért javasolt az adatbázishoz tartozó összes indexállományt is megnyitni, akkor is, ha nincs rájuk szükségünk.) Ilyenkor nekünk kell külön gondoskodnunk ennek kijavításáról. Az indexállományok aktualizálását, "újjáépítését" a
REINDEX
Paranccsal is kiválthatjuk, ez az aktív adatbázishoz megnyitott összes indexállományt újra elkészíti.
Az indexállományok csak ahhoz az adatbázishoz nyithatók meg, amelyhez készítettük (ezért lényeges megjegyezni, hogy egy-egy indexállomány hova tartozik). Az adatbázis lezárásakor az összes indexállománya is lezáródik. A munkaterületek tartalmáról kapott információk között (DISPLAY STATUS parancs) azt is elolvashatjuk, hogy egy-egy adatbázishoz mely indexállományok vannak nyitva, és ezek közül melyik a főindex.
6.3. A rekordmutató mozgatása indexelt adatbázisban
Az indexelt állományok listázásakor a rekordsorszámok már nem folyamatosan emelkedő rendben követik egymást, hanem meglehetős összevisszaságban, ahogy azt a logikai sorrend előírja. Lényeges, hogy ebben a fizikai sorrendtől független logikai rendben is tudjunk mozogni (például most a GOTO 1 paranccsal egyáltalán nem biztos, hogy az első rekordra kerülünk).
Az adatbázis két - logikai - végére a következő parancsok viszik a rekordmutatót:
GO TOP - a logikailag első rekordra áll
GO BOTTOM - a logikailag utolsó rekordra áll
Szükség van arra is, hogy a rekordsorszámok ismerete nélkül logikai rendben "a következő" rekordra tudjunk menni. Ezt teszi az alábbi parancs:
SKIP
E parancs ilyen formában eggyel "lejjebb" lépteti a rekordmutatót a sorbann. Megadhatunk azonban egy számot is, hogy annyival menjünk előbbre, esetleg (negatív szám esetén) visszafelé:
SKIP <n>
elmondottakból következik, hogy a következő két parancs teljesen egyenértékű:
SKIP
SKIP 1
Valamink a következő parancsok is helyesek: SKIP 5, SKIP -2
A SKIP parancs - éppen azért, mert nem lehet tudni melyik rekordra helyezi a rekordmutatót, végrehajtás után üzenetet küld. A "Record 0009" üzenet például arról tájékoztat bennünket, hogy a 9. sorszámú rekord lett az aktuális. Az üzenet megjelenése a SET TALK paranccsal tiltható le. Ha az utasítással "kilépnénk" az adatbázisból, a parancs az első vagy utolsó rekordra ugrik.
Esetenként fontos lehet tudni, hogy az aktuális rekord után van e további rekord, vagy esetleg az adatbázis végén állunk. Ezt egy tesztelő függvény ellenőrzi:
EOF - igaz értéket szolgáltat, ha az állomány végén állunk (end of file)
A függvénynek nincs argumentuma.
 7. Keresés az adatbázisban
7. Keresés az adatbázisban
Keresés alatt azt a folyamatot értjük, amikor a rekordmutatót egy adott tulajdonságú rekordra szeretnénk beállítani, hogy utána valamilyen parancso(ka)t hajthassunk végre a rekordon. Kétféle keresési módszer áll rendelkezésünkre:
Soros (szekvenciális) keresés - a feltétel vizsgálata az első rekordon indul, és a megfelelő rekordon áll meg. Tetszőleges adatbázisra alkalmazható.
Gyorskeresés - kihasználja, hogy az állomány a keresési szempint szerint rendezett. Csak indexelt állomány esetén, a főindex keresésre használható.
7.1 Soros keresés
A soros keresést megvalósító parancs formája:
LOCATE [FOR <feltétel>] [WHILE <feltétel>] [<érvényességi kör>]
Leggyakrabban FOR paraméterrel használjuk (ilyenkor az érvényességi kör az "ALL" alapértelmezést kapja), ha elhagyjuk mindhárom paraméterét, az aktuális rekordot "tatalja meg". Bármilyen - dBASE által értelmezhető - feltétel szerint tud keresni az aktív adatbázisban.
Ezzel a paranccsal lehetőségünk van az összes adott feltételnek eleget tevő rekord megkeresésére. Az utolsó LOCATE parancs által kijelölt keresés folytatható (nincs minden munkaterületnek külön LOCATE lehetősége, ezért a folytatási parancs kiadása előtt mindig gondoskodjunk arról, hogy ugyanazon a munkaterületen legyünk, ahol eredetileg kiadtuk a LOCATE parancsot). A továbbfolytatás a
CONTINUE
Paranccsal (continue = folytat) kérhető.
Ez a parancs-pár (a LOCATE és a CONTINUE) is üzenetet küld a végrehajtás eredményéről ("Record = 00002" azt jelenti, hogy ráállt a rekordmutató a második rekordra, amint ezt a példában szereplő DISPLAY parancs is bizonyítja).
Ha az érvényességi körben nincs több ilyen tulajdonságú rekord, ezt "END OF FILE ENCOUNTERED" üzenettel jelzi. "ALL" érvényességi kör esetén a rekordmutató ilyenkor az állomány végén van. A LOCATE parancs rendezetlen és rendezett adatbázisban egyaránt tud keresni, indexelt adatbázisban a logikai sorrendben veszi sorra a rekordokat (ezért előfordulhat, hogy a tizedik rekordot hamarabb találja meg, mint az ötödiket).
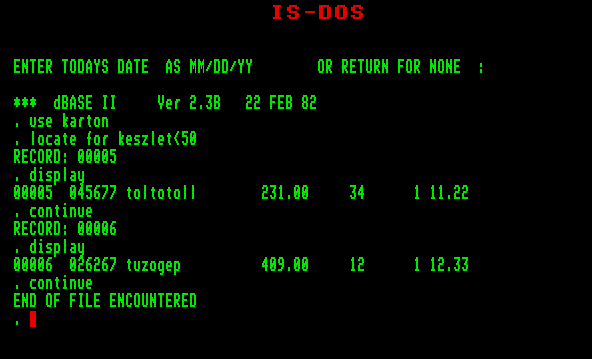
7.2.Gyorskeresés
A gyorskeresés működési elve miatt lényegesen gyorsabb mint a soros keresés (főleg nagyobb adatbázisoknál), de csak indexelt bázisban, a főindex szerinti keresésre alkalmazhatjuk. Nem adható meg paraméterként érvényességi kör, Mindenképpen az egész állományban keresünk. Ezt a keresési formát nem lehet továbbfolytatni, a feltételt kielégítő rekordok közül mindig csak az elsőt találhatjuk meg. Megjegyzendő azonban, hogy amennyiben vannak megfelelő rekordok, akkor azok a megtalált rekordot követik a logikai rendben. A parancs formája:
FIND <karaktersorozat> vagy <kifejezés>
Karakteres vagy numerikus indexkulcs mellett használható. A parancsszó után felírt karaktereket vagy számjegyeket hasonlítja össze indexkulccsal. Például - "CIKKNEV" szerint indexelt "KARTON" esetén - keressük "toltotoll" rekordját:
FIND toltotoll
A FIND előnye, hogy a karaktereket nem kell határolójelek közé tenni, hátránya, hogy ettől beszűkül a felhasználási lehetőségek köre. Például memóriaváltozók nem írhatók a parancsba csak úgy, önmagukban. Ha szóközzel kezdődő karakterláncot akarunk keresni, idézőjelek közé kell rakni a karaktersorozatot.
A parancs nem küld üzenetet, ha talált megfelelő rekordot, csak amikor nem talál, akkor üzen: "NO FIND" Mivel a rekordkeresésnek elsősorban programok készítésekor van jelentősége, szükségünk lehet annak eldöntésére, hogy találtunk-e megfelelő rekordot. Itt is használhatjuk az EOF függvényt, mert "nemtalálás" esetén biztosan az állomány végére kerül a rekordmutató.
7.2.1 A makróhelyettesítés funkciója
Többek között azért, hogy a FIND paranccsal memóriaváltozó értéke szerint is tudjunk keresni, meg kell ismerkednünk (és barátkoznunk) az makró-helyettesítéses funkcióval. Tegyük fel például, hogy van egy "ARUCIKK" nevű memóriaváltozónk, amiben elhelyeztük a "toltotoll" karaktersorozatot; keressünk most a változó segítségével:
FIND &arucikk
A "&" funkció hatására a dBASE még a parancs végrehajtása előtt a "&arucikk" helyére beírja a változó tartalmát, és ezek után gyakorlatilag végrehajtja a "FIND toltotoll" parancsot (a & jel és a változó neve között lehet szóköz).
A "&" funkció karakterláncok belsejében, határoló-jelek között is működik:
? "Ezek &arucikk.ak"
A parancs hatására "ezek toltotollak" felirat jelenik meg a képernyőn. A változónév mögötti pont jelzi a "&" funkció részére a memóriaváltozó nevének végét, utána újra konstans karakterek következnek.
Előnyös tulajdonsága a makró-helyettesítésnek, hogy tetszőleges parancsot is tárolhatunk makrókban, amit bármikor végrehajthatunk, akár parancsmódban, akár program futása közben:
STORE "DELETE RECORD" TO D
&D 5
A fenti két utasítás hatása: DELETE RECORD 5
Az elmondottak miatt, vagy ezek ellenére a "&" funkcióval bánjunk mindig óvatosan, egyrészt mert lelassítja a programvégrehajtást, másrészt a változó tartalmától függően megzavarhatja a tényleges parancsvégrehajtást.
8. Adatbázis készítése meglévő állományok felhasználásával
Alaptevékenységként az elsők között említettük, hogyan kell egy adatbázist létrehozni, megteremteni. Most azzal foglalkozzunk egy kicsit, hogy létező adatbázisaink felhasználásával hogyan tudunk új adatbázis-állományokat készíteni.
8.1. Adatbázis szerkezetének módosítása
Először egy olyan paranccsal ismerkedjünk meg, amelynek elsődleges célja nem az, hogy új állományt hozzon létre. Az adatbázisokkal végzett munka során bármikor szükség lehet az aktív adatbázis szerkezetének módosítására, például azért, mert egy meződefiníciót rosszul rögzítettünk, és javítani szeretnénk. Erre szolgál a
MODIFY STRUCTURE
parancs. (Csak az aktív adatbázis szerkezetét lehet így módosítani.) A parancs megjelenési formája hasonló, mint a CREATE parancsé, de a jelenleg létező mezők tulajdonságaikkal együtt ki vannak kiírva. Nekem leginkább úgy sikerült módosítani egy mező tulajdonságait, ha törlöm a sort (CTRL+G), majd újra beírjuk az egész, hasonlóan a CREATE parancsnál megismertekhez: vesszővel elválasztva a paramétereket. A funkció értelmét megkérdőjelezi, hogy bármit is módosítunk, mindenképpen elvész az adatbázis egész tartalma!
8.2. Az adatbázis részeinek másolása
A következő parancsok már vadonatúj lemezes adatbázis-állományokat hoznak létre, felhasználva a létező adatbázisokat (az új állományok típusjele alapértelmezés szerint ".DBF"). Az aktív adatbázisról vagy annak egy jól meghatározott részéről a
COPY TO <új állománynév> [<érvényességi kör>] [WHILE <feltétel>] [FOR <feltétel>] [FIELD <mezőlista>]
paranccsal készíthetünk másolatot. Az elhagyható paraméterek megfelelő definiálásával befolyásolhatjuk, hogy az adatbázisnak mely rekordjai és mezői kerüljenek át az új állományba. Paraméterek nélkül a teljes adatbázisról készít másolatot, de nem szabad elfelejteni, hogy az esetleges szűrőfeltételt és specifikált mezőlistát, valamint a főindex sorrendjét (ha van) figyelembe veszi ez a parancs is. Az átkerülő mezők tartalmukkal együtt másolódnak az új állományba. A létrejött állomány egyelőre a lemezen található, használat előtt a USE paranccsal meg kell nyitni. A COPY parancs végrehajtása után üzenetet kapunk, amelyből megtudjuk a másolt rekordok számát.
Másolhatjuk úgy is az aktív adatbázist, hogy a tartalmát nem mentjük át a másolatba. Ilyenkor az állománynak csupán a szerkezetét struktúráját - kopírozzuk le. A parancs:
COPY STRUCTURE TO <új állománynév> [FIELDS <mezőlista>]
A szerkezetről készített másolatban csak a mezők közti válogatásra van lehetőségünk. A rekordok nem kerülnek át az új állományba, amelynek így nem lesz egyetlen rekordja sem. Ezt is külön meg kell nyitni, ha használni szeretnénk.
Az üres szerkezetet megnyitása után valamely más állomány segítségével feltölthetjük az
APPEND FROM <állománynév> [FOR <feltétel>]
paranccsal. A forrásállománynak, amelyből a rekordokat át akarjuk emelni, zártnak kell lennie. A "FOR" paraméter feltételében csak olyan mezőnevek szerepelhetnek, amelyek mindkét állományban megtalálhatók. A parancs hatására az azonos nevű és típusú mezők feltöltődnek.
Az aktív adatbázis szerkezetét egy speciális állományba is bemásolhatjuk, amely maga is egy adatbázis, de rekordjaiban a másolt állomány meződefinícióit tartalmazza. Ezt a speciális adatbázist (melynek szerkezetét ugyanúgy a rendszer hozza létre, mint a katalógusállományokét) "szerkezeti állománynak" nevezzük; lehetőséget nyújt arra, hogy rekordtartalmát módosítva - akár programból is - új adatbázist készítsünk. A szerkezeti állományt létrehozó parancs:
COPY TO <állománynév> STRUCTURE EXTENDED
Az újonnan keletkező állomány, ha másként nem intézkedünk, ".DBF" típusjelet kap, és pontosan annyi rekordja lesz, ahány mezője van az aktív adatbázisnak, amelynek a szerkezetét tartalmazza. (A szerkezeti állományt is külön meg kell nyitni.)
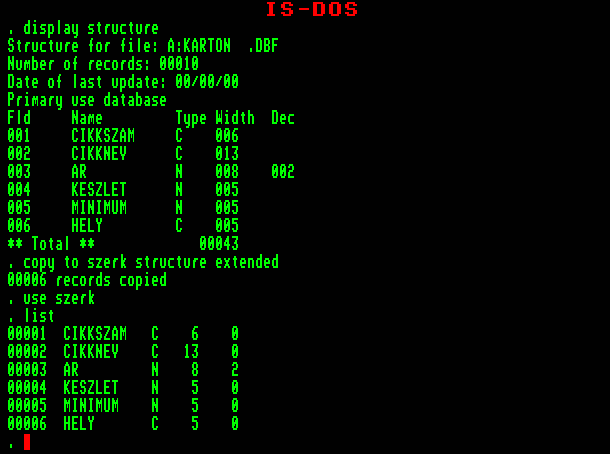
A szerkezeti állomány felépítése kötött (ha ki akarjuk használni adottságait, ne változtassunk a meződefinícióin). Négy mezője van, a következő tulajdonságokkal:
FIELD:NAME (karakteres típusú, 10 byte hosszú) - egy korábbi, illetve elkészítendő mező nevét tartalmazhatja, azaz betűket és számjegyeket
FIELD:TYPE (karakteres típusú, 1 byte hosszú) - az iménti mező típusát tartalmazhatja, azaz a C, N, L betűk valamelyikét
- FIELD:LEN (numerikus, 3 byte hosszú) - egy lehetséges mezőhosszt tartalmaz, azaz 1 és 254 közötti egész számot
- FIELD:DEC (numerikus, 3 byte hosszú) - a mezőhosszhoz tartozó tizedesjegyek számát tárolja
Amikor ezzel a szerkezeti állománnyal dolgozunk (mint adatbázissal, azaz a tartalmát módosítjuk), a dBASE nem ellenőrzi, hogy "értelmes" dolgok kerülnek-e a rekordjaiba vagy sem. Az esetleges hibák csak a szerkezeti állomány felhasználásakor derülnek ki, amikor új adatbázist szeretnénk segítségével létrehozni.
Vadonatúj adatbázis készíthető egy szerkezeti állomány felhasználásával, az alábbi paranccsal:
CREATE <állománynév> FROM <szerkezeti állomány neve> EXTENDED
(A parancs kiadása előtt a szerkezeti állományt le kell zárni.)
E parancs hatására létrejön egy új adatbázis-állomány olyan struktúrával, amilyent a szerkezeti állomány rekordjaiban elhelyeztünk. Az új állomány rekordjait nekünk kell feltölteni.
E két parancs (a COPY STRUCTURE EXTENDED és a CREATE FROM) felhasználásával olyan programokat írhatunk, amelyek futásuk közben építik fel a később használt adatbázisokat. (Kicsit csal az előbbi kijelentésünk, mert pusztán ezzel a két paranccsal nem lehet megoldani a paraméterezett programok írását. Ehhez szükségünk van még néhány speciális függvényre, amelyek ismertetésére a programozásról szóló fejezetben térünk ki.)
8.3. Az összegzetállomány
Egy aktív, numerikus mező(ke)t tartalmazó adatbázisról készíthetünk ún. összeg- vagy összegzetállományt, amelyben az eredeti állomány azonos kulcsú rekordjaiból egyetlen rekord jön létre; ez a numerikus mezőkben az eredeti adatbázis megfelelő rekordjainak összegét tartalmazza.
Az összegzetállományt elkészítő parancs végrehajtáskor feltételezi hogy az aktív adatbázis az összegzési kulcs alapján rendezett. A logikai rendet veszi figyelembe, tehát aktív indexállomány esetén a főindex által meghatározott sorrendet; ha nincs főindex, akkor a fizikai sorrend szerint megy végig a rekordokon. Ez azt jelenti, hogy mindenféleképpen végrehajtódik a parancs, csak rendezetlen állomány esetén nem összegez minden egyforma kulcsú rekordot, csupán azokat, melyek egymást kővetően helyezkednek el a logikai rendben. Az összegzetállományt a következő paranccsal állíthatjuk elő:
TOTAL TO <állománynév> ON <kulcsmező> [FIELDS <mezőlista>] [FOR <kifejezés>] [WHILE <kifejezés>]
A parancs "FIELDS" paramétere nem az elkészülő adatbázis mezőit határozza meg, hanem azokat a numerikus mezőket, amelyekben végre kell hajtani az összegzést. Alapértelmezés szerint minden numerikus mezőt összegez. (A parancs többi paraméterét már ismerjük.)
8.4. Adatbázis-állományok összefésülése
Két adatbázis felhasználásával is készíthetünk új állományt, ez a forrásállományok mezőit tartalmazza, megadott feltétel szerint "összefésülve" a rekordokat. A műveletben szereplő mindkét adatbázisnak nyitva kell valamely munkaterületen. A keletkező állomány rekordjainak sorrendjét befolyásolja, hogy a kettő közül melyik az aktív. Az állományok összefésülését a JOIN (= összekapcsol, csatla parancsszóval indíthatjuk:
JOIN TO <állománynév> FOR <kif.> FIELDS <mezőlista>
A FOR paraméter feltétele határozza meg, hogy mely rekordokból készül az új állomány. A végrehajtás során az aktív adatbázison megy végig a rendszer, a logikailag első rekordtól az utolsóig, és egy konkrét rekordon állva, a másik állományból kikeresi az összes olyan rekordot, amely kielégíti az adott feltételt, ezeket a megtalálás sorrendjében beírja adatbázisba. A parancs nem igényli egyik állomány rendezettségét sem, hiszen nem kulcs szerint keres.
 9. Nyomtatási lehetőségek
9. Nyomtatási lehetőségek
Temérdek begépelt információinkat előbb utóbb szeretnénk papíron is viszontlátni. Az sem mindegy, milyen formában böngészhetjük adatainkat, ezért szükség lehet, hogy (korlátok között) a saját igényeinknek megfelelő formában nyomtathassuk ki adatainkat. Az alaptevékenységek között már megismerkedtünk azzal a lehetőséggel (ld. a SET PRINT ON parancsot), amikor minden nyomtatásra került, ami a képernyőn megjelent, kivéve a teljesképernyő-szerkesztő parancsok eredményét. Ebben a fejezetben olyan a nyomtatási lehetőséggel foglalkozunk, amelyek csak a megjelenítendő információt nyomtatja, az ezt előállító parancsot nem.
9.1. Formázott nyomtatás
Ha az adatbázisokról készítünk listát, azt többnyire valamilyen formátumban szeretnénk látni, ez a forma általában gondos tervezés mellett sem (vagy éppen azért nem) egyezik meg az adatbázis rekordfelépítésével. Például egy listában nem árt, ha két adat között nem egy szóköz van, ahogy az a LIST és DISPLAY parancsok esetében szokásos; jó lenne értelmesebb fejlécet is írni a lista tetejére, a jelenleg LIST és DISPLAY esetén megjelenő mezőnevek, melyek nem biztos, hogy mindenkinek egyértelműen jellemzik a mező tartalmát; problémát okozhat, hogy listáink gyakran hosszabbak egy oldalnál, ilyenkor egy LIST segítségével készült lista teljesen kezelhetetlenné válik. A problémák megoldására létrehozható egy ún. felhasználói listaformátumot tartalmazó állomány. A listaformátum-állomány előállítása és módosítása menüvezérelt paranccsal történik. A listaformátum-állomány az aktív adatbázishoz jön létre. A parancs teljes formája:
REPORT [FORM <formátum-állomány neve>] [<érv.kör.>] [FOR <kif.>] [TO PRINT] [PLAIN]
Első feladatunk létrehozni az új állományt:
REPORT FORM formátum-állomány neve
Ha nem adtunk meg nevet (csak azt írjuk be REPORT), a program először megkérdezi, milyen néven hozza létre a formátum állományt. Az utasítás kiadása után az alábbi kérdéseket teszi fel:
Enter options, m=left margin, I=lines/page, w=page width.
Meg kell adnunk, hol legyen a bal margó, hány sor legyen egy oldalon, és milyen széles legyen egy oldal. Például: m=2, l=15, w=50.
Page heading required? Y/N
Kérünk-e fejlécet az oldalra? Ha igen, a következő kérése, hogy gépeljük be. (Enter page heading.)
Double space report? Y/N
Dupla sortávolsággal írja-e a jelentést?
Are totals required? Y/N
Akarjuk-e összegezni valamelyik mezőt?
Subtotals in report Y/N
Akarunk-e, a mezőkhöz készíteni részösszegzést a lap aljára?
Col. width,
Itt írjuk be, hogy melyik oszlopban mi legyen, és milyen szélességben. (Pl: 15,cikknev) Minden oszlop megadása után rákérdez a föléje írandó fejlécre is (Enter heading), Valamint, ha kívánunk összegezni (Totals Required?), és az adott mező numerikus, rákérdez, hogy akarjuk-e összegezni.
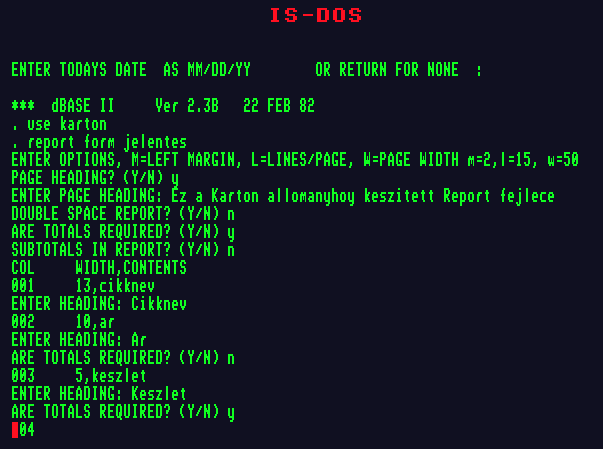
Ha mindez megvan, a formátumot egy file-ba tárolja, FMT kiterjesztéssel. A kész formátum-állományt ezek után máskor is használhatjuk. Ha minden kész, a jelentés megjelenik a képernyőn. Ez persze csak hevenyészett tájékozódásra jó, szebb jelentéseket programból lehet készíteni.
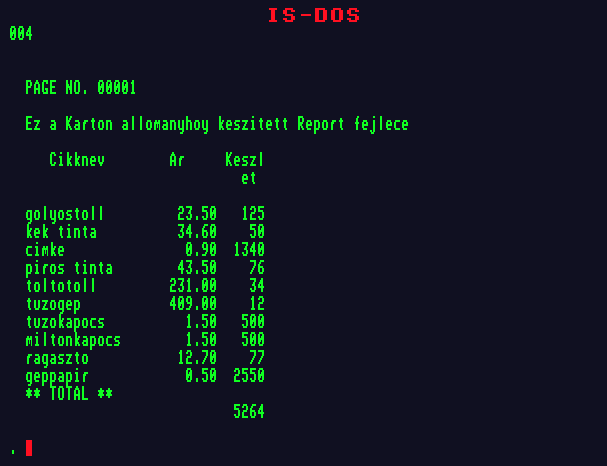
A kész jelentést bármikor kinyomtathatjuk a
REPORT [FORM <formátum-állomány neve>] [<érv.kör.>][FOR <kif.>] [WHILE <kif.>] TO PRINT
Mint láthatjuk, nemcsak a teljes adatbázis nyomtathatjuk, szűrőfeltételekkel meghatározhatjuk a nyomtatásban szereplő rekordokat. Jelentésünkben bármikor gyönyörködhetünk a képernyőn is, ha elhagyjuk a TO PRINT paramétert:
REPORT [FORM <formátum-állomány neve>] [<érv.kör.>][FOR <kif.>] [WHILE <kif.>]
10. Programozás dBASE II-vel
10.1. Néhány szó a "programozásról"
Egy-egy adatbázis használatakor általában ugyanolyan vagy hasonló tevékenységeket végzünk nap mint nap (például listát készítünk bizonyos rekordokról, egy rekordot kikeresve módosítunk benne valamit stb.). Az eddig megismert párbeszédes használat esetén a szükséges parancsokat minden alkalommal újra és újra be kell gépelni, ami fáradságos és egyáltalán nem illik bele a számítógépek "nagy tudásáról" alkotott képünkbe. Ha ezeket a dBASE parancsokat egy szöveges állományban helyezzük el, olyan utasítássorozatot, programot kapunk, amely egyetlen utasítás begépelésével elindítható és utána már "önállóan" dolgozik ugyanúgy, mint bármely más programozási nyelven PASCAL, C vagy BASIC) megírt program.
A gyakorlattal még nem rendelkező programozóknak is bátran ajánlhatjuk, hogy próbáljanak meg a dBASE segítségével programot írni (ha már a párbeszédes üzemmódban otthon érzik magukat). A dBase sok-sok hibaüzenete és tesztelési lehetősége előbb-utóbb mindenkit elvezet egy jól működő megoldáshoz. Ha rászántuk magunkat, érdemes a következő munkasorrendet betartani:
- a feladat pontos meghatározása, megértése
- a kimenő adatok meghatározása és formájuk megtervezése
- a szükséges - nyilvántartandó - adatok meghatározása és az állományok megtervezése
azon eljárás - tevékenységsorozat - megtervezése ("kitalálása"), amelynek eredménye a szükséges kimenet lesz (ezt az eljárást nevezik algoritmusnak)
- kódolás - az eljárás utasításainak lefordítása a dBASE parancsnyelvére
a program kipróbálása és a szükséges javításások elvégzése (ezt valószínűleg senki nem felejti el)
Ne keseredjünk el, ha első programjainkban látszólag több a hiba, mint a helyes utasítás, lehet, hogy egyetlen "fatális" hiba okozza az összes többit. Próbáljuk megtalálni és kijavítani a lehetséges hibákat, de amikor már "működik a remekmű", akkor se üljünk nyugodtan jól megérdemelt babérjainkon! Ugyanis a tapasztalt programozók körében igen elterjedt nézrt, hogy "tökéletes" programot nem lehet írni, ezért feltétlenül őrizzük kritikai érzékünket saját programunkkal szemben is.

10.2. dBASE programok készítése és futtatása
Tekintsük át a programírás manuális részét !
A programállomány elkészítéséhez szükségünk van egy szövegszerkesztő programra. Egyet beépítve tartalmaz a dBASE. Tekintve, hogy programjaink szöveges állományban tárolódnak, olyan szövegszerkesztőt használunk, amilyet akarunk. A szövegszerkesztő aktivizálása következő paranccsal történik:
MODIFY COMMAND <állománynév>
A parancs létrehozza a megadott nevű állományt, abban az esetben, ha még nem létezik, egyébként pedig jelenlegi tartalmát, a szerkesztővel együtt betölti a memóriába. Programíráskor az állománynévből a kiterjesztés elhagyható, ilyenkor automatikusan ".CMD" típusjelet kap az állomány, a megadott név az elkészülő program neve lesz.
A beépített szövegszerkesztő vezérlőbillentyűit a függelékben ismertetjük. (Annyit azért már itt segítek, hogy a szerkesztőből kilépni, és a változtatásokat elmenteni a CTRL+W billentyűkombinációval lehet.)
A programállományokba megkötés nélkül bármilyen dBASE utasítás, tehát a szintaktikai összefoglalóban található összes parancs beírható; ezek között van néhány, amelyet párbeszédes módban nem lehet használni, illetve olyanok, amelyeket programba nem érdemes beleírni. A formai követelmények azonosak a párbeszédes mód szabályaival, egyre mégis felhívjuk a figyelmet, mégpedig arra, hogy minden utasítást külön sorba kell írni, és az 'ENTER' billentyű megnyomásával kell befejezni. Ezt a szabályt különösen a "páros" parancsok használatánál ne feledjük el. Ha egy parancs fizikailag hosszabb, mint egy sor, akkor vagy folyamatosan írjuk (ilyenkor nincs "sorvégjel", de a következő sorban folytatódik a parancs, mivel beépített szövegszerkesztő automatikus szóátdobást végez), vagy pontosvessző (";") után 'ENTER'-rel befejezve a sort, a következő sorban folytatható az utasítás.
A programállományban a program elejét nem kell külön utasítás megjelölni. A program végét sem kötelező jelölni, de ezt már nem árt megtenni, mert a végrehajtást bizonyos helyzetekben megváltoztathatja. Egy program vagy eljárás végét jelölő utasítás a következő:
RETURN
Eljárásból kiadva a RETURN parancsot, a hívás helyére tér vissza a programvégrehajtás.
A parancsállomány (program) végrehajtását annak bármely pontján megszakíthatjuk a
CANCEL
paranccsal.
A program szövegébe megjegyzéseket ("commenteket") is elhelyezhetünk, melyek röviden magyarázzák egy-egy programrész tevékenységét, használatukkal programunk mások és (egy-két hét múlva) a magunk számára is érthetőbb lesz a puszta utasítások olvasásánál. Megjegyzés elhelyezhető külön sorban, a következő két "utasítás" valamelyikével:
NOTE <megjegyzés szövege>
* <megjegyzés szövege>
(Ha többsoros a megjegyzés, minden sor elejére ki kell írni a parancsszót.)
A parancsokat közvetlenül követően, azok sorában is elhelyezhetünk magyarázó szövegeket a "&&" jelek mögött (ez csak a fizikai sor végéig tarthat).
A kész programot a "pont prompt" mellett az alábbi parancs pelésével indíthatjuk:
DO <programállomány-név>
A parancs ".CMD" típusjelet feltételez, de más kiterjesztésű programállomány is elindítható, amennyiben a teljes nevét megadjuk.
Programvégrehajtás alatt (akárcsak párbeszédes módban) a dBASE ún. interpreterként viselkedik - az utasításokat sorról sorra értelmezi és próbálja meg végrehajtani (szinkrontolmácsol a gép és a programunk között). A bekövetkező hibákat azonnal jelzi az interaktív módban megszokott módon. Meg kell azonban jegyeznünk, hogy a hiba nem mindig a kijelzett sorban van.
10.3. Vezérlési szerkezetek
Az eljárásokban fontos szerepet kapnak az ún. vezérlési szerkezetek, amelyek használata minőségi különbséget jelent egy "program" és a párbeszédes parancsok egymás utáni végrehajtása között. Ezekkel a programnyelvi utasításokkal elérhető, hogy a különböző lehetőségek bekövetkezésekor, futás közben dőljön el, hogy pontosan milyen parancsokat hajtson végre a rendszer.
A dBASE II magasszintű programozási nyelvnek tekinthető, ezt bizonyítja az is, hogy rendelkezik olyan utasításokkal, amelyek ezeket a szerkezeteket létrehozzák és irányítják. (Az ilyen jellegű utasítások általában több részből állnak, így párbeszédes módban nem is használhatók. )
10.3.1. Döntési szerkezetek
Ezekben a programozási szerkezetekben valamilyen feltétel teljesülésétől függnek a továbbiakban végrehajtandó utasítások.
Egyszerű feltételes szerkezet:
A végrehajtás menete jól szemléltethető a blokkdiagramján. A szerkezetet létrehozó parancs formája: |
 |
IF<feltétel>
<parancsok>
ELSE
<parancsok>
ENDIF
IF ág:
a feltétel igaz volta esetén végrehajtandó parancsok
ELSE ág:
a feltétel igaz volta esetén végrehajtandó parancsok
|
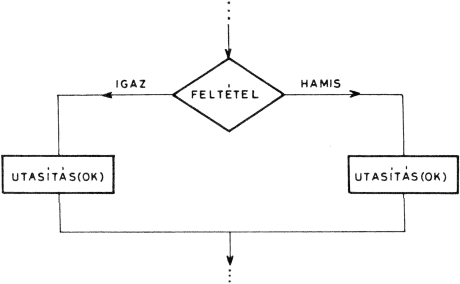 |
Ha az "ELSE" ágat elhagyjuk, hamis feltétel esetén azonnal az ENDIF utasítást követő parancsra lép a dBASE, és azt próbálja meg végrehajtani. Mindkét ágra tetszőleges utasítások írhatók, akár újabb IF szerkezet is, de vigyázzunk arra, hogy minden megnyitott IF-hez tartozzék egy ENDIF is!
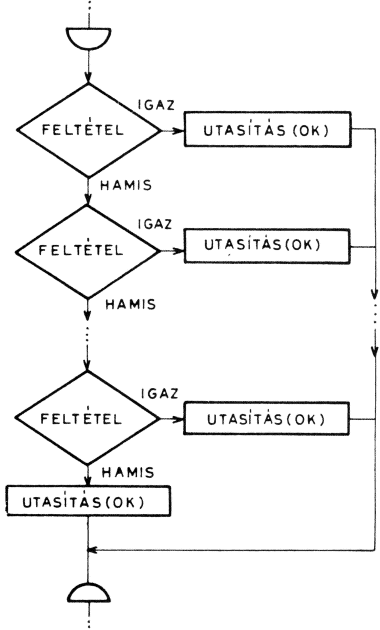 Esetszétválasztás:
Esetszétválasztás:
Néhány programnyelvben ezt "kapcsolószerkezetnek" is nevezik; több felsorolt feltételből kikeresi az első igaz értékűt, és a hozzá tartozó parancso(ka)t hajtja végre, majd kilép a szerkezetből, az azt követő utasításra. A szerkezet dBASE nyelvű megvalósítása:
DO CASE
CASE <feltétel>
<parancs(ok)>
[CASE <feltétel>
<parancs(ok)>]
[OTHERWISE
parancs]
ENDCASE
Csak egyetlen (az első igaz feltételű) CASE parancsait hajtja végre, utána kilép az ENDCASE utasítást követő parancsra. (A CASE ágak száma tetszőleges.) Az OTHERWISE után felsorolt parancsokat akkor hajtja végre, ha egyetlen feltételt sem talált igaznak. Ha nem használunk OTHERWISE részt, az ENDCASE után folytatódik a végrehajtás.
10.3.2. Ciklusszervezés
A ciklus egy utasításcsoport ismételt végrehajtása, amíg egy adott ún. ciklusfeltétel teljesül. Amikor a ciklusfeltétel hamissá válik, befejeződik a ciklus, és a ciklust követő paranccsal folytatódik a programvégrehajtás. A ciklust létrehozó utasításokat a következő formában kell a programszövegbe írni:
DO WHILE <feltétel>
<parancs(ok)>
ENDDO
Ez egy ún. elöltesztelt ciklus; a parancsok első végrehajtása előtt is ellenőrzi a feltételt. Ha már ekkor hamisnak találja, egyszer sem végzi el a ciklusmag utasításait. A ciklusok is "egymásba ágyazhatók", azaz a ciklusmag tartalmazhat egy másik ciklust, de azt is be kell fejezni az ENDDO utasítással. Elméleti szempontból fontos, hogy ha a programvégrehajtás belépett egy ciklusba, akkor a ciklusvégen is szigorúan át kell haladnia. Soha ne írjunk ciklusmag belsejébe RETURN parancsot. Programunkat egy program is elindíthatja, ilyenkor a RETURN hatására a hívott program befejeződik, de lezáratlanul marad a ciklus, és a hívó program ciklusai ettől zavarba jöhetnek.
A dBASE nyelve rendelkezik egy paranccsal, amelyek lehető ad számunkra, hogy a megkezdett ciklus befejezését a normális végrehajtás menetétől függetlenül is kezdeményezhessük. A
LOOP
parancs hatására a ciklusmag további parancsait figyelmen kívül hagyva, azonnal a ciklusfeltétel újbóli kiértékelését végzi el a rendszer. Ha előtte a ciklusfeltételben szereplő változó(k) értéke megváltozott, akkor ez a ciklus befejezését is jelentheti. Gyakran használjuk olyan helyzetekben is, amikor szeretnénk elölről elkezdeni a ciklusmag végrehajtását. Az utasítás az utoljára elkezdett - legbelső- ciklusra vonatkozik, azaz annak feltételét tudjuk újra kiértékeltetni. A külső, ezt tartalmazó ciklusokat az utasítás nem befolyásolja.
10.4. Változók a programokban
Programírás közben állandóan szükségünk van különböző tárolóhelyekre, ahol adatainkat ideiglenesen el tudjuk helyezni; mint már az alapfogalmaknál említettük, ezeket a tárolóhelyeket szokás változóknak nevezni. Programot írni változók használata nélkül szinte lehetetlen, mert így csak állandó értékű adatok szerepelhetnének az utasításokban, azaz minden alkalommal ugyanazt a tevékenységet végezné el a program, minden futtatás alkalmával pontosan ugyanazt az eredményt kapnánk. Az ilyen utasítássorozatot csak erős túlzással lehet számítógépes programnak tekinteni.
Programjainkban ugyanolyan változókat használhatunk, mint párbeszédes módban, azaz memóriaváltozókat és adatbázismezőket. Az eddig ismertetett, változókat kezelő parancsokon kívül rendelkezésünkre áll még néhány utasítás, amelyek egy részét nincs értelme programon kívül alkalmazni, de amelyek léte ékesen bizonyítja, hogy a változóknak (és itt most kivételesen elsősorban a memóriaváltozókat értjük ezen) a programírásban van elsődleges szerepük.
10.4.1. Memóriaváltozók használata programban
Először foglalkozzunk a memóriaváltozók programon belüli alkalmazásával! Ez több olyan új parancsot jelent, amelyek használatával nagyon kényelmesen és "egyszerűen" programozhatjuk adatbázis-kezelőnket. A memóriaváltozók definícióját- programon belül is az értékadó utasítások végzik. Az eddig megismert parancs (a STORE) mellett azonban használhatunk olyan utasításokat is, amelyek a program felhasználójától fogadnak adatot, és azt egy megadott memóriaváltozóban helyezik el. Az ilyen változók pontos értéke minden futtatásnál más és más lehet, értéküket a billentyűzeten begépelt kifejezés határozza meg.
Tetszőleges típusú adat bekérésére alkalmas a következő, interaktív dódban is használható (de legalább kipróbálható) parancs:
INPUT [<üzenet>] TO <memóriaváltozó>
Az "üzenet" egy karakteres kifejezés lehet, általában valamilyen magyarázószöveg, mellyel emlékeztetjük a felhasználót arra, hogy milyen jellegű adatot vár a program (ha ez egy állandó karaktersorozat, akkor a határolójelek közé kell tenni). Az "üzenet" a parancs végrehajtásának első lépéseként megjelenik a képernyőn (az utoljára használt sort követő sor első pozíciójától kezdve), és utána (a kurzortól kezdődően) gépelhetünk be egy tetszőleges, dBASE által értelmezhető kifejezést, a adott nevű memóriaváltozó ennek típusát és értékét veszi fel. Tekintettel arra, hogy kifejezést vár a parancs, a karakteres típusú adatok határolójelek között gépelve értékelődnek ki helyesen.
Próbaként gépeljük be a következő parancsot:
INPUT "Kerek begepelni egy szot: " TO szoveg
Hatására a képernyő következő sorában megjelenik az, általunk megadott üzenet, és mögötte a kurzor; ide gépelhetjük be például "PITE" szócskát mint karakteres adatot (idézőjelekkel együtt). A kifejezés begépelését az 'ENTER' billentyű megnyomásával kell befejezni. Egy egyszerű karakterlánc-állandó helyett begépelhető kifejezést is:
INPUT 'Kerek egy kifejezest:' to szoveg2
Kerek egy kifejezest:"ALMAS"+szoveg
? szoveg2 ALMASPITE
Kifejezetten csak karakteres adatok bevitelére alkalmas az
ACCEPT [<üzenet>] TO <memóriaváltozó>
parancs. Míg az INPUT parancs által létrehozott memóriaváltozóról csak futási időben dől el, hogy milyen típusú, addig az ACCEPT parancs a memóriaváltozót mindenképpen karakteres típusúként hozza létre, és begépelt karaktereket "betű szerint" helyezi el benne. Működési módja miatt nem kell határolójeleket használni a begépeléskor, illetve ha mégis kiírjuk ezeket, akkor a szöveg határolójelekkel együtt kerül a változóba.
Mindkét parancs a végrehajtáskor egy új memóriaváltozót hoz létre, illetve ha előzőleg már létezett ilyen nevű memóriaváltozó, akkor azt felülírja. A memóriaváltozó a típusát, hosszát, értékét mind az utasítás végrehajtásakor kapja. Az adat, illetve kifejezés begépelésének végét mindkét parancs esetén az 'ENTER' billentyű kell jeleznünk. Amíg ez nem történt meg, a program "áll".
A következő parancs is adatbevitelt valósít meg, de speciálisan egyetlen billentyű megnyomására vár, és amikor ezt megtettük, azonnal engedi tovább a program futását:
WAIT [TO <memóriaváltozó>]
Paraméter nélkül használva a parancs felfüggeszti a programvégrehajtást (a képernyőn erről a WAITING felirat tájékoztat), amíg a felhasználó egy tetszőleges billentyű megnyomásával nem jelzi, hogy folytatható az utasítások kiértékelése. A folytatáshoz a vezérlőbillentyűk (pl. a 'SHIFT' ) kivételével bármelyik billentyűt megnyomhatjuk.
Ha beírjuk a parancsba a "TO <memóriaváltozó>" paramétert is, a lenyomott billentyűnek megfelelő karakter bekerül a megadott nevű, egy byte hosszúságú memóriaváltozóba. Ha ezt a paramétert nem használjuk, a karakter nem tárolódik, utólag nem lehet lekérdezni, hogy milyen billentyű hatására folytatja a dBASE a programvégrehajtást.
Még egyszer hangsúlyozzuk, hogy míg az előző két parancs végrehajtásakor az 'ENTER' billentyű megnyomása jelzi az adatbevitel befejezését, addig a WAIT parancsát az első leütött billentyű hatására már befejeződik az utasítás végrehajtása.
Az ismertetett három parancs egyike sem ad lehetőséget arra, hogy adatbevitel képi formáját befolyásoljuk, ennek módjaira a "Formátumozott adatbevitel" című fejezetben térünk ki.
10.4.2. Adatbázismezők tartalmának módosítása programból
Ha nem is hangsúlyoztuk, eddigi példáinkból érezhető, hogy, az adatbázismezők és a memóriaváltozók egy lényeges tevékenység szempontjából nagyon különböznek egymástól. Ez pedig az értékadás. Ahhoz, hogy programjainkban tudjuk módosítani a mezők tattalmát, mégpedig anélkül, hogy a felhasználó kezébe helyeznénk minden ellenőrzési lehetőséget az EDIT, BROWSE vagy hasonló parancs segítségével, szükségünk lesz egy olyan utasításra, amely valamilyen változó vagy kifejezés értékét tudja elhelyezni egy adott mezőben. Ezt valósítja meg a következő parancs:
REPLACE [<érvényességi kör>] <mezőnév> WITH <kifejezés> [,<mezőnév2> WITH <kifejezés2> ...] [WHILE <feltétel>] (FOR <feltétel>]
Ez a parancs az érvényességi körébe eső rekordok (alapértelmezés szerint az aktuális rekord) megadott mezőinek tartalmát cseréli ki a megadott kifejezések értékével. Az összetartozó mezők és kifejezések típusának egyezni kell. Mezőnévként bármely nyitott adatbázis mezőjét megadhatjuk. Indexelt állományban az indexállomány minden egyes rekordon elvégzett módosítás után aktualizálódik. Ezért az indexkulcs mezőjében történő módosítás alkalmával a FOR és WHILE paraméter használata nem ajánlatos, mert az azonnali átrendeződés miatt bizonyos rekordok kimaradhatnak a műveletből.
Ha ezzel a paranccsal egy új rekordot szeretnénk kitölteni, akkor azt a rekordot előzőleg létre kell hozni. Erre szolgál az
APPEND BLANK
parancs, mely az adatbázishoz fűz egy új rekordot, és a rekordmutatót erre állítja, ezért az ezt követően kiadott REPLACE parancs, érvényességi kör nélkül megadva, ennek mezőit tudja módosítani.
Lehetőségünk van arra is, hogy egy teljes adatbázist aktualizáljunk másik, adatbázis-állomány segítségével, felhasználva a két állomány azonos tartalmú mezőit. A kulcs szerint megegyező rekordokban történik meg a módosítás. A parancsot az alábbi formában kel megadni:
UPDATE FROM <adat-állomány> ON <kulcsmező> ADD <mezőlista> vagy REPLACE <mezőlista>
Az adatbázis-állományok mezői is mint változók alkalmasak a felhasználói adat fogadására, erre azonban csak a formátumozott adatbevitelt megvalósító parancs használható (az "interaktív" APPEND, BROWSE és társaiktól eltekintve), ennek alkalmazását ismertetjük` következő fejezetben.
10.5. Formátumozott adatbevitel, adatmegjelenítés
Egyik eddig ismertetett adatbeviteli parancs sem adott lehetősé arra, hogy az adatbeviteli képernyő megjelenési formáját befolyásolhassuk. Az ún. formátumozott adatbevitelt megvalósító parancsok használatával egy egyszerű APPEND parancs "semmitmondó megjelenési formáját is megváltoztathatjuk, ily módon a program "felhasználó-barátsága" nő. A képernyőn nem csupán a kurzor vagy az adatbázismezők puszta neve jeleníthető meg, hanem általunk meghatározott magyarázó és segítségnyújtó szövegek is.
A formátumozott adatbevitel megvalósításához végeredményben egyetlen parancs ismerete elegendő. A parancs, amely a felhasználó által definiált formában fogadja billentyűzetről vagy jeleníti meg a képernyőn az adatokat, az adatbekérés vagy -megjelenítés pontos helyét is befolyása. A parancs teljes felépítése:
@ <oszlop>,<sor> [SAY <kifejezés> [USING <formátum>]]
@ <oszlop>,<sor> [SAY <kifejezés>] [GET <változó> [PICTURE <formátum>]]
A "sor" és "oszlop" paraméterek a kurzort pozícionálják, a "SAY" paraméter megjeleníti a kifejezés értékét, a "GET" paraméter az adott változó tartalmát ajánlja fel módosításra, a "PICTURE" paraméterrel lehet befolyásolni a megjelenítendő vagy tárolandó adat formáját és tartalmát.
A parancs összetettségére való tekintettel egyesével, példákkal illusztrálva tárgyaljuk a paramétereket; hogy ezek közül melyek hagyhatók el, illetve melyek használhatók együtt, azt a parancs szintaktikájából leolvashatjuk (a [] zárójeleket figyelembe véve). Érdemes kipróbálni interaktív módban a parancs formáit (közben néha le kell törölni a teljes képernyőt az ERASE paranccsal).
A "sor" és "oszlop" paraméterek helyezik a kurzort a képernyő megadott sorába, illetve oszlopába. Mindkét paraméter megadható numerikus változóval is, de ügyeljünk a korlátokra. A képernyőn 25 sorban és 80 oszlopban helyezhetők el karakterek. Példa a pozícionálásra:
@ 4,5
A "SAY" paraméter használatával egy kifejezés értékét tudjuk megjeleníteni, esetleg más formában, mint ahogy a kifejezésben található adatokat tároljuk (például a kisbetűs szavakat megjeleníthet nagybetűsként, anélkül hogy valójában módosítanánk a tárolt adatot). A kifejezésbe bármely nyitott adatbázis mezője beírható, de ez csak aktuális rekord mezőjét jelenti. Hangsúlyozzuk, hogy egyetlen kifejezés írható a paraméterbe, így több adat megjelenítéséhez különböző "trükkökre" lesz szükségünk. Példaként tekintsük a következő parancsot:
@ 4,5 SAY 'Az aru ara forintban: '+STR(ar,7,2)
Hatására a rendszer a megadott pozíciótól kezdve kiírja a határolójelek közé tett szöveget, és mögéje az aktuális rekord "ar" nevű mezőjének, tartalmát. (Az STR() konvertáló függvény a típusegyezés miatt kell, ennek második és harmadik argumentuma a keletkező karakterlánc hosszát, illetve a numerikus adatból az átalakítandó tizedesjegyek számát adja meg.) Ha egyetlen numerikus típusú kifejezés érti szeretnénk megjeleníteni, nem kell használni a különböző konvertáló függvényeket, de amikor ezeket karakteres adattal keverve íratjuk akkor már igen.
A "GET" paraméter segítségével adatokat tudunk a billentyűzetről bekérni. Mégpedig olyan kényelmes formában, hogy a megadott változó jelenlegi értéke megjelenik a képernyőn és - karakteres típusú adat esetén - azt a megszokott szerkesztőbillentyűkkel javíthatjuk olyanra, amilyent tárolni szeretnénk. A "PICTURE" paraméter használatával bizonyos mértékben korlátozhatjuk a bevihető adat formáját és tartalmát. A "GET" paraméterben megadott változónév egyaránt lehet memóriaváltozó és adatbázismező neve. A szerepeltetett változónak léteznie kell, ez memóriaváltozó esetében azt jelenti, hogy a beviteli parancs előtt valamilyen értékadó utasításban kell szerepeltetni, adatbázismező esetében pedig gondoskodnunk kell a parancs kiadása előtt, hogy a rekordmutató az aktív adatbázisnak egy rekordjára mutasson (az EOF() függvény ne legyen igaz értékű), és az adott táblázatban legyen olyan mező, melynek a megadott neve van.
A "@ ... GET" parancs az adatbevitelt még csak előkészíti; definiálja, hogy hol és mely változókba szeretnénk adatot bekérni. A tényleges adatbevitel engedélyezését (vagy ahogy másképpen szoktuk nevezni, a változók" aktivizálását) egy másik parancs, a
READ
végzi. Hatására a kurzor megjelenik az első változó kezdő pozíciójában. A parancs az előtte szereplő összes olyan "get változót" aktivizálja, amelyeket egy előző READ parancs még nem olvasott be. Az "összes" nem értendő szó szerint, ennek is van egy korlátja, mely számszerint 64. Ezt a 64 darab "get változót" célszerű egy oldalra zsúfolni, különben egyesek magyarázó szövegei már letörlődtek, és csak a puszta változó jelenik meg jelenlegi értékével. Az adatbevitel akkor ér véget, ha az utolsó változót is kitöltöttük, és leléptünk róla valamilyen módon (a kurzormozgató, illetve az 'ENTER' billentyű megnyomásával). Ameddig a kurzor valamelyik változó "mezőjében" látható, a szerkesztőbillentyűkkel bármilyen irányban mozoghatunk, például egy előzőleg kitöltött változót javíthatunk.
A READ parancs nélkül a "@ ... GET" parancsok hatására ugyan megjelennek a változók a képernyőn, de a program továbbfut, nem ad lehetőséget arra, hogy adatainkat begépeljük.
Numerikus változóba való adatbekérés esetén a dBASE csak számjegyeket, előjelet és/vagy tizedespontot fogad el. Minden egyéb billentyű megnyomásakor figyelmeztető hangjelzést ad a rendszer, és képernyőre nem ír ki újabb karaktert. Példa két változó beolvasására:
@ 2,2 SAY "Csaladnev:" GET CSNEV
@ 3,2 SAY "Keresztnev:" GET KNEV
READ
Előfordulhat (például egy cikluson belüli adatbekéréskor), hogy definiált "get változók" egy részét mégsem akarjuk a READ utasítással aktivizálni. Ilyenkor kell a
CLEAR GETS
parancsot használnunk, amely minden előtte kiadott, de READ-del még be nem olvasott GET parancsot figyelmen kívül hagyat a következő READ paranccsal.
Adatok megjelenítésénél és bekérésénél egyaránt használható paraméter a "PICTURE", amellyel az adat formáját és tartalmát befolyásolhatjuk bizonyos mértékig. Ezt a paramétert bevezető kulcsszót egy ún. formátumvezérlő karakterlánc vagy karakteres kifejezés követi, minden formavezérlő karakter egyetlen karakterre vonatkozik, mely az adott pozícióban helyezkedik el, ebből annyi van a karakterláncban, ahány karakteres a változó, vagy ahány karakterét be akarjuk olvasni (ezek a maszkkarakterek). A formátumvezérlő megadható egy előzőleg hozott karakteres változóval is.
A karakterláncba írt maszkkarakterek pontosan annak a karakternek a formáját befolyásolják, amelyik ezen a pozícióban helyezkedik el. Legtöbbször GET parancsban használjuk. A maszkban megadható karakterek az alábbiak:
- # - csak számot, vagy szóközt fogad el
- a - csak betűt fogad el
- X - mindenféle karaktert elfogad
- 9 - csak számot fogad el
- ! - nagybetűsíti a beírt karaktert (szókezdéskor hasznos)
Bármely egyéb jel a kiírásban elválasztójelként jelenik meg, és ezeket beolvasáskor a kurzor átlépi. Például a telefonszámba tehetünk kötőjeleket, vagy a körzetszámnak zárójeleket:
PICTURE "+(###)-###-##-##"
Az USING hasonló a PICTURE paraméterhez, de ezzel nem a beolvasandó változó "képét", hanem az általunk, a képernyőre írt kifejezés megjelenési formáját befolyásolhatjuk. A "USING" után megadható paraméterek:
X | - a mező / változó tartalma, vagy ha azon a helyen nincs semmi, akkor szóköz (Az X-et nagybetűvel kell írni) |
* és $ | - a mező / változó tartalma, vagy ha azon a helyen nincs semmi, akkor ezek a jelek jelennek meg. |
| |
Bármely egyéb jellel a mező / változó tartalmát a képernyőn felülírja. |
Példaként kérjünk be értéket a "KARTON" állományunk "HELY" mezőjébe a paranccsal:
@ 2,2 GET hely PICTURE '99.99'
A parancs kiírja a mezőt öt karakteren, középen megjelenít egy pontot. Kitöltéskor csak a tíz számjegy valamelyikét üthetjük le. A kiírt pontot átugorja a kurzor, azt felülírni nem tudjuk. Mivel a "HELY" mező karakteres típusú, ezt a pontot is tárolja.
A @ parancsok kimenetét állíthatjuk képernyőre, vagy nyomtatóra. A váltást a következő parancsokkal tehetjük meg:
SET FORMAT TO SCREEN vagy PRINT
Érdemes megemlíteni, hogy van még egy parancs, amivel a képerőre tudunk írni, ez pedig a REMARK. Ezzel a paranccsal csak egy adott karaktersorozatot tudunk írni a képernyőre, melynek a formája a következő:
REMARK szöveg
Mint látjuk, itt a megjelenítendő szöveget nem kell idézőjelbe tenni, tehát változók tartalmát ezzel a paranccsal nem tudunk megjeleníteni. (Viszont a makrók használatra itt is megoldást jelent).
10.6. Programtesztelési lehetőségek
A címben említett és "programtesztelési lehetőségeknek" nevezett módszerek a programban elkövetett különböző típusú hibák felderítésében segítenek. Három környezeti paraméter arra ad lehetőséget, hogy programfutás közben (vagy a befejezés után) ellenőrizhessük, mely parancsokat hajtotta végre a rendszer. Ez különösen ott előnyös, ahol a különböző vezérlési szerkezetek egymásba ágyazottsága miatt "szárazon" (papíron olvasgatva) nehéz felfedezni a logikailag hibás utasításokat.
Az alábbi parancs végrehajtása után a program minden utasítássorát végrehajtás előtt kiírja a képernyőre:
SET ECHO ON
A parancsot beépíthetjük a programba is, ha csak a kritikus részen a akarjuk tesztelni, hiszen szépen elkészített képernyőinket alaposan elrontják a megjelenő utasítások.) A következő paranccsal kérhetjük, hogy az ECHO paraméter kimenete - az utasítássorok, a képernyő telefirkálása helyett - a nyomtatón jelenjenek meg:
SET DEBUG ON
Vannak helyzetek, amikor érdemes a programot lépésenként végrehajtatni. Ezt úgy kell érteni, hogy minden parancs végrehajtására a felhasználó külön ad engedélyt a megfelelő billentyű megnyomásával, ha úgy gondolja, hogy felesleges folytatni, vagy szeretne menet közben módosítani egy változót, megszakíthatja a programvégrehajtást, ideiglenesen vagy akár végleg is. A lépésenkénti végrehajtáshoz az alábbi parancsot kell kiadni:
SET STEP ON
Ez a parancs is kiadható programból, de akkor csak az ezt követő parancsok végrehajtásakor tér át a lépésenkénti megállásra. Minden parancs végrehajtása előtt kiír egy üzenetet:
"Single step Y:=STEP, N:=KEYBOARD CMD, ESC:=CANCEL"
A "Y" megnyomásával folytathatjuk a program végrehajtását, az "N" megnyomása megszakítjuk a program futását, és tetszőleges parancs kiadására nyílik lehetőség (a programot az ESC megnyomásával folytathatjuk), az ESC megnyomásával félbeszakíthatjuk a program futását. A STEP paramétert az ECHO-val együtt érdemes használni, mert ha mindkettő be van kapcsolva, akkor azt is látjuk, hogy milyen parancs végrehajtását engedélyezzük.
10.7. A programozást segítő speciális függvények
Ebben a fejezetben bemutatunk néhány speciális függvényt, amelyeket interaktív módban nem nagyon használunk, de segítségükkel általánosan alkalmazható programok írhatók. Olyan adatok lekérdezését lehet velük megvalósítani, amelyeket más programnyelvekben alig, vagy egyáltalán nem lehet változóként használni. Ahhoz, hogy teljesen általános programot írhassunk, mindazoknak az adatoknak, logikai változóknak a pillanatnyi értékét meg kell tudnunk vizsgálni - a rendelkezésünkre álló utasításokkal -,amelyeket párbeszédes módban egyszerűen leolvashatunk a képernyőről.
Elsőként tekintsük át azokat a függvényeket, melyek az adatbázis szerkezetéről, jelenlegi állapotáról nyújtanak információkat. Ezekre szükségünk lehet például olyankor, ha a CREATE FROM utasítás segítségével programból állítjuk elő az adatbázis-állományt.
Lekérdezhető, hogy adott nevű (tetszőleges típusjelű) állomány létezik-e már a háttértárolón. A függvény formája:
FILE(<Kkif>)
argumentumban szereplő karakteres kifejezést állománynévnek tekinti a rendszer; a teljes nevet - kiterjesztéssel együtt - kell elhelyezni határolójelek között vagy egy erre alkalmas változóban). A függvény logikai értéket ad vissza (.T., ha létezik a keresett állomány, és .F., ha nem létezik). Példaként kérdezzük le, létezik-e a KARTON.DBF nevű állomány:
? FILE("karton.dbf")
Időnként szükségünk lehet (pl. keresés után), hogy melyik rekordon áll a rekordmutató. A
#
függvény a megnyitott adatbázisban a rekordmutató helyét mutatja, azaz melyik rekord az aktív.
A programozott adatbevitel során, ha INPUT utasítást adunk ki, a felhasználó hangulatától függően bármilyen típusú memóriaváltozó létrejöhet, pedig további utasításaink valószínűleg csak egyféle típusra vannak felkészítve. A
TYPE(<kifejezés>)
függvény a határolójelek közé tett kifejezés típusát adja vissza, a megfelelő kezdőbetűvel (C = karakteres, N = numerikus, L = logikai). Ha a felhasználó nem megfelelő típusú adatot helyezett el a változóban, bekérhetjük újra, vagy a konverziós függvények segítségével átalakíthatjuk a megfelelő típusra:
A logikai típusú adatokat nem lehet más típusúvá konvertálni. A típusellenőrzést, és az esetleges konvertálást, minden bevitel után érdemes elvégezni, hiszen a tisztelt felhasználó mindent el fog követni, hogy "kiakassza" a programunkat...
Ha egész számra van szükségünk, de egy kifejezés értéke tizedes jegyeket is tartalmaz (ami pl. osztás után elég gyakran előfordul), lehetőségünk van a tizedesjegyek elhagyására. Ezt a
INT(Nkif)
Függvénnyel tehetjük meg. Szándékosan kerültük a kerekítés említését, mivel a tizedesjegyek elhagyása nem azonos a kerekítéssel!
A karakterláncok kezelésére is szükségünk lesz néhány függvényre (ezek más programozási nyelvből ismerősek lesznek, esetleg más formában).
A LEN függvény egy karakterlánc hosszát adja meg:
? LEN ("HELLO")
A RANK függvény egy karakter ASCII kódját adja vissza. A következő kifejezés értéke: 65
? RANK ("A")
A CHR függvény a RANK ellentétje, azaz egy ASCII kódhoz tarozó karaktert ad meg. A következő kifejezés értéke: A
? CHR(65)
Ne felejtsük el, hogy a karakterlánc végén álló szóköz karakternek számít (bár nem látszik). Egy -véletlenül- a karakterlánc végére gépelt szóköz kellemetlen hibákat okozhat összehasonlításnál, és keresésnél, ezért ilyen művelet elvégzése előtt érdemes levágni ezeket a szóközöket:
TRIM (változó vagy kifejezés)
Programban hasznos lehet egy beolvasott kifejezésről eldönteni, hogy az helyes-e, milőtt hibát okozna a programfutásban. Erre szolgála a
TEST(<kifejezés>)
Ha a kifejezés helyes nullától eltérő értéket ad vissza, ha helytelen, nullát kapunk.
A kor "hagyományainak" megfelelően kapott helyet a dBASE függvényei között a
PEEK(<memóriacím>)
ami megadott memóriacímen lévő byte-ot adja vissza.Használata egy adatbáziskezelő rendszerben minimum fölösleges.
10.8. Néhány (jó)tanács a programozáshoz
A dBASE egyetlen utasítást sem tilt el a programban való használattól. Vannak azonban olyan parancsok, melyek használata mégsem ajánlatos, mert végrehajtásuk közben a felhasználó kezébe kerül mindennemű ellenőrzési jog, a program nem tudja befolyásolni, hogy a billentyűzeten mit és hová gépelünk be. Ilyen parancs az összes teljesképernyő-szerkesztő parancs (APPEND, EDIT, INSERT, BROWSE és az összes MODIFY, illetve CREATE parancs). Ezeket csak indokolt esetben, nagyon körültekintően célszerű programban elhelyezni. Az APPEND BLANK - tekintve, hogy nem is szerkesztő parancs - nem tartozik ide, programban igen gyakran előfordul.
Adatbázisainkat úgy is védhetjük a sérülésektől, hogy a programokban nem közvetlenül a valódi állományokat módosítjuk, hanem ideiglenes állományokban és változókban tároljuk a módosításokat, és egy-egy résztevékenység befejezése után aktualizáljuk az adatbázisokat (REPLACE, UPDATE parancsokkal). Az ideiglenes állományokat létrehozhatjuk programfutás közben is a COPY parancs különböző formáival. Ha egy valódi, "éles" adatbázisban módosítottunk valamit, lehetőleg rögtön zárjuk is le, hogy minden módosítás biztosan felkerüljön a lemezre, még ha, közben áramszünet is lenne.
A környezeti paraméterek közül többet érdemes a megfelelő értékre beállítani a program elején. Általában nem célravezető ezek alapértelmezésére, így a programunk megjelenése nagyon környezetfüggő lesz, szerencsétlen esetben működése is lehetetlenné válik.
Az egyes parancsok után megjelenő üzenetek interaktív módban nagyon hasznosak, de programunk eleganciáját erősen rontja, ezért programunkat érdemes a
SET TALK OFF
Paranccsal kezdenünk, hogy elkerüljük ezek megjelenését. A program befejezése előtt, viszont érdemes gondoskodni a visszakapcsolásáról.
Nem árt, ha programjainkat úgy írjuk meg, hogy a felhasználó ne tudjon kiszállni belőle, csak a szabályos, általunk programozott módon. Ehhez szerepeltetni kell a programban az ESCAPE paraméter kikapcsolását. Formája:
SET ESCAPE OFF
E parancs végrehajtása után, amíg vissza nem állítjuk ON értékre, az 'ESC' billentyű programmegszakító hatása nem működik. (A program tesztelésekor ezt még ne hajtassuk végre, mert mi sem tudjuk leállít programot; akkor sem, ha nyilvánvalóan végtelen ciklusba zuhant, és soha nem fog megállni, csak ha kikapcsoljuk a gépet.)
A felhasználó kedvéért, hogy programunk kezelését könnyebben elsajátítsa, kiadhatjuk az alábbi parancsot:
SET CONFIRM ON
Hatására a "@ ... GET" parancsokban a változókat nem lehet elhagyni másképp, csak az 'ENTER' billentyű megnyomásával. Egyébkép az olyan mezőkből, amelyeket teljesen ki kell tölteni, az utolsó karakter leütésekor külön intézkedés nélkül kilép a kurzor a következő mezőre - ha van még kitöltetlen "GET változó" a képernyőn -, és ez bizony megzavarhatja a számítástechnikában még járatlan felhasználókat.
Végül emlékeztetünk arra, amit a nyomtatási lehetőségeknél már említettük, hogy mindenféle nyomtatás közben a képernyőre is felkerül az információ (kivételt képez, amikor a "@ ... SAY" parancsot a nyomtatóra irányítjuk). Szépen megtervezett képernyőinkre, menüképeinkre ez igen károsan hat, ezért "természetesen" ezt is le lehet tiltani, erre szolgál a
SET CONSOL OFF
parancs. Ezt interaktív módban is végrehajtja a rendszer, de ott nyilván nincs értelme.
Természetesen nem hiányzik a parancsok között a PEEK függvény "párja" sem. A
POKE <memóriacím><byte-lista>
paranccsal okozhatunk adatvesztést eredményező rendszerösszeomlásokat. Az utasítás a memóriacímtől kezdődően helyezi el a byte-listában felsorolt, veszővel elválasztott byte-okat. A parancs használata egyáltalán nem ajánlott.
Végezetül álljon itt egy példaprogram részlet, mely a dBASE programokban gyakorlatilag nélkülözhetetlen menükezelést mutatja be:
STORE 0 TO choice
DO WHILE choice <> 6
ERASE
@ 3,1 SAY " ========================================================="
@ 4,28 SAY "Peldaprogram Menu "
@ 5,1 SAY " ========================================================="
@ 8,26 SAY "1) Telefonkonyv"
@ 10,26 SAY "2) Nev keresese"
@ 12,26 SAY "3) Rekord felvitele"
@ 14,26 SAY "4) Rekord javitasa"
@ 16,26 SAY "5) Rekord torlese"
@ 18,26 SAY "6) Kilepes"
STORE 0 TO choice
DO WHILE (choice < 1) .OR. (choice > 6)
@ 20,18 SAY "Valasszon a fenti lehetoseg kozul " GET choice PICTURE '9'
READ
ENDDO
DO CASE
CASE choice = 1
* Menu 1
CASE choice = 2
* Menu 2
CASE choice = 3
* Menu 3
CASE choice = 4
* Menu 4
CASE choice = 5
* Menu 4
ENDCASE
ENDDO |
Függelék
A. Szerkesztőbillentyűk
Az alábbi összefoglalónkban a dBASE II-ben előforduló összes teljesképernyő-szerkesztő parancs, illetve szövegszerkesztő vezérlőbillentyűt felsoroljuk. A billentyűzet kezelése sajnos eléggé nehézkes, lévén, hogy a dBASE CP/M program, így nem kimondottan Enterprise-ra készült. A billentyű táblázatot érdemes mindig kéznél tartani.
| Billentyű |
Funkció |
EDIT |
BROWSE |
APPEND
CREATE
INSERT |
MODIFY
STRUCTURE |
MODIFY
COMMAND |
CTRL + F
CTRL + J |
A kurzor a következő mezőre lép |
X |
X |
X |
X |
X |
CTRL + E
CTRL + A
|
A kurzor az előző mezőre/ felfelé lép |
X |
X |
X |
X |
X |
| CTRL + D |
A kurzor a következő karakterre (jobbra) lép |
X |
X |
X |
X |
X |
| CTRL + S |
A kurzor az előző karakterre (balra) lép |
X |
X |
X |
X |
X |
| CTRL + X |
Kurzor mozgatása lefelé |
X |
X |
X |
X |
X |
| CTRL + G |
A kurzor alatti karakter törlése (jobbratörlés) |
X |
X |
X |
X |
X |
| CTRL + C |
Menti a változtatásokat és a következő rekordra lép |
X |
X |
X |
X |
1 |
| CTRL + R |
Menti a változtatásokat és az előző rekordra lép |
X |
X |
|
X |
2 |
| CTRL + W |
kilépés a változások mentésével |
X |
X |
X |
X |
X |
| CTRL + Q |
kilépés a változások tárolása nélkül |
X |
X |
X |
X |
X |
| CTRL + Z |
A képernyőablak balra mozgatása |
|
X |
|
|
|
| CTRL + B |
A képernyőablak jobbra mozgatása |
|
X |
|
|
|
| CTRL + T |
Sor törlése a szöveg felzárásával |
|
|
|
X |
X |
| CTRL + N |
Üres sor beszúrása |
|
|
|
X |
X |
| CTRL + Y |
sor / mező tartalmának törlése |
X |
X |
X |
X |
X |
| CTRL + U |
törlésre jelölés be / ki |
X |
X |
X |
|
|
| CTRL + V |
felülírás / beszúrás üzemmód kapcsoló |
X |
X |
X |
X |
X |
| CTRL + P |
nyomtató be- / kikapcsolása |
X |
X |
X |
X |
X |
1 - Lapozás előre
2 - Lapozás hátra
A CTRL + M hatása megegyezik az ENTER lenyomásával.
Parancssorban a CTRL + R az előző parancsod adja ki újra, a, CTRL + X törli a parancssor tartalmát, a CTRL + H (ERASE) egy karaktert töröl vissza.
B. Méretkorlátozások és specifikációk
| Egy időben nyitott állományok száma |
16 |
| Rekordok száma egy állományban |
65535 |
| Mezők száma egy rekordban |
32 |
| Karakterek száma egy rekordban |
1000 |
| Karakterek száma egy mezőben |
254 |
| Memóriaváltozók száma |
64 |
| Memóriaváltozók hossza karakterben |
254 |
| Memóriaváltozók összterjedelme (byte) |
1536 |
| Változók nevének hossza (karakter) |
10 |
| Függőben lévő GET-ek száma |
64 |
| Állománynevek hossza (kiterjesztés nélkül) karakterben |
8 |
| Karakterlánc hossza (karakter) |
254 |
| Parancssor hossza (karakter) |
254 |
| Fejléc hossza a REPORT-ban (karakter) |
254 |
| REPORT-ban szereplő mezők száma |
24 |
| Indexelési kulcs hossza (karakterben) |
99 |
| SUM és REPLACE utasítás műveleteinek száma |
5 |
| Számítási pontosság számjegyekben |
10 |
| Legnagyobb ábrázolható szám |
1.8 *10^+63 |
| Legkisebb ábrázolható szám |
1.0 * 10^-63 |
C. Műveleti jelek és végrehajtásuk sorrendje
Aritmetikai műveletek:
| * |
szorzás |
1. |
| / |
osztás |
1. |
| + |
összeadás |
2. |
| - |
kivonás |
2. |
Összehasonlító (relációs) műveletek:
| > |
nagyobb |
3. |
| < |
kisebb |
3. |
| >= |
nagyobb vagy egyenlő |
3. |
| <= |
kisebb vagy egyenlő |
3. |
| <> vagy # |
nem egyenlő |
3. |
| = |
egyenlő |
3. |
Logikai műveletek:
| .NOT. |
negáció (tagadás) |
4. |
| .AND. |
logikai ÉS |
5. |
| .OR. |
logikai VAGY |
6. |
Karakterlánc-műveletek:
| + |
konkatenáció (összefűzés) |
1. |
| - |
konkatenáció, a köztes szóközöket a karakterlánc végére helyezve |
1. |
| $ |
részkarakterlánc képzése |
1. |
Először az 1. szint műveletei hajtódnak végre, az azonos szinten elhelyezkedő operátorok balról jobbra értékelődnek ki.
Vissza